80 吴恩达机器学习课程笔记
0 引言
在具体的机器学习实践中,发现碰到了很多问题,这些问题单凭不断实验已经无法解决了,必须要从理论上提高认识水平,来进一步指导自己的研究。具体的问题有下面这些。
(1)针对具体问题,是选择特征工程 + 机器学习(ML)方法还是采用端到端的深度学习(DL)方法?
(1.1)问题本身是否适合用深度学习/机器学习,通常认为深度学习模型复杂度高,需要数据量大,可解释性差,但是泛化能力好。而机器学习模型复杂度相对较低,所需数据量小,可解释性好,泛化能力一般比深度学习要差一些。
(1.2)如果采用机器学习,考虑自己提取特征的话,需要调研文献,看看学术界针对具体问题提取了哪些特征,这些特征是否容易泛化等。
(2)如何评价(evaluation)模型的效果?
(2.1)训练集与测试集的划分;
(2.2)其他指标:准确率,召回率等,分别是什么意义?能够具备说服能力?
(3)如果模型的效果不好,要怎样改进?
(3.1)如果模型出现欠拟合(underfitting)的情况,应该怎么办?
(3.2)如果模型出现过拟合(overfitting)的情况,应该怎么办?
(4)细节问题:梯度下降法,正则化方法等等
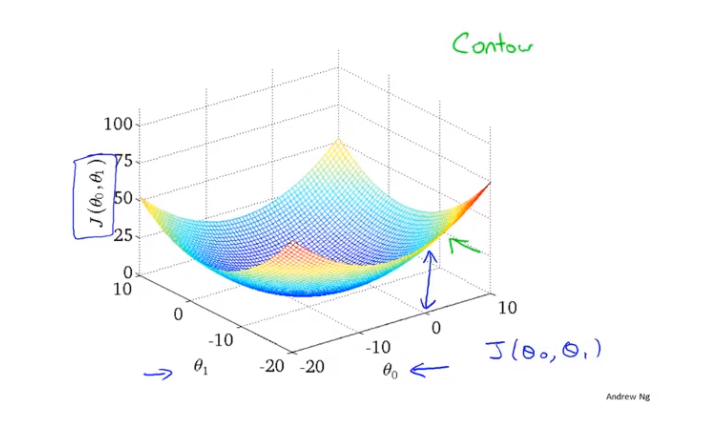
2 梯度下降:代价函数(cost function)和等高线图(contour line)
(1)采用两个参数来说明什么是等高线图
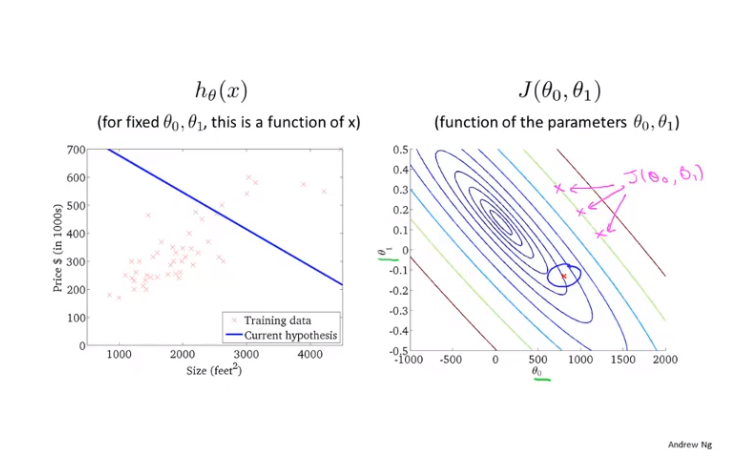
(2)梯度下降时,必须同步更新权重;另外需要设置学习率(learing rate, 图中的 α ),保证收敛速度的同时,使权重收敛到更为合适的位置。

