mysql(4)mysql的sql优化
1.索引
1)尽量使用where,或者子句中指定的列,而不是select后的列;
2)非重复/总数越接近1越好,
3)使用短索引,一个很长的char(200),假如前十个就能找出结果,那么我们可以只对前10个所以,减少io的负担,以及缓存块中可以缓存更多的键值,
4)对于符合索引遵循左前缀法则,值查询索引的应该从最左前列开始,不跳过索引的列;
5)不要过度的使用索引,因为会增加维护以及空间的开销,
6)对于索引不要做任何操作(计算,函数,自动或手动类型转换),否则会导致索引失效而转向全表扫描;
7)尽量使用覆盖索引,尽量减少select *的使用
8)like以通配符开头mysql索引会失效变成全局扫描,建议加在右边,假如两边都需要%,,可以使用覆盖索引来处理。
9)字符串不加单引号,索引失效,存在类型转换
10)mysql使用!=,<>,is null ,null的时候无法使用索引,少用or,用它连接是会导致索引失效
11)存储引擎不能使用索引中范围条件右边的列
备注:
索引会自动优化调试,对于const与> , < 等时有效,在 order by ,group by 时无效且order by与group by后的字段顺序不可变,Order by ,group by 可以使用前面为const的引用,一条sql只能使用一条索引,至于是那条索引,那么看sql优化机制来选取,所以对于order by ,group by 的很多时候会用到联合索引去除文件排序(filesort),索引不要太多,一般不超过6个,但是某些情况还得看请情况。支持函数索引// 5.7 例如mod(i,10)
iot表(索引表)是根据主键排序的,根据btree来说,顺序执行较随机执行的效率高很多。
索引的优化知识mysql优化的一部分,还需要考虑关键字的宽度大小,例如inttiny较int肯定快,int较varchar肯定快,因为这个涉及到io读写速度已经内存的存储量大小
这里顺便说一下原子性也一致性,原子性的保证是通过redo(新数据),undo(旧数据),来实施的,那么一致性也是依赖这个实施的,假如宕机,那么会检查log日志,然后根据log日志去看是执行redo还是undo。包括隔离性也是在redo和undo的基础上实施。
假如在innodb中没有主键,那么就会使用唯一索引(假如没有主键的前提下,那么会显示pri(分析时)),假如都没有那么会产生一个隐藏主键(比较慢),索引优化,默认会选择较长的索引达到较高的匹配。
innodb的存储单位是page,一个页是16k(默认,可以更改)
索引是不合做更新和插入的,涉及到查找后排序,适合查找。
2.查看用户使用情况
1)show status like ‘com%’;
com_select :执行select操作的次数,一次查询增加1次
com_insert:执行插入的操作次数,一次插入加1,对批量插入也只加1
com_update:更新的次数
com_delete:删除的次数
2)对于innodb还有以下参数:(status)
innodb_rows_read:select查询返回的行数
innodb_rows_inserted:执行insert操作插入的行数
innodb_rows_updated:执行update操作更新的次数
innodb_rows_deleted:执行delete操作的次数
3)多余提交,回滚(status)
connections:视图连接mysql服务器的次数;
uptime:服务器工作的时间
3.explain

id:大小相同,从上至下运行,id不同,大的先运行。
select_type:simple(简单表,不使用子查询或者连表查询),primary(主查询,外层的查询),union(union中的第二个语句或者后面的语句),subquery(子查询中的第一个select)等,
table:输出结果集的表
type:常见如下:all(全表,不带索引), index(全表,带索引), range(局部范围,带索引,> ,<等) ref(非唯一索引,匹配单个值的结果可以是多行),eq_ref(唯一索引,对应唯一的结果),const(单表通过索引一次就找到结果了,如将主键至于where且用等于号),systrem(单表只有一行的查询),依次变好;
rows:预计扫描的行数;
key_len:这里指的是最大可能使用的索引长度,不是实际的索引长度,是通过表计算得出的,不是通过检索出的结果;
possible_keys:可能使用到的索引;
key:实际用到的索引;
ref:表示之前的表在key列记录的索引中查找值所用的列或常量
extra:unsing index 使用了覆盖索引,避免访问数据行,效率比较好,如果同时出现了where,表明索引被使用来执行索引键值的查找,如果没有出现use where,表名索引用来读取数据而非执行查找动作,use filesort :表名mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序排序,mysql无法利用所以完成的拍讯称为文件排序;use temporary:使用了临时表保存中间结果,mysql在查询排序时使用临时表,常见于排序order by和分组查询 group by 后面;
filtered:表示针对表里符合某个条件的记录数的一个悲观的百分比
partitions:版本5.7以前,该项是explain partitions显示的选项,5.7以后成为了默认选项。该列显示的为分区表命中的分区情况。非分区表该字段为空(null)。
备注:
order by 比较特殊
当query总和小于max_length_for_sort_data,且排序字段不是text/blob类型时,会用改进后的算法—单路排序,否则是老算法,多路排序,不能超出sort_buffer_size的容量,超出之后会创建临时表进行合并排序。
limit
limit的优化,先取值再排序//5.6, order by id limit 10000,10这样相当于全表扫描,可以使用where id>10000 order by id limit 10;来优化 ;
having与where
少用having,尽量用where会更好;
explain update
支持explain update //5.6
join与子查询
在生产环境中尽量少使用子查询,用join 替代可能会好一些
4.小表驱动大表
尽量使用小表驱动大表,少建立连接
原则:当A表大于B表时,使用in优于exists
select * from A where id in (select id form B)
当A表小于B表时,使用exists优于in
select * from A where exists(select 1 from B whereB.id=A.id);//对应exists,select *也可以是 select1 或者select ‘x’,也可以用join替代
5.profile
profiling 默认情况下处于关闭状态 ,并保存最近的15条记录 show variables like ‘profiling’;开始设置为on。
show profiles;//可以查看出哪条sql慢;

