软考程序设计语言基础
程序设计语言基础
考点归纳
1. 汇编、编译、解释系统基础
汇编程序的概念、编译程序的概念、解释程序的概念、编译与解释的区别(重点)、编译过程的工作原理(包括词法分析、语法分析、语言分析、中间代码生成、代码优化等)、文法(重点)、有限自动机(重点)、正规式(重点)、后缀表达式
2. 程序设计语言基础
C/C++语言基本语法、程序的控制结构、函数调用的参数传递、程序的书写规范与常识
3. 各类程序设计语言基础
过程式程序语言、函数式程序设计语言、逻辑程序设计语言的基本特点、脚本语言的特点、各种程序语言的特点比较
基础知识
1.低级语言和高级语言
(1)低级语言
机器语言和汇编语言称为低级语言。
机器语言指0、1组成的机器指令序列。
※ 汇编语言指用符号表示指令的语言
MOV AX,2
MOV BX,3
ADD AX,BX
(2)高级语言
高级语言是从人类的逡辑思维角度出发、面向各类应用的程序 语言,抽象程度大大提高,需要编译成特定机器上的目标代码才 能执行。这类语言不人们使用的自然语言比较接近,大大提高了 程序设计的效率。
2.编译程序和解释程序
高级语言或汇编语言编写的程序称为源程序,源程序不能直接在计算机上执行。
※ 如果源程序是汇编语言编写的,则需要一个称为
汇编程序的翻译程序将其翻译成目标程序,然后才能执行。
※ 如果源程序是为高级语言时,这个翻译程序称为编译程序
※ 按源程序中语句的执行顺序,逐条翻译并立即执行相关功能的处理程序、称为解释程序。
程序的执行方式:
1、编译执行:按编译方式在计算机上执行用高级语言编写的程序,需经过两个阶段:
编译阶段,把源程序翻译为目标程序;
运行阶段,真正执行此目标程序。
※ 优点:执行效率高、占用资源小。
※ 缺点:兼容性差。
2、解释执行:源程序的每个语句一经解释就立即执行。
※ 优点:可移植性较好、开发速度较快、不用户通信方便。
※ 缺点:效率低。
二者背后的最大区别是:对解释执行而言,程序运行时的控制权在解释器而不在用户程序;对编译执行而言,运行时的控制权在用户程序。
即后者生成目标代码,而前者不生成。
编译系统基本原理
参考链接:编译程序基本原理
反编译通常不能把可执行文件还原成高级语言源代码
编译程序的工作过程可以分为 6个阶段:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。

①词法分析阶段
1、输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个“单词”符号,删掉无用信息,报告分析时的错误。
一个程序语言的基本语法符号分为五类:关键字、标识符、 常量、运算符、界符等。
词法分析器所输出单词符号常常表示成如下的二元式:
(单词种别,单词符号的属性值)
描述词法规则通常用:正规式 和 有限自动机。
例如:while(i>=j) i-- 经词法分析器处理后,它将被转为如下的单词符号序列:
< while , _>
< ( , _>
< id , 指向i的符号表项的指针>
