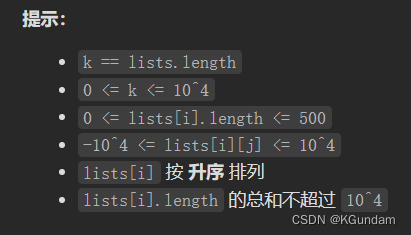
leetcode-23.合并K个升序链表
优先队列
题目详情
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例2:
输入:lists = []
输出:[]
示例3:
输入:lists = [[]]
输出:[]
前置知识
在解决这道题之前,我们需要先知道怎样合并两个有序链表,在许多数据结构的书里一般都会有合并方法,假设有两个有序链表a和b
首先,我们需要一个head来保存我们合并后的链表头(可以是头结点,也可以是第一个有效结点)
其次,我们需要一个tail指针来保存合并链表下一个即将插入元素位置的前一位置,再用两个指针aPtr bPtr保存a和b的剩余未插入部分的首结点
接着,我们只需让aPtr和bPtr都非空的时候,依次比较a和b遍历到的结点的值,将较小者插入tail->next,最后a和b可能都空了(处理完了),也有可能二者剩一条残留的
最后,我们将剩余的a或b的部分接在合并链表的后面即可
代码:
ListNode* mergeTwoLists(ListNode *a, ListNode *b)
{
if ((!a) || (!b)) return a? a : b; // 有一个空就直接返回
ListNode head, *tail = &head, *aPtr = a, *bPtr = b; //我这里的head保存的是头结点(不包含有效元素)
while (aPtr && bPtr) //两个都非空就比较插入
{
if (aPtr->val < bPtr->val) //a较小就接入a
{
tail->next = aPtr;
aPtr = aPtr->next;
}
else //b较小就接入b
{
tail->next = bPtr;
bPtr = bPtr->next;
}
tail = tail->next; //别忘了每次都要更新tail为下一节点
}
tail->next = (aPtr? aPtr : bPtr); //最后将残留部分接上
return head.next; //返回head的next
}
再回到这道题上,我们知道了两个有序链表的合并方法,就可以利用其写出K个链表的合并方法:
用一个变量 ans 来维护以及合并的链表,第 i 次循环把第 i 个链表和 ans 合并,答案保存到 ans 中。代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* mergeTwoLists(ListNode *a, ListNode *b) //辅函数
{
if ((!a) || (!b)) return a? a : b;
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr)
{
if (aPtr->val < bPtr->val)
{
tail->next = aPtr;
aPtr = aPtr->next;
}
else
{
tail->next = bPtr;
bPtr = bPtr->next;
}
tail = tail->next;
}
tail->next = (aPtr? aPtr : bPtr);
return head.next;
}
ListNode* mergeKLists(vector<ListNode*>& lists) //主函数
{
ListNode *ans = nullptr; // 初始化指向空指针
for (size_t i = 0; i < lists.size(); ++i)
{
ans = mergeTwoLists(ans, lists[i]); //依次合并
}
return ans;
}
};
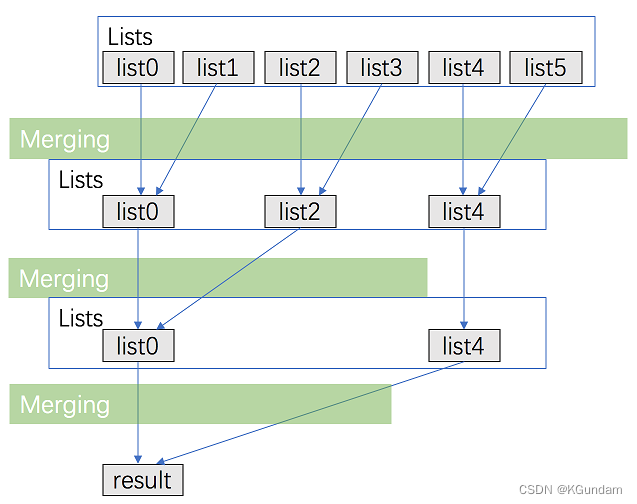
方法二(优化):分治合并
我们可以利用分治的思想,将链表两两配对组合,然后合并后继续配对组合,链表数量将以k --> k/2 --> k/4 --> k/8最后合并为1,这样就会适当减少比较次数,举个例子,链表有5个,长度为1 3 2 2 5
那么就会1 3组合 2 2 组合 5自己组合–>然后变为 4 4 5–>再让4 4组合 5自己 -->8 5–>最后8 5合并
这样相比1+3=4,4+2=6,6+2=8,8+5=13,四次比较就变成了3次,从而达到优化的作用
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* mergeTwoLists(ListNode *a, ListNode *b) //辅函数1(合并两个链表)
{
if ((!a) || (!b)) return a? a : b;
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr)
{
if (aPtr->val < bPtr->val)
{
tail->next = aPtr;
aPtr = aPtr->next;
}
else
{
tail->next = bPtr;
bPtr = bPtr->next;
}
tail = tail->next;
}
tail->next = (aPtr? aPtr : bPtr);
return head.next;
}
ListNode* merge(vector<ListNode*>& lists, int l, int r) //辅函数2
{
if (l == r) return lists[l]; // l==r代表合并为最后一个了
if (l > r) return nullptr; // l > r返回空指针
int mid = (l + r) >> 1; // 等价于(l+r)/2
return mergeTwoLists(merge(lists, l, mid), merge(lists, mid + 1, r));//递归分治
}
ListNode* mergeKLists(vector<ListNode*>& lists)
{
return merge(lists, 0, lists.size() - 1);
}
};
方法三:优先队列合并
思路:用容量为K的最小堆优先队列,把链表的头结点都放进去,然后出队当前优先队列中最小的,挂上链表,,然后让出队的那个节点的下一个入队,再出队当前优先队列中最小的,直到优先队列为空。
注意: comp这个自定义比较规则里为什么是a->val > b->val呢???
我们不是要的是哪个val小才排在队列前面吗?
是的,在C++的priority_queue中,默认的第三个参数(这里是我们传入的comp)
是less<>,所以我们这里要写的是优先级的比较规则而不是元素的比较规则
return a->val > b->val表示哪个元素的val大,哪个元素的优先级就小(less)
priority_queue详细原理可以参照这个:C++ | priority_queue的用法(含自定义排序方式)
class Solution
{
public:
struct comp //传入queue的比较规则
{
bool operator()(ListNode* a, ListNode* b)
{
return a->val > b->val;
}
};
// 创建优先队列(链表数组实现)
priority_queue<ListNode*, vector<ListNode*>, comp> q;
ListNode* mergeKLists(vector<ListNode*>& lists)
{
for (auto node:lists) // 将所有链表的头存入队列(这里会自动按从小到大排序)
{
if (node) q.push(node);
}
ListNode head; //记录头结点
ListNode* tail = &head;//从头结点开始处理
while (!q.empty())
{
//依次取出q中的最小头,临时存入node
ListNode* node = q.top();
q.pop();
tail->next = node; //将最小node接在答案tail后面
tail = tail->next; //tail后移
//将刚才pop的那个元素所在链表的next入队(如果存在)---新头
if (node->next) q.push(node->next);
}
return head.next;//返回头结点的next
}
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号