如何防止过拟合
一、什么是过拟合?
简单的说,就是对模型过度训练,把"训练数据学的太好了"。如下图所示:
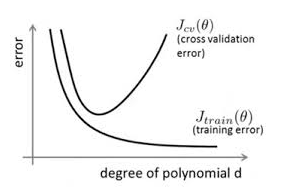
通过上图可以看出,随着训练的进行,训练损失逐渐减小,而验证损失先降后升,此时便发生了过拟合。即模型的复杂度升高,但是泛化能力却降低。
降低过拟合的方法:数据集扩增(Data augmentation)、正则化(Regularization)、Dropout
一、数据集扩增
"拥有更多的数据胜过一个好的模型"。数据的增加对模型训练大有益处,当然收集与标注数据费时费力,我们可以在已有的数据上动动脑筋,以得到更多的数据。
1. 简单的来说就是进行数据增强,使得数据看起来更多元化一些。这样模型每次处理样本的时候,都会以不同于前一次的角度看待样本。这就提高了从每个样本中学习参数的难度。
2. 增加噪声数据:
对于输入:和数据增强的目的相同,但是也会让模型对可能遇到的自然扰动产生鲁棒性
对于输出:让训练更加多元化
注意:在这两种情况中,你需要确保噪声数据的量级不能过大。否则最后你获取的输入信息都是来自噪声数据,或者导致模型的输出不正确。这两种情况也会对模型的训练过程带来一定的干扰。
二、正则化方法
在进行代价函数优化时,加上一个正则项,一般有L1正则和L2正则。
- L1惩罚项的目的是将权重的绝对值最小化
- L2惩罚项的目的是将权重的平方值最小化
L1:
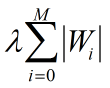
L2:

L1正则化的模型叫做Lasso回归,L2正则化的模型叫做Ridge回归(岭回归)
下图是python中Lasso回归的损失函数,加号后面一项为L1正则化项

下图是python中岭回归的损失函数,加号后面一项为L2正则化项

说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和。L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择(1-范数)
- L2正则化是指权值向量w中各个元素的平方和然后在求平方根(其实就是权重的2范数)
L1正则化另一个优点是它能进行特征选择,也就是说它可以让一部分无用特征的系数缩小到0,从而帮助模型找出数据集中最相关的特征。缺点是通常它在计算上不如L2正则化项高效。
三、Dropout
在训练中随机的让一部分神经元无效。如图所示: