JavaScript正则表达式入门
工作中,正则表达式用的可能不是很多,一般使用的时候网上都有现成的实例,很少缺乏比较全面的理解。本文主要以匹配HTML标签为例,简述下正则表达式常用的功能点。匹配HTML片段如下:
let str = ` <div id="app"> <div>21</div> <h1> <span>hello</span> <span>smile</span> </h1> <button>按钮</button></div> `;
正则匹配本文查看结果主要用String.match(RegExp)方法,常用的正则匹配方法为:RegExp.test(String),RegExp.exec(String)
1、正则表达式的声明
正则表达式的声明方式和普通变量的声明方式类似,一般情况下有两种,字面量和正则构造方法RegExp。以匹配span标签为例,匹配单个span标签的正则如下:
// 字面量方式 let normalPattern = /span/ // 调用正则构造方法 let pattern = new RegExp('span')
2. 修饰符
上述的正则,在匹配测试文本是,输出的结果是一个数组,只有一个元素span,如果我想匹配多个呢,这里就要引入正则修饰符的概念了,常用的就是 i 和 g。
i的含义是忽略大小写,比如用/span/只能去匹配span字符串,SPAN匹配不了,如果想匹配SPAN,就要加上i修饰符
g的含义是global,全局查找,正则默认只匹配第一个符合条件的值,如果要全局匹配,就要加上g修饰符。
具体写法如下:
// 字面量方式 let normalPattern = /span/ig // 调用正则构造方法 let pattern = new RegExp('span', 'ig')
3.字符类别
以上匹配的文本都非常的基础,假如我想匹配所有的HTML标签,该怎么写呢?HTML标签很多,没法一个个全部罗列出来,我们可以使用字符类别,进行快速的匹配。参考列表如下:

字符类别,在某种程度上来说,可以理解为一个字符集,如上述列表所示,\d是数字0-9的集合,如果我们要匹配一段文本中所有的数字,可以直接声明如下正则:
let numberPattern = /\d/g
假如我要匹配所有的HTML标签呢?在匹配一个文本之前,我们需要先分析下HTML标签规律,首先,HTML标签和一般的XML标签,都是以尖括号<大头,以尖括号>结尾,其次,中间只能是英文字母或者数字,最后,数字或字母可能出现一次或者多次。写正则的第一要素是先归纳总结,总结出规律才能去分析正则的写法。正则表达式本质上也是一种规律的解释文本。从我们总结的规律中,我们可以按照如下写法:
let matchTags = /<\w+>/g
匹配结果如下:
[ '<div>', '<h1>', '<span>', '<span>', '<button>' ]
\w代表数字或者字母,+代表匹配一次或者多次,g代表全局匹配。我们在匹配文本的时候,一种规律有时候不可能只用一次,正则表达式提供了丰富的数量词语法,能够满足我们绝大多数要求,下面的章节会有介绍。
我们看到,我们匹配的HTML标签只是前面的标签,并没有后面的闭合标签,我们如何匹配闭合标签呢?闭合标签比普通的标签多了一个斜杠/,如果我们单纯的写/,是不可以的,大家可能意识到,正则表达式的字面量写法是两个斜杠/包起来的,如果我们直接写,会有冲突,这时候,我们需要借助转义字符反斜杠\进行转义即可,一些与正则表达式冲突的,都需要用转义字符进行转义,比如特殊字符(),[],还有是一些具有特殊意义的集合,\w,\d....
匹配闭合标签的正则如下:
let matchCloseTags = /<\/\w+>/g
匹配结果:
[ '</div>', '</span>', '</span>', '</h1>', '</button>', '</div>' ]
4.数量词
在字符类中,我们用到了数量词+,代表匹配一次或多次。正则表达式数量词远远不止这些,具体列表如下所示:
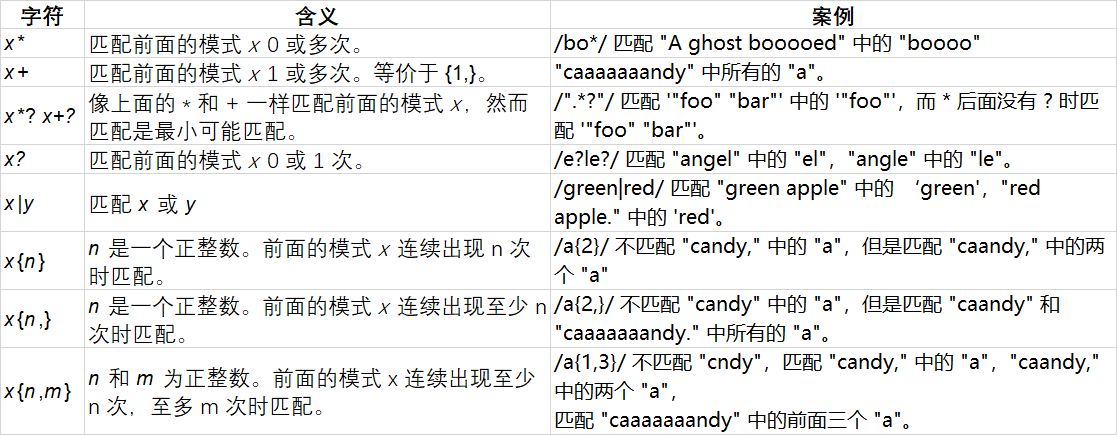
举个例子,假如我要匹配HTML片段中的h标签,我们都知道h标签的基本规则为只有一个字母和数字,从上述我们可以得出,我们可以用数量词{n},正则表达式如下:
let matchH = /<h{1}\d{1}>/g
匹配结果:
[ '<h1>' ]
在这里,我们要记住两个个数量词,x*?和x+?,这个是最小匹配原则。假如现在我们要匹配第一个span闭合标签和文本,即<span>hello</span>,如果我们按照正常思路去写,以<span>开头,</span>结尾,中间是任意字符,正则表达式实现如下所示:
let matchSpan = /<span>(\S|\s)+<\/span>/g
匹配结果可能和我们预想的不大一样,实际上匹配结果只有一个,如下所示:
[ '<span>hello</span>\n <span>smile</span>' ]
正则默认的会全文匹配,并不会按照最小匹配原则,即找到符合条件的文本就返回,他会最大程度的去匹配符合条件的文本。如果我们要分别匹配两段span标签,我们就需要用到最小匹配原则的数量词,具体如下:
let matchSpan = /<span>(\S|\s)*?<\/span>/g
let matchSpan2 = /<span>(\S|\s)+?<\/span>/g
文本匹配结果:
[ '<span>hello</span>', '<span>smile</span>' ]
5.集合
正则表达式中,集合使用也比较多,语法比较简单,所有需要匹配的文本依次放在中括号[]中,比如如果你想匹配abc三个字母,pattern=/[abc]/,如果不想匹配abc,那就是pattern=[^abc],如果匹配数字,那就是/[0-9]/,-代表一个连续的集合,字母就是[a-zA-Z]
6.边界
边界最简单的用法,^代表匹配输入的开始,$代表匹配输入的结束。
7.分组
假如现在有这样一个需求,需要匹配span标签里的文本,而不需要span标签, 此时可能会用到分组,从字面意思上来说,分组就是把规则分类。分组的语法比较简单,就是小括号()。转换为正则的语法如下:
let matchSpanText = /(<span>)(\S+)+?(<\/span>)/
let result = str.match(matchSpanText)
匹配结果如下图所示:

