
项目:从零开始做一个HTTP服务器(准备篇 —— 无尽弯路错路)
我的牛逼追问知乎直答链接分享
豆包问答链接分享

截图
知乎直答找项目问答分享(不再贴图了)
感触:BOSS直接找项目主管


1 自己自言自语了无数遍面试自我介绍开场白,没任何经验,就最直白最真诚的语言讲述自己这几年的经历和思想,并提供类似比赛或者项目来证明我的兴趣、驱动学习能力、细心好研究有想法。通过这些也说明我并不是一个游手好闲的人(几年空窗确实不好搞) 2 3 2元烤肠针线破袜子洗衣粉眼镜托都不舍得花,给阿辉高考椅子,给父母逢年节日花红包吃的车厘子猕猴桃毛丹山竹肯德基蛋糕, 4 5 回忆二哥看网络编程、王钰涵 6 7 8 9 10 11 给阿辉买椅子 12 从22:30到现在一直给阿辉搞他填报的事 13 14 1h耽误自己 15 16 17 18 19 乐于助人 20 思维拓展能力 21 联想 22 发散思维能力➕非钻牛角尖,刨根问底研究问题本质底层逻辑 23 24 一步步见证。背书, 25 二哥东北大学 26 不需要说什么 27 编程指北名头 28 可我。。。 29 30 31 32 33 没成家没对象 34 就想在这行多学点东西多点赚钱 35 36 我带骑行团,朝气 37 38 我好研究 39 不然我也不会辞职饿肚子一直自学C++开发,我会继续外包待下去。哪怕饿肚子也没有想过再去外包公司 40 我对算法感兴趣,也不会刷题打比赛,这些其实我知道对找工作好多人都说没用没帮助,但我还是坚持了下去,就为了找学习状态(虽然发现没啥关系好像确实没啥用) 41 但我很享受其中 42 43 44 blue祝峰:你学发现哪里不对头可以再找我,咱们再分析分析 45 他很中肯 46 47 父母赡养 48 总不能就这么算了吧 49 50 51 52 53 世界就是一个巨大的草台班子 54 55 56 ---------------------------------------------------------------- 57 1. 58 之前spyder 59 找到 60 61 2. 62 之前感觉自己遥遥无期 63 一无是处穷途末路 64 如今知乎直答豆包给了信心 65 尤其是一些C++真正的项目:http服务器,好兴奋 66 尤其是量化投资高频交易 67 (知乎评论好多劝退,如果不知道那次浙大考研最牛逼的说高频交易一辈子都不会知道,知乎只知道游戏) 68 (说真的学会了信息壁垒这个词。之前只觉得真的好难,消息不灵通,根本周围没有懂的人,就很难搞。我认识了那些“贵人”,虽然可以联系,问,但基本不好意思去问啥。 69 但总觉得一旦用上了内卷,信息壁垒这些词,就没之前的思维深度和广度了 70 71 更别提我悟出来的这些东西了 72 我自以为牛逼开悟透彻,也确实,但别人真的很难懂) 73 真的没经历过确实不会懂的 74 75 而我这些,技术那些玩意,以后的路怎么走,哪怕处在高中,为没办法从任何渠道体会到真正的大学。 76 曾经我低谷时候22年问知乎问所有贵人(唯独郑浩然撂脸子呲牙了跟我),可是我已经迷茫 77 曾经我想过问究竟考研工作。问了工作的人,问了研究生的,啥都问了,(哪怕知乎值乎哪怕找到行业厉害的名气大的直接转账红包有偿解答这些“信息”方面的问题,也不行,因为人是环境的产物,不在那个环境真的太难了。除非问技术)无论怎样权衡,都会想不到。或者说无论怎么周到详尽,都无法真正的懂或者决策。 78 因为没趟过一遍 79 贺炜:“无论怎么未雨绸缪,当初可他们一样渴望的年轻人,显微镜研究” 80 我实况足球,魔术 81 82 【曾经我以为不要太过度 83 84 其他人也该像我一样“自私”精致利己了 85 86 可是发现中国的底层韭菜海厚海后的 87 88 他们的认知 89 一辈子改不掉了,自己骗自己 90 疯涨啥叫韭菜,真的是韭菜海厚海厚的 91 不用担心乱套 92 他们就是这个思维 93 根深蒂固 94 —————————— 95 他们的单纯善良 96 好拿捏 97 98 真的无法改变刻在基因里的 99 所以狠狠的杀就行了 100 101 狠狠的宰就行了 102 —————————— 103 我看到的太多了 104 105 立志!! 106 —————————— 107 狠狠的吸底层人的血,一滴都不要留,他们就不值钱。像我们这种底层人的命就不值钱。以后我翻身了,就会吸这种底层人的血,我也想活着。】 108 109 3. 110 现在找 111 难念的经 112 天龙八部 113 114 115 ************************************** 116 我已经找到了linlinsong:改变性格,想你呀,捡瓶子,山东菏泽奶草鞋,怒了刷题,依然自由自我,⭐不知道第几次学吐了 117 ⭐我已经体会到王钰涵。那时候的绝望,还在用qq,转专业不成(我想不起那时候怎么安慰的了,也不想再去想了) 118 119 但王钰涵他好乐观好低调 120 但我真的看不懂他 121 122 大头哥哥。“在不公。医大一,欺凌下长大的不可能这么善良” 123 124 ⭐我想到了那个北邮294分,上岸计算机院,那时候还没合并,19年考研的。自己大学弄了无数项目,自己租服务器。 125 我如今。 126 也确实 127 可怜巴巴的?“我电脑是17年买的”,之前弄过乌班图但磁盘空间不够用了,就租了一个 128 算了这些事只有自己知道就好了,沉淀 129 130 131 好想找王钰涵和祝峰哥问问唉 132 133 我tm的问豆包和知乎直答回答考虑的不知道靠不靠谱,大模型对技术解答的还行,但大方向有点墙头草不靠谱,而我认为最权威的知乎搜“自学c++要不要租服务器” 134 根本差不到 135 X﹏X 136 137 138 139 饿肚子租服务器 140 297分最低上岸那个扛起大旗 141 贴吧认识的那个,自学谷粒商城Java那个,入职一周后才知道啥是服务器 142 143 144 用云服务器简历镀金(本地装Linux无法证明生产环境能力,面试官会质疑“真用过吗?”) 145 真的用过吗,真会用吗,真的会用吗 146 147 148 149 真的不再熬夜真的虚弱了,虽然之前也熬夜虚弱,但脑子昏昏沉沉精力脑力不足 150 更加懒得看周围,纷争沟通 151 有事可做linux更加专注了,有目标有挑战了压迫斗争,回家不再看电视剧视频啥的了。也是兴趣,紧迫 152 153 美色也没了(之前是纯没性欲了)(培养杀伐果断无法识别容貌颜值了之前是) 154 155 156 王钰涵或者阿辉燕北可能有服务器,唉算了
真的感觉培训班或者小伙伴一起搞、最好有人指导有人带,我tm误入歧途踩过太多坑了。很多都不知道要不要学,自制力和学习技术问题不怕,就怕方向弄错了,
-
指的是xx要不要学,别tm学半天发现这玩意都废弃了比如CGI编程。(windows下弄那三条命令,又弄vim)
-
还有方向,不知道要不要用 Linux,唉~~~~(>_<)~~~~
- 妈逼的刷的邝斌算法是冷门的KMP、并查集
▶我好崩溃啊
之前从CGI学安装不上库(说过时了),到弄http服务器项目,知乎直答说看《Boost.Asio C++ Network Programming》(2nd Edition)搞boost,找半天电子版到处找不到,再查又说 Boost也过时 了
哎不管了,硬头皮弄吧
弄起来发现不那么想弄他的OJ项目了
不那么想去华为OD了
把知乎直答的东西贴过来方便看
▶妈逼的图书馆也没有这书,网上PDF也没有,今天下午刚来图书馆找了本《 Visual C++网络编程》 ,查说值得看吗?然后知乎直答给出了一大堆东西,好tm头大啊,需要掌握的东西都还没学,直接差点给我劝退这行了。根本不知道从哪里入手了~~~~(>_<)~~~~
▶先找B站视频看吧,说的码农有道还没有这个up,找了其他视频
▶B站2小时视频《C++ 从零开始构建后端技术栈》课程介绍》
博主文章
仿佛内功,有信心搞好
-
他那个代码重构也很适合我,C语言风格 → C++
-
很多契合我之前刷的算法题,7集里的4′54″那块:IO多路复用,算法里叫离散化
动态改变着
发现知乎直答上的建议根本不可行,什么一天,方向方法还得自己看视频动态调整
而且发现之前思路是做完什么就可以找了,现在看感觉说是高级教程,我有种感觉不是全学个大概,真的就是学个七七八八就找,因为东西确实太多了,写着这部分是高级教程,学个碰上哪个加点运气找到个工作就行了
之前方法真错了,不应该看菜鸟教程,浪费那么久。哎~~~~(>_<)~~~~我这水平其实可以直接自己跟着做项目的,总感觉要学C++的知识
而且发现tmd需要安装Linux艹了!
管道的那个代码用不了,跑过去追问大模型之前都没提要用linux的事,~~~~(>_<)~~~~
唉,都很坑啊~~~~(>_<)~~~~╮(╯▽╰)╭
我现在突然发现照着大模型学习有点扯纯几把蛋啊艹,大模型有点墙头草的意思
好难受,要不是知道高频交易量化交易金融真的就放弃了,唉~~~~(>_<)~~~~,好难啊。
▶B站《动力膜拜!斯坦福大佬竟把C++讲的如此通俗简单!整整600集,草履虫都能听懂》, (只看了一集)(为什么学C++)勇气(之前张俊黑哥)(但都没提到高频交易量化交易)
C++指的学习的四个特性:
-
智能指针
-
右值引用(rvalue reference)
-
function/bind救赎
-
lambda和闭包
好烦,看书太慢,看视频,可是很多都讲的好水好水啊,《华为大佬竟把C++讲的如此通俗简单!整整600集,学完即可上岗!》,妈的都没自己看他的PPT快,可看ppt是下策中的下策,不如根据目录自己问豆包,但之前菜鸟教程这么学过了,这次打算手写,但后来发现也不行,根据目录自己追问豆包感觉很飘渺架空楼阁,感觉会欠缺很多基础找不到重点,都不知道要查啥,没一个宏观的框架体系,现在都不知道该从哪里学起,好他妈烦啊!!~~~~(>_<)~~~~~~~~(>_<)~~~~
-
基础视频课讲的好多都是会的,又不敢快进怕错过内容,太JB墨迹慢浪费时间
-
而直接看项目课(好多都他妈钓鱼收费的虽然无可厚非但对我不利,得辨别)我连软件都不会用(视频里让你点开编译器软件里的啥啥啥,我他妈版本不同一会汉化一会英文的妈逼的都找不到地方艹),Linux命令行也不会,基础语句语法也不会,可以说啥都不会(各种环境、系统、一些语法、技术啥都不懂最主要是编译器啥的),很跳跃,但算法和自学C++的强大内功,又不需要那些基础视频
总结起来就是没有讲的又有基础又符合我超强学习能力(该快的快,该慢的慢),又直接面向项目的课
回顾自己追问豆包参考菜鸟教程学C++两个月仿佛啥都没学,仿佛又会点,因为之前每个地方研究的太细太细了,没宏观的认知,啥都接不上,应用不起来,现在一步步学会了怎么找视频,哪些值得看,都是成长进步,及时分辨很水的视频的能力
回忆刷题第一天和看C++第一天写的博客,很多东西都因为讲的不好很劝退
这个《C++网络编程,从Socket基础到Epoll》很好(可能不适合很多人,但他讲课的思路理念真的太适合我了!!一级棒,知乎直答推荐的也好棒),不是先讲什么各种管道我tm代码运行不了还得搞Linux系统,各种类似枯燥的定义似的,很多视频看了跟没看一样,他的不错
图书馆走的时候发现了《TCP/IP网络编程》,踏破铁鞋无觅处,得来全不费工夫!
明天起直接看这本书,比看视频好,可以自己改变看的速度!书写的很好很有针对性,感觉比《 Visual C++网络编程》好多了!
调整作息
《C++网络编程,从Socket基础到Epoll》视频先略过
- 每天记录收获不然还是啥也没学会(知乎直答给出的建议)
-
半个小时想不懂的东西及时处理,有个意识,别耗下去(知乎直答给出的建议)
-
早这么弄就了,确实走了很多弯路(烧饼)
- 越有压力越牛逼,绝处逢生开出绝处的花(岛娘台阶微弱WIFI信号打codeforce借着散热器取暖)
View Code
——岛娘微弱打codeforce唯一一个HIT进去微软但没毕业的,同系说确实厉害 ——王钰涵边考研边竞赛管理 ——linlinsong 竞赛 绩点 管理 单弄一样我早无敌了 ——阿辉,饿骊山,弄车没钱,真的是绝处逢生更牛逼 ——穷人家的,中科院博士 ——路上风雨大风太冷刺骨 查粤语就是想学,到家安逸不冷没大风就不想查学了 -
学了linux基础命令操作,文件描述符句柄,知道大概通信网络编程咋回事了,这座大山啃下来,开门红,接下来就砍瓜切菜了,我一直以为网络编程很难无从下手所以一直毫无进展(其实基于B站码农论坛的《C++网络编程,从Socket基础到Epoll》讲课风格开了个好头,这本书和B站这个码农论坛的风格一样,都是从一个宏观框架,知道都啥东西,才有兴趣有信心,不至于茫然的把这些当做一个大山一样始终无从下手无头苍蝇没进展(烧饼),那些上来就tm讲http讲TCP讲管道讲协议直接看什么ppt的就纯他妈误人子弟的傻逼。我之前就在这栽跟头了又想死磕唉╮(╯▽╰)╭ 毫无进展毫无收获
二哥大二拿本网络编程
开始啃《TCP/IP网络编程》读书笔记
-------------------------------------------------------------------------
Part 1 开始网络编程
第一章
豆包问答链接分享,太卡被迫新开
初入学习网络编程,各种工具、所用系统、
errno结合strerror用的,C/C++ 都用
errno(当像 socket 这类系统调用或库函数执行出错时,系统会自动给 errno 设置对应错误码)、
strerror(把这个错误码转成人能理解的字符串)、
cerr(无缓冲,对比cout理解,差别就是立马输出,C++的)、
stderr(无缓冲,输出到屏幕,结合fputs用,C的):
-------------------------------------------------------------------------
| Linux: | windows: | |
| 服务端: |
socket创建 bind绑定 listen转为可接受请求状态 accept受理连接请求(没请求一直等待) write用于传输数据(到了这步证明有了连接请求) close关闭 |
WSAStartup初始化套接字库 socket创建 bind绑定 listen转为可接受请求状态 accept受理连接请求 send向accept调用传输数据 closesocket关闭 WSACleanup注销创建的初始化套接字库 |
| 客户端: |
socket创建套接字 调用connect函数向服务端发送连接请求(先服务端listen后才能调用connect,不然connect失败) read close关闭 |
WSAStartup初始化套接字库 socket创建 connect发出连接请求 recv接受服务器传来的数据 closesocket关闭 WSACleanup注销创建的初始化套接字库
|
| 差异 |
Linux里也有windows的send和recv 只是Linux内把套接字视为文件(I/O相同,直接用文件I/O),所以直接用write和read |
|
第一章习题
学C++好烦会遇到好多格式语法,相比刷算法题自由惬意享受其中舒服的多,C++好多库、宏乱七八糟的看不懂的玩意,查一个说XX定义的XX里有的,查一个说XX定义的XX里有的。架空楼阁的学习体验真的难受
文件各种东西语法格式好TM烦~~~~(>_<)~~~~,习题涉及到的太深了,先学后面的章节吧
-------------------------------------------------------------------------
第二章习题
豆包问答链接分享
-------------------------------------------------------------------------
感受:
-
有意识的计算规定时间内看了多少东西做总结,(考试周破防北理工1h好几十页书)
-
改掉总纠结细节的毛病,带着朦胧看下去,后面见多了就理解了,看的还快,不然一页一段话耽搁纠结半天太低效率了
- 看书心得成长:之前总是一个点不懂立马研究,问豆包,甚至自学很深很细后来发现都是接下来会讲到的,所以逐渐开始看不懂也带着不懂继续往下看,既快又高效率
第三章
-------------------------------------------------------------------------
P76页的echo_server回声那段挺值得多看的 —— 个人觉得对比第二章课后习题,那个多次读写可以理解下
| 关于服务端套接字 | 参数 |
| write | 要写的地址,写的内容,长度。(返回字节数) |
| read | 要读的地址(数据源的文件描述符),写入某位置,长度。(返回字节数) |
| accept |
服务器套接字描述符,请求的客户端地址,客户端地址长度 |
| connect |
客户端套接字描述符,目标服务器信息,长度 |
╮(╯▽╰)╭唉,为什么我学东西要这么费劲~~~~(>_<)~~~~
好饿啊,真的感觉浑身好虚弱,可是又没钱吃饭,头好晕,脑动力已经枯竭了
~~~~(>_<)~~~~
应用层HTTP FTP
传输层 TCP UDP
网络层(IP层) IP协议
数据链锯层
-------------------------------------------------------------------------
第五章
豆包链接分享(5.1那个计算器示例过去复杂,单独分出来)
豆包链接分享(5.2开始 ~ 习题)(相当细节,值得看)(但最后混用了freopen、rend、recv啥的,书里暂时没介绍,懒得提前浪费时间看了)
链接里搜
“那你现在再把这个过程从客户端怎么建立的,怎么发起请求的,服务端怎么写的,怎么相应的,说下,仅仅用几行关键代码来说就行,禁止帖完整代码”
结合
第四章的链接里搜的“accept书上说addr参数调用函数后向传递来的地址变量参数填充客户端地址信息没懂””
配套理解整个执行过程(其实书里的代码,clnt_sock写成new_sock,且用的时候再int而不是一开始就int更有助于理解)
熟悉后发现,防止TCP无数据边界所做的事,就是加个条件而已,对刷题的思维真的小儿科,但应用上各种自带的函数、参数,就很唬人,仔细研究后发现真的简单
豆包的优势,我这种人很适合用豆包,简直如虎添翼,我会想的很细心,研究的很深,附上我的牛逼思考,链接里搜“但有个疑问,服务端不用做啥限制吗”
★★★★★
(当然需要平衡,不要想太多,因为发现豆包的解释很多都是后面才学的,研究多了浪费时间,很不划算)。
这也是思维缜密度的痛苦, 微信搜,专家程序员猴子问题,垃圾公司里活不下去
现在打算不考虑那么多,讲的理解就好,不然看书速度太慢了。
★★★★★
链接里搜“给我代码,还是根据TCP/IP网络编程这本书和我目前看到第五章的 这个程度给出”
更加深刻理解了客户端服务端的数据传送的流程其实没任何难道
ASC表:深入理解char
#include <stdio.h> #include<iostream> using namespace std; int main() { char a = 51; cout<<a<<endl; printf("%d\n", a); printf("%c\n", a); cout << static_cast<int>(a) << endl; cout<<endl; char b = '3'; cout<<b<<endl; printf("%d\n", b); printf("%c\n", b); cout<<endl; char c = 18; cout<<c<<endl; printf("%d\n", c); printf("%c\n", c); }
~~~~(>_<)~~~~好饿 头好晕 饿的营养不良了 饿的瘦了眼睛都大了~~~~(>_<)~~~~
反复多次重复,一次可能懂一点,搜“人情世故”
像按指纹一样,不断扫描重复直到完全扫描完
问邮储组织架构,都没人问~~~~(>_<)~~~~
呼气都是颤抖嘚瑟的 我会不会死在这里 外面的东西都不舍得买,2块烤肠也不想买,啥都买不起 我只想去买维族人卖的那个1块钱的坚果巧克力,可是好远,耽误时间 一个月的自己交的养老就要908.4 医疗就要最低档都没了,23年后默认都是最高档要自己交,一个月医疗就要725.15元 一个月自己交钱就要1633 唉 我要做这种喝老百姓血的坐那就可以一个人收这么多钱 管你死活? 人真的是环境的产物 不经历不会懂
书上的代码相当之坎坷 P87~90
加上协议后真的好复杂
三次握手:
A主机向B主机:[SYN] SEQ:1000,ACK:-
B向A: [SYN+ACK] SEQ:2000,ACK:1001
A向B: [ACK] SEQ:1001,ACK:2001
书里提到的这里有源代码
-------------------------------------------------------------------------
第六章(每章都是包涵习题的)
| UDP 没固定客户端和服务端 都是返回传输字节数 |
|
| recvfrom | sendto |
| sock套接字描述符 | 同上 |
| 存到哪里 | 发送啥内容 |
| 最大可接收字符 | 发送多长 |
| 0 | 0 |
|
存有发送端地址信息 的结构体变量 的地址值 |
存有目标地址信息 的结构体变量的 地制值 |
| 保存上一个参数的长度的地址值 | 保存上一个参数的长度那个变量的地制值 |
| 对于后两个参数,需要先指定最大的大小,然后实际接收完会更新对方的信息的 | 而这个发送的事先可以知道接收端的大小,地址信息啥的 |
上面俩函数研究透彻后,书上代码会看那的很舒服
TCP的客户端在运行时候输入服务端IP和端口 然后connect的时候给自己自动分配IP和端口
通过课后习题那,自己的牛逼追问,逐渐懂了
应用层、传输层、网络层、数据链路层,是咋协调工作的
-------------------------------------------------------------------------
第七章 (相当多的 细节 和 基础,这一章对我来说全是 精华 ——真正的量变产生 质的飞跃 质变了)
附上我的豆包牛逼追问链接分享 (所有说的 链接搜 都指的是对应章节的豆包链接分享里的)
学到这里,之前每天6/7个小时但其实所学的东西如果说起来其实就是些很简单的东西,但很值得。
因为更加熟悉了网络编程的风格、思路,各种边边角角重点的东西都有,学的很充实,很有体系,很完整
P120,关于半关闭的好处,目前没法体会!!!
书里解释的在我追问豆包后发现完全无法自洽
可能涉及到后面的很多东西,所以先用个障眼法来蒙骗着解释,很多不思考的傻逼就信了
懂了懂了书中P74说调用close,是向对方发送EOF,即read()会返回0 ,基本也到了close那里
为了防止无限的读,需要设定一个结束符eof,但设定后就无法接受后面的thankyou,所以选择关闭服务端的输出流。这样依旧可以有接受后面传来的thankyou
关于close和EOF强烈建议看链接里的
搜“等下,“当一方调用close关闭其套接字的写端时??” close不是啥都关了吗?咋就关闭写端”,不写出来是因为单独写某句会断章取义造成误解,读原汁原味的身临其境的解释会更靠谱
关于
Linux的open:返回的是
windows的CreatFile:
通用的C库fopen:返回的是、有缓冲
| 对比 | Linux的 open read write 是底层操作 |
Windows 无标准open那些 用CreatFile ReadFile WriteFile |
跨平台 fopen fread fwrite |
| 所属库 | 系统调用 | Windows的API函数 | C库(基于read和write封装) |
| 返回值 |
open返回描述符(整数) write和read返回字节数 read读到文件末尾返回 0,出错返回 -1 |
句柄(类似指针) | FILE指针 |
| 缓冲 | 无(可手动设置) | 无(需手动管理) | 有 |
| 场景 | 底层文件操作,比如操作网络套接字、硬件设备文件等特殊文件,以及需要精准控制文件访问的场景 | 普通文件的常规输入输出操作 | |
| 语法 | int fd = open("test.txt", O_RDONLY); |
懒得写,用得少,还复杂麻烦
|
FILE *fp = fopen("test.txt", "r"); |
| 说明 | 打开test.txt文件用于只读,fd为文件描述符,O_RDONLY是只读标志。 |
打开test.txt文件用于只读,fp是指向FILE结构体的指针,"r"是只读模式。 |
read函数先将数据从磁盘读到内核缓冲区,再读到用户指定缓冲区。
read比fread慢的原因想通了,链接搜“但read也有用户指定缓冲区啊? 如果读到一样的不依据可以从缓冲区取吗”
提一个ifstream、ofstream,太乱,没空搞清差别,链接搜“ifstream和ofstream是 C++ 中用于文件输入输出的流类”
哎强迫症发散思维遇到什么就展开联想学很多,效率好低好累好痛苦啊
博客园好像搜索关键词找文章只能显示近期的,之前都还有的,现在怎么都搜不到了,之前博客整理过getline(),腾出功夫好好修理解决
-------------------------------------------------------------------------
第八章
指针,花了很大精力深入了解!
真的太透彻了!懂完了相当爽
-------------------------------------------------------------------------
第九章
附上我的豆包牛逼追问链接分享(习题加本章学习内容)
学到了缓冲并不一定是数组
另外貌似是C++的风格,封装淋漓尽致,就比如书上P143,起初感觉写的好der,15行代码的是&len,这里的len起初是socklen_t类型的,之后又有个int snd_buf,然后又sizeof()了一下snd_buf,又把这个值给了len,后来才明白大概是层层封装+可移植性!
好后悔刷acm邝斌专题,好后悔学算法,唉~~~~(>_<)~~~~。
年轻的时候说不后悔,乐趣,那就是自己意淫,自明清高最后下场就是要饭,我连个工作都没有,谁甘心给别人做嫁衣啊,别人都拿高薪工作了,我每天饿肚子浑身虚弱低血糖饿的头晕眼花吃不饱饭,自己还要饭呢。
怀疑质疑自己,虽然我有信心,不需要清晰价值,坚定自己,可是每天饿肚子真的很难受,切切实实学到的东西又不知道有没有用
-------------------------------------------------------------------------
第十章
牛逼追问豆包链接分享(太卡了,先分享10.5之前的内容)
我的牛逼豆包追问链接分享(10.5之后到习题)
系统学习真的太爽了
学会有问题不先思考,带着问题读完这章,最回头看,这种妥协会提高效率
P161 自己试验把代码修改了下
说是“僵尸进程是指子进程已经结束运行”才有的,我把子进程也sleep了,结果发现确实,就没Z+了
好他妈难受
我就上海和北京这俩地方,且有算法基础(刷了一些u邝斌算法,自己钻研了很多很深的细节),但我是96年的,大学毕业的时候爸爸有病照顾家人,导致空窗待业好几年,我现在想自学一步步接近这个目标,每天都学习,哪怕工作后也是(现在没工作)薪资大概多少?目前只有一年的银行外包测试的经验,已经辞职了
链接搜“这么低吗”
真tm打击人艹,妈逼的我之前问也不是这样的啊唉~~~~(>_<)~~~~ 知乎直答 真他妈能扯淡
心灰意冷,这么多心酸经历学,最后入职工资可能都比之前的傻逼银行外包测试7300工资还低,艹,~~~~(>_<)~~~~
真他妈想哭的心都有了,唉,事与愿违 (想起了学吐的linlinsong、转专业的王钰涵)
唉,这么不堪吗?你能不能好好回答啊 我之前做银行外包测试,就是因为没前途,大家都糊弄,我做事认真好钻研,在这里根本活不下去,会的算法又用不上 我自己离职自学刷了邝斌专题BFS、DFS、并查集、最短路、最小生成树、KMP这些,自己都有很深研究 学了C++语法,目前在啃TCPIP网路编程,怎么到头来完全看不到希望呢
这段代码研究的真费劲,唉
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <signal.h> #include <sys/wait.h> void read_childproc(int sig) { int status; pid_t id = waitpid(-1, &status, WNOHANG); if (WIFEXITED(status)) { printf("Removed proc id: %d \n", id); printf("Child send: %d \n", WEXITSTATUS(status)); } } int main(void) { struct sigaction act; act.sa_handler = read_childproc; sigemptyset(&act.sa_mask); act.sa_flags = 0; sigaction(SIGCHLD, &act, 0); pid_t pid = fork(); if (pid == 0) { puts("Hi! I'm child process"); sleep(10); return 12; } else { printf("Child pid: %d \n", pid); pid = fork(); if (pid == 0) { puts("Hi! I'm another child process"); sleep(10); exit(24); } else { int i; printf("Child pid: %d \n", pid); for (i = 0; i < 5; i++) { puts("wait..."); sleep(5); } } } return 0; }
知乎直答也没解决
1、为啥输出了6个wait?我是租用的腾讯云服务器,别说那些代码错误、负载、硬件坏的那些不可能的胡扯屁话!!
2、为啥我只输出了一个Removed
3、为啥我Removed之前,输出了总共4个wait???
算了姑且当作什么系统的一些逻辑吧,只理解理论结果就行
多进程并发服务器的代码解释,链接搜“有点懂了,再详细解释下,禁止代码,”
-------------------------------------------------------------------------
第十一章(问题很多,学到很多,所以分了12345...这样,每个里面的链接,都是一段收获,只是太长太卡,才另起一个)
1、傻逼智障豆包问答链接分享(自相矛盾,无限重复无意义话语分,放弃豆包)(毅力邝斌)
2、无奈通义千问更垃圾,用豆包问了一天 vim 复制问 分享链接
3、vim复制到系统问题、个人感觉很精彩很有收获的进程代码(搜“只需要解释”)、vim游戏、回忆盲打软件、抢先一步github、公钥私钥加密、太卡了 分享链接(第一次超过了500条,无法分享,只能复制链接了)
4、链接分享,(回顾第十章的10.3)附上我的牛逼追问,深刻研究钻研,想的很深、很多、很细致诡异问题,链接搜“这里好诡异啊!”,个人感觉status貌似应该先随便赋个值,学到个挺有用的玩意,链接搜“示例修正逻辑”
while (waitpid(-1, &status, WNOHANG) == 0) { // 子进程未结束,可执行其他操作或sleep }
// 子进程已结束,处理status搜“那你一开始说2次,误人子弟??”已经可以给豆包挑错了
vim、高频交易违法?量化交易,C++不好锁死业务,搜“客观评价这个人的回答”
一大胜利,搞懂俩fork
改进:给书里的 P189代码完善(回忆之前刷算法题的时候,给网上一些博客里WA的代码不能AC的,给他改AC,夏天群、手把手教HIT和BUPT研究生上岸):哎给别人做嫁衣,改代码毫无意义。又给TCPIP网络编程的代码逻辑纠错
bind error解决办法:
// 在创建套接字之后,绑定之前添加以下代码
serv_sock=socket(PF_INET, SOCK_STREAM, 0);
// 添加设置SO_REUSEADDR选项的代码
int optval = 1;
if (setsockopt(serv_sock, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval)) == -1) {
error_handling("setsockopt() error");
}
memset(&serv_adr, 0, sizeof(serv_adr));输入完后写入txt文件,但输入10次就固定写入结束了,且服务端就返回 removed proc id: 809484,但客户端输入还可以返回信息,只是不往txt里写了,而客户端主动Ctrl+C断开服务端还会输出 removed proc id 不影响
重开一个子进程也是显示new client connected...,但就是不往里写了,重启服务器才行。
而且按Q或者q虽然结束了但没往txt里写入,只有输入10次的时候才会写入
就算不改进完善也要只知道为啥出现这样的情况!也是一个了解很多诸如read、各种这些细节的好机会
把有些复杂的代码逻辑,自己说给豆包听,让他给我纠正,然后加深理解,搜“你把我的客户端和服务端代码以代码块形式给我”,从这这开始,这段代码真的太多学问了!!!尽管他可以说是个半成品残次品,但这是这本书的第11章,只是重点展示作者讲的一些知识点,而我自己挖掘出很多问题,追问豆包,对各种函数,指令流程之类的有了更进一步的了解!!
(豆包指令:从现在开始全面准确地考虑各种细节 精简回答所有问题!禁止贴代码!禁止展开没问到的东西!全是C++!全是Linux)(严格仔细参照全面分析代码)
很多东西研究的比工作好几年的人研究的深,改的代码bug跟大厂几年经验的人差不多,很多都不会让新人碰的(写书)
搜“我对这个代码彻底研究懂了”,逆天牛逼追问得来的深刻透彻理解,书上P189例子,研究的相当透彻、细致细节、挖的很深、钻研研究的很深。
这些都是我考虑的全面发散思维,细心、钻研研究、有想法的得来,追问豆包得来的,就单单这样,都有好多说错的地方,还是我费劲扒拉知道的收获,就这样追问每个细节,豆包都跟个傻逼一样呢(但已经是市面上大模型最好的了!),而你如果想让他说出我给的那段话,根本不可能!这大模型智障只能说,你表达完给你加以肯定,彻头彻尾的墙头草!!!,追问真的崩溃很累,还经常误人子弟
这第十一章收获巨大
熟悉了网络编程的风格
6、
停用垃圾豆包(习题开始),链接分享
神技Deepsee,唯独没分享,没法删除,没语音输入走路就没法骂他追问了,且代码块无法白色(只有当那些傻逼不用了,不那么火爆了,我才能用来正经学习)(后来发现也tm有时候误人子弟!)
习题+发现上一个5、里,关于Q退出的解释有问题重新进一步深入理解了
以上链接
以下本章正文,即开始展开1~6的链接内容,从链接1开始
自言自语
捷科作为符合社会运转逻辑
我错了
饭店肉坏了没人砸他店,我错了,我不应该进去
与公斗不如与几斗,这是人情世态为人处世待人接物。且解决给了我第一份工作我没资格说什么
可如果是技术的话,哪怕楼教主说的话我也会在脑海里判断思考一下,质疑权威
技术是技术
社交是社交
我看的很透分的很清
而对于外包的评价,我作为一个小小的求职者同样无法评价公司
说不好但有华为od这样我跳起来都进不去的地方(我是这样认为的)
但我之前的经历,痛苦折磨挣扎活不下去
我铭记梦魇粪坑
评判上一家公司这话可轻可重,怎样都不好,但
我用实际行动证明了
我在饿肚子最难受的时候,我没有想过考公务员
我没有想过再回去做外包
我一心想找个好的公司做开发,以后想做高频交易量化投资赚多多的钱
我的项目可能对你们来说,相比其他求职者很低级很小儿科,但我每一个都是自己实现的,我追问
罗斯
你们有些比我年长许多
有些比我差不了几岁
但在这个领域你们都是我的老前辈,都比我强
柳婼100分有资格徒弟
我现在菜,垃圾,但我一辈子都比你们弱吗?
我好研究钻研
我细心
我有想法
这是任何人都取代不了或者不输任何这个行业里的人的优势优点
我自暴自弃过,现在拉一裤兜子要自己收拾烂摊子
我浪费了,我自暴自弃那么多年
不会再放弃了
我不搞对象
不结婚32岁之前
我就想一心搞事业赚钱
高频交易
量化投资
高管管理
无数次的自己推演
又不想觉得是博取同情
自言自语
可是我有对未来30岁一事无成但有信心自己可以有所成就
梦想
高频交易量化交易
但我现在真的好饿,好痛苦,
每个月钱吃不饱饭
走路的时候自言自语,跟面试官说我的苦衷或者是我的的经历
为什么我之前工作
没有人喜欢
总是失败
哪怕结交什么处长
唉
可是有啥用
被辞退了
唉
唉
头饿昏却怎么也睡不着
无数次自言自语
对自己狠
对自己讲
对面试官?
心里话
我真的吃了太多的苦
周星驰
这一章P187那个解释27行的 和 上一章P181解释第62行的,追问豆包解释更易于理解
豆包又更新版本了,手机上传图片不会传完还是那个很长大上框需要弄第二次了
但网页版回答智障了许多!!!深度思考按钮也变了。而且深度思考连思考那些自言自语都没有了
用了这么久的豆包放弃了
做完还好好的,改版了现在彻底成了一个智障(之前起码追问能明白许多,现在追问彻底无限重复无意义的话语,彻底毫无逻辑自相矛盾了,怀疑是我用的过多被他们团队黑名单了只给我垃圾版本的~~~~(>_<)~~~~),改用通义千问(但通义千问安卓网页版没历史记录,还有1000字数限制,太鸡肋了)
唉上次豆包加入了深度思考没按钮的时候也是难受了几天,这回估计在整合什么,没开启完整版搜索模型啥的
妈逼的试了下通义千问还不如豆包呢!回答的更垃圾扯淡,墙头草
哎还是辗转会了豆包
一个vim复制代码搞了许久~~~~(>_<)~~~~好崩溃啊
TinyMCE妈逼的不知道为啥每一个新的换行,最开头都有一个空格,唉,超链接选择字体加粗和颜色还必须用TinyMCE
妈逼的vim复制是到寄存器,无法直接贴到win10
选择是到系统,所以可以粘贴到win10
妈逼的搞了1小时了
算了右键也不行,总之进入非vim普通模式就有问题
只好去掉行号
唉,弄完了依旧是复制到寄存器
真的无语,算了,问了知乎直答也听不懂。
真他妈无语了,vim怎么这么傻逼啊,复制个东西操!!C你 妈 逼的弄了一天!!!都没弄好!
哎选择复制到自己win10:scp root@101.42.164.217:/root/cpp_projects/main.cpp C:\Users\GerJCS岛\Downloads
又说一屁眼子的报错这他妈服了!
彻底放弃腾讯云的乌班图里vim复制到系统的win10粘贴,完全没有任何可行的办法!!
去你妈的吧艹
妈逼的直接cat main.cpp !!艹弄了一天任何方法都不行,只能这个cat,或者临时隐藏行号那么一页一页普通模式选中吧
垃圾玩意连个滚轮都没有
路上语音问豆包,就是放不下,到家试验到凌晨3点
妈逼的傻逼豆包,set clipboard=unnamedplus " 启用系统剪贴板支持
这句话居然是图形界面的玩意!艹!
应该按插件:vim-clipboard插件!艹捣鼓学习B站的SSH公钥私钥
(其实我没说清自己是命令行而不是vim图形界面)
哎安装插件的时候又说2021年起Github不用密码了,用SSH密钥了,豆包没解释明白,查了下B站解释:参考视频、Github公钥私钥实操。
然后发现https://github.com/roxma/vim-clipboard这玩意不存在了,没法装vim-clipboard插件了艹好烦!
换插件
算了这复制是死这了
代码啥提示没有可以接受,但要等到 g++ 的时候才发现问题,想搞个实时监测插件都安不上
好烦~~~~(>_<)~~~~妈逼的vim真他妈傻逼
复制问题搞1天半,代码插件搞一天
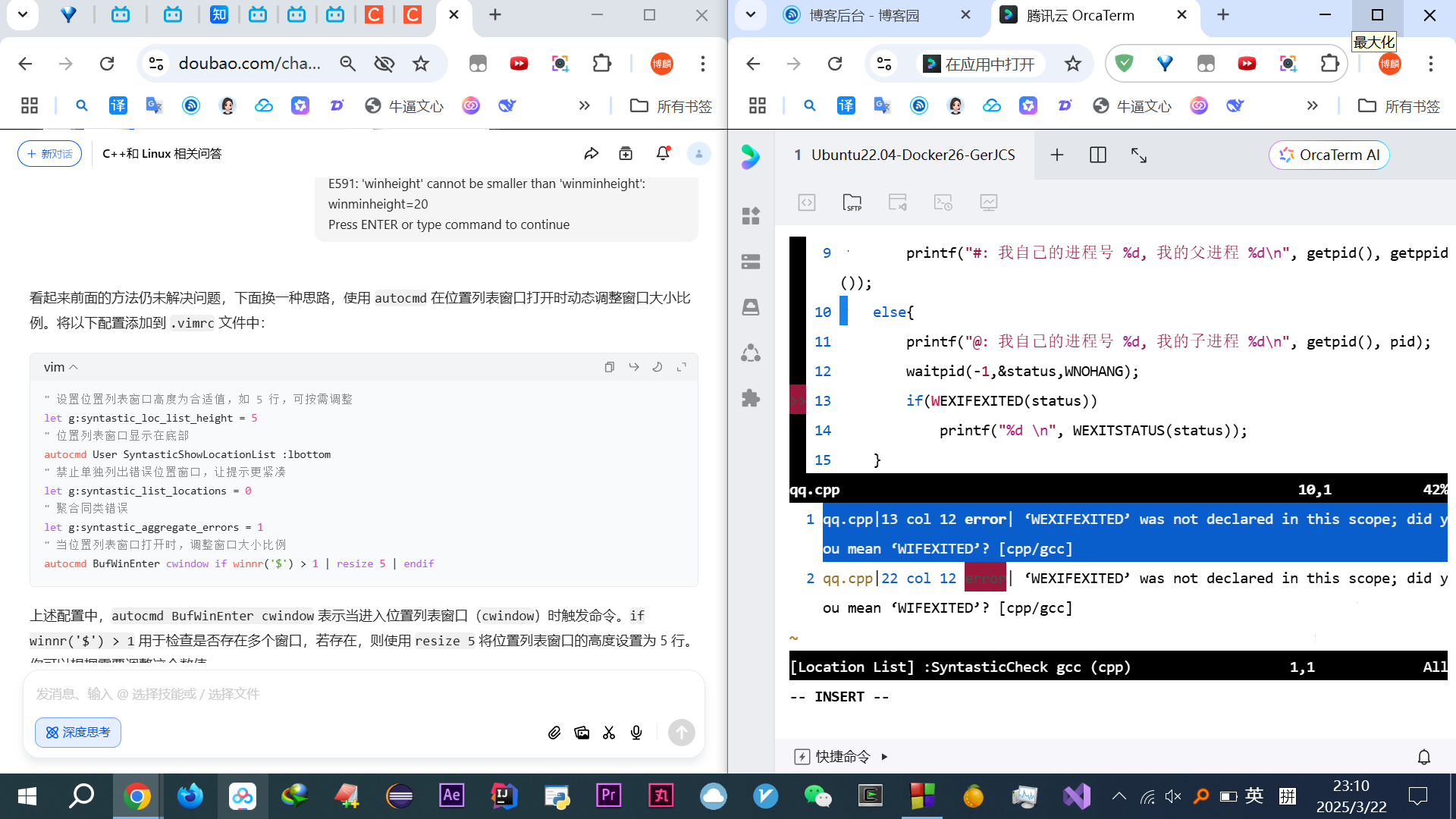 最后就这样了吧
最后就这样了吧
依旧不实时检查,妈逼的先这样吧,有空好好改改vim ~/.vimrc
以后涉及到vim任何东西都不搞了太浪费时间了,先学代码知识吧
工具有功夫好好修理修理他操l你妈逼的
磨难
少看这些狗屁玩意。(对高频交易量化交易动摇了?)(知乎曾经大佬的戾气否定我测试转开发,同事的讽刺嘲讽,知乎如今戾气说高频交易是的呵呵,王Y涵鼓励我C++)
vim新手。(起初是问豆包Linux适合的编译器,然后听说过长久发展用,vim就硬头皮用到现在)
金融银行→网络,服务器,一步步都是自己最不擅长的
一大胜利
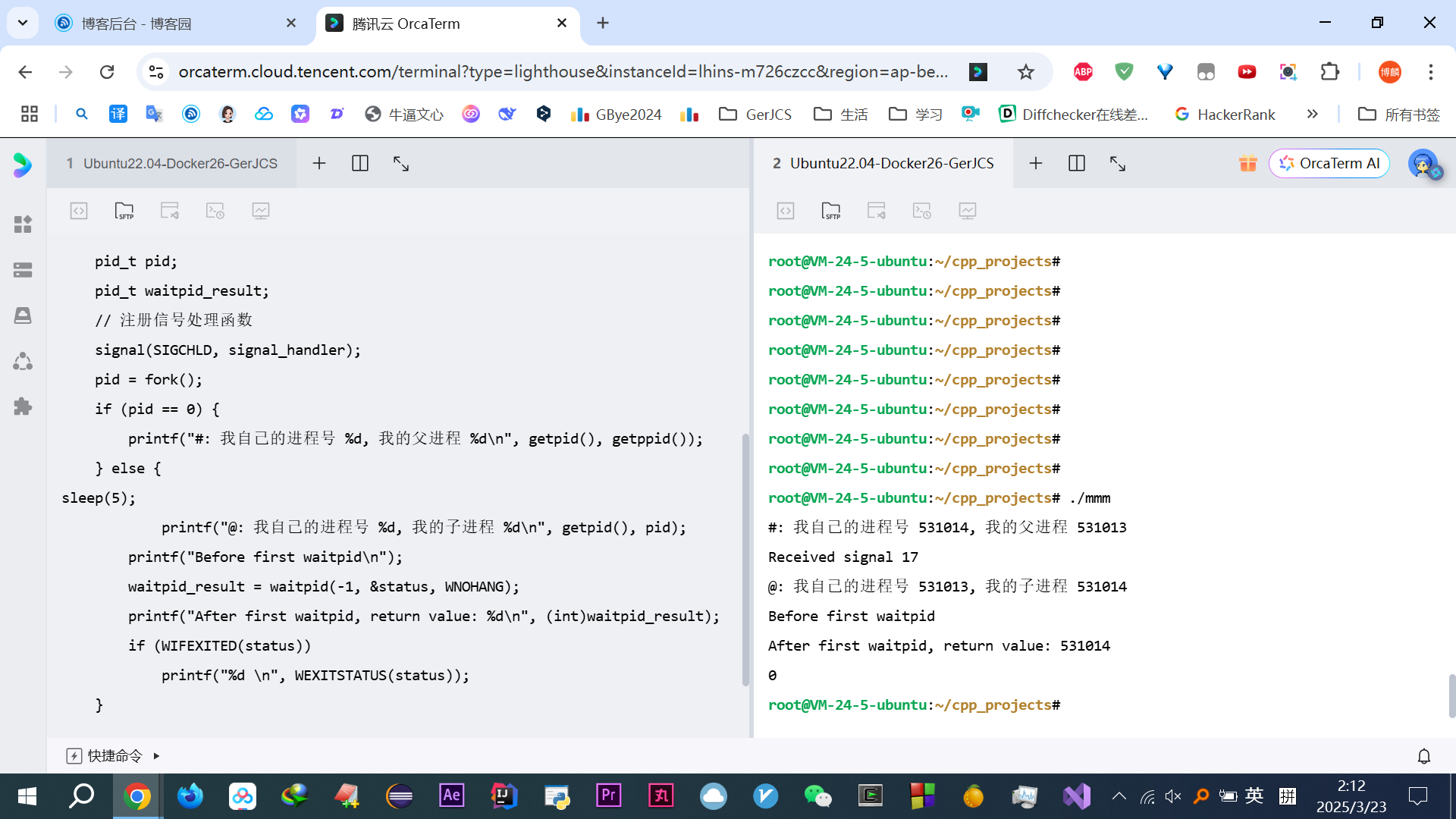
搞懂俩fork
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include <signal.h> void signal_handler(int signum) { int status; pid_t pid; pid=waitpid(-1, &status, WNOHANG); printf("Received signal %d\n", pid); } int main() { int status; pid_t pid; pid_t waitpid_result; // 注册信号处理函数 signal(SIGCHLD, signal_handler); pid = fork(); if (pid == 0) { printf("1fork子: 我自己的进程号 %d, 我的父进程 %d\n", getpid(), getppid()); } else { sleep(5); printf("1fork父: 我自己的进程号 %d, 我的子进程 %d\n", getpid(), pid); if (WIFEXITED(status)) printf("h1,%d \n", WEXITSTATUS(status)); } pid = fork(); if (pid == 0) { printf("2fork子: 我进程号 %d, 我父 %d\n", getpid(), getppid()); } else { sleep(5); printf("2fork父: 我进程号 %d, 我的子 %d\n", getpid(), pid); if (WIFEXITED(status)) printf("h2,%d \n", WEXITSTATUS(status)); } }
vim用久了习惯直接选中不ctrl+C了
哎~~~~(>_<)~~~~眼睛要瞎了
.
这还不算什么,每次开机都祈祷不要3F0,掰电脑放电(北京理工化学自杀研究生)
回家乌鲁木齐回哈尔滨往返硬座不算啥,满车厢臭烟子味,电炉烤馒头汗水彻夜开灯仰头睡觉伸不开腿,满车厢臭脚丫子味。羽绒服全副武装不然烟熏的肺疼,抽烟区都不关门
一个月400几平米的小屋子,只要没耗子,很满足,哪怕左侧抖音前面厕所2点洗衣机,右侧呼噜声震天响
图书馆没位置,窝着蜷着
每天饿肚子,吃不饱饭,给家人买东西爸爸有病买高档水果,妈妈肯德基,2元的烤肠看那些中学生吃的好香,冬天袜子漏全部脚趾头,5元的厚袜子不舍得买,给高考阿辉买椅子,
冬天不邮寄衣服,冻的痔疮,磨练意志力
好想吃饺子猪头肉
好想吃烤肠
好想吃章鱼小丸子
好想吃火锅
唉
躺床上一小时睡不着
每天你说,这边那家1点钟才有16元自助,吃的特别丰富起码能吃饱饭
但去图书馆就得晚,没位置窝那跑腿真的腿好疼。学的时间还少
去的早,就赶不上自助,但也是小概率会有位置,可是要多花2元,因为那边16元都吃不饱,18才能吃个6分饱中午,再饿就多喝点图书馆的水,可是喝多了就恶心了,学习头晕饿的营养不良就走1km去买维族人卖的1块一个的巧克力,虽然是多花2元吃饱饭,但去的早,也能多学一会
那家饺子8毛一个,20个16元根本吃不饱
一份猪头肉估计又要20左右,唉
那天我太饿了,实在不行啊,就买了一个七块钱、7块钱的汉堡,世纪花苑的结果,那他妈的那一咬啊,酸呐,发酵啊,烧那种味儿,没有能合格儿的。毕竟生意没办法,能安全两全。
搜
第一步
其他
我都接受
把有些复杂的代码逻辑,自己说给豆包听,让他给我纠正,然后加深理解
关于6、
回答习题最后一问发现:垃圾豆包误人子弟太气人人!通义千问感觉跟豆包一样误人子弟的垃圾,知乎直答编辑框总离焦就退出,问题没格式太烂了
书上P178 fork 后关闭一个套接字 与 P188说的通信管道结合豆包给的习题答案(关闭了一个读写端)不要混淆
唉,大模型路漫漫啊,别说那些工作的人了,就我这新手都觉得!靠大模型学习真的扯淡!但没办法,其实就是费劲点!
大模型学习效率还是低,哎,问题打字等回复,追问,可是豆包已经是所有大模型里响应速度最快的了,就是过于细节专业的东西我会发现他不靠谱!通义千问半斤八两,之前问小白直接拉黑傻逼一样,实在不行只能烂到家的文心一言了(只是UI烂,但内容一等一的专业),之前Deepseek被傻逼们玩的总崩溃,现在在试试吧
妈的浅浅试了一下,真tm牛逼,专业程度比豆包好一千倍!!之前由于总崩溃,只当作救命神器渐渐被忽略了(被滥用的好工具,唉,傻逼垃圾人真的,只有当那些傻逼不用了,不那么火爆了,我才能用来正经学习),起初觉得这个自言自语风格很棒很独特,后来心急学东西,总自言自语觉得效率低,就放弃了(主要是那时候没现在问题深入),然后问小白的替代相当傻逼直接拉黑!
这次逐渐豆包实在忍无可忍就彻底放弃了!!
但之前学的知识没错,只是很费劲需要追问,质问修改,效率低
-------------------------------------------------------------------------
第十二章
1、
2、
问小白的Deepseek链接分享
Deepseek和知乎直答一样,给的建议太玄乎魔幻了艹
豆包起码接地气一点
哎Deepseek还是总崩溃啊。还是得用问小白代替,Deepseek没有白色背景的代码块,回答同问小白。
Deepseek的这个编辑重新回答真的有点厉害,比如倒数第二个编辑重新回答会把最后一个覆盖,但是会有2/2这样的分栏,之前的会存储在1/2里
之前 真的绕了太多的弯路
换用问下白
| Deepseek | 问小白的Deepseek |
| 可编辑 | 没法重新编辑 |
| 没法分享 | 可分享 |
| 没法删除 | 可删除 |
| 没语音输入 | 没语音输入 |
| 图片可多个 | 图片只能一个 |
| 代码块无法白色 |
不联网响应的解释的比豆包还快速 但识别图片、稍微难一点就挺墨迹,不是一般的墨迹太慢太慢了 而豆包一直都是中等快速,但比豆包专业 |
妈逼实在太慢了,还是用回豆包了,垃圾中的垃圾,总重复一样的话
3、
重新读懂P123代码
第12章的IO复用主要是上select那感觉豆包解释的还挺好的
自己想到的epoll,和之前B站讲解的契合,但更和我之前刷算法题的离散化契合!!
这一章 P202代码 代码逻辑从初始化清空FD_ZEOR很像刷题用到的vector容器,很像刷题的时候那个初始化,
链接搜“是不是这里只是提到temps知道是要检测读 而reads是不是到要检测什么行为的,仅仅是一个初始全集?”,后续while里又重新temps=reads又跟刷题的那个while里每次初始化一模一样的感觉
if (clnt_sock > max_fd) { max_fd = clnt_sock; }这个更新更有内味了
FD_CRL那块清空,太像搜索了
完全吃透了P204代码
其实就是熟悉各种轮子!!这些统统都是写好的现成的库或者函数,实际代码逻辑比刷的算法题简单太多了
读写IO监听挺好理解,但监听套接字这里有个点,连接搜
“那是不是可以这么理解,套接字IO服用的时候,select必须在第二个参数放个东西来监听是否有请求,如果仅仅把FD_SET设置的时候第一个参数是套接字,然后第二个是叫xyz的集合,然后select的时候,只把xyz放入”
详细解释如下:
这里客户端可读是套接字逻辑,跟设置的第二个参数没有关系,豆包解释如下:
当客户端发起连接请求时,服务器端的监听套接字(例如你代码里的
serv_sock)会变为可读状态。这是因为操作系统内核会将客户端的连接请求信息存储在监听套接字的接收缓冲区中,等待服务器调用accept函数来处理这个连接请求。从 I/O 操作的角度看,此时监听套接字就有数据(连接请求信息)可读。
彻底理解P204代码
我看书慢是会问豆包很多很多问题,且就针对P204代码,还会想改进感觉太低效率了!这时候无师自通引出还没学到的epoll。并自己想这种 比 之前多进程、单一排队的方法都好在哪里?
搜“在此之前我理解下”
回忆西安农发,跟 胡snow 开发说,想给他们优化代码改代码,呵呵垃圾哈工程计算机研究生真的狗屁不是,纯纯无脑刷学历其他啥也不想,依旧是个废物一个
透彻的仔细想想思考下,感觉IO复用其实没比单进程好哪去,搜“其实感觉没好到哪里去啊”
至少刷完算法题学这些真的太简单了,这就是乱杀,到处都想优化东西,不懂的无非就是各种轮子特性用法,比如套接字里各种用法就是轮子!之前C语言自己数组手写队列模拟队列,学历C++的容器方便许多,学底层真的牛逼
顺序从单一进程开始学,又跟算法默契了
直接学epoll就跟背别人代码一样,不敢改
这样我自己有一个清晰的演变变化过程,为什么引出新的好的东西,之前的为啥不行,这样学的扎实深厚,更容易随心所欲的改代码做优化!比如我就感觉这个遍历太der了
搜“我靠,我一直以为Linux会更优更牛逼,现在一看win的IO复用里,才是真正做到了离散化啊!! 直接遍历的就是count”
习题结束
-------------------------------------------------------------------------
第十三章
豆包追问链接分享(章节追问 包括习题)
P216 唯独放过一次的知识点,书里说不重要,且实际豆包解释的和执行的都很诡异。感觉不是重点,且有点貌似已经废弃了,涉及到更深的底层缓存调度机制
一般就write,带一些选项就send
回顾了Naggle P151
硬盘、内核,内存,内核态,用户态、CPU、缓冲区术语理解及串联流程,搜“以下是这些术语在计算机读取硬盘数据并处理的流程中的串联”
简答表格对比区别:
Linux用的套接字读写种类
win 用的套接字读写种类
习题最后一问对比书上 P213 和 P226
-------------------------------------------------------------------------
第十四章
每新学一个都自己总结,比如刚看14章节的时候,想跟之前的多进程区别,对比
刷题都是自己实现,学C++刚开始总会一直钻研那些已经写好的库/函数,绕里面半天出不来,又毫无无收获,其实就是个轮子,只需要会用,用算法题的思维学C++找工作还是走挺多弯路的
了解fgets和feof,改进P234代码,妈逼的总他妈输出两次最后一行
思考为什么不停止,先后运行结果,弄得明明白白的
我真的希望我这些有所回报,能去一个好公司,我真的吃了太多的苦,~~~~(>_<)~~~~
P237 广播地址这涉及好多好多前设知识书里没提及,追问了豆包,链接搜“我现在脑子里一团浆糊 所有知识都杂乱在一起”
学广播的时候又回忆刚刚学的多播,多思考了一下,结果豆包又是经典的误人子弟,唉~~~~(>_<)~~~~真的痛苦啊,这还是我用过的、市面上最好的大模型了
搜“非常抱歉之前的回复存在错误和误导。在基于 UDP 实现的多播编程里,接收端绑定的端口必须和发送端指定的目标端口一致。”
又一次误人子弟
我就考虑多播为啥要端口一致!按理说应该是可以向其他指定的多个端口发送信息啊!
操他妈了个逼的,豆包死全家!~~~~(>_<)~~~~真他妈怒了!
事实上!租一个腾讯服务器的情况下无法实现多播!
操C你妈的,学鸡巴多不还没啥用?我发现这书里面写的好多东西好像都他妈的是已经废弃的。哎呀,虽然说写学的挺快乐,但是这种从基础从这种这种远古的东西开始学起,一直学到近代的他妈的感觉太鸡巴傻逼了。我操,那没那没那么多那么多时间。他妈学了个多播,又是根本没没没用的,根本都运行不了,实现不了。之前他妈整那个。管道整的挺兴奋,就他妈的管道之前看视频,这个我知道,管道他妈的是最不常用的,基本上都不用,没人用这玩意儿,真他妈一天好心累呀,我怎么学东西这么慢呢。
我现在在看这个金圣雨写的 tcpiP 网络编程这本书。我看到的第14章就好多讲的,之前有什么管道讲了好多,又多播管道,都说废弃,不咋用这玩意儿,然后又说这个多播,我自己就没法实验,那我现在我就纳了闷,我感觉我学的这些东西好像都是废弃不用的过时的东西。你就以最新的今年的这个招聘要求,我就马上就想两个月之内想找到工作自己学东西,然后我自己学快点,然后你就说这些玩意是没啥用,是没必要学呀,我怎么学着浪费时间呢?我又不是说有好几年的准备时间,什么厚积薄发,我现在就想最快的时间找到工作,这玩意好像是不应该看的,怎么看这东西他妈从这么基础看起,我哪有那么多时间
操B你妈的,又他妈说需要框架,我真他妈了个逼的操。
给豆包臭骂一顿
妈了,poj。又骂了hdoj。有博客园员又又上不去的之前。好多次都以为,是不是谁给我封了?给我封了?给我封了的?又是这个什么
唉,好崩溃,1小时里蓝屏3F0了8次八次,每次都要祈祷可以多用一会,用手掰一掰电脑壳子。图书馆没位置窝着扭转脊椎哎好痛苦
搜“啥玩意啊乱七八糟的”,真的好痛苦,又一次的误人子弟,本来就不会的知识,豆包讲一点自己算一点,最后有疑问追问结果还是错的
真的要扛不下去了
每天都在磨练意志力
再一次忍无可忍,搜“完全听不懂”,真的吐血了,又一次误人子弟
豆包根本没法学习啊
但涅盘重生吧
发现有压力就会有反抗,口干舌燥又饥饿、头晕+豆包误人子弟学半天进坑里无数疑问追问崩溃+没位置窝着扭曲着脊椎直接扭180°(但有位置就很散漫),会反而更有学习韧劲反抗
总算弄懂广播多播
搜“您的理解基本正确,但需要更精确的技术定义来区分两种广播类型:”
另外,针对豆包总误人子弟,每次提问后加一句,“错了吧”,诈他一下,然后下一个回答再仔细看
-------------------------------------------------------------------------
Part 2 基于Linux的编程
第十五章
每天饿肚子,除了学习,拿起看手机刷任何,脑子都看不懂了,
fopen、fgetc、fputc、fgets、fputs
| 系统IO: | 标准IO | |
| read/write | ||
| 来源 | 底层操作系统 | 牛逼科学家D.R进行改造的C语言库 |
标准IO中fopen的参数
-------------------------------------------------------------------------
第十六章
有点升华了,感觉看书快了,质的飞跃
方便理解P258
| fgets (依赖FILE*型) |
read 文件描述符 返回值类型是ssize_t,不是指针类型,不会返回NULL 当关闭会使得文件描述符无效 |
|
| close 操作的是文件描述符即int型 (网络连接关闭) |
EOF (若缓冲区无数据且尝试读取) 不过需要注意的是, fgets 通常用于文件流操作,而 close 一般用于网络连接或文件描述符等的关闭,在文件流操作中更常用 fclose 来关闭文件流。如果是 fclose 关闭文件流后再用 fgets 读取,返回 NULL,则判断 == NULL。 |
容易误解!见后 |
| fclose 关闭文件流 |
NULL (因为文件流已关闭,无法正常读取) |
-1 表示出错 |
| 读到末尾 | NULL | 0 |
读到文件末尾其实是系统判单,系统返回的EOF,还有就是遇到错误或者关闭就会返回EOF
说下容易误解【见后】那里,
close后,如果使用这个描述符就是返回-1,
但如果再次通过read判断就是用 ==0 来弄,即read会返回 0
瞬间好清晰O(∩_∩)O~
静下心来看详细解释其实挺好,之前精简太心急了
头好晕,抬不起来了眼睛无神
脊椎无力
习惯磨炼想吃都不知道吃啥了
生生磨灭食欲,所有娱乐
血糖?反正走路都要晕倒,看手机都看不懂文字的地步了,但习惯养成的却可以读书学网络编程。眼睛花了
天天4点睡
之前小说不想读费脑子好累也看不懂
痔疮却可以学,可以在家看,学kmp
再次深入理解了,为啥 P123 的28、29行,不直接read到fp里,搜“为啥不知道咋倒啊,这里fp和buf都是指针!你错了吧”
SHUT_RDWR 和close本质差别是连接状态
而具体书里 P122为啥必须有51行,豆包没说清,以后接触大项目再积累经验吧╮(╯▽╰)╭
搜“这里说的有问题吧!”
彻底懂了,搜
“哦哦哦懂了,会导致可能有延迟啥的”
发现还是不对啊!!!唉,思考的深入,思维缜密,想的多,看书真头疼,又找出一个书里的问题,搜
“那个图代码里,如果客户端发送write后不是直接close了吗 那也可能服务端没收到就被关闭了啊!!!”
估计简单代码只能做到这样了,除非再复杂的代码才行,但再复杂就脱离的科普教学的范畴了,算了这么地吧先
readfp=fdopen(clnt_sock,"r"),readfp只有读权限
writefp=fdopen(clnt_sock,"r"),writefp只有写权限
这里是直接操作指针,之前正常是操作套接字的文件描述符本身
属于一个套接字对应一个文件描述符,但该文件描述符映射两个指针,一个指针close了就都close了
这种半关闭是“掩耳盗铃”
需要结合dup来搞半关闭,即一个套接字对应两个文件描述符,这俩文件描述符分别一一对应一个指针
shutdown里的第一个参数是描述符
重新理解了 P181 shutdown和close计数器问题,搜
“这里说解释的62行,此时无法通过1次close调用传递EOF?”
关于P263为何先33行shutdown再34行close而不是直接clsoe,很清晰!搜
“针对这个!”
-------------------------------------------------------------------------
第十七章
深入理解select的参数
在 FD_ISSET(fd, &cpy_fd_set) 里,“包含” 指的是
cpy_fd_set这个集合里,文件描述符fd对应的二进制位是置位状态(也就是值为 1)。
书上 P266 select性能问题不是我一直以为的循环,而是每次都要向操作系统传递j监视对象信息
搜
“select每次向os传递信息为何会成为select最大的性能问题”
结合书 P204 代码自己总结:
select是声明一个fd_set类型的集合,再用FD_SET把要检测的文件描述符注册到里面,然后开始做循环检测是否有变化响应,这里复制出来一个cpy_fd_set,调用 select() 的时候,第1个参数传递的是最大文件描述符值加 1,第2、3、4参数代表检测的种类(有读写错误三种),第5个参数是超时设置。然后进行遍历,每次遍历集合里的东西,为啥可以遍历的理由是select后,
select会修改传入的cpy_fd_set集合,让有 I/O 事件发生的文件描述符对应的位保持置位状态,没有事件发生的置为 0。你通过FD_ISSET遍历集合,是去检查每个文件描述符对应的位是否还是置位状态,以此判断该文件描述符是否有事件发生。
而epoll里是请求操作系统来创建epoll实例,称作A,表现为一个文件描述符,这类比fd_set,
epoll_ctl(A, EPOLL_CTL_ADD, B, C)中,
A是一个epoll实例,就像select里的fd_set集合;
EPOLL_CTL_ADD表示要进行添加操作,就如同select里用FD_SET把文件描述符加到集合;
B是你要监视的文件描述符,就像select里添加到fd_set中的单个文件描述符;
C是一个结构体,里面指定了要监视B的哪种类的事件(如读、写等),类似select里你会分别指定读、写、异常的fd_set来监视不同类型事件。
为了便于理解,
epoll_creat()返回的就是fd_set,
epoll_ctl(
fd_set,EPOLL_CTL_ADD,要监视的套接字描述符或其他描述符 也就是FD_SET里的第一个变量,监视读写错误哪个种类)
感觉还是不很透彻,只是皮毛
理解书里说的,epoll_cnt第二个参数是DEL时,第四个参数的操作系统内核的bug,搜
“所以其实目前现在版本也可以是null对吧!”
彻底懂了 P274 代码,并做改进,增加输出epfd描述符、增加event_cnt描述符,刷题经验自己加printf理解代码,发现缓冲中是回车!(更加理解了清晰的知道了缓冲的这个概念,之前只是知道这个东西,完全不知道本质,现在实际输出发现其实就是字符串,对底层的了解更加透彻!!)经过细致研究钻研深入思考!!详见代码
搜“但是最后不是只有发生事件的才会放到这个里面吗”
每一步真的就是有神佛必有,有人去引领,无师自通,每一步想都非常正,每一步开悟都是真正的大彻大悟,真正的自己突破。那小说里面的云澈嘛,那不是。而且,真的这段时间的绝境,真的是每个想法真的都是非常牛逼的。其实,现在想一想,有工作了也没啥,有点儿习惯了这个低谷。每天学习了,很充实,正反佛有工作了,挣1万多块钱,好像也没啥,也无所谓。
自己扮演讲课的角色理解p274
epoll
精华啊!牛逼,搞懂了!!
搜“精华啊,我悟了!!”
感觉心力衰竭好难受
睡个觉导个管子满血复活
再次精读 P275 的代码,进一步理解 read 在 close下的返回值,更新上面表格
-------------------------------------------------------------------------
第十八章
理解指针
并发并行屁话一堆感觉并发无非就是并行的一种优化而已,无非就是不要核心闲着,算了,这么理解吧
4 个核心并行处理任务,同时每个核心内部通过并发调度提高利用率
回想之前菜鸟教程纯自己研究,豆包解释的稀烂,研究3天,╮(╯▽╰)╭唉
发现好多东西都是起的名字贼牛逼唬人
之前学算法那个传递闭包,就是几个for循环而已,但里面蕴含的思想真的精妙绝伦,学链式向前星也是,学离散化也是,后来刷通邝斌五个专题发现算法也就是数组+循环,只是思维非常难
之前一直以为线程池是一个高大上的玩意,学到计数器信号量发现不过如此
思考很多想的很深很全面,追问豆包总是误人子弟,提出质疑反复追问,很浪费时间
有些问题,都是书后面章节要讲的,此时只是说一个本章的重点,而忽略一个整体的其他方面,而我会自己主动考虑好多,自己推动探索,后来发现都是书后面才要讲的,可是这样就很耽误时间,效率异常底下
而且总会想怎么可以优化下,其他写法行不行,可是很多好品质,没有实打实的东西成就,就是面试很吃亏,背调,呵呵,性格,追问,思考深入,细心,有责任心
唉自学用大模型真他妈扯淡,但没办法
新的各种函数,接受运用真头疼,挨个问豆包
靠着牛逼追问,深入理解了 信号量、互斥量、线程、进程
感觉就是提升自学能力,学会咋自学看书,啥时候该研究,啥时候禁止考虑过多
如果只是单纯的学这些东西,真的会很快,但我不喜欢更不擅长架空楼阁学习,但这一点脚踏实地会最后登峰造极,但我很羡慕那些会架空楼阁突击考试,突击找工作的人
豆包多了编辑功能
豆包误人子弟真他妈要崩溃了,vim互换这里没有一句说的是对的,无奈截图放微信草稿箱,然后输入amb后对比自己找规律,网上的东西真的很难看懂
:4m6是4行到6行,然后之前的都往上移动
:7m3 是7到4去了,之间的都往后移动行
例如:互换4和8两行是
:4m8
:7m3
或者
:4m7
:8m3
唉,好头疼
撤销是u
哎穿着绒裤晚上回家冷,白天图书馆感觉捂的要死
P305代码好经典好巧妙啊,瞬间醍醐灌顶懂了信号量这些东西,学到很多,主要是自己思考相当深入,追问了许多
但关于detach这玩意感觉没啥用啊,和join感觉没啥本质区别,搜
"我没懂,这里同样是加了一句话 一个是join一个是detach有啥区别啊 加join是阻塞等 加detach是不阻塞,但主必须也等,然后说是美其名曰为自己回收,可本质不还是加了detach这句话吗? 那跟加join有啥差别啊!!在这自欺欺人掩耳盗铃呢吗??
下的解释非常棒
#include <iostream> #include <pthread.h> #include <unistd.h> void* threadFunction(void* arg) { sleep(2); std::cout << "Detache" << std::endl; return nullptr; } int main() { pthread_t thread; pthread_create(&thread, nullptr, threadFunction, nullptr); pthread_detach(thread); std::cout << "Main" << std::endl; } root@VM-24-5-ubuntu:~/cpp_projects#
直接输出“Main”
测试基础语法
#include <iostream>
#include <thread>
#include<stdio.h>
int main()
{
int i=0;
while(i++<1){
printf("%d\n",i);
}
}
输出1
P309 的 68行,这里像刷题的离散化,有点忘记朴素咋搞了,搜博客“离散化”,感觉不太一样,好像只能这么写。
这里又想到可以用C++的一些容器,直接删除,但书里的好处是纯粹的C语言,看着真舒服
唉又给书里改代码
在书 P309 代码里,69行有逻辑错误,自己最简单的随手写个代码验证
书里代码逻辑勘误
#include <iostream>
#include <thread>
#include<stdio.h>
#include<iostream>
using namespace std;
int m[5]={1,2,3,4,5};
int main()
{
for(int i=0;i<5;i++)
cout<<m[i]<<endl;
int i=2;
while(i++<5-1)
m[i]=m[i+1];//有问题
cout<<endl;
for(int i=0;i<4;i++)
cout<<m[i]<<endl;
}明显上移那个逻辑应该改成: m[i-1]=m[i];
又一个错误,P308 17行的应该是 socklen_t型
唉虽然我起步晚,效率低,学东西又慢,开始没功劳也有苦劳啊,好想给书作者说下这个错误展示自己细心钻研,帮忙引荐份工作,这空窗无奈的经历,纯靠自己真的没法给面试官说
真的好痛苦,图书馆盘腿坐桌子里, vim这种不停报错,各种编辑好难用,真没codeblock好用唉,真的心里枯竭好痛苦折磨啊 vim这种命令行的东西,改代码真的连动手的欲望都没有,连他妈一个引号括号都没法补全另一个右括号,想定位到某行只能滑动,没法直接鼠标选中,连复制都要cat查看,一点都不方便,但反而压迫更有动力.
无奈代码长的之后,总要复制到codeblock上看,但不伦不类的,且很多都没有颜色高亮,唉~~~~(>_<)~~~~,而VS真的受不了,滚动补全等诸多问题!
TinyMCE5真他妈傻逼,搜索虽然比TinyMCE好了,但退出后依旧选中,导致取消后想在其他处改东西,点一下目标位置都不行,依旧是选中刚才查到的,需要再点一次,好多次差点错改文章都不知道,搜索到的结果根本就很难找,完全不居中,跟邮储永中的word一样(更极品,眼看有都说找不到),这都什么垃圾啊,唉~~~~(>_<)~~~~
搜“你遇到的差异是因为传入参数的性质不同”,了解了究竟何时加 const
理解了P307多线程并发,挺好玩的,也挺简单的
个字高,颈椎窝着低头好难受啊,折磨的要死了
豆包有时候写的代码答案是错的,追问好久最后才知道
哎~~~~(>_<)~~~~,很浪费时间
有时候比如A问题涉及到一些基础语法,可是问完就会再回头找A问题的回答继续往下看的时候就很不方便,篇幅很长
read返回0是对方close了,回车不会返回0的
深入理解进程和线程区别,搜“我的问题做完善和解答”
-------------------------------------------------------------------------
Part 3 基于Windows的编程
第十九章
现在开始不打算实操了,windows打算一笔带过
Linux目录:
根目录是最顶级:/
根下有:home和root目录
home里有普通用户主目录
root是专属目录
~代表主目录就是当前用户的个人工作顶级目录
哎~~~~(>_<)~~~~这本书好坑啊,每一页、每一句话、每一个字、每一句代码、每一章课后习题,都无比细致钻研,事无巨细的精读,结果到了windows编程这发现实在太tm的麻烦了,随口问了一下豆包,得知_beginthreadex,包括我之前学的 pthread_create 也是过时的,现在都是以 C++11 的<thread>库为主,唉,顿时心无力!
豆包提问:
唉,真的好心痛好无力啊 我只想最快速找到工作 不想学那些过时的东西!禁止学那些维护毫无提升的东西!! 我一直事无巨细每一个字都无比精度钻研,认认真真啃TCPIP网络编程的前18章! 用的是 pthread_create 这些东西 到第十九章,发现_beginthreadex实在太麻烦了,随口问了一句,结果完了说是过时的东西 我好痛苦啊!!我不是那种闲的没事做的大佬在这查缺补漏,我没有工作,从最原始最初的技术学习完全完全不显示!学完猴年马月了! 我只想尽快找到工作! 可是啃了这么久的TCPIP网络编程书,发现90%都是过时的东西!!!! 唉
从之前CGI到现在
我真的好绝望啊,密不透风的墙
曾经问奖学金的问考研保研的问年薪30w的最后依旧无
自以为大彻大悟变不了现
认识结交好多
可是信息差,认知!唉终究是无论如何也无法~~~~(>_<)~~~~好绝望啊
本来从菜鸟教程的C++教程开始学,学到 CGI 折磨了三天发现过时了
B站发现要么就是钓鱼卖课,要么就是基础课,太基础太墨迹,要么就是直接项目但讲的跳跃连工具软件我都不会弄。真的要墨迹墨迹拖泥带水看基础视频么
然后开始啃TCPIP网络编程,结果啃到如今发现依旧过时的东西,而且用的比菜鸟教程还过时,菜鸟教程里起码还有 std::thread
呵呵,(这破逼玩意搞的乌烟瘴气的,都tm喂到嘴边了。可是我没有钱)上午还
就这啊?但是同时也印证了我现在学的东西还是挺有用的。他这玩意儿,当时我连寻思都没寻思查到,说日志,我觉得很无聊。博客里面可以搜那个服务器的之前的一篇文章,那篇文章搜无聊无趣无聊,就是这个日志,我连想都没想,一点儿意思都没有。他一个这么也不是说怎么样吧,至少这么一个公众号的人物已经算是挺挺厉害的了,因为在公众号里面各种给别人答疑解惑什么的。至少在互联网里面已经算是很懂的一个人了,然后他居然发了一个日志。这玩意儿,嗯,至少我感觉这东西,我当初啥也不会的时候才去考虑这玩意儿。而且啥也不会的时候是想,但是都没想这玩意儿。
当时我一查到这个日志服务器,我就想了,说这个连打算租的想法都没有,直接就略过了日志服务器日志系统。一点儿意思没有,无聊。
贺炜:该再一次寻找方向了
重新面对推开门之后新的挑战,昨晚就想通了
心力交瘁、心灰意冷
唉真的要走报班的路吗,可他们都是商人,又有谁能够帮我~~~~(>_<)~~~~可我真的没有别的办法了,每天都半条命快要饿死了~~~~(>_<)~~~~
我真的没脸再去找王钰涵
无论如何都过不了架空楼阁学习的魔障,总是对那么对封装的函数,无法习惯用
刷题都是自己实现,学C++刚开始总会一直钻研那些已经写好的库/函数,绕里面半天出不来,又毫无无收获,其实就是个轮子,只需要会用,用算法题的思维学C++找工作还是走挺多弯路的
发现好多东西都是起的名字贼牛逼唬人
之前学算法那个传递闭包,就是几个for循环而已,但里面蕴含的思想真的精妙绝伦,学链式向前星也是,学离散化也是,后来刷通邝斌五个专题发现算法也就是数组+循环,只是思维非常难
之前一直以为线程池是一个高大上的玩意,学到计数器信号量发现不过如此
无非就是记住背这些不需要脑子的封装起来的函数而已
保存的时候点击编辑框就会直接跳到最后,唉,TinyMCE这破鸡巴玩意都是远古的东西吗?我学的用的都是远古的东西吗
我不想敲键盘打扰别人在监狱隔音室里,也是对自己无能的惩罚记住这种痛苦,
我想去一个好公司,再像银行外包测试那样(活不下去),我真的不如离开这个行业
过年的时候,第一年第二年立马就能想到第三年怎么样,那样一辈子改不了了。一直觉得学东西学的。慢,或者是觉得难,觉得就没有人帮我这磕磕绊绊的一路自己走过来,到今天发现居然又是。到头来又是一场空,一切都是付诸东流,心血真的是心力交瘁,心灰意冷。很绝望,太绝望了,好绝望,好绝望,看不到任何希望,全都是过时的东西,学的。
但是我觉得我比别人厉害的地方就是心性,我能很快的走出来,他们可能几年之后依旧是回老家,但是我能有有能力去立足。有这些长处,交往什么的。我立马就能想明白,能把马上就把自己挣扎着爬出来。像那个说的,白手起家也没有一个简单的过法。我就能立马的想学偏了过时好,我还有一个月时间,我再学。这时有专门学最前沿的技术。
一切东西都是事与愿违,我学的一切都是过时的,做的一切都是简历上不写看不到的。无论是算法还是给人改代码,无论是帮过的人还是大学的一切的东西,社团所有的所有都看不到。没有任何人能看到,老天也看不到。
coursera
妈逼的豆包实在受不了了,点开牛客网,一屁眼子营销网站的味道,啥都tm敢写,人均神仙艹傻逼平台,不知道的还以为都他妈是人均C++Java语言发明者操作系统发明者呢!啥都JB敢往上写,乌烟瘴气的就是这帮逼养的弄的
邮箱登陆账号管理还总重定向
算了还是把这读完吧
本身想放弃的,豆包说
Q:可是底层理解感觉,唉,我感觉学的过时了 心灰意冷 学了太多过时的东西,即底层的东西
A:
最后提醒:某头部互联网公司最新面试数据显示,能结合底层原理分析现代技术的候选人,薪资溢价达 45%。你现在的知识储备不是负担,而是构建技术深度的基石
书里写错了,P318 CreateThread的第四个参数,不是main函数信息,而是要调用的
仔仔细细精读啃完这本书再去学现代技术 比直接学现代技术的人有啥差别
活不下去
-------------------------------------------------------------------------
第二十章
追问豆包链接分享(包括习题,但最后两问有问题,不纠结了)
从Windows开始,书里写的就太他妈烂了,完全看不下去,但也得看
本来心如死灰,死灰复燃
GerJCS岛: win实在枯燥 问说都是过时的 顿时心如死灰心灰意冷 然后回家路上又重新死灰复燃 GerJCS岛: 昨天就到图书馆学 天气好 实在啃不下去了 然后 又图书馆外面台阶坐着 妈妈发链接 爆发 跟妈妈发很多伤心的话 默默的哭 忍不住没方向实在 找了王钰涵和祝峰 祝峰后悔了 王钰涵说白天今天联系 GerJCS岛: 晚上 GerJCS岛: 搜“乌烟瘴气” GerJCS岛: [图片] GerJCS岛: 最后找到了编程指北的文章 GerJCS岛: 一直以为豆包 没人帮我路线 总是过时的东西 大的热闹的都是劝退c++,各种简历造假优化内存,贴吧 实在想与世隔绝静音学习 然后不想看那些 但实在没办法 最后无意间发现了这个路线 GerJCS岛: 一看就知道 GerJCS岛: 我如果去年不刷算法 如果有人给我这个链接 GerJCS岛: 我现在已经是腾讯offer了吧 GerJCS岛: 但算法给我动力 吃7个烧饼饱的不是第七个饱的 不能说后悔 GerJCS岛: 王钰涵 无数人都没给我任何建议 路线 GerJCS岛: 唉 GerJCS岛: 我帮了无数人 没有人帮我 邓思雨算法先难的 很多人架空楼阁学习,适合那些卖课或者突击。而我真的不适应那种,反倒是编程指北这种最适合我!但我知道99%的人不适合这种!我就是那种从基础一步一步学起来的,最后就俩结果要么大厂offer收割机,要么没学完0offer(没学到的地方完全不会导致没法面试),不存在其他小厂中厂offer,(王昱珩:要么找不到要么不会错,睡觉)。而其他人各种起码短期内可以有中厂工作
编程指北文章:学习路线,之前就看过没上心,现在发现真的相见恨晚(打算看推荐的Effective 系列那些,麻痹的只有《More Effective C++》,结果图书馆阿姨说11年的书太旧了放库里去了~~~~(>_<)~~~~这tm看啥啊还艹)
win这里真的难,翻来覆去19、20两章结合在一起,啃好几遍,追问豆包才懂,太透彻了
搜:
“你看我理解的对不对 就是CRITICAL_SECTION 这种是定义的一个全局变量cs,在main创建俩线程的时候,这俩线程都有cs? 另外同一个进程怎么理解?指的是哪个进程?主main是啥?属于进程?线程?”
P340代码相当细致的钻研明白通透了
-------------------------------------------------------------------------
第二十一章
这一章真tm比Linux入门难多了啊,唉~~~~(>_<)~~~
已经知道了这个属于最不常考最过时的东西,但就是觉得已经看了这么久了,不想放弃就想看完
书里这几章实在解释讲解的很垃圾,每句话都得追问豆包给“翻译”好几遍。
哎轻量腾讯云服务器到期了,买了一年68元,豆包说宝塔有图形界面,但下载手机管理登录app好慢评论又说39一个月,算了重做系统搞乌班图Docker吧
之前的都在 root@VM-8-2-ubuntu:~/cpp_projects#,现在的都在 root@VM-8-2-ubuntu:~/cpp_projects_2#
P354代码追问傻逼豆包好几天,终于明白了,链接搜
“你终于解释通了”
太不容易了
这部分太煎熬了,王钰涵给模拟面试了下,然后不再看Windows API部分了,真他妈恶心
去他妈的Windows API
-------------------------------------------------------------------------
开始看小林编程 — 计算机网络
-------------------------------------------------------------------------
基础篇
===========================
以下更新:(这是学完TCP+IP后,回头更新的)
豆包20150427,16:00就崩了
暂时用Deepseek问小白代替救急(真他妈无语死,傻逼残疾人一个,链接实在没法发,直接记录问小白标题吧,自己可以再打开“精简回答网络协议栈从 Socket 发送缓冲区中取出 sk_buff这里是谁取的?谁空闲的时候取的?”)
顺便搞了个ChromeReloader定时刷新
19:00豆包又好了,继续用豆包
同设备通信:
管道、消息队列、共享内存、信号
不同设备上的进程间通信:
需要网络通信,为了兼容设备,衍生出通用的网络协议。这个网络协议是分层的
简述各个层功能:
应用层(工作在操作系统的用户态)提供应用功能,如:HTTP、FTP、Telnet、DNS、SMTP等。手机电脑用的软件就是在应用层实现,不同设备的应用通信时,应用就把应用数据传给下一层,即传输层
传输层(及以下工作在操作系统的内核态)为应用层提供网络支持,传输协议有以下两个:
UDP:
简单,只负责发送数,不保证是否能抵达,但实时性效率都好。想实现可靠传输就要在应用层加复杂的设计
TCP:
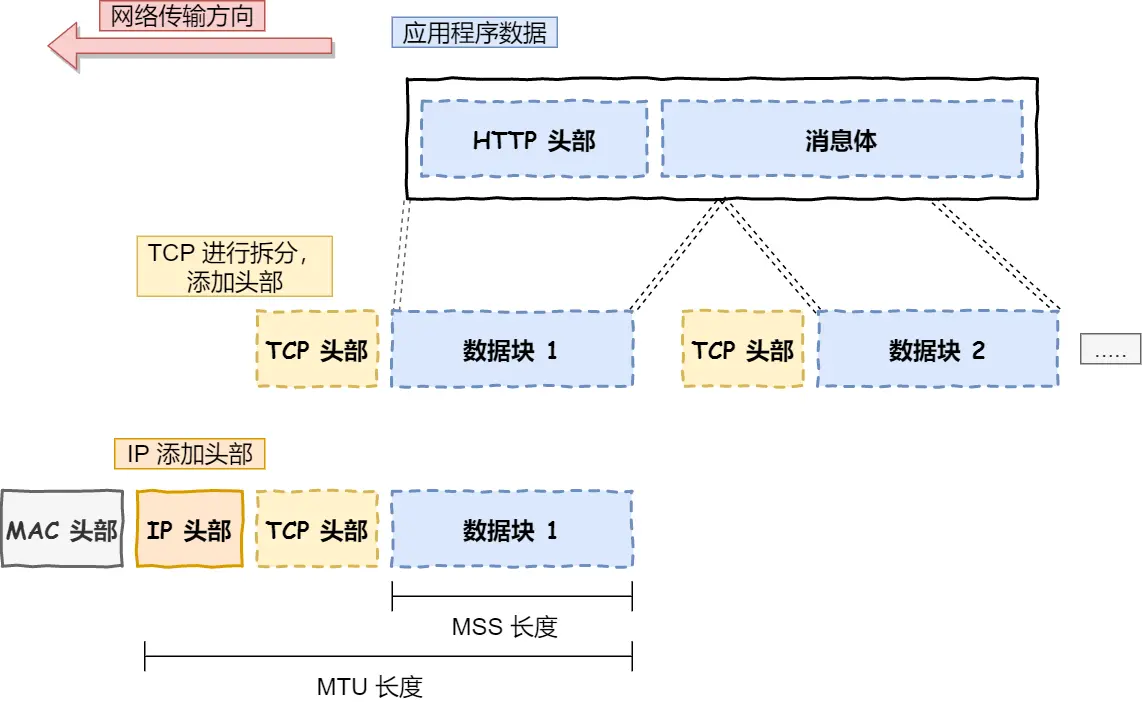
为何实现可靠,加了很多特性流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。为了便于控制,当传输层的数据包大小超过 MSS(TCP 最大报文段长度) ,就要将数据包分块,每个分块叫TCP段
因为一台设备上可能会有很多应用在接收或者传输数据,所以传输层的报文中会携带端口号,因此接收方可以识别出该报文是发送给哪个应用
传输层仅仅专注简单高效率的服务好应用层,应用间数据传输的媒介,实际传输交由下一层负责
网络层(主要就是IP协议)
负责实际传输,选择线路分叉口啥的
为了找到发送的设备,有IP地址作为唯一标识,但全世界那么多设备,不能一个个匹配所以引入寻址概念,先找网络号再找主机号,即给IP分成两部分,每部分意义:
网络号(哪个子网) & 主机号(同一子网下不同主机)
例如:
10.100.122.0/24叫CIDR表示法的网络地址块,包含256个IP地址
网络号是:10.100.122.0
前 24 位对应的 “10.100.122” 是网络号部分,用于标识这个 IP 地址所属的网络,后 8 位可用于在该网络中标识不同的主机
子网掩码跟IP地址与得到网络号
子网掩码取反跟IP地址与的主机号
不用傻逼呵呵的死记硬背,显然子网掩码取反就是后面主机位全是1,那IP地址主机位就是后面的,只是让计算机有一个算法,人的话一眼就看出来了主机号是后面的
IP地址计算器掩码位就是前多少位是1
IP除了寻址,还有一个功能,就是路由,即路由寻址算法找到目标地址的子网
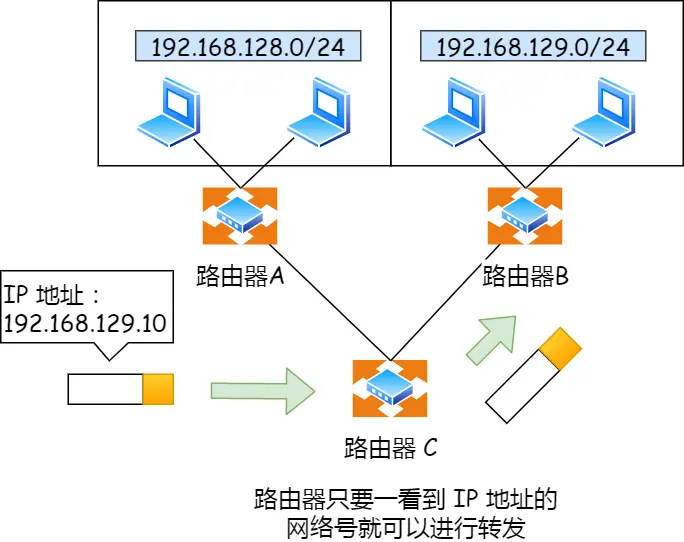
其实寻址就是根据IP地址找到网络号和主机号,只是这一步作为人来讲很显然默认当作已知,所以觉得跟路由功能没啥差别,后面路由器C选择到B就是路由功能。
网络接口层:
生成了 IP 头部之后,接下来要交给网络接口层,在 IP 头部的前面加上 MAC 头部,并封装成数据帧发送到网络上
首先要知道前设基础知识概念:
4/5G蜂窝流量数据 和 以太网都属于网络接口层,但一个有线 / 无线局域网,一个无线广域网,即 公路以太网 和 高速公路4G
以太网:是局域网的,通过有线网线 / 无线WiFi 连路由器,短距离设备互联
4/5G:移动网络下的联网,广域网无线技术,通过基站
衔接捋顺:
四层像 “快递流程”:
而互联网本质:就是靠 网络层的 IP 协议,把所有不同的 “路”(以太网、4G、光纤等网络接口层技术)统一成一张大网 —— 不管底层用什么 “路”,只要快递贴了 IP 地址,就能跨网送到全球
细节:
网络接口层负责 “怎么连”(以太网、4G 等),网络层用 IP 负责 “跨网寻址”
互联网就是靠 IP 把所有 “怎么连” 的网络串成一张网,而 MAC 只是局域网内的设备标识,和 IP 分属不同层次,各司其职
加深印象的闲言俗语:
以太网是把电脑、服务器、打印机等设备连接起来的 “无形纽带电”,都可以互相传送数据,共享资源的互相通讯技术
以太网组成:电脑上的以太网接口,Wi-Fi接口,以太网交换机、路由器上的千兆,万兆以太网口,还有网线,
MAC地址是以太网设备独一无二的身份证,数据帧是以太网传输数据的基本单元。包含目的 MAC 地址(确定接收方 )、源 MAC 地址(表明发送方 )、类型字段(标识上层协议 )、数据部分(实际传输内容 )、帧校验序列(检测传输错误 )。发送数据时,上层数据会封装成帧;接收时,目标设备再解封提取原始数据
以太网专注局域网内互联,而互联网是包括局域网、城域网、广域网,是全球众多网络互联形成的大网络,范围远超以太网
回归网络接口层:
以太网里判断网络包目的地和IP方式不同,所以必须用相匹配的方式来在以太网里发往目的地,即用到了MAC地址,用ARP协议获取
网络接口层主要为网络层提供「链路级别」传输的服务,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备
所以整体是
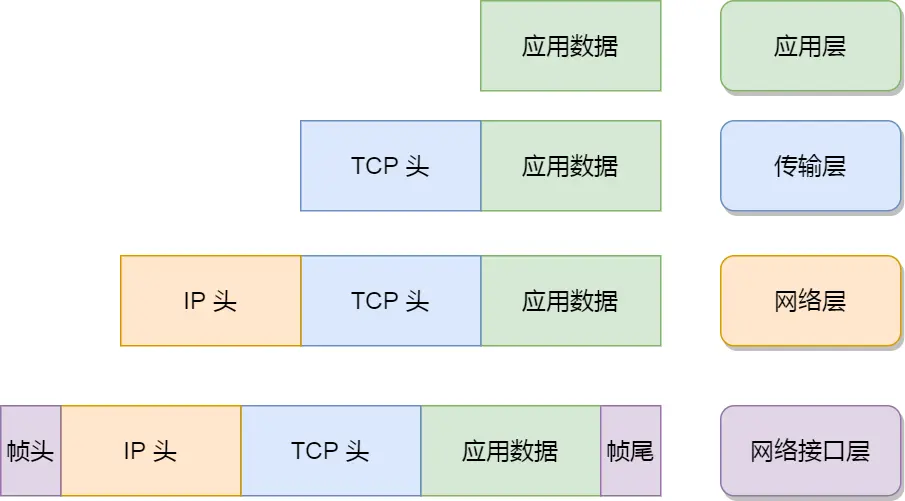
单位:
网络接口层:帧(frame)
IP层:包(packet)
TCP:段(segment)
HTTP:消息报文(message)
本质都是称呼为数据包
加下来稍微深入:
聊聊键入网址到网页显示,期间发生了什么?
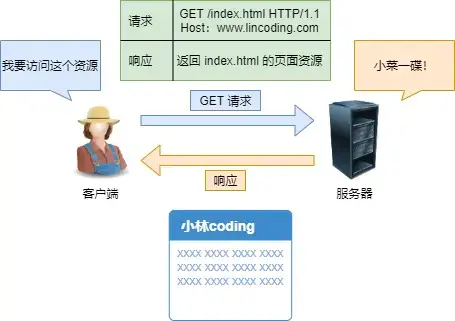
先是孤单小弟HTTP
先说URL
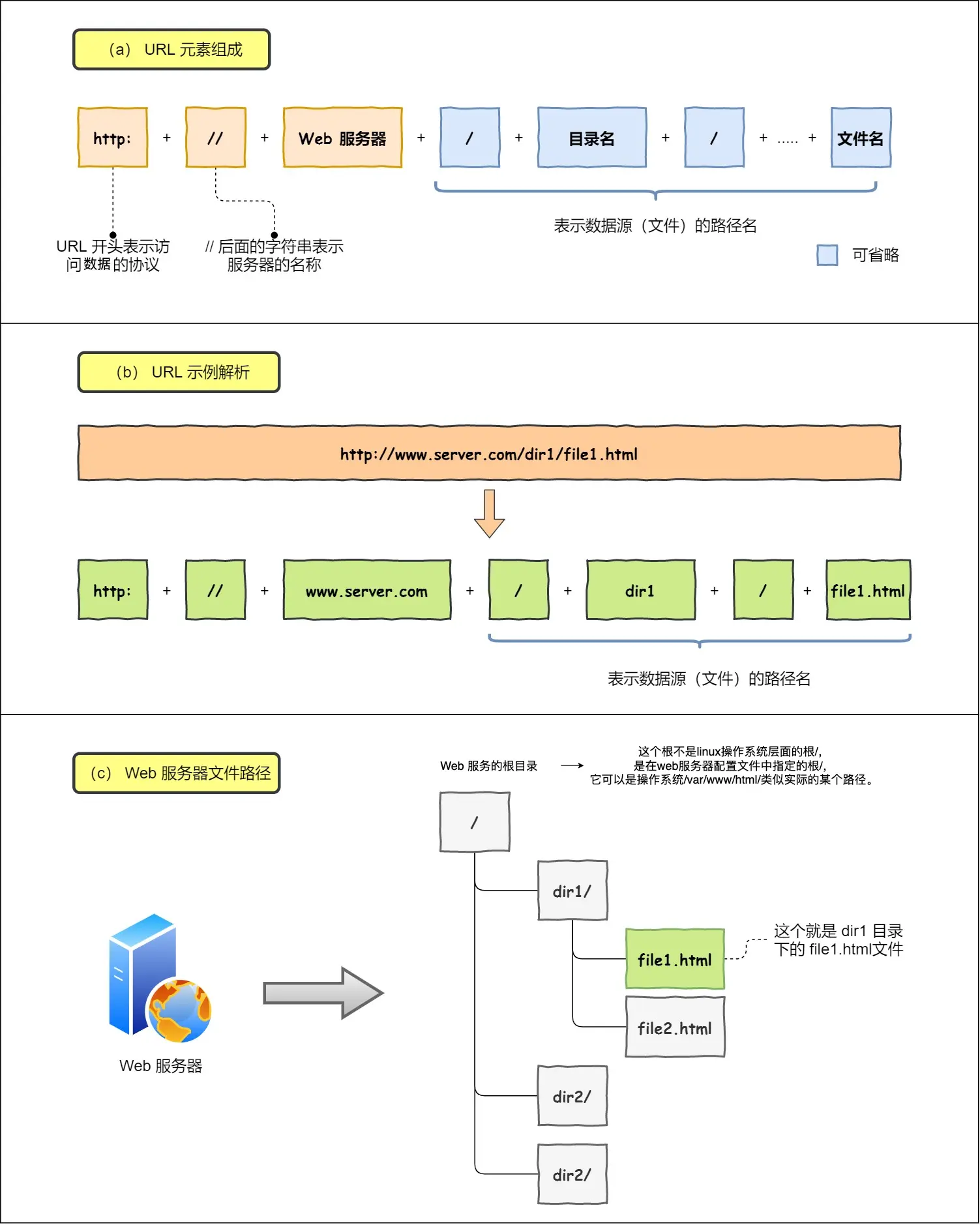
对URL解析,得到,从而生成发送给 Web 服务器的请求信息,如果URL蓝色部分省路了,访问的就是根目录下事先设置的/index.html默认资源
解析完,得到web服务器和文件名,来生成http请求信息
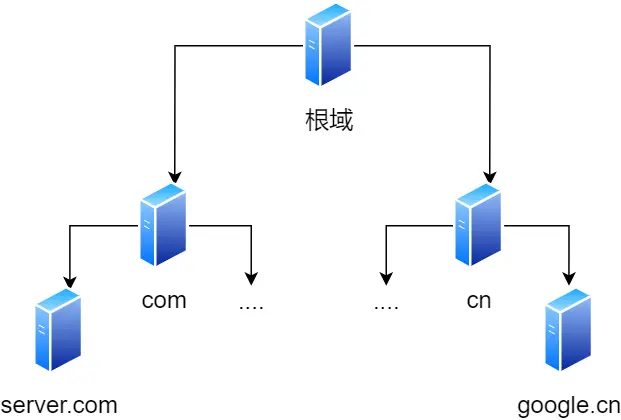
再说DNS
通过浏览器解析 URL 并生成 HTTP 消息后,需要委托操作系统将消息发送给 Web 服务器
但通信对象的IP地址必须提供:DNS服务器里保存了web服务器域名和IP的对应关系
域名层级关系:
www.server.com.句点分隔,越右侧越高级

