【笔记】Neural Parameterization for Dynamic Human Head Editing
Neural Parameterization
Introduction
mesh方法易于编辑,但表现能力有限,NeRF的效果好,但是难以编辑;这篇工作用隐式方法完成一致性强的动态场景重建,同时可以显式地编辑几何及纹理。
之前的工作中,对NeRF进行编辑,采用的都是latent code的方式,这样无法得到好的结果。NeuTex用2D的texture maps对隐式场的表面建模,通过编辑2D texture maps来改变纹理,但只局限于静态场景,且无法改变几何。Nerual Atlas提出视频所有帧共享一个texture atlas space,将每个像素映射到这里,从而只需要修改texture atlas space就能一致地编辑视频纹理。
这篇工作将人头分解为三个部分,density volume,UV volume和2D texture,从而可以分别编辑几何和纹理。这三部分都是隐式建模的,从而获得更高的精度,以及更少的内存需求;为了显式编辑几何以及纹理,在MLP中加入explicit layers,从而获得一致性强的编辑结果。
直接对网络进行优化,会陷入局部最优解,因此引入了一些regularization,以及两步优化的策略。
Overview
重建的目标是获得一个模型F
即给一个空间坐标\(\mathbf{x}=(x,y,z)\),一个视角方向\(\mathbf{d} = (\theta,\phi)\)和时间戳\(t\),求得该点的颜色\(\mathbf{c}\)和密度\(\sigma\)
时间戳\(t\)被encode成一个latent code,并对\(\mathbf{x}\)和\(\mathbf{d}\)做position encoding
编辑则分为几何和纹理的编辑,又各有2个模型,显式和隐式
\(V\)表示几何模型,\(T\)表示纹理模型,下标\(I\)和\(E\)表示隐式和显式
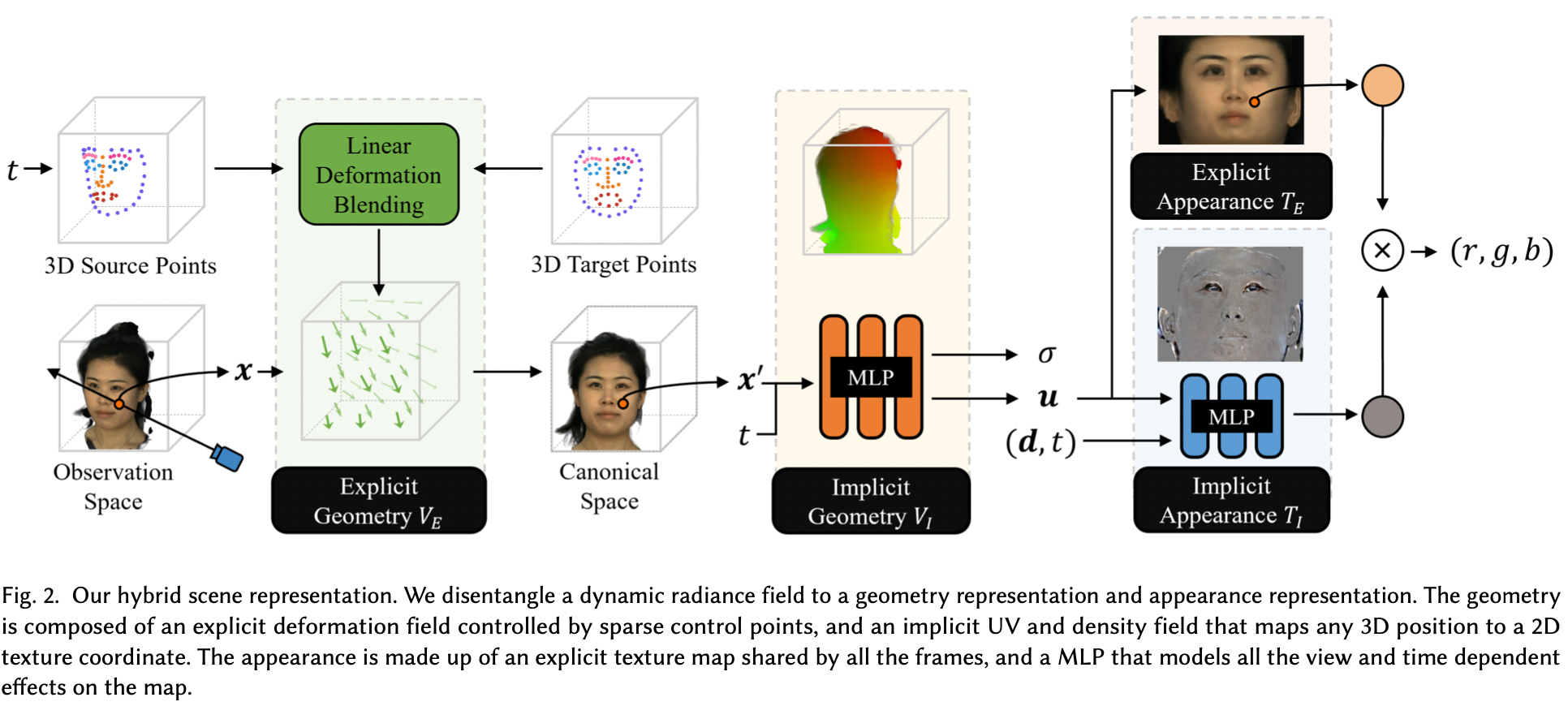
Geometry Modeling
几何重建的目标是,输入一个空间坐标和时间,输出UV坐标和density
如果只用隐式方法重建几何,将难以编辑
这里加入了\(V_E\),进行显式变形,理想的变形场需要满足三个要求
- 为了进行volumetric rendering,\(V_E\)要有density定义
- \(V_E\)要可微分,才能进行学习
- \(V_E\)可由部分参数控制,达到更精细的控制效果
\(V_E\)形如
其中的\(\psi(\cdot)\)是高斯核函数
为了获得一致性强的编辑,控制点要精心选取
如果一个控制点在所有帧中都有着相同的语义信息(即在人脸上的位置相同)
那么在任意一帧内修改这个控制点,便能将改变传播到其余所有帧中
作者在face landmark的基础上,挑了96个顶点,作为控制点

