随机森林
随机森林(Random Forest,简称RF)
森林是有树构建的,随机森林是由多个决策树构建的。
如何随机?
- 数据的随机性化
- 待选特征的随机化
流程:
1. 采取有放回的抽样方式构建子数据集,保证不同子数据集之间的数量级一样
2. 利用子数据集构建子决策树,每个子决策树输出一个结果
3. 统计子决策树的投票结果,得到最终分类就是随机森林的输出结果
2. 待选特征的随机化(k的引入)
a. 子树从所有的待选特征中随机选取一定的特征。
b. 在选取的特征(k个特征)中选取最优的特征。
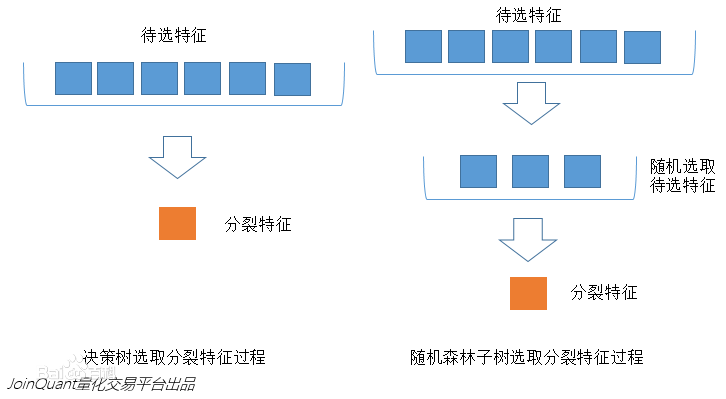
假如当前所有特征为d个,传统决策树是从d个选一个最优特征;而随机森林里的子树是从d个中随机选取k个,在从k个中选一个最优特征。
当k = d时,子树就变成了传统决策树;
当k = 1时,子树就随机选择一个特征进行划分。
推荐值:
 随机森林 开发流程
随机森林 开发流程
收集数据:任何方法
准备数据:转换样本集
分析数据:任何方法
训练算法:通过数据随机化和特征随机化,进行多实例的分类评估
测试算法:计算错误率
使用算法:输入样本数据,然后运行 随机森林 算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
