
在HuggingFace上,我们时不时就会看到GGUF后缀的模型文件,它是如何来的?有啥特点?
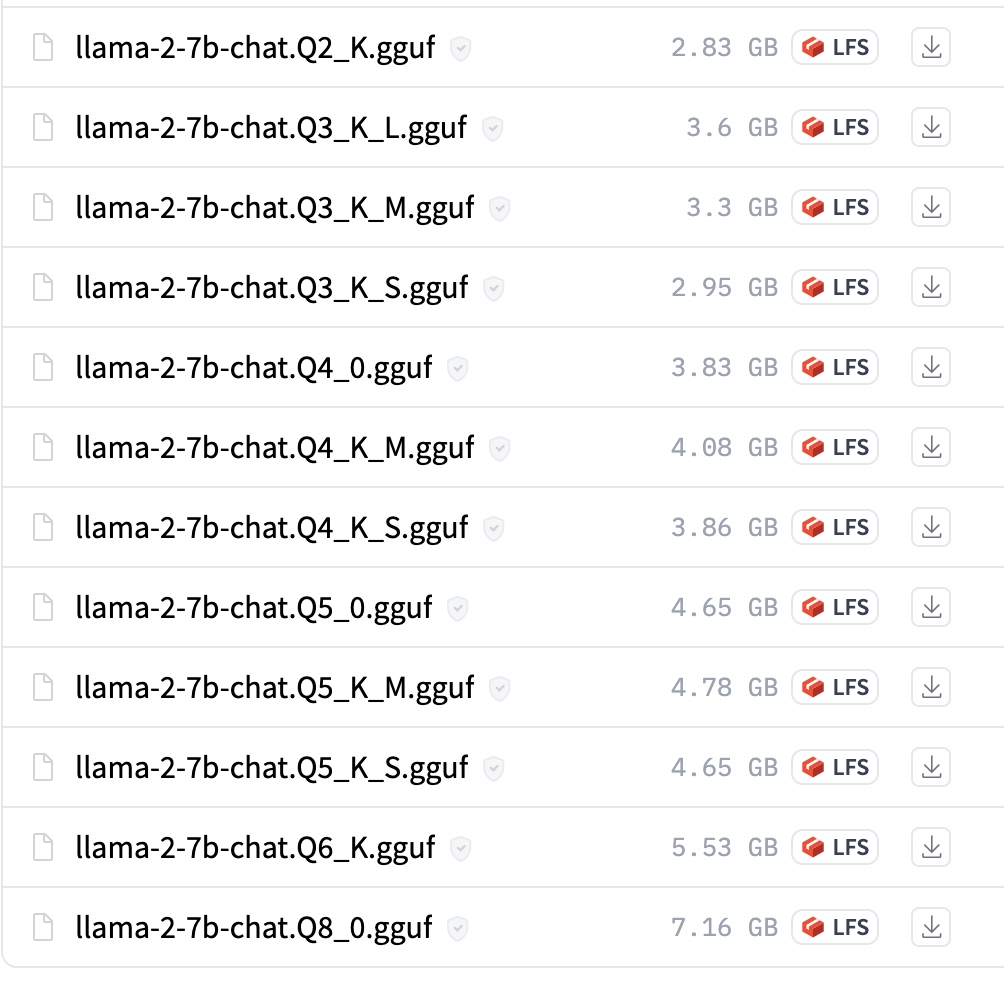
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF
GGUF 由来
Georgi Gerganov(https://github.com/ggerganov)是著名开源项目llama.cpp((https://github.com/ggerganov/llama.cpp))的创始人,它最大的优势是可以在CPU上快速地进行推理而不需要 GPU。
创建llama.cpp后作者将该项目中模型量化的部分提取出来做成了一个用于机器学习张量库:GGML(https://github.com/ggerganov/ggml),项目名称中的GG其实就是作者的名字首字母。它与其他张量库(tensor library)最大的不同,就是支持量化模型在CPU中执行推断。从而实现了低资源部署LLM。
而它生成的文件格式最初只存储了张量,这就是GGML工具,后来由于一些不足:
它无法有效地识别不同的模型架构,
对超参数的添加和移除具有破坏性,这使得模型的迭代和升级变得复杂。
为此,在2023年8月份,Georgi Gerganov推出了GGUF作为后续的替代者,即:GGUF格式标准:
https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
- GGUF (GPT-Generated Unified Format) 是一种二进制模型文件格式,
- 专为GGML及其执行器快速加载和保存模型而设计。
- GGUF 是 GGML、GGMF 和 GGJT 的后继文件格式,通过包含加载模型所需的所有信息来确保明确性。
