
激活函数的比较,sigmoid,tanh,relu
1. 什么是激活函数
如下图,在神经元中,输入inputs通过加权、求和后,还被作用了一个函数。这个函数就是激活函数Activation Function
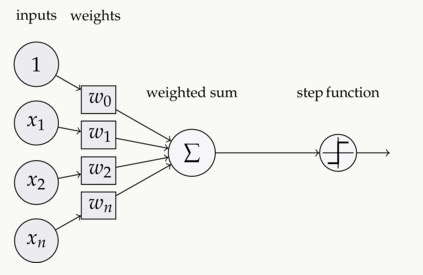
2. 为什么要用激活函数
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网路有多少层,输出都是输入的线性组合。与没有隐藏层效果相当,这种情况就是最原始的感知机了。
使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
3. 都有什么激活函数
(1)sigmoid函数
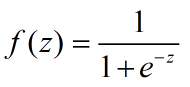

导数:
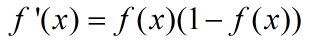
等式的证明也很简单。sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1)
sigmoid缺点:
- 激活函数计算量大,反向传播求误差梯度使,求导涉及除法
- 反向传播使,很容易就会出现梯度消失的情况,从而无法完成生成网络的训练
- sigmoid两端饱和且容易kill掉梯度
- 收敛缓慢
为何出现梯度消失:
sigmoid原函数及导数图如下图所示:
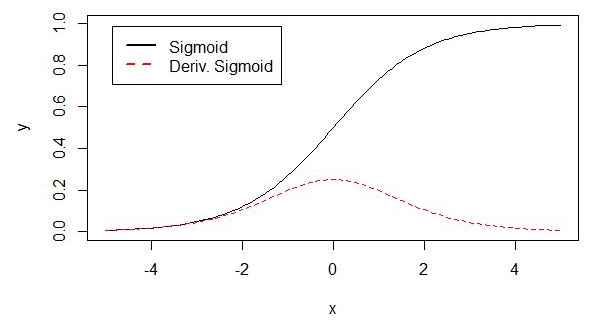
由图可知,导数从0开始很快又趋近于0,易造成"梯度消失"现象
(2)tanh函数(双曲正切)
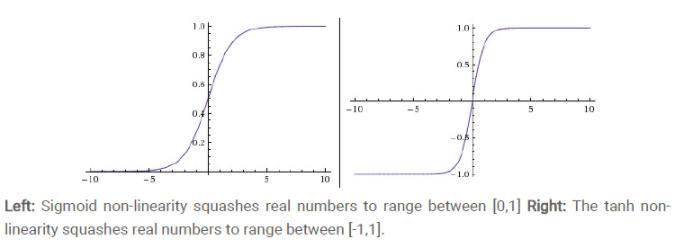
取值范围[-1,1]。0均值,实际应用中tanh比sigmoid要好
(3)ReLU
公式:
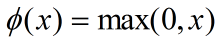
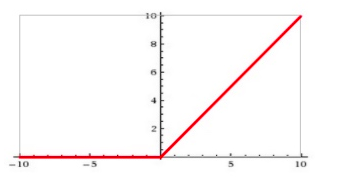
输入信号 < 0时,输出都是0;输入 > 0时,输出等于输入
1. ReLU更容易优化,因为其分段线性性质,导致其前传、后传、求导都是分段线性的。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢失信息
2. ReLU会使一部分神经元输出为0,造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合。
3. 当然现在也有一些对ReLU的改进,比如lrelu、prelu,在不同的数据集上会有一些训练速度上或者准确率上的改进。
4. 现在主流的做法,是在relu之后,加上一层batch normalization,尽可能保证每一层网络的输入具有相同的分布。
ReLU的缺点:
训练的时候很"脆弱",很容易"die"
例如:一个非常大的梯度流过一个ReLU神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元就永远都会是0.
(4)softmax函数
Softmax-用于多分类神经网络输出
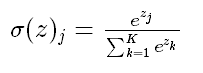
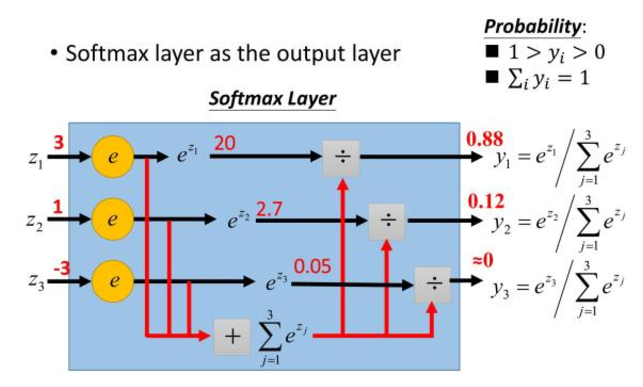
上图所示,如果某个 zj 大过其他 z,那这个映射的分量就逼近于1,其他逼近于0,主要应用于多分类
为什么要取指数?
1. 模拟 max 的行为,让大的更大
2. 需要一个可导函数