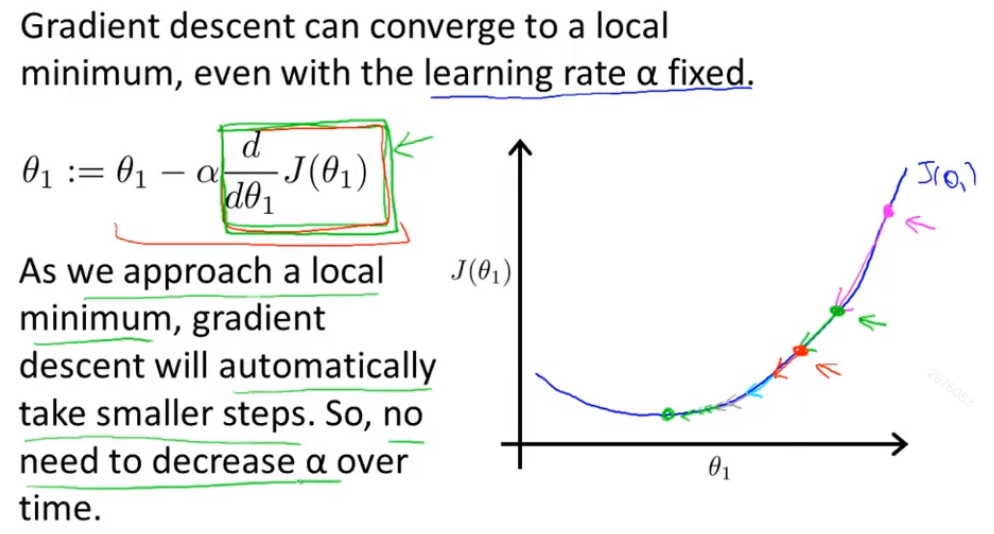
(3)学习率不合适会导致的问题:太小的话,收敛速度太慢;太大的话,可能导致无法收敛到最低点,甚至发散。

(4)梯度下降法会在逼近局部最优权重时,自动减少步幅,因为局部最优点的偏导数等于零。
3 过拟合与正则化
(1)什么是过拟合:当变量过多时,模型能够很好地拟合训练集,但是在应用到测试集时,拟合效果不好。

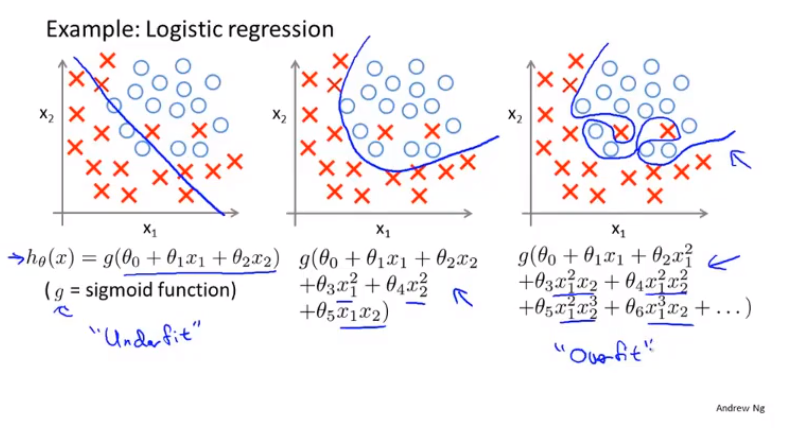
(2)解决过拟合的方法:
(2.1)通过人工进行特征选择,达到减少变量的目的;
(2.2)通过正则化方法,使权重参数具备更强的泛化(generalize)能力。

(3)正则化:通过往代价函数中引入新的项,达到避免过拟合的目的。正则化项通常可以使参数变小。
图中是一个不好的例子,这个例子展示了正则化参数太大会导致的不好的结果,即欠拟合。

