【python】B站弹幕数据分析及可视化(爬虫+数据挖掘)
成果展示



项目地址
完整代码可在我的github中下载:https://github.com/XavierJiezou/python-danmu-analysis
爬取弹幕
可以看我之前写的这篇文章:10行代码下载B站弹幕
下载代码
# download.py
'''依赖模块
pip install requests
'''
import re
import requests
url = input('请输入B站视频链接: ')
res = requests.get(url)
cid = re.findall(r'"cid":(.*?),', res.text)[-1]
url = f'https://comment.bilibili.com/{cid}.xml'
res = requests.get(url)
with open(f'{cid}.xml', 'wb') as f:
f.write(res.content)
样例输入
B站番剧《花丸幼稚园》第六集视频播放地址:https://www.bilibili.com/bangumi/play/ep17617
样例输出
弹幕文件51816463.xml:https://comment.bilibili.com/51816463.xml
数据处理
下载弹幕文件51816463.xml后,我们打开看一下:
<?xml version="1.0" encoding="UTF-8"?>
<i>
<chatserver>chat.bilibili.com</chatserver>
<chatid>51816463</chatid>
<mission>0</mission>
<maxlimit>3000</maxlimit>
<state>0</state>
<real_name>0</real_name>
<source>k-v</source>
<d p="302.30800,1,25,16777215,1606932706,0,b105c2ee,41833218383544323">长颈鹿呢?还是大象呢?(</d>
<d p="608.17000,1,25,16707842,1606926336,0,af4597df,41829878640672775">我也不想的,实在是太大了呀</d>
<d p="249.95600,1,25,14811775,1606925877,0,af4597df,41829637765988357">真是深不可测啊</d>
此处省略很多字
</i>
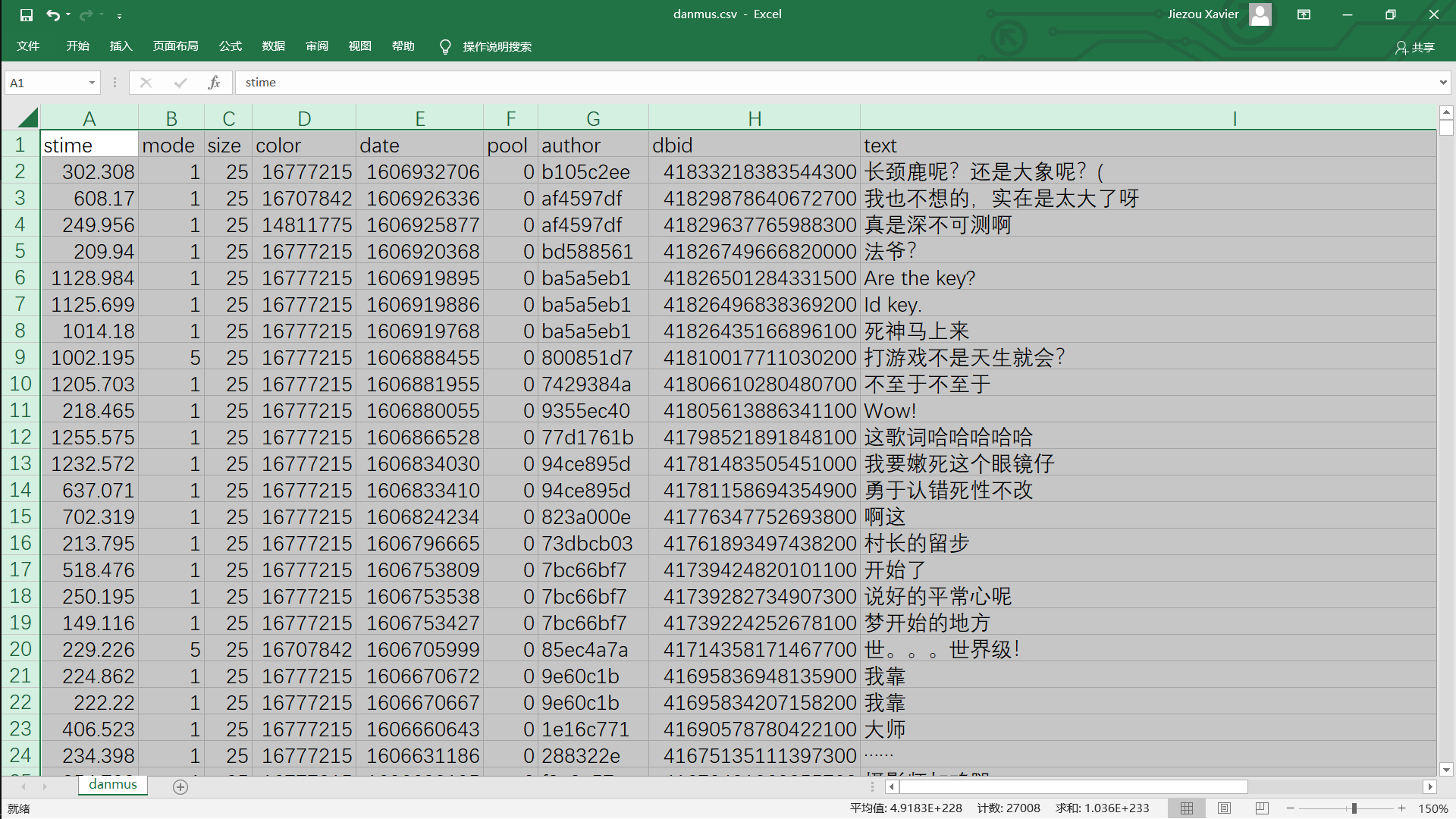
可以看到xml文件中d标签的text部分就是弹幕的文本,而d标签的p属性应该是弹幕的相关参数,共有8个,用逗号分隔。
参数略解:
- stime: 弹幕出现时间 (s)
- mode: 弹幕类型 (< 7 时为普通弹幕)
- size: 字号
- color: 文字颜色
- date: 发送时间戳
- pool: 弹幕池ID
- author: 发送者ID
- dbid: 数据库记录ID(单调递增)
参数详解:
① stime(float):弹幕出现时间,单位是秒;也就是在几秒出现弹幕。
② mode(int):弹幕类型,有8种;小于8为普通弹幕,8是高级弹幕。
- 1~3:滚动弹幕
- 4:底端弹幕
- 6:顶端弹幕
- 7:逆向弹幕
- 8:高级弹幕
③ size(int):字号。
- 12:非常小
- 16:特小
- 18:小
- 25:中
- 36:大
- 45:很大
- 64:特别大
④ color(int):文字颜色;十进制表示的颜色。
⑤ data(int):弹幕发送时间戳。也就是从基准时间1970-1-1 08:00:00开始到发送时间的秒数。
⑥ pool(int):弹幕池ID。
- 0:普通池
- 1:字幕池
- 2:特殊池(高级弹幕专用)
⑦ author(str):发送者ID,用于"屏蔽此发送者的弹幕"的功能。
⑧ dbid(str):弹幕在数据库中的行ID,用于"历史弹幕"功能。
了解弹幕的参数后,我们就将弹幕信息保存为danmus.csv文件:
# processing.py
import re
with open('51816463.xml', encoding='utf-8') as f:
data = f.read()
