

数据库(三)分组查询,having条件,语句执行顺序,内连接,外连接,子查询
分组查询:
select 列名 from 表名 group by 列
在分组查询中使用聚合查询,会对每一个组别单独执行一次聚合操作
在执行聚合查询或者是分组查询中,只能查询被分组的列或聚合列
同时对多个列进行分组:
select 列名 from 表名 group by 列,列
having条件筛选:
select 列名 from 表名 group by 列 having 条件
having和where一样表示条件的筛选过滤,但是having只能和group结合使用
having和where条件的相同点和区别点:
1.都表示条件的过滤
2.having只能写在group后,where可以出现任何情况
3.先执行where再执行group by最后执行having
4.having中可以使用聚合函数,where不能使用
语句的执行顺序:
select 列 from 表 where条件 group by 列 having 条件 order by 列
1.from
2.where
3.group by
4.having条件
5.select
6.order by
例子数据

-- 创建学生表 create table student ( stuId int primary key auto_increment, stuName varchar(20) not null, email varchar(50) ); -- 创建课程表 create table course ( courseId int primary key auto_increment, courseName varchar(20) not null ); -- 创建成绩表 create table score ( stuId int not null, courseId int not null, score float ); -- 插入学生数据 insert into student values(null,"tom","tom@geekhome.com"); insert into student values(null,"jack","jack@geekhome.com"); insert into student values(null,"tony","tony@geekhome.com"); insert into student values(null,"rose","rose@geekhome.com"); -- 添加课程数据 insert into course values(null,"Java"); insert into course values(null,"MySQL"); insert into course values(null,"JDBC"); -- 添加成绩信息 insert into score values(1,1,45); insert into score values(1,1,58); insert into score values(1,1,60); insert into score values(1,2,78); insert into score values(1,3,82); insert into score values(2,1,90); insert into score values(2,2,92); insert into score values(2,3,78); insert into score values(3,1,53); insert into score values(3,2,45); insert into score values(3,3,75);
-- 查看班级的平均分
select avg(score) as avg_score from score;
-- 对课程进行分组查询
-- 在分组查询,只能对被分组的列进行查看
select courseId from score group by courseId;
-- 在分组查询中使用聚合查询,会对每一个组别单独执行一次聚合操作
-- 在执行聚合查询或者是分组查询中,只能查询被分组的列或聚合列
-- 查看每一门课程的平均分
select courseId,avg(score) from score group by courseId;
-- 查询每个部门总薪资和平均薪资
select department_id,sum(salary) as sum_salary,avg(salary) as avg_salary from emp group by department_id;
-- 查询每个岗位的人数
select job_id,count(*) as empCount from emp group by job_id;
-- 查询每个部门中最高的薪资和最低的薪资
select department_id,max(salary) as maxSalary,min(salary) as minSalary from emp group by department_id;
-- 每个部门中入职时间是晚于2010年的员工总数
select department_id,count(*) as empCount from emp where hire_date>='2010-1-1' group by department_id;
-- 查询参加单科累计考试次数达到5次以上的所有科目的平均成绩
-- where条件中不允许进行聚合操作
-- having表示在group by分组后执行的条件筛选,可以使用聚合函数
select courseId,avg(score) from score group by courseId having count(*)>5
-- 查询参加过补考的同学编号
-- 思路:每个学生考的每门课程超过1次以上的,就是参加过补考的
-- 同时对多个列进行分组
-- 要查的是每个学生参加过的每一门考试超过一次 select stuId from score group by stuid,courseId having count(*)>1;
-- 以下两个都不是要查询的结果 --查询的是每个学生考试超过一次,即这个学生参加过的所有课程 select stuId from score group by stuid having count(*)>1; -- 查询的是所有学生参加的课程考试超过一次的,即所有参加过这门考试的数据 select stuId from score group by courseId having count(*)>1;
数据高级查询:
如果希望查询得到学生的姓名课程科目和成绩该怎么办?
