pacemaker入门
原文链接:https://blog.csdn.net/a964921988/article/details/82628478
因为数据库部署在Linux上,需要做数据库集群实现高可用,而所有的PostgresqlHA方案中,流复制HA的可用性,部署成本,性能都是比较好的,而管理流复制集群的工具,pacemaker+corosync则是比较成熟可靠的,借此机会学习下Pacemaker。Pacemaker官网 http://clusterlabs.org/
简要介绍
Pacemaker是Linux环境中使用最广泛的开源集群资源管理器
- Pacemaker利用集群基础架构(Corosync或者Hearbeat)提供的消息和集群成员管理功能,实现节点和资源级别的故障检测和资源恢复,从而最大程度保证集群服务的高可用
- 从逻辑功能而言,pacemaker在集群管理员所定义的资源规则驱动下,负责集群中软件服务的全生命周期管理,这种管理甚至包括整个软件系统以及软件彼此之间的交互.
- Pacemaker在实际应用中可以管理任何规模的集群,由于其具备强大的资源依赖模型,这使得集群管理员能够精确描述和表达集群资源之间的关系(包括资源的顺序和位置等关系).同时,对于任何形式的软件资源,通过为其自定义启动与管理脚本(资源代理),几乎都能最为资源对象被Pacemaker管理.
- Pacemaker仅是资源管理器,并是不提供集群心跳信息,由于任何高可用集群都必须具备心跳监测机制,因而很多初学者总会误以为Pacemaker本身具有心跳监测功能,而事实上Pacemaker的心跳机制主要基于Corosync或Hearbeat来实现
- Pacemaker只是作为HA资源管理器,所以不要相当然它能够直接管控资源,如果你的资源没有做脚本配置那么对于Pacemaker来说它就是不可管理的.
特性
1、监测并恢复节点和服务级别的故障。
2、存储无关,并不需要共享存储。
3、资源无关,任何能用脚本控制的资源都可以作为集群服务。
4、支持节点 STONITH功能以保证集群数据的完整性和防止集群脑裂。
5、支持大型或者小型集群。
6、支持 Quorum机制和资源驱动类型的集群。
7、支持几乎是任何类型的冗余配置。
8、自动同步各个节点的配置文件。
9、可以设定集群范围内的 Ordering、 Colocation and Anti-colocation等约束。
10、高级服务类型支持,例如:
Clone功能:即那些要在多个节点运行的服务可以通过Clone功能实现,Clone功能将会在多个节点上启动相同的服务;
Multi-state功能:
即那些需要运行在多状态下的服务可以通过 Multi--state实现,
在高可用集群的服务中,有很多服务会运行在不同的高可用模式下,如:Active/Active模式或者 Active/passive模式等,
并且这些服务可能会在 Active 与standby(Passive)之间切换。
11、具有统一的、脚本化的集群管理工具。
pacemaker 总体架构与详细架构
总体架构
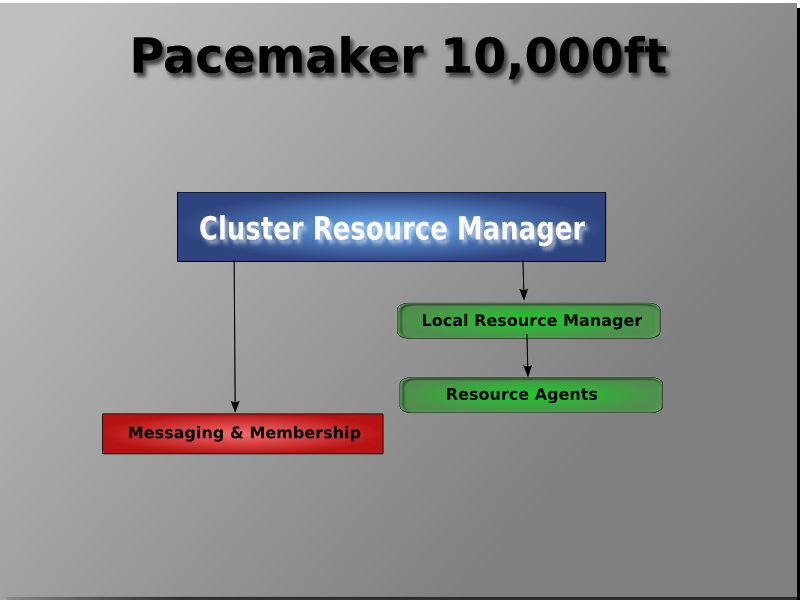
在最高一个层次,集群由三个部分组成:
- 提供消息和集群关系功能的集群核心基础组件(红色的部分)
- 集群无关的组件(蓝色部分),在Pacemaker架构中,这部分不仅包含有怎么样启动,关闭,监控资源的脚本,而且还有一个本地的守护进程来消除这些脚本实现的(采用的)不同标准之间的差异.
