《信息安全系统设计与实现》第十一周学习笔记
《信息安全系统设计与实现》第十一周学习笔记
第十二章 块设备I/O和缓冲区管理
块设备I/O缓冲区
-
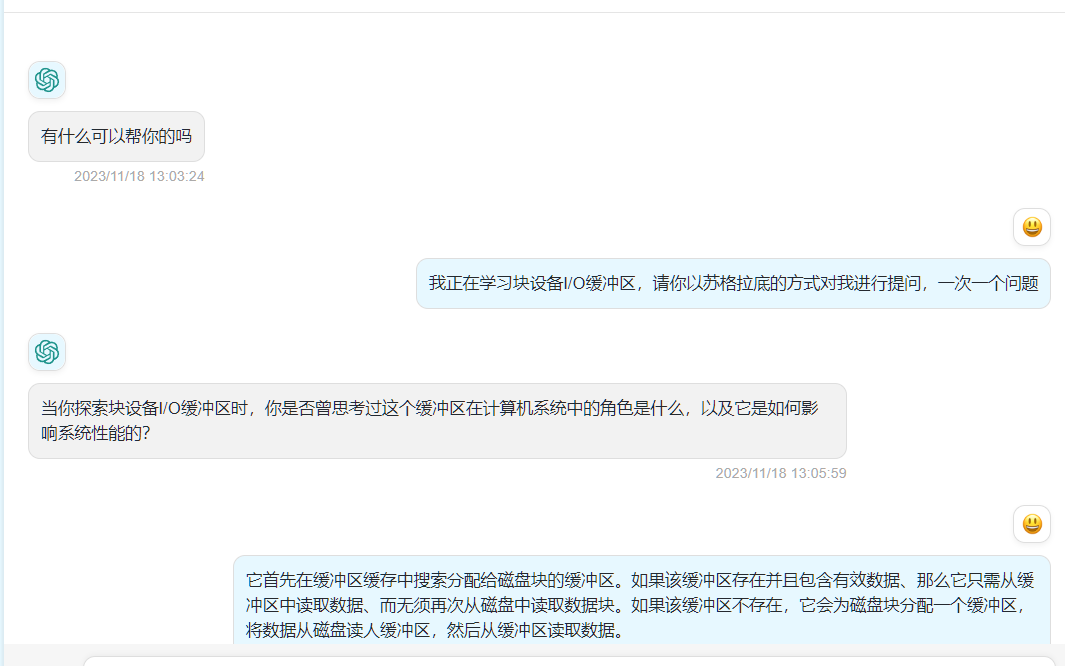
I/O缓冲的基本原理:文件系统使用一系列I/O缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时。它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据、那么它只需从缓冲区中读取数据、而无须再次从磁盘中读取数据块。如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读人缓冲区,然后从缓冲区读取数据。当某个块被读入时、该缓冲区将被保存在缓冲区缓存中,以供任意进程对同一个块的下一次读/写请求使用。同样,当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写入缓冲区,将缓冲区标记为脏,以延迟写入,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写请求,而不会引起实际磁盘I/O。脏缓冲区只有在被重新分配到不同的块时才会写入磁盘。
Unix I/O缓冲区管理算法
- I/O缓冲区:内核中的一系列NBUF 缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
-
typdef struct buf[ struct buf*next__free;// freelist pointer struct buf *next__dev;// dev_list pointer int dev.,blk; // assigmed disk block;int opcode; // READ|wRITE int dirty; // buffer data modified int async; // ASYNC write flag int valid; //buffer data valid int buay; // buffer is in use int wanted; // some process needs this buffer struct semaphore lock=1; / // buffer locking semaphore; value=1 struct semaphore iodone=0;// for process to wait for I/0 completion;// block data area char buf[BLKSIZE];) } BUFFER; BUFFER buf[NBUF],*freelist;// NBUF buffers and free buffer list
-
- 设备表
-
struct devtab{ u16 dev; // major device number // device buffer list BUFFER *dev_list;BUFFER*io_queue // device I/0 queue ) devtab[NDEV];