根域DNS服务器信息保存在互联网中所有的 DNS 服务器中
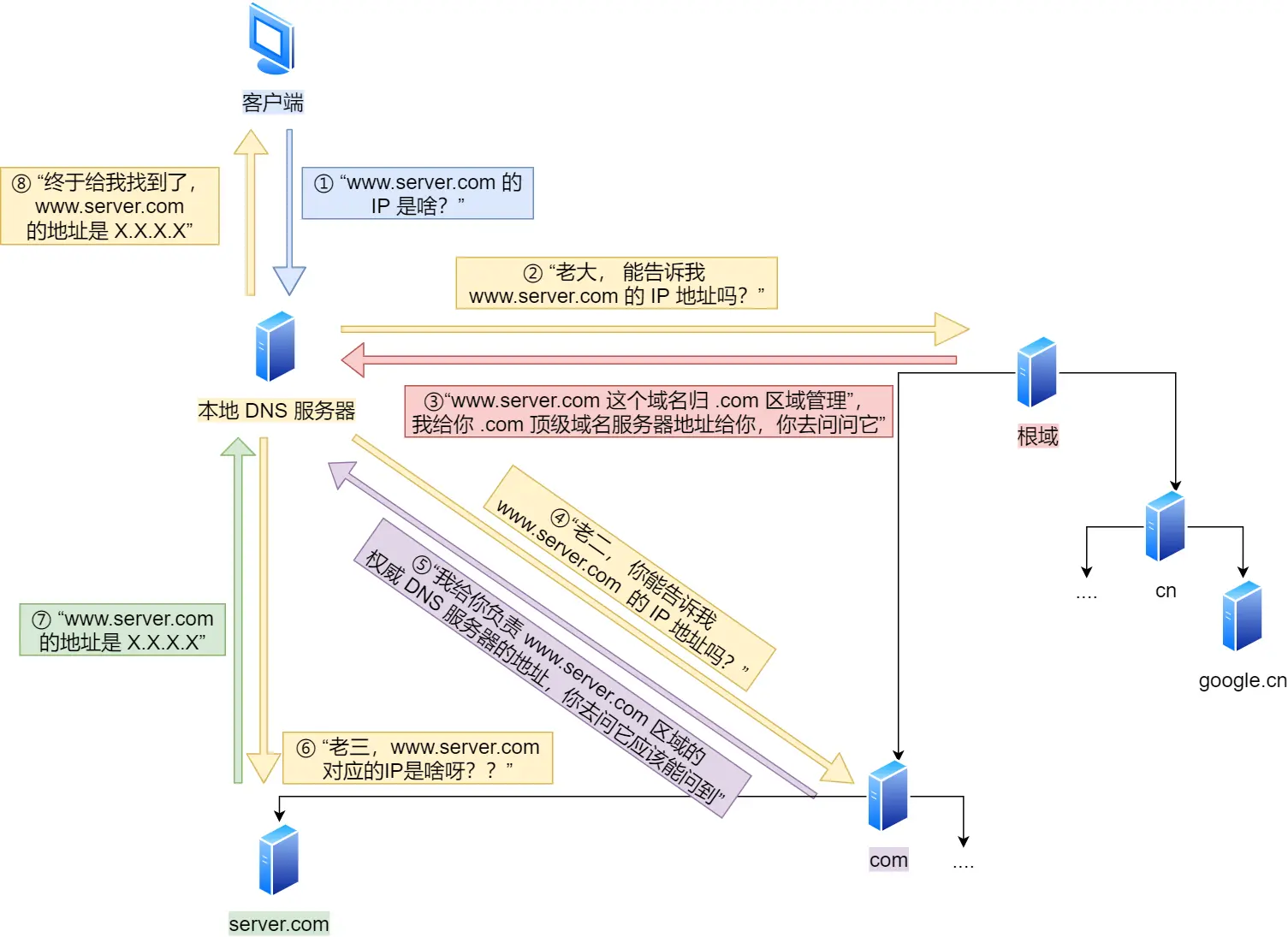
访问过的就存到hosts文件里,下次直接拿,没有就问本地DNS服务器
至此 数据包 知道了目的地
再说协议栈:
通过DNS或得到IP后,就把HTTP传输工作交给操作系统的协议栈
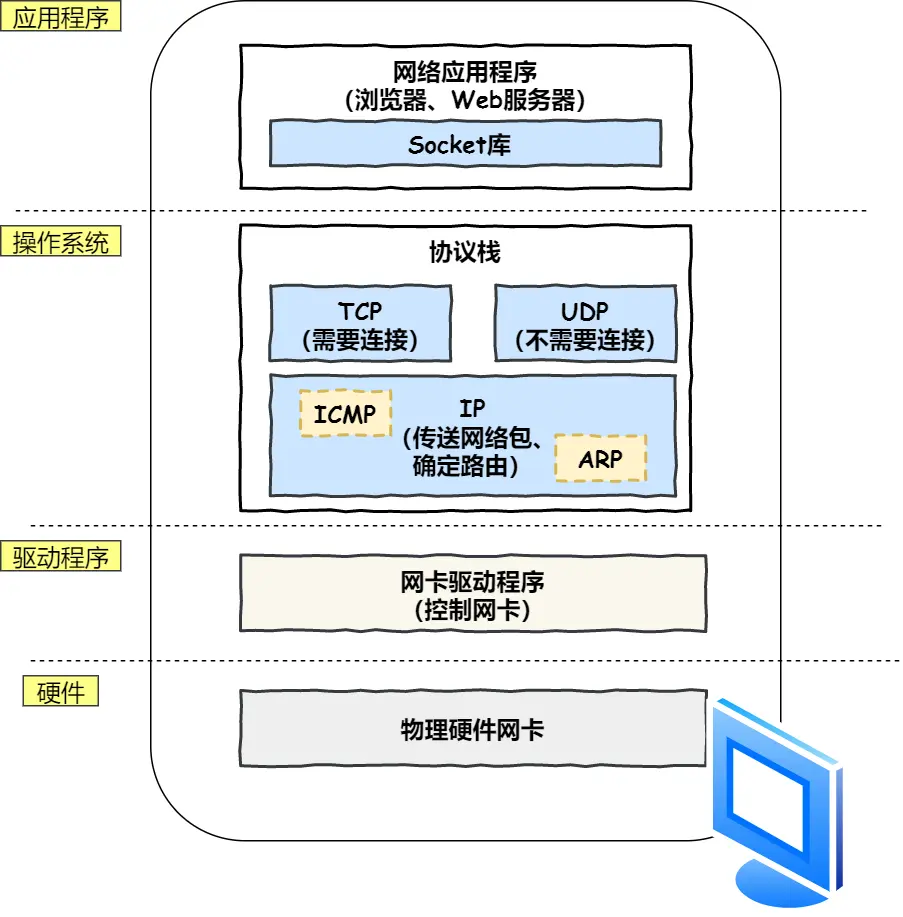
协议栈:
上半部分TCP、UDP协议执行收发数据工作,主要端到端进程,把应用层的数据分段重组,通过端口号区分不同的应用程序
下半部分IP协议负责控制网络包收发操作,即将网络包发送给对方,主要是源主机→目的主机,不同网络之间的,不关心具体内容和可靠性,负责网络层的寻址和路由选择
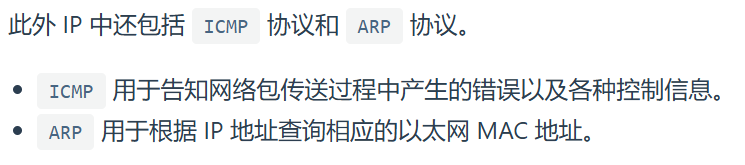
IP里:
ICMP 用于告知网络包传送过程中产生的错误以及各种控制信息
ARP 用于根据 IP 地址查询相应的以太网 MAC 地址
小细节:
应用程序(浏览器)通过调用 Socket 库,socket依托操作系统来工作,操作系统管理各种协议栈、网卡驱动程序,来委托协议栈工作,其实是网络通信模型在操作系统层面的映射示意,展示应用程序通过操作系统的 Socket 库、协议栈、网卡驱动等实现网络通信,体现软件与底层硬件交互在操作系统中的协作关系
所以先是应用层的协议(如 HTTP)确定使用的 TCP 端口号(为了让数据能够准确地交付到目标应用程序),然后再由网络层的 IP 协议来处理网络地址网络号啥的(为了正确路由和传输到目的主机)
传输层TCP传输端口
网络层传IP(主机地址就是IP头里的IP地址)
数据链路层传MAC
至此 数据包 知道了先去找TCP
TCP:
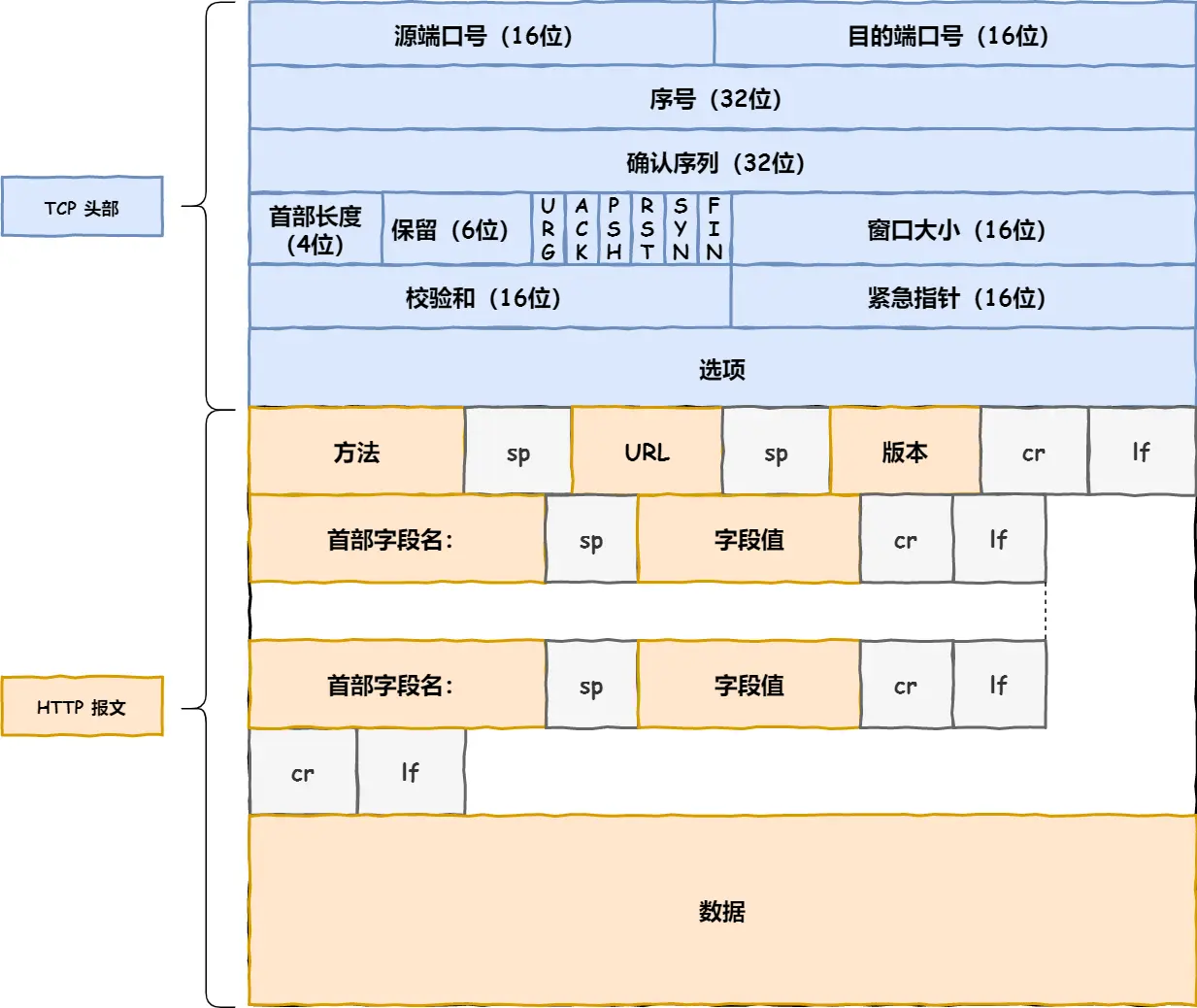
先看TCP报文头部格式:
源头端口号 & 目的端口号:数据知道发给哪个应用
包的序号:这个是为了解决包乱序的问题
确认号:目的是确认发出去对方是否有收到。没有收到就应该重新发送,直到送达,这个是为了解决丢包的问题
状态位:例如 SYN 是发起一个连接,ACK 是回复,RST 是重新连接,FIN 是结束连接等
窗口大小(缓存大小):做流量控制
拥塞控制
TCP传输数据前要TCP建立连接,成为三次握手,所谓「连接」,只是双方计算机里维护一个状态机
这里不展开,下面TCP篇有详细
然后分割数据
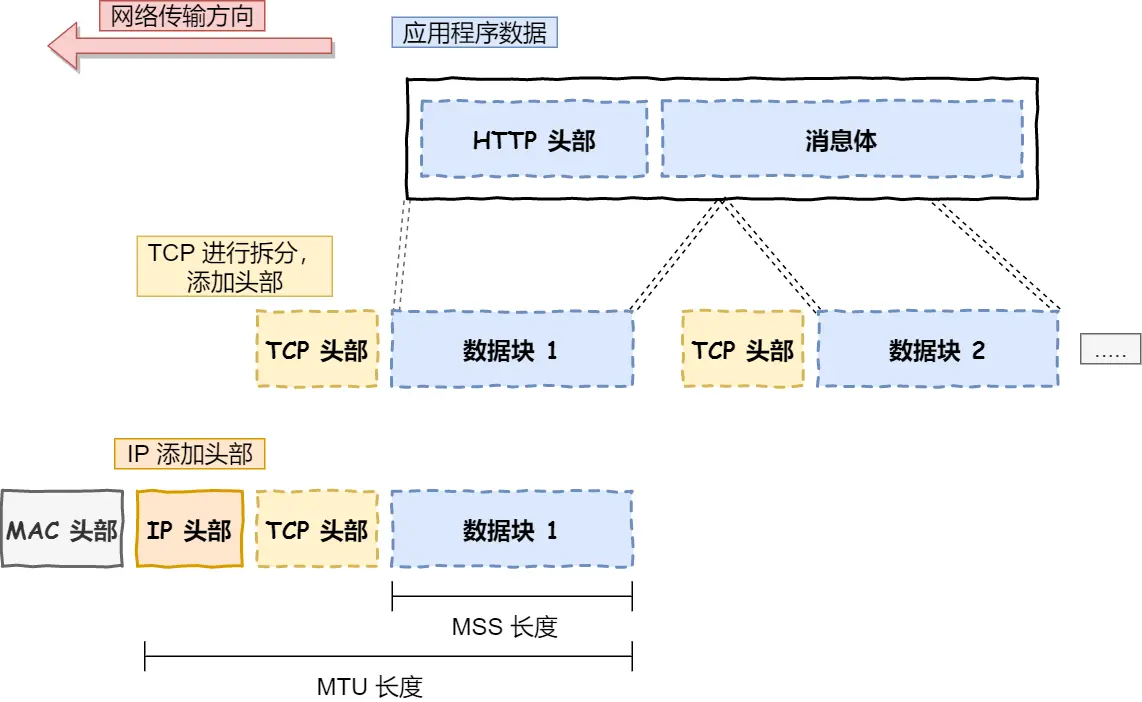
然后TCP报文生成
TCP协议里有俩端口:
一个是浏览器监听的端口(通常是随机生成的)
一个是 Web 服务器监听的端口(HTTP 默认端口号是 80, HTTPS 默认端口号是 443)
TCP 报文:TCP头部+数据,而数据指的是 HTTP 头部 +消息体,组装好后交给网络层处理(注意:HTTP头部就是下图http报文里首部字段名那些,消息体就是数据)
网络包报文
至此通过TCP给数据包加上TCP头部,然后研究往哪里走
引入网络层IP
TCP 模块在执行连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成网络包发送给通信对象
IP头部:
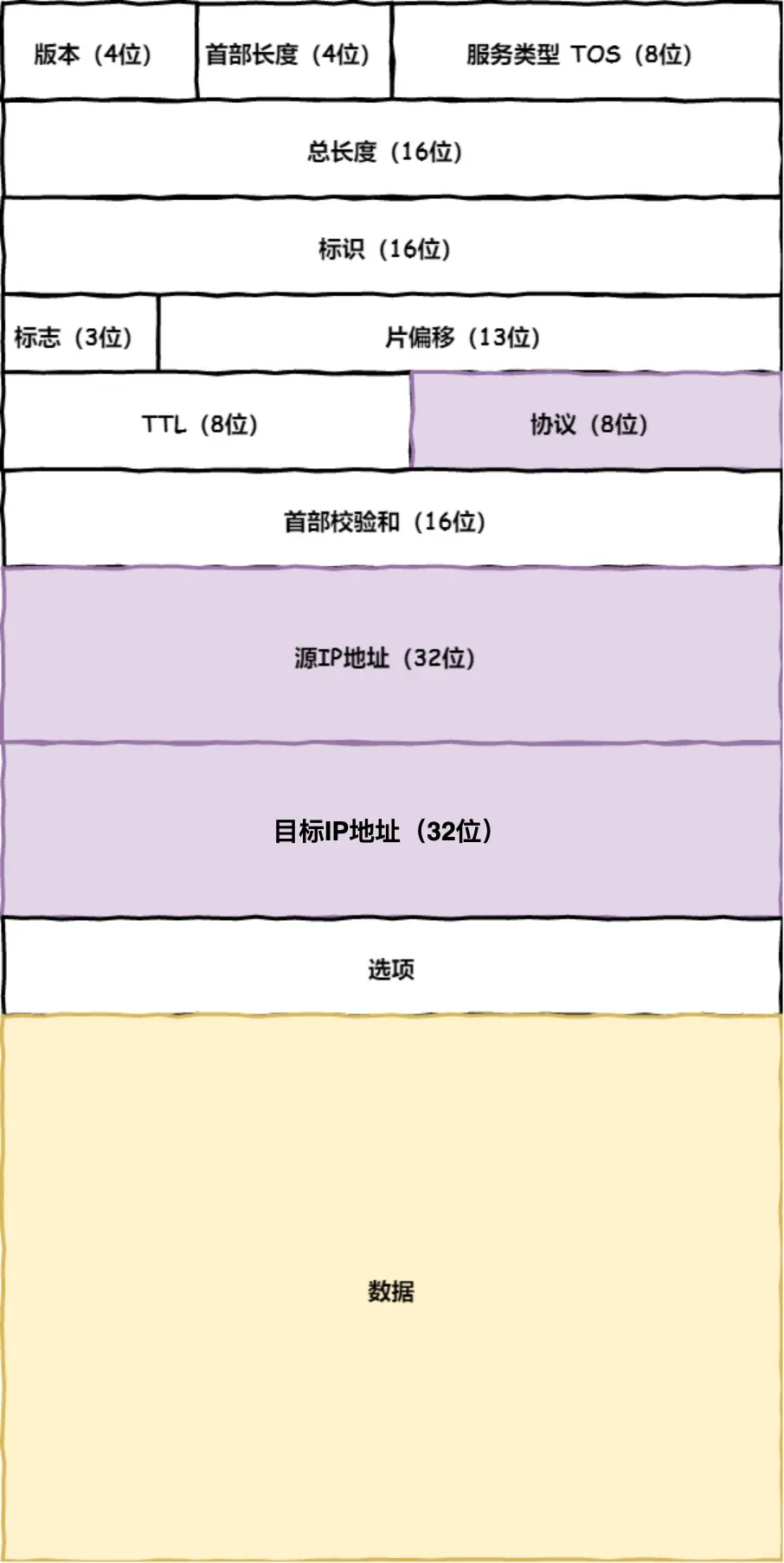