从上图可以看出,匹配结果数组result长度为4,第一部为匹配的结果,第二部分为(span)匹配的结果,第三部分为(\S+)匹配的结果,第四部分为(</span>)匹配的结果,如果我们要拿纯文本,直接去arr[2]即可。我们也能得出一个结论,所谓分组,其实就是普通的正则匹配加上分组条件的匹配集合。
8.断言
断言是个好东西,能够解决许多比较棘手的问题,比如上面的例子,我想拿两个标签中间的文本,采用分组去取,是可以实现,但是就看每次都要拿匹配结果的第三个数组,有点不爽,怎么办呢,断言可以帮你解决这个烦恼,匹配的结果直接是文本。断言的基本规则如下:

从基本规则中,我们可以从字面上得出,断言可以设置一个文本前后的匹配规则,我们可以将匹配标签中间的文本规则改造如下:
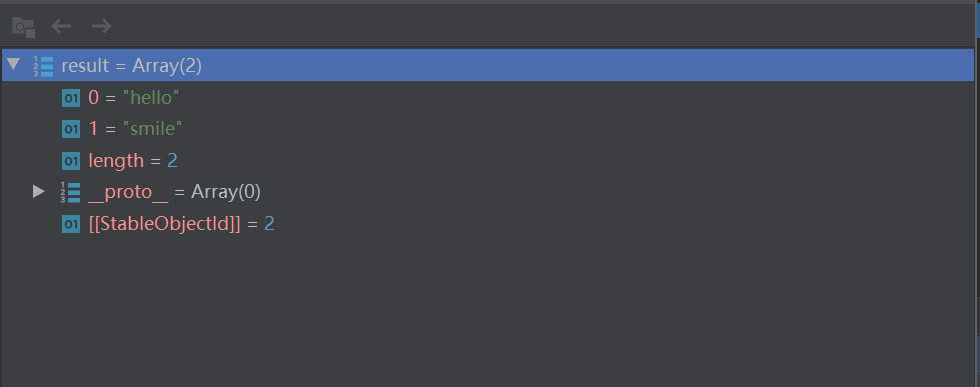
let matchSpanTextDescribe = /(?<=<span>)(\S+)+?(?=<\/span>)/g
let result = str.match(matchSpanTextDescribe)
匹配结果如下:
参考资料:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp#boundaries

 浙公网安备 33010602011771号
浙公网安备 33010602011771号