4 如何评价模型
(1)训练集:测试集 = 7:3, 随机选择会更好; 采用misclassification error来评价模型的准确率
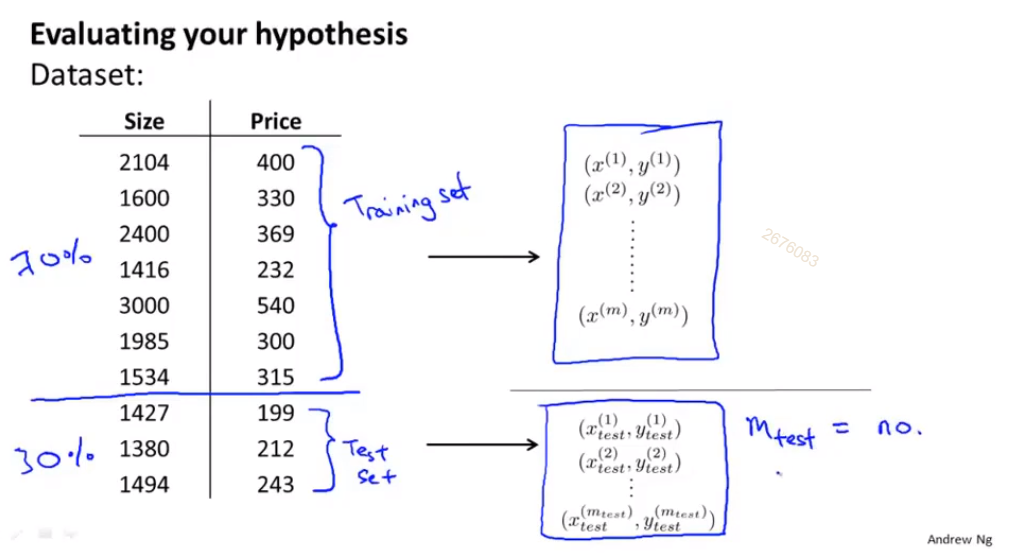