协议号要填写为 06(十六进制),表示协议为 TCP,因为http是经过TCP传输的
如果客户端有多个网卡,就有多个IP,那源地址IP咋确定呢?
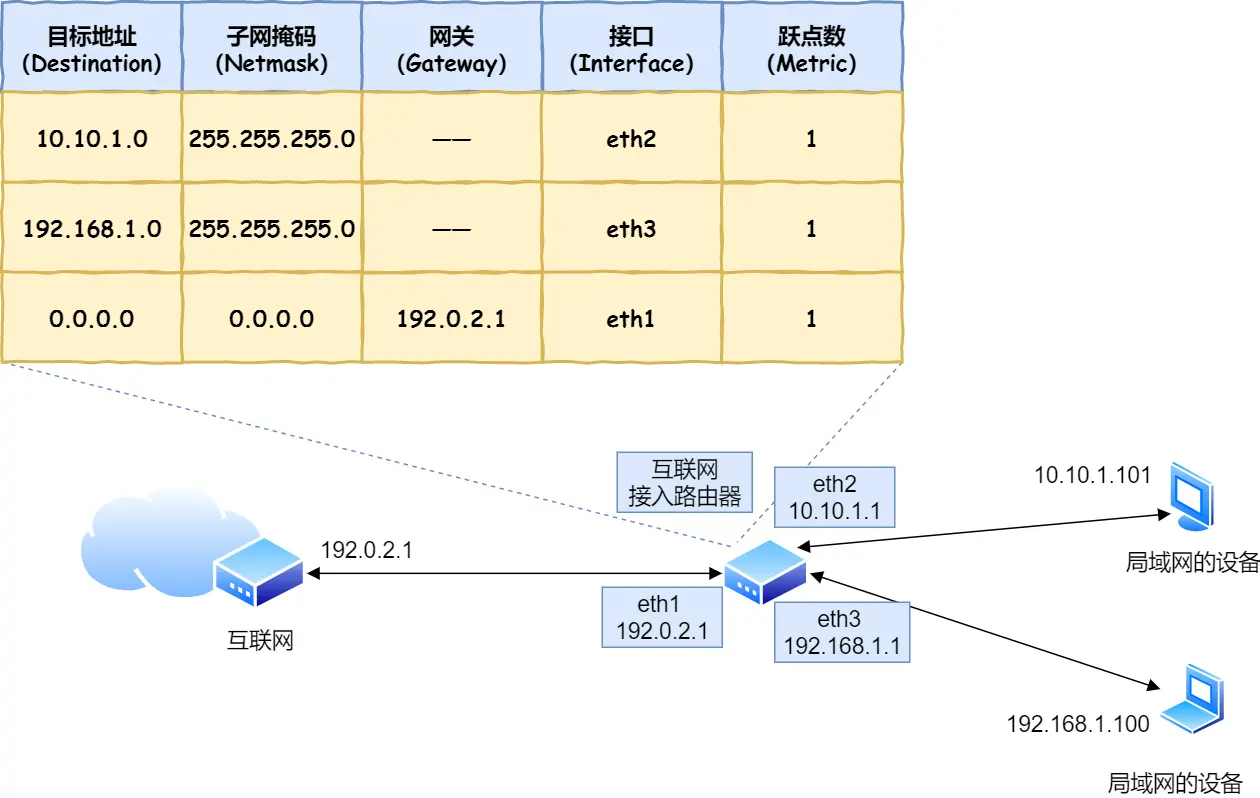
需要根据路由表规则,确定选择哪一网卡作为源地址IP,用 route -n查看Linux系统路由表
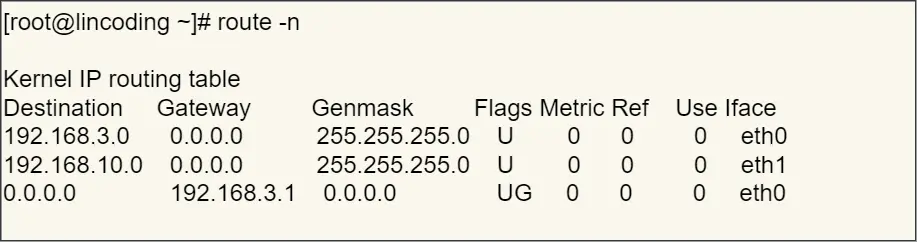
然后,挨个条目的Genmask(子网掩码)做与运算,结果去和Destination 对比,决定发送给那个路由器IP地址(即Gateway,即网关,网络连接的枢纽,用于连接不同网段,实现网络之间数据转发和通信)
都不行就最后一个0.0.0.0
目标地址和子网掩码都是 0.0.0.0,这表示默认网关
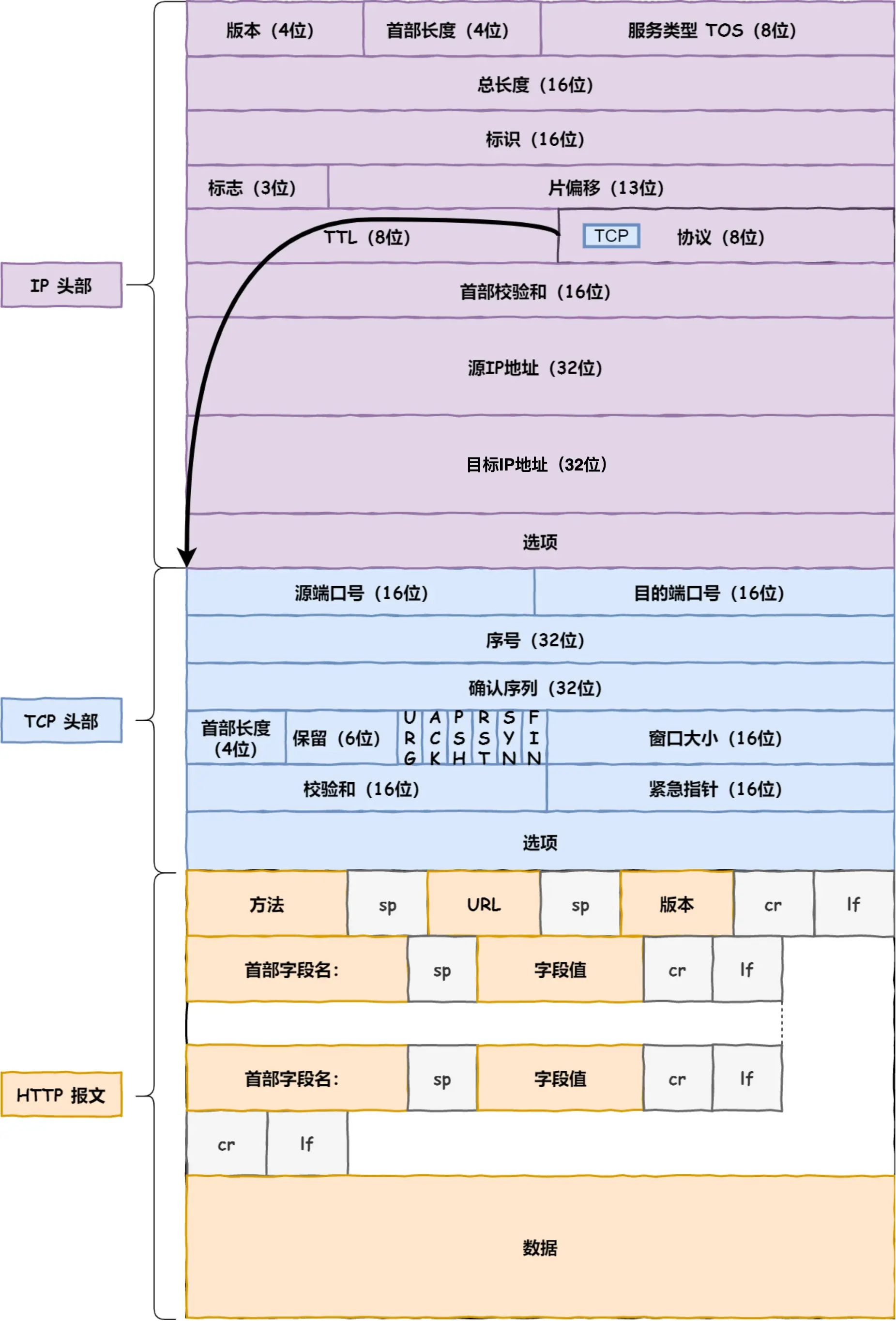
此时加上IP头部,知道了远程定位的目的地,该改咋去?
两点传输 —— MAC:
生成了 IP 头部之后,接下来网络包还需要在 IP 头部的前面加上 MAC 头部
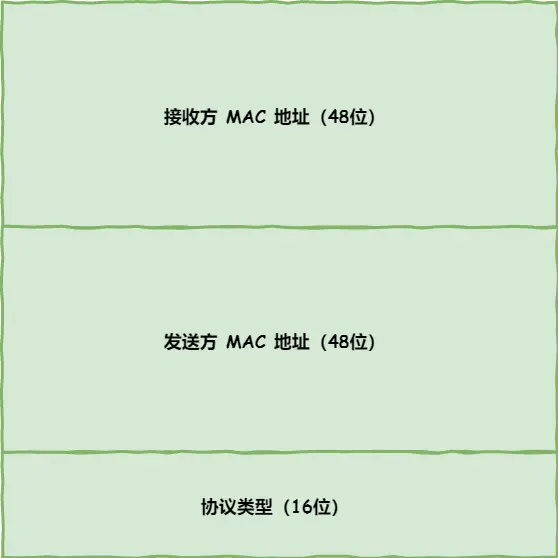
TCP/IP通信里,MAC包头协议类型只有:
0800: IP 协议0806: ARP 协议
发送方MAC:在网卡生产时写入到 ROM 里,读取后写到到MAC头部就行
接收方MAC:查路由表,找到匹配条目,发给Gateway列中的IP地址
(这里有错字,勘误)
知道IP地址后通过ARP协议找到MAC地址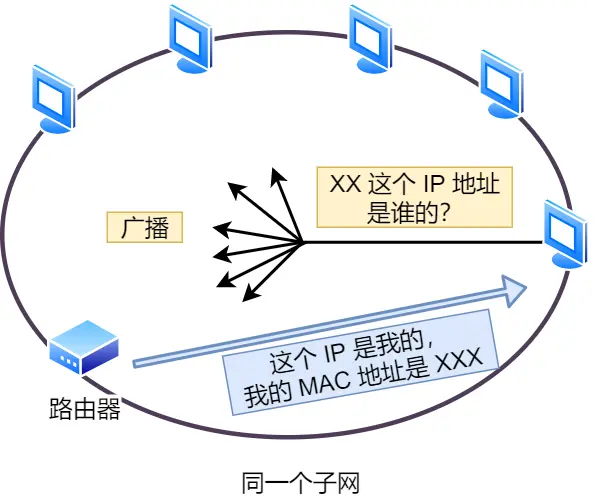
ARP 协议会在以太网中以广播的形式,对以太网所有的设备喊出:“这个 IP 地址是谁的?请把你的 MAC 地址告诉我”
然后就会有人回答:“这个 IP 地址是我的,我的 MAC 地址是 XXXX”
至此头部 双方的MAC 就有了
操作系统会把本次查询结果放到一块叫做 ARP缓存表 的内存空间下次用,但只存在几分钟
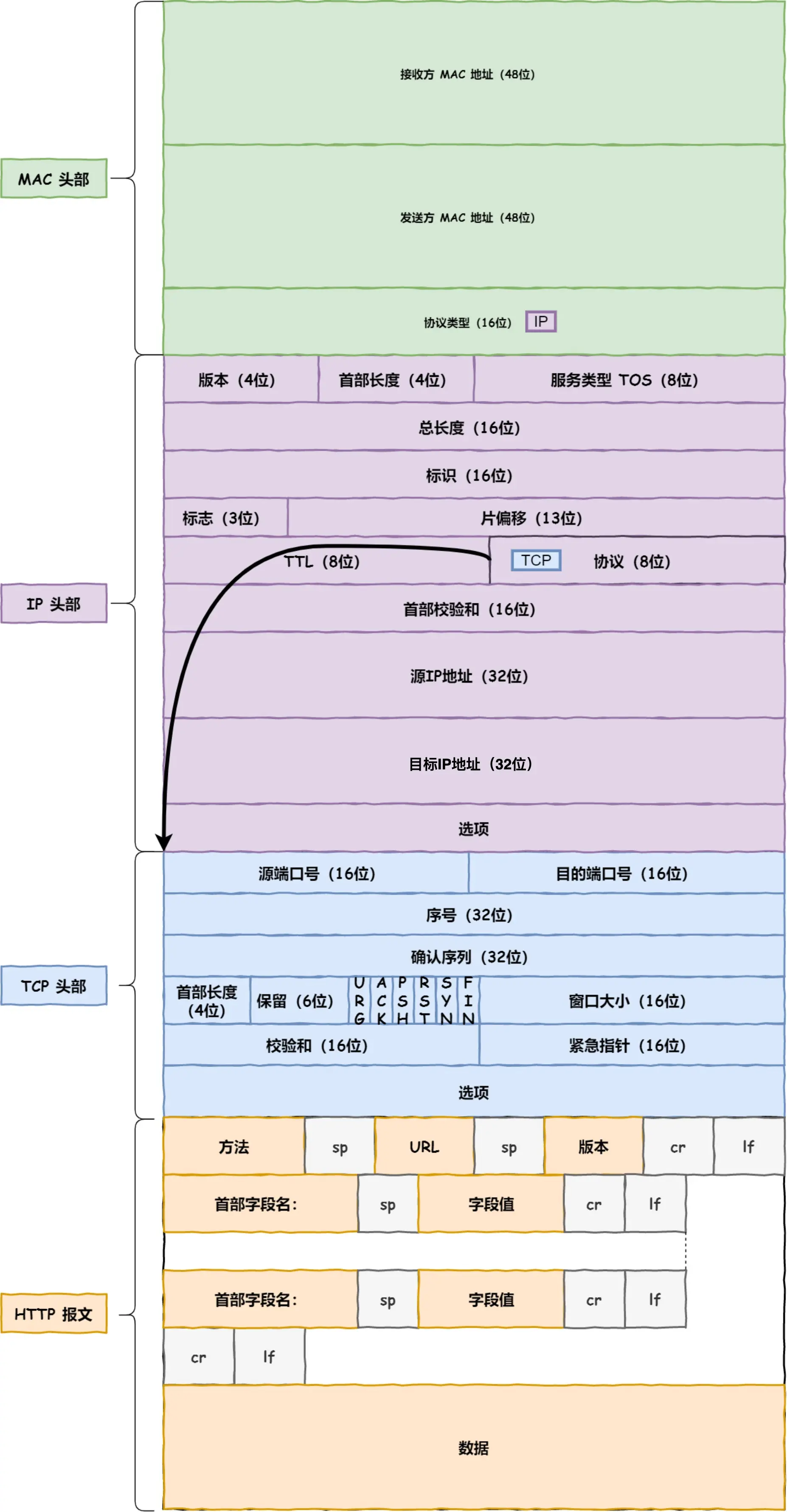
至此通过加MAC头部,数据包知道去哪了
网络包只是存放在内存中的一串二进制数字信息,没有办法直接发送给对方,因此,我们需要靠网卡驱动程序,用网卡将数字信息转换为电信号,才能在网线上传输,也就是说,这才是真正的数据发送过程
网卡驱动获取网络包之后,会将其复制到网卡内的缓存区中,然后会在其开头加上报头和起始帧分界符(包起始位置),在末尾加上用于检测错误的帧校验序列(看包是否损坏)
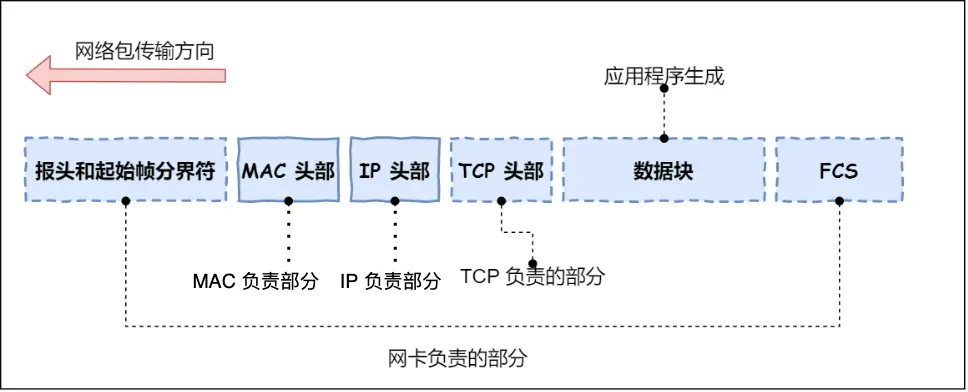
最后通过电信号,通过网线发送出去。至此数据包带着诸多头部出发了,但这只是刚出自己电脑这头,现在开始去往目的地的过程
交换机(数据链路层设备)
类似一个大门门卫:
概念及知识细节:
工作流程:
电信号到达网线接口,交换机里的模块进行接收,接下来交换机里的模块将电信号转换为数字信号。然后通过包末尾的 FCS 校验错误,如果没问题则放到缓冲区。
但注意,计算机网卡本身有MAC,并通过核对收到的包的接收方 MAC 地址判断是不是发给自己的,如果不是发给自己的则丢弃。不会承担中转任务,属于终端设备
但交换机的端口不核对接收方 MAC 地址,而是直接接收所有的包,并存放到缓冲区中(因此,交换机端口没MAC地址),然后查MAC地址表
当交换机收到一个数据包时,它会根据数据包中的源 MAC 地址来更新自己的 MAC 地址表,记录下该源 MAC 地址对应的端口,这样以后如果有发往这个源 MAC 地址设备的数据包,交换机就知道该从哪个端口(主要是有线网络)转发出。一般都是假设交换机端口跟设备都是稳定连接的,这里又纠结了好久钻牛角尖
MAC地址表里的端口是交换机(二层网络设备)的物理端口
接受端口:
当设备 A 通过网线连接到交换机的端口 1 并发送数据时,交换机的端口 1 是接收端口(数据从这里进入交换机内部)
接收端口的核心作用是读取数据帧的源 MAC 地址,并记录到 MAC 表中(例如:设备A的MAC → 端口1
发送端口:
交换机根据 MAC 地址表或广播规则,将数据帧转发到外部设备的物理接口
层次:
一层物理层
二层(MAC层)指的是数据链路层(处理MAC,交换机工作在此,交换机连接同一子网内的 “端”,按 MAC 表转发)(以太网是该层的典型实现技术)
三层指的是网络层(处理IP地址,路由器工作在此,负责跨子网 “路途” 的路由转发)
四层是传输层
唉,这么学东西太痛苦了,总之钻研的很深,不然不放弃,而且当时豆包链接,根本读不下去,跟新学一样,当初刷算法后,菜鸟教程、TCPIP网络编程尹圣雨,一场空都白啃了~~~~(>_<)~~~~
广播地址:
子网广播地址(如 192.168.1.255):指定这个网络(192.168.1.0/24 这个子网)的所有设备。可跨网段(需路由器支持)
受限广播地址(255.255.255.255):跟上面的一样,只不过默认自己这个子网,不涉及任何子网指定,仅作用于当前未路由的本地网络,无法跨网段
当IP层用那些广播地址时候,链路层会用MAC 的 广播地址 FF:FF:FF:FF:FF:FF 封装(一般255那个是本地设备启动时找 DHCP 服务器定IP地址临时广播用的)
子网掩码 255.255.255.0 会和IP地址搭配划分网络/主机位,不会单独作为地址用
场景:


细节:

注意:
交换机本身有MAC地址,但端口无MAC,接受所有帧。MAC地址表有就直接找端口发,没有就广播泛洪(泛洪是交换机的事),更新表

泛洪是交换机在数据链路层的行为,路由器工作在网络层。当交换机泛洪时,路由器一般不会对这种基于 MAC 地址的泛洪进行回应



网卡是看不是自己的就丢,自己的就接 交换机是,都接收,然后表里有就精准转发,没有就泛洪,泛洪的时候其他设备忽略这个包
设计原理:


至此先插入几个自己追问豆包的知识点:
为何有了IP地址还要用MAC,主机地址不能确定吗?
不同局域网内的IP地址可能相同,而MAC唯一的。虽然确定了子网,子网内不会有相同IP,但IP是网络层的东西,用于路由选择,确定数据要往哪个子网传输。
而 MAC 地址是数据链路层的地址,需要通过 MAC 地址来准确找到目标设备,或者说网络接口层数据链路层是不认IP地址的,所以哪怕有主机地址也没用,因为数据在网卡层面传输时,根本 “看不懂” IP 地址,只认得 MAC 地址
且动态分配IP会变,比如更换子网了,那IP的网络号一定会变,而MAC不变
且设备发送广播消息时,所有设备都会收到。如果仅依靠 IP 地址来确定目标设备,那么每个设备都需要对收到的广播消息中的 IP 地址进行检查,这会消耗大量的 CPU 资源。而 MAC 地址可以让设备在数据链路层就直接判断是否是自己的消息,减少不必要的处理(没懂,我感觉就算MAC,主机们也会看是不是自己的MAC啊。不纠结了,钻牛角尖了)
适配器:
一种能使不同设备或系统相互兼容、协同工作的设备或软件,它就像一个 “桥梁” 或 “转换器”
例如,电源适配器能将市电转换为适合电子设备使用的特定电压和电流;网络适配器能让计算机通过不同的网络接口连接到网络。
IP协议里是:ICMP 协议和 ARP 协议,MAC包头有: IP 协议 和 ARP 协议,咋交叉都有啊?好混乱:



数据链路层通过MAC地址转发数据帧,
IP里有ARP为了映射MAC地址
MAC包头有ARP是因为ARP数据包要通过MAC帧传输,ARP用于将网络层的IP解析为数据链路层MAC
妈逼的又有了刷算法题的感觉,这些人到达是死背书还是咋回事啊,我不断追问才发现,小林coding讲的太浅了吧?MAC头部是每经过网关都会变的!!
再次深入解释刚追问学到的知识:(具体追问历程可以看开头基础篇更新下的豆包链接)
首先,他文中写的这个就很误导人!!
但这个是对的

因为ARP根本不是IP里有的!!!重点是IP来驱动ARP,ARP是工具人!
每次跨网段转发时,MAC 头部都会被重新封装,而 IP 数据报本身(包括 TCP 等上层数据)保持不变
ARP本质不是“层”,是独立协议,靠封装传输,独立于IP,跟IP平级,为IP服务,封装在MAC帧里,IP 数据报的传输依赖 MAC 地址,而 MAC 地址的获取依赖 ARP 协议,二者是 “上下游协作”,不是 “IP 包含 ARP
ping用的是ICMP,IP头部协议字段是1,ICMP是IP子协议
ARP用IP解析MAC地址,不经过IP封装,直接封装在链路层的MAC里
触发ARP请求的是网络层IP模块的驱动下发生的,由数据链路层封装ARP请求广播
至此,交换机这里讲了好多细节,数据报离开自己的子网,该路由器了
路由器:

电信号到达网线接口,路由器将电→数字信号,FCS错误校验。检查MAC头部接收方地址,不是自己就丢,是就接受(接受会去掉MAC头部),根据MAC头部后方的IP头部查路由表决定咋转发
假设10.10.1.101 的计算机要向地址为 192.168.1.100 的服务器发,根据接收方IP来判断

知道对方IP后,通过ARP得到接收方MAC,发送方即源MAC填写路由器输出端口的MAC地址,网络包制作完成,转换为电信号通过端口发送
具体:(网关是路由器端口的 IP 地址)

同一局域网内设备通信,交换机直接转发,无需经网关;不同网络间通信时,交换机先将数据转发到连接网关(如路由器)的端口,再由网关进行跨网络转发
琐碎知识点:
局域网是物理范围
局限在小范围(如办公室、家里)的网络,用交换机连接设备,属于同一物理网络
子网是逻辑划分
通过子网掩码从一个大网络划分出的逻辑网络单元,可属于同一局域网,也可跨物理局域网
最后总结:
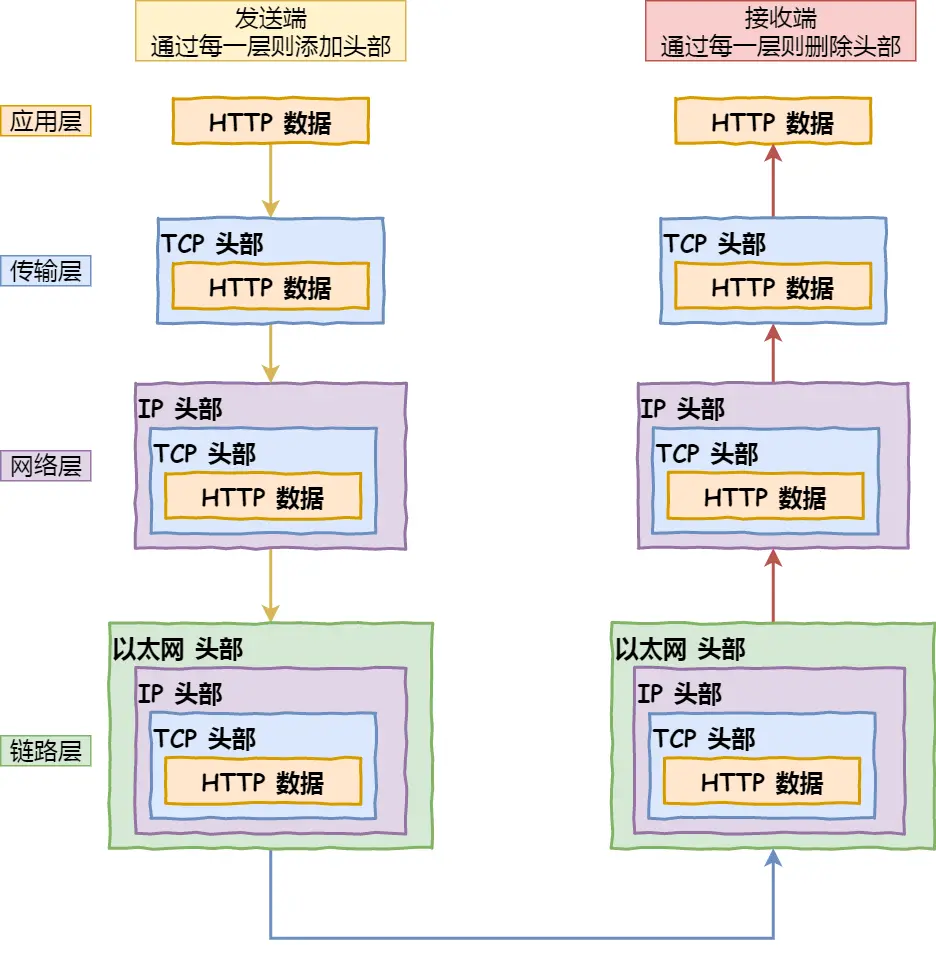


接着说Linux 系统是如何收发网络包的?
OSI是理论网络通信模型,太复杂,具体实现是四层TCP/IP模型
四层负载均衡中的 “四层” 指的是 OSI 七层网络模型中的第四层 —— 传输层
负载均衡它基于传输层的信息(如 IP 地址和端口号 )进行负载均衡决策,将网络流量分配到多个服务器上
七层负载均衡:对应 OSI 模型的第七层 “应用层”
它会解析应用层协议(如 HTTP、FTP 等)的内容,例如根据 HTTP 请求中的 URL、请求头信息等更具体的应用数据来分配流量,能实现更精细的控制,比如根据请求内容将流量导向特定的服务器处理
Linux用的网络协议栈是4层的
吞吐能力:
1 秒内最多能处理多少数据
MTU越大 → 包头占比越低,有效数据传输效率越高,单个数据包携带的数据越多 → n包就要n次确认,协议交互减少 → 传相同数据需要的包数越少 → 有效数据传输效率提升
至此Linux网络协议栈的结构工作流程:
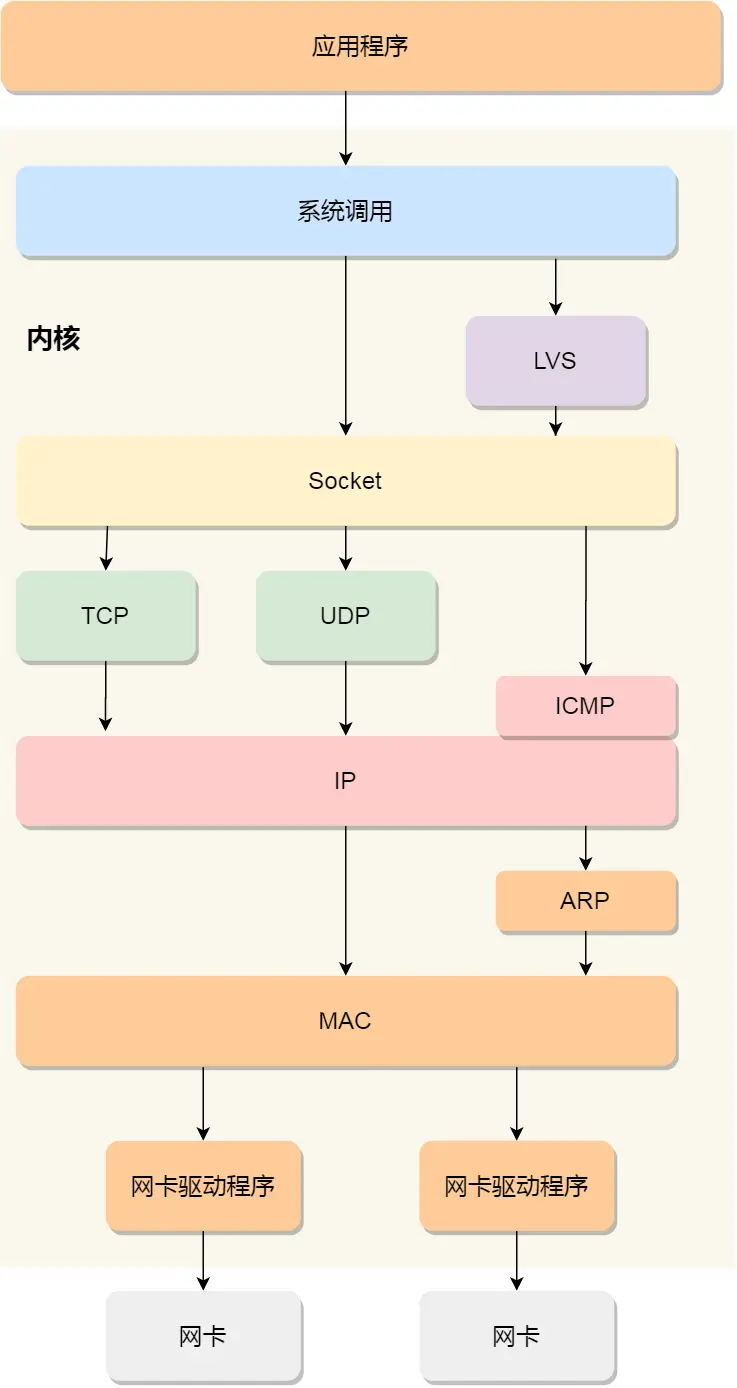
Linux 接收网络包的流程
网卡是计算机里的一个硬件,专门负责接收和发送网络包,当网卡接收到网络包,会通过 DMA技术,将网络包写入指定内存地址, 即Ring Buffer 这环形缓冲区,接着就会告诉操作系统这个网络包已经到达
怎么告诉已经到达?
首先想到触发中断,但高性能频繁中断会影响正常效率,引入NAPI机制:
即混合「中断和轮询」的方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后 poll的方法来轮询数据。
那么网络包到了,DMA写入指定内存,向CPU发硬件中断,CPU根据中断表调用注册中断的处理函数
软中断:
内核中的 ksoftirqd 线程专门负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据
ksoftirqd 线程会从 Ring Buffer 中获取一个数据帧,用 sk_buff 表示,从而可以作为一个网络包交给网络协议栈进行逐层处理
网络协议栈:

