
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024 |
|---|---|
| 这个给作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
| 这个作业的目标 | 论文查重 |
一、github链接:
https://github.com/githdx/3122004570.git
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 18 |
| -Estimate | -估计这个任务需要多少时间 | 15 | 18 |
| Development | 开发 | 450 | 495 |
| -Analysis | -需求分析 (包括学习新技术) | 200 | 240 |
| -Design Spec | -生成设计文档 | 20 | 20 |
| -Design Review | -设计复审 | 15 | 10 |
| -Coding Standard | -代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| -Design | -具体设计 | 60 | 65 |
| -Coding | -具体编码 | 100 | 120 |
| -Code Review | -代码复审 | 30 | 20 |
| -Test | -测试(自我测试,修改代码,提交修改) | 20 | 15 |
| Reporting | 报告 | 40 | 38 |
| -Test Repor | -测试报告 | 15 | 12 |
| -Size Measurement | -计算工作量 | 10 | 8 |
| -Postmortem & Process Improvement Plan | -事后总结, 并提出过程改进计划 | 15 | 18 |
| All | 合计 | 505 | 551 |
三、计算模块接口的设计与实现过程
设计:
CheckMain类:实现类。
- 读取命令行参数。读取第一个路径为原文txt,第二个路径为抄袭txt,第三个路径为答案txt。经过一系列方法后将相似度写入答案txt中。
txtHandle类:处理txt文件
- txtRead方法:文本读取。将txt文本内容读取成字符串。
- txtWrite方法:文本写入。将相似度写入到txt文本内。
Calculation类:获取SimHash
- getSimHash方法:获取字符串的SimHash。传入txt文本内容的字符串,经过一系列方法,输出该文本的SimHash值。
- participle方法:分词。传入txt文本内容的字符串,输出特征词数组
- Hash方法:传入特征词数组,输出对应的hash值
- weightedAndMerged方法:加权、合并。传入文本的hash值,经过加权、合并最后输出权重向量
- dimensionalityReduction方法:降维。传入文本的权重向量,输出文本的SimHash值
- calculateHammingDistance方法:根据两个文本的SimHash计算海明距离
- calculateHammingSimilarity方法:根据海明距离计算论文相似度保留两位小数
流程图:
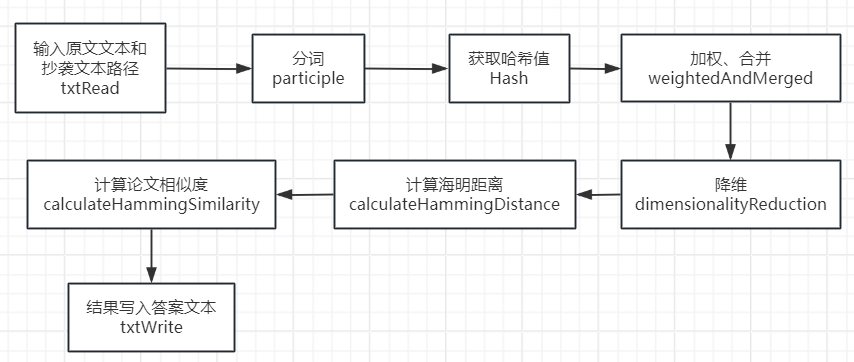
算法关键:
参考:https://zhuanlan.zhihu.com/p/578254728
先通过txtRead读取原文文件和抄袭文件后,再经过分词、hash、加权、合并和降维分别计算两个文本SimHash值,接着根据两个文本的SimHash值计算海明距离,最后再计算出相似度并写入答案文件中
四、计算模块接口部分的性能改进
改进部分:
原加权、合并方法分开写,要经历两次两层for循环
//加权
private static int[][] weighted(List<String> hashList){
int size= hashList.size();
int[][] weightVectorList=new int[size][256];
for(int i=0;i<size;i++) {
String str = hashList.get(i);
for (int j = 0; j < str.length(); j++) {
//权重范围0-10,特征词在数组中位置越靠前权重越大
int weight = 10 - 10 * i / size;
//加权
if (str.charAt(j) == '1') weightVectorList[i][j] = weight;
else weightVectorList[i][j] = -weight;
}
}
return weightVectorList;
}
//合并
public static int[] merged(int[][] list){
int length=list.length;
int[] weightVectorList=new int[length];
int i=0;
System.out.println(list.length);
for(int[] arr:list){
//System.out.println(arr.length);
for(int j=0;j<256;j++){
weightVectorList[i]+=arr[j];
}
i++;
}
return weightVectorList;
}
优化后,加权、合并在一个方法中,只经历一次两层for循环
//加权、合并
private static int[] weightedAndMerged(List<String> hashList){
int size= hashList.size();
//256位的加权向量
int[] weightVectorList=new int[256];
for(int i=0;i<size;i++) {
String str = hashList.get(i);
for (int j = 0; j < str.length(); j++) {
//权重范围0-10,特征词在数组中位置越靠前权重越大
int weight = 10 - 10 * i / size;
//加权并合并
if (str.charAt(j) == '1') weightVectorList[j] += weight;
else weightVectorList[j] -= weight;
}
}
return weightVectorList;
}
性能图

五、计算模块部分单元测试展示
测试在不同的原文文件和抄袭文件下得到的相似度
@Test
public void mainTest(){
String test1= "../../src/resources/orig.txt";
String test2= "../../src/resources/orig_0.8_add.txt";
String test3= "../../src/resources/orig_0.8_del.txt";
String test4= "../../src/resources/orig_0.8_dis_1.txt";
String test5= "../../src/resources/orig_0.8_dis_10.txt";
String test6= "../../src/resources/orig_0.8_dis_15.txt";
String test7= "../../src/resources/test_1.txt";
String test8= "../../src/resources/test_2.txt";
String test9= "../../src/resources/test_3.txt";
String test10= "../../src/resources/test_4.txt";
String ans1="../../src/resources/answer_test.txt";
System.out.println("测试一结果:");
test(test1,test2,ans1);
System.out.println("测试二结果:");
test(test1,test3,ans1);
System.out.println("测试三结果:");
test(test1,test4,ans1);
System.out.println("测试四结果:");
test(test1,test5,ans1);
System.out.println("测试五结果:");
test(test1,test6,ans1);
System.out.println("测试六结果:");
test(test1,test7,ans1);
System.out.println("测试七结果:");
test(test1,test8,ans1);
System.out.println("测试八结果:");
test(test1,test9,ans1);
System.out.println("测试九结果:");
test(test1,test10,ans1);
System.out.println("测试十结果:");
test(test4,test5,ans1);
}
public static void test(String path1,String path2,String path3){
String txt1,txt2;
//文件打开失败,结束
if((txt1=TxtHandle.txtRead(path1))==null||(txt2=TxtHandle.txtRead(path2))==null)return;
//获取txt文本的SimHash值
int[] weightVectorList1,weightVectorList2;
//文本内容过短,结束
if((weightVectorList1=Calculation.getSimHash(txt1))==null||(weightVectorList2=Calculation.getSimHash(txt2))==null)return ;
//计算海明距离
int distance= Calculation.calculateHammingDistance(weightVectorList1,weightVectorList2);
//计算论文相似度
double similarity= Calculation.calculateHammingSimilarity(distance);
System.out.println("论文相似度为:"+similarity+"%");
//将结果写入文件
TxtHandle.txtWrite(path3,similarity);
}
测试结果

测试覆盖率

六、计算模块部分异常处理说明
输入的文本路径数量不对时,输出错误提示

输入的文本路径不存在时,输出错误提示

输入的文本内容过短时,输出错误提示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号