comments = re.findall('<d p="(.*?)">(.*?)</d>', data)
# print(len(comments)) # 3000
danmus = [','.join(item) for item in comments]
headers = ['stime', 'mode', 'size', 'color', 'date', 'pool', 'author', 'dbid', 'text']
headers = ','.join(headers)
danmus.insert(0, headers)
with open('danmus.csv', 'w', encoding='utf_8_sig') as f:
f.writelines([line+'\n' for line in danmus])
数据分析
词频分析

# wordCloud.py
'''依赖模块
pip install jieba, pyecharts
'''
from pyecharts import options as opts
from pyecharts.charts import WordCloud
import jieba
with open('danmus.csv', encoding='utf-8') as f:
text = " ".join([line.split(',')[-1] for line in f.readlines()])
words = jieba.cut(text)
_dict = {}
for word in words:
if len(word) >= 2:
_dict[word] = _dict.get(word, 0)+1
items = list(_dict.items())
items.sort(key=lambda x: x[1], reverse=True)
c = (
WordCloud()
.add(
"",
items,
word_size_range=[20, 120],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.render("wordcloud.html")
)
情感分析

由饼状图可知:3000条弹幕中,积极弹幕超过一半,中立弹幕有百分之三十几。
当然,弹幕调侃内容居中,而且有很多梗,会对情感分析造成很大的障碍,举个栗子:
>>> from snownlp import SnowNLP >>> s = SnowNLP('阿伟死了') >>> s.sentiments 0.1373666377744408"阿伟死了"因带有"死"字,所以被判别为消极情绪。但实际上,它反映的确是积极情绪,形容对看到可爱的事物时的激动心情。
# emotionAnalysis.py
'''依赖模块
pip install snownlp, pyecharts
'''
from snownlp import SnowNLP
from pyecharts import options as opts
from pyecharts.charts import Pie
with open('danmus.csv', encoding='utf-8') as f:
text = [line.split(',')[-1] for line in f.readlines()[1:]]
emotions = {
'positive': 0,
'negative': 0,
'neutral': 0
}
for item in text:
if SnowNLP(item).sentiments > 0.6:
emotions['positive'] += 1
elif SnowNLP(item).sentiments < 0.4:
emotions['negative'] += 1
else:
emotions['neutral'] += 1
print(emotions)
c = (
Pie()
.add("", list(emotions.items()))
.set_colors(["blue", "purple", "orange"])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
.render("emotionAnalysis.html")
