
在当今的数字化时代,网络连接的重要性不言而喻。路由转发作为网络通信的核心环节,其配置的正确与否直接影响着网络的稳定性和效率。
本文使用下图这个简化网络来演示:
- 如何简洁高效地配置路由转发;
- 在遇到问题时,如何利用常用工具进行分析和定位。:
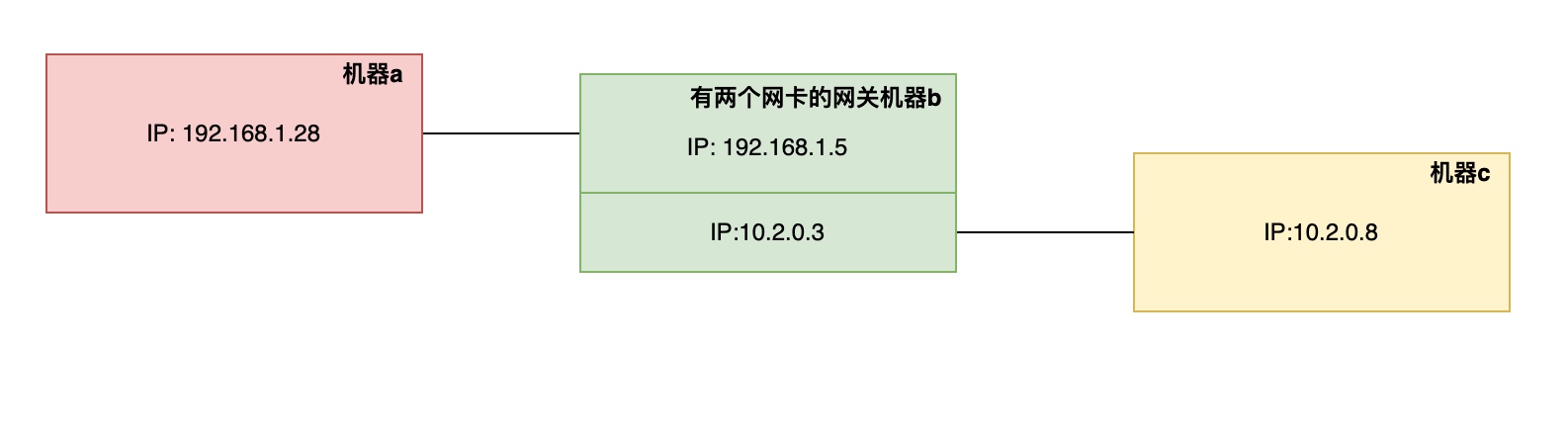
图说明:
- 一台具有两个网络接口的机器b(
192.168.1.5和10.2.0.3),作为两个网络之间的路由器/网关。 - 机器a(
192.168.1.28) 和 机器c(10.2.0.8)在各自网络。
配置路由转发
为了确保从机器a(192.168.1.28) 发出的 ping 请求能够到达机器c(10.2.0.8) 并且能收到回应,你需要正确配置网络和路由。
以下是配置步骤:
1、启用 IP 转发
在扮演路由器角色的机器b上启用 IP 转发。
在 Linux 上,你可以这样做:
echo 1 > /proc/sys/net/ipv4/ip_forward
或者永久启用,编辑 /etc/sysctl.conf 文件,添加或取消注释以下行:
net.ipv4.ip_forward = 1
然后运行 sysctl -p 来应用更改。
IP 转发的作用
net.ipv4.ip_forward = 1 这个设置是在 Linux 系统中启用 IP 转发的配置。启用 IP 转发后,该系统可以将接收到的网络包转发到另一个网络接口,这是路由器和多宿主主机进行数据包转发的基础功能。
路由器功能:当启用 IP 转发时,该机器可以充当路由器,允许不同网络之间的通信。例如,一个接口连接到 192.168.1.0/24 网络,另一个接口连接到 10.2.0.0/24 网络,该机器可以转发这两个网络之间的数据包。
多宿主主机:在一个多宿主(多个网络接口)的机器上,启用 IP 转发可以使得这台机器在其接口之间转发数据包,从而连接不同的网络。
在有两个或多个网络接口(包括虚拟网卡)的机器上,启用 IP 转发最有意义,因为这允许机器在其不同的网络接口之间转发数据包。
2、路由器上的防火墙规则
确保你的路由器(双网卡机器)上的防火墙设置允许从一个接口到另一个接口的流量。这可能涉及到添加 iptables 规则,允许转发。
我们这里假设前面路由器机器b有两个网卡:
gnb_tun对应192.168.1.0/24网络enp1s0对应10.2.0.0/24网络
下面这两个命令配置了一个简单的NAT和数据包转发规则:
- 允许从特定接口(如
gnb_tun)来的数据包经过主机并通过另一个接口(如enp1s0)发送出去, - 同时修改这些数据包的源地址,使其看起来像是从主机本身发出的。
我们这里用nftables来演示,nftables 是设计来替代 iptables 的新一代网络流量管理框架,在 Linux 3.13 内核中引入(2014年)。以ubuntu 22.4 为例,默认使用的是 nftables 作为其主要的网络包过滤框架,如果你在 Ubuntu 22.04 上执行 iptables 命令,这些命令实际上是通过 nftables 的后端执行的(通过使用 iptables-nft 包实现的)。
配置防火墙规则:
# 发出去的包动态地改变源地址
sudo nft add table ip nat
sudo nft add chain ip nat postrouting { type nat hook postrouting priority srcnat; }
sudo nft add rule ip nat postrouting oifname "enp1s0" masquerade