- GGUF 被设计为可扩展的,以便可以在不破坏兼容性的情况下将新信息添加到模型中。
GGUF 的特点
大语言模型的开发通常使用PyTorch等框架,其预训练结果通常也会保存为相应的二进制格式,如pt后缀的文件通常就是PyTorch框架保存的二进制预训练结果。
但是,大模型的存储一个很重要的问题是它的模型文件巨大,而模型的结构、参数等也会影响模型的推理效果和性能。
将原始模型预训练结果转换成GGUF之后,有下面优势:
一、可以更加高效的使用
原始的大模型预训练结果经过转换后变成GGUF格式可以更快地被载入使用,也会消耗更低的资源。
原因在于GGUF采用了多种技术来保存大模型预训练结果,包括采用紧凑的二进制编码格式、优化的数据结构、内存映射等。
1、二进制格式
GGUF作为一种二进制格式,相较于文本格式的文件,可以更快地被读取和解析。
二进制文件通常更紧凑,减少了读取和解析时所需的I/O操作和处理时间,这对于需要频繁加载不同模型的场景尤为重要。
2、优化的数据结构
GGUF采用了特别优化的数据结构,这些结构为快速访问和加载模型数据提供了支持。例如,数据可能按照内存加载的需要进行组织,以减少加载时的处理。
3、全面的信息包含
GGUF包含加载模型所需的所有信息,无需依赖外部文件。这大大简化了模型部署和共享的过程。
这就可以跨平台和跨设备地加载和运行模型,无需安装任何额外的依赖库。
二、量化技术,降低资源消耗
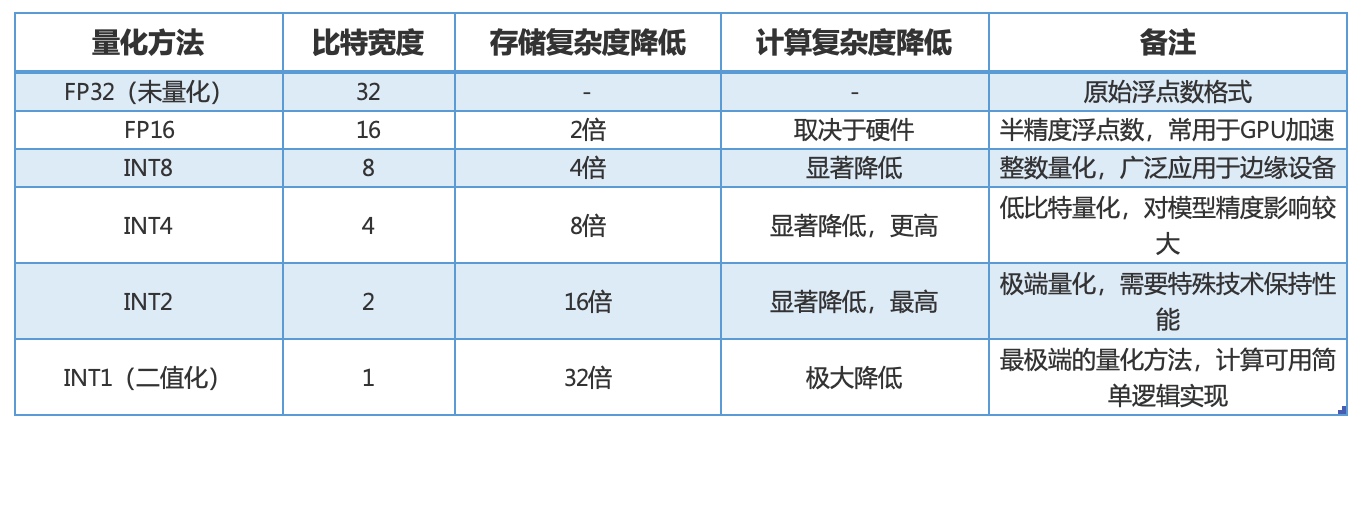
模型量化是一种将浮点计算转成低比特定点计算的技术,它可以有效的降低模型计算强度、参数大小和内存消耗,从而提高模型的推理速度和效率。
llama.cpp官方提供了转换脚本,可以将pt格式的预训练结果以及safetensors模型文件转换成GGUF格式的文件。转换的时候也可以选择量化参数,降低模型的资源消耗。这个过程性能损失很低!
