

初识HTML

我们的浏览器会利用HTTP协议向web服务器软件请求下载服务器物理硬盘上的网页到自己的电脑上,
下载后大家可以就可以用浏览器浏览网页了。
为啥必须要用浏览器浏览网页,用word,excel不行吗?
答案是不行,因为每个服务器上的网页其实是用HTML语言写成的一个文档,只有浏览器才能自动解析HTML,Excel不能解析html。
注意HTML不是一门编程语言而是一种排版语言,
HTML通过标签来告诉浏览器如何将网页呈现给电脑前的用户。
HTML的一个例子如下:

在上面的例子中,左侧是HTML文档,右侧是在浏览器中打开后的效果,
同学们可以先不管HTML中的具体代码含义,先在浏览器上把这个文档解析出来。
撰写html文档的方法有两种,一种是用windows自带的记事本来写,另一种是用云编辑器Jsbin来写。
记事本运行非常简单,打开记事本,将HTML代码写到记事本中,
注意保存时要保存成html的文档而不是文本文档(后缀名必须是html,不能是txt!!!)。
存完后,用浏览器打开这个html文件(可以直接拖进浏览器里)后即可看到效果。代码如下:
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <title>Page Title</title> 5 </head> 6 <body> 7 8 <h1>This is a Heading</h1> 9 <p>This is a paragraph.</p> 10 11 </body> 12 13 </html>
Jsbin是一款很优秀的web前端开发在线编辑器,使用起来非常简单,网址是https://jsbin.com/?html,output
截图如下:左边HTML区写代码,右边output区直接看结果!!

每个HTML文档在浏览器里被存储成一棵以<HTML>元素为根的树模型(英文叫Document Tree,简称dom tree)
存成树结构是便于被浏览器解析,学过编译原理的同学都知道,代码要被变成一颗语法树后编译器才能解析的。
树模型将在本门课JavaScript部分详细探讨。
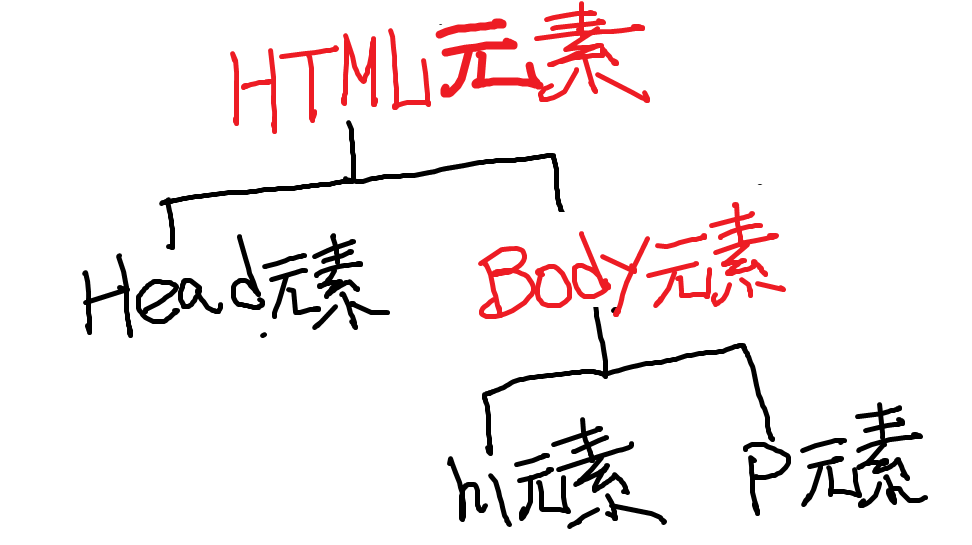
<html>元素是树根,它代表整个HTML文档,即整个网页。
这棵树除了<HTML>元素和<body>元素必须有外,其它元素可有可无。
所有人眼可见的元素必须作为<body>元素的子孙。
<head>元素可有可无,一般head的子孙都是人眼不可见但浏览器需要的元素。
从上面的代码可以看出一个HTML的元素主要由四部分构成:开始标签+属性+内容+结束标签。

需要注意的是HTML的元素必须有开始标签但可以没有属性、内容和结束标签,
没有内容和结束标签的元素称为空元素。例如:

属性必须写在开始标签里面,一个属性由属性名和属性值组成,多个属性间用逗号隔开。

例如:在img元素中通过src属性来指出在网页中待插入图片的名字。

最后提一下,一个HTML网页在浏览器里是按树模型存储的,
但程序员为了便于理解网页元素在空间上的布局关系,
还弄出了一种叫做盒子模型的东西。
盒子模型英文叫作Box Model, 盒子模型的特点如下:,
1)每个元素看作一个矩形,
2)根元素<html>是最大的那个矩形,它的尺寸近似网页的高度和宽度
2)元素的嵌套关系通过矩形的嵌套关系表示。
3)矩形块之间的位置关系模拟元素在显示时的空间关系
盒子模型将在本门课的CSS部分详细探讨。