# 转发数据包
sudo nft add table ip filter
sudo nft add chain ip filter forward { type filter hook forward priority 0; }
sudo nft add rule ip filter forward iifname "gnb_tun" oifname "enp1s0" accept
参数解释:
创建 NAT 表和规则
nft add table ip nat
nft:nftables命令行工具。add: 添加一个新元素(如表、链、规则)。table: 表示要添加的是一个表。ip: 指定表的家族,这里是ip,用于IPv4。对于IPv6,使用ip6。nat: 表的名称,这里称为nat。
nft add chain ip nat postrouting { type nat hook postrouting priority srcnat; }
add chain: 添加一条新链。ip nat: 指定链所在的表和家族。postrouting: 链的名称。{ type nat hook postrouting priority srcnat; }: 定义链的类型和钩子。type nat: 指定链的类型为 NAT。hook postrouting: 指定链挂载的钩子位置,这里是在POSTROUTING,即在路由决策后处理出站数据包。priority srcnat: 设置链的优先级,这里是用于源 NAT。
nft add rule ip nat postrouting oifname "enp1s0" masquerade
add rule: 添加一条新规则。ip nat postrouting: 指定规则所属的表、家族和链。oifname "enp1s0": 规则的匹配条件。这里表示匹配出站接口名称为enp1s0的数据包。masquerade: 执行的操作,即MASQUERADE。这会将数据包的源地址改为出站接口的地址。这用于动态地改变数据包的源地址,使得从内部网络(例如私有网络)出去的数据包看起来都是从防火墙或者网关的公共地址发出的。。
创建 Filter 表和规则
nft add table ip filter
- 同上,这次创建的是名为 filter 的表,用于包过滤。
nft add chain ip filter forward { type filter hook forward priority 0; }
add chain: 添加链。ip filter: 指定表和家族。forward: 链的名称。{ type filter hook forward priority 0; }: 定义链的类型和钩子。type filter: 表明这是一个过滤链。hook forward: 指定在FORWARD钩子上,即处理转发的数据包。priority 0: 设置链的优先级。
nft add rule ip filter forward iifname "gnb_tun" oifname "enp1s0" accept
add rule: 添加规则。ip filter forward: 指定规则所属的表、家族和链。iifname "gnb_tun": 匹配入站接口名称为gnb_tun的数据包。oifname "enp1s0": 同时匹配出站接口名称为enp1s0。accept: 规则的动作,这里是接受匹配的数据包。
在 nftables 中,规则是按照定义的顺序进行处理的,所以确保您的规则顺序符合您的网络策略需求。
如何确认已经启用上述规则?