< >= , _>
< id , 指向j的符号表项的指针>
< ) , _>
< id , 指向i的符号表项的指针>
< -- , _>
2、状态转换图
状态转换图是状态有限的有向图,用圆圈表示结点状态,结点之间有向边代表状态转换,有向边上可标记字符,表示前一状态接受某一个字符之后的状态转移。 右图表示在状态i下的状态转换:
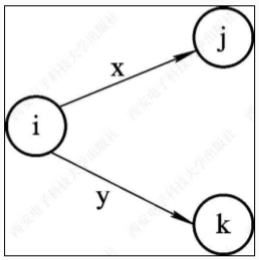
※ 若输入字符为x,则读入x并转换到状态j;
※ 若输入字符为y,则读入y并转换到状态k。
状态转换图的功能
※ 用于识别一定字符串
状态转换图的要求
※ 状态(即结点)个数有限
※ 至少一个初始状态,若干终止状态
※ 每条边上标有字符(也可以是空字符)
状态转换图的表示习惯
※ 初始状态用“ ○”表示
※ 非终止状态用“○”表示
※ 状态之间的跳转用“ ”(有向边)表示
”(有向边)表示
※ 终止状态用“ ◎ ”表示
※ 多读进一个字符用“ * ”表示
 3、正规表达式不正规集(定义和运算)
3、正规表达式不正规集(定义和运算)
状态转换图可以构造词法分析程序,但属于非形式化描述正规表达式(简称正规式)是词法分析的形式化表示方法。所谓形式化的方法,是指用一整套带有严格规定的符号体系来描述问题的方法。
优点:更加清晰和准确
正规式不正规集的递归定义:
- ε和Φ都是字母表∑上的正规式,它们所表示的正规集分别为{ε}和Φ;
- 任何a∈∑,a是∑上的一个正规式,它所表示的正规集为{a};
| 正规式 | 正规集 | 正规式 | 正规集 |
|---|---|---|---|
| U | L(U) | (U | V) |
L(U)∪L(V) |
| V | L(V) | (U·V) | L(U)L(V) |
| 无 | 无 | (U)* | L(U)*(闭包) |
仅由有限次使用上述三步骤而得到的表达式才是∑上的正规式。仅由这 些正规式所表示的子集才是∑上的正规集。
正规式定义中 :
“|”读为“或
“ · ”读为“连接”
“ * ”读为“闭包”(即,任意有限次的自重复连接)。
| 正规式 | 正规集 |
|---|---|
| a | {a} |
a|b |
{a,b} |
| ab | {ab} |
(a|b)(a|b) |
{aa,ab,ba,bb} |
| a* | {ε,a,aa, ……任意个a的串} |
(a|b)* |
{ε,a,b,aa,ab ……所有由a和b组成的串} |
(a|b)*(aa|bb)(a|b)* |
{∑*上所有含有两个相继的a或两个相 继的b组成的串} |
※ 初始状态
※ 终止状态(接收状态):
※ 后继状态:有限状态机在读入一个字符时,其状态改变为另 一状态,则改变后的状态被称为后继状态。
如果有限状态机每次转换后的状态是唯一的则称之为确定有限状态自动机(DFA);如果转换后的后继状态丌是唯一的则称之为不确定有限自动机(NFA)。
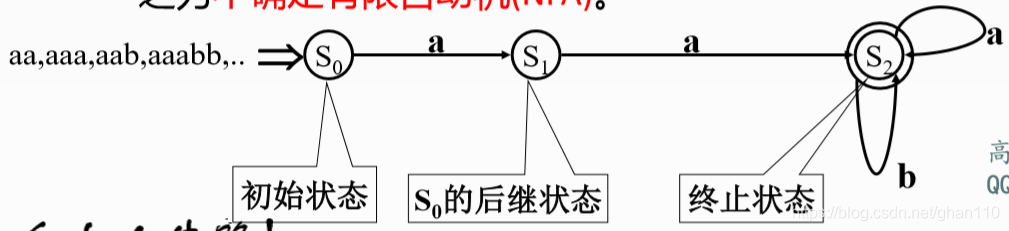 4、有限自动机(DFA)
