保存中文文本
SON 函数
使用 JSON 函数需要导入 json 库:import json。
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
json.dumps
json.dumps 用于将 Python 对象编码成 JSON 字符串。
语法
json.dumps(obj, skipkeys=False, ensure_ascii=True,\
check_circular=True, allow_nan=True, cls=None, indent=None, \
separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
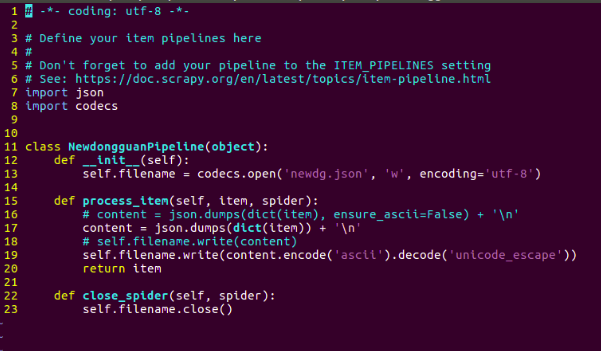
其中参数ensure_ascii=False,表示json.dumps转换python数据时禁用ascii编码格式,如果保存文本想为友好中文则禁用,
文本中出现其他编码格式的文本时可用上面图片中的两种方法,处理。
python 原始类型向 json 类型的转化对照表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| None | null |
json.loads
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
json.loads(s[, encoding[, cls[, \
object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
json 类型转换到 python 的类型对照表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number (int) | int, long |
| number (real) | float |
| true | True |
| false | False |
| null | None |
JSON 函数
| 函数 | 描述 |
|---|---|
| encode | 将 Python 对象编码成 JSON 字符串 |
| decode | 将已编码的 JSON 字符串解码为 Python 对象 |
encode
Python encode() 函数用于将 Python 对象编码成 JSON 字符串。
语法
demjson.encode(self, obj, nest_level=0)
实例
以下实例将数组编码为 JSON 格式数据:
#!/usr/bin/python
import demjson
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = demjson.encode(data)
print json
以上代码执行结果为:
[{"a":1,"b":2,"c":3,"d":4,"e":5}]
decode
Python 可以使用 demjson.decode() 函数解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
demjson.decode(self, txt)
实例
以下实例展示了Python 如何解码 JSON 对象:
#!/usr/bin/python
import demjson
json = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = demjson.decode(json)
print text
以上代码执行结果为:
{u'a': 1, u'c': 3, u'b': 2, u'e': 5, u'd': 4}
二、编码对比
在 Python 中,不论是 Python2 还是 Python3 中,总体上说,字符都只有两大类:
- 通用的 Unicode 字符;
- (unicode 被编码后的)某种编码类型的字符,比如 UTF-8,GBK 等类型的字符。
Python2 中字符的类型:
- str: 已经编码后的字节序列
- unicode: 编码前的文本字符
Python3 中字符的类型:
- str: 编码过的 unicode 文本字符
- bytes: 编码前的字节序列
我们可以认为字符串有两种状态,即文本状态和字节(二进制)状态。Python2 和 Python3 中的两种字符类型都分别对应这两种状态,然后相互之间进行编解码转化。编码就是将字符串转换成字节码,涉及到字符串的内部表示;解码就是将字节码转换为字符串,将比特位显示成字符。
在 Python2 中,str 和 unicode 都有 encode 和 decode 方法。但是不建议对 str 使用 encode,对 unicode 使用 decode, 这是 Python2 设计上的缺陷。Python3 则进行了优化,str 只有一个 encode 方法将字符串转化为一个字节码,而且 bytes 也只有一个 decode 方法将字节码转化为一个文本字符串。
Python2 的 str 和 unicode 都是 basestring 的子类,所以两者可以直接进行拼接操作。而 Python3 中的 bytes 和 str 是两个独立的类型,两者不能进行拼接。
Python2 中,普通的,用引号括起来的字符,就是 str;此时字符串的编码类型,对应着你的 Python 文件本身保存为何种编码有关,最常见的 Windows 平台中,默认用的是 GBK。Python3 中,被单引号或双引号括起来的字符串,就已经是 Unicode 类型的 str 了。
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号