由于tracked face mask可能不准确,添加了一个loss监督控制点尽量贴近顶点
最终的UV模型为
这里\(V_I\)用来建模一些短暂的变化,比如眨眼
Appearance Model
为了对view dependent和time dependent的texture进行建模,选择了隐式模型
但这将导致难以编辑,因此加入显式texture maps
显式的\(T_E\)存储大部分texture信息,而隐式\(T_I\)则负责建模瞬间的变化(如皱纹的变化)
最终的texture表示为
由于我们希望\(T_E\)存储主要信息,\(T_I\)存储其余的信息,因此加入loss
这样会鼓励\(T_I\)尽量小,从而使得\(T_E\)的贡献更大
Rendering
采用和NeRF一样的volume rendering
Training
Main Supervision
添加了对\(\alpha\)的监督,从而防止网络用伪影来仿造材质效果
Texture Unwrap Regularization
网络已经可以获得不错的重建质量了,但是UV field噪声非常多,导致难以进行下一步编辑

首先用tracked 3D face进行监督
由于tracked face不够精确,所以这个loss的weight在20000轮左右指数衰减到0
同时,添加了cycle loss,更合理地建模头部表面信息
其中\(\hat{\mathbf{x}}'_i = V_I^{-1}(\mathbf{u},t)\),\(V^{-1}_I\)将UV坐标映射回3D坐标
为了更平滑地建模,添加了保角loss
Two-stage Training
为了更好地编辑,希望texture尽量静止,因此采用了两步训练法
首先固定材质(实际上是让所有时间戳映射到统一输出),让UV field尽可能学习
然后再加入动态材质,进行进一步优化,学习UV field没能成功建模的部分
Experiments
Reconstruction
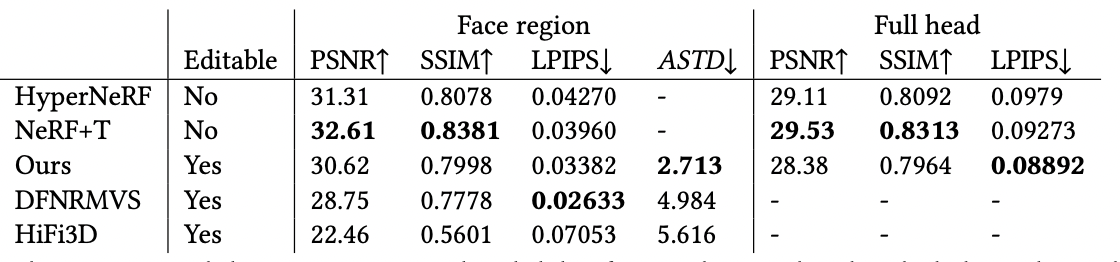
比NeRF系列略差一些,因为为了增强可编辑性,做了许多regularization
做完regularization后,效果应该更好才对?
Editing

