从整理上理解进程创建、可执行文件的加载和进程执行进程切换
0.
学号后三位094
“原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/ ”
一、阅读理解task_struct数据结构
1. 什么是进程
进程是程序执行的一个实例、是正在执行的程序、是能分配处理器并由处理器能够执行的实体。
2. PCB
为了管理进程,操作系统必须对每个进程所做的事情进行清楚的描述,为此,操作系统使用数据结构来代表处理不同的实体,这个数据结构就是通常所说的进程描述符或进程控制块(PCB)。在Linux中,task_struct其实就是通常所说的PCB。该结构定义位于:/include/linux/sched.h。

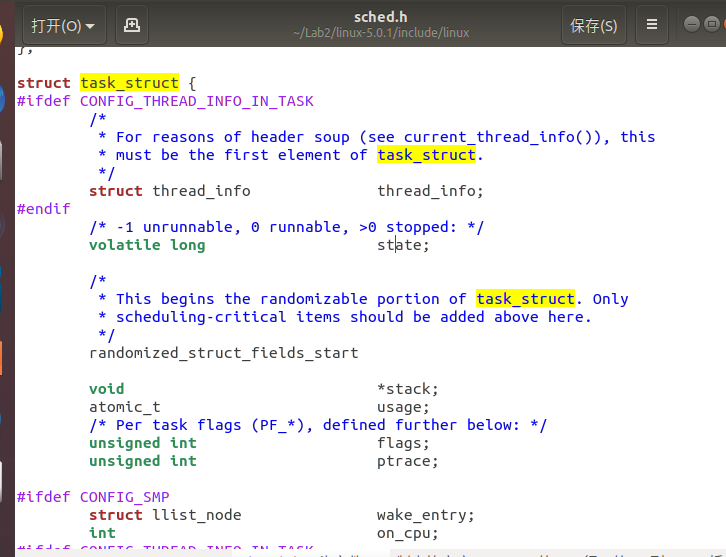
源文件过于繁琐,在此只分析重要片段。
1 /* -1 unrunnable, 0 runnable, >0 stopped: 进程状态 **/ 2 volatile long state; 3 /** 进程状态*/ 4 unsigned int flags; 5 /** 进程退出 */ 6 int exit_state; int exit_code; int exit_signal; 7 /** 进程标识号 */ 8 pid_t pid; pid_t tgid; 9 /** 用于通知LSM是否被do_execve()函数所调用 */ 10 unsigned in_execve:1; 11 /** 在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特殊地址*/ 12 struct completion *vfork_done; 13 /* CLONE_CHILD_SETTID: */ 14 int __user *set_child_tid; 15 /* CLONE_CHILD_CLEARTID: */ 16 int __user *clear_child_tid;
task_struct结构中主要包含以下内容:
状态信息:如就绪、执行等状态
链接信息:用来描述进程之间的关系,例如指向父进程、子进程、兄弟进程等PCB的指针 各种标识符:如进程标识符、用户及组标识符等
时间和定时器信息:进程使用CPU时间的统计等 调度信息:调度策略、进程优先级、剩余时间片大小等
处理机环境信息:处理器的各种寄存器以及堆栈情况等 虚拟内存信息:描述每个进程所拥有的地址空间
二、分析fork函数
1.进程创建
fork、vfork、clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现的
(1)子进程被创建后继承了父进程的资源。
(2)子进程共享父进程的虚存空间。
(3)写时拷贝 (copy on write):子进程在创建后共享父进程的虚存内存空间,写时拷贝技术允许父子进程能读相同的物理页。只要两者有一个进程试图写一个物理页,内核就把这个页的内容拷贝到一个新的物理 页,并把这个新的物理页分配给正在写的进程
(4)子进程在创建后执行的是父进程的程序代码。
对于父进程 fork 返回子进程号,对于子进程 fork 返回 0 ,fork 先是调用 find_empty_process 为子进程找到一个空闲的任务号,然后调用 copy_process 复制进程, fork 返回 copy_process 的返回值 last_pid ,也就是子进程号。所以fork()实际上是一次调用,两次返回。
1 long do_fork(unsigned long clone_flags, 2 unsigned long stack_start, 3 unsigned long stack_size, 4 int __user *parent_tidptr, 5 int __user *child_tidptr) 6 { 7 struct task_struct *p; 8 int trace = 0; 9 long nr; 10 11 // ... 