

52 点云配准领域论文
0 引言
点云配准有两大核心步骤:(1)建立从源点云到目标点云的点-点匹配关系(粗配准)。(2)找到两个点云间的最佳刚体转换关系,该RT能够最小化所有对应点之间的欧氏距离(精配准)。其中,(2)可用ICP算法或RanSAC算法实现。关键的问题在于如何求解source点-target点的匹配关系并得到相对准确的粗配准结果。
传统的配准算法有 ICP 和RanSAC,均可根据匹配点对拟合刚体转化矩阵。
泡泡点云讲解ICP的文章链接如下。
https://mp.weixin.qq.com/s/eNofskmSmwl8jH6BvNKfBg
根据PCL源码写的ICP的例子如下。
https://github.com/hyx007/paopao_ws/blob/master/icp_example/src/icp.h
1 3DFeatNet
(1)绪论:3DFeatNet 认为近年来在深度学习描述子的研究方面,尚无人能够提出一种既可以充当检测器(检测关键点),又可以充当描述子的网络,比如3DMatch没有关键点检测功能,只能随机选取部分点作为配准的benchmark点。 原因在于现存的深度学习方法需要及其大量标签数据用于监督学习训练集的构建,殊为不易。另一方面,3DFeatNet注意到GPS/INS标签数据集及其丰富,可用来喂点云深度学习框架。于是,3DFeatNet这一既可以检测关键点、又可以计算关键点描述子的框架就应运而生了。

(2)相关研究综述:
三维手工特征:PFH,FPFH等,这些手工设计的描述子应用到真实世界点云上时,由于其噪声和低密度等特点,效果不佳。
二维学习特征:

LIFT:Siamese CNN,训练集中的匹配点对来自于Structure from motion 流程方法 Yi, K.M., Trulls, E., Lepetit, V., Fua, P.: Lift: Learned invariant feature transform. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) European Conference on Computer Vision (ECCV). pp. 467–483. Springer International Publishing (2016). https://doi.org/10.1007/978-3-319-46466-4 28
TILDE:可靠应对不同光照条件下的点匹配问题,训练集中的匹配点对来自于二维SIFT方法 Verdie, Y., Yi, K.M., Fua, P., Lepetit, V.: TILDE: A Temporally Invariant Learned DEtector. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5279–5288 (2015). https://doi.org/10.1109/CVPR.2015.7299165 DELF:采用弱监督框架学习突出的局部二维描述子,该框架采用一个重要的识别任务中的注意力机制。该方法启发作者将注意力机制引入到自己的框架中。 Noh, H.Noh, H., Araujo, A., Sim, J., Weyand, T., Han, B.: Large-scale image retrieval with attentive deep local features. In: IEEE International Conference on Computer vision (ICCV). pp. 3476–3485 (2017). https://doi.org/10.1109/ICCV.2017.374
三维学习描述子:
3DMatch: 利用3D卷积网络从RGBD图中学习局部描述子。 Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., Funkhouser, T.: 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In: IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 199–208 (2017). https://doi.org/10.1109/CVPR.2017.29
PPFNet:利用原始点,合并点匹配特性以及全局上下文改善描述特性。
Deng, H., Birdal, T., Ilic, S.: Ppfnet: Global context aware local features for
robust 3d point matching. In: IEEE Conference on Computer Vision and Pattern
Recognition (CVPR) (2018)
CGF: 降维,手工设计描述子
khoury, M., Zhou, Q.Y., Koltun, V.: Learning compact geometric features.
In: International Conference on Computer Vision (ICCV). pp. 153–161 (2017).
https://doi.org/10.1109/ICCV.2017.26
LORAX:降维,手工设计描述子
Elbaz, G., Avraham, T., Fischer, A.: 3d point cloud registration for
localization using a deep neural network auto-encoder. In: IEEE Conference on
Computer Vision and Pattern Recognition (CVPR). pp. 2472–2481 (2017).
https://doi.org/10.1109/CVPR.2017.265
利用学习网络检测关键点,利用SHOT计算描述子
Salti, S., Tombari, F., Spezialetti, R., Stefano, L.D.: Learning a descriptor-specific
3d keypoint detector. In: IEEE International Conference on Computer Vision
(ICCV). pp. 2318–2326 (2015). https://doi.org/10.1109/ICCV.2015.267
(3)注意力机制应用
1 决定需要关注输入的哪部分
2 分配有限的信息处理资源给重要的部分
2 PointNet
(1)摘要:由于点云数据的特性,很多研究者通过将点云转换为其他更为有序的形式对点云进行处理(通常是网格形式或者多视图形式)。这些方法引入了大量不必要的数据,容易导致一些问题。PointNet可以直接将三维散点作为输入,化解了这一问题。PointNet可应用于目标识别、分割、场景语义解析等。
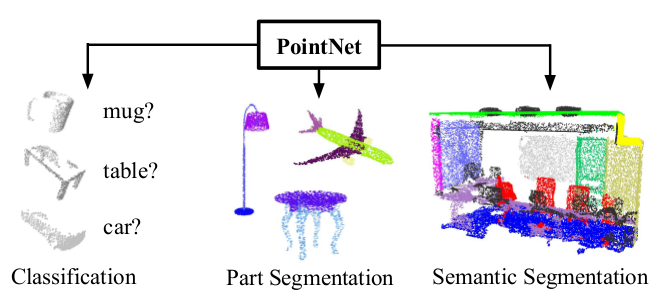
(2)绪论:经典的卷积结构需要高度组织化的数据形式,很多研究者将点云转化之后,引入了新的问题。为了应对这一问题,提出了PointNet,该框架可以直接处理散点。
(3)相关研究综述:
point cloud features: 手工设计的描述子为主,面向具体的任务。 其特征编码通常包含某种特定的统计特性,并且被设计为对某种变换具有不变形(旋转、尺度缩放不变性等)
在面向一个具体的任务时,无法找到最佳的特征组合。
deep learning on 3D data:
1 Volumetric CNNs: 将三维的卷积神经网络应用到体素形状(voxelized shapes)的先驱。由于数据稀疏性和3D卷积的计算成本,体积表示受其分辨率的限制。
D. Maturana and S. Scherer. Voxnet: A 3d convolutional
neural network for real-time object recognition. In IEEE/RSJ
International Conference on Intelligent Robots and Systems,September 2015.
C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas.
Volumetric and multi-view cnns for object classification on
3d data. In Proc. Computer Vision and Pattern Recognition(CVPR), IEEE, 2016.
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and
J. Xiao. 3d shapenets: A deep representation for volumetric
shapes. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition, pages 1912–1920, 2015.
2 multiviewcnns:尝试想三维点云渲染成二维图片,并应用于二维图像卷积。该法在形状识别和形状检索等任务中取得了主导地位,但是在推广到场景理解等任务或者点识别或形状补偿时表现平平。
C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas.
Volumetric and multi-view cnns for object classification on
3d data. In Proc. Computer Vision and Pattern Recognition
(CVPR), IEEE, 2016.
H. Su, S. Maji, E. Kalogerakis, and E. G. Learned-Miller.
Multi-view convolutional neural networks for 3d shape
recognition. In Proc. ICCV, to appear, 2015.
3 Feature-based DNNs:受制于提取的特征的表现力。
Y. Fang, J. Xie, G. Dai, M. Wang, F. Zhu, T. Xu, and
E. Wong. 3d deep shape descriptor. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 2319–2328, 2015
K. Guo, D. Zou, and X. Chen. 3d mesh labeling via
deep convolutional neural networks. ACM Transactions on
Graphics (TOG), 35(1):3, 2015.
deep learning on unordered sets:点云可视为一堆无序的向量,大部分的网络则处理有序(sequence)点云、图像等
读-处理-写网络,引入注意力机制,可将无序的文本作为网络输入。该网络具有对数字排序的能力。
O. Vinyals, S. Bengio, and M. Kudlur.
Order matters: Sequence to sequence for sets.
arXiv preprintarXiv:1511.06391, 2015.
(4)结论:该网络提供了一种统一的方法,用于处理目标识别、部件分割与语义分割任务。
目标识别:输入点云是直接从形状点云中采样得来的,或者是从场景点云中分割得到的。将该点云输入网络,网络输出所有k个候选类的k个分数。
语义分割:输入是单个的目标物体或者场景中的部分点云,网络将输出n×m个分数,n个分数对应n个点,m对应m个语义子类别。
3 PartNet:用于细粒度和分层的部件级3D对象理解的大型基准测试