- 大脑(绿色部分)处理并响应来自集群和资源的事件(比如节点的离开和加入,资源的失效),以及管理员对配置文件的修改。在对所有这些事件的响应中,Pacemaker会计算集群理想的状态,并规划一个途径来实现它。这个操作可能会包含移动资源,停止节点,甚至使用远程电源管理来强制使他们下线。
详细架构
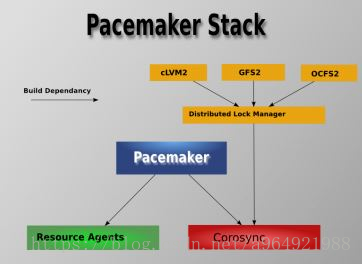
- Pacemaker - 资源管理器(CRM),负责启动和停止服务,而且保证它们是一直运行着的以及某个时刻某服务只在一个节点上运行(避免多服务同时操作数据造成的混乱)。
- Corosync - 消息层组件(Messaging Layer),管理成员关系、消息和仲裁。
-
Resource Agents - 资源代理,实现在节点上接收 CRM 的调度对某一个资源进行管理的工具,这个管理的工具通常是脚本,所以我们通常称为资源代理。任何资源代理都要使用同一种风格,接收四个参数:{start|stop|restart|status},包括配置IP地址的也是。每个种资源的代理都要完成这四个参数据的输出。Pacemaker 的 RA 可以分为三种:(1)Pacemaker 自己实现的 (2)第三方实现的,比如 RabbitMQ 的 RA (3)自己实现的,比如 OpenStack 实现的它的各种服务的RA,这是 mysql 的 RA。
pacemaker 内部组件
Pacemaker作为一个独立的集群资源管理器项目,其本身由多个内部组件构成,这些内部组件彼此之间相互通信协作并最终实现了集群的资源管理。
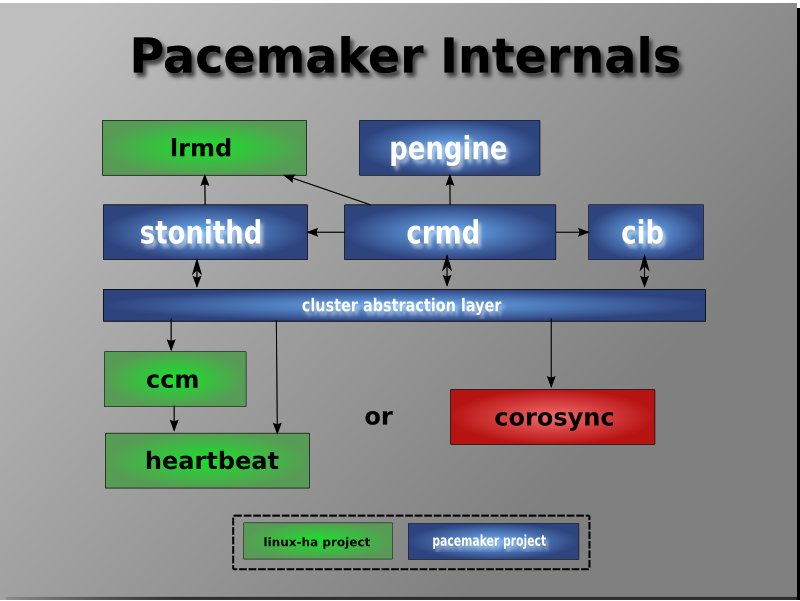
- CIB:集群信息基础( Cluster Information Base):集群信息基础,在内存中的一个xml格式集群配置文件,包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有集群节点。
- CRMd:集群资源管理进程( Cluster Resource Manager deamon):集群资源管理守护进程,每个crmd上有一个cib用来定义维护资源, 主要是消息代理的PEngine和 LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群。
- LRMd:本地资源管理进程(Local Resource Manager deamon):本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)。
- PEngine(PE):策略引擎(PolicyEngine):根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表。