GGML支持将模型权重量化为较低位数的整数,进一步减小模型大小并提高计算效率,同时也是一种平衡性能和精度的手段。
参看:QLoRa 低秩分解+权重量化的微调 权重量化部分。
使用范围
在HuggingFace上这类模型有6K+个。
https://huggingface.co/models?library=gguf&sort=trending
可以看到这类模型不少了。
文件名格式
GGUF 有多种格式,主要区别在于浮点数的位数和量化的方式。不同的格式会影响模型的大小、性能和精度,一般来说,位数越少,量化越多,模型越小,速度越快,但是精度也越低。
在模型文件命名中,也能看到这样的区别,类似如下:
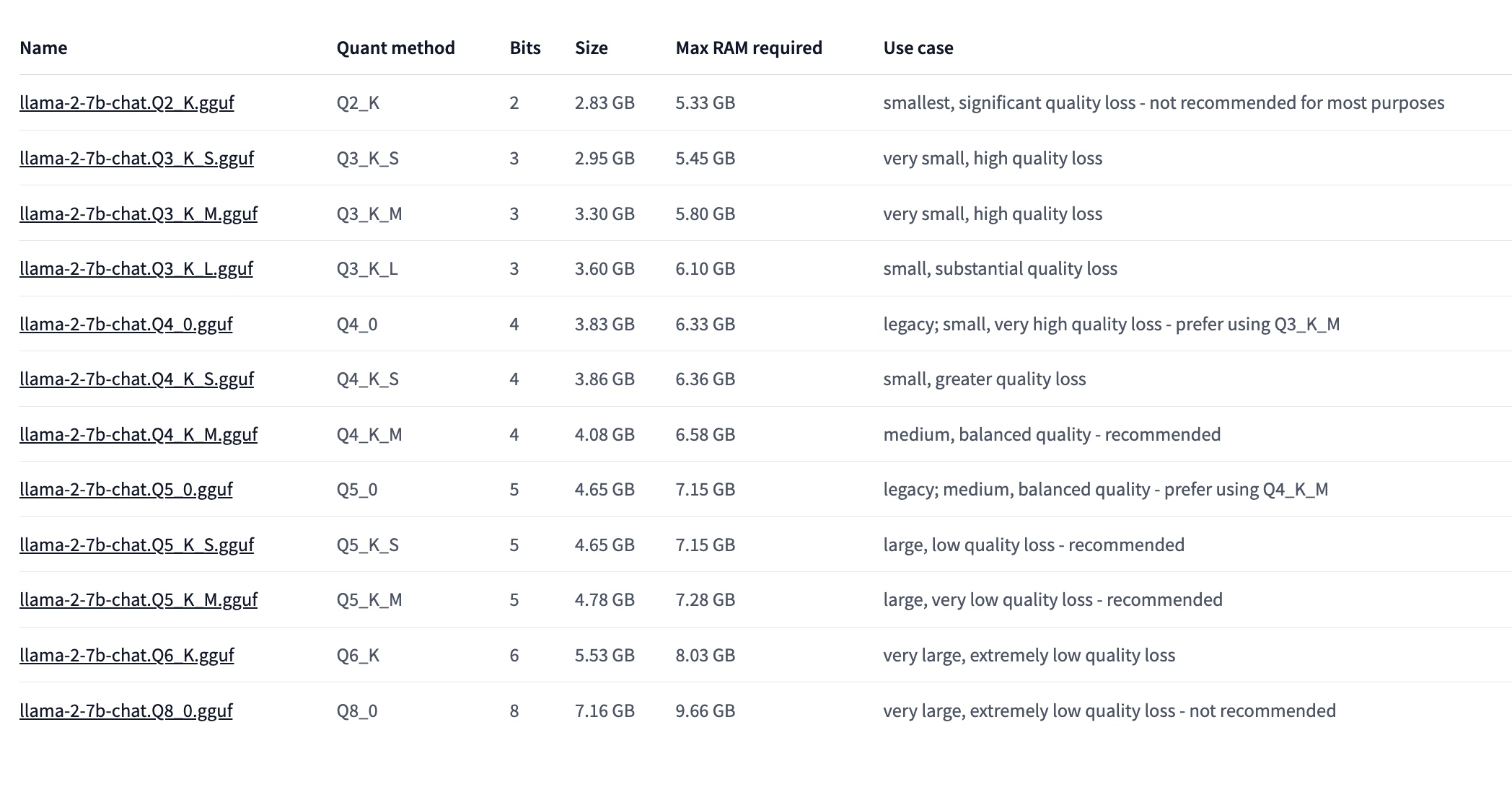
上面命名中的关键字解释:
“Q”+用于存储权重(精度)的位数+特定变体。
1、Q(Quantization):
Q2、Q3、Q4、Q5、Q6 分别表示模型的量化位数。例如,Q2 表示 2 位量化,Q3 表示 3 位量化,以此类推。量化位数越高,模型的精度损失就越小,但同时模型的大小和计算需求也会增加。
2、特定变体
特定变体的几个参数,我们从 https://github.com/ggerganov/ggml/blob/master/docs/gguf.md 文档可以看出,这些是量化方案的类型。
按照 https://towardsdatascience.com/quantize-llama-models-with-ggml-and-llama-cpp-3612dfbcc172 这里对每个变体的说明:
- q2_k: Uses Q4_K for the attention.vw and feed_forward.w2 tensors, Q2_K for the other tensors.
- q3_k_l: Uses Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
- q3_k_m: Uses Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
- q3_k_s: Uses Q3_K for all tensors
- q4_0: Original quant method, 4-bit.
- q4_1: Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models.
