MariaDB——数据库基础与sql语句
数据库介绍
关系型数据库
关系型数据库介绍
关系型数据库模型是把复杂的数据结构归结为简单的二元关系(既二维格式表)。在关系型数据库中,对数据的操作几乎全部建立在一个或多个关系表上,通过对这些关联表格分类,合并,连接或选取等运算来实现数据的管理。
关系型数据库诞生距今已经有40多年了,从理论产生发展到现实产品,例如:大家最常见的mysql和oracle数据库,oracle在数据库领域里上升到了霸主的地位,形成每年高达数百亿美元的庞大产业市场,而mysql也是不容忽视的数据库,以至于被oracle中心收购了。
非关系型数据库(nosql)
非关系型数据库也称之为nosql数据库,请注意,nosql的本意是“not only SQL”,指的是非关系型数据库,而不是“no SQL”的意思,因此nosql的产生并不是要彻底否定关系型数据库,而是作为传统关系型数据库的一个有效补充,NoSQL数据库在特定的场景下可以发挥出难以想象的高效率和高性能。
随着互联网的兴起,超大规模和高并发量的微博,微信,SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,例如:传统的关系型数据库IO瓶颈,性能瓶颈都难以有效突破,于是开始出现了大批针对特定场景,以高性能和使用便利为目的的功能特异化的数据库产品,NoSQL类的数据库就是在这样的情景中诞生并得到了非常迅速的发展
NoSQL是非关系型数据库的广义定义。它打破了长久以来关系型数据库与ACID理论大一统的局面,NoSQL数据存储不需要固定的表结构,通常也不存在连接操作,在大数据存取上具备关系型数据库无法比拟的性能优势,该术语(NoSQL)在2009年初得到了广泛的认同
google的BigTable与Amazon的Dynamo是非常成功的商业NoSQL,一些开源的NoSQL体系,如
Redis, mongodb也逐渐的越来越受到各大中小型企业的欢迎和追捧.
一、关系型数据库
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
- 易于维护:都是使用表结构,格式一致;
- 使用方便:SQL语言通用,可用于复杂查询;
- 复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 固定的表结构,灵活度稍欠;
- 高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
二、非关系型数据库
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
- 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
- 高扩展性;
- 成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
- 不提供sql支持,学习和使用成本较高;
- 无事务处理;
- 数据结构相对复杂,复杂查询方面稍欠。
常见的数据库
非关系型数据库(nosql):mongodb,redias
关系型数据库:oracle,db2,sqlserver,mysql,mariadb
Mariadb发源
MySQL之父Widenius先生离开了Sun之后,觉得依靠Sun/Oracle来发展MySQL,实在很不靠谱,于是决定另开分支,这个分支的名字叫做MariaDB。
RDBMS
Relational Database Management System

- sql语句主要分为:
- DQL:数据查询语言,用于对数据进行查询,如select
- DML:数据库操作语言,对数据库进行增删改查,如:insert,update,delete
- TPL:事物处理语言,对事物进行处理,包括begin,transaction,commit,rollback
- DCL:数据控制语言,如grant,revoke
- DDL:数据定义语言:进行数据库,表的管理等,如create,drop
- CCL:指针控制语言,通过控制指针完成表的操作,如declare cursor
- sql是一门特殊的语言,专门用来操作关系型数据库
- 不区分大小写
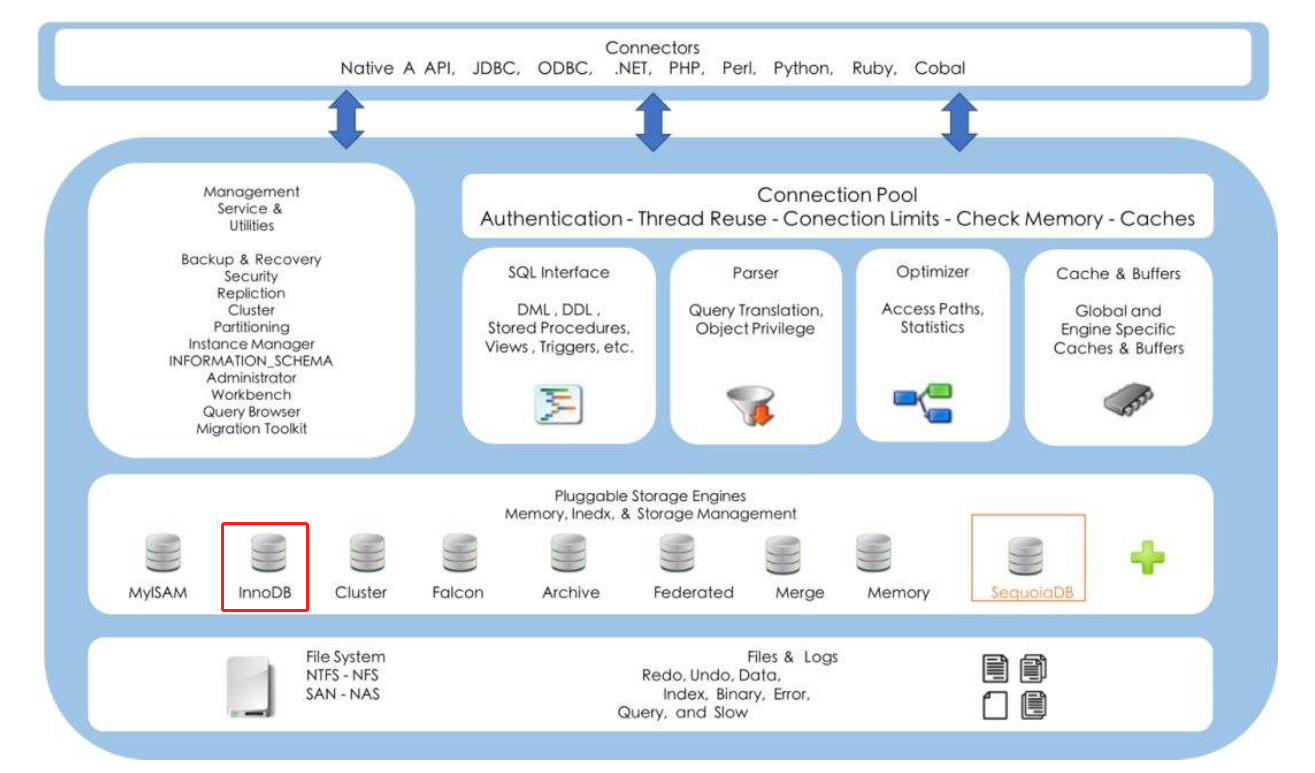
Mariadb安装
[mariadb]
name = MariaDB
baseurl = http://mirrors.ustc.edu.cn/mariadb/yum/10.3/centos7-amd64/
gpgkey=http://mirrors.ustc.edu.cn/mariadb/yum/RPM-GPG-KEY-MariaDB
gpgcheck=1
忘记mysql的root密码
vim /etc/my.conf.d/server.conf
添加skip-grant-tables
mysql -uroot | mysql -u root -p
数据库常用操作
客户端类型应用程序的可用选项:
-u ,--user=
-h ,--host=
-p ,--password=
-P ,--port=
-D ,--database=
-e 'SQL;SQL' #命令行执行sql语句的操作选项
mycat:
mysql -h 192.168.254.24 -P8066 -utestuser1 -ptestuser1 (可以执行增删改查)
mysql -h 192.168.254.24 -P9066 -utestuser1 -ptestuser1 (可以查看节点状态)
msyql-client的操作:
show global variables; #获取mysql进程的各项服务参数及比例
show create database testdb;
alter database testdb character set utf8;
show create database testdb;
grant all on *.* to test@‘%’ identified by '123';
grant all on mysql.testtable to test@‘%’ identified by ‘123’;
revoke all privileges on *.* from test;
show databases;
show grants;
show grants for test;
show grants for test@localhost;
mysql -uroot -proot -e "show databases;use mysql;show tables;"
show creata database aaa;
drop database aaa;