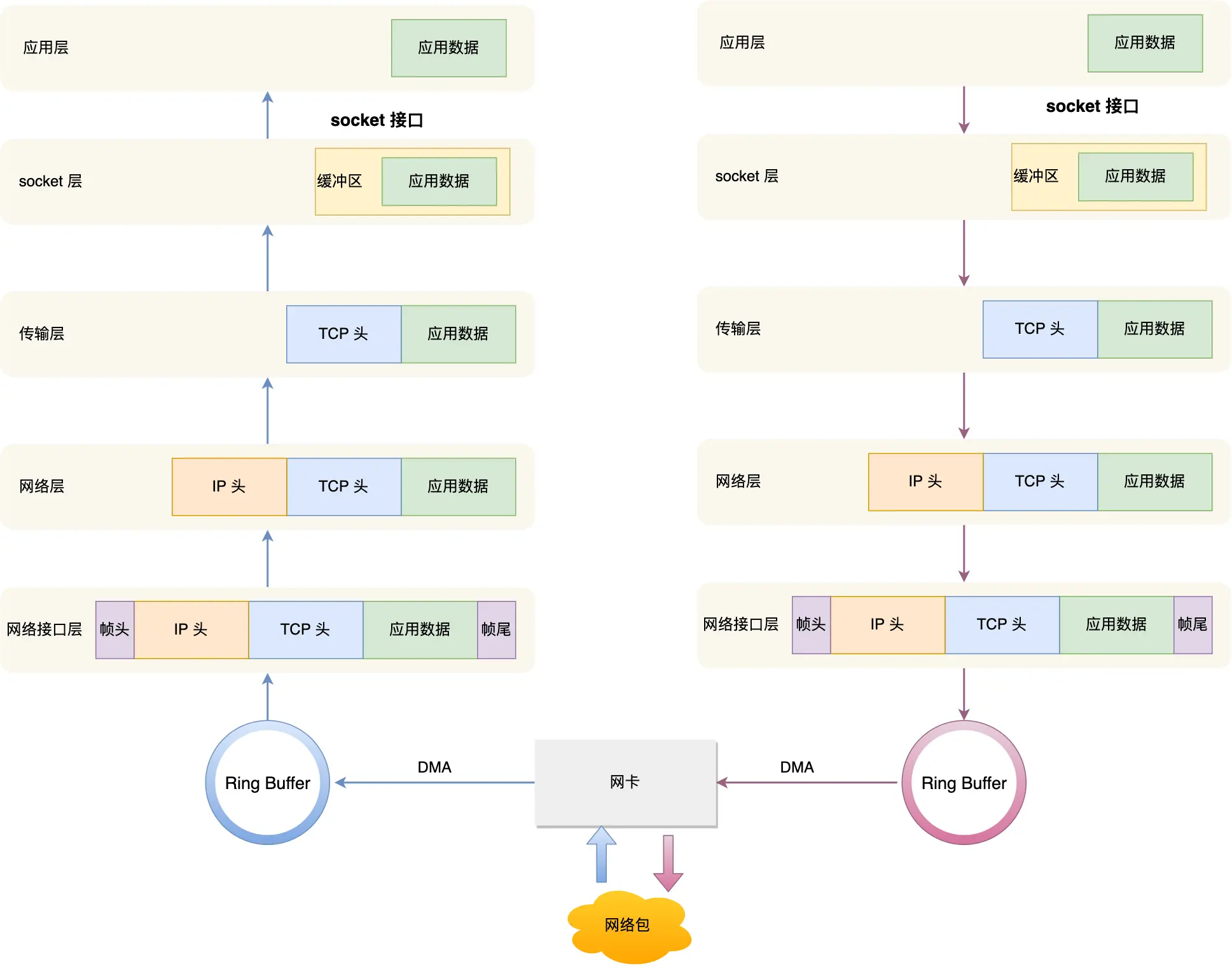
Linux 发送网络包的流程
先说下整体流程:
- 应用层→传输层→网络层→内核协议栈(内存中处理)
比如发微信“你好”,“你好”就是应用层数据,存储在进程缓冲区也叫用户空间内存,数据是:[你好]。(接下来下面该到了内核协议栈了)
通过系统调用socket.send(),从用户空间复制到内核空间内存也就是内核协议栈的缓冲区,逐层加头部:比如现在是传输层,那就TCP传输层拆分成MSS小块,添加端口号比如5000,数据变成:[端口号5000][你好
继续到了网络层添加源IP目的IP,数据变成:[源IP:192.168.1.100][目标IP:114.114.114.114][端口号5000][你好]
至此,数据包处理好了,但本质依旧是内存中的二进制数据块,尚未离开计算机
- 接口层(内核网卡驱动→网卡硬件)
内核协议栈处理完后,数据进入网卡驱动程序(内核空间的一部分),驱动会将数据从内核内存复制到网卡的硬件缓冲区 (最后也是由他发送到网络上,即交换机路由器),即名叫 Ring Buffer 的发送环形缓冲区,属于网卡硬件的一部分,位于网卡自带内存
添加源MAC目的MAC,数据变成:[源MAC:00:1A...][目标MAC:00:AA...][源IP...][目标IP...][端口号...][你好]
数据在计算机内是 “从上到下逐层包装”,最后才交给网卡发送
- 至此通过交换机路由器开始发送
好至此了解了基本宏观框架,再回顾说接收机制
至此发现,无论是发送还是接收,数据在用户空间内存(应用层)、内核空间内存(协议栈)、硬件缓冲区(网卡 Ring Buffer)之间流动,但所有高层协议处理(如封装 / 拆包)都在内核空间内存中由内核协议栈完成
数据从用户空间→内核空间→网卡硬件缓冲区(可能通过主内存或直接到网卡自带内存),最终由网卡硬件发送。
网卡硬件→DMA 写入主内存(内核空间)→内核处理→用户空间。
核心逻辑:网卡作为硬件,不能直接处理用户数据,必须通过内存(内核空间)与操作系统交互,DMA 技术让硬件能高效访问内存,避免 CPU 瓶颈
内核是操作系统的核心,负责管理内存空间,划分用户空间(应用程序使用)和内核空间(系统级代码,如协议栈、驱动程序使用),两者隔离以保证稳定性
再次从不同角度啰嗦一下加深记忆:
至此稍微加深了粗浅的了解,脑子不受控制的开始回忆发散思维联想各种东西:
啃尹圣雨TCPIP网络编程时的 signal()、sigaction() 属于用户态中断处理,比如输入个Ctrl+C是SIGINT信号,该信号发生自动执行我们自定义的函数
但 request_irq () 、devm_request_irq () 都属于内核
DMA中断属于这个吗?
不是
DMA:
本质:属于 硬件层面的中断,由外设(如硬盘、网卡)或 DMA 控制器主动触发,用于通知 CPU“DMA 数据传输已完成”,仅标记事件
触发方式:在操作系统内核或硬件驱动中,通过 注册硬件中断处理函数 实现(如 Linux 内核的 request_irq),属于 内核态编程
应用场景:硬件设备与内存之间的高效数据传输(如网卡接收数据、磁盘读写),减少 CPU 干预(DMA 控制器接管数据传输控制权,CPU 仅需初始化配置(如设定数据源、目标、传输量等),启动后 DMA 直接在内存与外设间传输数据,无需 CPU 逐字节搬运。传输完成后 DMA 发中断通知 CPU,期间 CPU 可执行其他任务,从而减少对数据传输过程的干预)
SIGINT:
处理方式:在用户空间通过 signal 或 sigaction 注册自定义处理函数,属于 用户态编程。
应用场景:进程间通信、用户输入响应、程序调试(如 SIGTRAP)等。
但跟DMA同属于内核态中断搭配去理解的是 ksoftirqd,解释ksoftirqd和DMA:
发送数据时:CPU 只需告诉 DMA 控制器 “从内存某地址发数据到网卡”,DMA 控制器负责完成数据搬运,网卡发送完成后再通知 CPU
接收数据时:网卡收到数据包后,通过 DMA 直接把数据写入 主机内存缓冲区无需 CPU 参与
为了清晰,说下没DMA的话理论上是咋操作
接收时(网卡→内存),没DMA,CPU 需亲自完成“读网卡→搬数据→处理协议:
没DMA的话,从网卡硬件缓冲区逐字节 / 逐包读取数据,复制到内存(内核协议栈缓冲区),再逐层处理(网络层解 IP 头、传输层解 TCP/UDP 头,最终到应用层)
发送时(内存→网卡):
没DMA的话,CPU 需将内核协议栈处理好的数据(内存中)逐字节写入网卡硬件缓冲区,直到网卡发送完毕,全程盯着网卡
但注意:
发送数据的真实流程(无论有无 DMA,CPU 都参与关键步骤):
应用程序通过socket.send()触发系统调用,CPU 将用户空间数据复制到内核空间,并逐层添加协议头(TCP/UDP/IP 头)
-
-
有 DMA:CPU 配置 DMA 控制器(告诉它 “从内核内存某地址搬数据到网卡 Tx 缓冲区,长度 XX”),DMA 接手搬运,搬完后发中断通知 CPU。
-
无 DMA:CPU 亲自将内核内存数据写入网卡 Tx 缓冲区(逐字节 / 逐包写),写完后才能继续其他任务。
-
无论是否用 DMA,网卡将数据转为电信号发送的过程由硬件自动完成,CPU 不参与。
再解释一些术语:
总结:
-
操作系统(软件) 运行在 CPU(硬件) 上,管理 内存(硬件)和 磁盘(硬件)
-
应用程序(如微信) 运行在 用户内存(内存硬件的一部分),通过操作系统提供的接口请求硬件操作(如发送数据到网卡)。
-
数据流动必须经过内存:CPU 处理数据时,数据需先从磁盘加载到内存;发送网络数据时,数据需从用户内存→内核内存→网卡硬件缓冲区
啰嗦一些不知道有没有用但却是自己学东西一直以来的习惯(即强迫症)导致追问出来的细节:
CPU 主要与内存进行数据交互,因为内存的读写速度相对较快,能满足 CPU 高速处理数据的需求。但 CPU 也能通过输入输出接口和总线与其他设备交互,如硬盘、显卡、键盘、鼠标等,实现数据的读取、写入和控制等操作,只是这些设备的数据传输速度通常比内存慢,需要通过特定的控制器和协议与 CPU 进行通信
代码运行原理:操作系统和应用程序的代码平时存于硬盘(持久存储),运行时需先加载到内存(RAM)。CPU 仅能直接读取内存中的指令和数据,无法直接运行硬盘中的代码。
三者关系(类比理解):
-
-
硬盘:相当于 “仓库”,长期存放代码和数据(断电不丢)。
-
内存:相当于 “工作台”,CPU 从内存中快速取指令、处理数据(断电数据消失)。
-
CPU:相当于 “工人”,按顺序执行内存中的指令,完成计算
-
操作系统通过虚拟内存机制将内存划分为内核空间和用户空间两个逻辑分区。
所谓CPU将数据调用到内核空间,本质是逻辑区的用户空间的代码,移动到逻辑区内核空间,都是一块内存中
CPU即处理器,CPU内核即处理器的核心,CPU内核是硬件概念,独立计算单元,多核 CPU(如 4 核、8 核)就是多个 CPU 内核集成在一起
操作系统是总管家
CPU类似工人
内存RAM类似大仓库,工人(CPU内核)从这取材料放成品
用户空间:普通工作区
内核空间:管理员办公室
ksoftirqd 是内存内核(内核空间)的内核线程,负责处理软中断任务(如网络数据、定时器事件),运行在内核空间,与 CPU 内核(硬件计算单元)无关
Ring Buffer 是位于内核内存中的,由网卡通过 DMA 将数据写入其中,供 ksoftirqd 线程读取
轮询是客户端主动定期向服务器或设备发送请求以获取数据或状态更新的通信方式
关于接受和读取再说深入一点,便于理解小林coding2.3这章(之前啃菜鸟教程、TCPIP网络编程尹圣雨,每一页每一个字都是这么过来的,只是之前没这么整理,现在这是根据豆包链接回头后整理的,看了机械上岸腾讯感觉要重复看,之前只是无脑截豆包追问图 — 啃菜鸟教程时期,放链接 — 啃TCPIP网络编程时期,没做整理总结,但豆包追问是都没落下):
-
- Socket 是应用层与传输层的 “衔接桥梁”:或者说应用层调用传输层服务的接口(一般也叫Socket层,服务的接口层),应用层通过系统调用(如
send()/recv())经 socket 接口,让内核网络协议栈处理数据收发,它本身不固定在用户或内核空间,而是通过系统调用在两者间衔接
- Socket 是应用层与传输层的 “衔接桥梁”:或者说应用层调用传输层服务的接口(一般也叫Socket层,服务的接口层),应用层通过系统调用(如
写代码时创建的 Socket(如socket()函数),会在系统内核中对应一个结构体,绑定了四元组(源 IP + 端口、目标 IP + 端口)
-
-
当传输层(TCP/UDP)收到数据后,用数据中的四元组作为 “快递单号”,在内核维护的Socket 表中查找匹配的 Socket 结构体,找到后才能通过这个 Socket 将数据递交给对应的应用程序(比如你写的客户端 / 服务器进程)
bind()(绑定端口)、accept()(建立连接)等操作,本质是在填充 Socket 的四元组信息,让传输层能精准匹配-
Socket 是传输层识别应用进程的 “唯一身份证”,四元组就是这张身份证的号码,传输层靠它从内核的 Socket 表中找到对应的应用程序连接,实现数据交付
-
写服务器代码时:
Socket 是应用层操作传输层(端口、连接)的 “手柄”,网络层(IP)是传输层下面的 “跑腿的”,Socket 只和传输层直接打交道,网络层对应用层不可见
内核的 socket 层:属于应用层下,传输层之上的接口层,可不是我们说的分层里的那个网络层下的网络接口层啊,别误解了
socket层的发送缓冲区处于用户态和内核态的交互层面:
因为应用层比如微信发个“你好”,数据处于用户态,socket调用send()函数,想把“你好”发出去,那一方面send()是用户可以调用的东西,也是socket的对外接口或者说函数
另一方面有了send(),os底层机制会主动触发CPU从用户态到内核态,进入内核执行内核函数,操作系统也就控制内核内存,把“你好”放到sk_buff的内核空间,sk_buff本质是内核中用于管理网络数据报的核心数据结构,负责在不同的网络协议层之间传递和处理数据包。申请sk_buff 内存,是为了给即将发送的数据分配一个 “载体”,它会记录数据的位置、长度、各层协议头信息啥的。接着再放入待发送的socket缓冲区
sk_buff 内核空间的结构体(不是数据本身!),用于下面网络协议的一个承载,用于 “管理” 数据包,包含指针(指向数据缓冲区)、长度、协议层信息等。就像一个 “数据包的户口本”,记录数据包的元数据,但不直接存数据(数据存在它指向的缓冲区里)
知道了内存内核、CPU内核,那操作系统又是啥?
操作系统内核是最核心的那段代码,负责内存管理、进程调度、硬件驱动等核心功能的 “最小必要部分”,其实日常说操作系统就是省略内核的叫法。宏观的操作系统较真起来其实除了操作系统内核,还包括用户可见的界面,系统管理器啥的
关于数据砸到网卡的就不研究了,帖个问小白回答得了
-
- 无线网卡工作原理: 无线数据通过电磁波传输,网卡的PHY层(物理层)将数字信号调制成射频信号发送,接收时解调为数字信号。例如,Wi-Fi网卡基于IEEE 802.11协议,通过载波侦听(CSMA/CA)避免冲突
-
- DMA的直接内存访问: 无论有线或无线,网卡均通过DMA控制器直接读写内存,数据绕过CPU拷贝。例如,无线网卡接收数据时,DMA将射频信号解调后的数据直接写入内核缓冲区,触发硬中断后由协议栈处理
- DMA的直接内存访问: 无论有线或无线,网卡均通过DMA控制器直接读写内存,数据绕过CPU拷贝。例如,无线网卡接收数据时,DMA将射频信号解调后的数据直接写入内核缓冲区,触发硬中断后由协议栈处理
至此,通过啰嗦总结自己强迫症得来的追问细节,了解了一些基本前设铺垫知识,差不多可以继续回去理解原文了
继续说Linux 发送/接手网络包的流程:
当网卡收到数据(硬中断→软中断处理),数据会先被存到内核空间的 Socket 接收缓冲区(属于操作系统内核管理)
你写代码时调用的socket()、recv()等函数,本质是通过系统调用(从用户空间 “请求” 内核空间干活)
Socket 接收缓冲区是 TCP 接收缓冲区在应用层的体现,用于暂存从 TCP 接收缓冲区中拷贝过来的数据供应用程序读取
所以流程是:
进一步深入捋顺:
接收时:
Ring Buffer是内核内存中的缓冲区,内核内存中有ksoftirqd线程会在收到软中断后轮询处理,从Ring Buffer获取数据帧叫sk_buff
sk_buff 是 Linux 内核中的一个结构体,用于管理和控制网络数据包的相关信息,在网络协议栈各层间传递,承载数据包处理所需的元数据,是内核网络子系统处理网络数据的核心数据结构,不直接存储完整数据包数据,而是通过指针指向数据所在缓冲区,实现高效的网络数据处理与传输
发送时:(妈逼的这里弄了整整2天,整个基础篇更新这整整用了3天)
备注:豆包20150427,16:00崩了傻逼问小白实在受不了,仿佛回到了刷题提交不了的日子,但就先记住,这里拷贝副本就行了,实际不是直接拷贝数据,而是通过移动data指针调整协议头的位置,看问小白说又涉及到零拷贝,好像挺重要,后面学小林coding的os和豆包好了重新再深入问吧
在不同层,sk_buff 有不同名称:应用层叫 data,TCP 层叫 segment,IP 层叫 packet,数据链路层叫 frame,最终完成网络包的封装与发送
多说一句:socket发送给缓冲区的生命周期从创建socket连接开始,os就为其分配,关闭socket连接时会被释放。而sk_buff生命周期短暂的,为处理单个网络数据包所创建,数据包处理完毕就被释放

真他妈烦人Chrome总崩溃闪退(妈逼的我被人电脑设置了定时闪退了艹~~~~(>_<)~~~~好崩溃),豆包又崩了,傻逼问小白居然问完问题卡住,刷新后这最后问的问题直接没了,好不容易措辞追问,这下都不知道问到哪了,思路断了。问小白简直太垃圾了
微信搜索聊天记录也有bug,假如搜索3个字,总是按照第一个字搜索。搜素视频号历史搜索文字聊天反应很慢,清理垃圾也是很烦人,没法退出,之前微信可以回复语音表情包语音转文字形式回复新功能都没了
傻逼问小白跟个残疾人一样,豆包分享起码会把最开头的问题分享出来(哪怕上面的问答没加载出来),问小白tmd直接只分享加载出来的,最开始原始的根本不管,你要不回头看一下都不知道这问题,等过阵子再找都找不到,因为问小白没及时问题链接,所有问题都是用户的链接,打开都是主页面,真他妈傻逼
最痛苦的是,豆包大模型属于所有大模型里最好的,百度bing到的csdn和博客园很多东西都说错误或者照搬别人的水博客的,可算用豆包+小林coding都有很多错误,技术错误,不知道是哪个对,还要连环追问豆包,唉,好心累
=========================
以下原文:(很多缩减归入到上面的更新了)
不写了,多读小林网站几遍得了
学会了每个细节,比如头部、报文都不再先钻研,而是一直往下读,有一个整体的宏观框架,脉络
为何有了IP地址还要用MAC,主机地址不能确定吗?
链接搜“终于解释通了”、“解释的太妙了”
深度思考新大陆!明显比直接答有条理太棒了,一次的深度思考回答顶千百次的直接回答
但发现关于vim和古老的线程pthread那些回答的一坨屎
我如果一开始就这么学,早就腾讯offer了吧?甚至SP 我如果考研用心,有豆包早就北邮网研14组许长桥了吧 听说很多啥也不会的985女生大厂offer唉
关于路由器、交换机理解深刻了
链接搜“精妙绝伦”、“太JB透彻了”
小林coding里的,这段太精髓了“互相扒皮 —— 服务器 与 客户端”
进步:学会了舍弃,学会了怎么看书学东西,先不钻研看那些细节,重点就是看完反复回头重新读这些章节
读到这里,发现图里有socket,想到可以把看的TCPIP网络编程书里的代码应用到做一个项目,就说学计算机网络的时候自己看书展开写了个项目,回声服务器,都是底层的
毕竟看了,之前还觉得一切都是浪费时间无尽悔恨
第十章信号处理提及中断注册函数signal、sigaction
此文的“知乎直答找项目问答分享”那个链接搜“HTTP服务器项目快速落地方案(2个月求职导向)”
后来感觉不太合适有点扯淡
好牛逼懂了很多啊
搜“终于进一步理解了底层设备”、“那我接着完善我的理解,你看对不对”
操!一下子串联了,感觉书没白读
早用深度思考好了
-------------------------------------------------------------------------
HTTP篇
===========================
以下更新:(这是学完TCP+IP后,回头更新的)
豆包链接是这篇下面原文里的(链接)
HTTP 是 超文本传输协议
超文本:文字,图,视频,压缩包,超链接(最常见的超文本HTML,本身只是纯文字文件,但内部用标签定义了图片、视频等的链接,再经过浏览器的解释,呈现给我们的就是一个文字、有画面的网页了)
传输:双向
协议:参与者的交流通信规范及相关的各种控制和错误处理方式
综上:HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」
常见状态码



HTTP 常见字段有哪些?
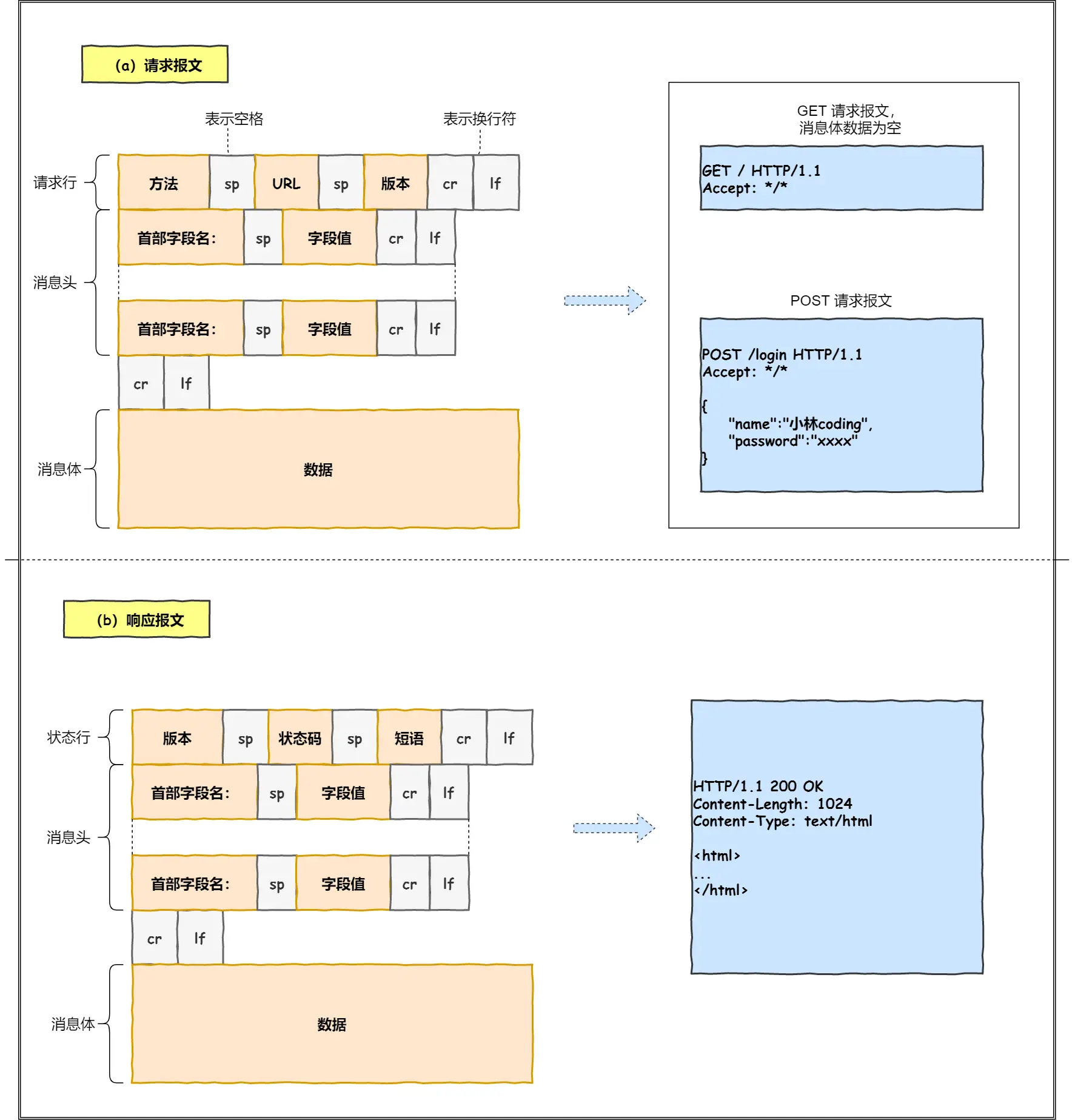
host:指定服务器的域名,例如:Host: www.A.com
Content-Length:本次服务器回应的数据长度字节,例如:Content-Length: 1000
解决粘包:
http协议设置回车符,换行符作为HTTP header边界
Content-Length 作为 HTTP body 边界
关于粘包这里展开说下:
UDP不拆分数据包
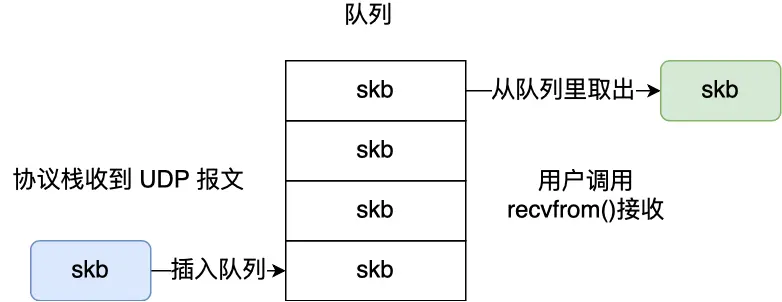
每个收到的UDP都插入队列,每recvfrom()都从里读取,然后从内核里拷贝给用户缓冲区
TCP拆分数据包
当send()后,数据只是从应用程序拷贝到了操作系统内核协议栈中。真正发送的时期取决于发送窗口、拥塞窗口以及当前发送缓冲区的大小等条件。
所以「Hi.」和「I am Xiaolin」 两个TCP报文可能会拆分合并的不成样子不可辨认,当两个消息的某个部分内容被分到同一个 TCP 报文时就叫粘包,不知道边界就不知道咋读这个数据,因此交给应用程序解决
-
-
-
- 固定长度的消息
- 比较少用,当接收方接满规定字节长度就认为是一个完整消息
- 特殊字符作为边界
- HTTP通过设置回车换行符作为报文边界 ,但为了避免跟消息内容重复,就要对字符转义
- 自定义消息结构:
-
-
struct {
u_int32_t message_length;
char message_data[];
}message;
包头+数据,包头里有字段说明紧随其后的数据有多大
Connection:最常用客户端要求服务端使用HTTP长连接机制,例如:Connection:Keep-Alive
HTTP长连接只要任意一端没有明确提出断开连接,则保持 TCP 连接状态
http/1.1默认长连接,老版本即http/1.0默认不支持长连接
所以两个版本通信就指定Connection首部字段值是Keep-Alive
TCP保活机制keepalive底层传输层机制,独立于应用层长连接,仅用于检测连接是否存活,不直接定义长连接的超时时间 ,当连接处于空闲状态,超时时间来保证发送探测包,没反应就判定连接失效关闭连接,通过套接字开启,默认关闭
HTTP的Keep-Alive是应用层协议,减少TCP创建开销,指多次请求复用同一个TCP连接,其 “超时” 由应用层协议(如 HTTP 头中的 Keep-Alive: timeout=xxx)控制,用于决定连接保持的时间,HTTP也可以Connection:close明确关闭TCP连接。HTTP作为应用层控制传输层TCP连接的声明周期
所以keep_alive长连接后,可以HTTP层主动clsoe关闭,也可以TCPkeepalive保活机制关闭
经过豆包确认的个人理解:
Keep-Alive是HTTP应用层的长连接
keepalive是TCP传输层的保活机制
长连接是做主动不断开用的,而保活机制是做断开用的,只要这个长连接Keep-Alive一段时没通信,就保活探测,实现有效关闭
但除此之外还可以HTTP请求头主动发connection:close让TCP关闭并四次挥手
还可以在Keep-Alive长连接的设置里加超时设置timeout-xxx来关闭TCP链接
Content-Type :回应客户端,本次数据是什么格式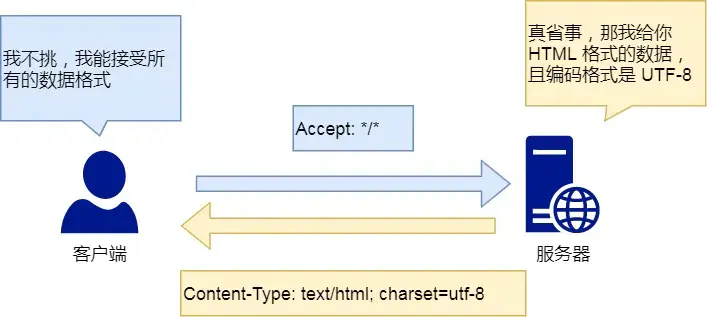
Content-Encoding :压缩方法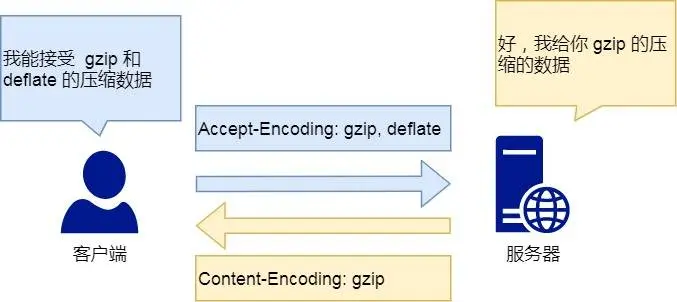
GET和POST:
GET是从服务器获取指定的资源,请求参数写在URL里,作为查询字符串附加在 URL 的路径之后,并非仅指域名部分,URL只能是ASCII,浏览器对URL长度有限制,GET的 “/index.html” 是URL的一部分
POST是请求负荷(报文body)对指定资源做出处理,浏览器不会对body大小做限制
比如留言,点击提交后把东西放入报文body里,拼接POST请求头,通过TCP协议发送给服务端

GET 和 POST 方法都是安全和幂等的吗?
安全和幂等在RFC互联网协议规范里给出的概念:

GET方法是安全且幂等的,因为他是只读操作,可以对GET请求做缓存
POST会修改服务器上的资源,不安全不幂等,浏览器不缓存POST请求
但实际操作开发者不一定按照RFC规范实现,比如
笑话:
GET只读是语义规范的约定,但实际学代码可以不遵守,比如定义一个 GET 请求 http://example.com/deleteBlog?id=123,服务器收到这个请求后,执行删除 ID 为 123 博客的操作),技术上完全可以实现。如果说Google爬虫按正常逻辑访问链接,且能被爬虫发现且没权限限制,那就会像对待普通GET连接一样访问,触发删除操作
POST用body传输,GET用URL传输,地址栏可以看到GET的东西,HTTP传输内容是明文,抓包依旧可以看到POST的body,所以引入HTTPS协议,加密传输
GET也可以带body,POST请求URL也可以带参数
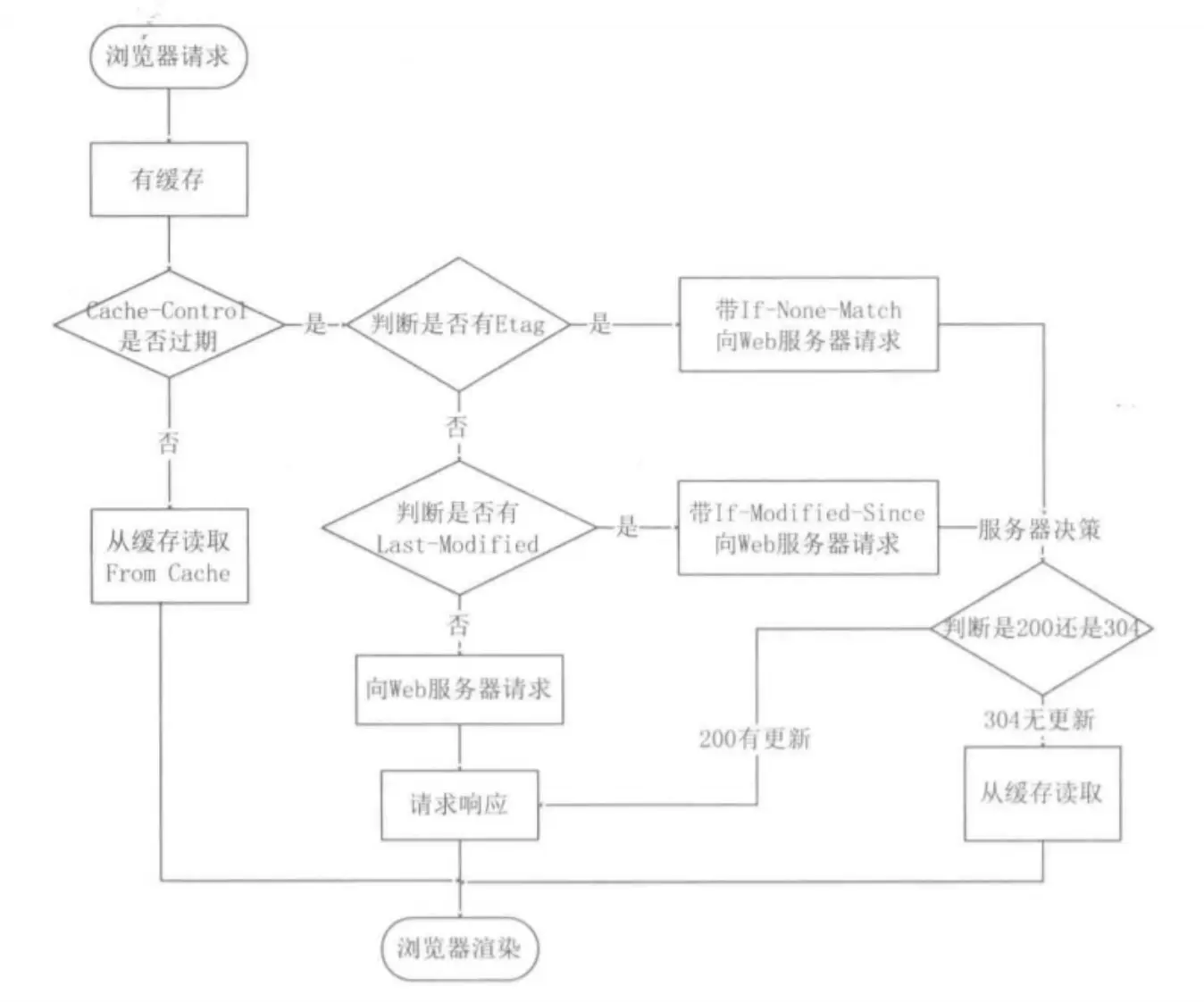
重复HTTP请求就用缓存,不必通过网络获取服务器响应,提升性能,引入强制缓存和协商缓存:
强制缓存:
比如200状态码(from disk cacha)就是浏览器本地缓存,只要浏览器判断缓存没过期就用他
强缓存利用下面两个HTTP响应头部字段实现
Cache-Control, 是一个相对时间;Expires,是一个绝对时间;
同时有的话,就用Cache-Control ,因为cache-control优先级高于 Expires ,设置也精细
比如第一次请求服务器资源时,返回资源同时在Response头加一个Cache-Control,这里设置了过期时间大小,等再次访问,通过比较请求资源时间与Cache-Control设置的过期时间大小,计算是否过期,过期了即再次发送更新Cache-Control
协商缓存:
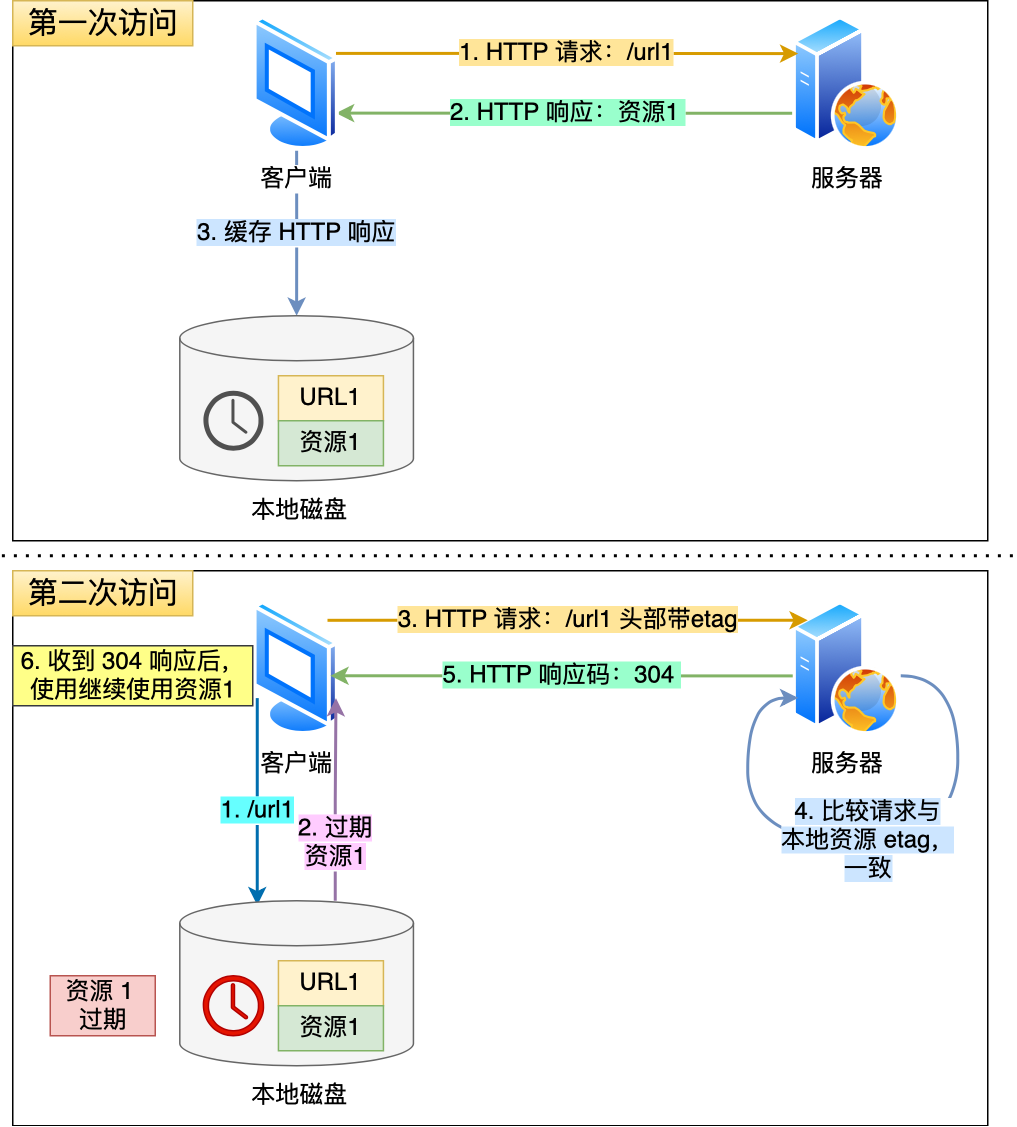
304是服务端的相应码,告诉浏览器可以用本地disk磁盘缓存,即协商了
两种头部实现
一、响应头部的 Last-Modified 和 请求头部的 If-Modified-Since
二、请求头部的If-None-Match 和响应头部的 ETag
ETag:服务器在响应头中给资源一个唯一标识(类似 “指纹”,如ETag: "abc123"通过哈希弄的,比如100M文件可以生成唯一的一段ETag),代表资源内容-
If-None-Match(缓存过期后客户端会拿 “指纹” 问服务器:“还是这个版本吗?”):
客户端下次请求时,会在请求头中带上之前记录的ETag值,即If-None-Match: "abc123",意思是 “如果资源的当前标签 不等于 这个abc123,就给我新内容;如果等于(没变化),就告诉我不用下载”。
服务器处理逻辑:
以上都是过期了再问的,本地有效期到达不一定资源有变化
这两种的优先级:
第一种基于时间,第二种 基于唯一标识,更加精准,因为时间戳精度不够会导致问题
同时有Etag和Last-Modified会优先用Etag,因为
1、如果只修改了所有者或者文件属性,但文件内容没变,此时也会变最后修改时间,导致没必要传输却重新请求传输了
2、有些文件秒级内修改的,If-Modified-Since检测颗粒度是秒级别的,Etag保证1s内刷新多次
3、有些服务器不能精确获取文件最后修改时间
注意:这两种都需要配合强制缓存的Cache-Control字段用,未命中强制,即缓存已经过期失效才会用协商缓存
做笔记的意义在于好回顾,之前没整理,现在重看豆包+HTTP篇跟新东西一样~~~~(>_<)~~~~
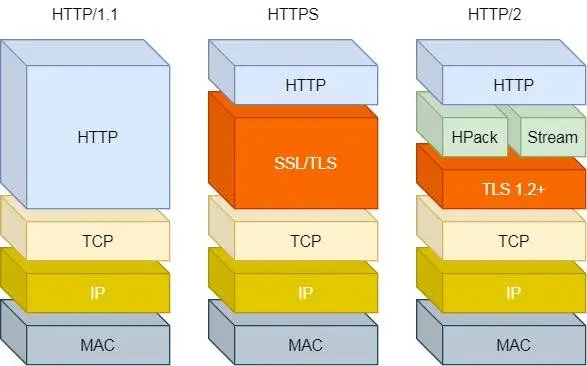
HTTP特性(常见的版本,HTTP/1.1、HTTP/2.0、HTTP/3.0)
HTTP/1.1
优点:
1、简单,HTTP 基本的报文格式就是 header + body,头部信息也是 key-value 简单文本的形式
2、灵活易于扩展,

3、应用广泛跨平台
缺点:
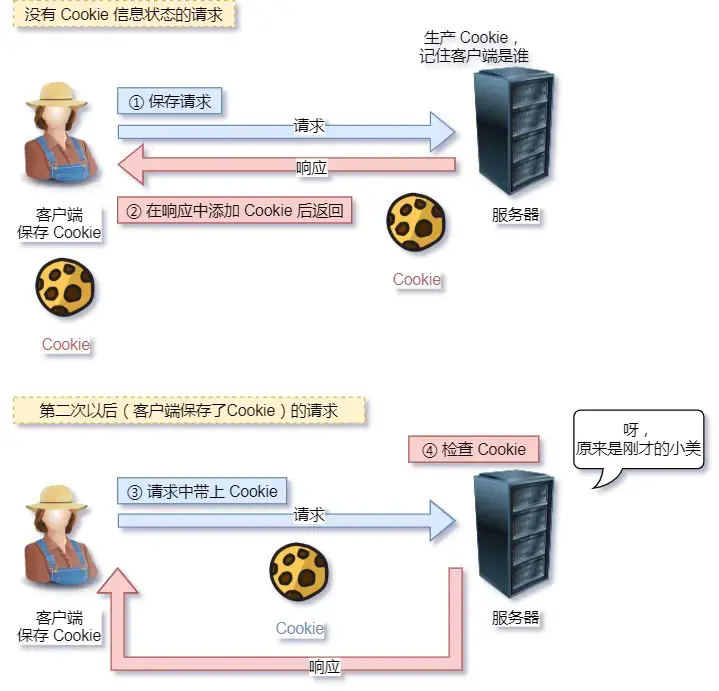
1、无状态

为了解决这个有Cookie技术,通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态
2、明文传输,账号密码信息裸奔无隐私
3、不安全
-
通信使用明文(不加密),内容可能会被窃听,账号信息容易泄漏
-
不验证通信方的身份,因此有可能遭遇伪装,假淘宝
-
无法证明报文的完整性,所以有可能已遭篡改,垃圾广告
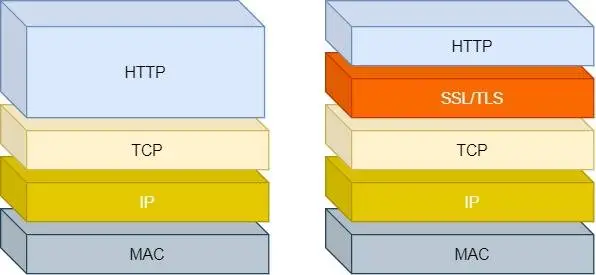
至此关于HTTP安全问题用HTTPS解决,即引入SSL/TLS层
想到TLS最长上升子序列和滑动窗口算法,有功夫再说
HTTP/1.1 的性能如何?
HTTP 协议是基于 TCP/IP,并且使用了「请求 - 应答」的通信模式,所以性能的关键就在这两点里。
1、长连接
用于解决早期HTTP/1.0的缺陷,减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻服务器负载。
只要任意一端没有明确提出断开连接,则保持 TCP 连接状态
如果某个 HTTP 长连接超过一定时间没有任何数据交互,服务端就会主动关闭 TCP 连接,即四次挥手断开这个连接:
注意这里就可以结合自己啃的尹圣雨TCPIP网络编程了,应用层HTTP操作TCP关闭连接,底层都是通过调用socket套接相关函数来实现的

2、管道网络传输
管道网络传输:是数据在网络中,不同设备间的应用层的交互
管道通信:是操作系统进程通信的一种机制,同一台计算机内,本地的不同进程间的数据传输,内存中直接传递,不涉及网络
现在说的是管道网络传输(pipeline),即管道机制,允许浏览器一股脑发送多个请求(但必须按照请求顺序发送回应),不用像以前一样,发A等服务器回应,等到再发B
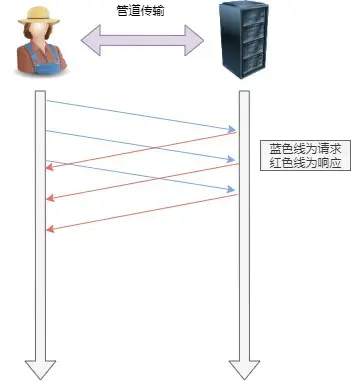
如果服务端在处理 A 请求时耗时比较长,那么后续的请求的处理都会被阻塞住,这称为「队头堵塞」
所以,HTTP/1.1 管道解决了HTTP/1.0请求的队头阻塞,但是没有解决响应的队头阻塞。
注意:管道化技术不是默认开启,而且浏览器基本都没有支持。所以讨论HTTP/1.1默认没管道化。
不用的理由:因为并行处理请求时,服务器需缓存结果,增加服务器负担,且有响应队头阻塞。所以用HTTP/1.1干脆不开管道,所以应用HTTP/1.1的场景性能一般般
开了会响应对头阻塞,且会增加服务器缓存负担
不开会有请求对头阻塞
历史迭代实践(可靠性、安全性、复杂性)发现不开了好,管道化不是加密传输,存在中间人攻击风险,那么就衍生出3、
3、队头阻塞
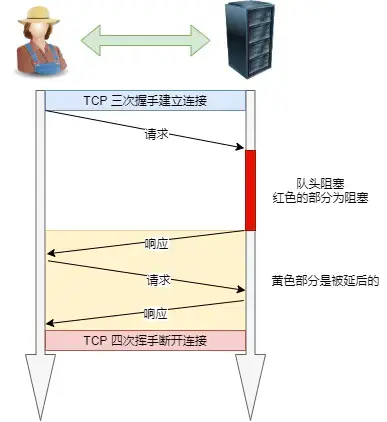
可以理解为在这一点又回到了HTTP/1.0
HTTPS:
-
HTTP是明文传输,安全风险,HTTPS解决这个事, TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,加密传输
-
HTTPS在TCP三次握手后还有SSL/TLS握手才能加密
- HTTP默认80,HTTPS默认443
-
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的
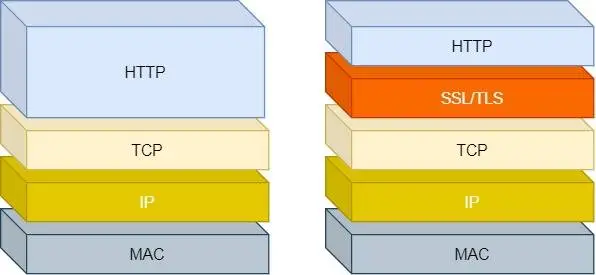
| HTTP | HTTPS | |
| 窃听 | 通信链路上可以获取通信内容 | 混合加密实现信息机密性,防止窃听 |
| 篡改 | 垃圾广告 | 摘要算法校验机制,保证完整性,独一无二的指纹,无法篡改内容 |
| 冒充 | 冒充交易网站 | 将服务器公钥放在数字证书中,保证是真的交易网站 |
具体实现:
1、混合加密(很多傻逼将东西,欠缺太多东西了。还有乱用对我来说百害而无一利的比喻,因为对我思维缜密度极强,发散思维极强,思想深度极强,考虑的过多的人来说,很多比喻漏洞百出)
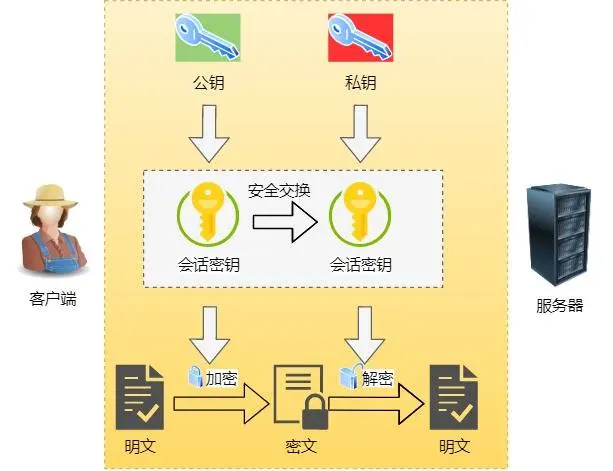 先用非对称加密(非对称加密是用公钥加密,私钥解密)交换会话密钥,
先用非对称加密(非对称加密是用公钥加密,私钥解密)交换会话密钥,
后续通信就一直用对称加密,因为非对称加密计算耗费性能
但注意这里有个问题,我始终搞不懂下面的摘要算法+数字签名为何引出,我始终搞不懂都有混合加密了为何还要数字签名,小林coding说是保证传输的内容不被篡改,但搞不懂咋会篡改,很多地方豆包也是,解释的根本无法串联起来,那个爸爸给老师请假的例子更是扯淡,因为对来说,知识理论是很严谨的,你说小明偷了爸爸和老师的公私钥,可是我却会展开想很多,实际网络中咋可能有偷这个概念,就算能偷,那具体是咋偷的起码要对技术有一个简单的说明吧,所以不再陷入强迫症纠结那个傻逼垃圾比喻的泥沼强迫弄懂那个比喻并想着像刷算法题一样给人纠错了。
像刷刷算法题一样,很多博客都是倒着写的,这里也是很多比喻都是懂了再比喻出来,但很狭隘,不懂的人逆向通过这个比喻却没法弄懂
还有小林coding说爸爸给老师请假,把老师的私钥偷了,这纯纯傻逼吗不是,实际应用到专业网络知识里,私钥还能丢还通信个JB
追问豆包得知:
本质是完整性和身份验证会有问题,正常是我用服务端发来的公钥,加密一个密码“qwe123”发送给服务端,那头解密得到“qwe123”,然后后续就用qwe123加密通信
可是如果中间攻击者劫持了服务端发的公钥,替换成自己的公钥发给客户端,那客户端加密的“qwe123”发给服务端的时候就会被攻击者劫持,攻击者会用自己的私钥解密得到“qwe123”,再发给服务端,服务端不知情,以为是正常通信,且后续通信比如发送“转账100”,用“qwe123”加密,被攻击者劫持成“转账10000”
综上,公钥被窃取是致命问题,他没法保证是真正发送人发的,没法保证数据是正确(完整)的
2、摘要算法+数字签名
摘要算法就是哈希算法,即当作信息的指纹,这玩意就是把信息弄成很长的一串字符串,字符串是唯一的、无法推导出内容
- 同数据哈希稳定不变,微小改动值完全不同
- 哈希具体是对数据预处理去除空格啥 ,然后进行数据分隔迭代位运算、异或运算啥的
- 鸽巢原理,多个不同输入对应同一个哈希。反推需要遍历2256种可能,远超计算能力
把内容+内容的哈希值发给对方
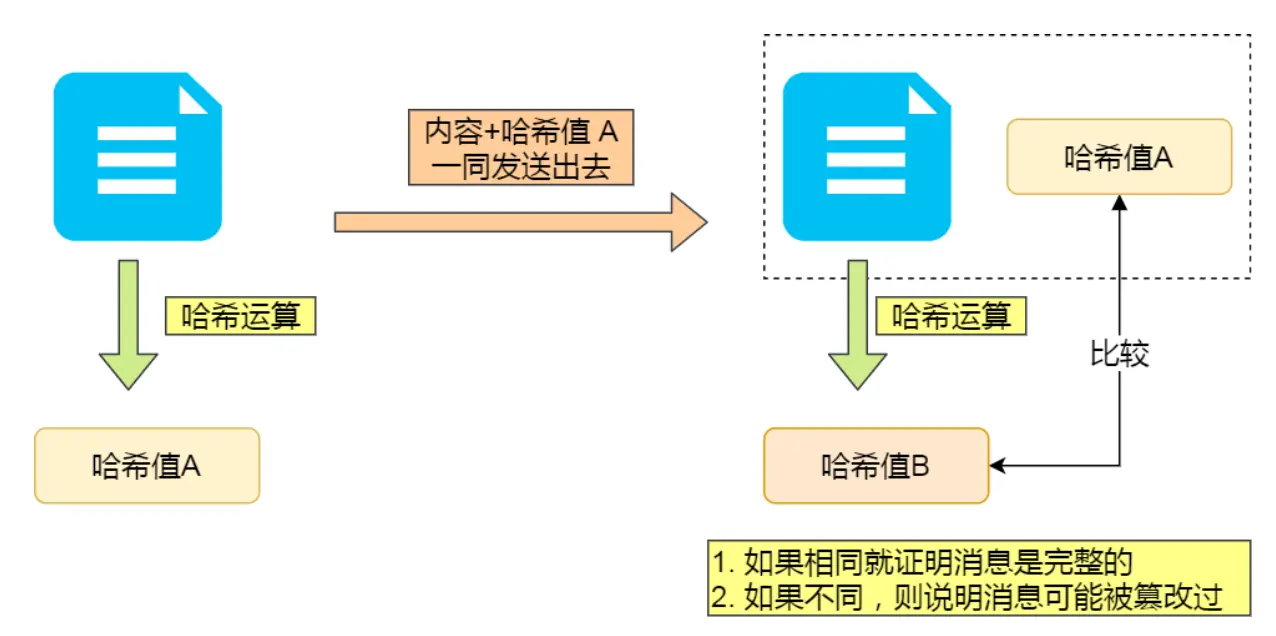
但有可能内容+哈希值会被中间人替换,因为这里缺少对客户端收到的消息是否来源于服务端的证明,为此,用非对称加密算法解决(公私钥双向加解密)
-
公钥给所有人
-
私钥本人管理不可泄露
公钥加密,私钥解密:保证内容传输安全,公钥加密的内容,其他人是无法解密的,只有持有私钥的人,才能解密出实际的内容
私钥加密,公钥解密:保证消息不会被冒充,私钥是不可泄露的,如果公钥能正常解密出私钥加密的内容,就能证明这个消息是来源于持有私钥身份的人发送的(注意私钥加密的是内容的哈希值,数字签名算法就是如此)
私钥由服务端保管,然后服务端会向客户端颁发对应的公钥。客户端收到的信息,能被公钥解密,就说明该消息是由服务器发送的。
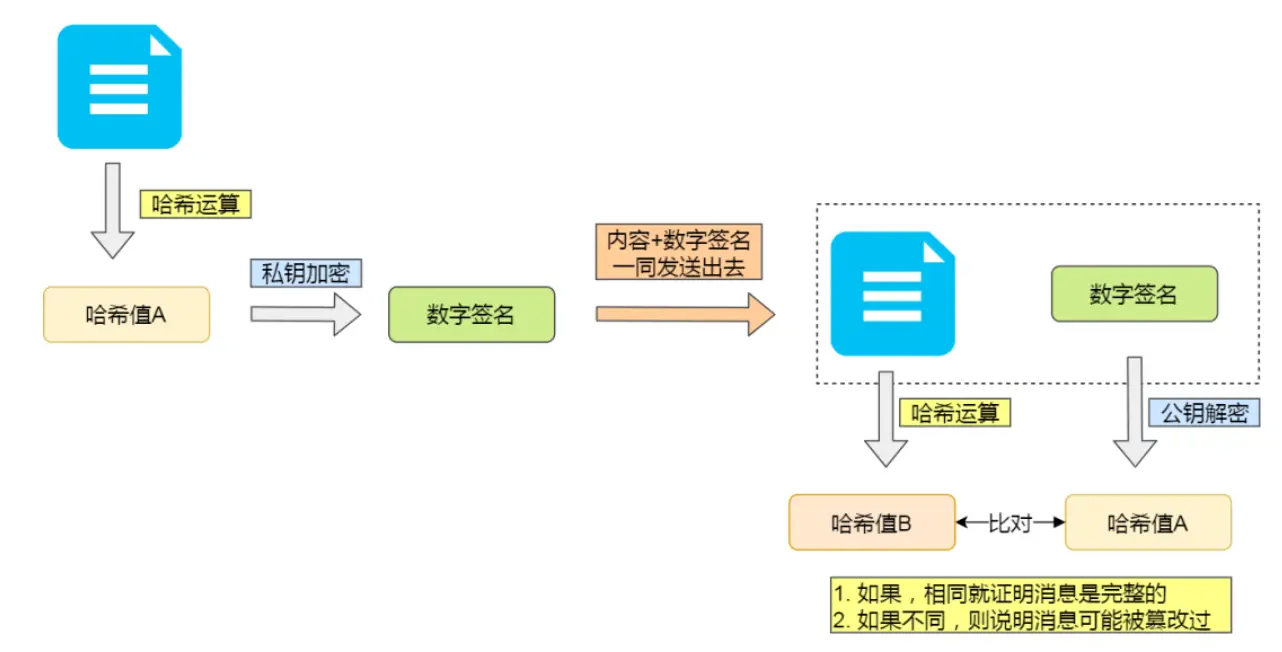
至此,哈希保证完整性,数字签名保证消息来源可靠(即持有私钥一方发的)
那公私钥被伪造咋办,伪造的一定会解密出来,但双方用的钥匙早都不是正确的了,这就需要身份验证,引入数字证书
即公私钥加解密之前做了个权威审查,你不说会替换吗,也就是说在我客户端这头用公钥解密的时候,公钥可能被换了,这里公钥是之前持有私钥的服务器给的,那现在就看看咋保证这个公钥发送的时候不被替换
这个傻逼偷老师和爸爸钥匙例子完全是幼儿园小孩学东西用的,就是那种给父母女朋友讲的方法,咱们用专业知识模拟实际场景来深刻理解,
假如:
黑客介入:
-
黑客 Eve 自己生成 私钥 EvePri 和公钥 EvePub,冒充 Alice 把 EvePub 发给 Bob(Bob 以为这是 AlicePub)。
-
Eve 用 自己的私钥 EvePri 对信息签名(此时签名与 EvePub 匹配)。
-
Bob 用 假公钥 EvePub(以为是 AlicePub)验证,由于 EvePri 和 EvePub 是匹配的,验证 必然通过,但 Bob 误以为这是 Alice 的签名(实际是 Eve 的)
这就是假签名通过的例子,即保证了来源和是否篡改,但来源不可靠,本质是验证工具(公钥)就是错的,
总结:
混合加密是公钥被窃取导致信息没法确定来源,没法保证信息完整性。
而用了数字签名,解决了可以判断来源,解决了可以确定信息是否完整,但依旧是公钥可能被改。所以用数字证书来确保公钥也没事
3、数字证书
也就是持有私钥的服务器,先告知客户端公钥的过程,之前都是上来就默认手里公钥是没问题的,直接传信息
注:该图的步骤②,后面有具体流程展开,详见“客户端校验数字证书流程”
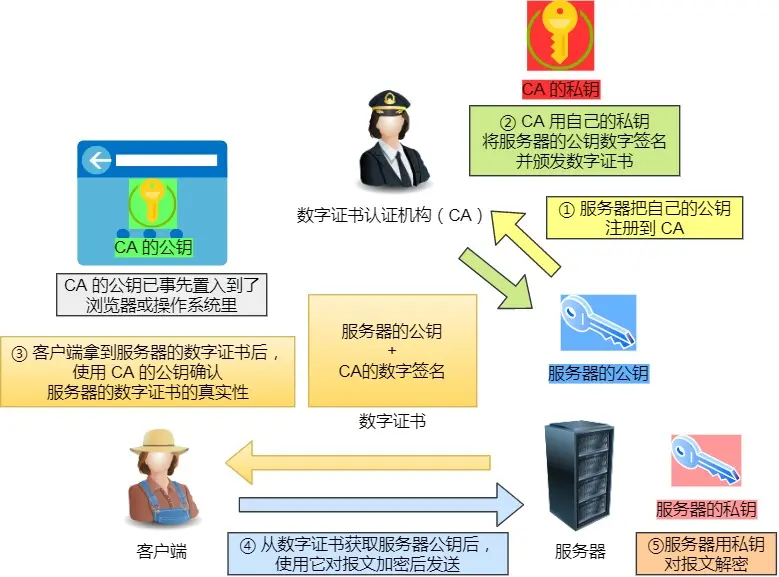
CA是数字证书认证机构,很权威,没必要研究这个,只知道他内置在操作系统或者浏览器里了,那他们这个机构有公钥私钥,这个就是一个切入点
服务器想发公钥的时候,就把公钥注册到CA,CA会用自己私钥把服务器的公钥先做哈希再用私钥加密,至此有了数字签名,之前是要发送的信息,比如“你好”,给“你好”做哈希,然后私钥加密得到你好的数字签名,这里是用靠谱的CA的私钥,给要发送的公钥做数字签名,接收方同样用内置到操作系统里的CA公钥解密,没问题说明里面的公钥没问题。这就解决了公钥被冒充
总结:
数字证书是用数字签名的原理来保证公钥没事,没事指的是知道是否被篡改了,那有了数字证书就可以确定公钥没问题
然后公钥正常给到对方后,开始非对称加密一个会话密钥,对方用公钥加密一个会话密钥,自己用私钥解密,
此后用会话密钥对称加密
至此说几个自己追问豆包的思考:
哈希保证完整性其实就是正确性,因为变动一点哈希就会变,所以叫完整性,但说人话其实就是正确性,检测信息是否被篡改
数字证书则用于认证服务器公钥的真实性,防止混合加密中被中间人攻击,确保机密性的前提是 “用对了公钥”
再捋顺一下一些专业术语:
关于机密性,一开始认为,混合加密都机密性了为啥还会篡改,既然会篡改为啥叫机密性,其实机密性就是加密的意思,本质是及时篡改了称之为假数据,也会把假数据当作真数据进行加密,密文传输,所以是机密性也可以说防止窃听,但可能已经被窃听了,但依旧对错误内容进行加密,所以叫防止窃听,所以需要摘要+签名验证是否被改动,而验证是否被改动的东西基于公私钥,所以再用数字证书来确保用来做验证的工具公钥是没事的没被冒充的
私钥加密这个无法保证是否被劫持,只是验证是否是原对象发,且如果公钥被偷了,验证也是错的
所以上述费半天劲数字证书只是为了解决安全传递的公钥问题
数字签名本身无法保证公钥的合法性,因为它没有解决 “公钥从哪里来” 的信任问题,他是建立在假设公钥正确的基础上,可以确保信息是否是本人发的
再说几个逻辑:
私钥加密,公钥解密防止冒充:只有私钥持有者能用其加密内容,公钥解密成功则证明内容来自合法私钥持有者。如果调过来公钥加密私钥解密的话,公开的公钥任何人都可以用,没法判断谁发的,如果公钥加密,私钥解密,被劫持无数次都可以用公钥伪造一个看似正确的,但不是原对象发的信息
公钥加密,私钥解密:保证内容传输安全,如果调过来谁都能解密了
最后梳理:
① 客户端生成对称密钥 K(临时密钥,仅本次通信使用)。
② 客户端用 服务器的公钥(已通过证书验证为真)加密 K,得到密文 E(K)。
③ 客户端发送 E(K) 给服务器。
④ 服务器用自己的 私钥 解密 E(K),得到原始对称密钥 K
⑤后续双方直接用 K 加密通信数据(对称加密),不再需要公钥 / 私钥。
又想了下,对称加密不会被窃取吗?
没私钥无法解密,长度够安全无法硬破解
无法伪造公钥做掉包,有CA担保,假的直接拒绝
又想了下,既然CA这么权威,直接跟CA发送加密密钥不就得了
CA 的核心角色是 “认证公钥归属”,证明某个公钥是否属于某个服务器,而非 “转发密钥”
如果每次通信都要经过 CA 转发密钥,CA 会成为全球通信的 性能瓶颈(想象全球所有 HTTPS 连接都先把密钥发给 CA,再由 CA 发给服务器,这显然不可行)
CA 若存储所有通信的对称密钥,会成为黑客的 “终极目标”(一旦 CA 私钥泄露或数据库被攻击,所有依赖该 CA 的通信都会被破解)
至此OVER
HTTPS 是如何建立连接的?其间交互了什么