在UV maps上,这篇工作的一致性更好,同一点始终在脸上的同一位置
并且能覆盖到整个头部,其他方法只能追踪部分

这是不同帧texture maps的情况,这篇工作的变化更少,一致性更强
Ablations
\(\mathcal{L}_{sparsity}\)旨在降低\(T_I\),让\(T_E\)完成主要材质,\(T_I\)作为辅助
可以看到,\(\lambda_{sparsity}\)过小,会让\(T_I\)学太多信息;过大则会让\(T_I\)学不到重要的temporal variations
最终选了0.05,兼顾了\(T_E\)和\(T_I\)

Two-stage Training让texture maps更趋于静态,一致性更强,从而易于编辑

\(\mathcal{L}_{angle}\)的权重小,会有更好的重建效果(因为regularization更弱)
但这样一来,UV maps噪声太多,难以编辑
若权重过大,模型不收敛,性能急剧下降
最终选了\(\lambda_{angle}=0.5\)作为重建和编辑最好的trade-off

\(\mathcal{L}_{semantic}\)的加入,让控制点保持一致的位置,便于编辑
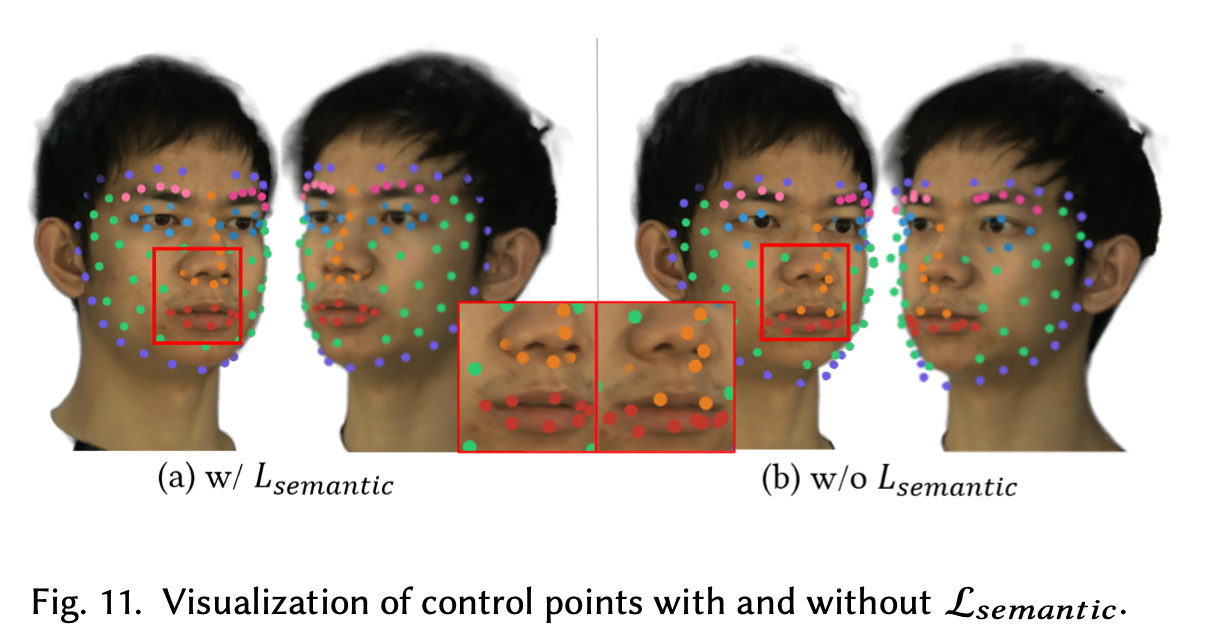
\(V_E\)本意是便于几何编辑,但意外地能增强重建的质量

本文来自博客园,作者:GhostCai,转载请注明原文链接:https://www.cnblogs.com/ghostcai/p/16572238.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号