姓名来自于学生表,课程来自于课程表,而成绩又来自于成绩表,所以必须从三张表中获取各个数据
表连接查询:多表查询时,如果两张表中存在同名的字段,则必须要使用表名.字段名 加以区分(不同名不用加)
(多表查询时只查询单个表中的数据用子查询,需要查找多表中的数据需要用内连接和外连接)
1.inner join:
内连接查询 获取两表中共同部分的数据
语句:select 列 from 表A inner join 表B on 表A.列=表B.列 [where 条件]
2.left join:
左外连接 获取左表中的所有数据和右表中匹配的数据
左连接以左表为基表去连接右边的数据表,查询出左表的所有数据以及右边和左表关联的数据
3.right join:
右外连接 获取右表中的所有数据和左表中匹配的数据
(左连接和右连接只是基表不一样,表的排放顺序不一样,其余没有任何区别,会一种就行)
inner join ··· on 的执行机制:查找学生的姓名和成绩,通过stuid进行连接
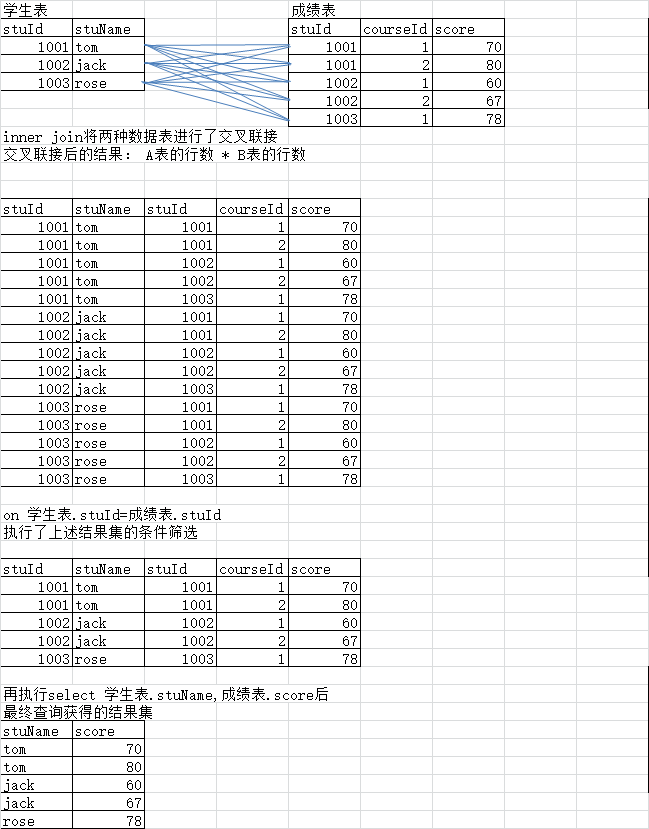
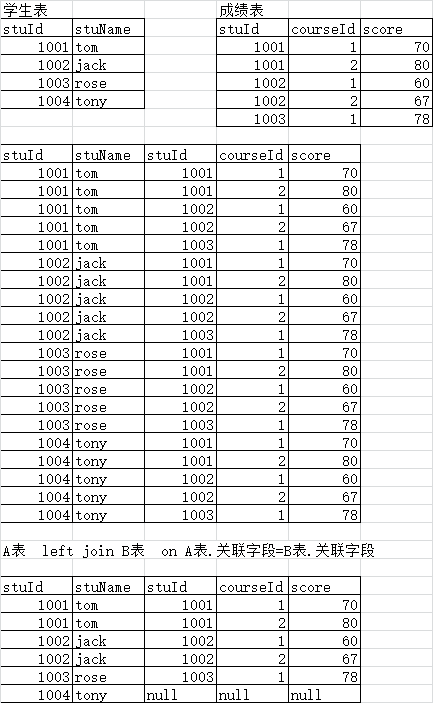
left join 左连接的执行机制:找到没有参加考试的学生(最后只要查找右表不为null的列值为null的情况)
-- inner join 内联接查询多表的数据
-- 查询所有学生的姓名和课程编号和对应的成绩
方法一:inner join ··· on
-- 多表查询时,如果两张表中存在同名的字段,则必须要使用表名.字段名 加以区分
select stu.stuName,s.courseId,s.score from student as stu//表一 inner join score as s//表二 on stu.stuId=s.stuId//两张表的连接条件;
方法二:from a表,b表 where 关联的条件
-- 使用from A表,B表也可以实现多表的关联查询(不写where的时候可以查看交叉的具体情况)
select stuName,courseId,score from student as stu,score as s where stu.stuId=s.stuId;
-- 查询所有及格的学生的编号、课程名称以及成绩
-- 课程表和成绩表通过courseID进行连接
select stuId,courseName,score from course as c inner join score as s on c.courseId=s.courseId where score>=60;
-- 查询所有学生的姓名,课程名称、成绩
-- inner join 每次只能连接两个表,连接以后生成一个新的表,然后再去连接另外的表
--多表连接是有顺序的,要两个表键有直接联系的才能直接连接(学生表——成绩表——课程表)
select stuName,courseName,score from student as stu inner join score as s on stu.stuId=s.stuId -- 学生表和成绩表连接 inner join course as c on s.courseId=c.courseId;-- 成绩表和成绩表连接
课堂练习
-- 查询员工的姓名、薪资和所在部门的名称 select first_name,last_name,salary,department_name from emp inner join dep on emp.department_id=dep.department_id; -- 查询部门编号是50的部门名称和该部门每个员工的姓名、入职时间 select first_name,last_name,hire_date from emp inner join dep on emp.department_id=dep.department_id where emp.department_id=50; -- 查询发帖人的姓名、主贴的名称、回帖人姓名、回帖的内容
--inner join ··· on的方法 select u.uname,t.ttopic,r.rcontents,u2.uname from
bbsusers as u inner join bbstopic as t on u.userid=t.tuid-- 用户表和主贴表的关联inner join bbsreply as r on t.tid=r.rtid-- 回帖表和主贴表的关联inner join bbsusers as u2 on u2.userid=r.ruid; -- 用户表和回帖表的关联
-- from A表,B表 查询的方法 select u1.uname,t.ttopic,r.rcontents,u2.uname from
bbsusers as u1,bbsusers as u2,bbstopic as t,bbsreply as r -- from 的四张表where u1.userid=t.tuid and u2.userid=r.ruid and t.tid=r.rtid; -- 四张表的三个关联关系
左连接:
使用join left ··· on查询没有参加考试的学员姓名
-- 使用left join左连接实现 select * from student as stu left join score as s on stu.stuId=s.stuId where s.stuId is null;
右连接:
使用right join ··· on 查询没有参加考试的学生
-- 使用right join右联接 select * from score as s right join student as stu on stu.stuId=s.stuId where s.stuId is null;
