1.大数据概述
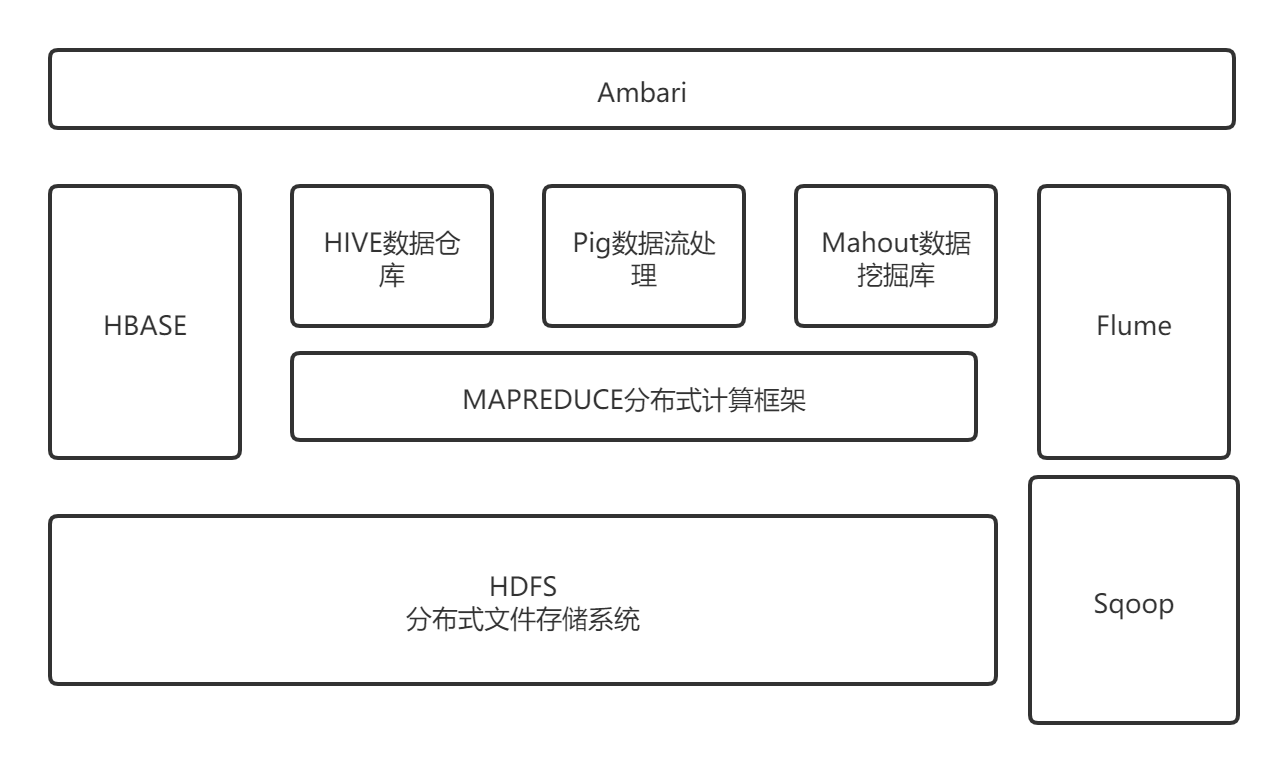
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
2.对比Hadoop与Spark的优缺点。
答:第一,中间数据放在spark内存中,迭代运算效率高,MapReduce中的计算必须登录并存储在硬盘上,这将不可避免地影响整体速度。Spark程序支持分布式并行DAG图计算,减少了迭代过程中的数据量,提高了数据处理效率。(下载延迟)
第二,Spark的容错性高。Spark引入了一个抽象的RDD数据集,即在只读组之间弹性分布的数据集。如果数据集的一部分丢失,可以通过“血统”来重建。
第三,Spark 会比mapreduce更通用。mapreduce 只提供了 Map 和 Reduce 两种数据集操作类型,Spark 提供的则有很多,其中便包括了mapreduce的这两种。
第四,Hadoop中对于数据的计算,一个Job只有一个Map和Reduce阶段,对于复杂的计算,需要使用多次MR,这样涉及到落盘和磁盘IO,效率不高;而在Spark中,一个Job可以包含多个RDD的转换算子,在调度时可以生成多个Stage,实现更复杂的功能;
第五,Hadoop适用于静态数据处理,迭代流数据处理不好;Spark提高了流式和迭代数据处理性能
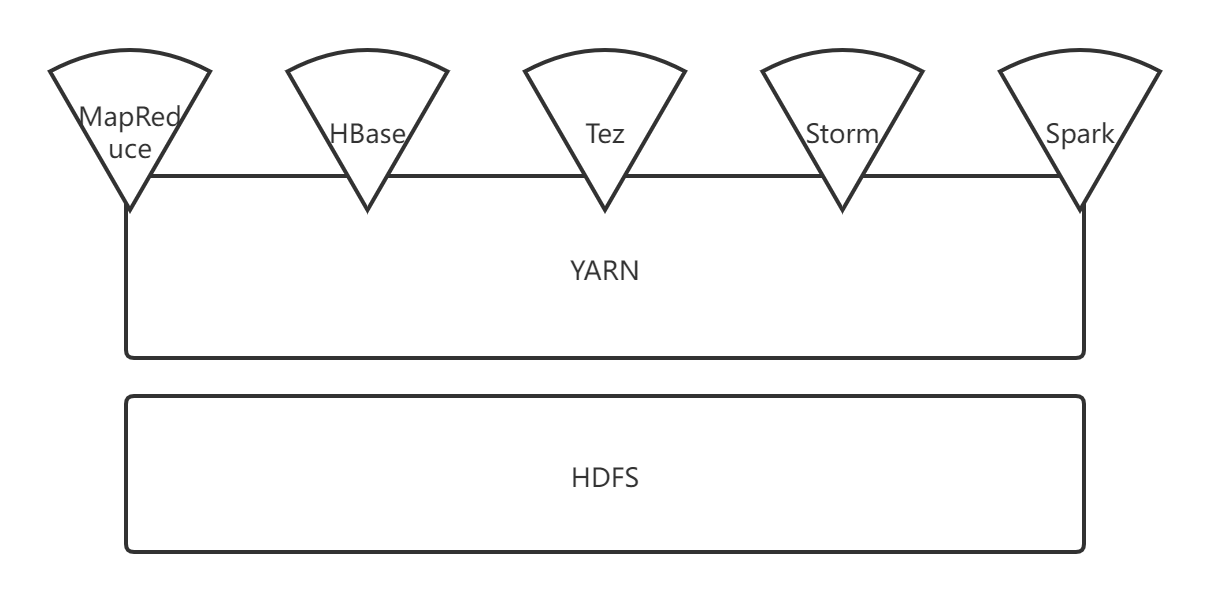
3.如何实现Hadoop与Spark的统一部署?
答:在YARN之上进行统一部署

 浙公网安备 33010602011771号
浙公网安备 33010602011771号