

认识Redis、redis安装、常用命令
什么是redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助
在redis之前,memcached是主流的key-value数据库,虽然redis和memacahed都是将数据缓存在内存中,但是redis可以周期性地将数据写入磁盘文件,并实现主从同步
redis的优缺点
优点:
- 灵活的数据模型,结构比后者更丰富,传统关系型数据库都是结构化的表,nosql可以是列式存储、key-value和文档存储;
- 更易扩展,像nosql数据库分分钟就可以添加一台新的服务器;
- 高可用,查询效率高,传统关系型数据库受限于磁盘io,所以在高并发的情况下,压力倍增,而像redis这种nosql每秒支持10w次读写;
- nosql成本也比较低,相比较Oracle这种企业级授权费用是低了不少
缺点:
- 不支持sql这样的工业标准查询,所以学习成本就比较高;
- 大多都是初创产品,不够成熟,和传统数据库几十年的完善不可同日而语;
- 大多数nosql都不支持事务(redis支持,MongoDB不支持);
关于nosql
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
nosql数据库的分类(键值、列存储、文档型、图形)
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph.
NoSQL数据库的四大分类表格分析
|
分类 |
Examples举例 |
典型应用场景 |
数据模型 |
优点 |
缺点 |
|
键值(key-value) |
Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB |
内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 |
Key 指向 Value 的键值对,通常用hash table来实现 |
查找速度快 |
数据无结构化,通常只被当作字符串或者二进制数据 |
|
列存储数据库 |
Cassandra, HBase, Riak |
分布式的文件系统 |
以列簇式存储,将同一列数据存在一起 |
查找速度快,可扩展性强,更容易进行分布式扩展 |
功能相对局限 |
|
文档型数据库 |
CouchDB, MongoDb |
Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) |
Key-Value对应的键值对,Value为结构化数据 |
数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 |
查询性能不高,而且缺乏统一的查询语法。 |
|
图形(Graph)数据库 |
Neo4J, InfoGrid, Infinite Graph |
社交网络,推荐系统等。专注于构建关系图谱 |
图结构 |
利用图结构相关算法。比如最短路径寻址,N度关系查找等 |
很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
nosql应用场景
1. 数据模型比较简单;
2. 需要灵活性更强的IT系统;
3. 对数据库性能要求较高;
4. 不需要高度的数据一致性;
5. 对于给定key,比较容易映射复杂值的环境
redis应用场景
redis广泛用于数据缓存如排行榜等实时更新信息、消息队列、解决分布式锁的问题(数据库锁,缓存锁,zookeeper锁)、排行列表等诸多场景
- 分布式开发中解决服务器集群共享数据的访问
- 提供分布式锁的解决方案(数据库锁、zookeeper锁、缓存数据库锁)
a) 数据库锁:悲观锁(for update)、乐观锁
乐观锁的实现,表中存在版本字段,如:
Emp表:empId、empName、salary、version
对表执行修改前先查询出版本号
select version from emp where empId=100
//实现一系列的数据持久化操作
提交数据时根据版本号辨识数据是否被更改
受影响行数=update emp set salary=xx where empId=100 and version=之前查出的版本号
根据受影响行数判断是否执行成功,如果执行成功则修改版本号
3.实现高效的数据读写(用作缓存服务器使用)
redis的安装
- 使用rz命令将redis压缩包上传至linux
- 使用tar –zxvf命令对其进行解压
- 由于解压后的redis需要编译源码才能执行安装,而编译需要安装gcc-c++编译器,因此需要使用yum –y install gcc-c++命令安装编译器
- 进入redis的解压目录,使用make命令对其进行编译
- 编译完成后使用make install命令进行安装,安装完成后可以在/usr/local/bin目录中找到redis的执行文件

redis的运行
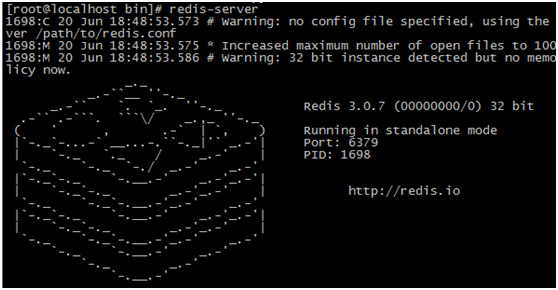
前台模式运行(服务器专门运行Redis时启用前台模式)
该模式下linux无法执行其他操作,如果当前linux为redis主服务器时可以采取该方式
使用redis-server命令启动redis
后台模式运行
后台模式下redis的启用不影响linux系统的使用
使用步骤:
- 修改redis解压目录下的redis.conf文件