要检查是否已经设置了上述的 nftables 规则,您可以使用 nft 命令来列出当前的规则集。这样可以查看所有的表、链和规则,包括您刚刚添加的那些。以下是如何进行检查的步骤:
列出所有规则集:
sudo nft list ruleset
这个命令会显示当前系统上所有的 nftables 配置。它包括所有的表、链和规则。由于输出可能很长,您可能需要仔细查看或使用文本编辑器进行搜索。
查看指定的表
如果您只想查看特定的表,比如 nat 表或 filter 表,可以使用以下命令:
sudo nft list table ip nat
# 或者
sudo nft list table ip filter
查看特定表中的特定链
如果您想要更加具体,只查看某个特定表中的特定链,例如 nat 表中的 postrouting 链或 filter 表中的 forward 链,可以使用如下命令:
sudo nft list chain ip nat postrouting
# 或
sudo nft list chain ip filter forward
这些命令将仅显示您指定的链及其包含的规则。
保存当前的规则集
在默认情况下,通过 nft 命令直接添加到 nftables 的规则在服务器重启后不会自动保留。这意味着,如果您重启服务器,您之前添加的规则将丢失,除非您采取了措施来持久化这些规则。
导出规则集
sudo nft list ruleset > /etc/nftables.conf
这个命令会将当前的 nftables 规则集导出并保存到 /etc/nftables.conf 文件中。这是大多数 Linux 发行版的标准位置,包括 Ubuntu。
确保在启动时加载规则
设置自动加载:
- 大多数现代 Linux 系统(使用 systemd)都会在启动时自动加载
/etc/nftables.conf中的规则,因为 nftables 服务默认会查找这个文件。 - 如果您的系统没有自动执行此操作,您可能需要启用 nftables 服务:
sudo systemctl enable nftables
检查配置文件
-
确保
/etc/nftables.conf文件包含了您想要的规则。 -
在重启之前,您可以手动运行如下命令,来测试配置文件是否正常工作。
sudo nft -f /etc/nftables.conf
nftables 的主要概念和工作流程
nftables 的主要概念是围绕着“表(Tables)”、“链(Chains)”和“规则(Rules)”。这三个组件构成了 nftables 配置的核心。除此之外,还有一些其他的概念,如“集合(Sets)”和“元素(Elements)”,但表、链和规则是最基础和最重要的。
下面是这些概念之间的关系和它们的作用:
表(Tables)
作用:表是用于存储规则的容器。它们提供了一个组织结构,用于分类规则。
类型:表可以是特定类型的,如 filter、nat 等,这决定了表中的链和规则可以执行的操作类型。
链(Chains)
作用:链是规则的序列,它们定义了如何处理网络流量。链可以是内建的(如 INPUT、FORWARD、OUTPUT 等),也可以是用户定义的。
钩子(Hooks):链与特定的网络流量处理点(钩子)相关联,例如 prerouting、input、output 和 postrouting。这决定了链在网络堆栈的哪个点上处理数据包。
规则(Rules)
作用:规则定义了对匹配特定条件的数据包执行的操作。每条规则都包含一个或多个匹配条件和一个动作(如接受、丢弃、修改等)。
顺序:规则在链中按定义的顺序执行,直到找到匹配的规则。
