
k-近邻算法-优化约会网站的配对效果
KNN原理
1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
a. 计算新数据与样本数据集中每条数据的距离。
b. 对求得的所有距离进行排序(从小到大,越小表示越相似)
c. 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签
3. 求 k 个数据中出现次数最多的分类标签作为新数据的分类
通俗的说:给定一个数据集,对新的输入实例,在训练集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把这个新输入实例分为这个类
项目案例1: 优化约会网站的配对效果
海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
她希望:
- 工作日与魅力一般的人约会
- 周末与极具魅力的人约会
- 不喜欢的人则直接排除掉
1. 将文本记录转换为 NumPy 的解析程序
from matplotlib.font_manager import FontProperties import matplotlib.lines as mlines import matplotlib.pyplot as plt import numpy as np from numpy import * import matplotlib import operator
def file2matrix(filename): """ 导入训练数据 :param filename: 数据文件路径 :return: 数据矩阵returnMat和对应的类别classLabelVector """ fr = open(filename) # 获得文件中的数据行的行数 numberOfLines = len(fr.readlines()) # 生成对应的空矩阵 # 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0 returnMat = zeros((numberOfLines, 3)) # prepare matrix to return classLabelVector = [] # prepare labels return fr = open(filename) index = 0 for line in fr.readlines(): # str.strip([chars]) --返回移除字符串头尾指定的字符生成的新字符串 line = line.strip() # 以 '\t' 切割字符串 listFromLine = line.split('\t') # 每列的属性数据 returnMat[index, :] = listFromLine[0:3] # 每列的类别数据,就是 label 标签数据 classLabelVector.append(int(listFromLine[-1])) index += 1 # 返回数据矩阵returnMat和对应的类别classLabelVector return returnMat, classLabelVector
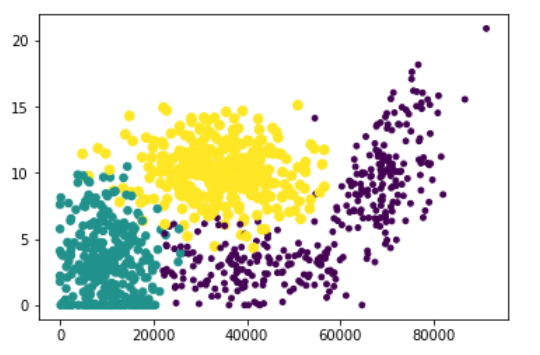
2. 使用Matplotlib创建散点图
import matplotlib import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*array(datingLabels), 15.0*array(datingLabels)) plt.show()
3. 归一化特征值,消除特征之间量级不同导致的影响
def autoNorm(dataSet): """ Desc: 归一化特征值,消除特征之间量级不同导致的影响 parameter: dataSet: 数据集 return: 归一化后的数据集 normDataSet. ranges和minVals即最小值与范围,并没有用到 归一化公式: Y = (X-Xmin)/(Xmax-Xmin) 其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。 """ # 计算每种属性的最大值、最小值、范围 minVals = dataSet.min(0) maxVals = dataSet.max(0) # 极差 ranges = maxVals - minVals normDataSet = zeros(shape(dataSet)) m = dataSet.shape[0] # 生成与最小值之差组成的矩阵 normDataSet = dataSet - tile(minVals, (m, 1)) # 将最小值之差除以范围组成矩阵 normDataSet = normDataSet / tile(ranges, (m, 1)) # element wise divide return normDataSet, ranges, minVals
normMat, ranges, minVals = autoNorm(datingDataMat)
normMat
array([[0.44832535, 0.39805139, 0.56233353],
[0.15873259, 0.34195467, 0.98724416],
[0.28542943, 0.06892523, 0.47449629],
...,
[0.29115949, 0.50910294, 0.51079493],
[0.52711097, 0.43665451, 0.4290048 ],
[0.47940793, 0.3768091 , 0.78571804]])
4. K近邻算法
def classify0(inX, dataSet, labels, k): """ inX: 用于分类的输入向量 dataSet: 输入的训练样本集 labels: 标签向量 k: 选择最近邻居的数目 注意:labels元素数目和dataSet行数相同;程序使用欧式距离公式. """ # 求出数据集的行数 dataSetSize = dataSet.shape[0] # tile生成和训练样本对应的矩阵,并与训练样本求差 """ tile: 列: 3表示复制的行数, 行:1/2 表示对inx的重复的次数 例:In []: inX = [1, 2, 3] tile(inx, (3, 1)) Out[]: array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) """ # 用inx(输入向量)生成和dataSet类型一样的矩阵,在减去dataSet diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 取平方 sqDiffMat = diffMat ** 2 # 将矩阵的每一行相加 sqDistances = sqDiffMat.sum(axis=1) # 开方 distances = sqDistances ** 0.5 # 根据距离排序从小到大的排序,返回对应的索引位置 # argsort() 是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。 """ In [] : y = argsort([3, 0, 2, -1, 4, 5]) print(y[0]) print(y[5]) Out[] : 3 5 由于最小的数是-1,它的序号是3,因此y[0] = 3, 最大的数是5,它的序号是5,因此y[5] = 5 """ sortedDistIndicies = distances.argsort() # 2. 选择距离最小的k个点 classCount = {} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]
5. 分类器针对约会网站的测试代码
def datingClassTest(): """ 对约会网站的测试方法 :return: 错误数 """ # 设置测试数据的的一个比例(训练数据集比例=1-hoRatio) hoRatio = 0.1 # 测试范围,一部分测试一部分作为样本 # 从文件中加载数据 datingDataMat, datingLabels = file2matrix('F:/迅雷下载/machinelearninginaction/Ch02/datingTestSet2.txt') # load data setfrom file # 归一化数据 normMat, ranges, minVals = autoNorm(datingDataMat) # m 表示数据的行数,即矩阵的第一维 m = normMat.shape[0] # 设置测试的样本数量, numTestVecs:m表示训练样本的数量 numTestVecs = int(m * hoRatio) print('numTestVecs=', numTestVecs) errorCount = 0.0 for i in range(numTestVecs): # 对数据测试 classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])) if (classifierResult != datingLabels[i]): errorCount += 1.0 print("the total error rate is: %f" % (errorCount / float(numTestVecs))) print(errorCount)
numTestVecs= 100
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
....
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 1
the total error rate is: 0.050000
5.0

