
WEB自动化-验证码处理
WEB自动化的过程中遇到验证码的时候,有以下方法:
1、Debug模式启动浏览器(浏览器复用)(技术)--推荐
2、识别法(技术)--OCR
3、接口法(技术):开发人员提供接口,通过这个接口可以获取到图片验证码,只用于测试环境
4、移除法(非技术):让开发人员在测似乎环境直接去掉验证码
5、暗号法(非技术):万能验证码
6、Cookie跳过验证码(技术)
一、Debug模式启动浏览器(浏览器复用)(技术)--推荐使用方法:
1 Debug模式浏览器配置详解
1.1 浏览器路径问题
1)通常设置方式
找到浏览器的路径,配置到bat文件里头
2)浏览器路径中有空格或者中文或者特殊字符的设置方式
例如:C:\Program Files\Java
先配置浏览器路径到环境变量

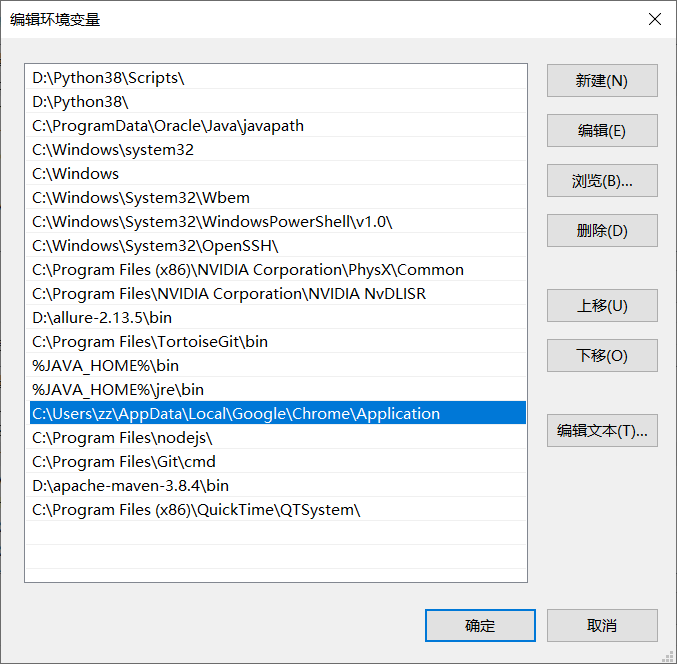
然后在cmd中检查是否可以直接输入chrome.exe来打开浏览器
然后把bat文件中的路径删掉,改成如下:
chrome.exe --remote-debugging-port=9222
记得要重启pycharm,不然会提示chrome.exe 不是内部或外部命令。。。
PS:有同学只有C盘,会有文件无权限读取的情况发生,这个最好是分个D盘出来,不然解
决比较麻烦
1.2 编码问题
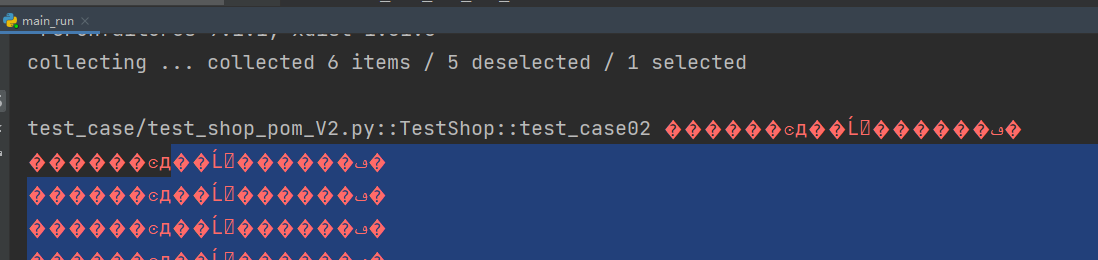
使用bat文件控制台会输出一些乱马上,通过如下方式解决
File > settings > Editor > File Encodings > 将 Project Encoding 设置为 Gbk 即可
PS:其实乱码也没啥影响,改了编码会影响到其他工程的运行,建议不改
1.3 需要进行预登陆
因为我们这种操作,相当于直接用本机的浏览器去访问淘宝,因此预登陆后就可以绕过淘宝