集合(Sets)和元素(Elements)
集合:集合是一组预定义的值,可以在规则中使用。例如,您可以创建一个包含特定 IP 地址的集合,并在规则中引用这个集合来匹配这些地址。
元素:元素是集合中的具体值,如特定的 IP 地址、端口号等。
它们之间的关系
层级关系:表位于最顶层,存储着一系列的链。链则定义了特定条件下应当如何处理数据包,通过一系列的规则来实现。
工作流程:当网络流量到达时,它会根据其类型(如 IPv4 或 IPv6)和目的(如过滤或 NAT)进入相应的表。然后,根据流量的具体特性(如来源、目的地等),在表中的适当链上进行处理。最终,链中的规则会根据匹配条件决定对数据包的操作。
3、配置路由
我们演示的要能ping通,所以需要配置两条路由,一条去的路由(红线),一条回来的路由(蓝线)。
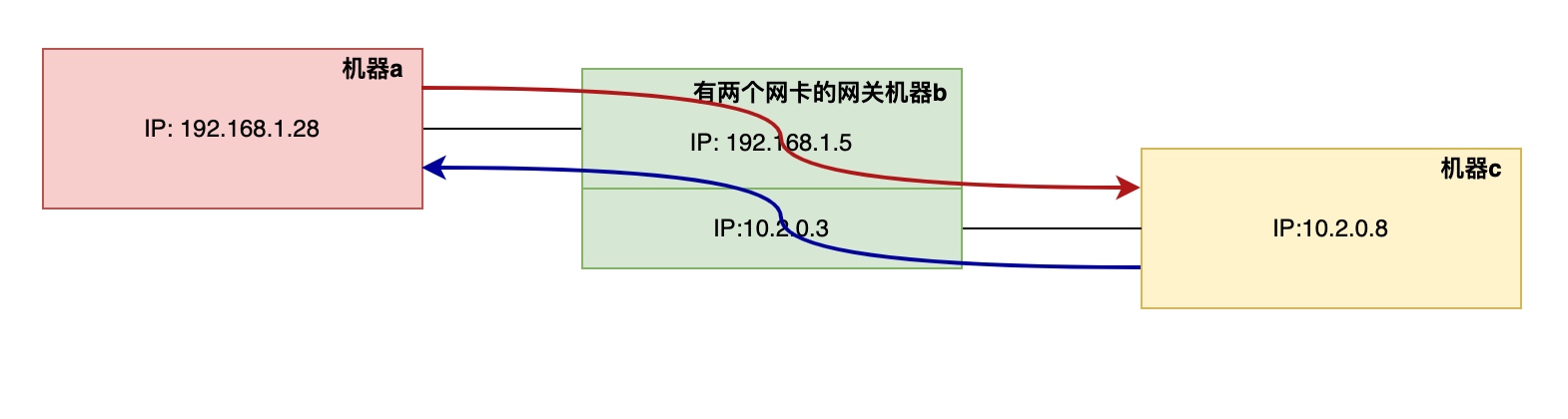
去的路由
在 192.168.1.28 上,你需要确保有一条路由告诉它如何到达 10.2.0.0/24 网络。这可以通过以下命令完成:
ip route add 10.2.0.0/24 via 192.168.1.5
这告诉 192.168.1.28,要到 10.2.0.0/24 网络,需要通过 192.168.1.5。
回来的路由
在 10.2.0.8 上,确保它知道如何将数据包发送回 192.168.1.0/24 网络。这可能已经由默认路由覆盖,但如果没有,你需要添加一个类似的路由:
ip route add 192.168.1.0/24 via 10.2.0.3
这告诉 10.2.0.8 通过 10.2.0.3(你的路由器的另一个接口)来达到 192.168.1.0/24 网络。
ip route add 参数说明
ip route add 命令的一般形式及其参数的含义:
ip route add [destination] via [gateway] dev [device] [additional-options]
-
[destination]: 这是目的网络的地址。它可以是一个特定的 IP 地址,也可以是一个 IP 地址范围,通常以子网掩码(如 /24)表示。例如,
192.168.1.0/24或10.0.0.0/8。 -
via [gateway]: (可选)这个参数指定了到达目的地的网关或下一跳地址。网关应该是本地连接的网络上的一个地址,通常是路由器的接口地址。
-
dev [device]: (可选)这个参数指定了用于发送到该目的地的数据包的网络接口(如
eth0、eth1、wlan0等)。在多网卡系统中,这可以用来指定特定的网络接口。 -
[additional-options]: 这里可以包括额外的选项,如
src [address](指定发送数据包时使用的源 IP 地址),metric [value](为路由指定一个度量值,用于在有多条路由可用时选择路由),和其他高级路由选项。
一个典型的命令可能如下所示:
ip route add 192.168.2.0/24 via 192.168.1.1 dev eth0
这个命令的含义是:添加一条路由,指示系统发送到 192.168.2.0/24 网络的所有数据包都应该通过 192.168.1.1 这个网关,且使用 eth0 网络接口。
常用分析工具
- 使用
ping命令测试网络连通性。 - 使用
traceroute(在 Windows 上是tracert)命令追踪数据包的路径。
ping命令
ping 命令是一个常用的网络工具,用于测试到另一台计算机的网络连接。