show profile cpu ,block io for query 3;//返回第3条sql的cpu ,block,io的信息;一般而言我们只关心cpu与block io相关的信息
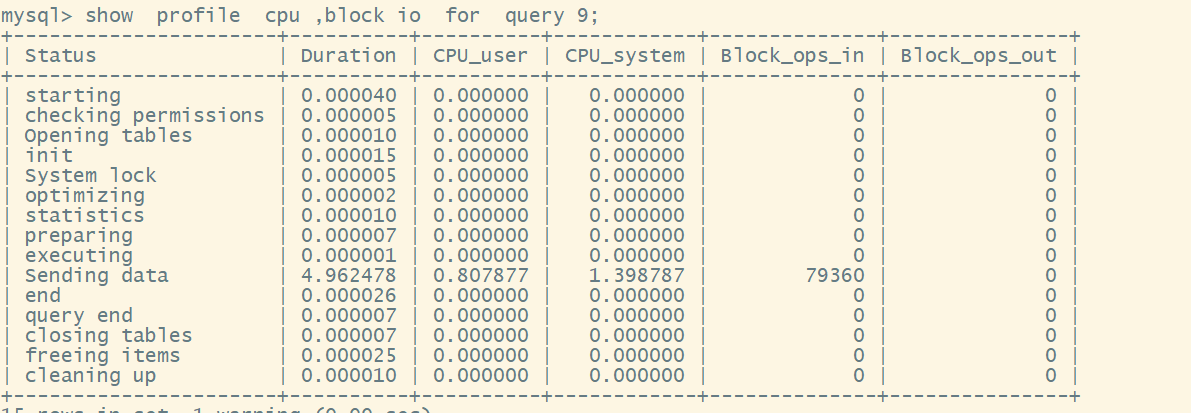
optimize:优化器
sending data:传输数据
参数说明:all 所有的开销信息,block io 显示io的开销信息, cpu显示cpu的开销信息, ipc 显示发送和接受相关的开销信息 ,memory 显示内存相关的开销信息, context switches 上下文切换的开销信息, page faults错误页的开销信息,source 显示source-function,source_file,souce_line相关的信息, swaps 显示交换次数相关的开销信息。
备注:
出现了如下情况是绝对不好的
Creating tmp table;Copying to tmp table on disk;removing tmp table //创建临时表,复制临时表
6.日志
慢日志:
默认情况下mysql没有开启慢日志查询,需要我们手动的开启,如果不是进行调优的话,不建议开启该参数,慢日志支持将日志记录写入文件。
show variables like ‘%slow_query_log%’; //可以查看日志是否开启以及文件的位置 ,可以通过select sleep(n)单位秒获取(测试)

show variables like ‘%long_query_time%’;//设置慢日志时长,大于而非等于。

也可以在my.cnf中配置
mysqldumpslow :日志分析工具
mysqldumpslow -s r -t 10 日志文件地址;//返回记录集最多返回的10条sql记录
mysqldumpslow -s c -t 10 日志文件地址;//得到访问次数最多的10个sql;
参数说明:s表示按照何种方式排序,c访问次数,l锁定时间,r返回记录,t查询时间,al平均锁定时间,ar平均返回记录数,at平均查询时间,t返回前面多少条记录,g匹配正则表达式,对大小写不敏感

