Xpath编码问题解决
使用Xpath获取属性时,出现乱码问题,解决办法找了好多,终于解决,特将办法贴在这,供大家尝试
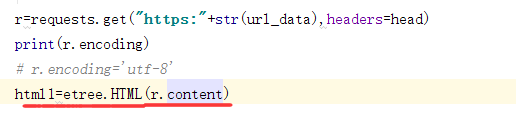
不要直接简单的将爬取的网页设置为utf-8,
先通过print(r.encoding)输出看看爬取的是什么编码,每个网页采用的编码不同,
后通过标红线的代码可解决问题
selector_new = etree.HTML(html.text)
是将HTML转化为文本/html 格式
selector_new = etree.HTML(html.content)
是将HTML转化为二进制/html 格式
我是通过以下链接博客解决的:
https://blog.csdn.net/hyg55555/article/details/85246353

 浙公网安备 33010602011771号
浙公网安备 33010602011771号