)
精彩片段

由折线图可知:第3分钟,第8、第9分钟,还有第13分钟分别是该视频的精彩片段。
# highlights.py
'''依赖模块
pip install snownlp, pyecharts
'''
from pyecharts.commons.utils import JsCode
from pyecharts.charts import Line
from pyecharts.charts import Line, Grid
import pyecharts.options as opts
with open('danmus.csv', encoding='utf-8') as f:
text = [float(line.split(',')[0]) for line in f.readlines()[1:]]
text = sorted([int(item) for item in text])
data = {}
for item in text:
item = int(item/60)
data[item] = data.get(item, 0)+1
x_data = list(data.keys())
y_data = list(data.values())
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
area_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#eb64fb'}, {offset: 1, color: '#3fbbff0d'}], false)"
)
c = (
Line(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="弹幕数量",
y_axis=y_data,
is_smooth=True,
symbol="circle",
symbol_size=6,
linestyle_opts=opts.LineStyleOpts(color="#fff"),
label_opts=opts.LabelOpts(is_show=True, position="top", color="white"),
itemstyle_opts=opts.ItemStyleOpts(
color="red", border_color="#fff", border_width=3
),
tooltip_opts=opts.TooltipOpts(is_show=True),
areastyle_opts=opts.AreaStyleOpts(
color=JsCode(area_color_js), opacity=1),
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_="max")])
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(
color="#fff", font_size=16),
),
xaxis_opts=opts.AxisOpts(
type_="category",
boundary_gap=False,
axislabel_opts=opts.LabelOpts(margin=30, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=2, color="#fff")
),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=25,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=True, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
)
),
yaxis_opts=opts.AxisOpts(
type_="value",
position="left",
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=2, color="#fff")
),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=True, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="line")