备注:当开启了慢日志的时候 ,创建函数假如报错:this function has none of determinis..,是由于开启过了慢日志查询,因为开启了bin_log,所以需要给function指定一个参数,show varias like ‘log_bin_trust_function_creators’是否为1,不是设置为1;
全局日志:
全局查询日志,不要在生成环境开启;
开启全局: general_log=1; 输出文件格式log_output=‘table’;//所写的sql语句会记录到mysql库的general_log表里,也可以设置路径general_log_file=/path/logfile;//记录日志文件的路径
7.锁
表级锁:开销小,不会出现死锁,锁定颗粒度大,发生锁冲突的概率高,并发度低,myisam属于这种类型;
行级锁:开销大,加锁慢,会出现死锁,锁定的颗粒度小,发生锁冲突的概率低,并发高,innodb属于这样类型
页面锁:开销和加锁介于上述两者之间,会出现死锁,发生锁冲突的概率介于上述两者之间,并发度一般,ndb属于这样类型;
lock table 表名 read ;//只读
unlock tables;//释放锁后可写
备注:Innodb只有在在索引的基础上才使用行锁,否则使用表锁,innodb的增删改查属于行锁
备注:死锁:juc中有解释,发生死锁后,innodb一般会自动检测到,他会让一个事务放锁并回退,死锁的无法避免的,只能调整业务来尽量减少死锁的产生,
备注:读己之所写,添加读锁(共享锁,与写互斥),添加写锁(会互斥读和写)
备注:在大量事务的情况下,很多事务无法获取锁,或占用大量的计算机资源,造成严重的性能问题,甚至拖垮数据库,这是需要通过设置合适的所等待阀值 innodb_wait_timeout来解决,一般是100秒即可
查看锁的状态show status like ‘innodb_row_lock%’
innodb_row_lock_current_waits:当前正在等待锁定的数量
innodb_row_lock_time:从系统启动到现在锁定总时间长度
innodb_row_lock_time_avg:每次等待所花平均时间
innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间
nnodb_row_lock_waits:系统启动后到现在总共等待的次数
备注:
更改索引名不会锁表;更改varchar的属性时不会锁表,
Innodb_print_all_deadlocks=1;//将死锁打印到错误日志里面 ,5.6
start transaction read only ;//支持只读事务,5.6
8.压力测试
//产生随机字符串的函数
delimiter $$
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'abcdefghigklmnopqrstuvwxyz';
declare return_str varchar(255) default ' ' ;
declare i int default 0 ;
while i<n do
set return_str=concat(return_str,substr(chars_str,floor(1+rand()*26),1));
set i=i+1; end while ;
return return_str;
end$$
//产生实际数字
create function rand_num() returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*10);
return i ;
end $$
//创建存储过程
delimiter $$
create procedure insert_stu(in max_num int(10))
begin
declare i int default 0;
set autocommit=0;
repeat
set i =i+1;
insert into students(sname,job,birth,sal,classno) values(rand_string(10) , 'study',,now(), 2000, rand_num());
until i=max_num end repeat;
commit;
end$$
delimiter ;
students(ename,job,birth,sal,classno)
9.主从复制
作用:
1)做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2)架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3)读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
原理:
1)数据库有个bin-log二进制文件,记录了所有sql语句。
2)我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3)让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
主
修改mysql配置
[mysqld]
log-bin=本地路径/mysqlbin //开启二进制日志
server-id=1 //设置server-id
重启mysql,创建用于同步的用户账号
mysql> CREATE USER 'repl'@'123.57.44.85' IDENTIFIED BY 'slavepass';//创建用户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'123.57.44.85';//分配权限
mysql>flush privileges; //刷新权限
查看master状态,记录二进制文件名File和位置Position:
SHOW MASTER STATUS;
从
修改mysql配置
[mysqld]
server-id=2 //设置server-id,必须唯一
打开mysql会话,执行同步SQL语句
CHANGE MASTER TO
MASTER_HOST='182.92.172.80',
MASTER_USER='rep1',
MASTER_PASSWORD='slavepass',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=73;
启动slave同步进程
mysql>start slave;
当Slave_IO_Running和Slave_SQL_Running都为YES的时候就表示主从同步设置成功了。接下来就可以进行一些验证了,比如在主master数据库的test数据库的一张表中插入一条数据,在slave的test库的相同数据表中查看是否有新增的数据即可验证主从复制功能是否有效,还可以关闭slave(mysql>stop slave;),然后再修改master,看slave是否也相应修改(停止slave后,master的修改不会同步到slave),就可以完成主从复制功能的验证了。
其他相关参数:
//不同步哪些数据库
binlog-ignore-db = mysql
binlog-ignore-db = test
binlog-ignore-db = information_schema
//只同步哪些数据库,除此之外,其他不同步
binlog-do-db = game
备注:
Bin_log复制默认是异步的,效率较高,但是在主表,或者从表出现问题的时候,可能会有数据没有及时的读取到,虽然出现了半同步复制,但是数据可能发生错误,效率没有异步高//5.5
事务提交后,先到bin_log然后的redo_log里,假如宕机到bin_log中没到redo_log中,主就会造成回滚,从从bin中复制数据,主从数据库就会出现不一致,innodb_support_xa设置为1可以保证一致性;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号