12 13 // 复制进程描述符,返回创建的task_struct的指针 14 p = copy_process(clone_flags, stack_start, stack_size, 15 child_tidptr, NULL, trace); 16 17 if (!IS_ERR(p)) { 18 struct completion vfork; 19 struct pid *pid; 20 21 trace_sched_process_fork(current, p); 22 23 // 取出task结构体内的pid 24 pid = get_task_pid(p, PIDTYPE_PID); 25 nr = pid_vnr(pid); 26 27 if (clone_flags & CLONE_PARENT_SETTID) 28 put_user(nr, parent_tidptr); 29 30 // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行 31 if (clone_flags & CLONE_VFORK) { 32 p->vfork_done = &vfork; 33 init_completion(&vfork); 34 get_task_struct(p); 35 } 36 37 // 将子进程添加到调度器的队列,使得子进程有机会获得CPU 38 wake_up_new_task(p); 39 40 // ... 41 42 // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间 43 // 保证子进程优先于父进程运行 44 if (clone_flags & CLONE_VFORK) { 45 if (!wait_for_vfork_done(p, &vfork)) 46 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); 47 } 48 49 put_pid(pid); 50 } else { 51 nr = PTR_ERR(p); 52 } 53 return nr; 54 }
2. do_fork过程
(1)调用copy_process,将当前进程复制一份做为子进程,并设置上下文信息。
(2)初始化vfork的完成处理信息。
(3)调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
(4)如果是vfork调用,需要阻塞父进程,直到子进程执行exec。
三、使用gdb跟踪分析一个fork系统调用内核处理函数do_fork
下载menu文件,修改test.c,制作镜像
git clone https://github.com/mengning/menu.git
mv test_fork.c test.c
make rootfs
启动qemu
另开一个终端,gdb

跟踪每一步
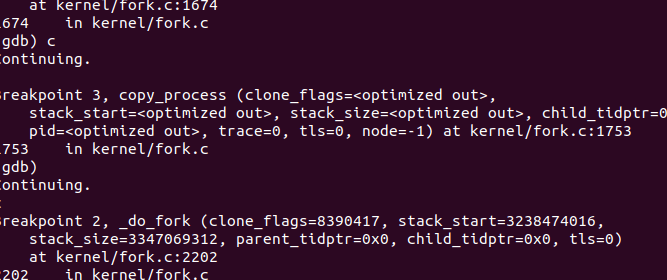
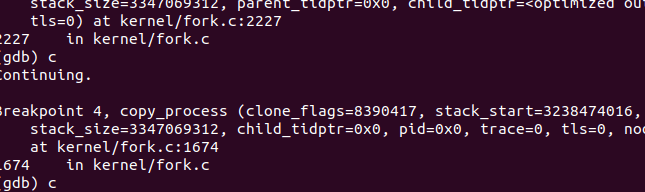
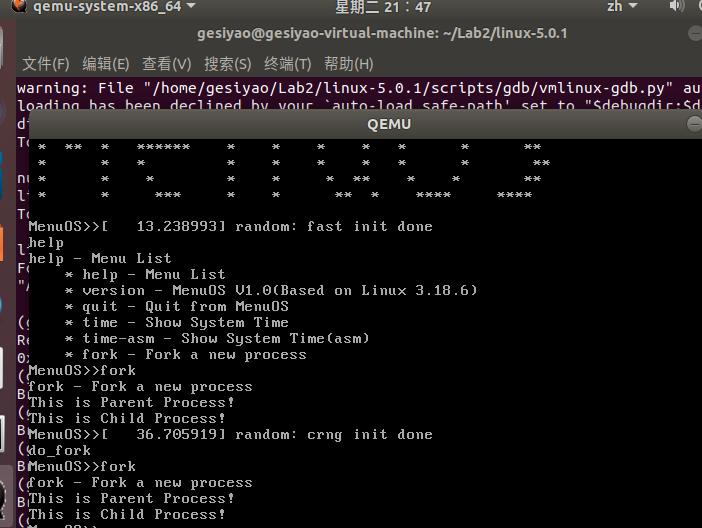
运行后首先停在sys_clone处,然后到copy_process,进入copy_thread。与之前分析一致。
四、理解编译链接的过程和ELF可执行文件格式
(1)编译
编译是指编译器读取源程序,对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
(2)汇编
汇编器把汇编语言代码翻译成目标机器指令的过程。目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
(3)目标文件
可重定位(Relocatable)文件:由编译器和汇编器生成,可以与其他可重定位目标文件合并创建一个可执行或共享的目标文件;
共享(Shared)目标文件:一类特殊的可重定位目标文件,可以在链接(静态共享库)时加入目标文件或加载时或运行时(动态共享库)被动态的加载到内存并执行;
可执行(Executable)文件:由链接器生成,可以直接通过加载器加载到内存中充当进程执行的文件。
(4)静态链接
链接器将函数的代码从其所在地(目标文件或静态链接库中)拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
(5)动态链接
在此种方式下,函数的定义在动态链接库或共享对象的目标文件中。在编译的链接阶段,动态链接库只提供符号表和其他少量信息用于保证所有符号引用都有定义,保证编译顺利通过。动态链接器(ld-linux.so)链接程序在运行过程中根据记录的共享对象的符号定义来动态加载共享库,然后完成重定位。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
(6)加载
加载器把可执行文件从外存加载到内存并进行执行。
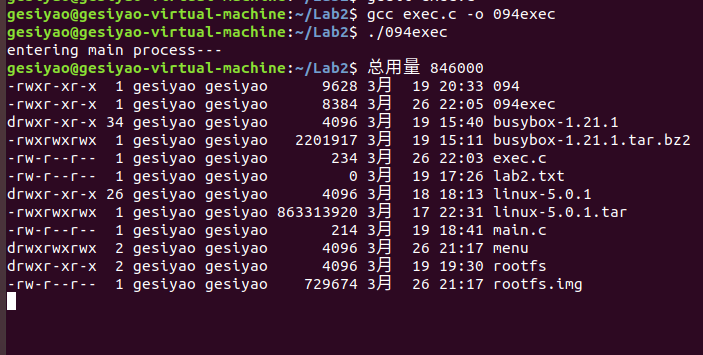
五、使用execve函数
加载一个可执行目标文件需要调用execve函数,将命令行参数和环境参数传递给可执行程序的main函数(先函数调用参数传递,在系统调用参数传递),最后execve返回到另外的程序。
