
汤森路透 Thomson Reuters --使用多模型数据库ArangoDB 打造快速安全的简洁视图分析
技术不断改变企业。我们汤森路透(Thomson Reuters)一直致力于利用技术,使我们在业务过程中收集的信息更具相关性和更个性化,同时更快地向我们的客户和员工交付信息。通过使用共享平台并在我们的业务部门工作,我们希望使我们的数据更易于访问和深入我们的人员,无论通过哪种渠道。
为了促进这种方法,我们希望创建一个复杂的业务分析和智能(BA / BI)平台,为所有汤森路透员工提供一切视图。这是一个相当大的挑战,因为我们必须将包含半相关数据的许多不同数据源集成到不同的结构中,以满足多个部门和角色的各种需求。
选择正确的数据存储
对于数据访问和管理,很显然,我们需要一个快速,无模式的数据存储来处理我们的BA / BI应用程序中越来越多的非结构化数据。我们的应用程序使用了二十多个数据源,提供了各种信息。这需要一个强大的查询语言,能够表达我们员工想要快速回答的广泛问题。
一个关键的要求是支持即席连接,以及图遍历,为应用程序的不同部分使用正确的数据访问策略,并能够提出更多的问题。我们的选择是开源代码解决方案,以及一个积极响应的社区。
为什么我们选择了ArangoDB ?
首先,ArangoDB是一个真正的开源项目,具有开发者友好的Apache 2 许可证。另外,其背后的团队非常友好且透明。经过相当短的调整阶段,我们便开始沉迷于ArangoDB查询语言(AQL)。对我们来说,用AQL 编写查询非常直观,我们可以利用各种各样的函数和数据访问模式。 AQL 更令人称赞的方面是它使用嵌套的FOR循环来组合查询。因此,使用AQL 编写代码和写入查询之间的转换非常顺畅。他们的”多模型“ 方案以及在AQL 本地连接和图表遍历的可能性也非常好, 因为有时在相同的查询中结合连接和遍历是很方便的。
另一个重要的是ArangoDB 的微服务框架Foxx。我们使用Foxx 相当频繁; 我们已经为我们的应用程序创建了二十多个Foxx 服务。坦率地说, Foxx 入门有点难:文档可以进一步改进,更多的示例或最佳实践都会有很大的帮助。不过,目前ArangoDB 团队和社区支持已经缓解了这一缺陷。他们非常专业,也很积极回应。这是我们决定使用ArangoDB 数据库的原因之一。
目前,我们在ArangoDB中存储了270GB以上的数据(转储到408GB的磁盘)。随着数据量的稳步增长,我们很快将转向三节点集群,主要是为了提高可用性(参见下图)。
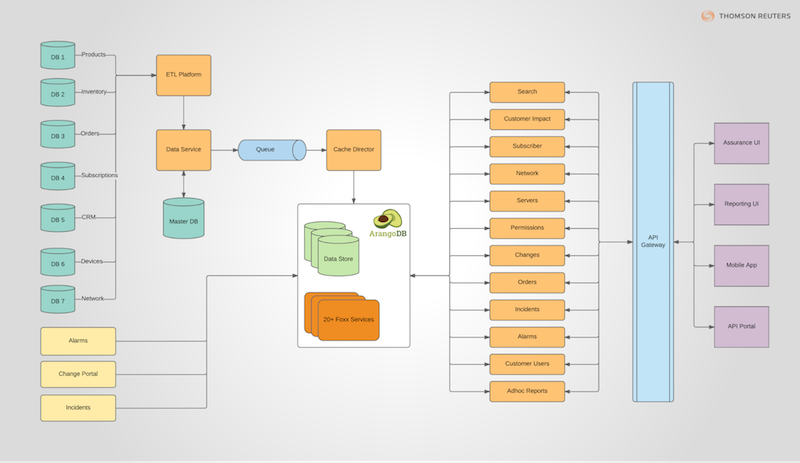
我们当前单节点设置的设置是24个vCPU和512GB的RAM。对于集群设置,我们计划为主设备使用相同的机器。
我们的应用程序本身是读/写密集型的,在高峰期每秒至少有三次写入和每秒两千次更新。我们体系结构中的队列有助于阴影写入,甚至可以加载ArangoDB。读数一般稳定, 我们预计不会出现大规模的高峰。
我们从ArangoDB 中获得了什么 ?
首先,我们了解到,在查询中结合不同的数据模型实际上是可能的,有时也是非常有用的。查询运行速度非常快,AQL 非常直观,即使我们的产品负责人和业务分析师现在也在写相当容易的超过二百行的庞大查询。有时候他们不得不问哪个索引应该被使用,但是大多数查询的性能都可以接受,而且不需要额外的工作。
Foxx 框架帮助我们大大减少了我们的开发时间。正如我们将与许多REST 服务集成一样,我们过去为集成测试编写了大量的模拟器。现在REST 服务可以随即由 Foxx 得出。我们还可以定义自己的路由,这样运行的数据不必发送给客户,相反,它可以在数据库中进行处理,之后只将结果发送给客户。通过这种方法,我们可以减少很多麻烦,并在需要时提高安全性。对于我们来说,Foxx与ArangoDB 提供了极大的帮助,使用经验也非常棒。
总的来说,我们现在可以将得所需的所有数据 --保证,报告,移动,API门户-- 在一个地方获得,从而提供快速和安全的访问。 AQL的灵活性,以及不同数据模型的组合,可以轻松地获得所需的查询运行和优化。由于Foxx和AQL,我们轻松地扩展了应用程序的功能。这样我们可以将更多的时间花在实际的应用程序开发上,并更迅速地获得所需的结果答案。毕竟,我们被称为“答案公司”。
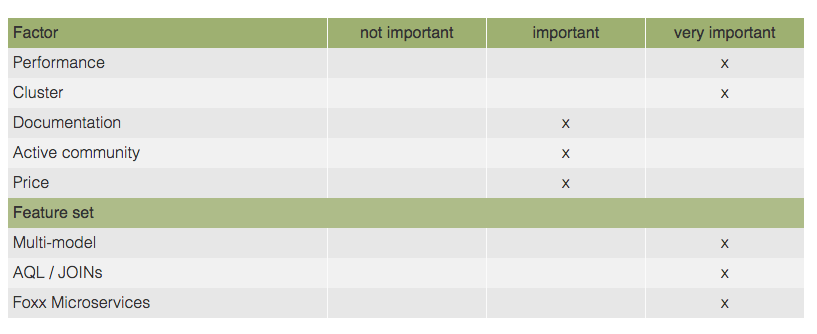
关键特征的重要性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号