子查询:(多表查询时只查询单个表中的数据用子查询,需要查找多表中的数据需要用内连接和外连接)
如果想查询年龄比TOM的年龄大的学生信息怎么办?(要先查询tom的年龄,在进行查询比他年龄大的,要两次查询)
使用子查询解决!
子查询:即查询语句中使用嵌套的查询,在SQL语句中可以将查询的结果作为呈现数据或者将结果作为条件再次进行条件筛选
使用子查询的注意事项:
select 列名 from 表名 where 列名=(select 列名 from 表名)
1.当使用关系运算符对子查询结果进行处理时,子查询的结果必须为单行单列的值,只有单行单列的值才能用 > < =进行比较
2.如果是多行数据,则可以使用 in 进行比较
-- 查询年龄比tom大的学生信息
-- 使用子查询,可以将查到的结果集继续进行查询处理
select * from student where age>(select age from student where stuname='tom');
-- 可以通过子查询作为结果集的虚拟表,继续完成查询,起别名为n
select stuName,age from (select * from student) as n;
-- 查询所有及格的学生姓名:groupby stuid是为了不重复
select stuid,stuname from student where stuid in (select stuid from score where score<60 group by stuid);
-- 查询没有参加考试的学生姓名(对成绩表中的学生编号进行分组,然后查找学生表中学生学号不在之前的分组中的学生)
select stuname from student where stuid not in(select stuid from score group by stuid);
-- 查询java课程的平均分(查找课程表中的Java对应的courseid ,然后对成绩表中的courseid和Java对应的courseID相同的所有成绩,进行平均分计算)
select avg(score) from score where courseId=(select courseId from course where courseName='Java');
-- 查询在所在地(location)在美国的所有部门的员工姓名(emp)和部门名称(dep)
方法一:用inner join 但是交叉的数据量较大
select first_name,last_name,department_name from emp inner join dep on emp.department_id=dep.department_id inner join location as l on l.location_id=dep.location_id where country_id='US';
方法二:
-- 先查询出所在是美国的部门编号,
-- 然后根据部门编号查询这些部门的员工姓名和部门编号
-- 最后将查询的结果集inner join部门表
-- 先查询出所在是美国的部门编号, select location_id from location where country_id='US' -- 然后根据部门编号查询这些部门的部门编号 select department_id from dep where location_id in (select location_id from location where country_id='US') -- 然后根据部门编号查询这些部门的员工姓名 select first_name,last_name,department_id from emp where department_id in (select department_id from dep where location_id in (select location_id from location where country_id='US')) -- 最后将查询的结果集inner join部门表 select first_name,last_name,department_name from (select first_name,last_name,department_id from emp where department_id in (select department_id from dep where location_id in (select location_id from location where country_id='US'))) n (-- 别名) inner join dep on n.department_id=dep.department_id
或者:
-- 先查询出所在是美国的部门编号
-- 然后根据部门编号查询这些部门的部门名称
--在通过部门编号和emp进行交叉查询
select first_name,last_name,department_name from (select department_id,department_name from dep where location_id in (select location_id from location where country_id='US')) n inner join emp on n.department_id=emp.department_id


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!