的诸多验证,只需要预登陆一次即可
1.4 以下报错信息不用管,用例可以正常执行
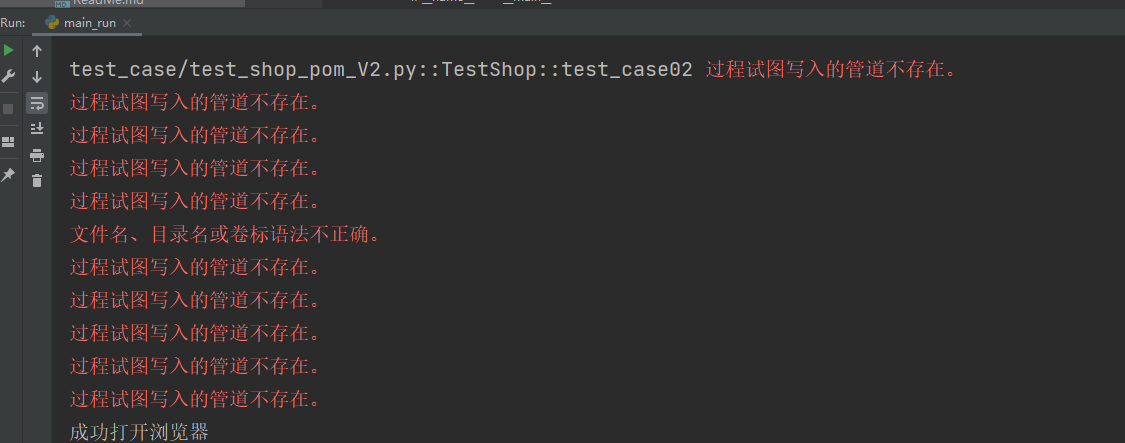
1.5 启动前,要关闭所有的谷歌浏览器
2 浏览器复用
通过debug模式浏览器实现在已打开的浏览器上继续运行自动化脚本调试
操作方式:
第一:注释掉打开浏览器的代码,让他不重新打开浏览器
1# os.popen("d:/chrome.bat")
第二:把已经执行完的步骤注释掉
第三:浏览器复用模式下:如果需要切换窗口,需要特殊处理
1.在页面上,点击回到第一个窗口
2.运行窗口切换代码
三、Cookie跳过验证码
首先获取网站登陆后的cookie,然后通过添加cookie的方式,实现网站登陆的目
的。我们用cook来表示xxxxxx的登录后的cookie。
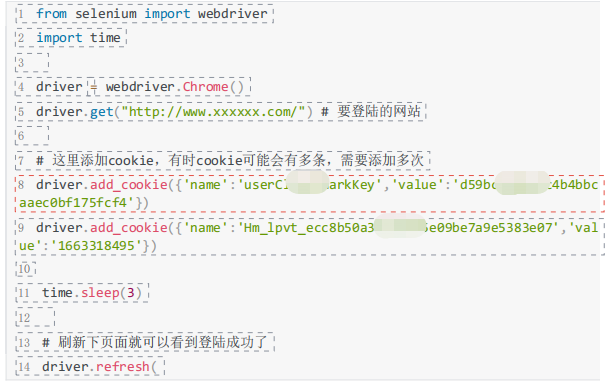
注意:
登录时有勾选下次自动登录的请勾选,浏览器提示是否保存用户密码时请选择确
定,这样获取的cookie成功登陆的机率比较高
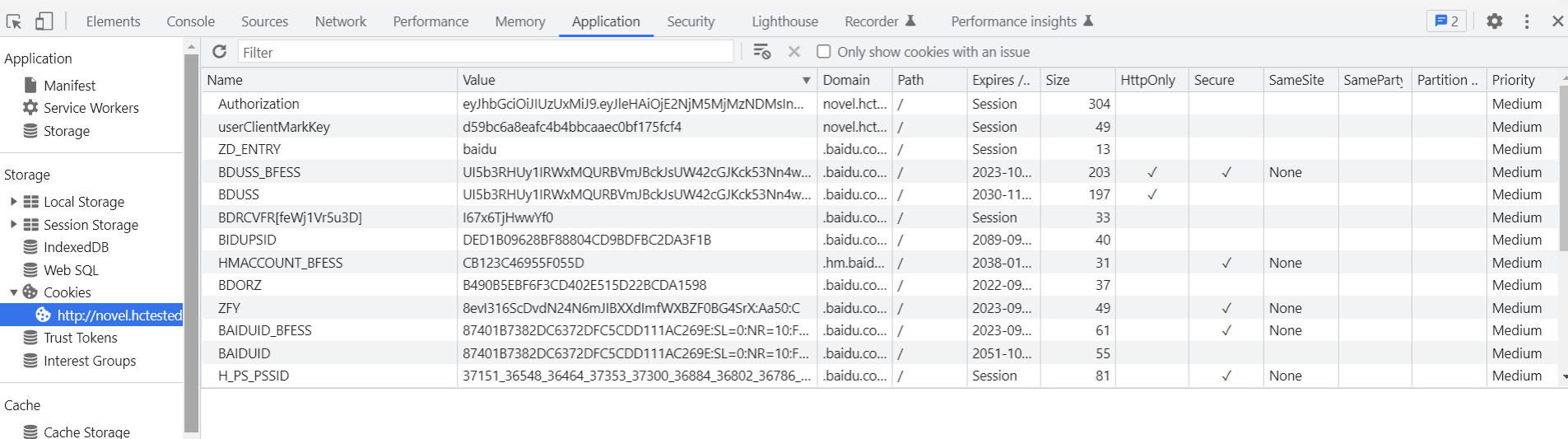
cookie获取方法:
利用开发者工具,编辑修改。F12打开开发者工具--->Application--->cookies,对对应的
值进行查看、编辑、修改
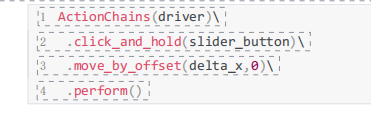
三、JS处理方案(滑动解锁)
滑动解锁问题
使用ActionChains功能,用鼠标按住滑块并移动
练习网站:https://layuion.com/demo/slider.html
四、OpenCV 图像预处理:灰度化和二值化
PS:简单来说,要做图像文本识别,一般会将图片预处理成黑白的
1 图像二值化基本原理:
对灰度图像进行处理,设定阈值,在阈值中的像素值将变为1(白色部