上图的效果让人想到region growing算法,如果实际测试的精度可以达到这个级别,则可以考虑用该框架提取part,建立基于part-oart的配准方法。目前,该框架的代码和数据集还未公开,要再等等看。
4 LORAX: 实现对手工设计的描述子的降维表示
(1)摘要:该算法从点云中选取 super points,然后用一个低维的描述子对点云进行描述,用于粗配准。super points的提取方法是用重叠的球体覆盖点云,然后将低质量的或者非凸的区域滤出掉。该描述子采用最先进的无监督机器学习方法,利用了自编码深度神经网络技术。该方法可替代广泛采用的手工提取关键点用于配准的算法。使用super points而非key points可以更好滴利用几何数据求解正确的转换关系。用深度神经网络编码局部3维几何结构比用传统的描述子可获得更好的结果。
(2)算法流程
RSCS算法提取super points -》 为每一个super point选择归一化坐标系 -》将super point data投影到二维深度图像 -》 凸点检测以及super points过滤
-》深度神经网络自编码器降维 -》 找到关联描述子候选匹配关系 -》 局部搜索求解粗匹配关系 -》 ICP精配准
5 非刚体形状匹配描述子深度学习框架
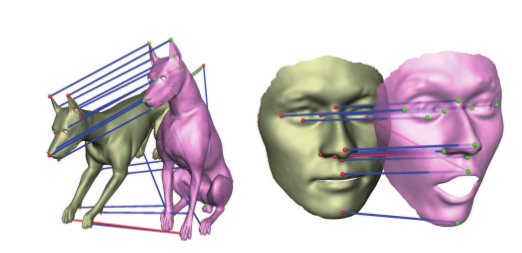
(1)摘要: 文章提出了一种推导具有区分性的局部三维曲面形状描述子的新型深度学习框架。该框架将关键点邻域点云参数化为多尺度二维网格图像。这种几何图像可以保留足够的几何信息,且允许使用标准CNN来处理。 另外,文章还使用了一种三联体网络进行深度量学习,该网络以三联体作为输入,并设计了一种新的三联体损失函数(triplet loss),该函数可将关键点匹配点对之间的距离最小化。测试中,向网络输入感兴趣点的几何图像,网络将输出具有区分行的局部描述子。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!