show database;
create database kkk character set utf8;
show create database kkk;
alter database kkk character set utf8;
select user(); #查看当前的用户
use mysql;
show tables;
desc user; #user表存放用户信息
select * from user;
select host,user,password from user;
revoke all privileges on msyql.user from user520@localhost;
show grants for ken@localhost;
show grants;
update user set password=password('root') where user='root';
flush privileges;
select now();
--创建class表(id name两个字段)
use testdb;
create table class (
id tinyint unsigned primary key not null auto_increment,
name varchar(20)
);
create table students (
id smallint unsigned auto_increment primary key,
name varchar(22),
age tinyint unsigned default 0,
high decimal(5,2),
gender enum('male','female','secret') default 'secret',
cls_id tinyint unsigned
);
alter table students add birth datetime;
--修改表修改字段,不重命名
alter table students modify birth date;
--修改表字段,且重命名
alter table students change birth birthday date;
desc students;
alter table students modify birthday date;
desc students;
alter table students change birthday birth datatime;
drop table classes; #删除classes表
--删除字段
alter table students drop birth;
desc students;
select id,age,name from students;
insert into students values (1,'ken',23,170,'male',1);
insert into students values (0,'ken1',23,170,'male',1),(0,'ken2',23,170,'male',1);
select * from students;
insert into students values (default,'pheb',24,176.250,’male‘,1);
insert into students values (null,'pheb',24,176.250,’male‘,1);
--三种情况都是走primary-key的默认值
insert into students values (0,'pheb',24,176.250,’male‘,1);
--这个时候再插入数据的时候,就会默认从11开始
show create table students; #可以看到auto_increment的值
insert into students (name,age,high) values ("joy",23,176.24); #如果有些不能为空的字段没有默认值会报错
select * from students;
delete from students; #会清空这张表
select * from students;
bit(2): 00 01 10 11
--删除表
truncate table students; #不可恢复的删除
delete from students; #可以恢复
添加的bit位可能很小,看不到值,但是不影响使用。
select * from students where is_delete=1;
Update students set age=22,class=6 where id=10;
--主键字段可以使用 0 null default 来占位。
--枚举类型也可以使用数字来指代。1——表示定义的第一个枚举类型。超出枚举范围会出现报错的清况。
--delete from 表名 where 条件
两种类型最主要的区别就是Innodb支持事物处理与外键和行级锁。
myisam支持表级锁
--update 表名 set 列1=值1,列2=值2..... where 条件;
update students set age=100,cls_id=3 where id=10;
update students set age=100,cls_id=3 where id<=10;
update students set cls_id=null where id<=6;
select students.name from students;
select s.name from students as s; #起别名常用于关联查询
select * from students where id < 22;
select * from students where age > 38;
select * from students where age > 18 and age < 30;
select * from students where age <= 23;
select * from students where age >= 18 && age <= 38;
select * from students where age < 18 || age > 33;
select * from students where age between 18 and 28; #头和尾都包含了。
select * from students where age > 18 || high > 170;
select * from students where name like '%锋'; #%就相当于shell中的*