4、有限自动机(DFA)
一个确定有限自动机(DFA) M是一个五元式:
M=(S , ∑ , δ , s0 , F),其中
1、S是一个有限集,它的每个元素称为一个状态
2、∑是一个有穷字母表,它的每个元素称为一个输入字符
3、 δ是一个从S × ∑至S的单值部分映射。 δ(s,a)=s’意 味着:当现行状态为S,输入a时,将转换到下一状态s’我们 称s’为s的一个后继状态。
4、s0∈S是唯一的初态
5、F⊆S是一个终态集(可空)
若某DFAD与某NFAM等价,则DFAD与NFAM可识别的记号相同。
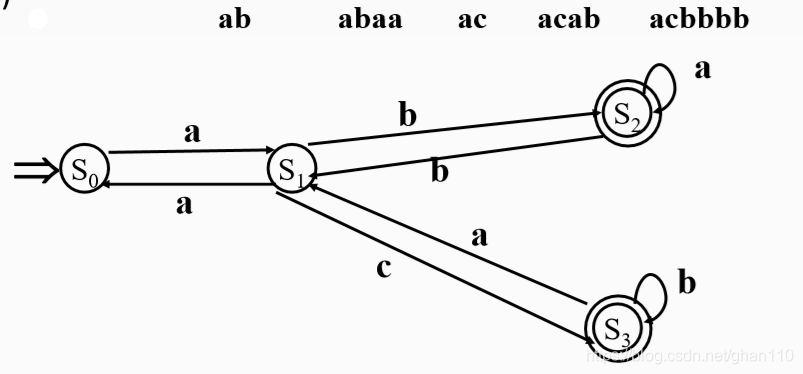
例:AD=(S, ∑ , δ ,K , F) 其中: S={S0, S1, S2, S3}; ∑={a,b,c} K= S0; F={S2, S3}; δ 转换函数: (S0,a)= S1; (S1,a)= S0; (S1,b)= S2; (S1,c)= S3; (S2,a)= S2; (S2,b)=S1; (S3,a)= S1; (S3,b)= S3;
②语法分析
语法分析器以单词符号作为输入,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等, 按语法规则分析检查每条语句是否有正确的逻辑结构。
int arr[2],b;
b = arr * 10;
语法分析的方法: 自上而下分析法 ; 自下而上分析法
词法分析和语法分析本质上都是对源程序的结构进行分析。

③语义分析— 类型分析和检查错误
语义分析阶段主要是检查源程序是否存在语义错误,并收集类型信息供后面的代码生成阶段使用,只有语法和语义都正确的源程序才能翻译成正确的目标代码。
语义分析的主要工作是进行各类型分析和检查。赋值语句的右端和左端的类型不匹配。表达式的除数是否为零等。
int arr[2],b;
b = arr * 10;
④中间代码生成
中间代码生成阶段的工作是根据语义分析的输出生成中间代码。它是一种简单且含义明确的记号系统,他们的共同特征是与机器无关。中间代码的设计原则:一是容易生成,二是容易被翻译成目标代码。
语义分析和中间代码生成所依据的是语言的语义规则。
⑤代码优化
由于编译器将源程序翻译成中间代码的工作是机械的,因此,生成中间代码往往在计算时间上和存储空间上有很大的浪费。优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。优化所依据的原则是程序的等价变换规则。
⑥目标代码生成
目标代码生成是编译器工作的最后一个阶段。这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码, 这个阶段的工作与具体的机器密切相关。
并不是所有的编译器都会有目标代码或代码优化的过程
⑦符号表管理
符号表的作用是记录源程序中各个符号的必要信息, 以辅助语义的正确性检查和代码生成, 在编译过程中需要对符号表进行快速有效地查找、插入、修改和删除操作.