TlS握手涉及4次通信,使用不同的密钥交换算法握手流程不同,常用密钥交换算法
RSA算法、ECDHE算法
说下RSA的,比较好理解

TLS 协议建立的详细流程:

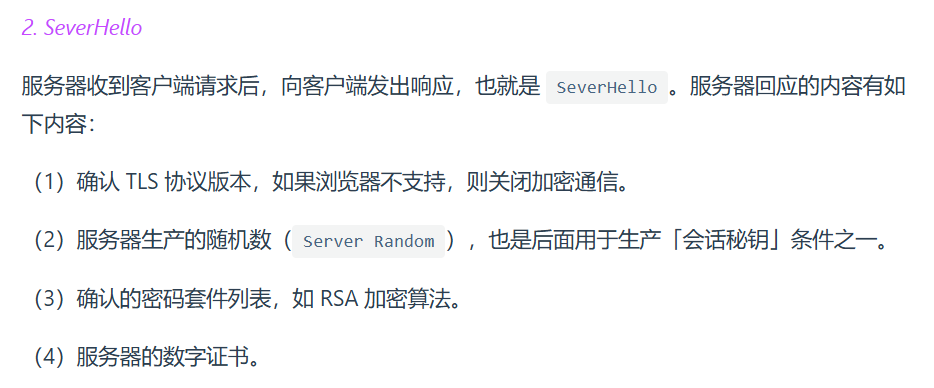
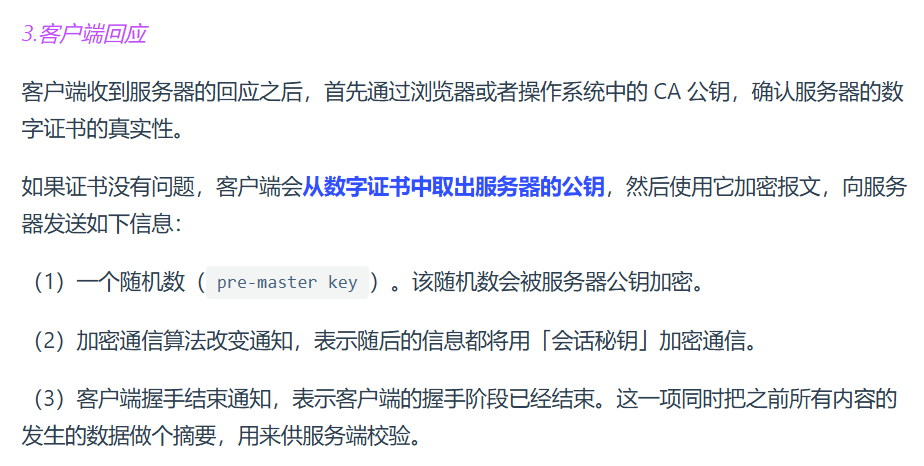


但RSA算法有前向安全问题:如果服务端的私钥泄漏了,过去被第三方截获的所有 TLS 通讯密文都会被破解
为此有了ECDHE密钥协商算法,目前主流
再说下客户端校验数字证书流程:
其实就是上面数字证书CA那个图里的②
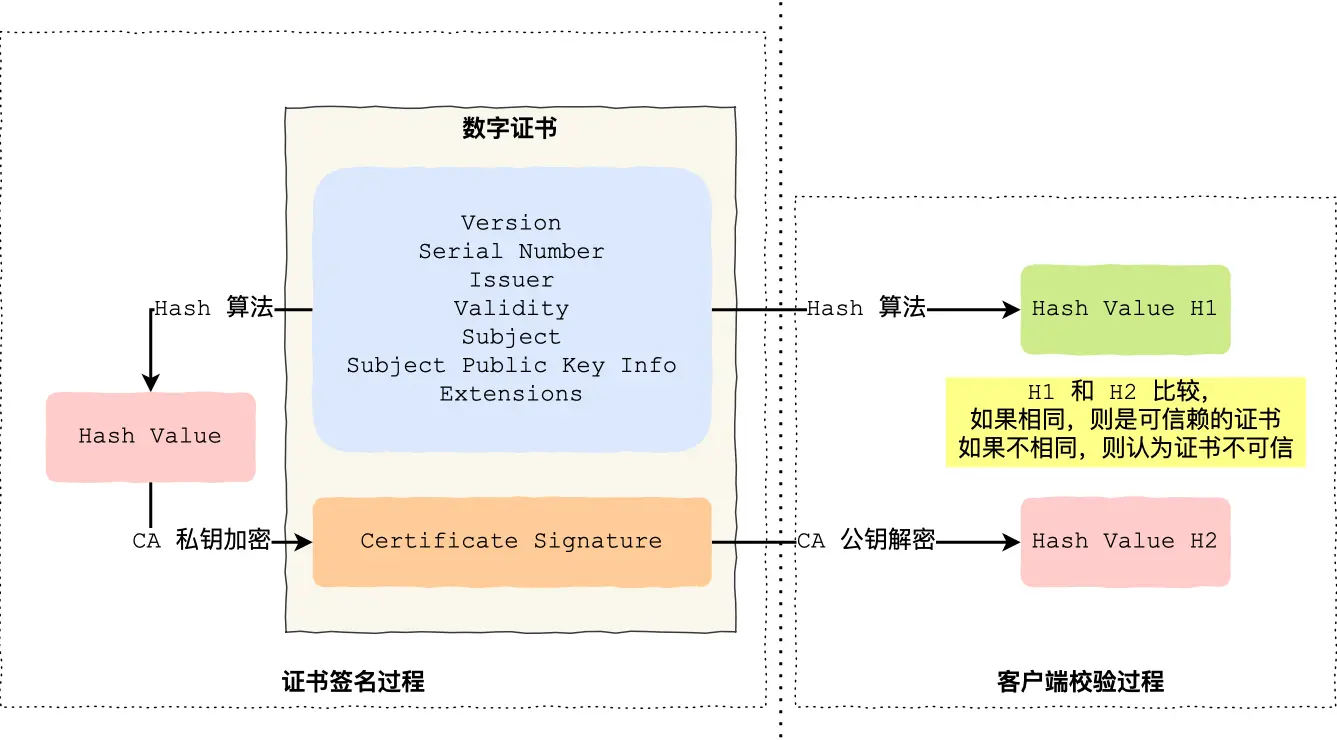
服务端:
CA会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,哈希计算出哈希值,用CA自己(保存在极其私密的地方,理解为私钥绝对机密不会篡改泄漏,但随着学习深入其实CA私钥也有风险,只是作为初学者现在讨论CA公私钥泄漏篡改风险的这个话题,百害无一利南辕北辙舍本逐末)的私钥,做加密,生成 Certificate Signature,这就叫 CA对文件证书做签名 操作,文件证书就是持有者的公钥、用途、颁发者、有效时间等信息
至此,Certificate Signature 和 文件证书一起形成了数字证书
客户端:
对证书做哈希计算,得到哈希值比如叫做A1,通过浏览器和操作系统中集成了 CA 的公钥信息,用公钥解密 Certificate Signature ,记作A2,如果A1 和 A2 一样,则认为收到的持有者的公钥、用途、颁发者、有效时间等信息是可信赖的文件证书 (记住这里 的A1和A2代表的内容,后面会用到)
理由:因为基于CA的私钥和公钥绝对保密万无一失,那么一旦数字证书被篡改,客户端用CA公钥解密的时候,由于没指定CA的私钥加密,公钥只能解出来不匹配的A1和A2,或者说想解出来相等,必须用篡改人他的公钥去解
至此是单一的情况,即服务端注册操作,即CA的私钥加密服务端的文件证书,然后客户端的os里的CA公钥解密操作,都是基于CA的
但实际为了确保根证书的绝对安全性,将根证书隔离地越严格越好,不然根证书失守整个信任链就都有问题,所以引出层级证书,即证书信任链
注意:证书颁发用户无感知自动的
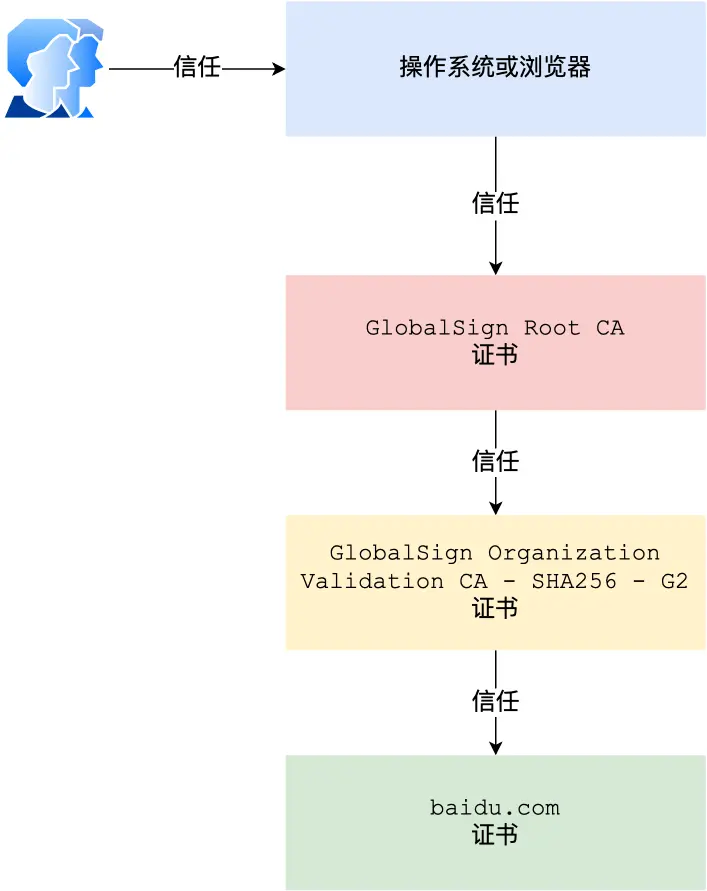
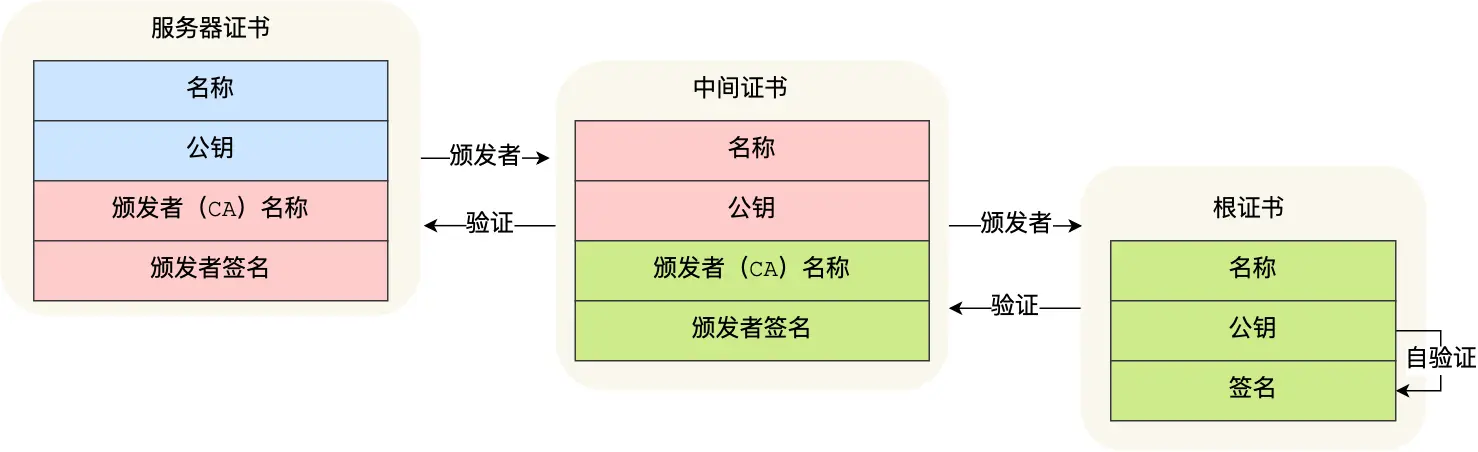
简单说就是,无论是服务器,还是这些证书,他们都可以抽象提取添加,形成自己的那头发的持有者公钥、用途、有效期等信息,即文件证书,那么这些就是一个检测抓手,检测根据
那么前面说过,A1和A2,
当收到baidu.com或者服务端的证数字书后,发现证书的签发者不是根证书CA,就无法用本地的A公钥去验证,就会向CA请求中间证书,
回顾整体:
至此说完了整个加密公钥私钥
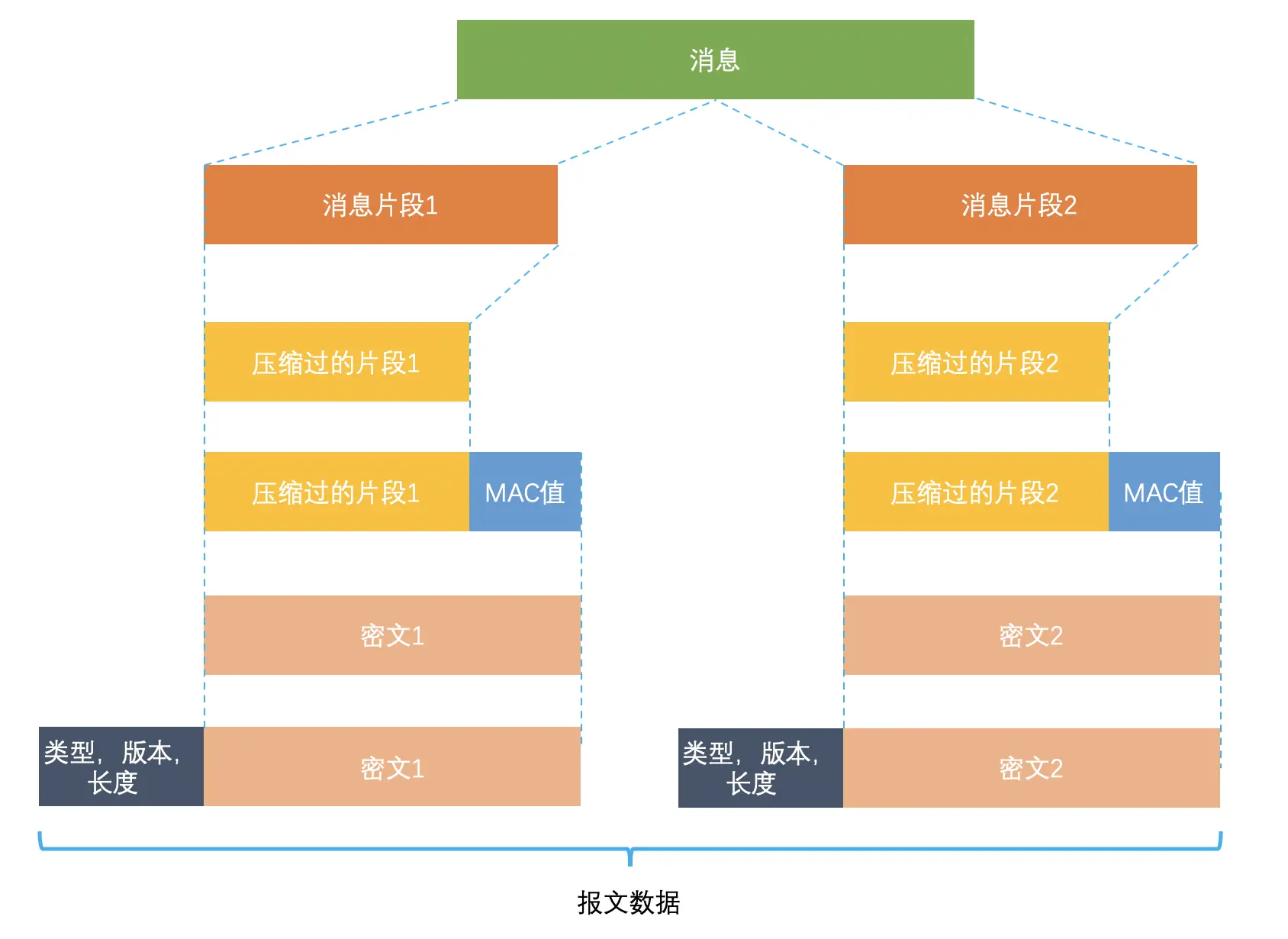
HTTPS 的应用数据是如何保证完整性的?
HTTPS 的本质:是 HTTP 协议 + TLS/SSL 安全层 的组合,即 HTTP over TLS
TLS 包含多个子协议,其中 记录协议是最底层的 “数据处理引擎”,负责对上层数据 HTTP 数据进行加密、校验、旧版本的压缩等安全封装

HTTPS 一定安全可靠吗?
绝对安全没任何漏洞,但有中间人攻击的事,本质是利用客户端漏洞(点击继续访问接受中间人服务器证书,或者被恶意导入伪造的根证书,使得中间人偷看浏览器和服务端HTTPS请求和相应的数据)
具体就是
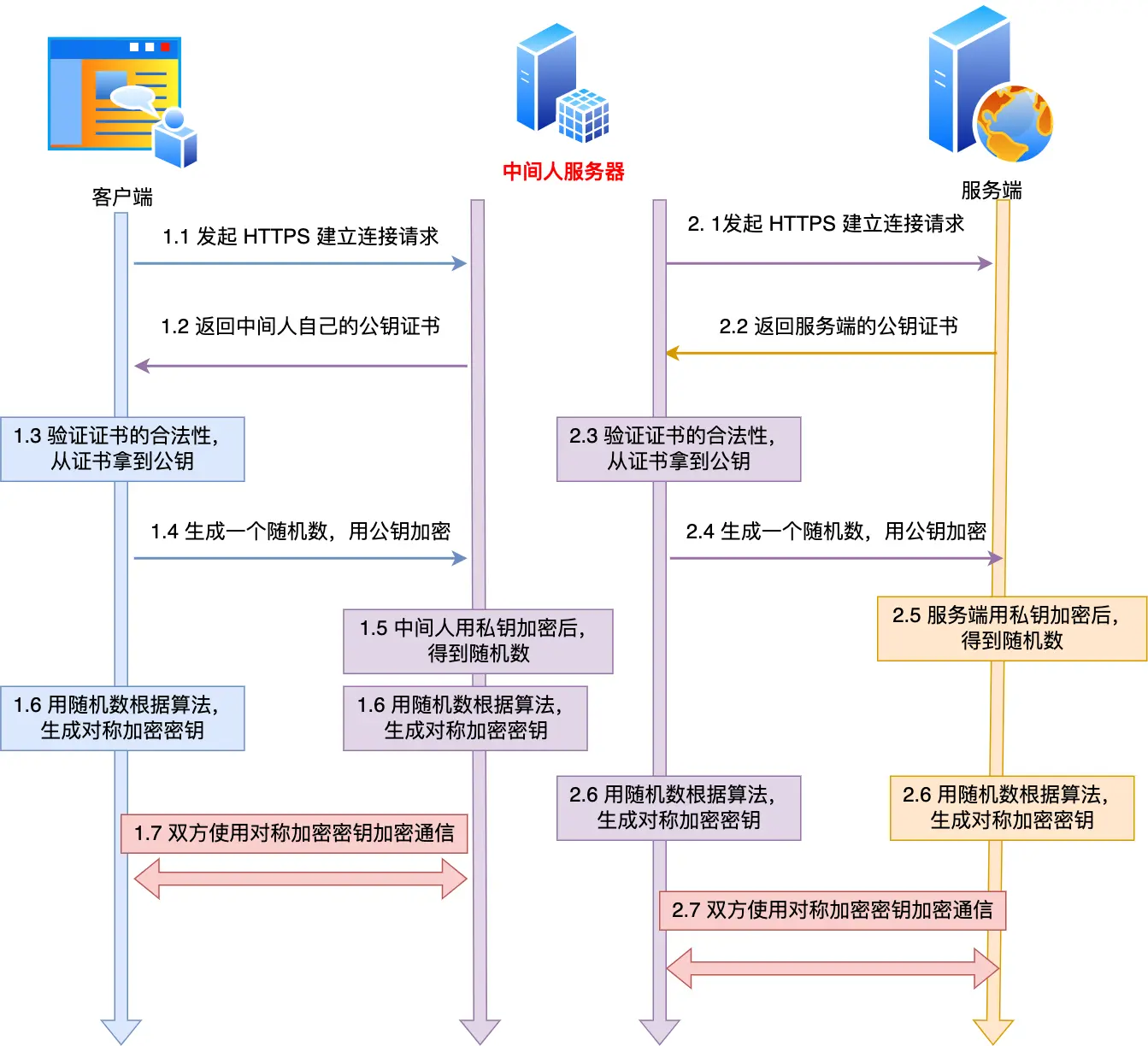
-
客户端向服务端发起HTTPS建立连接请求,被「假基站」转发到「中间人服务器」,中间人向服务端发起 HTTPS 建立连接请求,客户端与中间人进行 TLS 握手,中间人与服务端进行 TLS 握手;
-
客户端与中间人进行 TLS 握手过程中,中间人发自己的公钥证书给客户端,客户端验证证书的真伪,然后从证书拿到公钥,生成一个随机数,用公钥加密随机数发送给中间人,中间人使用私钥解密,得到随机数,此时双方都有随机数,然后通过算法生成对称加密密钥(A),后续客户端与中间人通信就用这个对称加密密钥来加密数据了
-
中间人与服务端进行 TLS 握手过程中,服务端会发送从 CA 机构签发的公钥证书给中间人,从证书拿到公钥,并生成一个随机数,用公钥加密随机数发送给服务端,服务端使用私钥解密,得到随机数,此时双方都有随机数,然后通过算法生成对称加密密钥(B),后续中间人与服务端通信就用这个对称加密密钥来加密数据了
-
后续通信,中间人用对称加密密钥A解密客户端的HTTPS请求的数据,然后用对称加密密钥(B)加密 HTTPS 请求后,转发给服务端,接着服务端发送 HTTPS 响应数据给中间人,中间人用对称加密密钥(B)解密 HTTPS 响应数据,然后再用对称加密密钥(A)加密后,转发给客户端
抓包工具截取HTTPS数据底层逻辑也是中间人角色

(错别字勘误)都是第三种方式取得中间人身份,抓包时候客户端安装Fiddler的根证书,客户端往系统受信任的根证书列表中导入抓包工具生成的证书,也就是抓包工具给自己创建了一个认证中心 CA,客户端拿着这个CA公钥,去验证由自建 CA 签发的抓包工具。相当于自己是裁判来判断自己
如何避?
要么自己别点,要么HTTPS双向认证,即多一个服务端验证客户端身份
正常TLS四次握手:
-
客户端发送:通信加密请求、Client Random(不加密)、自身支持的加密算法
-
服务端回:数字证书、Server Random(不加密)、确认加密算法
-
客户端取数字证书的公钥,加密发pre-master key、通知下次用会话密钥通信
-
服务器拿到pre-master key,至此双方都通过Client Random、Server Random、pre-master key根据协商算法生成了通信的会话密钥、确认下次用会话密钥通信
HTTPS的双向认证:

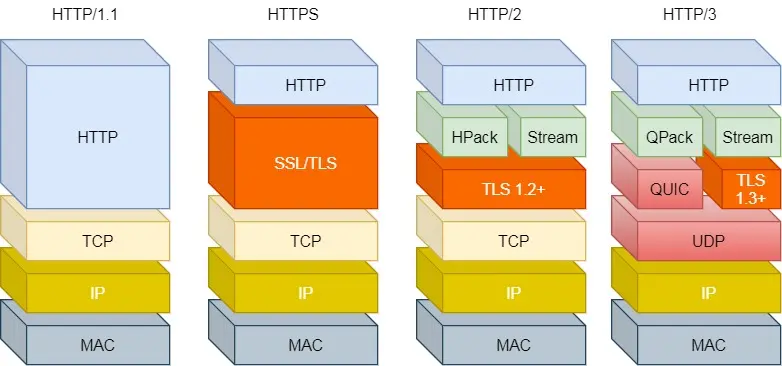
HTTP/1.1、HTTP/2、HTTP/3 的演变过程:
HTTP/1.1 相比 HTTP/1.0 提高了什么性能
场景:
HTTP/1.0串行请求(请求 + 响应必须一对一)
你问阿姨“有包子吗?”→阿姨找包子(等待)→给你包子→你再问“有粥吗?”
TCP 连接频繁建立断开,效率低,且每个请求都要等上一个响应。
连续发送多个请求,不用等前一个响应回来
你一次性问阿姨“有包子吗?有粥吗?有鸡蛋吗?”

HTTP/2
基于HTTPS,所以安全性也有保证
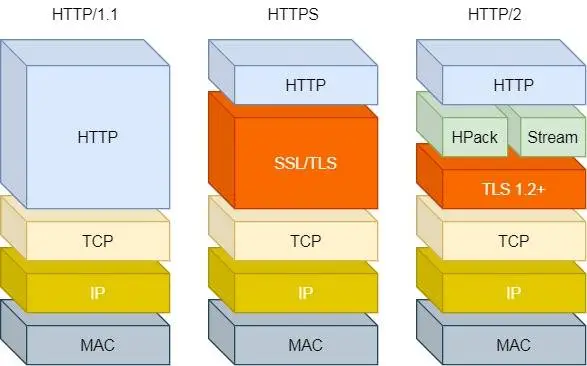
HTTP/2性能上的改进总共4点:
1/4:头部压缩
同时发送多个请求,头一样就消除重复,即HPACK算法,在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成索引号,只发索引号,提高速度
2/4:二进制格式
不像HTTP/1.1里纯文本报文,采用二进制,即头信息帧和数据帧,对计算机友好
HTTP/1.x 的文本格式像“一篇用自然语言写的文章”,计算机解析时需要 “理解语法规则”,效率低;
HTTP/2 的二进制分帧像 “一张用固定格式填写的表格”,计算机可以直接 “按列读取数据”,解析又快又省资源,这就是效率提升的核心原因,比如读取前几个字节就能知道这是HEADERS帧还是DATA帧,流 ID 是哪个请求 / 响应的,无需复杂的字符串处理
3/4:并发传输
HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,没法做其他事。响应迟迟不来,那么后续的请求是无法发送的,基于此引入Stream概念,多个Stream复用在一条TCP连接
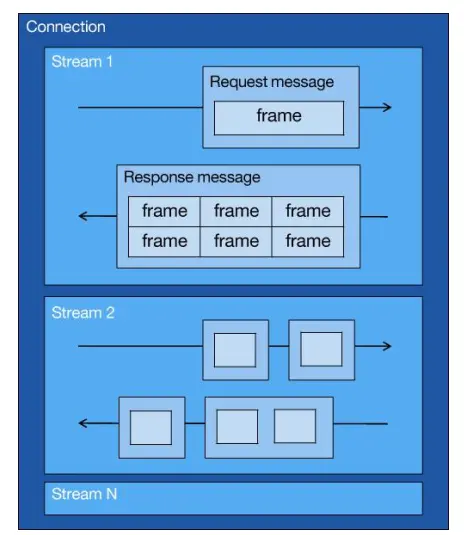
如上图,箭头是HTTP数据传输方向,1个TCP(connection)包含多个Stream,一个Stream里有一个或多个Message即HTTP/1说的那个请求响应,Stream里装的是请求响应组合,由 HTTP 头部和包体构成,把他们分成1个或多个二进制压缩格式的Frame,Frame 是 HTTP/2 最小单位
不同HTTP请求用独一无二的Stream ID区分,接收端通过Stream ID有序组装成HTTP消息,因此可以交错(乱序)发送
客户端发起的Stream ID奇数
服务端发起的Stream ID偶数
比如这里服务端箭头表示向客户端发起的流(如 stream 1)传输响应数据
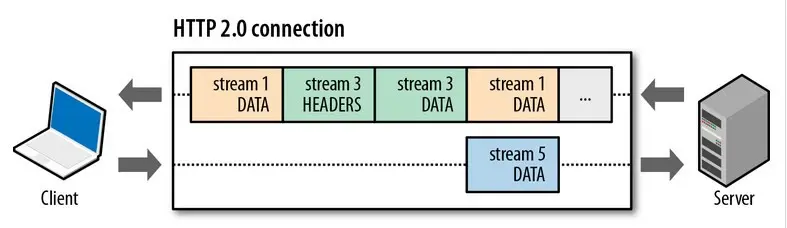
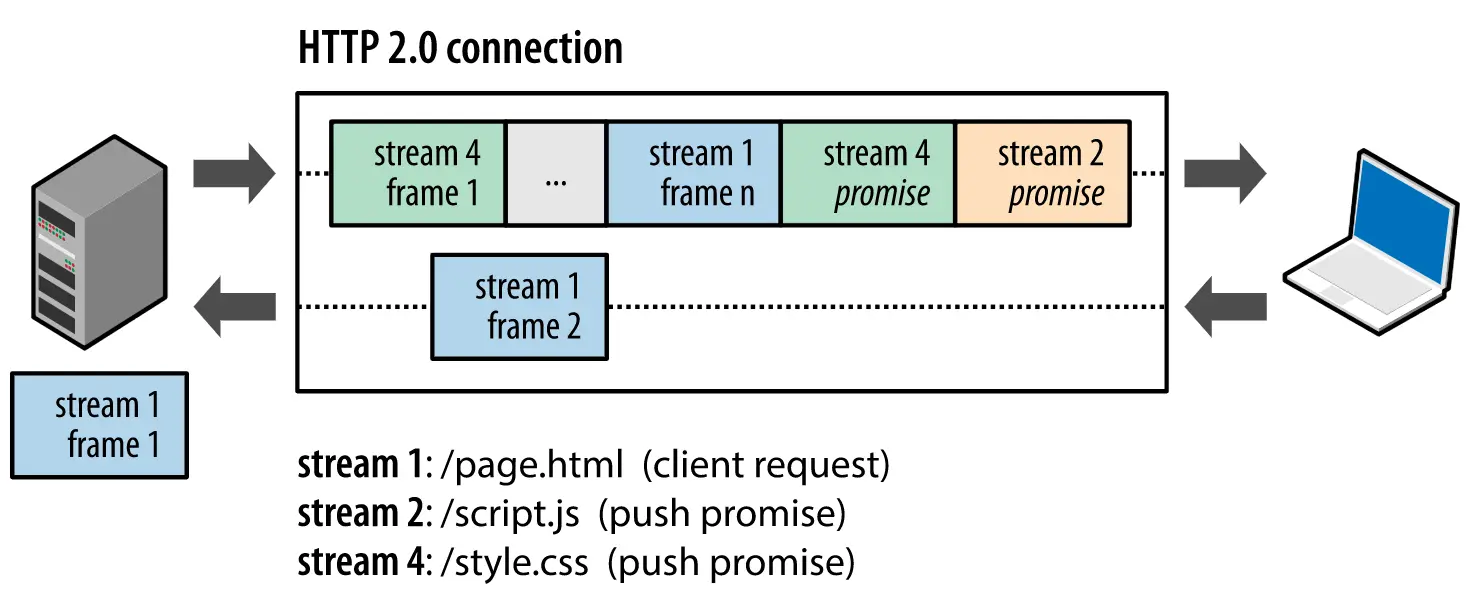
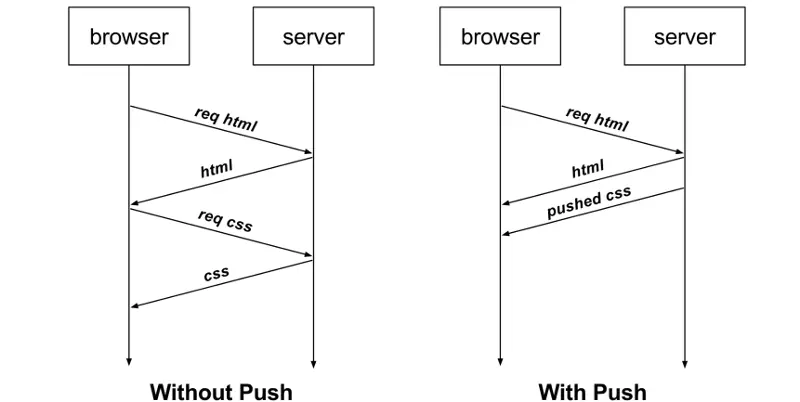
4/4:服务器主动推送资源
不再被动响应,主动发消息,
继续往下解释前,说点自己愤怒下无尽追问,靠着强大追问能力从豆包那学到的知识,因为目前所有东西没串起来,对我来说很重要,此文搜“分层和动态”,再结合下面这个图和下面的文字理解
要知道我们说烂了的TCP属于应用层下,网络层上,但为啥总是起手就叫你建连接呢?这全网没人说,其实发数据本质是先动态再静态
动态指的是先TCP三次握手建立连接,后续用这个连接作为通道进行通信,理解为两点之间修公路
对你没看错,起手先传输层TCP上来干活,然后有TLS安全加密4次握手建立连接,理解为给公路建立护栏 然后通过静态协议栈,
至此动态搞好了,比如想发“你好”,开始走静态,即我们熟知的分层协议栈,
数据从应用层(HTTP)开始打包“你好”,
经传输层(TCP)加端口号头部啥的再次打包“你好”
网络层(IP 选路,如 GPS 规划路线)加网络头部打包“你好”
然后数据链路层(MAC 帧封装,类似给包裹贴标签)到物理层(线缆等传输,如货车运输),接收端反向处理
那现在回头来看3/4:并发传输那个图,里面的Connection我以为是TCP连接,但豆包说是HTTP/2的连接,我懵了,应用层跟传输层究竟咋联系起来的啊,其实
所以,至此我用人话解释完,也才刚能理解全网都在说的这句狗逼官网不接地气的话语:
这里的“Connection” 通常指的是 HTTP/2 连接 ,它基于 TCP 连接构建,但并非单纯指 TCP 连接。HTTP/2 连接复用了底层的 TCP 连接,在这个连接上可以创建多个 Stream 来并行处理不同的请求和响应
现在再来看是怎么主动推送的,图里箭头全网有很多没脑子的傻逼都管这个叫HTTP连接,他逻辑上是HTTP连接,本质是TCP连接,箭头方向表示HTTP传输数据的流向


HTTP/2缺陷:
Stream并发解决了HTTP/1的队头阻塞,但HTTP/2还存在队头阻塞问题
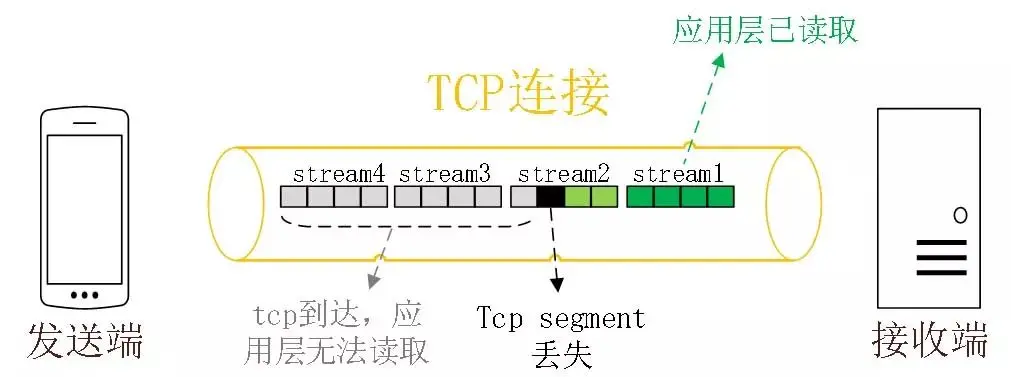
HTTP/2基于TCP,TCP是字节流,TCP层必须保证收到字节完整连续,这样内核才会将缓冲区里的数据返回给 HTTP 应用,前一个字节数据没有到达,后收到的字节只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是队头阻塞
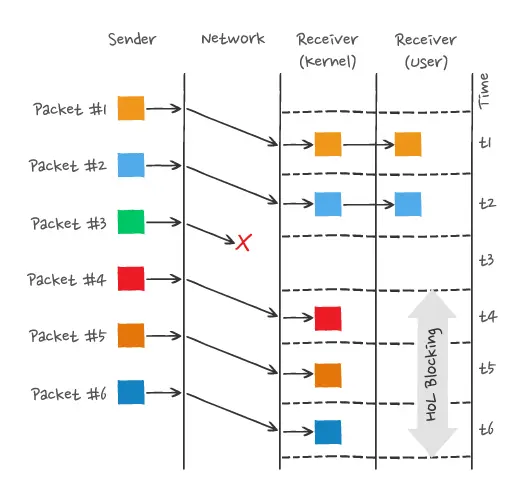
只有等到packet#3重传收到后,接收方应用层才可以从内核读取数据,这就是TCP层的队头阻塞
所以,一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来
而且,TCP 的拥塞控制、流量控制机制(如慢启动、滑动窗口)会影响 HTTP 的传输效率(比如突发大流量时可能被 TCP 限制)
HTTP/3做了哪些优化
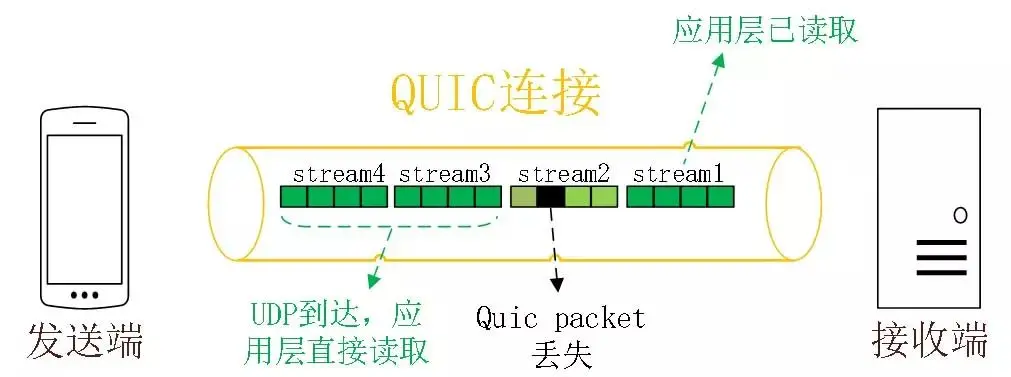
UDP不管丢包,不管顺序,不可靠传输,基于UDP的QUICK协议可以实现TCP的可靠传输
QUIC的3个特点
1/3无队头阻塞:
QUIC协议有类似Stream的多路复用概念,Stream 可以认为就是一条 HTTP 请求
某个流丢包了只会阻塞这个流,其他流不受影响
2/3更快的连接建立:
之前HTTP/2的TCP和TLS是分层的,先TCP三次再TLS四次握手(再啰嗦重复加深一下知识点:不管 TLS 握手次数如何,都得先经过 TCP 三次握手后才能进行TLS握手)
HTTP/3的QUIC协议不跟TLS(使用TLS1.3)分层,TLS在QUIC内部,QUIC握手只需要1个RTT确认双方连接ID就可以同时完成建立连接和密钥协商
且TLS1.2及之前4次握手,之后的版本,就3次握手了,即如下
-
客户端发送:通信加密请求、Client Random(不加密)、自身支持的加密算法、密钥共享扩展key-share
-
服务端回:数字证书、Server Random(不加密)、确认加密算法。此时服务器有了会话密钥了
-
客户端取数字证书的公钥,也得到会话密钥
这也是左图的解释,那右侧的QUIC是融合TCP和TLS的,直接2次握手就可以完成加密和连接,客户端打招呼、服务端回应、客户端确认
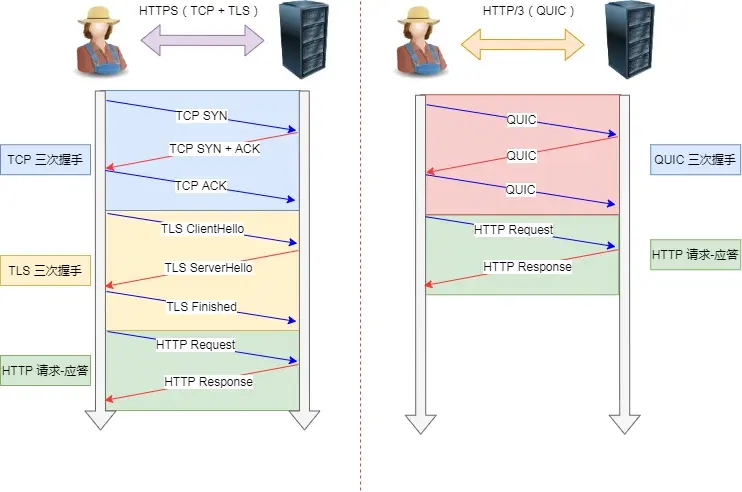
甚至第二次连接的时候,应用数据包可以和QUIC握手信息一起发送达到0-RTT,有效负载数据与第一个包一起发送(这里实在不想研究了,怕又浪费时间学深了,小林coding傻逼写的好像也是没咋懂就帖个图,没咋深入解释)
initial初始、resumed恢复
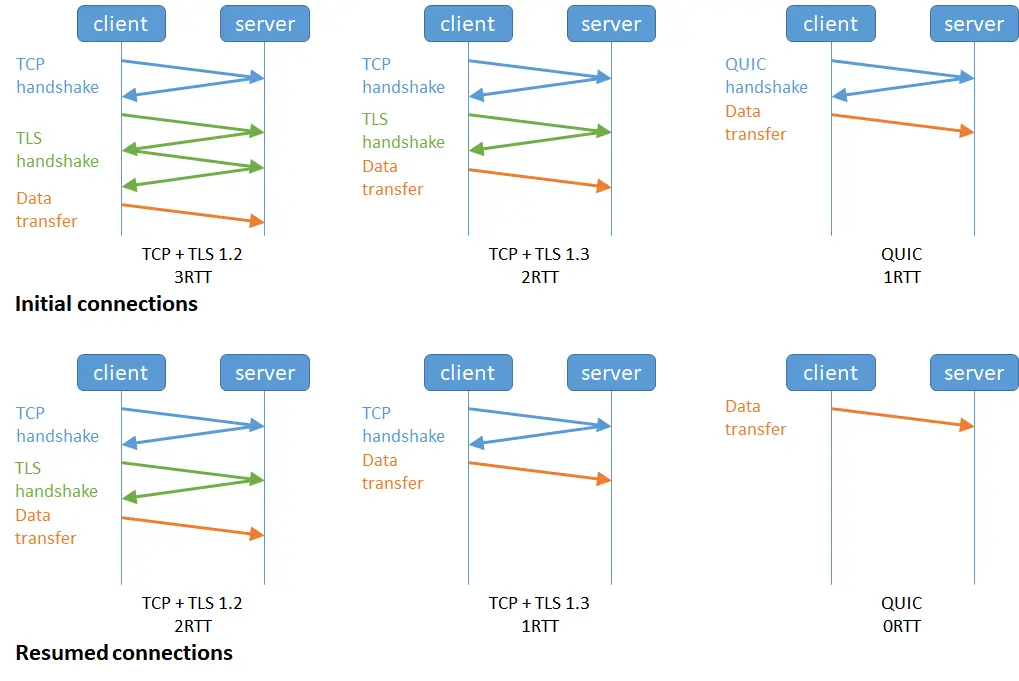
这4.14有个握手的事,现在没啥必要看,讲的是
客户端和服务端都开启了 TCP Fast Open 功能,且 TLS 版本是 1.3
且客户端和服务端已经完成过一次通信,
HTTPS的TLS和TCP三次握手同时进行
3/3连接迁移:
基于TCP的HTTP,由于通过四元组确定一条TCP
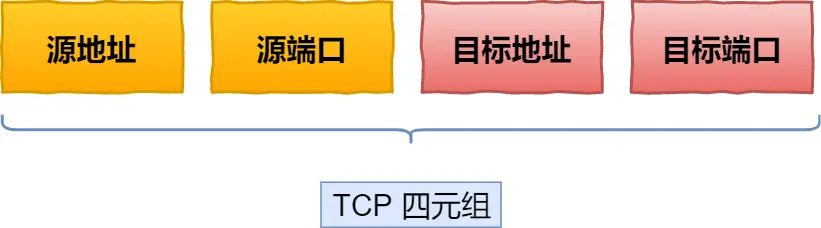
所以4G到wifi后IP会变化,TCP+TLS握手就会卡顿一下,而QUIC没绑定四元组连接,而是通过连接ID来标记通信两端点,IP变化扔保有上下文信息(ID、TLS密钥啥的)可以无缝复用原连接丝滑无卡顿
综上:
类似 TCP 的可靠性传输:(QUIC通过自身序列号确认机制保证的)
类似 TLS 的加密功能
类似 HTTP/2 的多路复用
QUIC是一个伪TCP + TLS(注意TLS就是SSL就是安全协议,由安全套接层演化来的) + HTTP/2 的多路复用的协议
但很多设备不知道QUIC,当作UDP又会丢包普及非常慢
小知识:
TCP全双工:这是传输层的能力
文件传输时,客户端和服务器可同时发送请求和响应(如客户端请求文件,服务器返回数据的同时,客户端可发送进度确认)
TCP 三次握手时,源端和目的端的 IP 地址会被包含在数据包中,这样一来,无论是客户端发送请求,还是服务器端进行响应,都能通过 IP 地址准确找到对方,确保数据能在复杂的网络环境中找到正确的目标设备,从而实现端到端的通信
HTTP半双工:这是应用层的设计结果
同一时间内,通信双方只能 单向传输数据
必须由客户端先发送 请求,服务器接收后处理并返回 响应,在响应完成前,客户端 不能发送新的请求(HTTP/1.x 时代)
HTTP/2及以上,通过二进制分帧和多路复用,实现全双工了
HTTP/1.1 如何优化?
优化方法1/3,尽量避免发送 HTTP 请求:
对于重复的请求响应,用HTTP协议头部缓存字段实现
把第一次请求以及响应数据保存在本地磁盘上,将请求的 URL 作为 key,而响应作为 value,形成映射关系,后续通过key找value
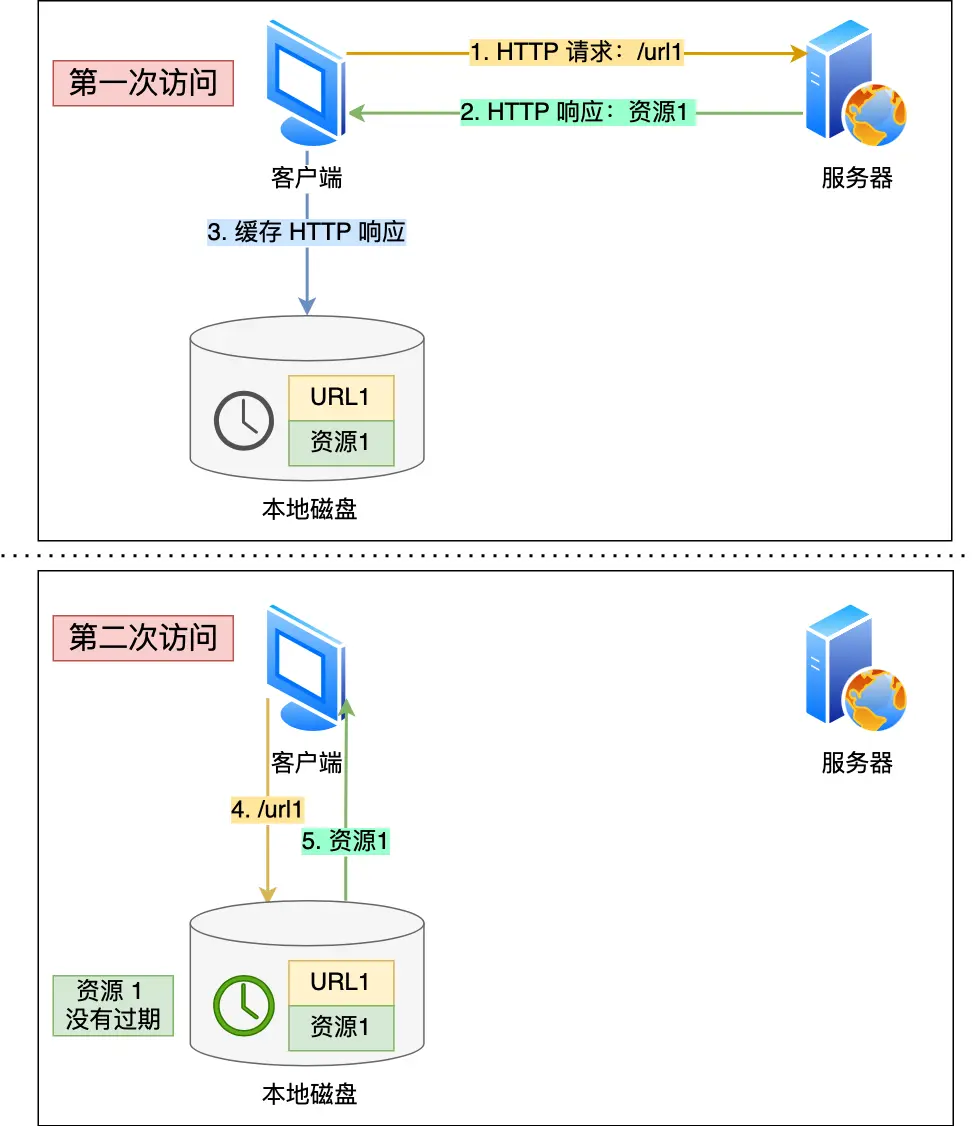