以下是一些跨平台常见的参数:
-
-4:强制使用 IPv4。 -
-6:强制使用 IPv6。 -
-t(仅限 Windows):持续 ping 目标主机,直到手动停止(使用Ctrl+C)。 -
-c[次数] (通常用于 Linux/Mac):发送指定数量的echo请求包。例如,ping -c 4[目标地址]。 -
-w[秒] (Windows) /-W[秒] (Linux/Mac):设置超时时间,单位为秒。如果响应时间超过此值,ping 请求将失败。 -
-i[秒]:设置 ping 请求之间的时间间隔(以秒为单位)。 -
-s[大小]:指定要发送的数据包的大小(以字节为单位)。 -
-l[大小] (仅限 Windows):设置发送缓冲区大小。 -
-a:将地址解析为主机名。 -
-n[次数]:发送指定数量的 echo 请求包。 -
-r[次数] (仅限 Windows):记录传递数据包的路由。 -
-v(Linux/Mac):详细模式,显示每个回应数据包的详细信息。
不同的操作系统和不同版本的 ping 命令可能支持不同的参数集合。因此,最好查看您的特定系统上的 ping 命令的帮助文档或手册页(通常可以通过在命令行中输入 ping -h 或 man ping 来访问)
traceroute/tracert
traceroute(在Windows中通常称为tracert)是一个网络诊断工具,用于显示数据包在到达指定目的地时所经过的路径。这个命令的常用参数因操作系统的不同而略有差异,但以下是一些常见的参数:
对于 Unix/Linux 系统 (traceroute):
-n: 不解析地址到主机名。这会显示IP地址而不是机器名。-m[max_ttl]: 设置最大生存时间(TTL)值,即最大跳数。-q[nqueries]: 设置每跳发送的查询数。-w[waittime]: 设置每次查询的等待时间。-I: 使用ICMP回声请求代替UDP数据包。-T: 使用TCP SYN数据包而不是UDP或ICMP。-A: 进行AS号(自治系统号)查询。-f[first_ttl]: 指定起始的TTL值。
对于 Windows 系统 (tracert):
-d: 不解析地址到主机名。-h[max_hops]: 定义最大跳数。-w[timeout]: 等待每个回应的毫秒数。-j[host-list]: 使用源站选路(源路由)的主机列表。-R: 使用ICMP回声请求跟踪回路。-S[srcaddr]: 使用指定的源地址。-4: 强制使用IPv4。-6: 强制使用IPv6。
PathPing/MTR
结合了 ping 和 tracert/traceroute 的工具有PathPing(Windows) 和 MTR(My Traceroute,在Unix/Linux上)
PathPing(Windows)
PathPing:这个工具结合了 ping 和 tracert 的功能,它会发送多个数据包到每个跳点,并统计丢包率和延迟。这对于识别链路中的问题节点非常有用。
如何使用 PathPing
打开命令提示符:
在Windows中,点击“开始”菜单,然后在搜索框中输入“cmd”或“命令提示符”,然后选择“命令提示符”程序。
运行 PathPing:
在命令提示符中,输入以下命令:
pathping [目的地地址]
其中 [目的地地址] 可以是一个IP地址或一个域名。例如:
pathping www.google.com
或
pathping 192.168.1.1
等待结果:
PathPing 首先会列出到达目的地的路径,这部分类似于 tracert 的输出。