- q4_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q4_K
- q4_k_s: Uses Q4_K for all tensors
- q5_0: Higher accuracy, higher resource usage and slower inference.
- q5_1: Even higher accuracy, resource usage and slower inference.
- q5_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q5_K
- q5_k_s: Uses Q5_K for all tensors
- q6_k: Uses Q8_K for all tensors
- q8_0: Almost indistinguishable from float16. High resource use and slow. Not recommended for most users.
https://huggingface.co/mlabonne/gemma-2b-it-GGUF 也有类似的说明。可以看到不同变体其实就是采用了不同的量化方案来处理 attention.wv、attention.wo 和 feed_forward.w2 张量。
这些方案被命名为不同的变体,如 "q3_k_l"、"q3_k_m" 和 "q4_k_m"。这些变体的主要区别在于对于这些关键张量使用的量化方案的不同。
总结
GGUF 模型是一种二进制模型文件格式,专为在CPU上快速加载和保存模型而设计。它是 GGML、GGMF 和 GGJT 的后继文件格式,通过包含加载模型所需的所有信息来确保明确性,并且可以在不破坏兼容性的情况下扩展新信息。
GGUF 的特点包括:
- 更高效的使用:GGUF 格式采用多种技术来保存模型,包括紧凑的二进制编码格式、优化的数据结构和内存映射,从而使模型在加载和使用时更快速,资源消耗更低。
- 量化技术降低资源消耗:GGUF 支持模型量化,可以将模型权重量化为较低位数的整数,降低模型大小和内存消耗,提高计算效率,同时平衡性能和精度。
GGUF 模型在 HuggingFace 上已经有大量应用,文件名格式以"Q"开头表示量化位数,后跟特定变体,这些变体根据量化方案的不同而命名,影响模型的大小、性能和精度。