这里具体知识前面Etag那说过,不再展开
优化方法2/3,需要发HTTP请求时,考虑如何减少HTTP请求次数:
切入点有三个
2.1减少重定向请求次数:(想到了最小生成树,和问豆包金融项目的那个涉风险ABC减少成AB)
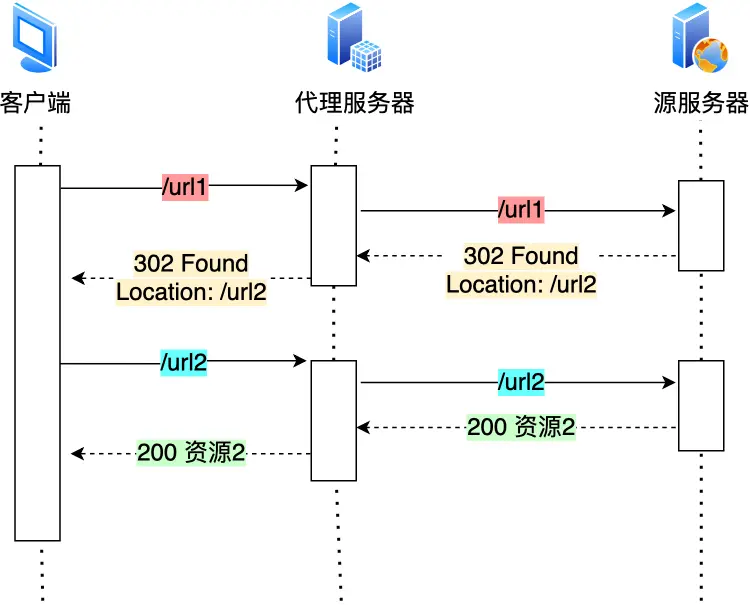
我们把重定向工作交给代理服务器
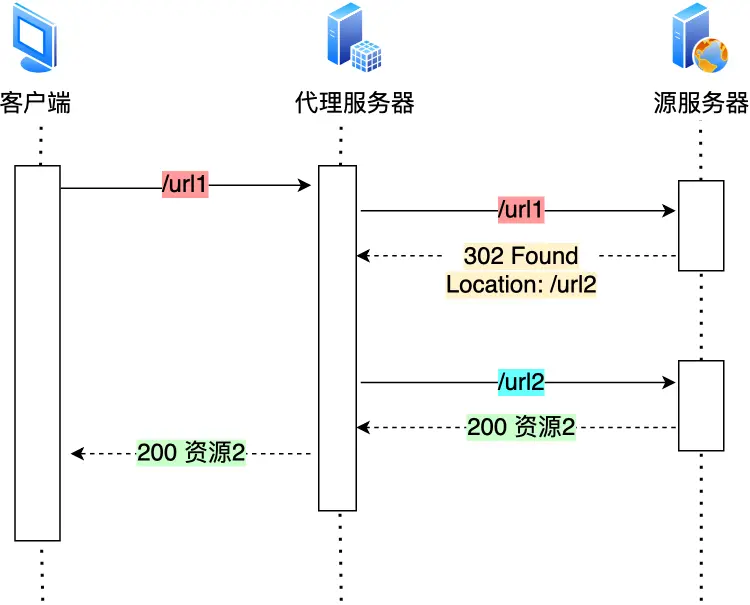
当代理也知道了,那更好了
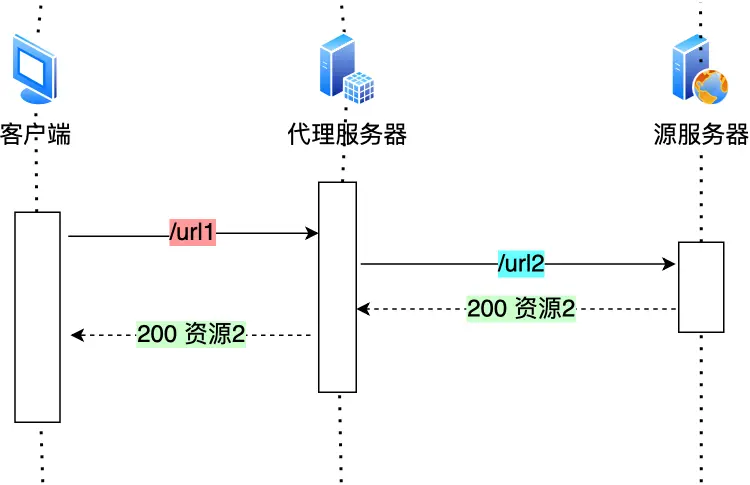
贴个响应码
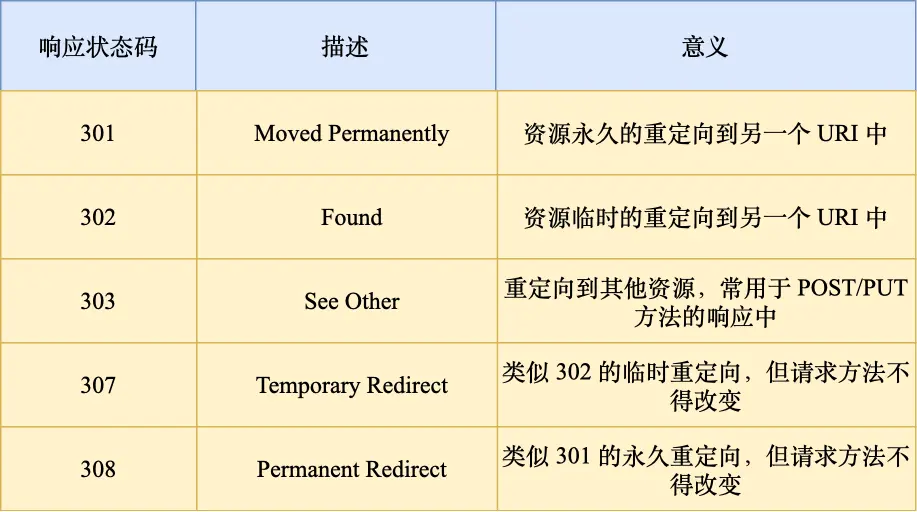
其中301是告诉客户端重定向响应缓存到本地磁盘,之后自动url2代替url1
2.2合并请求;
多个小文件一起发,减少请求
正常是不管道,但为了防止单个请求阻塞,同时发起5-6个请求,每一个请求都是不同的 TCP 连接
那合并了就减少TCP连接数量,比如先请求获得大图片,再根据CSS数据切割成多张小图

还有另一种方式,服务器端用webpack等打包工具将js、cs等资源合并打包
还有就是图片的二进制用base64编码,跟HTML一起发送<image src="data:image/png;base64,iVBO.../>客户端直接解码显示图
但合并请求即合并资源,大资源中某个小资源变化后,客户端必须下载整个完整大资源文件,增加网络消耗,引入延迟发
2.3延迟发送请求
一般 HTML 里会含有很多 HTTP 的 URL,当前不需要的资源,我们没必要也获取过来,于是可以按需获取。即只获取当前页面资源,往下滑页面的时候,再获取下面的
优化方法3/3,减少 HTTP 响应的数据大小:
HTTP响应数据大小比较大时,对资源压缩,减少响应数据大小,压缩方式两种
无损压缩:用于文本文件、程序可执行文件、程序源代码
计算执行不需要换行空格这些只是方便人阅读,这一步叫对语法规则压缩。然后利用统计模型将常出现的数据用较短的比特序列表示,不常出现的用长的二进制比特序列表示(生成二进制比特序列「霍夫曼编码」算法)
常见无损压缩gzip,客户端支持的会在HTTP请求头Accept-Encoding: gzip, deflate, br给出,服务端收到后会Content-Encoding: gzip
有损压缩:牺牲质量,用于多媒体,比如Google的Webp
HTTP头Accept里的「 q 质量因子」告诉服务器期望的资源质量,Accept: audio/*; q=0.2, audio/basic,另外说个词汇:增量数据:比如,一个在看书的视频,画面通常只有人物的手和书桌上的书是会有变化的,而其他地方通常都是静态的,于是只需要在一个静态的关键帧,使用增量数据来表达后续的帧,这样便减少了很多数据,提高了网络传输的性能。
HTTP几种说完了,再说下有个RPC协议
fd = socket(AF_INET,SOCK_STREAM,0);
其中 SOCK_STREAM,是指使用字节流传输数据,即TCP,然后bind()、connect()。最后send()、recv()。至此就是一个纯裸TCP,TCP的面向连接、可靠、基于字节流是基本特点,那说下基于字节流,
字节流即是双向通道里流淌的数据(01串),为了知道怎么读,区分数据边界,有了自定义规则,比如加消息头(里面写完整包长度是多少、压缩与否格式啥的,都是上下游约定好的,这就是协议),
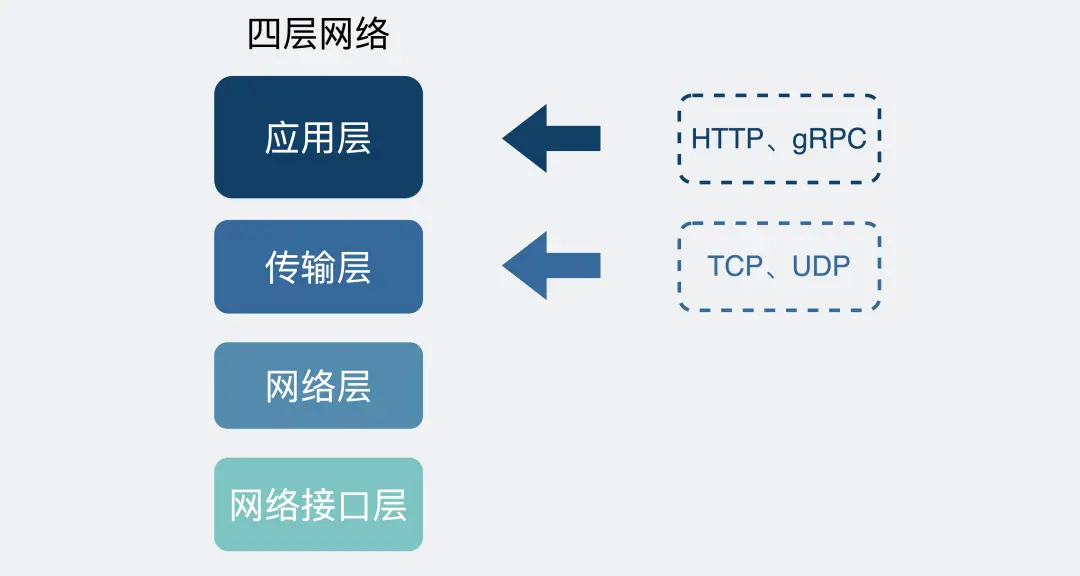
所以TCP的项目有一些自己定的协议标准,即衍生了HTTP和RPC
TCP是传输层协议,基于TCP定义不同消息格式的应用协议有:HTTP、各类RPC协议,
HTTP全称是超文本传输协议:
RPC全称是远程过程调用:即本质是要给调用方式,而像 gRPC 和 Thrift 这样的具体实现,才是协议,实现了RPC调用,RPC调用即调用远端服务器暴露出来的一些方法,好处是屏蔽掉一些网络细节
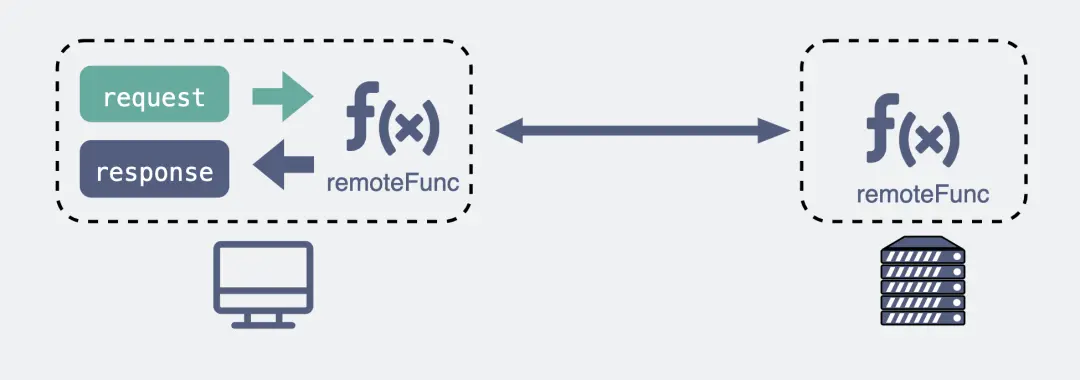
本质都是TCP做基础

再次说下时间线:
TCP是70年代的协议
直接用裸TCP会有问题,又有了RPC协议,
直到90年代又有了HTTP协议。
电脑上各种联网软件, xx管家,xx卫士,都跟服务器建立连接收发消息,叫Client/Server (C/S) 架构,这里可以用自家造的RPC协议,只管连自己公司服务器就行,
但浏览器不仅要能访问自家公司的服务器(Server),还需要访问其他公司的网站服务器,所以衍生统一标准,即HTTP,也是统一 Browser/Server (B/S) 的协议
所以多年前,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。
现在慢慢融合,很多软件同时支持多端,比如某度云盘,既要支持网页版,还要支持手机端和 PC 端
如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。
而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
那现在捋清楚发展时间线
都用 HTTP 得了,还用什么 RPC?
服务发现方式:
向某个服务器发请求,得先找到IP地址和端口,这个过程叫服务发现,然后才能建立连接,
HTTP里知道域名通过DNS解析得到IP地址默认80端口
RPC一般有专门的中间服务(Consul/Etc/Redis),保存服务名和IP信息,去中间服务获得IP和端口
底层连接方式:
HTTP/1.1默认底层TCP后保持KeepAlive,之后请求响应复用这条连接
RPC也是默认底层TCP后保持长连接,但还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用
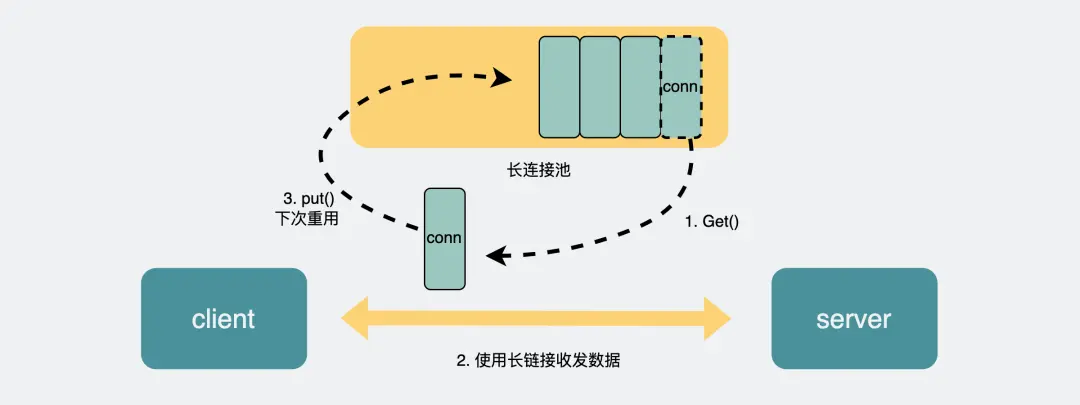
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的
传输的内容:
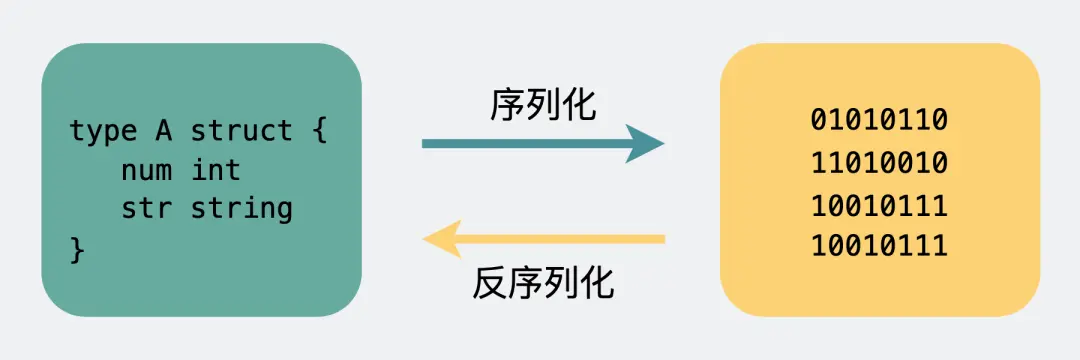
Header:消息体长度
Body:真正传输内容,数字和字符串转成编码再变成计算机认识的01串,结构体就用json转成01串,结构体转二进制数组过程叫序列化
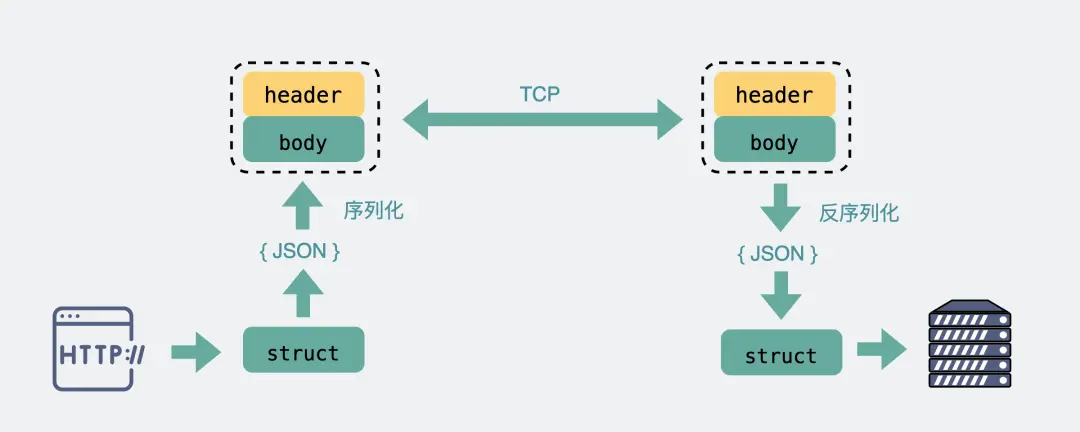
至此发现,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 Content-Type,就不需要每次都真的把"Content-Type"这个字段都传过来,,类似的情况其实在 body 的 Json 结构里也特别明显。
而RPC可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的
因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因
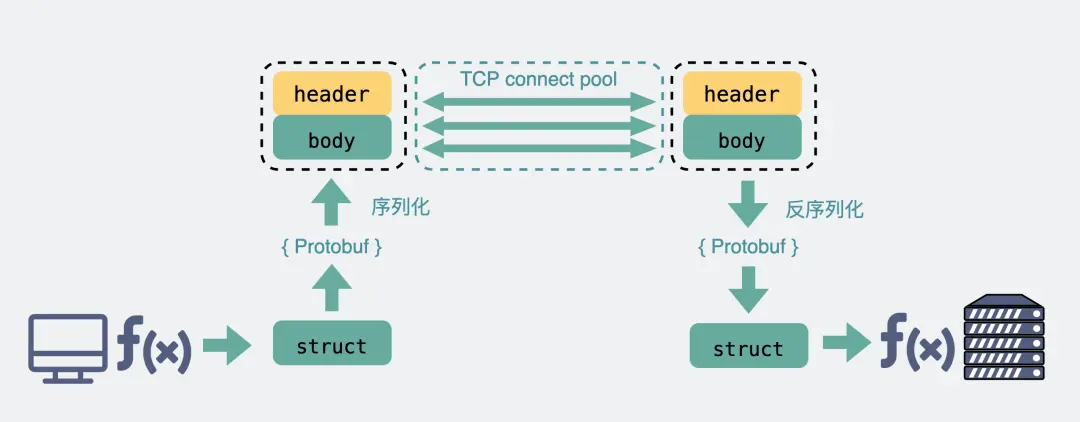


好他妈烦操,东西真鸡巴多
最后再说说WebSocket
一些页游,看起来服务器主动发消息给客户端,即自动点自动推送消息,本质是网页的前端代码里不断定时发 HTTP 请求到服务器,服务器收到请求后给客户端响应消息
即伪服务器推形式,再比如扫码登陆,HTTP定时轮询,即前端1~2s间隔,向后端服务器发出询问请求,看用户是否扫码了及时做响应(不断轮询)
但这样F12会看到满屏幕HTTP请求,消耗带宽,
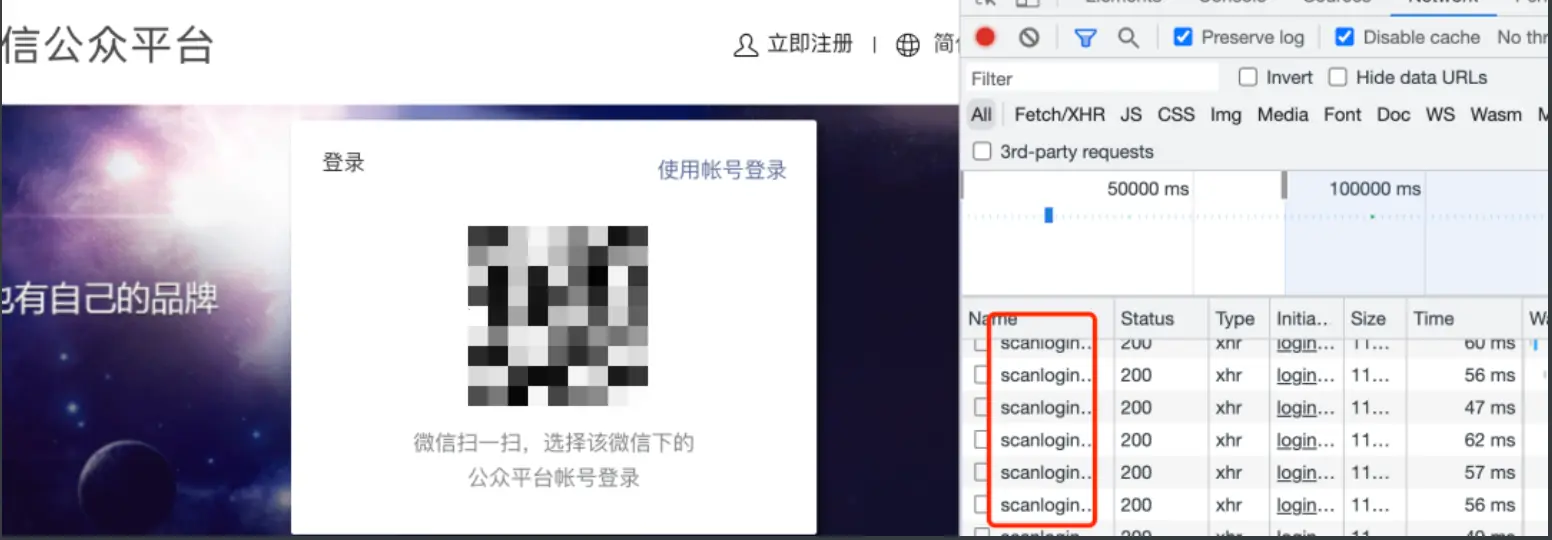
还增加下游服务器负担,1~2s会有明显卡顿
改进:
采用长轮询(长训轮询机制,消息队列ROC课题MQ中消费者去取数据场景),
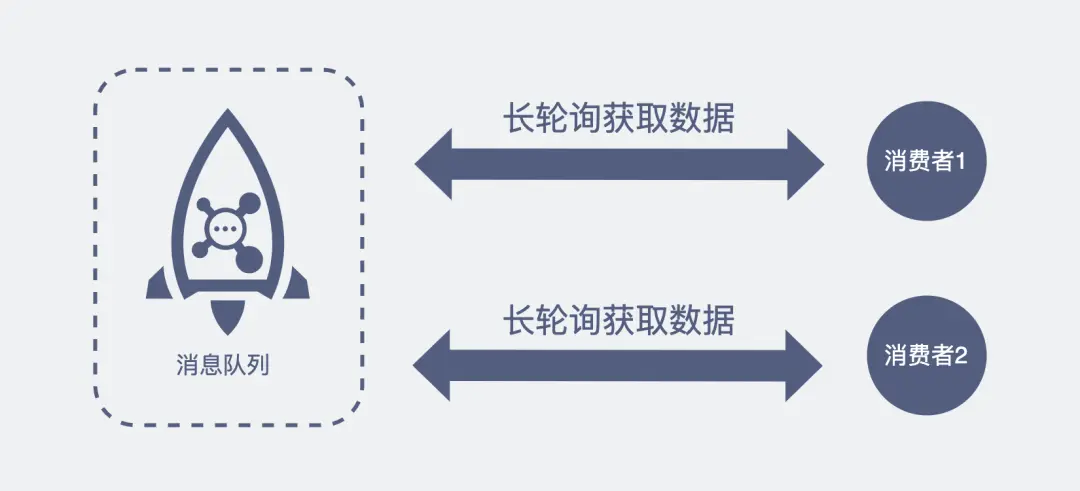
HTTP请求后,给服务器留一定时间做响应,没返回认为超时,期间一直再持续检测等待,扫码就秒跳转
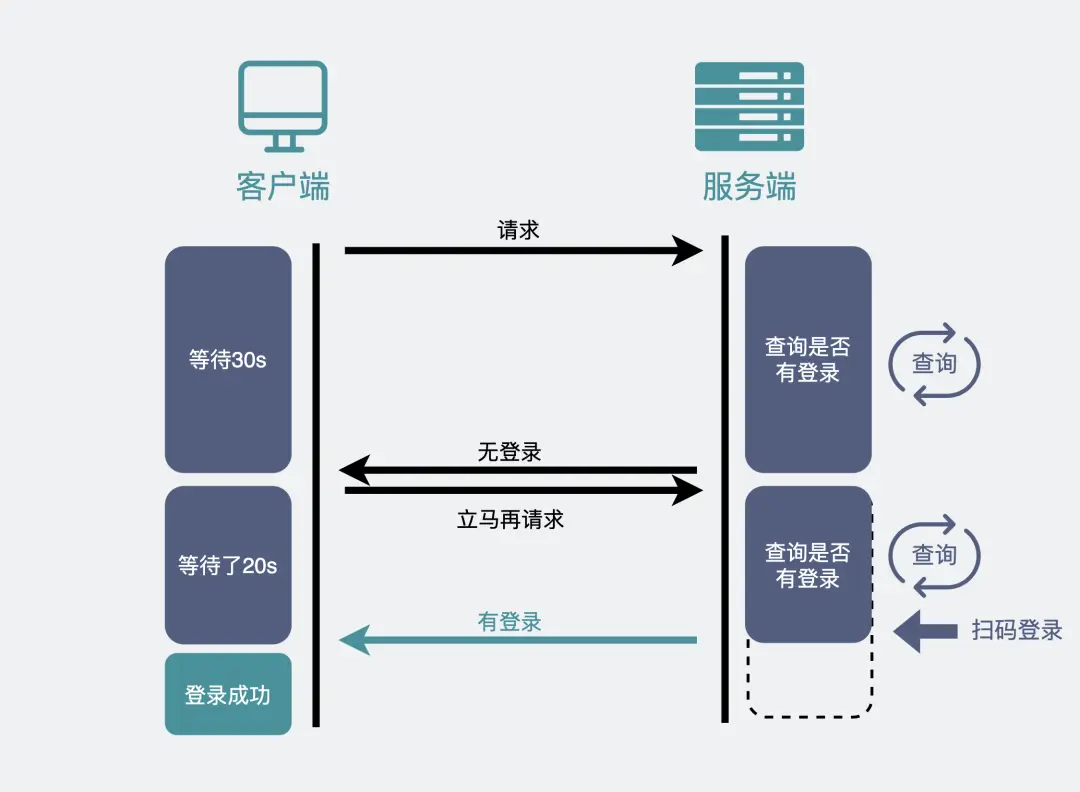
在用户不感知的情况下,服务器将数据推送给浏览器的技术,就是所谓的服务器推送技术(comet )
但如果游戏大量数据需要从服务器推送到客户端,引出应用层新协议WebSocket(名字虽然socket但跟socket没任何关系)
上面说过TCP全双工,HTTP/1.1应用成了半双工,因为HTTP设计初只考虑看网页文本场景,没考虑需要客户端和服务器之间都要互相主动发大量数据的场景
打开网页游戏,自动找到怪物推送给你的这些事就是WebSokcet干的事了
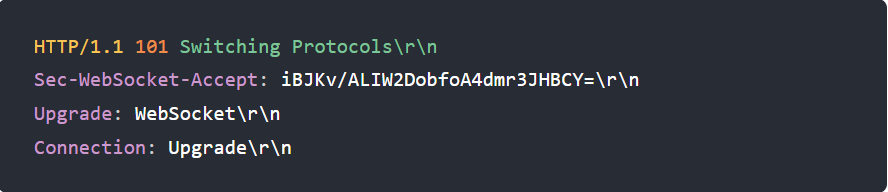
解析:浏览器想升级协议(Connection: Upgrade),
并且想升级成 WebSocket 协议(Upgrade: WebSocket)
同时带上一段随机生成的 base64 码(Sec-WebSocket-Key),发给服务器。
服务器支持就WebSokcet握手,同时根据客户端生成的 base64 码,用某个公开的算法变成另一段字符串,放在 HTTP 响应的 Sec-WebSocket-Accept 头里,同时带上101状态码,发回给浏览器(101是协议切换)
客户端
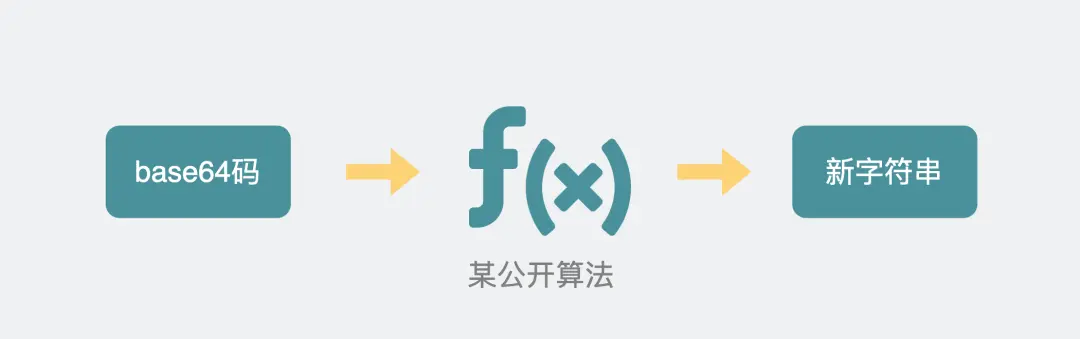
浏览器也用同样的公开算法将base64码转成另一段字符串,如果这段字符串跟服务器传回来的字符串一致,那验证通过
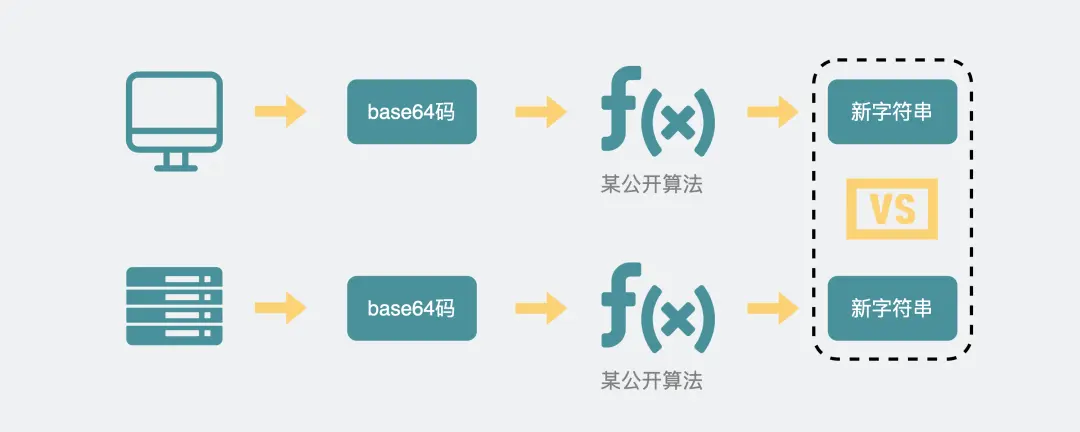
这样经历了一来一回两次 HTTP 握手,WebSocket就建立完成了,后续双方webSocket数据格式通信
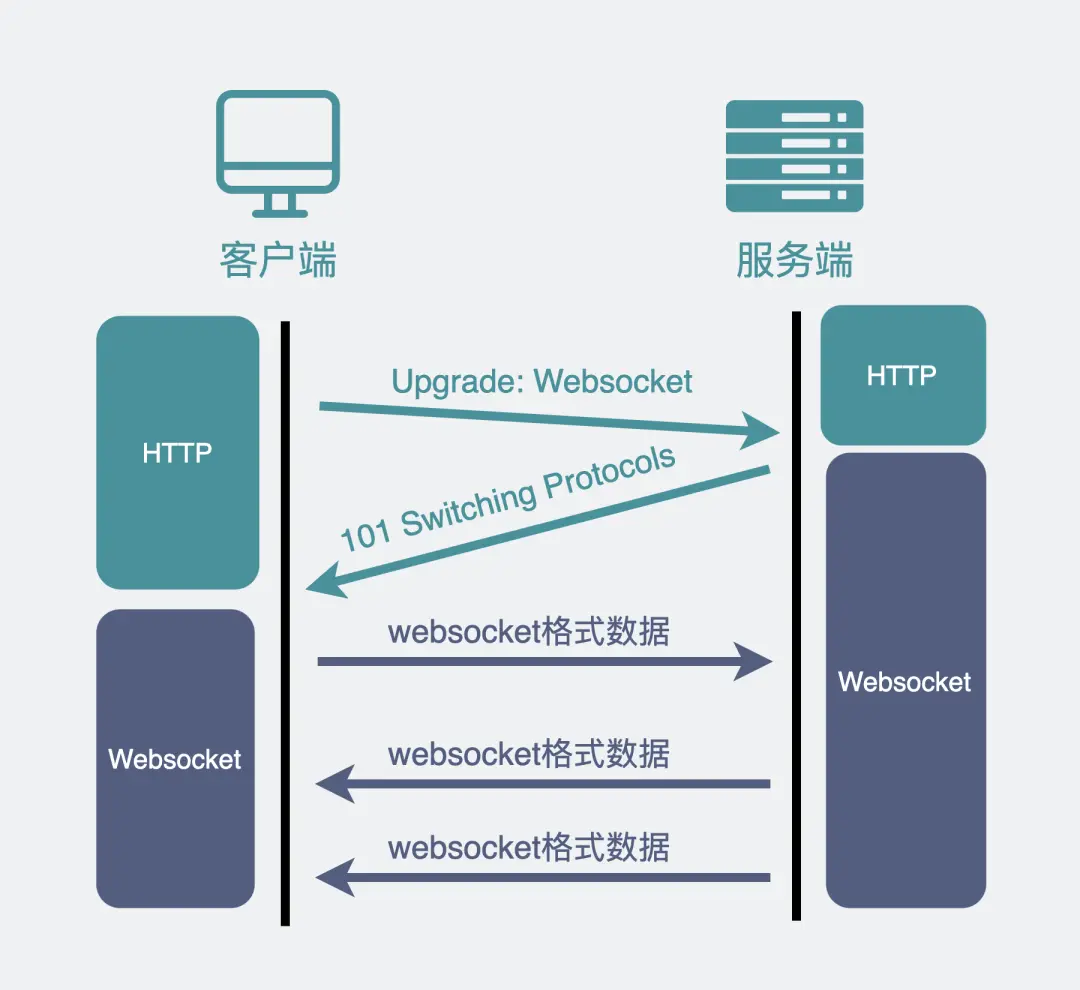
具体是TCP三次握手,利用HTTP协议升级为WebSocket协议
WebSocket并不是基于HTTP的新协议,只是用HTTP建立连接
WebSocket的消息格式:数据头(payload长度之前)+payload data
消息头里一般含有消息体的长度,通过这个长度可以去截取真正的消息体
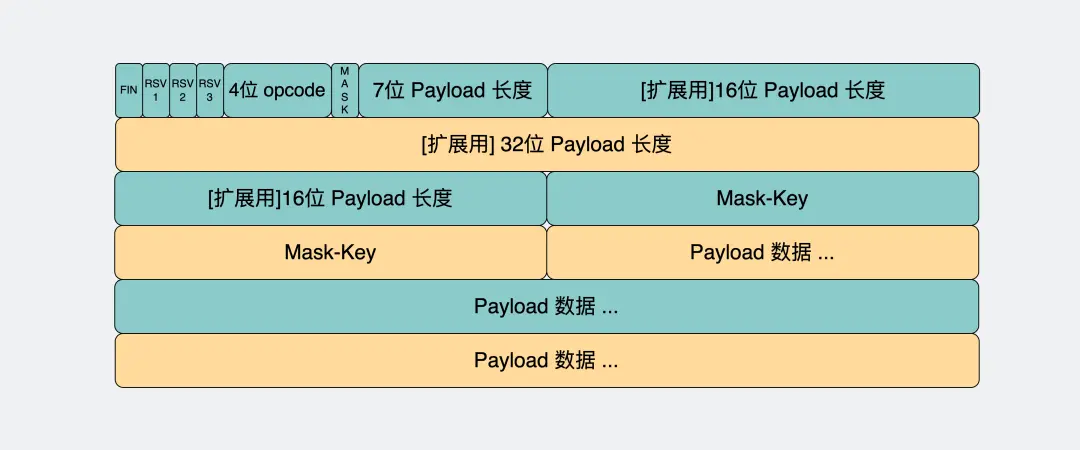
opcode字段:这个是用来标志这是个什么类型的数据帧
payload字段:存放的是我们真正想要传输的数据的长度,单位是字节
如果最开始的7bit的值是 0~125
如果是126(0x7E)。那它表示payload的长度范围在 126~65535 之间,接下来还需要再读16bit
如果是127(0x7F)。那它表示payload的长度范围>=65536,接下来还需要再读64bit。这64bit会包含payload的长度
(这里懒得研究了,究竟是32还是64他可能笔误了)
WebSocket完美继承了 TCP 协议的全双工能力,并且还贴心的提供了解决粘包的方案,适用于需要服务器和客户端(浏览器)频繁交互的大部分场景,比如网页/小程序游戏,网页聊天室
在使用 WebSocket 协议的网页游戏里,怪物移动以及攻击玩家的行为是服务器逻辑产生的,对玩家产生的伤害等数据,都需要由服务器主动发送给客户端,客户端获得数据后展示对应的效果
总结:

=========================
以下原文:(很多缩减归入到上面的更新了)
这个链接搜“就是啥都不对。感觉一直的努力都白费了”是豆包回复的找工作学习和终极规划方向
哎,很多细节我都看了~~~~(>_<)~~~~
有时候看公众号那些文章,乌烟瘴气的,连吹带骗的,走投无路,一无是处穷途末路
很多细节不该看的,到时候准备简历可以看看豆包的这段
搜“拜托你能不能仔仔细细看完我的问题”是绝望的回答,但也有些建议,到时候找工作写简历看下吧~~~~(>_<)~~~~
---------------------------
正常的的话,我早就 腾讯 SP offer 工作两年了吧,唉~~~~(>_<)~~~~
再也不那么笨了,太吃亏了~~~~(>_<)~~~~╮(╯▽╰)╭
发现很多大厂的人也不过如此,投机取巧而已,很多东西都没我追问了解的深,很多公众号写的各种深入拷打层层追问问题,不过都是我基本操作,可正因为每个东西多学的深,思考细致,唉浪费了这么久
小林coding里搜“警察局”,那个逻辑笔误了,爸爸是私钥,不是公钥
不仅仅这里,整个加密这块都有点会引起歧义,有空好好给他润色一下吧,就首先那个机密性就没说清,我的疑问和豆包解惑都在链接里,随便举个例子:
小林codeing文中说的“混合加密”根本不是解决窃听风险!
再举个例子:
小林codeing里,过早引入私密也被窃取这个事,导致前期在看数字证书的时候就说公钥私钥都会被窃取,其实此时只是公钥被窃取!解释混乱!漏洞百出,我强迫症追问豆包才彻底懂了这块,却还要回头去研究他的例子,发现例子完全很混乱!无语!
其实学东西我觉得禁止举例子打比喻,新手想的不多还行,像我这种想很深很缜密的新手,抓住一个就死磕钻研的,会发现他们很多比喻的例子都描述的不恰当(甚至小林这里都笔误了,就算不笔误),很多例子也完全不贴切,还要强行去理解比喻的栗子。适得其反,不如直接用更精准的语言来就事论事讲解
越了解透彻越觉得例子其实漏洞百出南辕北辙,只适合给幼儿园级别的人讲着玩,因为像我这种思考缜密有深度发散思维极强的人,对例子本身脑子里就自动映射出无数可能和场景,而这些场景有些不适用于知识本身,有些又有偏颇,反倒百害无一利,不如专注讲解知识本身
这里无关乎私钥被窃取!只是我之前最早弄github说的抢先一步发送的那个事!!!
之前捣鼓vim就研究了公钥私钥,就问过豆包,如果自己github早就被别人抢先一步弄了公钥私钥咋办
这里搜“太透彻了”,但自己想的过多,总想找点漏洞,有点CTF了哈哈哈,先这样吧
20250415:开始不那么细心那么钻研面面俱到事无巨细了
我好想加吴师兄、代码随想录、公子龙、鱼皮、小林coding、帅地、编程指北他们微信给他们转个88问一个问题和建议,唉算了他们,都是商人,又有谁能弄帮我~~~~(>_<)~~~~
磨练意志力“中科院黄国平博士论文”
学习方法比机械那个差远了
对着机械和编程指北学
不用学多深
崩溃的时候,好想问王Y涵,算了
自己解决吧,不想总麻烦他
问豆包,很多其实都学的太深了
又陷入绝望,得亏他妈问一句,这逼的王Y涵真他妈操蛋,完全不给你指导啊,这我他妈又差点儿陷死透了嘛,这照这看,我C你妈,他妈看半年,看一年,看十年百年,我他妈也看不完呢。我操你奶奶。
后来发现很多都是入职后才需要进阶的,现在看纯是浪费时间,我会的很多都是加分甚至比大厂都强好几个维度的
但很多基础不会,技能书点偏了
我总想问别人,我只是想问小林,可我得先把那个人的机械转那个什么的给我,但是。我不好意思问,哎呀,主要是自己挺烂的,六年毕业就一年工作经验,也没法说,不好意思,也没脸去找他们。他们也是商人,也够呛能给我这个东西,我也不想再联系任何人了。
智齿疼的要死
真的感觉自己要死了
睡觉冷不丁无意间咬合一下,疼的要命,受不了了啊😖😖😖😖😖😖😖
疼的腿都直打颤
想学这些东西,就无尽的绝望。而后又自己鼓气,而后又是绝望,何时,是个头啊
妈逼的一个小林coding网络给我看的
觉得要4个月,甚至8月份
艹无尽绝望,还有妈妈的期待
到头来网络编程学偏了
菜鸟教程学偏了
就是啥都不对。感觉一直的努力都白费了
啥都不该学
准确说不该看菜鸟教程和网络编程,唉浪费了巨多时间
每一章都认真做课后习题,可是又一次认真细心的品质辜负了我,感觉没任何用处,都不是面试要考的,唉浪费了巨多时间
算法
那些
都是工作后牛人做的?啥啥最低门槛我没有去学
我的心性,我总担心29岁大龄,那我就不能转化为优势吗?我就不能成为最年轻的高管吗?我心性悟的东西透彻,社会经历阅历
虽说工作年头少,但找自己的优点
从认真啃TCPIP网络编程(最后下定无数次决心勇气,一而再再而三的啃windows废弃的底层 API)
到开始看小林coding觉得轻松十倍百倍
看到TSL那觉得痛苦,问豆包针对性!
发现都是进阶知识
开始又用机械那人的方法看
更加轻松好多
回忆自己钻研各种小林coding之前的细节
还有菜鸟教程里的时间戳那些函数,唉头疼
不那么细致细心的看
不那么认真的咬文嚼字,力求完美字字都懂
真牛逼不愧是双一流武汉理工的,学习方法就是强
绝望后开始对着他和编程指北的路线看
算了还是继续这样吧,每一块搞懂,问豆包脑海里有框架就行,xmind没啥必要或者说浪费时间,typora 网页版免费还得使用markdown,也按照现在这个路子弄这么久了,知识留在脑海中就行,如果自己搞知识点,要写的就太多了,且导出都是要总结的,直接先看懂吧,一边给豆包捋顺自己的理解得了。最后找个网上的八股文看就可以了
虽然没用typora,但有意识的知道自己学的问的钻研深(经常看一些公众号或者小林codeing给人做培训前评测总结,发现就这也能干开发?按照他那个给人的测评自己学,内心:
这也能干开发?
就这啊?
公众号一些上岸大厂的标题或者讲解某知识点的文章,这种问题也叫面试拷打?也叫层层追问啊???我就是每一个点都这么学的啊,这不是基本操作啊?遂不再这么细致的学东西了
如果我不刷盘子无奈照顾家人待业那几年,正常成长轨迹,我早都腾讯 SP offer工作两年了吧,唉~~~~(>_<)~~~~
不该这时候研究这些入职后该进阶的东西就放弃了,只捋顺宏观知识体系,有意识的每学一个番茄时钟就回忆自己学了什么会了什么,如此一来,看小林coding快了,也很清晰了,可能也是吃七个烧饼不是第七个饱的缘故吧
-------------------------------------------------------------------------
TCP篇
带着问题学,这个有没有必要看,看完能否给面试官讲出来,没啥用感觉放弃不浪费一点时间 (不放链接了)
20250416
开始用xmind(操他妈的xmind太费时间了,不搞了)
哎之前总弄过帖图、放链接没总结,毫无用处~~~~(>_<)~~~~
估计最后还要重新找那些链接里捋顺总结给豆包的话╮(╯▽╰)╭
从这开始不用回头看了,只看这个就好
之前啃 TCPIP网络编程书 和 HTTP篇 的内容都重新总结吧
重点:
-
捋顺TCP三次握手:
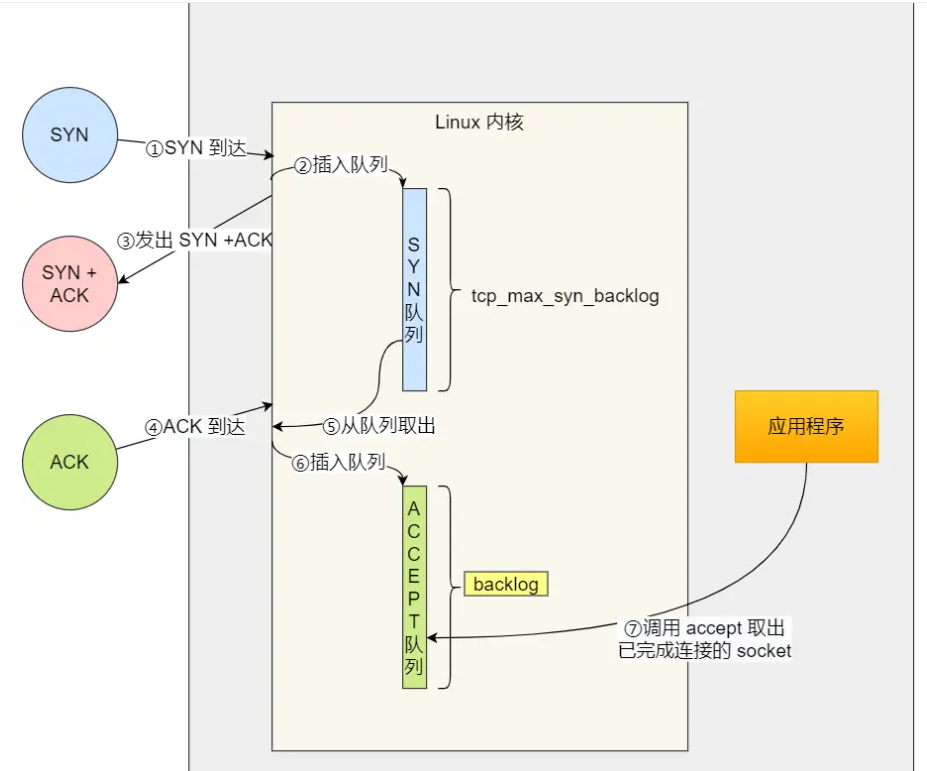
- UDP属于传输层,运行依赖或者说基于IP
结论:UDP 是传输层协议,基于 IP 层提供的 “主机间通信” 能力,但二者属于不同层次。
- 分层和动态
- HTTP下是TLS然后是TCP,但为何先TCP握手建立链接再TLS握手?
- 四元组
客户端connect时,里面的参数是目的IP地址和目的端口号,同时系统会自动为客户端分配源IP和端口
服务端会在bind的时候,为目的IP地址和目的端口号。accept的时候,自动填充获取客户端地址和端口号
- TCP在三次握手是怎么初始化Socket、序列号、窗口大小建立TCP连接的?
1、套接字:是os提供的网络通信端点抽象,本质是IP地址+端口号的组合,唯一标识网络中通信的两个进程(客户端&服务端)(四元组)
客户端和服务器在三次握手前,需各自创建 Socket(客户端指定服务器 IP + 端口,服务器绑定本地端口并监听)
2、序列号和窗口大小初始化:
客户端在发送SYN报文中就携带了初试接受窗口大小(告知服务器自己能接收的数据量,后续可动态调整)
综上工作流程:
创建套接字,三次握手,传输数据
- 窗口大小
TCP头部字段,窗口大小单位值字节,表示接收方允许发送方发送的数据量
- 宕机后
客户端宕机后,若服务器未收到客户端对之前数据的确认(ACK),会因超时触发重传机制,重新发送未确认的数据。
宕机后,TCP 连接的状态(序列号、ACK、接收 / 发送缓冲区等)仅存储在客户端和服务器的内存中,宕机(断电 / 重启)会直接清空客户端的所有连接状态
若客户端宕机前,服务器已发送旧数据但未收到 ACK,这些数据会暂存于服务器的重传队列中(内存中),服务器会按超时机制反复重传,直到超过最大重传次数
旧数据的 “序列号凭证” 对新连接无任何意义。
旧SYN称历史链接
- 勘误
小林codingTCP篇4.1的tips写的逻辑不通,都说了想解答先收到新的,却解答的还是先收到旧的
- 为何不2、4次握手
1、个人理解关键点在于客户端发送后,服务端没有向客户端做一个确认,是否真的是收到的这个,进而导致不会丢弃错误的,白白链接浪费服务端的资源,没有避免历史链接
2、保证双方可靠传输,这句话是官方说法,但理解的话本质就是:
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可优化成一步,就有了三次握手。
而两次握手只保证一方初始化序列号可以被对方成功接受,没办法保证双发的都能被接受
3、资源浪费无效链接
- 传输分片:
网络层进行IP分片,一份IP数据报分片后由目标主机IP层重组,再交给上一层TCP传输层。但IP层没有超时重传,由传输层TCP来负责超时重传,会重新传所有整个TCP报文
导致效率很低
先说下分片是啥
IP 分片是 “带新 IP 头部的 TCP 报文切片”—— 每个分片必须有 IP 头,数据来自 TCP 报文的头部或纯数据部分,分片丢失会导致接收方无法重组完整 IP 报文,进而触发 TCP 重传整个原始 TCP 报文(头部 + 数据全重传
理解了分片,改进:
那就不在IP分,协商个MSS,TCP层发现数据超过MSS,先分片且会依旧不会大于MTU,自然不用IP分片了
好处:TCP分片后,一个TCP分片丢失,只需要重发MSS为单位,不用重传所有分片
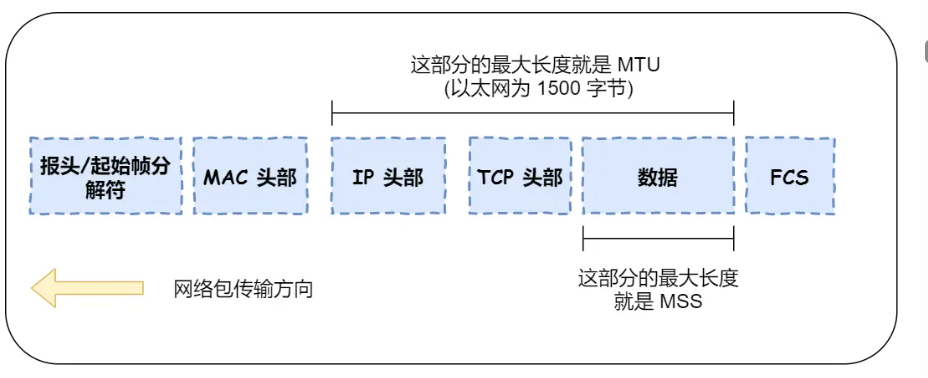
- 超时重传(无论挥手握手,ACK不会重传)(注意:所有重传都是会最后等待上一次的2倍时间,有些就没写太详细)
第一次握手丢失:
重发SYN
尝试
tcp_syn_retries次,每次RTO、2*RTO、4*RTO、8*RTO、12RTO、32*RTO秒... ...,之后再等一会(时间为上一次超时时间的 2 倍),依旧没SYN-ACK 确认就断开链接第二次丢失:
客户端重新发送SYN报文,最大传输次数由 tcp_syn_retries 内核参数决定
服务端也会重新发送SYN-ACK报文,最大次数由 tcp_synack_retries 内核参数决定,
第三次丢失:
ACK不会重新发送,而是尝试 tcp_synack_retries 次超时重传 SYN-ACK
- SYN攻击和避免
SYN攻击就是打满SYN队列
解决:
- 调大 netdev_max_backlog(网卡接受数据包的大小)
- 增加TCP半链接队列
- 开启 net.ipv4.tcp_syncookies(绕过队列)
- 减少 SYN+ACK 重传次数(因为大量处于SYN-RECV状态的,快速断开链接)
- 四次挥手
失败的话,同握手
第一次挥手失败:
尝试 tcp_orphan_retries 次后,还没收到ACK报文,客户端直接断开链接,即对方无响应则视为已关闭或不可达
第二次挥手失败(ACK不会重传):
客户端尝试重传FIN 共tcp_orphan_retries 次
注意:客户端收到第二次挥手,即服务端发送的ACK后,处于FIN_WAIT2状态,此时会等第三次挥手,但close关闭的链接,不会接受&发送数据,所以不会等待太久,固定60s,
tcp_fin_timeout,后直接关闭但如果是shutdown的话,就会一直处于FIN_WAIT2状态(
tcp_fin_timeout无法控制 shutdown 关闭的连接)第三次挥手失败:
服务端收到客户端的FIN后,内核自动回复ACK,同时连接处于CLOSE_WAIT状态,表示等待服务端的进程主动调用close来发送FIN报文。那此时会进入LAST_ACK,等待客户端返回ACK确认连接关闭。如果迟迟等不到第四次的ACK,会重发FIN,次数
tcp_orphan_retrie,且close的话,tcp_fin_timeout后服务端直接断开链接
因为FIN_WAIT_2时间有限
第四次挥手失败:
客户端收到FIN后,发送ACK进入TIME_WAIT状态,TIME_WAIT持续2MSL后关闭 (MSL=报文最大生存时间)
服务端没收到ACK之前,还是LAST_ACK状态
第四次挥手ACK没到达服务端,服务端发送FIN,
tcp_orphan_retries次,还没有第四次的ACK就断开而2MSL定时器,如果到了就断,如果期间有第三次的FIN又来了,就重置
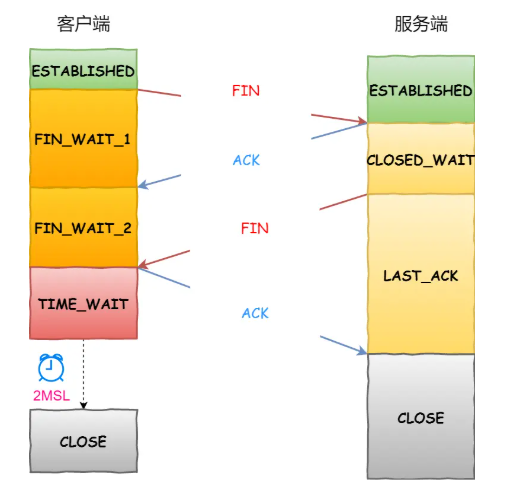

