


在上一篇文章中,介绍了卷积神经网络(CNN),CNN在图像识别中有着强大、广泛的应用,但有一些场景用CNN却无法得到有效地解决,例如:
- 语音识别,要按顺序处理每一帧的声音信息,有些结果需要根据上下文进行识别;
- 自然语言处理,要依次读取各个单词,识别某段文字的语义;
这些场景都有一个特点,就是都与时间序列有关,且输入的序列数据长度是不固定的。
例如对一个演讲进行语音识别,那演讲者每讲一句话的时间几乎都不太相同,而识别演讲者的讲话内容还必须要按照讲话的顺序进行识别。这就需要该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息。这个模型就是今天的主角 “循环神经网络”。
循环神经网络(Recurrent Neural Networks,RNN)是一种专门处理序列(sequences)的神经网络,它们通常用于自然语言处理(NLP)任务。
时序上下文很重要
我们看一个需要结合上下文去理解的场景:
现在有两句话:
- 第一句话:I like eating apple!(我喜欢吃苹果!)
- 第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
现在的任务是要给apple打Label,我们都知道第一个apple是一种水果,第二个apple是苹果公司。只看单词的特征我们是区分不了的,必须跟上下文捆绑。
RNN 的输入和输出特征
RNN让我们有可变长度的序列作为输入和输出。
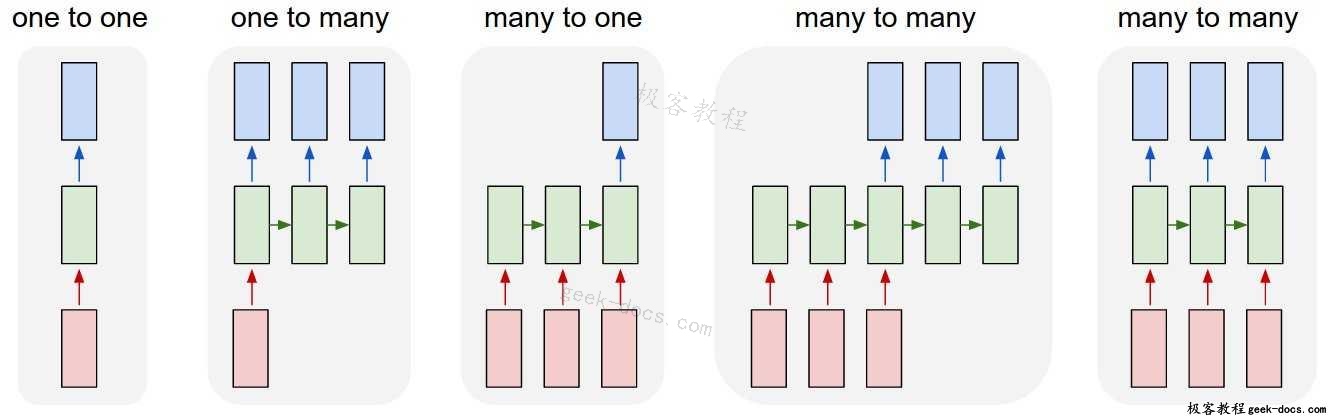
输入为红色,RNN本身为绿色,输出为蓝色。
下面是一些关于RNN的例子:
- 机器翻译(例如谷歌翻译)是通过“多对多”的RNN来完成的。原始文本序列被输入一个RNN,然后RNN生成翻译文本作为输出。
- 情绪分析(例如,这是一个积极的还是消极的评论?)通常是用“多对一”的RNN来完成的。要分析的文本被输入一个RNN,然后RNN生成一个输出分类(例如,这是一个积极的评论)。
RNN 如何保留上下文?
理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNN:

从上面的两个简化图,可以看出 RNN 相比经典的神经网络结构多了一个循环圈,这个圈就代表着神经元的输出在下一个时间戳还会返回来作为输入的一部分,这些循环让 RNN 看起来似乎很神秘,然而,换个角度想想,也不比一个经典的神经网络难于理解。RNN 可以被看做是对同一神经网络的多次赋值,第 i 层神经元在 t 时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(t-1)时刻的输出,如果我们按时间点将 RNN 展开,将得到以下的结构图:

在不同的时间点,RNN 的输入都与将之前的时间状态有关,\(t_n\) 时刻网络的输出结果是该时刻的输入和所有历史共同作用的结果,这就达到了对时间序列建模的目的。
RNN 和 Transformer 的区别
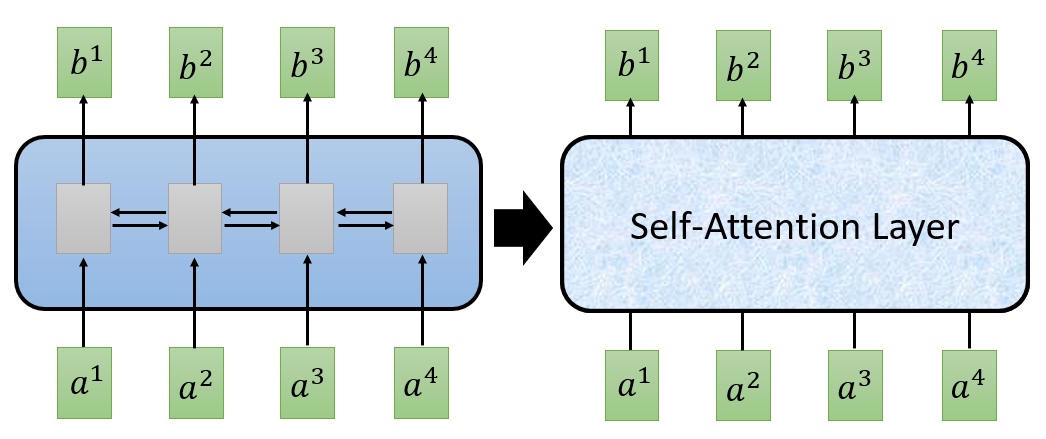
RNN和Transformer都可以用于机器翻译、文本摘要等任务,只是内部结构从无法并行的RNN,在Attention Is All You Need
https://arxiv.org/pdf/1706.03762.pdf 这篇论文之后,变成了可以并行的self-attension layer。
哪RNN还有啥应用场景么?
-
RNN是递归的,即它按照单词的顺序处理输入序列,并维持一个隐状态向量来捕捉上下文信息。这样的设计使得RNN能够很好地处理短期依赖,但也导致了梯度消失/爆炸、训练速度慢、难以并行化等问题。
-
Transformer是非递归的,即它一次性地处理整个输入序列,并利用自注意力机制来计算单词之间的相似度分数。这样的设计使得Transformer能够很好地处理长期依赖,而且训练速度快,易于并行化。Transformer还引入了位置嵌入来替代递归,以及多头注意力来增强表达能力。
-
RNN和Transformer都可以用于机器翻译、文本摘要等任务,但Transformer通常表现更好,尤其是在大规模数据集上。Transformer也有一些缺点,比如需要更多的内存、更难解释等。
因此,一般来说,如果您需要处理长序列或者需要高效地训练模型,那么Transformer可能更适合您。如果您需要处理短序列或者需要更简单、更可解释的模型,那么RNN可能更适合您。