⑧出错处理
用户编写的源程序不可避免地会有一些错误,这些错误大致可分为静态错误和动态错误。
动态错误也称动态语义错误, 他们发生在程序运行时, 例如变量取零作除数、数组下标越界等错误。
静态错误是编译时所发现的程序错误,可分为语法错误和静态语义错误, 如单词拼写错误、标点符号错误、表达式中缺少操作数、括号不匹配等有关语言结构上的错误称为语法错误; 而语义分析时发现的运算符与运算对象类型不合法等错误属于静态语义错误。
对于编译过程的各个阶段,在逻辑上可以把它们划分为
前端和后端两部分。
前端包括从词法分析到中间代码生成各阶段的工作;
后端包括中间代码优化和目标代码的生成及优化等阶段。
以中间代码为分水岭,把编译器分成了与机器有关的部分和与机器无关的部分。前后端的有机结合后就形成了该语言的一个编译器。
程序语言的控制结构
一、表达式
※ 前缀表达式:也被称为波兰表示法,其特点是将操作符置 于操作数之前,如: - × + 3 4 5 6 。
※ 中缀表达式:即我们常用的表示方法,(3 + 4) × 5 - 6 。
※ 后缀表达式:又被称为逆波兰法,其特点是将操作符置于操作数之后,3 4 + 5 × 6 - 。
1、前缀表达式
从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到 运算符时,弹出栈顶的两个数,用运算符对它们做相应的计 算(栈顶元素 op 次顶元素),并将结果入栈;重复上述过程 直到表达式最左端,最后运算得出的值即为表达式的结果。
例如前缀表达式“- × + 3 4 5 6”:
(1) 从右至左扫描,将6、5、4、3压入堆栈;
(2) 遇到+运算符,因此弹出3和4(3为栈顶元素,4为次顶元素,注意与后缀表达式做比较),计算出3+4的值,得7,再将7入栈;
(3) 接下来是×运算符,因此弹出7和5,计算出7×5=35,将35入栈;
(4) 最后是-运算符,计算出35-6的值,即29,由此得出最终结果。
2、中缀表达式(中缀记法)
中缀表达式是一种通用的算术戒逻辑公式表示方法,操作符 以中缀形式处于操作数的中间。中缀表达式是人们常用的算 术表示方法。 虽然人的大脑很容易理解不分析中缀表达式,但对计算机来 说中缀表达式却是很复杂的,因此计算表达式的值时,通常 需要先将中缀表达式转换为前缀戒后缀表达式,然后再进行 求值。
我们平常用的表达式a+b-c这样的就是中缀表达式。
3、后缀表达式
不前缀表达式类似,叧是顺序是从左至右: 从左至右扫描表达式,遇到数字时,将数字压入堆栈,遇到 运算符时,弹出栈顶的两个数,用运算符对它们做相应的计 算(次顶元素 op 栈顶元素),并将结果入栈;重复上述过程 直到表达式最右端,最后运算得出的值即为表达式的结果。
例如后缀表达式“3 4 + 5 × 6 -”:
(1) 从左至右扫描,将3和4压入堆栈;
(2) 遇到+运算符,因此弹出4和3(4为栈顶元素,3为次顶元素,注意与前缀表达式做比较),计算出3+4的值,得7,再将7入栈;
(3) 将5入栈;
(4) 接下来是×运算符,因此弹出5和7,计算出7×5=35,将35入栈;
(5) 将6入栈;
(6) 最后是-运算符,计算出35-6的值,即29,由此得出最终结果。
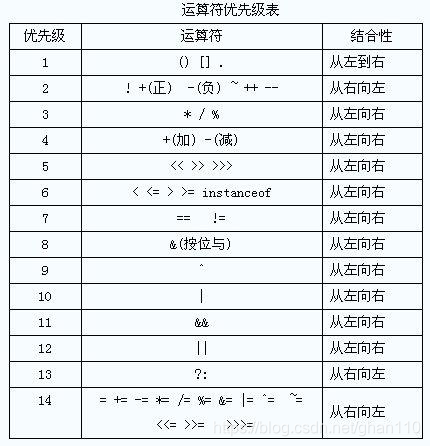
二、操作符的优先级
◎ 指针最优,单目运算优于双目运算。如正负号。
◎ 先乘除(模),后加减。
◎ 先算术运算,后移位运算,最后位运算。
1 << 3 + 2 & 7等价于 (1 << (3 + 2))&7
◎ 逻辑运算最后计算
三、语句间的结构
◎顺序语句 ◎ 选择语句 ◎ 循环语句
四、过程控制
int Function1 (int x,int y)
{
…
}
参数传递的方式
& 传值调用 -- 数据传送是`单向`的
& 引用调用(地址调用)--数据传送是`双向`的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号