
57 CUDA 编程入门
0 引言
由于毕设用到了Marvin,采用的是CUDA框架作为加速器,正好借此学习一下CUDA编程的一些基本知识。
各个版本的cuda的下载链接如下。
https://developer.nvidia.com/cuda-toolkit-archive
ubuntu 下cuda与cudnn安装
https://blog.csdn.net/dihuanlai9093/article/details/79253963/
1 GPU编程
参照了该博客,写得确实是非常之好,从硬件到软件,再到代码实现,由浅入深,由理论到实践,水平确实是很高,楷模!
https://www.cnblogs.com/skyfsm/p/9673960.html
(1)异构计算:现在的计算机体系架构中,要完成CUDA并行计算,单靠GPU一人之力是不能完成计算任务的,必须借助CPU来协同配合完成一次高性能的并行计算任务。一般而言,并行部分在GPU上运行,串行部分在CPU运行,这就是异构计算。具体一点,异构计算的意思就是不同体系结构的处理器相互协作完成计算任务。CPU负责总体的程序流程,而GPU负责具体的计算任务,当GPU各个线程完成计算任务后,我们就将GPU那边计算得到的结果拷贝到CPU端,完成一次计算任务。
(2)cuda编程模型:线程模型阵列及线程号的计算
CUDA C通过kernels这样一种方式,实现对一般c的扩展。当cuda 中的kernel被调用时,它将被N个不同的threads调用N次,而非cpu编程中,每个非递归function只被调用一次。GPU CUDA的这种编程模型是基于其物理上的超多核心架构设计的,符合其并行运算的特点。CUDA的计算单元结构如下。
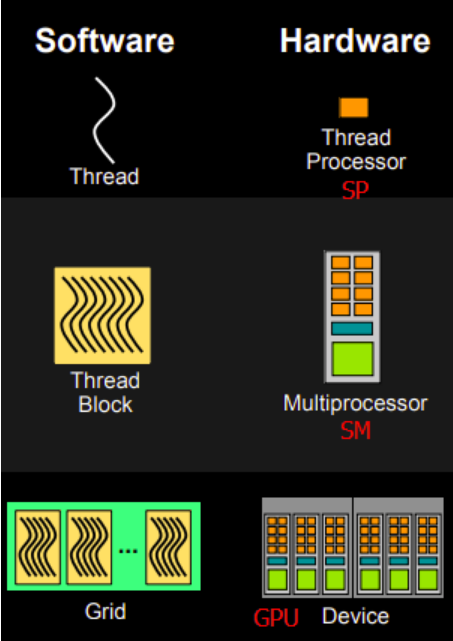

1、针对kernel的每次计算,定义一个grid,该grid包含若干个Block,每个Block又包含若干个threads,通过threadIdx访问这些Thread的索引号,即可调用这些单元。
2、threadIdx为三维向量,因此,每个block可以被定义为一维、二维或者三维向量,分别通过threadIdx.x, threadIdx.y, threadIdx.z来访问。 当前,每个block中可以包含至多1024个threads.
3、每个grid中的blocks可以组织成一维、二维或者三维的形式,每个grid中的blocks的数量决定于处理的数据的大小,或系统处理器的数量,访问grid中的block的方式是 blockIdx, 这是一个三维的变量,而block的维度通过blockDim变量来访问。
4、grid中blocks的数量以及block中threads的数量通过<<< blocks_number , threads_number>>>来定义,其中,blocks_number/threads_number的数据类型为int 或 dim3, 二维形式的可用dim3来存放,比如下面的例子。
// Kernel definition __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; } int main() { ... // Kernel invocation dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ... }
(3)我的GPU的硬件信息
使用GPU device 0: GeForce GTX 1050
设备全局内存总量: 4041MB
SM的数量:5
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
设备上一个线程块(Block)中可用的32位寄存器数量: 65536
每个EM的最大线程数:2048
每个EM的最大线程束数:64
设备上多处理器的数量: 5
2 linux + VSCode配置CUDA开发环境
(1)c_cpp_properties.json,其中的“includePath”相当于visual studio的 c/c++ -> 常规 -> 附加包含目录中添加的路径,可以避免代码中出现不影响执行的红色波浪线