- STONITHd:集群 Fencing进程( Shoot The Other Node In The Head deamon)。
CIB主要负责集群最基本的信息配置与管理,Pacemaker中的 CIB主要使用 XML的格式来显示集群的配置信息和集群所有资源的当前状态信息。CIB所管理的配置信息会自动在集群节点之间进行同步, PE将会使用 CIB所提供的集群信息来规划集群的最佳运行状态。并根据当前 CIB信息规划出集群应该如何控制和操作资源才能实现这个最佳状态,在 PE做出决策之后,会紧接着发出资源操作指令,而 PE发出的指令列表最终会被转交给集群最初选定的控制器节点( Designated controller,DC),通常 DC便是运行 Master CRMd的节点。
在集群启动之初, pacemaker便会选择某个节点上的 CRM进程实例来作为集群 Master CRMd,然后集群中的 CRMd便会集中处理 PE根据集群 CIB信息所决策出的全部指令集。在这个过程中,如果作为 Master的 CRM进程出现故障或拥有 Master CRM进程的节点出现故障,则集群会马上在其他节点上重新选择一个新的 Master CRM进程。
在 PE的决策指令处理过程中, DC会按照指令请求的先后顺序来处理PEngine发出的指令列表,简单来说, DC处理指令的过程就是把指令发送给本地节点上的 LRMd(当前节点上的 CRMd已经作为 Master在集中控制整个集群,不会再并行处理集群指令)或者通过集群消息层将指令发送给其他节点上的 CRMd进程,然后这些节点上的 CRMd再将指令转发给当前节点的 LRMd去处理。当集群节点运行完指令后,运行有 CRMd进程的其他节点会把他们接收到的全部指令执行结果以及日志返回给 DC(即 DC最终会收集全部资源在运行集群指令后的结果和状态),然后根据执行结果的实际情况与预期的对比,从而决定当前节点是应该等待之前发起的操作执行完成再进行下一步的操作,还是直接取消当前执行的操作并要求 PEngine根据实际执行结果再重新规划集群的理想状态并发出操作指令。
在某些情况下,集群可能会要求节点关闭电源以保证共享数据和资源恢复的完整性,为此, Pacemaker引人了节点隔离机制,而隔离机制主要通过 STONITH进程实现。 STONITH是一种强制性的隔离措施, STONINH功能通常是依靠控制远程电源开关以关闭或开启节点来实现。在 Pacemaker中, STONITH设备被当成资源模块并被配置到集群信息 CIB中,从而使其故障情况能够被轻易地监控到。同时, STONITH进程( STONITHd)能够很好地理解 STONITH设备的拓扑情况,因此,当集群管理器要隔离某个节点时,只需 STONITHd的客户端简单地发出 Fencing某个节点的请求, STONITHd就会自动完成全部剩下的工作,即配置成为集群资源的 STONITH设备最终便会响应这个请求,并对节点做出 Fenceing操作,而在实际使用中,根据不同厂商的服务器类型以及节点是物理机还是虚拟机,用户需要选择不同的 STONITH设备。