分),阈值为的将变为0(黑色部分)
2 图像二值化处理步骤:

六、OCR图像识别
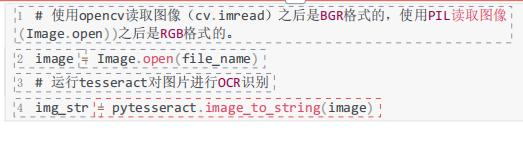
1 OCR原理
(Optical Character Recognition,光学字符识别)技术,将图片、照片上的文字内容,直接转换为文
本。opencv不自带ocr,即使从cv4.4以后的external中包含cv::text识别文字,也需要用户先预装
tesseract。
2 安装
需要安装的包:
(1)CV2
注意:下面这个包,实际安装的是cv2,pycharm自动装是装不了的,必须使用下面命令
pip install opencv_python
2)pytesseract
pip install pytesseract
(3)需要安装一个软件,并配置环境变量:
安装软件tesseract-ocr
软件下载地址,下载最新的,根据操作系统选择:
https://digi.bib.uni-mannheim.de/tesseract/
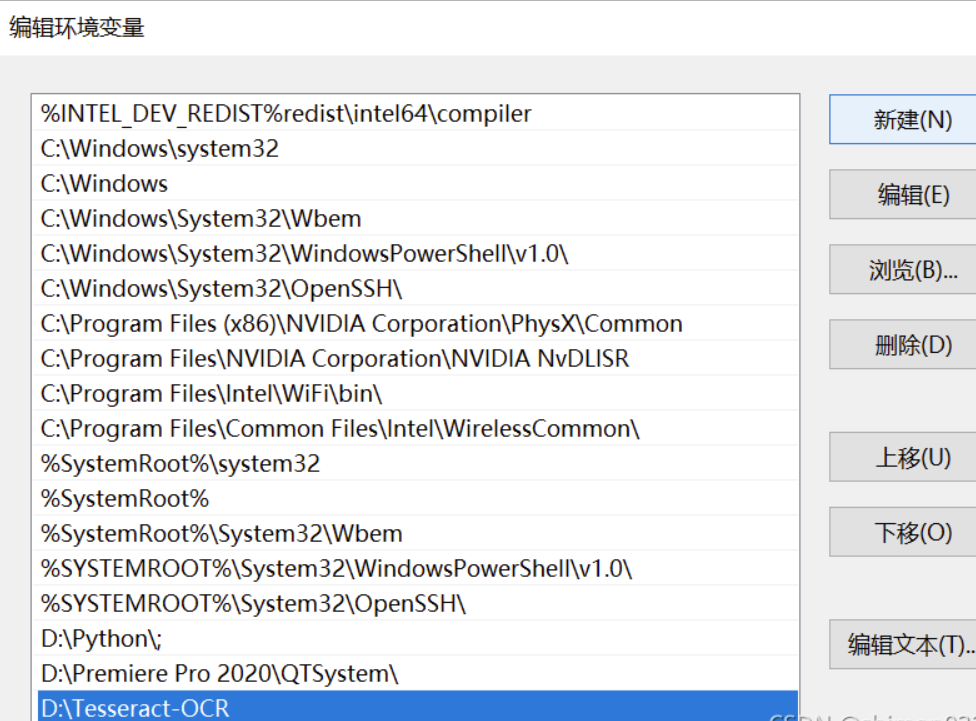
在D盘建立文件夹Tesseract-OCR,于该目录下解压,安装到电脑。
配置环境变量
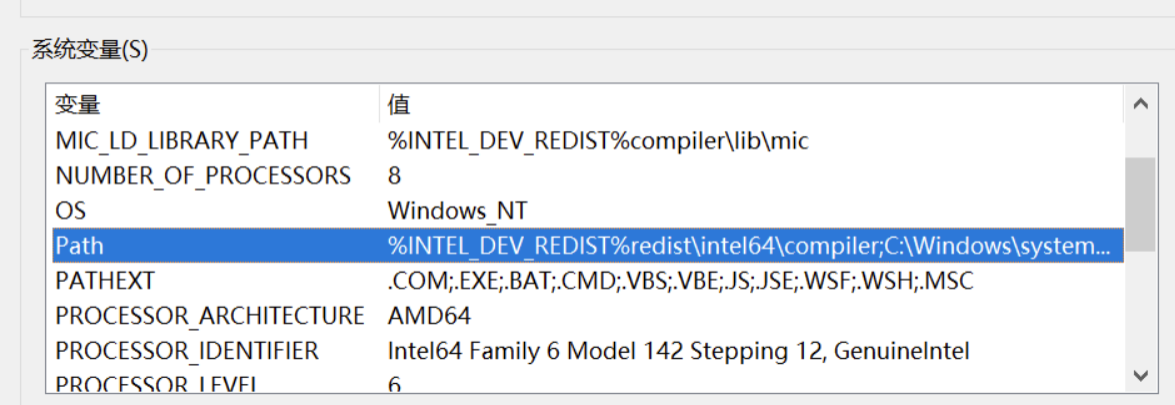
①右键“此电脑”——设置——高级系统设置——环境变量——系统变量---path---编辑
——新建,写入Tesseract文件的路径,配置环境变量——确定保存
可以参考以下代码:

import cv2 as cv import pytesseract from PIL import Image def test(): locator = ("css selector", ".code_pic") file_name = "imgVerify.png" # 定义文件名称用来保存验证码截图 wait.until(ec.visibility_of_element_located(locator)).screenshot(file_name) # 验证码截图后保存 # 对存储的验证码进行均值迁移去噪声,然后二值化处理,最终覆盖源文件,进行存储 image1 = cv.imread(file_name) # 定义用cv2的imread读取文件 image2 = cv.pyrMeanShiftFiltering(image1, 10, 100) # 进行去噪 image3 = cv.cvtColor(image2, cv.COLOR_BGR2GRAY) # 进行灰度图像 ret, image4 = cv.threshold(image3, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU) # 二值化处理 cv.imwrite(file_name, image4) # 把image4保存为file_name文件 # 使用 PIL 打开图像转化为图像对象,并使用 pytesseract 进行图像识别验证码 image = Image.open(file_name) # 导入PIL包的Image包,打开处理好的图片 img_str = pytesseract.image_to_string(image) # 读取图片中的文字 locator = ("css selector", ".s_input.icon_code") # 定位验证码输入框 wait.until(ec.visibility_of_element_located(locator)).send_keys(img_str)
分类:
WEB自动化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架