-
- Unix getblk/brelse算法
-
BUFFER *getblk(dev,blk){ while(1){ search dev_list for a bp=(dev,blk); if (bp in dev_lst) if(bp BUSY) set bp WANTED flag; sleep(bp); continue; } take bp put of freelist; mark bp BUSY; return bp; }
-
- 缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和I/O队列均为空。
- 缓冲区列表:当缓冲区分配给(dev, blk)时,它会被插入设备表的dev_list中。如果缓冲区当前正在使用,则会将其标记为BUSY(繁忙)并从空闲列表中删除。繁忙缓冲区也可能会在设备表的I/O队列中。由于一个缓冲区不能同时处于空闲状态和繁忙状态,所以可通过使用相同的next_free指针来维护设备I/O队列。当缓冲区不再繁忙时,它会被释放回空闲列表,但仍保留在dev_list中,以便可能重用。只有在重新分配时,缓冲区才可能从一个dev_list更改到另一个dev_list中。
- Unix算法的具体说明:
- 数据的一致性
- 缓存效果
- 临界区
- Unix算法的缺点:
- 效率低下
- 缓存效果不可预知
- 可能会出现饥饿
- 该算法使用只适用于单处理器系统的休眠/唤醒操作
新I/O缓冲区管理算法
- 信号量的主要优点
- 计数信号量可用来表示可用资源的数量,例如:空闲缓冲区的数量
- 当多个进程等待一个资源时,信号量上的V操作只会释放一个等待进程,该进程不必重试,因为它保证拥有资源
- 使用计数信号量上的 P/V 来设计满足以下要求的新的缓冲区管理算法:
- 保证数据一致性
- 良好的缓存效果
- 高效率:没有重试循环,没有不必要的进程“唤醒”
- 无死锁和饥饿
实践
perror()实践
setvbuf()函数实践
苏格拉底挑战
遇到的问题
问题
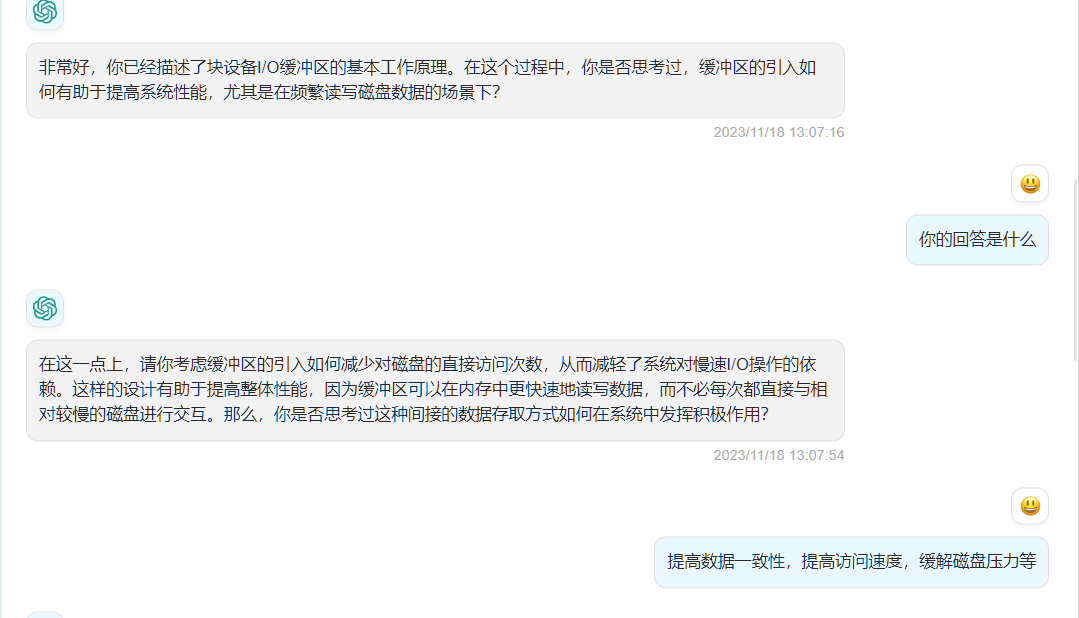
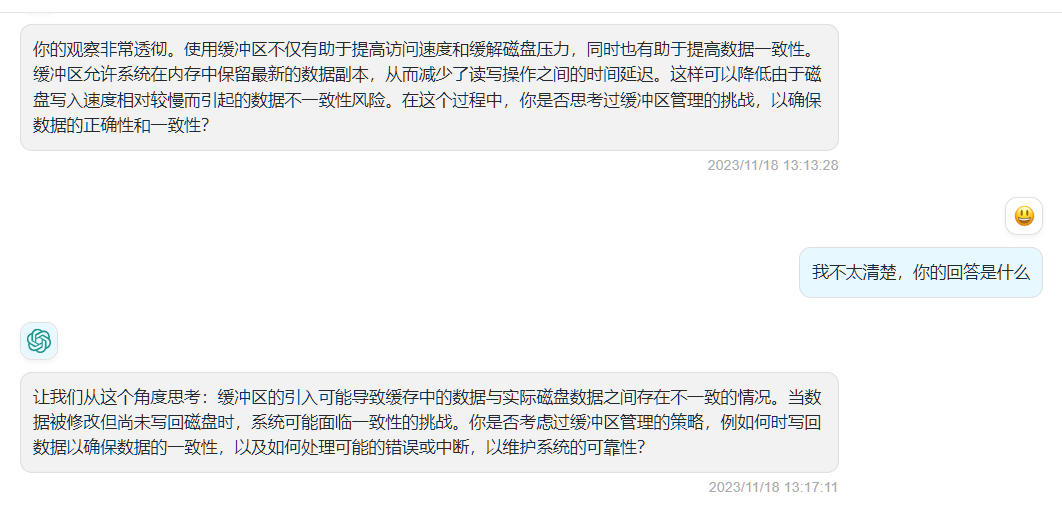
- 缓冲区的引入可能导致缓存中的数据与实际磁盘数据之间存在不一致的情况。当数据被修改但尚未写回磁盘时,系统可能面临一致性的挑战。考虑缓冲区管理的策略,例如何时写回数据以确保数据的一致性,以及如何处理可能的错误或中断,以维护系统的可靠性?
解决
- 在缓冲区管理中,一个重要的考虑因素是缓冲区的写回策略。系统需要决定何时将修改过的数据写回磁盘,以确保数据的一致性。常见的写回策略包括基于LRU(最近最少使用)的策略,或者根据一定的时间间隔进行写回。此外,一些系统可能使用写通知(write-through)策略,即每次对缓冲区的写入都立即同步到磁盘,以保持数据的强一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号