然后,它会进行一系列测试,通常持续几分钟,以收集和计算每个节点的丢包率和响应时间。这一部分是 PathPing 独有的。
分析输出:
输出结果会显示经过的每个节点(跳点)及其相应的统计数据。
查看每个节点的丢包率和延迟时间,可以帮助你识别网络中可能出现问题的节点。
注意事项
-
PathPing的完整测试可能需要几分钟到十几分钟不等,具体取决于路由的复杂性和网络状况。 -
输出结果的最后部分,即统计数据,尤其重要。它提供了关于网络性能和可靠性的详细信息。
-
在分析结果时,高丢包率或异常高的延迟可能表明该节点存在问题。
通过使用 PathPing,你可以更全面地了解网络性能问题,并识别出问题发生的具体位置。
MTR(My Traceroute,在Unix/Linux上)
MTR:类似于PathPing,MTR结合了 traceroute 和 ping 的功能,能持续监测网络链路状况,可以显示到达目标主机的路径以及每一跳的延迟。
要使用 mtr,您首先需要确保它已经安装在您的系统上。在大多数基于 Debian 的系统(如 Ubuntu)中,您可以使用以下命令安装它:
sudo apt-get update
sudo apt-get install mtr
安装完成后,您可以通过以下命令使用 mtr:
mtr [目标主机名或IP地址]
例如:
mtr google.com
这将显示从您的计算机到 google.com 的路由,包括每一跳的统计信息。
mtr 提供了丰富的输出,显示每个中继站点的地址、数据包丢失率、响应时间等信息。这对于诊断网络问题非常有用。
还有一些选项可以用来定制 mtr 的输出,例如:
-n:不进行 DNS 反向解析,直接显示 IP 地址。-r:生成报告模式。-c:设置发送的 ping 包数量。
例如,要发送 10 个 ping 包并生成报告,您可以使用:
mtr -r -c 10 google.com
mtr 是一个非常强大的网络诊断工具,适用于排查复杂的网络问题。
tcpdump
要捕获特定接口的数据包,可以使用:
sudo tcpdump -i [网卡名]
查看指定网卡上来自特定来源 IP 的数据包
sudo tcpdump -i [网卡名] src [来源IP]
# 例如,如果你想要监听 eth0 网卡上来自 IP 地址 192.168.1.100 的数据包,你可以使用以下命令:
sudo tcpdump -i eth0 src 192.168.1.100
#如果你只对特定类型的协议(如 TCP 或 UDP)感兴趣,可以进一步指定。例如,只捕获 TCP 数据包的命令是:
sudo tcpdump -i eth0 src 192.168.1.100 and tcp
# 只查看目标端口为 80 的数据包:
sudo tcpdump -i eth0 src 192.168.1.100 and port 80
# 保存到文件: 使用 -w 选项,你可以将捕获的数据包保存到一个文件中,稍后进行分析:
sudo tcpdump -i eth0 src 192.168.1.100 -w capture_file.pcap
总结
通过本文的介绍,您现在应该对路由转发的配置流程有了清晰的认识,并掌握了一系列分析和定位网络问题的工具。无论是基础的 ping 命令,还是更高级的 tcpdump 分析,这些工具都是每位网络管理员必备的武器。记住,网络管理是一个持续学习和适应的过程。随着您技能的提升和经验的积累,您将更加自信地面对各种网络挑战。祝您在网络管理的道路上一帆风顺!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号