(2)训练集:验证集:测试集 = 7:2:1;采用验证集来选择一个合适的模型(确定模型的最高次数d = degree)。


(3)biase and variance
Error = Bias^2 + Variance+Noise
误差的原因:
1.Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力。
2.Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。反应预测的波动情况。
3.噪声。
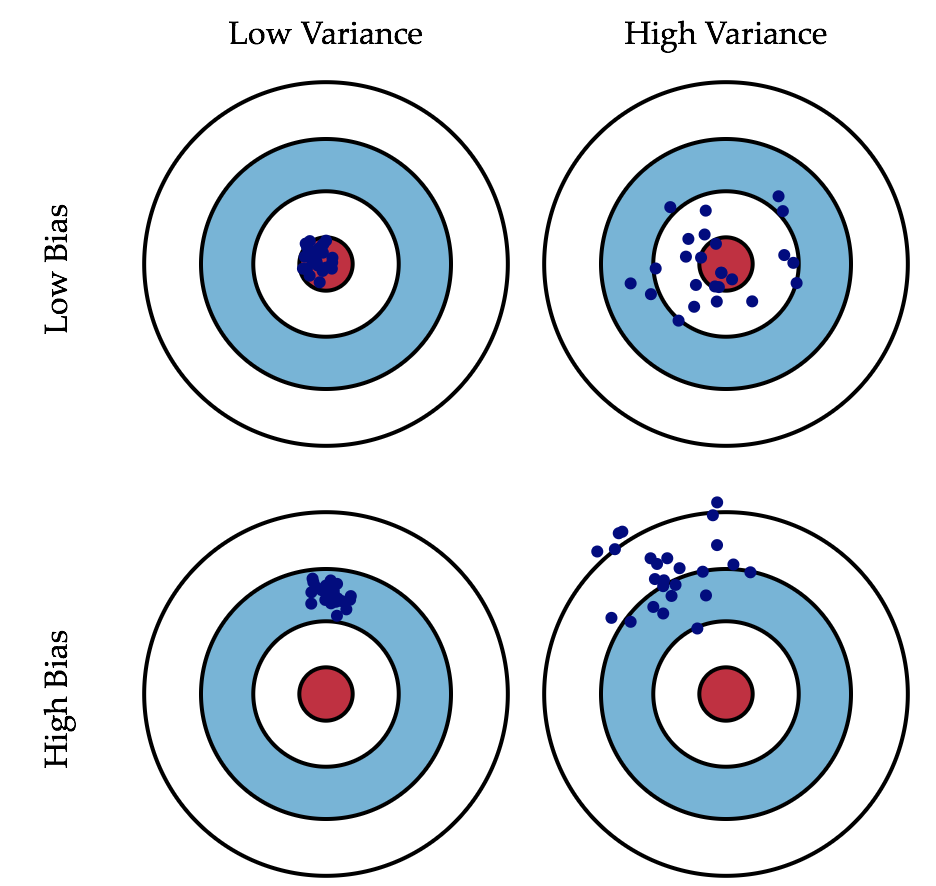
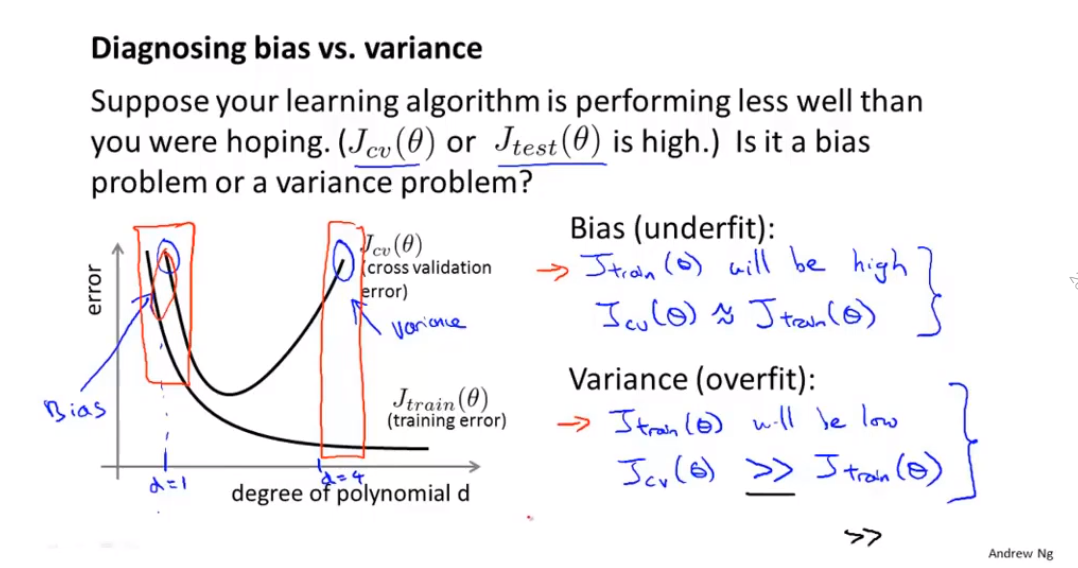
如何判断模型是欠拟合还是过拟合?
欠拟合:训练集和验证集的Bias都非常大;
过拟合:训练集的variance非常小,但是验证集的variance要远远大于训练集。
5 分类问题
(1)二分类问题中的离群点影响阈值,使得原本能够正确诊断的样本点现在不能正确诊断了
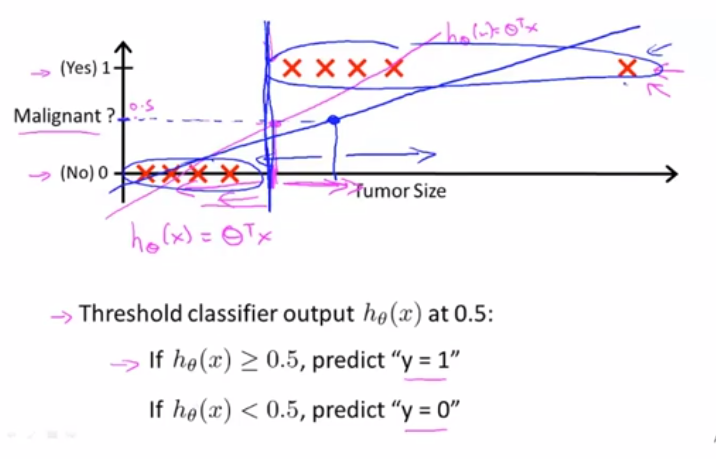
结论:将线性模型应用于分类模型并不好
为了解决这个问题,同时保证模型的输出 范围在【0, 1】之间,开发了logistic回归算法
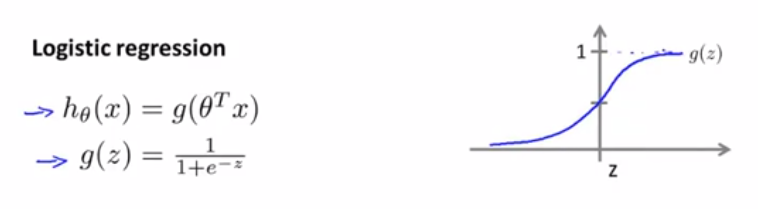
通过拟合参数求解决策边界。
(2)求解分类模型参数-决策边界:通过添加高次项,得到类似椭圆或者圆形的决策边界


 浙公网安备 33010602011771号
浙公网安备 33010602011771号