pacemaker 支持的集群模式
Pacemaker 支持多种类型的集群,包括 Active/Active, Active/Passive, N+1, N+M, N-to-1 and N-to-N 等。
Active/Active
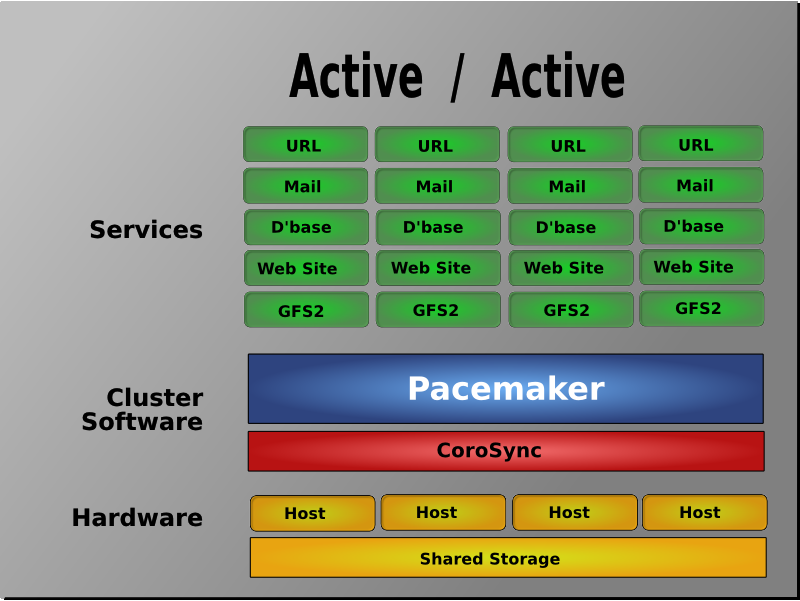
在这种模式下,故障节点上的访问请求或自动转到另外一个正常运行节点上,或通过负载均衡器在剩余的正常运行的节点上进行负载均衡。这种模式下集群中的节点通常部署了相同的软件并具有相同的参数配置,同时各服务在这些节点上并行运行。
Active/Passive模式
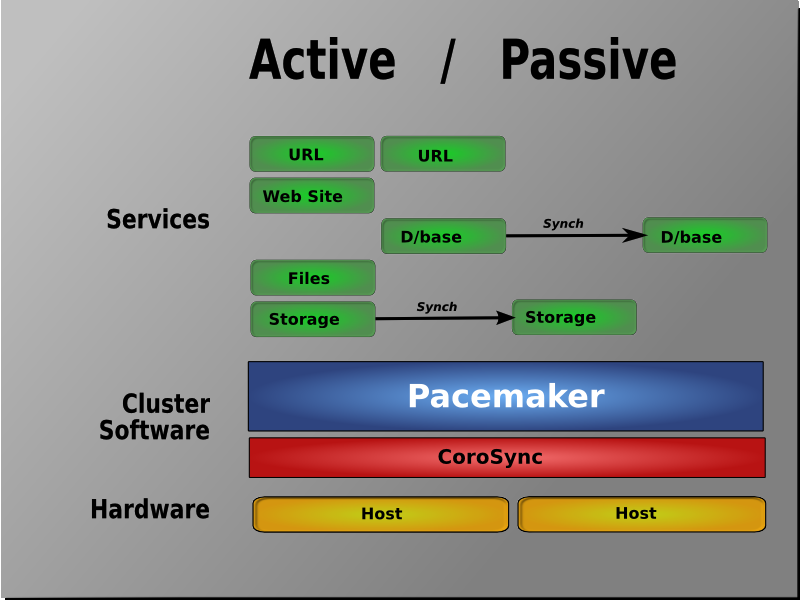
在这种模式下,每个节点上都部署有相同的服务实例,但是正常情况下只有一个节点上的服务实例处于激活状态,只有当前活动节点发生故障后,另外的处于 standby状态的节点上的服务才会被激活,这种模式通常意味着需要部署额外的且正常情况下不承载负载的硬件。
- N+1模式 所谓的N+1就是多准备一个额外的备机节点,当集群中某一节点故障后该备机节点会被激活从而接管故障节点的服务。在不同节点安装和配置有不同软件的集群中,即集群中运行有多个服务的情况下,该备机节点应该具备接管任何故障服务的能力,而如果整个集群只运行同一个服务,则N+1模式便退变为 Active/Passive模式。
- N+M模式 在单个集群运行多种服务的情况下,N+1模式下仅有的一个故障接管节点可能无法提供充分的冗余,因此,集群需要提供 M(M>l)个备机节点以保证集群在多个服务同时发生故障的情况下仍然具备高可用性, M的具体数目需要根据集群高可用性的要求和成本预算来权衡。
- N-to-l模式 在 N-to-l模式中,允许接管服务的备机节点临时成为活动节点(此时集群已经没有备机节点),但是,当故障主节点恢复并重新加人到集群后,备机节点上的服务会转移到主节点上运行,同时该备机节点恢复 standby状态以保证集群的高可用。
- N-to-N模式 N-to-N是 Active/Active模式和N+M模式的结合, N-to-N集群将故障节点的服务和访问请求分散到集群其余的正常节点中,在N-to-N集群中并不需要有Standby节点的存在、但是需要所有Active的节点均有额外的剩余可用资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号