{ "configurations": [ { "name": "Linux", "includePath": [ "${workspaceFolder}/**", "${workspaceFolder}", "/usr/include", "/usr/include/x86_64-linux-gnu/sys", "usr/local/cuda/include" ], "defines": [], "browse":{ "path":[ "/usr/include" ] }, "compilerPath": "/usr/local/cuda/bin", "cStandard": "c11", "cppStandard": "c++17", "intelliSenseMode": "gcc-x64" } ], "version": 4 }
(2)tasks.json,主要修改了“comman”,这里cuda编译用到的编译器是nvcc,同时还需要在nvcc编译指令中加入头文件地址和静态库lib文件地址。具体的编译任务中,根据错误提示添加对应的.so文件路径即可
{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks":[ // 可以有多个参数 { "label": "build", // 编译任务名 "type": "shell", // 编译任务的类型,通常为shell/process类型 "command": "nvcc", // 编译命令 "args":[ "-g", // 该参数使编译器在编译的时候产生调试信息 "${workspaceFolder}/${fileBasename}", // 被编译文件,通常为.cpp/.c/.cc文件等 "-o", // 生成指定名称的可执行文件 "${workspaceFolder}/${fileBasenameNoExtension}", // include path指令 "-I", "/usr/local/cuda/include", // lib 库文件地址 "-L", "/usr/local/cuda/lib64", "-l", "cudart", "-l", "cublas", "-l", "cudnn", "-l", "curand", "-D_MWAITXINTRIN_H_INCLUDED" ], "group": { "kind": "build", "isDefault": true } }, { "label": "cmakebuild", "type": "shell", "command": "cd build && cmake ../ && make", "args": [] } ] }
(3)launch.json,基本保持不变即可
{ // 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。 // 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "(gdb) Launch", // 强制:就一个名字而已,但是是必须要有的 "type": "cppdbg", "request": "launch", // 强制:launch/attach "program": "${workspaceFolder}/${fileBasenameNoExtension}", // 可执行文件的路径 "miDebuggerPath": "/usr/bin/gdb", // 调试器的位置 "preLaunchTask":"build", // 调试前编译任务名称 "args": [], // 调试参数 "stopAtEntry": false, "cwd": "${workspaceFolder}", // 当前工作目录 "environment": [], // 当前项目环境变量 "externalConsole": true, "MIMode": "gdb", // 调试器模式/类型 "setupCommands": [ { "description": "Enable pretty-printing for gdb", "text": "-enable-pretty-printing", "ignoreFailures": true } ] } ] }
3 cuda-gdb调试
https://blog.csdn.net/hxh1994/article/details/49621759
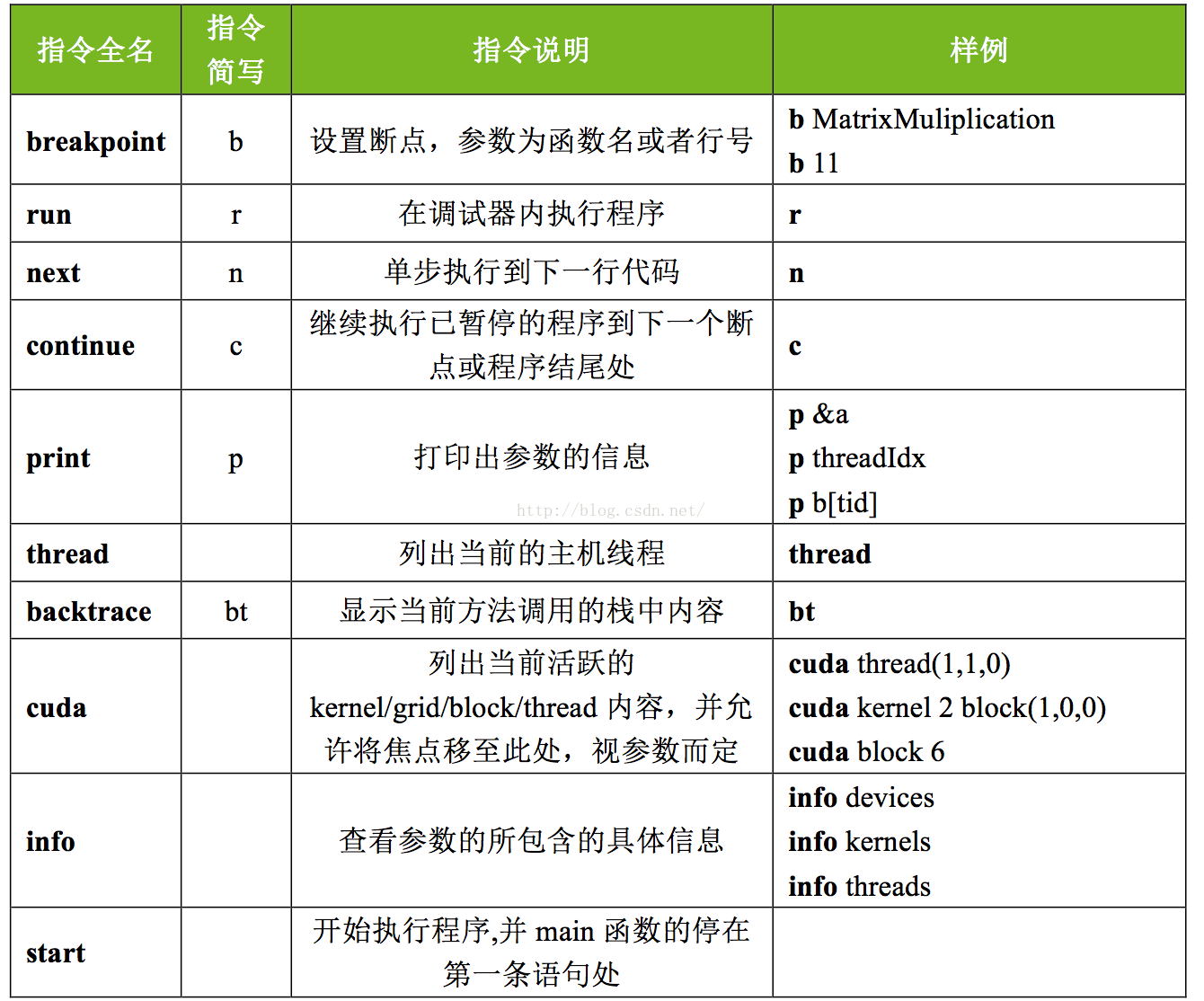
$ nvcc -g -G compute_matrix.cu -arch sm_50 -o compute_matrix
4 关键词及变量意义解析