select * from students where name like '%霆%';
select * from students where name like '__'; #一个下划线表示一个字
select * from students where name like '__%';
select * from students where age=16 or age=22;
select * from students where age in (18,34,55,66,22);
select * from students where age not between 18 and 33;
select * from students where high is null;
select * from students where high=175 and name="joy";
select * from students where high=175 or name="joy";
select * from students where high is not null;
select * from students order by age; #默认从小到大排列
select * from students order by age desc; #descent 降序排列
select * from students order by age desc,high desc;
select * from students order by age asc;
select * from students where age between 18 and 33 and gender=1 order by age desc;
--聚合函数
select * from students; #查询后会有一个总的行数统计,这个统计是准确的。
--但是这种查询来看总的行数的方式很可能会出现问题,一旦数据量较大,那么会出现卡死的现象,也就是说select * from students实际上会将
所有的内容读到你的内存里,大量的io操作会导致系统崩溃。
所以一般会先看看一张表里有多少行,再进行查询的操作。
--查询总行数
select count(name) from students;
select count(*) from students; #这种统计方式很准确,只要任意一个字段占一行都算。
select count(high) from students; #可能会少几行,如果有null的情况。
select count(*) as ’total‘ from students;
select max(age) from students;
select name,max(age) from students; #这条查询语句发生了错位,姓名和max不匹配
select max(age)as ‘max’ from students; #实际上没有办法用max去查询对应的数据
select min(age) from students;
select min(age) from students where gender=2;
select max(age) from students where gender=1;
select max(age) from students where gender=2;
select sum(age)/count(age) from students;
select sum(age)/count(age) as 'average' from students;
select round(sum(age)/count(age),2) as 'average' from students;
select round(avg(high),2) as 'avg' from students; #使用avg自动剔除了空项
select sum(high) from students;
select distinct gender from students; #查询不重复的
select gender from students gourp by gender;
select gender,count(*) from students group by gender; #统计各组性别的人数。
select gender,group_concat(name) from students group by gender;
select gender,group_concat(name,age) from students group by gender;
select gender,group_concat(name,'|',age,'|',high) from students group by gender;
select gender,group_concat(name,'|',age,'|',high) from students where gender=1 group by gender;
select gender,group_concat(name,'|',age,'|',high) from students where gender=2 group by gender;
select gender,avg(age) from students group by gender having avg(age)>=50;
select gender,avg(age) from students group by gender having avg(age)>=10; #这里的having使用where不符合语法规则。
select gender ,group_concat(name) from students group by gender having count(*)>3;
select * from students limit 2;
select * from students limit 0,2;
select * from students limit 4,2;
select * from students limit 6,2; #从6行之后的两行
select * from students where gender=2 order by high desc limit 2,1;
select * from students where gender=2 order by high desc limit 3,1;
update students set high=null where id=1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号