execve系统调用的处理过程如下:
sys_execve–>do_execve–>do_execve_common(do_open_exec、exec_binprm)
exece_binprm–>search_binary_handler–>list_for_each_entry–>load_binary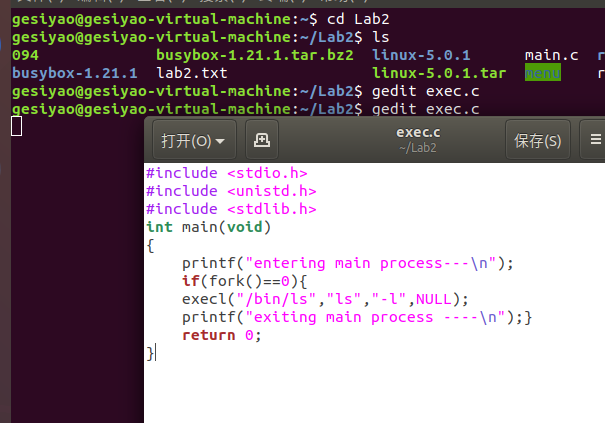
六、跟踪schedule过程&分析switch_to()
调用过程为:schedule() -->pick_next_task() --> context_switch() --> __switch_to()
对以上几处打上断点。

当进程间切换时,首先需要调用pick_next_task函数挑选出下一个将要被执行的程序;然后再进行进程上下文的切换,此环节涉及到“保护现场”及“现场恢复”;在执行完以上两个步骤后,调用__switch_to进行进程间的切换。
asm volatile("pushfl\n\t" /* 保存当前进程的标志位 */ "pushl %%ebp\n\t" /* 保存当前进程的堆栈基址EBP */ "movl %%esp,%[prev_sp]\n\t" /* 保存当前栈顶ESP */ "movl %[next_sp],%%esp\n\t" /* 把下一个进程的栈顶放到esp寄存器中,完成了内核堆栈的切换,从此往下压栈都是在next进程的内核堆栈中。 */ "movl $1f,%[prev_ip]\n\t" /* 保存当前进程的EIP */ "pushl %[next_ip]\n\t" /* 把下一个进程的起点EIP压入堆栈 */ __switch_canary "jmp __switch_to\n" /* 因为是函数所以是jmp,通过寄存器传递参数,寄存器是prev-a,next-d,当函数执行结束ret时因为没有压栈当前eip,所以需要使用之前压栈的eip,就是pop出next_ip。 */ "1:\t" /* 认为next进程开始执行。 */ "popl %%ebp\n\t" /* restore EBP */ "popfl\n" /* restore flags */ /* output parameters 因为处于中断上下文,在内核中 prev_sp是内核堆栈栈顶 prev_ip是当前进程的eip */ : [prev_sp] "=m" (prev->thread.sp), [prev_ip] "=m" (prev->thread.ip), //[prev_ip]是标号 "=a" (last), /* clobbered output registers: */ "=b" (ebx), "=c" (ecx), "=d" (edx), "=S" (esi), "=D" (edi) __switch_canary_oparam /* input parameters: next_sp下一个进程的内核堆栈的栈顶 next_ip下一个进程执行的起点,一般是$1f,对于新创建的子进程是ret_from_fork*/ : [next_sp] "m" (next->thread.sp), [next_ip] "m" (next->thread.ip), /* regparm parameters for __switch_to(): */ [prev] "a" (prev), [next] "d" (next) __switch_canary_iparam : /* reloaded segment registers */ "memory"); } while (0)
switch_to分析:
首先在当前进程prev的内核栈中保存esi,edi及ebp寄存器的内容。
然后将prev的内核堆栈指针ebp存入prev->thread.esp中。
把将要运行进程next的内核栈指针next->thread.esp置入esp寄存器中。
将popl指令所在的地址保存在prev->thread.eip中,这个地址就是prev下一次被调度。
通过jmp指令(而不是call指令)转入一个函数__switch_to()。
恢复next上次被调离时推进堆栈的内容。从现在开始,next进程就成为当前进程而真正开始执行。
七、总结
Linux通过复制父进程来创建一个新进程,fork()函数被调用一次,但返回两次。
Linux通过调用schedule()函数来实现进程调度,switch_to实现上下文切换。
进程上下文切换需要保存切换进程的相关信息,一般进程上下文切换是套在中断上下文切换中的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号