)
.render("highlights.html")
)
高能时刻
更多时候,我们可能对精彩片段不太关注,而是想知道番剧的名场面出自几分几秒,即高能时刻。
# highEnergyMoment.py
import re
with open('danmus.csv', encoding='utf-8') as f:
danmus = []
for line in f.readlines()[1:]:
time = int(float(line.split(',')[0]))
text = line.split(',')[-1].replace('\n', '')
danmus.append([time, text])
danmus.sort(key=lambda x: x[0])
dict1 = {}
dict2 = {}
control = True
for item in danmus:
if re.search('名场面(:|:)', item[1]):
print(f'{int(item[0]/60)}m{item[0]%60}s {item[1]}')
control = False
break
if '名场面' in item[1]:
minute = int(item[0]/60)
second = item[0] % 60
dict1[minute] = dict1.get(minute, 0)+1
dict2[minute] = dict2.get(minute, 0)+second
else:
pass
if control:
minute= max(dict1, key=dict1.get)
second = round(dict2[minute]/dict1[minute])
print(f'{minute}m{second}s 名场面')
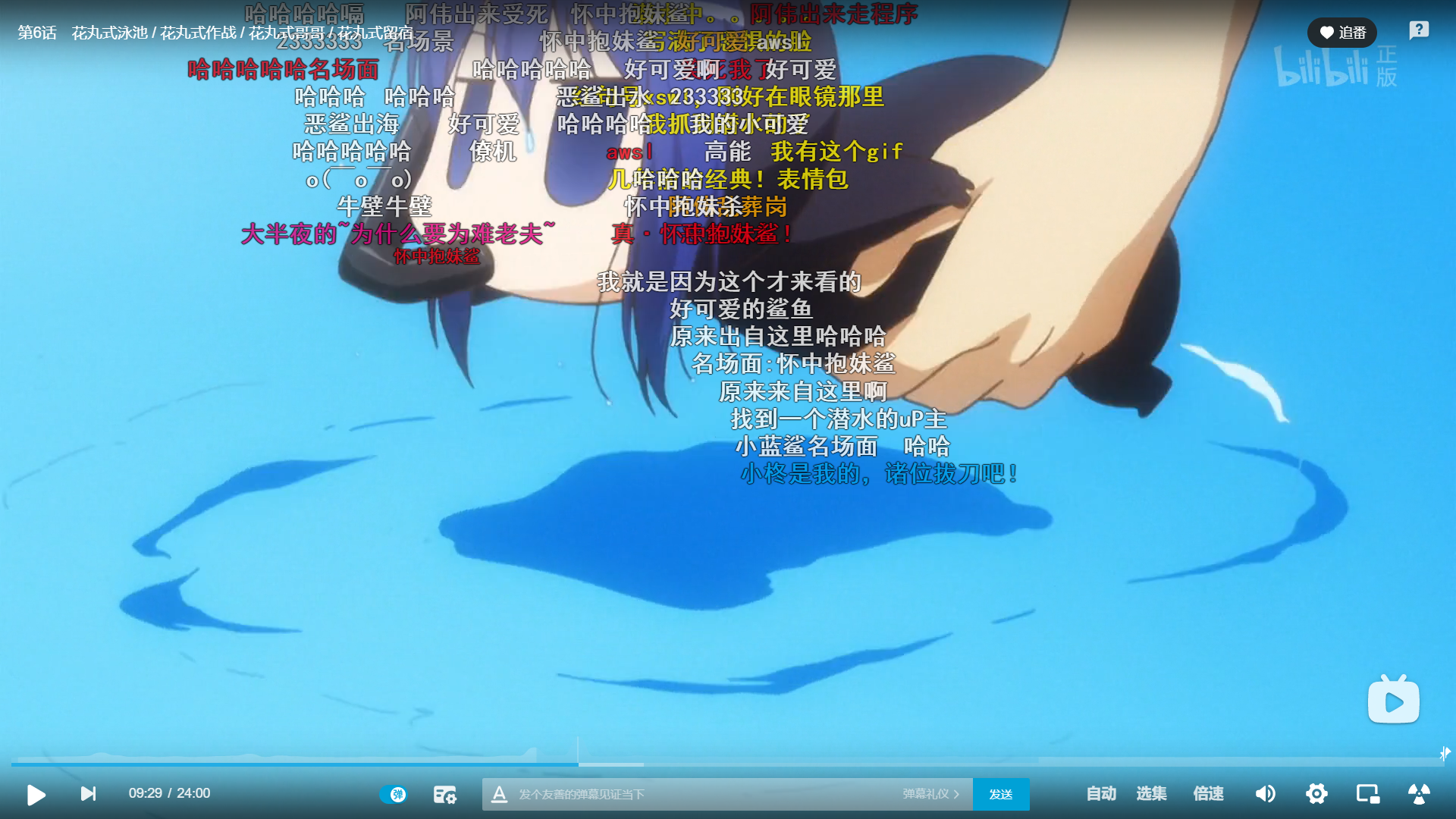
输出:9m29s 名场面:怀中抱妹鲨。我们去视频中看一下,9m29s确实是名场面:
福利情节
字体颜色为黄色,也就是10进制颜色的值为16776960时,就是那种比较污的福利情节,同时为了防止异常,只有当该分钟内出现黄色弹幕的次数≥3时,才说明该分钟内是福利情节,并且输出该分钟内第一次出现黄色弹幕的秒数:
02m15s 吼吼吼
03m30s 什么玩意
06m19s 真的有那么Q弹吗
08m17s 憋死
09m10s 前方万恶之源
10m54s 噢噢噢噢
11m02s 这就是平常心
12m34s 这个我可以
17m19s 因为你是钢筋混凝土直女
18m06s 假面骑士ooo是你吗
19m00s 警察叔叔就是这个人
20m00s 金色传说的说。。。
21m02s 嘿嘿嘿~
# textColor.py
with open('danmus.csv', encoding='utf-8') as f:
danmus = []
for line in f.readlines()[1:]:
time = int(float(line.split(',')[0]))
color = line.split(',')[3]
text = line.split(',')[-1].replace('\n', '')
danmus.append([time, color, text])
danmus.sort(key=lambda x: x[0])
dict1 = {}
dict2 = {}
for item in danmus:
if item[1] == '16776960':
minute = int(item[0]/60)
second = item[0] % 60
dict1[minute] = dict1.get(minute, 0)+1
if dict2.get(minute) == None:
dict2[minute] = f'{minute:0>2}m{second:0>2}s {item[2]}'
else:
pass
for key, value in dict1.items():
if value >= 3:
print(dict2[key])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号