将daemonize no修改为daemonize yes
- 使用命令redis-server redis.conf启动redis服务
- 可以通过ps –ef|grep redis查看当前redis进程及占用端口号
启动多个redis服务(复制redis.conf文件,修改端口号,就可启动多个Redis)
多个redis启动无需安装多个数据库,只需要准备多个redis.conf文件,并修改启动端口即可
使用步骤:
- mkdir创建conf文件夹
- cp复制redis.conf至conf文件夹中,并更名为redis2.conf
- mv命令移动原redis.conf至conf文件夹中,并更名为redis1.conf
- 修改redis2.conf文件,修改port端口号为6380
5.进入/tool/redis/conf目录,使用redis-server redis1.conf启动第一个服务
6.使用redis-server redis2.conf启动第二个服务
7.使用ps –ef|grep redis查看进程
停止redis服务
方法一:kill -9 redis进程PID
方法二:或者使用./redis-cli -p 端口号 shutdown关闭当前服务
启动redis客户端访问服务器
使用redis-cli –p 端口号 进入redis(使用redis-cli –h 地址 –p 端口号 进入redis)
使用exit退出
redis-cli --raw 用于解决redis的中文unicode编码问题
redis的删除
将usr/local/bin/目录下的redis文件删除即可
rm –rf /usr/local/bin/redis*
redis的常用命令
set 键 值:将数据以键值对的方式写入redis
get 键:根据键获取值
select 数据库索引:一个redis实例中包含了16个数据库,对应索引0-15,默认使用索引为0的数据库,select命名用于选择某个指定索引号的数据库
flushdb:将当前数据库中的所有数据清除
flushall:将所有数据库中的数据清除
del 键:根据键删除对应数据
keys *:查看当前数据库中的所有键
exists 键:返回0/1 判断是否存在该键的数据
expire 键 秒数:设置数据在内存中的保存时间,超时将自动删除
ttl 键:查看数据的保存时间
rename 键 新键名:对数据键进行重命名
type 键:查看该数据的类型
dbsize:查看该数据库中的数据记录量
redis中存储的数据类型
redis有着丰富的类型支持数据存储,包含了string、hash、list、set、sorted set(zset)这5种数据类型
string类型
这是redis中的基本key-value形式,其常用命令主要有以下:
set 键 值:将键值对写入数据库
get 键:获取对应的键值数据
mset 键 值 键 值……:批量写入多个键值数据
mget 键 键 键…..:批量获取多个键值数据
incr 键:将对应值递增1
incrby 键 递增值:以指定值进行递增
decr 键:将对应值递减1
append 键 追加的值:在指定数据的末尾添加值
strlen 键:获取值得字符长度
list类型
list是有序列表类型,可以在列表的两头添加重复的数据,内部使用双向链表实现,因此越接近两端的数据访问速度就越快,其常用命令有:
lpush 键 值:向列表的左端添加数据
rpush 键 值:向列表的右端添加数据
lrange 键 起始索引 结束索引:查看指定索引区间内的数据,-1表示最后一个元素,因此0 -1表示查询该列表的所有元素
lpop[rpop] 键:从列表的左边或右边弹出数据,被弹出的数据将从列表中删除
llen 键:获取列表的元素数量
lrem 键 删除数量(count) 值:根据指定数量删除对应的值
注意点:
count数量为正数时从左往右进行删除
count数量为负数时从右往左进行删除
count为0时删除所有对应的值
lindex 键 索引值:根据索引获取值
lset 键 索引 新值:根据指定索引替换新值
ltrim 键 起始索引 结束索引:根据起始索引和结束索引对列表进行截取
linsert 键 before|after 原值 新值:在原值的前(或者后)的地方插入新值
rpoplpush 原列表键 新列表键:将原列表的最后一个元素弹出并在新列表的顶端写入
hash类型
hash散列表类型适合用于存储对象,字段值只能为字符类型,其主要命令有以下:
hset 键 字段名 字段值:将数据写入数据库
hget 键 字段名:获取该字段对应的值
hmset 键 字段名 字段值 字段名 字段值….:批量写入数据
hmget 键 字段名 字段名….:批量获取字段数据
hgetall 键:获取该键下所有字段数据
hkeys 键:获取该键下所有字段名称
hvals 键:获取该键下所有字段值
hexists 键 字段名:判断该键下是否存在对应指定的字段数据
hlen 键:获取键对应的数据数量
hdel 键 字段名:将该键下对应的字段删除
hincrby 键 字段名 增长值:根据增长值对指定字段进行递增
set类型
set集合类型使用空散列表实现,是string类型的无序集合,不能存储重复的数据,但能提供多个集合的交集、并集、差集的运算,其常用命令有:
sadd 键 值 值 值:添加集合数据
smembers 键:获取集合中的所有元素
srem 键 值:将集合中指定值得元素删除
scard 键:获取集合中的元素数量
spop 键:随机移除一个元素
sdiff 键1 键2 键3:差集运算,返回第一个集合中存在,其他集合中没有的元素
sinter 键1 键2 键3:交集运算,获取多个集合共有的元素
sunion 键1 键2 键3:并集运算,获取多个集合合并后的结果并排除重复的结果
sorted set类型(zset)
和set类型一样是string值的集合,不同的是每个元素会关联一个double的分数,redis通过分数为集合中的每个元素进行排序,其常用命令有:
zadd 键 分数 值 分数 值:添加元素,每个元素需要设定一个用于排序的分数值
zrange 键 起始索引 结束索引[withscores]:升序查看索引区间内的所有元素
zcard 键:获取集合中的元素数量
zcount 键 min max:获取在指定分数范围内的元素数量
zrank 键 值:查看该元素在集合中的顺序排名索引
zincrby 键 增长值 值:根据增长值对值进行递增
zrevrange 键 起始索引 结束索引[withscores]:降序查看索引区间内的所有元素
zrem 键 值:删除指定元素
zrangebyscore 键 min max[withscores]:查看分数区间内的元素
zrangebyscore zset 10 50 表示查询分数在>=10并且<=50范围的元素
zrangebyscore zset (10 50 表示查询分数在>10并且<=50范围内的元素
zrangebyscore zset (10 (50 表示查询分数在>10并且<50范围内的元素
zremrangebyrank 键 起始索引 结束索引:删除指定排名索引内的元素
zremrangebyscore 键 min max:删除指定分数范围内的元素


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)