- TIME_WAIT:
TTL是IP的那个路由器跳数,一般64
MSL是时间要大于TTL消耗为0的时间,Linux设置30s,即64个路由器不会超过30s,否则认为消失在网络中。而2MSL就是一来一回
- 为啥要有TIME_WAIT:
1、如果有网络延迟,然后TIME_WAIT过少或者没有,那么就新建立的连接就会接受历史数据,错乱,2个TIME_WAIT充分丢弃残留
2、保证被动关闭连接的一方,能正常的关闭
假设最后一次ACK丢失了,服务端重发FIN,如果没TIME_WAIT,直接进入CLOSE状态,那么客户端收到后会返回RST错误报文,这种不够优雅对于可靠协议来说,没收到服务端会重新发FIN,一来一回两个MSL,客户端收到FIN后重置TIME_WAIT,
- RTO和MSL 以及解释为何正好2个MSL
客户端:
如果选择1000端口,四元组比如(
(客户端 IP,10000,127.0.0.1,9190)),那关闭后TIME_WAIT短时间1000占用,会有大量的比如1000、1001、1002占用,满了就没法连接了(引文会保证2MSL,避免干扰新链接,所以2MSL内不会再次用那个端口)总结:
TIME_WAIT状态占满端口时,仅影响与 同一「目的 IP + 目的 PORT」(如127.0.0.1:9190)的连接;对不同目的 PORT(如8080)或目的 IP 的服务端,因四元组变化,客户端仍可利用端口资源正常连接服务端:
TIME_WAIT和ctrl+C不同,四元组处于WAIT但服务端监听始终监听状态,等待新链接
WAIT是单个链接状态,不是端口状态,程序只要运行,端口就一直开放,与WAIT无关
Ctrl+C 2MSL只要未超时,就一直占用,不允许重新绑定,这也是TCPIP网络编程书里提到的,未来完全释放
TIME_WAIT 保护的是连接的唯一性,而非端口的可用性;端口能否监听,取决于服务端程序是否在运行并调用了监听函数
由于客户端是临时端口,WAIT后会释放重新分配,WAIT期间一直占用
socketopt指setsockopt函数里的选项参数。它能改变套接字行为,像 SO_REUSEADDR 可让端口在TIME_WAIT时被复用,避免bind error。调用时用setsockopt(sockfd, level, optname, &optval, sizeof(optval)),其中optname就是socketopt选项。设置
SO_REUSEADDR选项的主要作用是绕过TIME_WAIT状态对端口绑定的限制,而不是对TIME_WAIT时长进行优化// 设置 SO_REUSEADDR 选项 int optval = 1; if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval)) < 0) { // 处理错误 }
问题:“服务器重启时端口被占用,怎么解决?
SO_REUSEADDR的作用是什么?什么时候需要设置?”回答:SO_REUSEADDR
当服务器程序重启时,若上次关闭时端口处于 `TIME_WAIT` 状态,直接 `bind()` 会失败。 这时候设置 `SO_REUSEADDR`,就像“强制占用一个刚退房但还没打扫完的房间”,虽然可能有残留垃圾(旧连接的延迟包),但能让程序快速重启。 不过要注意:如果新旧连接的四元组(IP+端口+对端IP+对端端口)相同,可能导致数据包混淆,所以通常只在单实例服务器或测试环境用。
1、打开 net.ipv4.tcp_tw_reuse和 net.ipv4.tcp_timestamps 选项,
net.ipv4.tcp_tw_reuse:WAIT超过1s就复用
net.ipv4.tcp_timestamps :时间戳,记录比较比连接还早就丢弃
2、net.ipv4.tcp_max_tw_buckets
暴力无脑的18000个WAIT,新来的WAIT就重置扔掉,强制释放资源,不等待WAIT
3、
SO_LINGER:跟SO_REUSEADDR区别
问题:
调用 close() 后,缓冲区还有数据没发完,系统默认怎么处理?如果想直接断开不管数据,该怎么设置?
SO_LINGER 设置 l_linger=0 和默认情况有什么区别?为什么前者会发 RST 而不是 FIN?(答案:前者跳过四次挥手,直接重置连接)。回答:
分三种情况: ① **默认情况**(不设置):调用 `close()` 后,系统会发 `FIN` 开始四次挥手,等缓冲区数据发完(尽力发,不阻塞程序),最后进入 `TIME_WAIT` —— 就像“礼貌地说再见,慢慢收拾行李再走”。 ② **`l_linger=0`**:直接发 `RST` 断开,不管缓冲区有没有数据,直接丢弃 —— 相当于“摔门走人,行李不要了”,对方会收到“连接被重置”的错误。 ③ **`l_linger=5`**:等 5 秒,期间阻塞 `close()`,等数据发完+对方确认;超时后丢数据,发 `RST` 断开 —— 类似“等 5 分钟收拾行李,超时就强行走人”。查看代码
// 创建套接字 int sockfd = socket(AF_INET, SOCK_STREAM, 0); if (sockfd < 0) { // 处理错误 } // 设置 SO_REUSEADDR 选项 int optval = 1; if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval)) < 0) { // 处理错误 } // 绑定端口 struct sockaddr_in server_addr; // 初始化 server_addr if (bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) { // 处理错误 } // 监听端口 if (listen(sockfd, BACKLOG) < 0) { // 处理错误 }
- 关于应用层执行和内核底层机制
TCPIP网络编程尹圣雨书籍里,send后就close没出错是因为数据量小
但其实对我这种思考极深的来讲百害无一利!
其实send到close本质是,发送的数据量小,并且网络状况好的话,
send之后直接close通常不会有问题。不过在实际的复杂场景中,为保证数据的可靠传输,还是要对数据发送状态进行检查。具体解释:send把数据从代码里就是buffer数组(程序内存)复制到内核的发送缓冲区,发送完后,send就立马返回,不管数据是否发送目的主机
调用close是说以后不再发新数据了,不阻塞程序不等发完就返回(即发送完执行后续代码或者退出程序,但内核会完成发送),但缓冲区里有的还要发送给目的主机,内核会把内核缓冲区数据发送后,再给目的主机发送FIN,等待四次挥手
即程序应用层调用close后跑路了,操作系统作为内核会幕后默默把数据发完,后四次手
但有个现实可能是,正常会发送完,对方ACK确认,发送FIN挥手拜拜
而网络不好,多次重传会丢失数据,TCP可靠前提是双方主机在线网络可达,但也会发不出去,这是网络通信的客观限制
所以经常看到一些描述仿佛模棱两可的描述,叫“尽力发送”,其实是协议规定,但并非一定发送到!对方都关机关闭套接字了你还发个JB,TCP再可靠也不能把对方机子打开吧,哈哈哈
上层逻辑处理:
序列号检查,应用层维护序列号范围
时间戳过滤
- 至此再次深入了解优化WAIT的SO_LINGER
- 忏悔:
哎之前都是这么学的,只是没整理记录下来好亏,从截图豆包,到不截图放链接,到真正的的开始整理(一步步)
GerJCS岛: 其实真真正正学东西 从8月开始刷算法 12月结束(给人改代码) 后来得知都是冷门算法 1~3月啃菜鸟教程(完全走的错路啥收获也没感觉有,也可能七个烧饼原理) 3月初~4月初TCPIP网络编程(给书代码逻辑问题找代码bug) 后来得知都是过时的过于底层的已经废弃的知识 鼓气好几次win API根本看不下去,王钰涵不用看win的! 看小林coding,发现到了TLS完全无法钻研下去 看了机械上岸腾讯 各种文章发现就这啊? 开始放弃钻研这么多的东西 无比青松 GerJCS岛: 其实都是跑偏了 真正侧重点面试我tm感觉5个月足够去腾讯了 如果大学毕业不。。。正常我已经在大厂工作两年了吧,腾讯SP GerJCS岛: 如果每天上午来学习而不是下午学到23:40然后走路4.6km回家,4点睡觉 如果当初整理,不截图不贴链接,直接整理 唉 GerJCS岛: 这还不算什么,每次开机都祈祷不要3F0,掰电脑放电(北京理工化学自杀研究生) 回家乌鲁木齐回哈尔滨往返硬座不算啥,满车厢臭烟子味,电炉烤馒头汗水彻夜开灯仰头睡觉伸不开腿,满车厢臭脚丫子味。羽绒服全副武装不然烟熏的肺疼,抽烟区都不关门 一个月400几平米的小屋子,只要没耗子,很满足,哪怕左侧抖音前面厕所2点洗衣机,右侧呼噜声震天响 图书馆没位置,窝着蜷着 每天饿肚子,吃不饱饭,给家人买东西爸爸有病买高档水果,妈妈肯德基,2元的烤肠看那些中学生吃的好香,冬天袜子漏全部脚趾头,5元的厚袜子不舍得买,给高考阿辉买椅子, 冬天不邮寄衣服,冻的痔疮,磨练意志力 GerJCS岛: 躺床上一小时睡不着 每天你说,这边那家1点钟才有16元自助,吃的特别丰富起码能吃饱饭 但去图书馆就得晚,没位置窝那跑腿真的腿好疼。学的时间还少 去的早,就赶不上自助,但也是小概率会有位置,可是要多花2元,因为那边16元都吃不饱,18才能吃个6分饱中午,再饿就多喝点图书馆的水,可是喝多了就恶心了,学习头晕饿的营养不良就走1km去买维族人卖的1块一个的没生产日期的巧克力,虽然是多花2元吃饱饭,但去的早,也能多学一会
- syscall:
syscall是系统调用。当应用程序执行 syscall 时,会从用户态切换到内核态,由内核来完成相应操作,完成后再返回用户态 。
- 为何服务端会有大量WAIT?(由浅入深抽丝剥茧解释)
1、HTTP没用长连接
首先为何出现WAIT,那就是谁先close谁先WAIT
先说几个前设知识:
关于长短连接:
HTTP1.0默认关闭长连接(Keep-Alive):
只要请求头header中添加
Connection: Keep-Alive服务端回应时,也会添加到header,对同一个客户端四元组就会保持连接HTTP1.1默认开启:
只要请求头header中添加
Connection: close就会关闭,关闭长连接就会用短链接,这时候引出问题,谁先关闭(即谁先发FIN)?大多数浏览器都是无论谁先,都是默认服务端主动关闭
关于服务端探测客户端行为:
如果说想探测客户端是否发送close,有几个syscall:
1、select/epoll 检测:
读 TCPIP网络编程尹圣雨 易知,网络中可能存在多个 socket,select/epoll 用于检测特定 socket 是否有事件(如客户端关闭会触发相关事件)。这是一次系统调用(syscall),让内核检查 socket 状态,避免服务端无意义地死等,实现对 socket 事件的高效监控。这是一次syscall
2、read () 确认:
select/epoll 检测到事件后,依旧无法确定是客户端关闭还是其他数据传输。调用 read (),若返回 0(TCP 协议规定),则明确客户端已关闭连接。这又是一次 syscall,通过实际读取操作来最终确认连接关闭状态。
以上是底层设计实现的固定规则固定逻辑,没有为什么,所以至此发现,服务端想等客户端close就要 2次syscall。
基于以上前设知识:
对于
客户端开启 HTTP Keep-Alive,服务端禁用 HTTP Keep-Alive服务端直接close,只需要一次syscall,内核就会处理后续的连接关闭流程,不需要先检测再读取确认,所以更高效
而对于
客户端禁用 HTTP Keep-Alive,服务端开启 HTTP Keep-AliveKeep-Alive我查资料发现他设计的初衷就是为客户端后续请求重用连接,如果某次 HTTP 请求-响应模型中,请求的 header定义了
connection:close信息,那不再重用这个连接的时机就只有在服务端了,所以我们在 HTTP 请求-响应这个周期的「末端」关闭连接是合理的
所以以下哪种无论
客户端开启 HTTP Keep-Alive,服务端禁用 HTTP Keep-Alive
客户端禁用 HTTP Keep-Alive,服务端开启 HTTP Keep-Alive
底层机制都会设计成服务端是主动关闭方
所以只要有大量TIME_WAIT状态连接的时候,可以排查是否客户端和服务端都开启了HTTP Keep-Alive,因为任一方没开启都会使得服务端WAIT
2、HTTP长连接超时
Nginx 是一款轻量级、高性能的 Web 服务器和反向代理服务器,有助于理解现代 Web 应用架构。比如 nginx 提供的 keepalive_timeout 参数,keepalive_timeout 秒没收到客户端请求,定时器超时就关闭连接,这时候就会WAIT
一般是有大量客户端建立连接后,没发送数据导致的,排查网络问题,导致发送数据一直没被服务端收到
3、HTTP 长连接的请求数量达到上限
nginx上有 keepalive_requests ,比如A客户端的 keepalive_requests 默认是100,那客户端跟服务端通信100次,服务端就自动关闭这个长连接
QPS是每秒请求数
至此本文中以上所有省略写法“WAIT”,都指的是TIME_WAIT
- 为何服务端大量CLOSE_WAIT(四次握手的东西)
CLOSEWAIT是啥:
TCP服务端流程:
分析可能性:
第一个原因:第2步没做
没有将服务端 socket 注册到 epoll,这样有新连接到来时,服务端没办法感知这个事件,也就无法获取到已连接的 socket,那服务端自然就没机会对 socket 调用 close 函数了。
解释:
这种属于明显的代码逻辑 bug,在前期 read view 阶段就能发现的了。
第三个原因:
第四个原因:





20250418
- 感慨:
之前钻研无微不至,事无巨细面面俱到,心灰意冷
如今看了小林code机械经验帖,不再看无关的任何东西了,都无法写到简历里,太亏了,细致学之前问豆包面试问频率,再把知识点当作可以写在简历里的一个可说点记录到文章最下面
不再灰暗,微信搜“就这?”、“这个”
就是每个都认真,极致的深入思考,细心,好研究钻研,都不知道这个属不属于八股文,反正就是认真的学
- 关于保活机制
- 科普前设知识 - 主机宕机:
不是进程崩溃,进程崩溃后操作系统在回收进程资源的时时,会发送 FIN 报文,而主机宕机则是无法感知的,所以需要 TCP 保活机制来探测对方是不是发生了主机宕机
- 如果客户端宕机了,服务端一直
ESTABLISH状态占用系统资源,需要保活机制探测次数保证TCP连接有效:socket接口设置
SO_KEEPALIVE选项生效保活机制tcp_keepalive_time=7200:7200s即2h依旧没任何连接活动就启动保护机制,
tcp_keepalive_intvl=75:保活机制开启,且每个75ms检测一次
tcp_keepalive_probes=9:检测9次无响应中断本次连接
- 开启保活机制几种情况:
要么有相应正常重置保活时间
要么对端主机宕机重启后,产生RST报文(RST是强制终止当前连接。与通过 FIN 包优雅关闭连接不同,RST 包会立即中断连接,抛弃排队数据,接收方收到 RST 包后会终止连接并提示 “连接被另一端重置” 之类的错误,双方不再维持该连接,后续也不再通过此连接传输数据)
要么没响应直接说TCP连接死亡
保护机制时间是7200+75*9,很长,自己设置
keepalive_timeout心跳注意TCP连接是内核维护的,也由内核回收,开始第一次挥手,后续也不需要进程参与
- 通过这个小林codeing强化之前啃的TCPIP网络编程 Socket编程吧,唉,感觉好亏~~~~(>_<)~~~~
Linux内核维护两个队列
- 半连接队列(SYN 队列):接收到一个 SYN 建立连接请求,处于 SYN_RCVD 状态
全连接队列(Accpet 队列):已完成 TCP 三次握手过程,处于 ESTABLISHED 状态
int listen (int socketfd, int backlog)backlog是accept队列长度,有上限值somaxconn(内核参数)
简单铺垫基本工作逻辑流程:
客户端和服务端在未开始建立连接时都处于初始关闭的CLOSE状态,随后客户端通过
socket、connect(主动打开)服务端通过
socket、bind、listen(被动打开),脱离该状态,逐步完成 TCP 连接的建立流程。为何主动?被动?
主动打开指客户端主动发起连接请求(如调用
connect函数),启动连接流程;被动打开指服务端通过
bind绑定地址端口、listen进入监听后,被动等待客户端连接,通过accept接收请求,自身不主动发起连接,而是等待被连接。
accept发生在三次握手哪一步?
先看图:
客户端close,断开流程?
没有accept可以TCP连接吗?
可以
accpet 系统调用并不参与 TCP 三次握手过程,它只是负责从 TCP 全连接队列取出一个已经建立连接的socket
用户层通过 accpet 系统调用拿到了已经建立连接的 socket,就可以对该 socket 进行读写操作了
在 TCP 通信中,三次握手由操作系统内核负责完成,实现连接建立;
而
accept的作用是让应用层从全连接队列中取出已建立好连接的socket,以便后续读写数据。没有
accept时,内核仍会完成三次握手建立连接(可通过抓包工具观察到),但应用层无法获取对应的socket描述符,也就无法通过该socket进行数据收发操作。简而言之,
accept不参与连接建立过程,仅是应用层获取已建立连接socket的手段,没有它,连接能在内核层面建立,但应用层无法拿到socket进行后续处理。
没有 listen,能建立 TCP 连接吗?
自连接或者客户端A跟B
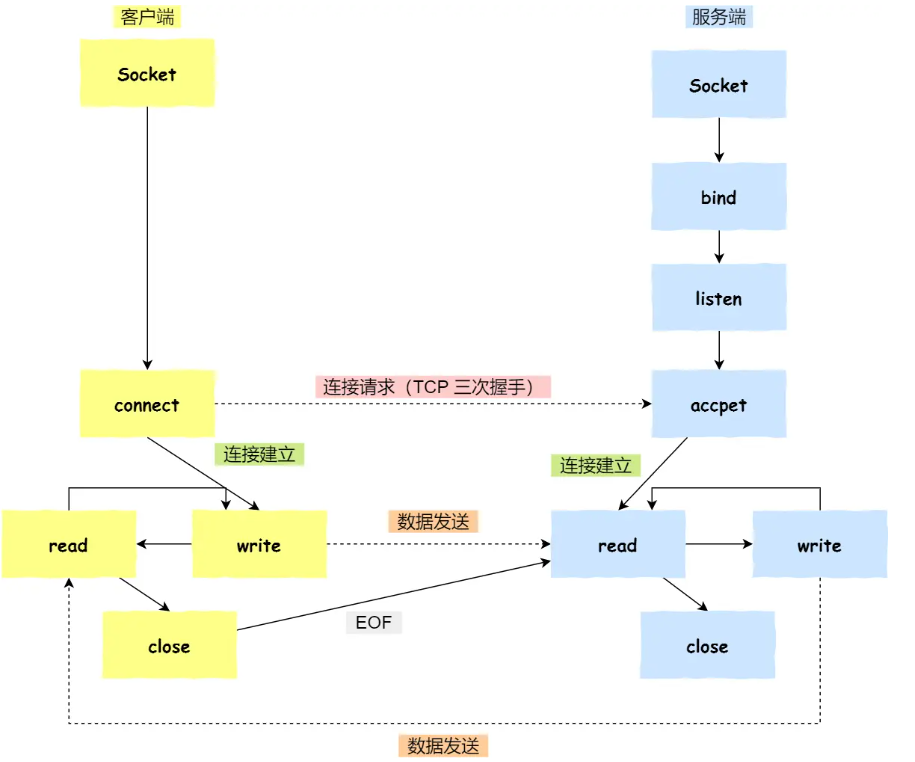

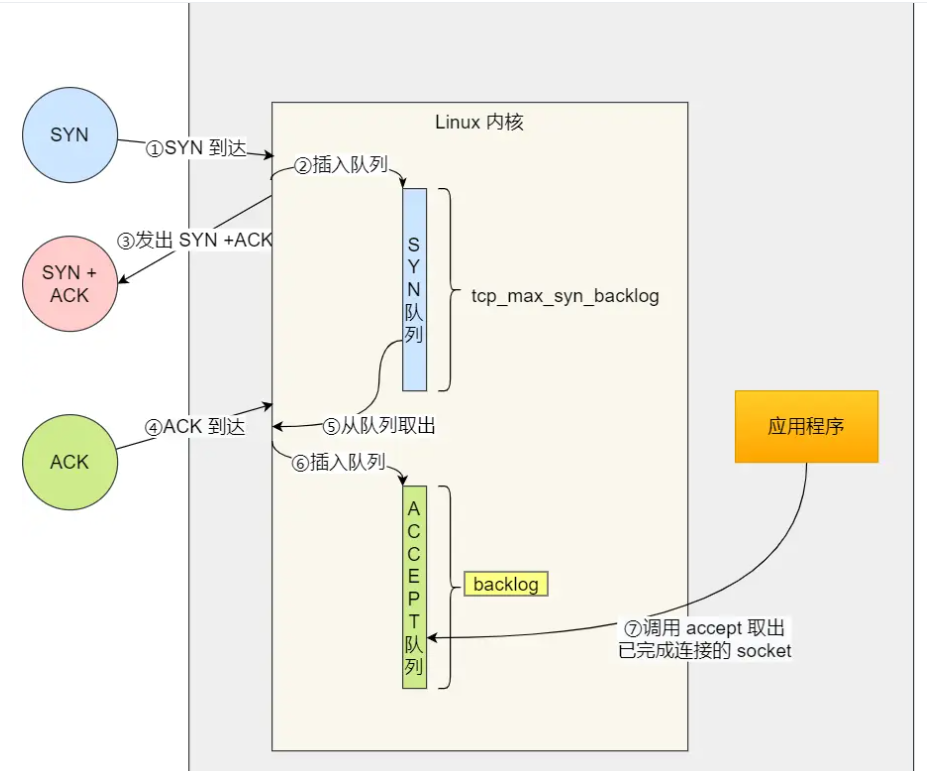
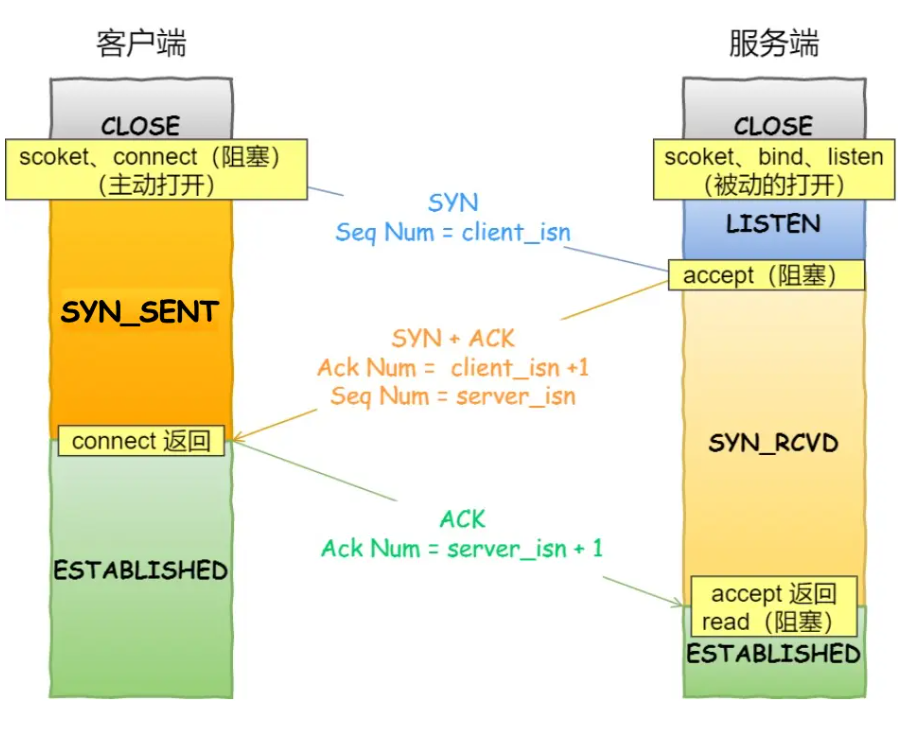

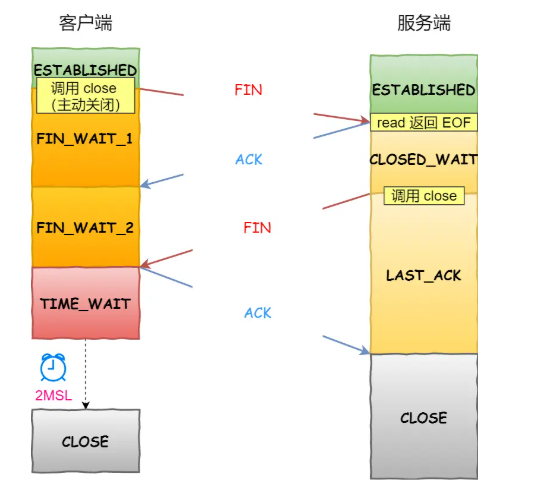

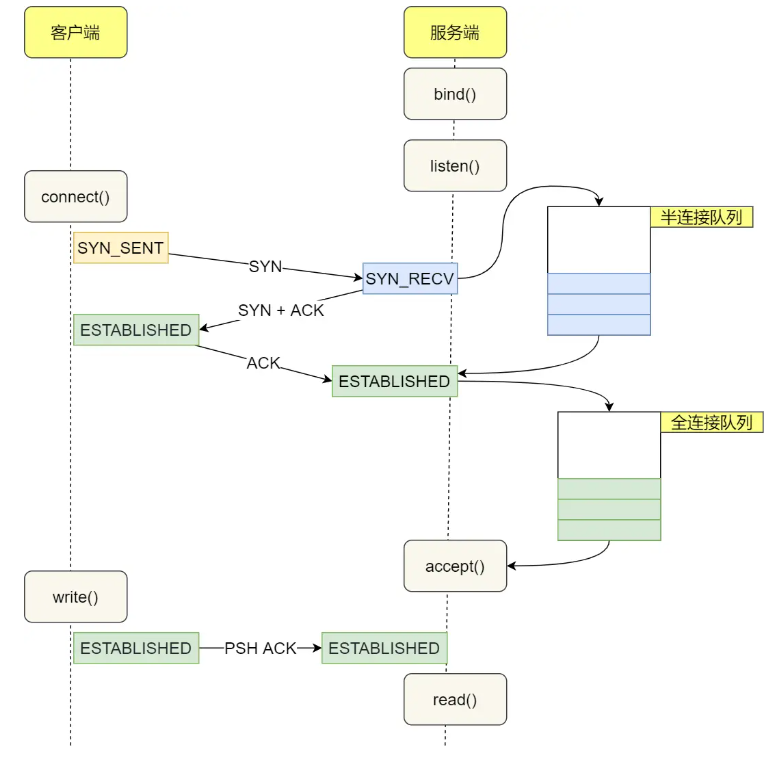
至此TCP4.1结束
TCP4.2
- 重传机制:
- 超时重传,RTT发送到接受到ACK的往返时间,RTO是超时重传时间
RTO过大:丢失老半天才发现,没有效率,性能差;
RTO过小:没必要的重复,增加网络拥塞,导致更多的超时,更多的超时导致更多的重发
所以,精确的测量超时时间
RTO的值是非常重要的,略大于RTT,RTO动态变化的。
如果需要重传说明网络不好,所以有种设计叫超时间隔加倍,本质是一种退避机制。
加倍延长重传间隔可减少重传频率,给网络留出缓冲恢复的时间。
若不加倍,频繁重传既无法解决问题,还会持续占用网络资源,使网络长期无法恢复正常
但这一方式存在不足:超时等待时间可能较长,于是会思考能否有更快捷的方式来处理重传,而非单纯依赖逐渐变长的超时等待。
- 引出快速重传
先科普下,
接收方收到seq1后该收到seq2,即发送ack2,但收到的是seq3此时会重新发送ACK2,而seq3会先存起来,等重传收到seq2后再处理他,收到seq2后该回复的是ack4
所以,快速重传是收到三个相同ACK会在定时器过期前,重新传丢失的报文
那重传所有还是1个?
1个的话如果丢失很多,后面的还得等收到3次再重传
多个的话如果没丢失,就浪费了
- 引出SACK(选择性确认)
头部添加东西,明确收到啥没收到啥
ACK期望收到的,是开
但SACK末尾是没收到的,左闭右开
注:SACK只是有问题时候才发,正常的话只会有ACK
- D-SACK
栗子一:ACK丢包
栗子二:网络延时
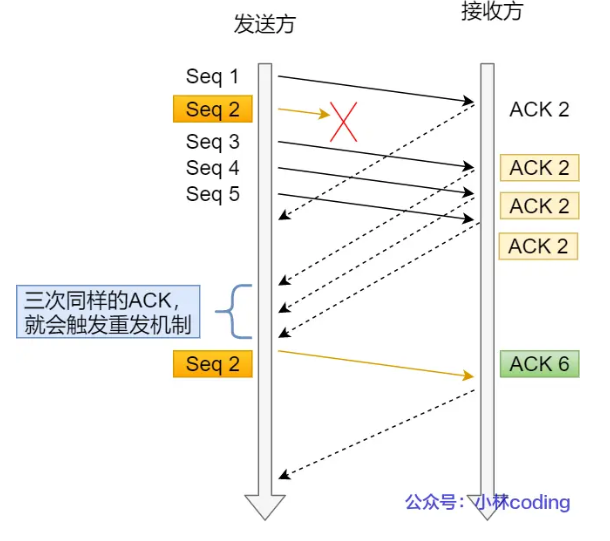
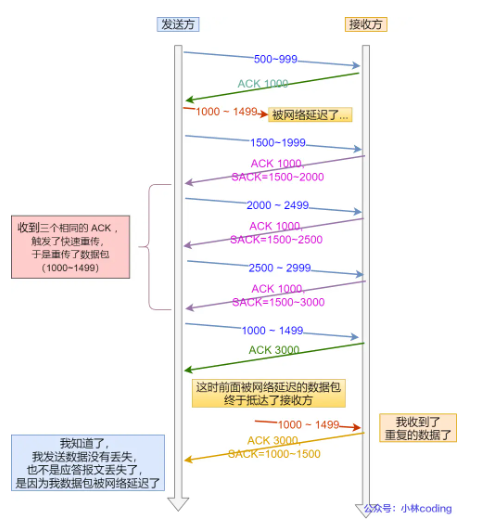

- 滑动窗口
- 概念:
TCP 是每发送一个数据,都要进行一次确认应答。当上一个数据包收到了应答了, 再发送下一个
窗口大小:是os开辟的缓存空间,发送方等待确认之前,在缓存中保留已发送数据,无需等待确认应答,而可以继续发送数据的最大值,收到确认应答活,再删除。
有点像我问开发问题,有时候测试测完了,把问题记录到本上,到时候打电话问开发解决了删除一个问题
至此回忆了啃TCPIP网络编程书的
- 窗口大小谁决定?
接收方
TCP头里 window 字段来定义窗口大小
- 发送方滑动窗口场景
注意:
发送方将数据从应用层缓冲区拷贝到内核缓冲区并发送。当收到接收方的 ACK 时,仅表明接收方已收到该数据,但发送方的应用层可能还未从自己的内核缓冲区中读取这些数据。例如,发送方应用程序调用发送函数后,数据进入内核缓冲区发送,若此时发送方直接删除已发送且收到 ACK 的数据,那么发送方应用层后续将无法从自己的内核缓冲区获取这些数据(如应用层需再次检查或处理已发送数据)
- 程序如何表示这四部分?
需要三个指针(俩绝对指特定序列号、1相对做偏移量)
- 接收方的滑动窗口(图勘误)
注意:“
#1 + #2 是已成功接收并确认的数据” 这里的 “确认” 是指接收方已向发送方发送了 ACK 帧,告知发送方这些数据已被成功接收。发送方收到 ACK 后,才会将对应数据标记为 “已发送并收到 ACK 确认”,差别是#1的ACK到了,#2的ACK 还在传输中
- 接收窗口和发送窗口的大小是相等的吗?
不完全等,只是约等于
如果接收方的应用进程读取数据速度非常快,,那接收窗口很快空出来,新的接收窗口大小是通过TP报文的 Window 字段来告诉发送方,那么这个传输过程是存在时延的

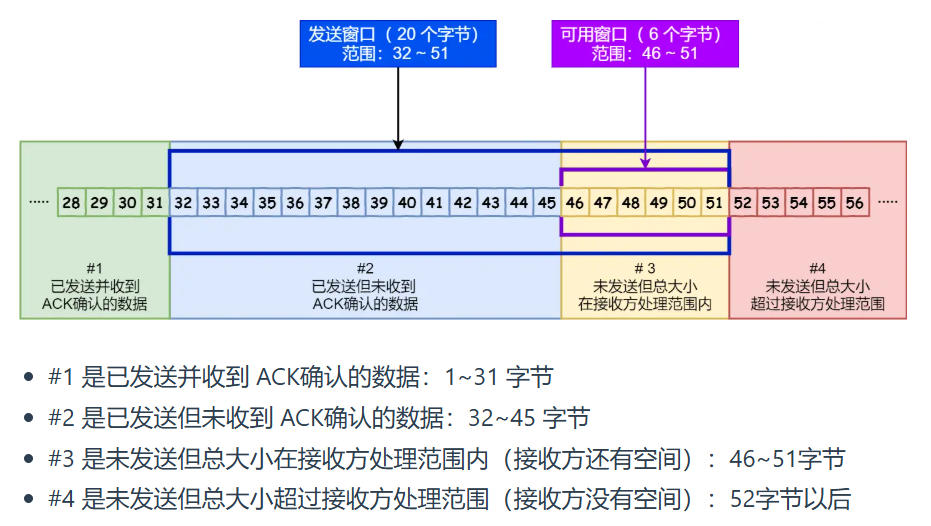
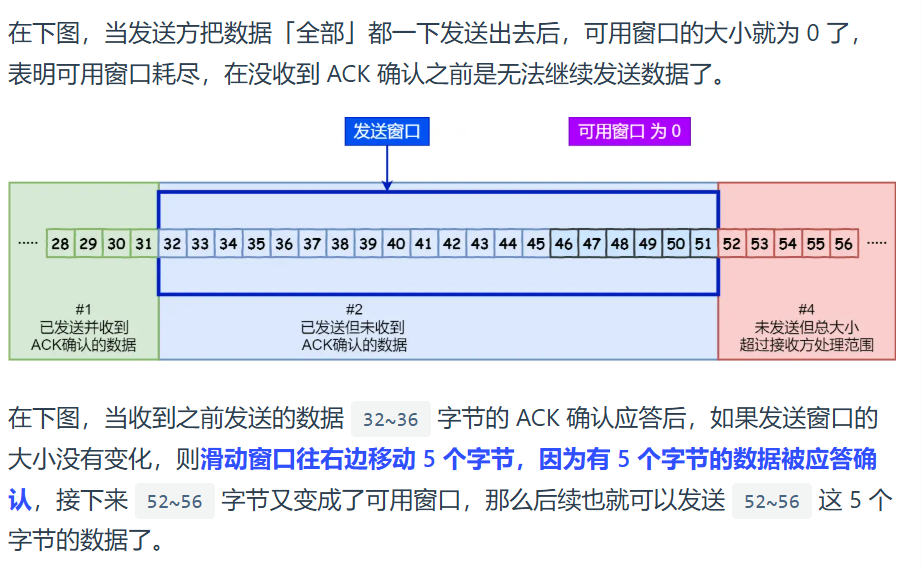
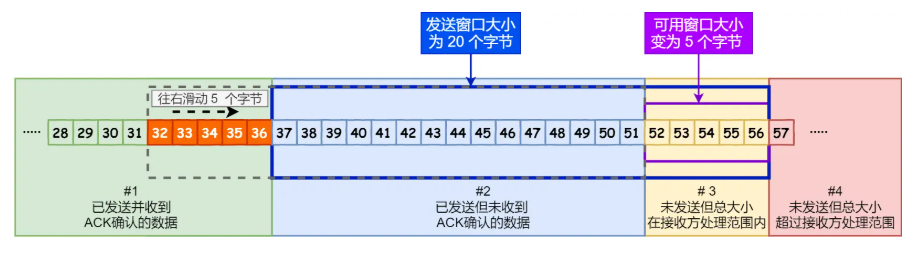
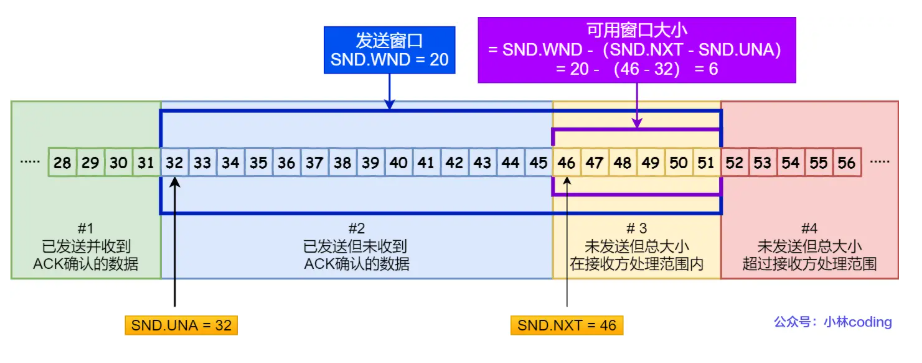


- 说流量控制之前,插几个我自己追问豆包的疑惑点(如今已经明白了)方便理解下面流量控制的流程解说
- 不考虑应用层读取慢时,接收缓冲区可用空间不变,窗口大小固定,仅因按序收数据导致窗口位置右移。
窗口【啥时候移动】:
- 对于接收方:
仅由「按序接收数据」触发(RCV.NXT 后移)。假设读到后立马应用层就可以读走,那按序收数据→RCV.NXT 后移→窗口右移,无需考虑应用层读取,才会动态调整那窗口大小,只要接收方按序收到数据,
RCV.NXT(下一个期望接收的序号)就会后移,带动接收窗口右移,与「应用层是否读取数据」无关!
- 对于发送方:
收到确认ACK后,窗口右移
窗口头始终是SND.NXT代表未发送但可发送的
SND.UNA代表已发送但未确认的第一个字节序号
由接收方缓冲区的可用空间(
usable)决定,受应用层读取速度影响(图中若未体现应用层,可默认假设缓冲区空间足够,窗口大小固定,仅位置移动)
- 流量控制
- 概念:
虽然有重发,但这只是一个辅助,就像自动驾驶,而真正要做的还是人去开车,这里人去开车就是流量控制,即你不能无脑不停发,靠重传去管制、保证这些数据。浪费网络流量
- 流程解说:
看这个图先看双方的互动,窗口移动,先别看什么ACK、seq、SND.NXT 这些数据细节,先关窗口为啥这样移动和可用窗口大小
20250419
- 操作系统缓冲区与滑动窗口的关系
场景一:
场景二:
- 窗口关闭:
窗口大小为0就阻止发送方发送数据
但有弊端:
- 解决窗口关闭的死锁
TCP为每个连接设个持续定时器,只要一方收到对方的零窗口通知,就启动持续计时器,超时发送窗口探测报文,对方确认此报文时给出现在接收大小。打破死锁局面,如果还是0就重启启动持续计时器,一般是3次每次30s,还0就RST中断
- 糊涂窗口综合症 (勘误计算错误,80/53/26,40w粉丝这都发现不了?读取1/3后不是26应该是27)
- 接收方策略:
- 发送方策略:
解释代码前说几个前设知识:
MSS(最大段长):
一个
TCP数据段能携带的最大应用层数据量(不含TCP头),发送方尽量按MSS大小发送数据,以降低TCP头占比(如MSS为 1460 字节时,20 字节的头占比约 1.37%;若发 100 字节,头占比达 20%)窗口 < MSS 或数据 < MSS:
表示当前无法组成一个
MSS大小的数据块存在未确认的数据:
说明发送方已有数据发出但未收到ACK。若继续发送小数据,会进一步产生小数据段,浪费网络带宽(每个小数据段都有固定的头部开销)至此大概可以理解:
如果窗口 < MSS 或数据 < MSS:
就说明不是大数据块就等待,积攒数据块大小
进入判断,如果有未确认的说明没达到满窗口,等待ACK后窗口可以右移,即可以扩大发送空间,积攒大数据块就可以发送了,
那如果没未确认的,那直接发(看似理论上应该是积攒满了窗口内存大小再发,但其实是立马发这个,发送方需等待该数据的 ACK 才能继续发送后续数据,不会在网络中持续产生多个小数据段,且保证实时性:若强制要求小数据也等待凑满 MSS 再发送,会导致不必要的延迟,如交互式场景中用户输入无法及时传输。立刻发送小数据可确保这类场景的响应速度,提升用户体验)
感觉这块像并查集路径压缩一样,会形成条件反射被代码
但注意:
不通告指的是 min( MSS,缓存空间/2 ) ,代码里只要没未确认就会发送,所以还是会有小数据,所以要接受方也做个通告设置,但如果把这个通告写在发送方的else里面也不行,解释:
各司其职:接收方主动控制窗口通告(避免发小窗口),发送方通过 Nagle 算法响应窗口信息(优化小数据发送)
不同接收方的缓存管理和窗口通告策略可能不同,发送方无法预知接收方的具体策略。若发送方统一采用除以 2 的方式,可能与部分接收方的实际处理逻辑冲突(如接收方有其他窗口控制机制),反而影响传输效率或可靠性。


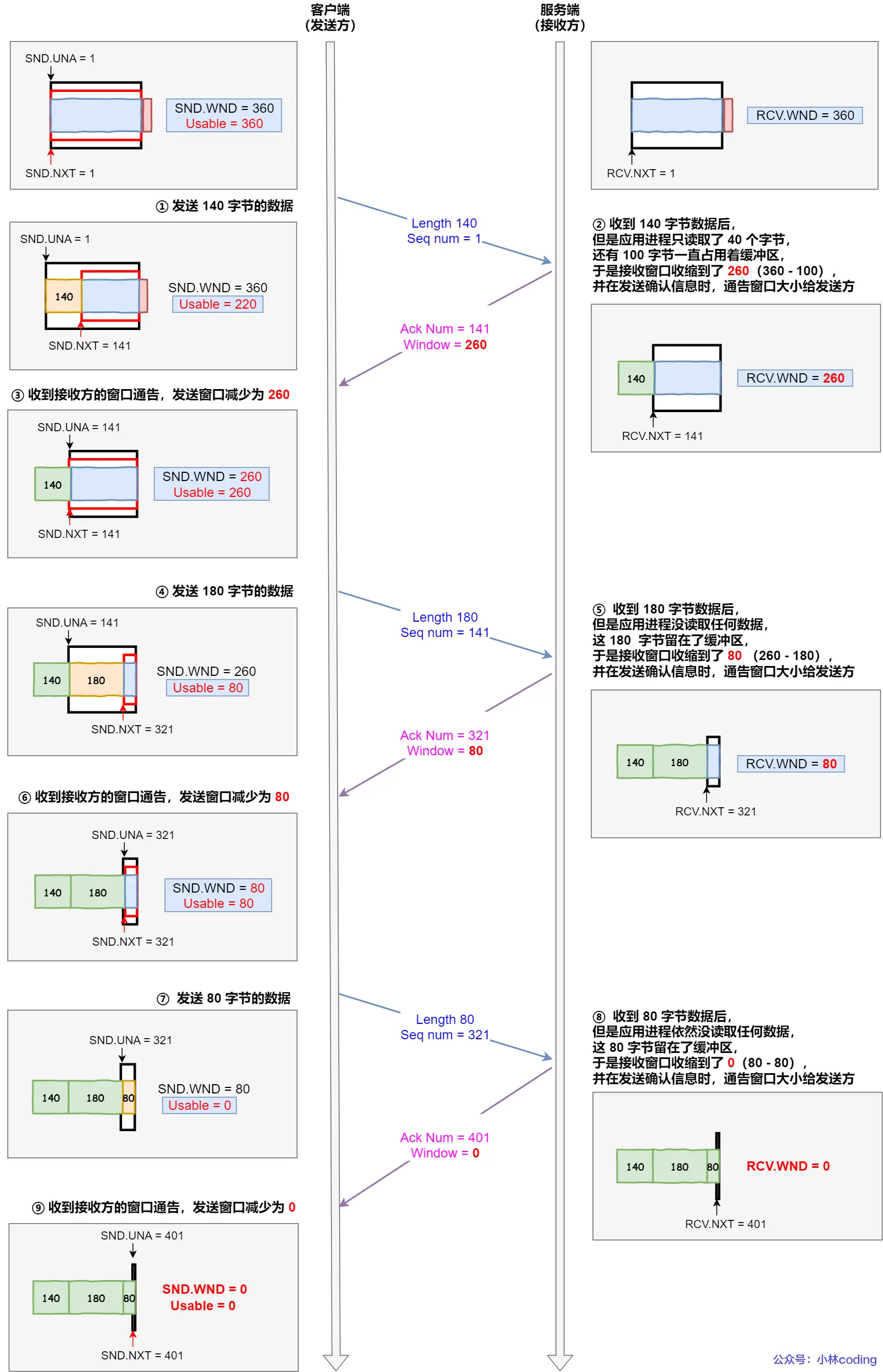

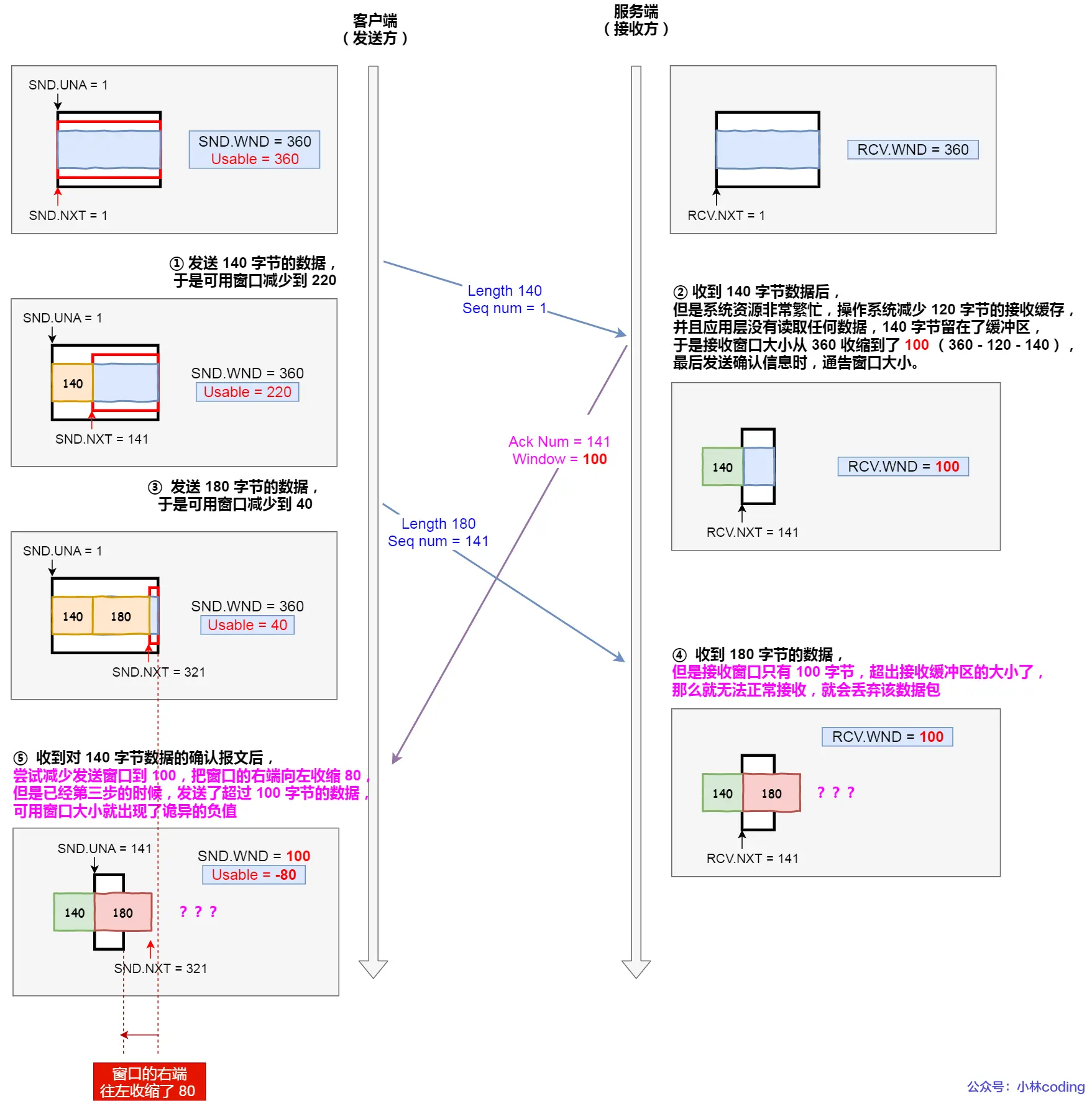

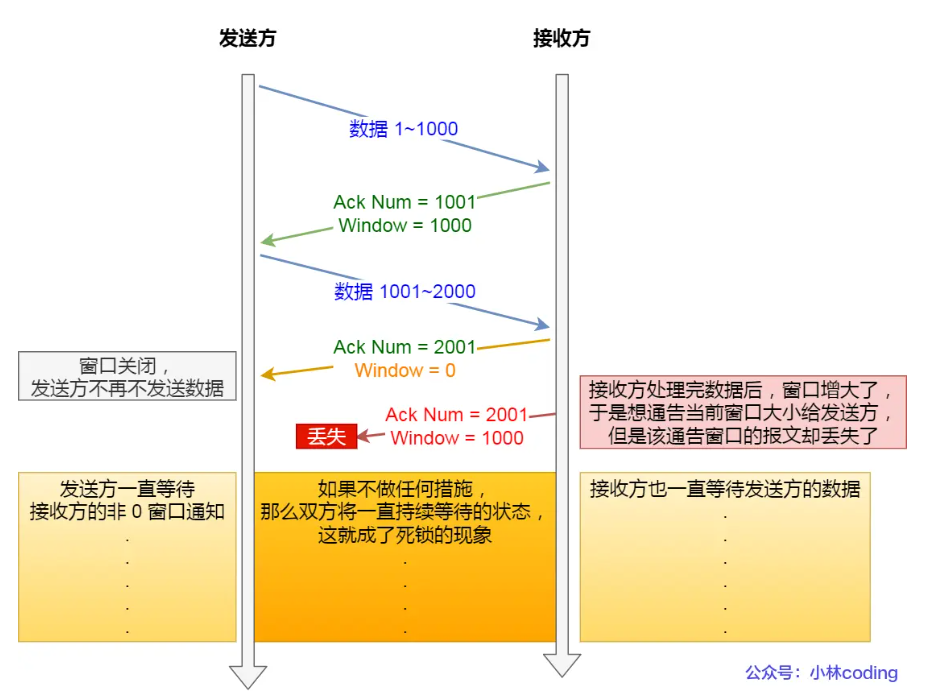

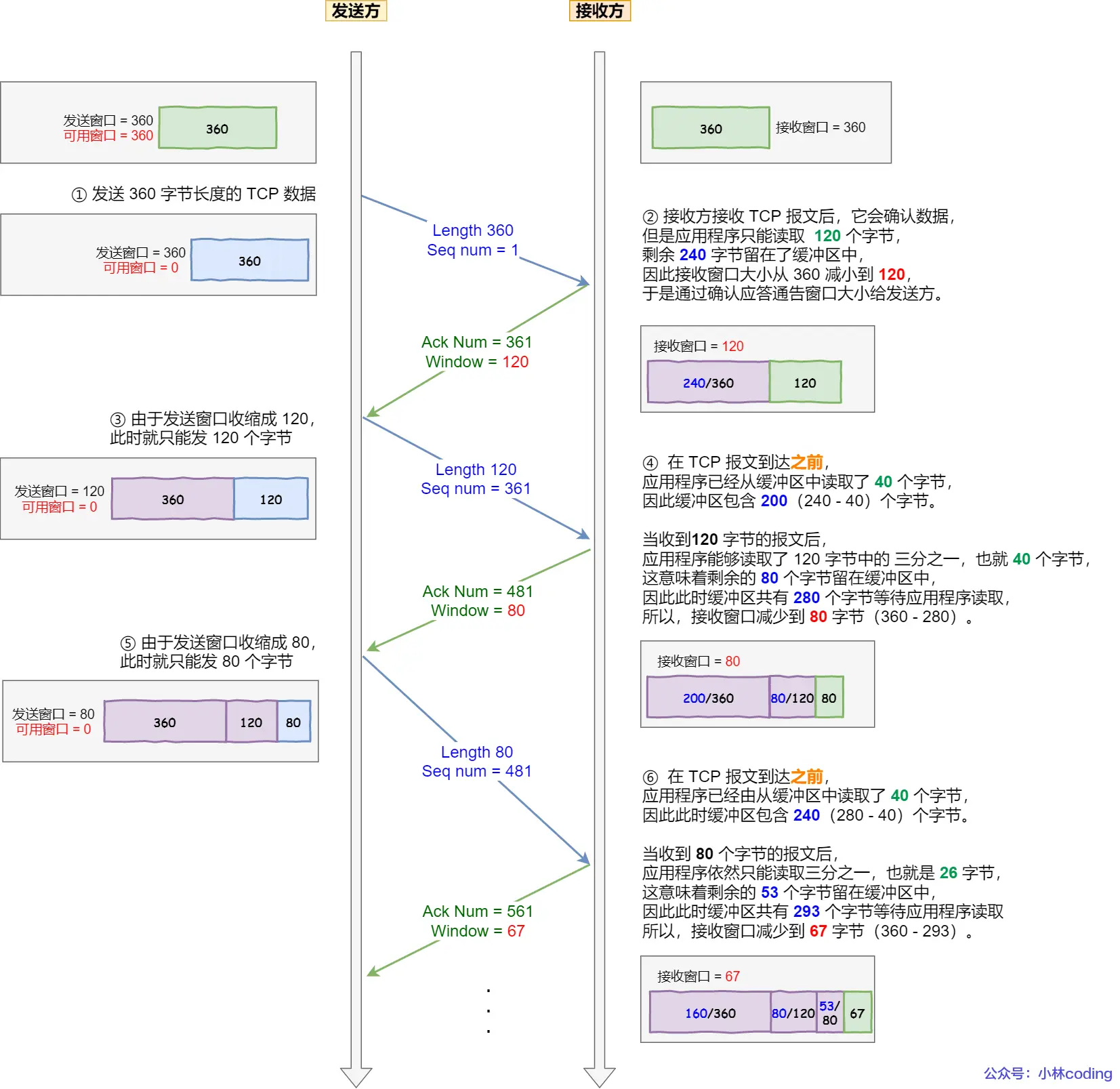



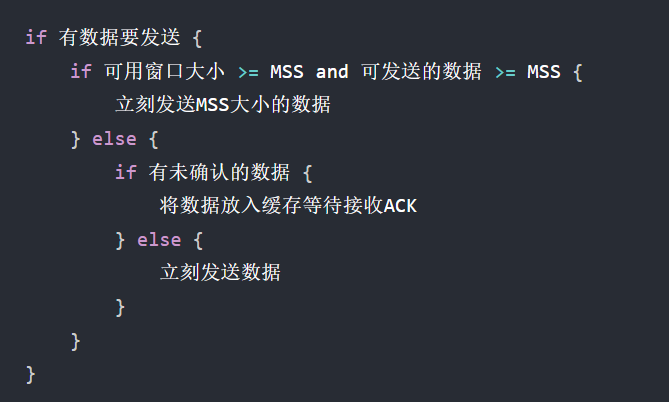

20250420
- 拥塞控制
意义:
流量控制的核心目的是让发送方发送速率与接收方处理能力匹配。若发送方持续高速发送,而接收方处理慢,接收方缓存会被数据填满。一旦缓存满,后续到达的数据会被丢弃,导致传输失败
引出拥塞窗口cwnd,发送方维护的一个状态量
与流量控制的区别
之前:发送窗口swnd ≈ 接收窗口rwnd,
现在:发送窗口swnd = min(接收窗口rwnd,拥塞窗口cwnd)
只要规定时间没收到ACK应答,超时重传,认为发生了拥塞,cwnd就减少,否则就增大
拥塞控制4种算法:
- 算法1:慢启动
收到一个ACK,cwnd就加1
啥时候是个头,ssthresh大小65535字节
- 算法2:拥塞避免
收到ssthresh个ACK就每个不再加1,而是加1/cwnd,总共cwnd个,就是1,线性了
此时慢慢进入拥塞,出现丢包就会重传,即触发进入拥塞发生
- 算法3:拥塞发生
发生拥塞 = 发送重传
此时讲的重传暗示网络拥塞,需调整拥塞控制参数(如
ssthresh、cwnd)之前说的重传从数据可靠传输角度,解决数据 / ACK 丢失问题,确保接收方正确接收
处理逻辑:
发生拥塞,触发超时重传或者快速重传,然后进入拥塞发生算法
发生重传有超时和快速
超时重传:
ssthresh设为cwnd/2( ss -nli查看cwnd)
cwnd重置为1(是恢复为 cwnd 初始化值)但慢启动太突然,就像最后几下库库导管子然后立马降低速度就很难受(非想寸止),简称激进重置,所以,为了解决这个问题,引出快速重传
快速重传:
先放图吧,慢慢解释,因为单看图会觉得有很多反常理的悖论地方
先说下我起初没搞懂时候认为的悖论点(现在懂了)
- 累计的3个重复ACK早在之前的就已经每次都+1了,为何最后又+个3
解惑:
触发快速重传时的「加 3」和平时单个重复 ACK 的「加 1」是两个不同机制下的操作,更直白说,+3是/2降低阈值后才+的3,比如:
平时的「加 1」是逐个试探:假设初始
cwnd=12,收到第 1 个重复 ACK 时cwnd=13,第 2 个时cwnd=14,第 3 个时cwnd=15快速恢复的「加 3」是重置后调整:快速恢复阶段会先将
cwnd设为ssthresh(比如ssthresh=6),然后 额外加 3(因为 3 个重复 ACK 证明有 3 个包已成功,对应 3 个 MSS 的可用带宽),最终cwnd=6+3=9(而非基于之前的 15 继续加)
- 当收到重复的时候,跟之前收到正常的时候一样,依据是旧继续+1
是的
- 收重复的时候依旧是+1,可收到正确的时候反而直接从12到6了(正确的错误的都混在一起,处理方法都一样,且正确的反而弄少,收到重复错误反而不停的+1,这啥JB玩意啊)
- 那重传后继续重复不是代表依旧不行吗?再加cwnd这就依旧会堵塞啊
整体流程:
慢启动、拥塞避免、快速重传、快速恢复)是 根据拥塞事件(超时 vs 重复 ACK)触发不同流程
细节:
ssthresh = cwnd / 2,cwnd重置为 1(或 1 个 MSS,进入慢启动)快速重传 + 快速恢复:
解惑:
- 当收到新 ACK(非重复),说明丢失的包已被重传并成功接收,此时网络可能仍处于轻度拥塞(否则不会丢包)。
- 将
cwnd重置为ssthresh(如从 9→6),是为了让窗口回到一个 “安全阈值”,后续通过线性增长(每次 + 1)逐步试探,避免直接回到丢包前的高水位(12)导致再次拥塞。- 不是 “弄少”,而是 “控速”:用降低起点的方式,防止窗口过大引发新的丢包。
比如:
至此理解了,小林coding那个图,太多没说清楚的了(我发现无论是小林coding,还是王钰涵对于并发并行,和那次的acm简单的那个,还是代码随想录傻逼标题《讲不好就得认》DP纯自欺欺人,进大厂也只是指方法而已,具体理解啥样真的纯纯投机取巧而已,没啥那么牛逼的真本事)那个TIP1、2、3,解释的真的很扯淡,下面的蓝色更是驴唇不对马嘴了,说明他根本不懂这个,要么帖的某本书的东西,要么背的答案,就这也能搞培训班进大厂?
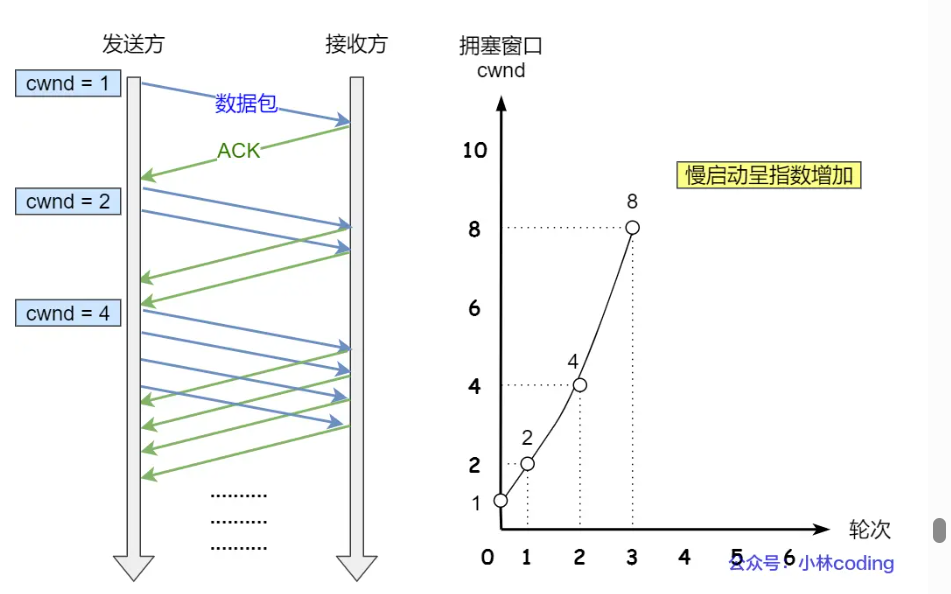

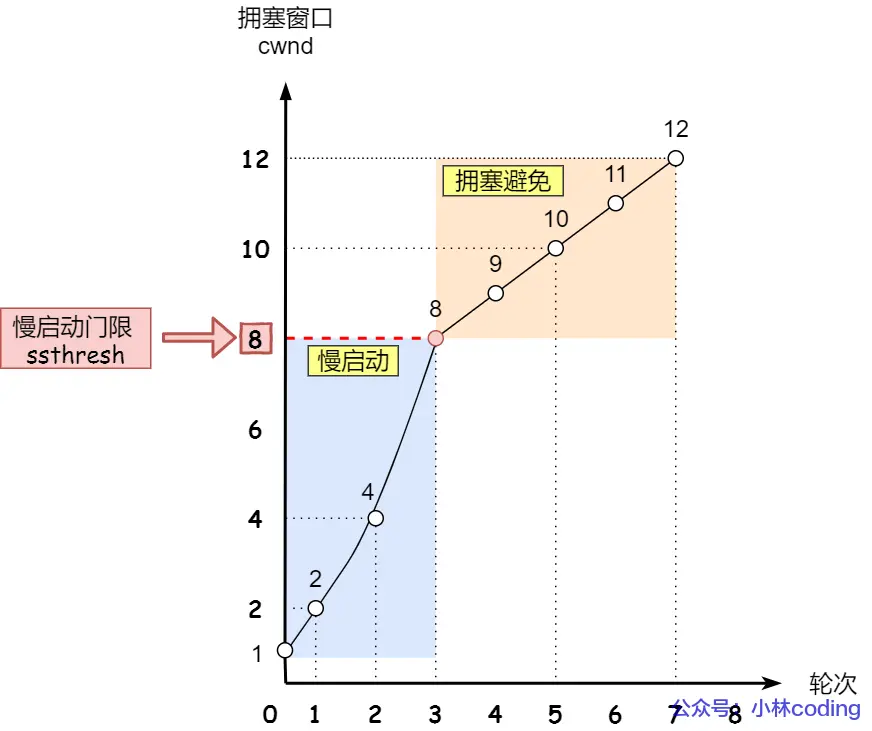
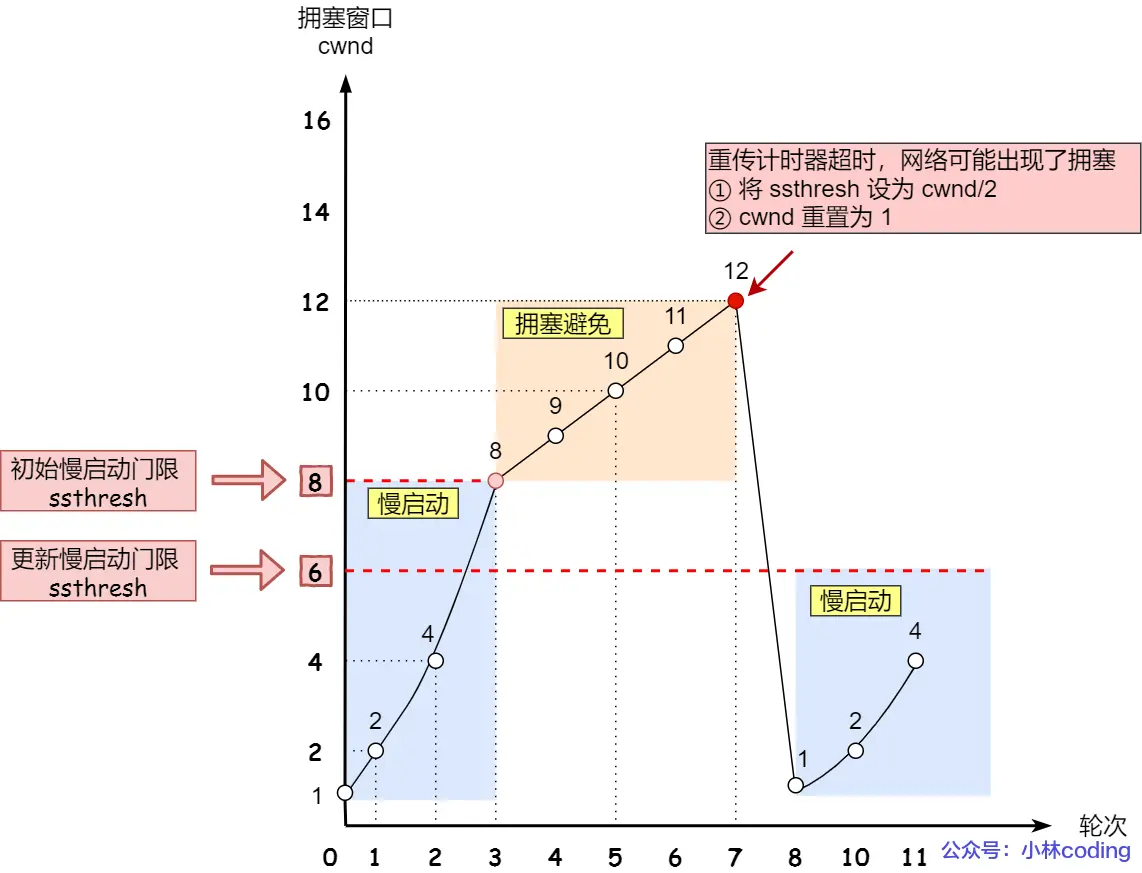
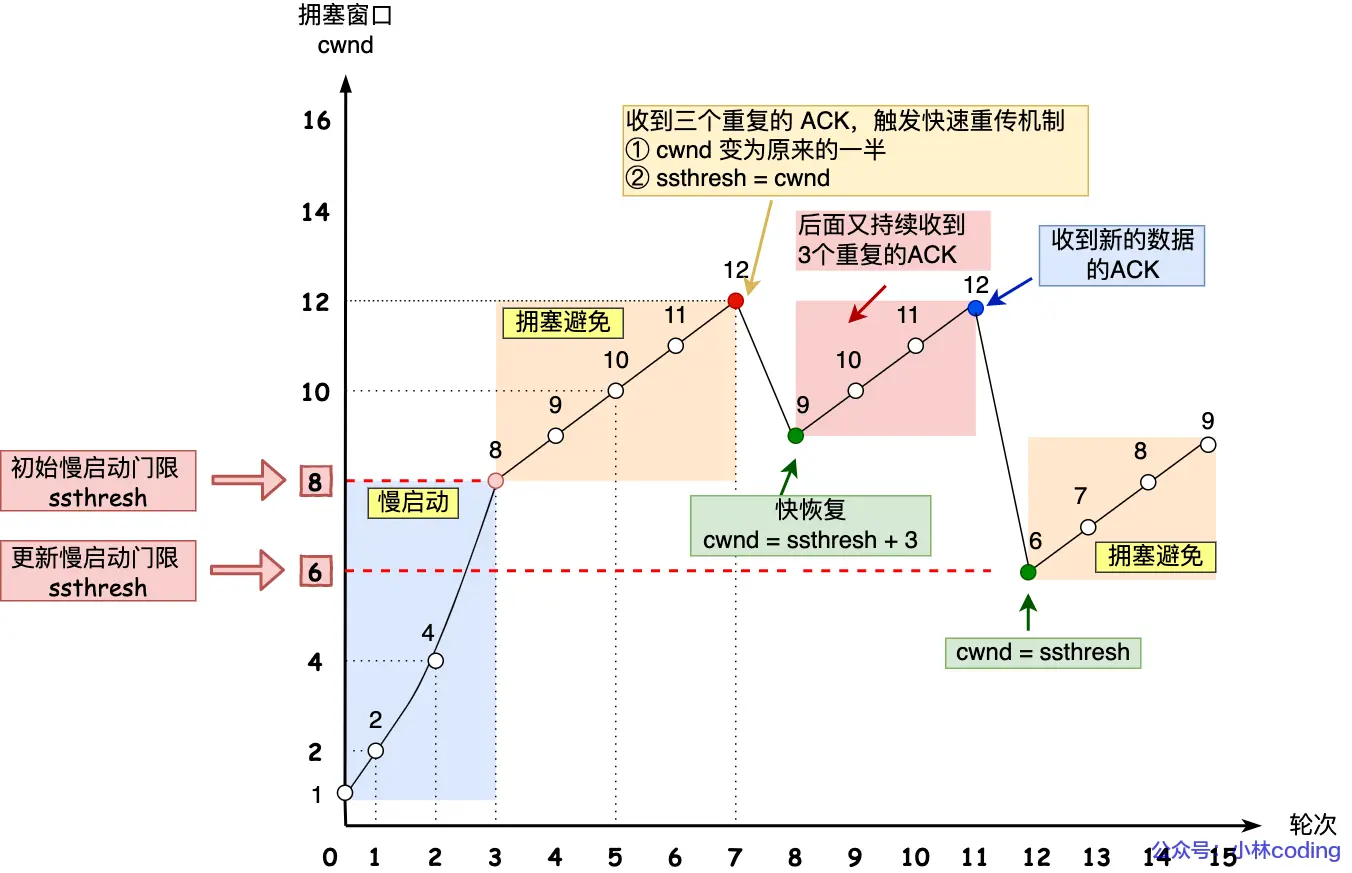
- 收获:
4.3、4.4都不想看了,扫了一眼后面都不想看了
知道哪些该看哪些不该看,哪些放弃,不该细致研究,一大收获,这些是到时候遇到问题来学补漏的,不是现在用来填补空白的
-------------------------------------------------------------------------
IP篇
20250422
- 基本概念:(优缺点)
一个设备有几个网卡,就配置了几个IP 好奇车牌号也会远远不够
点分十进制,32位二进制,所以232=43亿,但有网络地址&主机地址两部分,所以实际能连接到网络的计算机个数就更少了
但通过NAT(网络地址转换)技术,多台设备可共享一个公网 IP 地址(内部用私有 IP,访问外网时转换),缓解地址不足,同时,新一代 IPv6 协议采用 128 位地址,理论地址数量达 2128,近乎无限
黄色的叫分类号
D类的前四位1110表示多播地址,而剩下的 28 位是多播的组编号
C类最大28-2=254个主机个数
全1广播
全0指定
本地广播:本地网络内的
直接广播:不同网络间的,但默认受限制,因为会不安全,所以引出多播
D、E类地址么主机号
多播(即组播):可使数据包从源端同时发送给多个目标接收者,相比单播(一对一)更高效,相比广播(一对所有)更精准
便于理解
但IP分类缺点
缺点一:没层次,
缺点二:就是不能很好的与现实网络匹配
B类6万个
C类254个,既少又多引出CIDR
注意:以上讲的IP也就是有分类地址的概念,下面要说的针对性改进就CIDR,就是不用分类地址这个概念
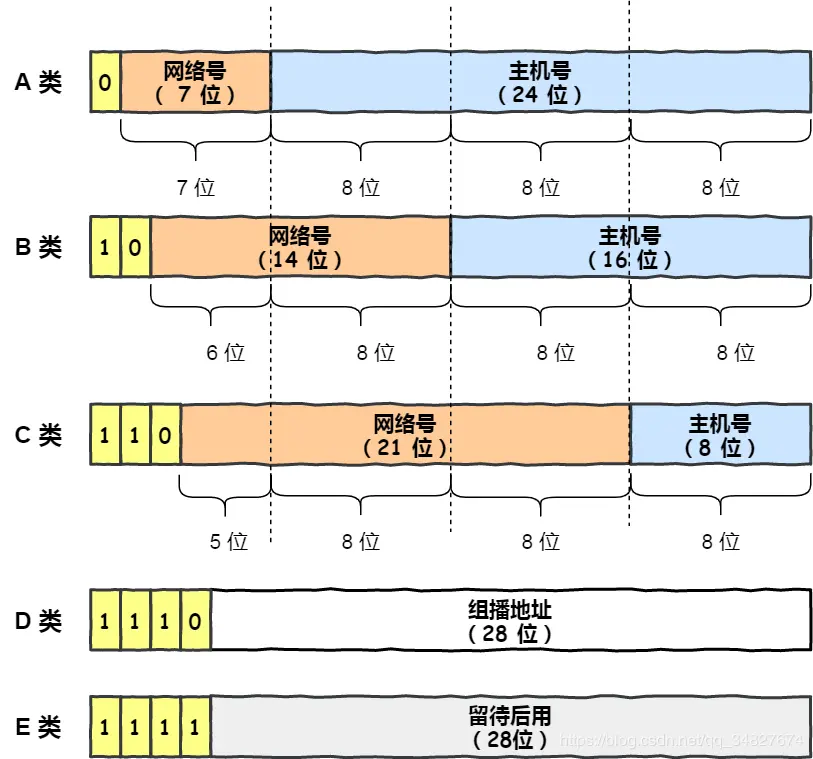


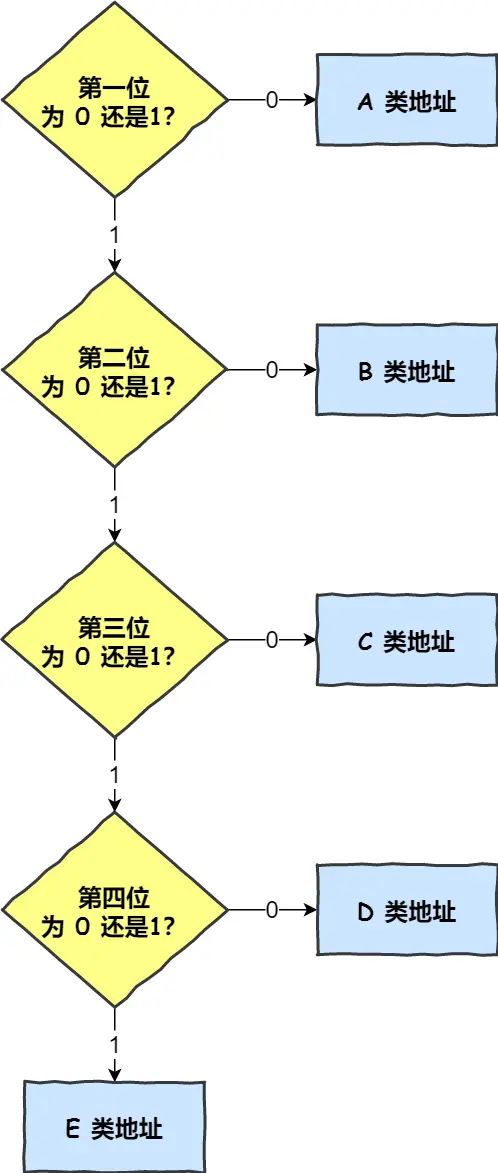

- 悔恨梦魇:
哎,真的浪费了好多时间,网上大把的好资源,被乌烟瘴气的互联网就业环境搞得直接不看所有,直接自己闭关读书,就像有线代工具不用,从原始石器时代开始自己一路摸索到现代社会,无数的本事优点,没法写到简历里。
后悔精读啃书TCPIP网络编程尹圣雨,后悔钻研算法题,后悔看误人子弟的菜鸟教程,后悔无头苍蝇追问刁钻犄角旮旯的各种没意义的问题~~~~(>_<)~~~~
- CIDR
CIDR前缀表示形式:
a.b.c.d/x,其中 /x 表示前 x 位属于网络号,范围0 ~ 32,使得 IP 地址更加具有灵活性
通过点分十进制数(如 \(255.255.255.0\)),用 “1” 覆盖网络号部分,“0” 覆盖主机号部分。



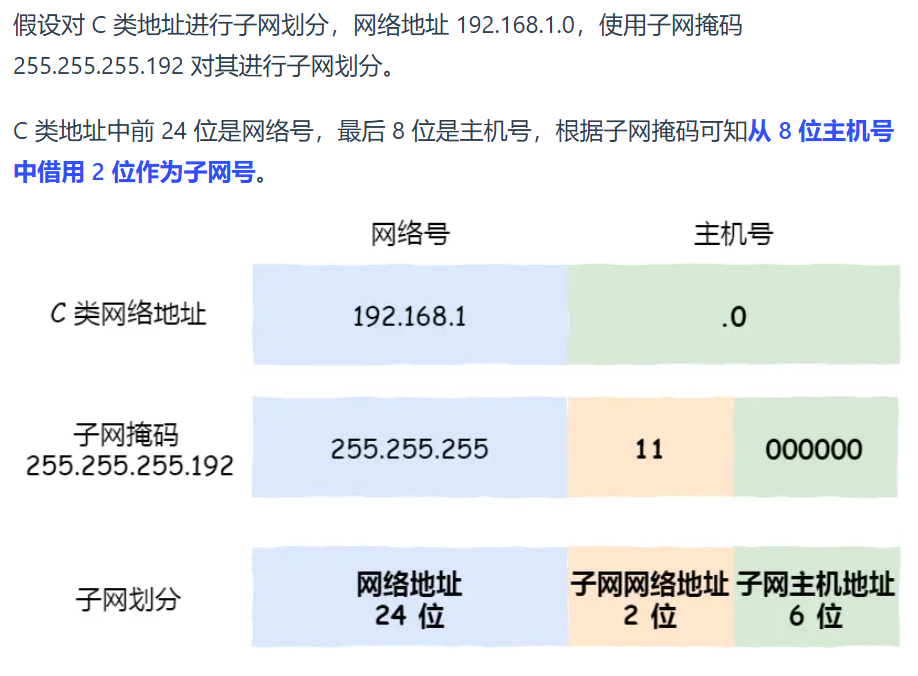

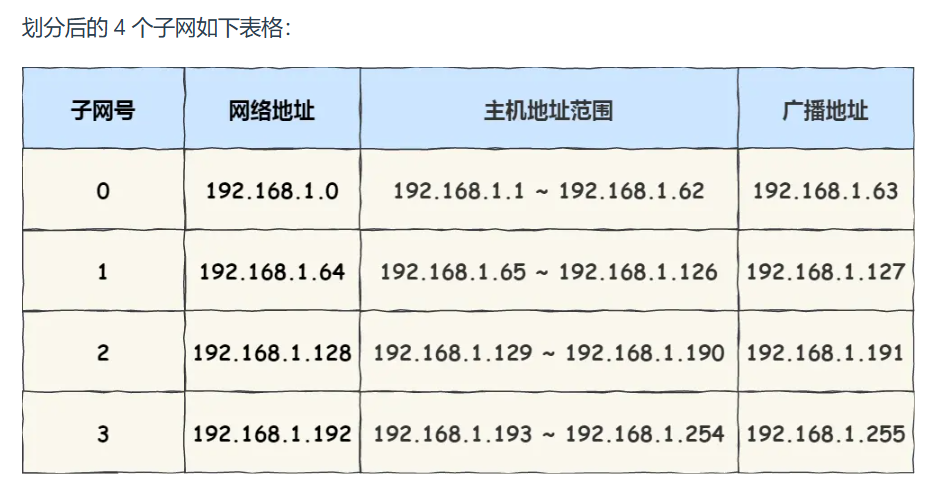
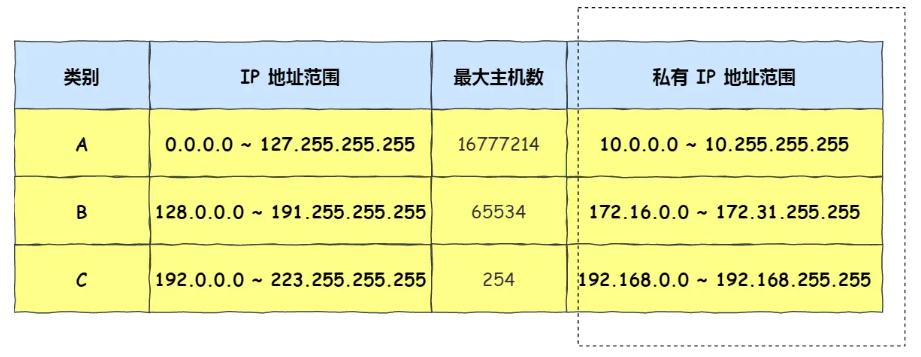 比如:家里路由器给手机分配的 IP 是
比如:家里路由器给手机分配的 IP 是
- IP地址与路由控制
细节:
10.1.1.0/24 是 网络地址,其中 “/24” 表示前 24 位为网络号
10.1.1.30 是该网络中的一个主机 IP 地址,二者属于 同一网络
10.1.1.0/24 代表整个网络范围(可用主机地址为 10.1.1.1 - 10.1.1.254),10.1.1.30 是这个范围内的一个具体主机地址
主机A的路由表:
在图中,
10.1.1.0/24代表一个网络,主机A的IP是10.1.1.30,此路由表项表示:当主机A与10.1.1.0/24网络内的目标通信时,“下一跳” 为10.1.1.30(即主机A自身),意味着在同一网络内,主机A可直接向该网络内的目标发送数据,无需经额外路由设备中转
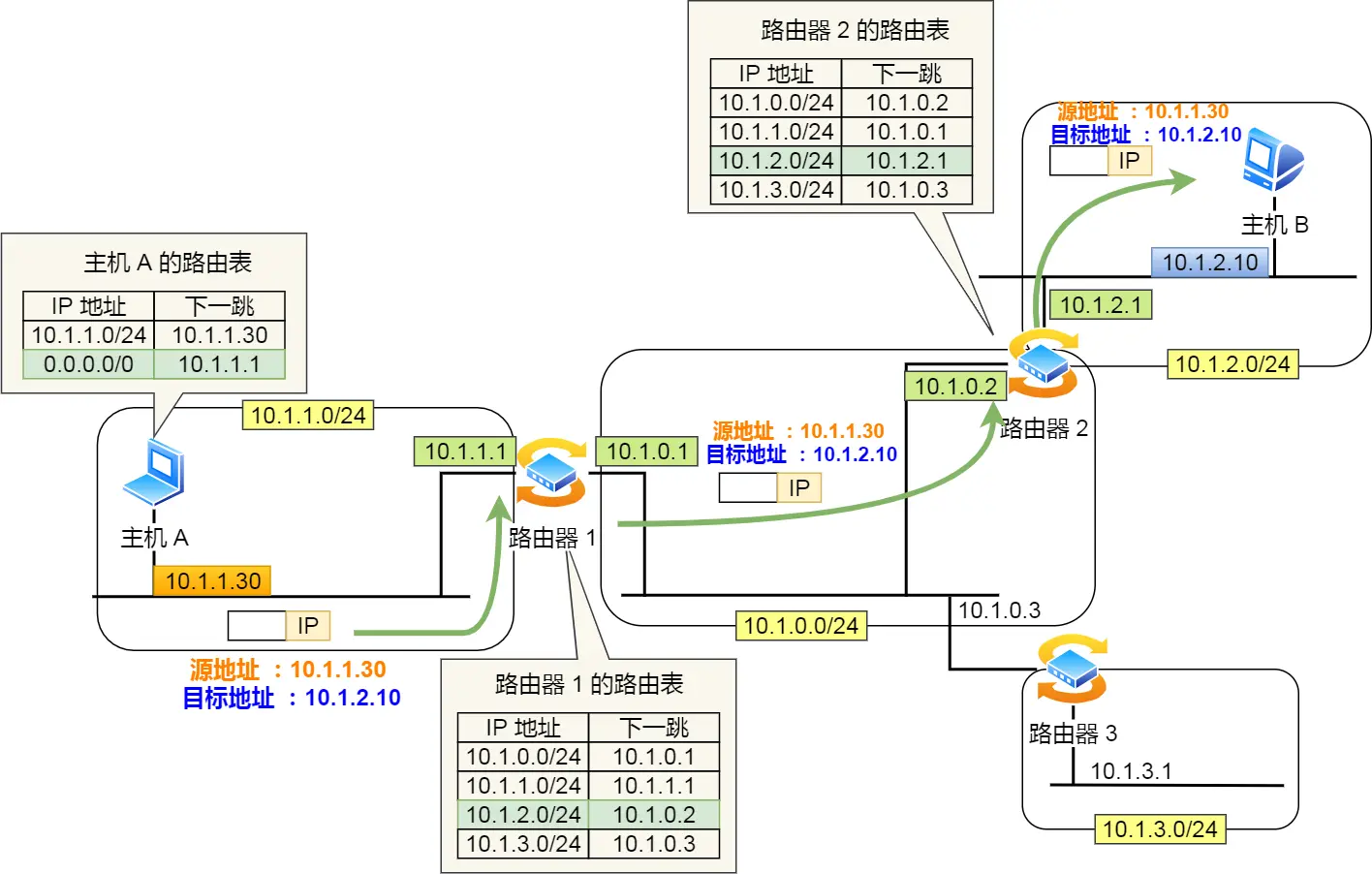
- 分片
IP数据包大于MTU分片,但会导致重传所有,所以TCP的MSS分片
细节:
P 层本身没有超时重传机制,当 IP 数据报分片后,只要有一个分片丢失,由于 IP 层无法单独重传某个分片,且若分片由中间路由器处理,起始端系统不清楚分片细节,只能依赖更高层(如 TCP)重传。而 TCP 重传时,无法精准知道哪个分片丢失,只能重传整个 IP 数据报对应的高层数据,导致所有分片都需重传
UDP 本身没有类似 TCP 的机制来处理分片丢失后的重传等情况。若 UDP 数据报文大于 MTU(最大传输单元),会在 IP 层进行分片,一旦某个分片丢失,整个 IP 数据报会被丢弃,且 UDP 不会重传,从而导致数据丢失。因此,为避免这种情况,对于 UDP 尽量不要发送大于 MTU 的数据报文,这样的表述是正确的
注意:不仅传输层和网络层分片
一个数据报从 MTU 大的链路到 MTU 小的链路,经过路由器时,若数据报超过出口 MTU,路由器就分片。前一个链路 MTU 大,报文能通过,经过路由器到以太网(MTU 1500),若报文大,路由器就分片。
不同链路 MTU 不一致时,路由器 R1 接收到的 IP 分组超过 R1 到 R2 链路的 MTU,就分片
- IPv6
注意:IPv4和IPv6不兼容
感觉目前来说没必要看着玩意,纯纯找罪受
链路:
链路可理解为接口层中 两个相邻网络节点(如两台电脑、电脑与路由器)之间的物理或逻辑连接通道。
两台电脑用网线直连,这条网线就构成一条链路;
手机通过 Wi-Fi 连接到无线路由器,这一无线连接也是链路
在接口层,数据帧通过链路在相邻设备间传输,它是数据在邻近设备间移动的 “路径”,如同一条供数据帧通行的 “道路
IPv6单播地址类型:
头部:没啥想看的贴个图
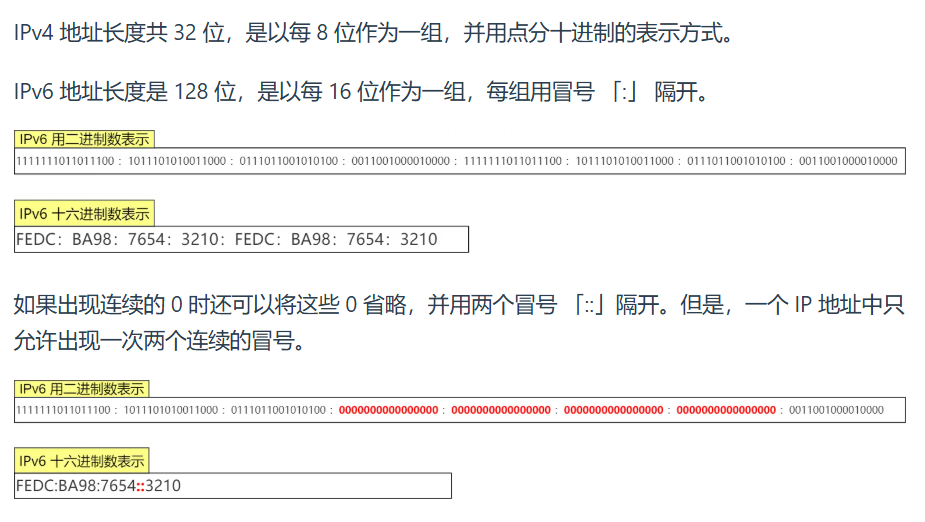

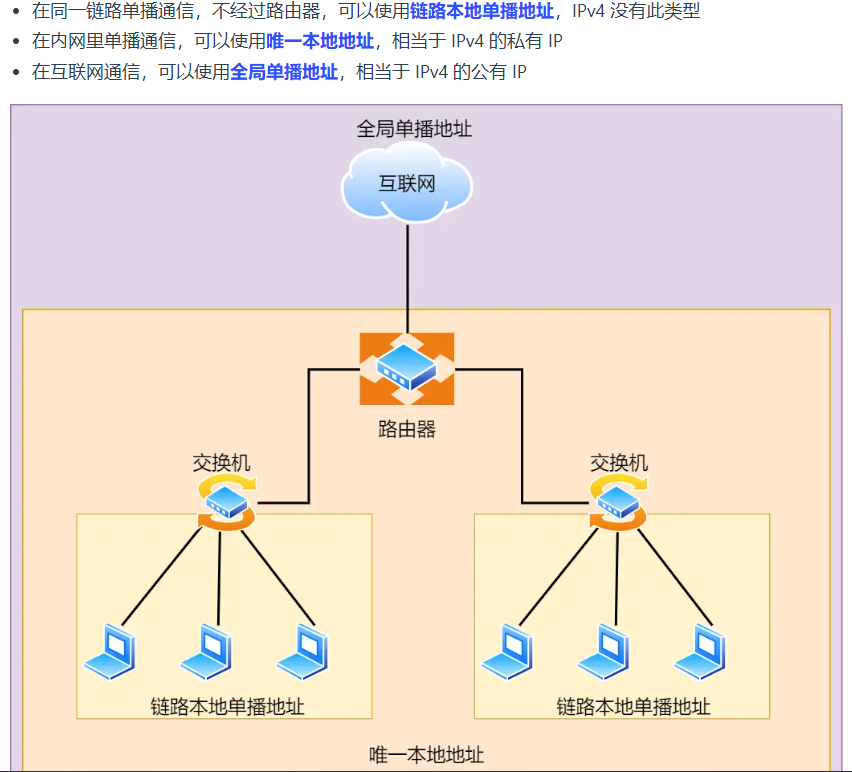
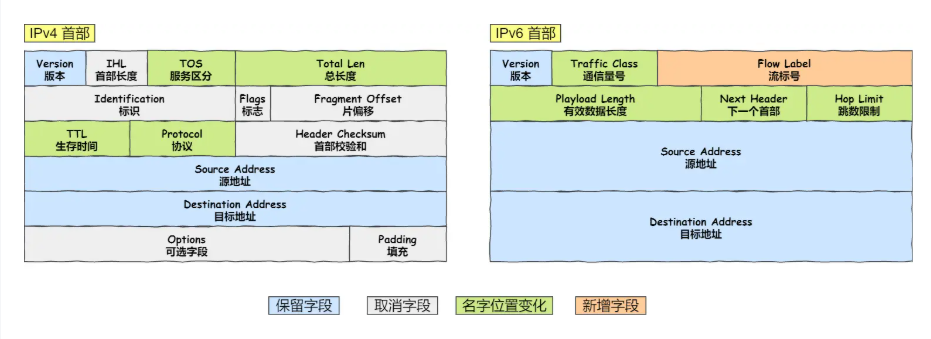

- IP 协议相关技术
- DNS域名解析
ARP
获得下一跳的MAC地址
RARP
已知MAC求IP,主机和RARP服务器的请求和相应
- DHCP
电脑都是DHCP动态获取IP地址
客户端进程监听68
服务端进程监听67
步骤:
全程用UDP广播,那如果 DHCP 服务器和客户端不是在同一个局域网内,路由器又不会转发广播包,那不是每个网络都要配一个 DHCP 服务器?
为此,出现DHCP中继代理,对不同网段的 IP 地址分配也可以由一个 DHCP 服务器统一进行管理。
- NAT
CIDR按需分配地址块,减少地址浪费;
同时利用路由聚合减少路由表项,提高地址分配与使用效率
再次之上,用IP地址+端口,网络地址与端口转换 NAPT来实现
缺点:
解决办法:
1.ipv6
2.NAT 穿透技术:就是客户端主动从 NAT 设备获取公有 IP 地址,然后自己建立端口映射条目,然后用这个条目对外通信,就不需要 NAT 设备来进行转换了
- ICMP
在哪:
封装在IP包里
ICMP 包头类型字段分两类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」
- 另一类是通知出错原因的错误消息,也就是「差错报文类型
A的ICMP到B,B收到A的回送请求(类型是8)ICMP报文,B主机的操作系统协议栈发现是个回送请求的ICMP报文,那么协议栈会组装一个回送应答(类型为0)的ICMP回应给A
作用:
确认 IP 包是否成功送达目标地址
报告发送过程中 IP 包被废弃的原因
改善网络设置
具体:
深入:(ping的勘误,正常版本都没写,这些例子真的恶心,就不能正常讲东西艹真他妈傻逼)
查询报文类型:(以下是ping时候的)
回送消息 —— 类型
0和8:用于进行通信的主机或路由器之间,判断所发送的数据包是否已经成功到达对端的一种消息,ping命令就是利用这个消息实现的
查询报文的使用:
同一个子网A主机和主机B,主机A执行ping主机B后,源主机首先会构建一个 ICMP 回送请求消息数据包
捋顺:
差错报文类型:
目标不可达又分6种类型:
重定向是
差错的使用:
- IGMP:
概念;
组播即对某组主机发送数据,管理组就用到了IGMP
工作在主机(组播成员)和最后一跳路由之间
常规查、与响应 的工作机制:
IGMP版本:,IGMPv1、IGMPv2、IGMPv3
IGMPv2来说
先科普个规定:
224.0.0.1 代表所有主机是 协议规定的特殊设定 ,它是 IPv4 中预定义的组播地址,专门用于表示本地子网内所有支持组播的主机(默认所有主机都加入该组播组)
224.1.1.1 是普通组播地址,仅代表 特定组播组 ,设备需主动加入该组播组才会接收其数据,并非默认代表所有主机,是按需分配的组播标识。(傻逼小林这块完全没解释224.0.0.1和224.1.1.1)
224.0.0.2 所有组播路由器
离开组播组的工作机制:
情况一:
情况二:
是否加入组播组和离开组播组,是由socket一个接口实现的
组播都是UDP

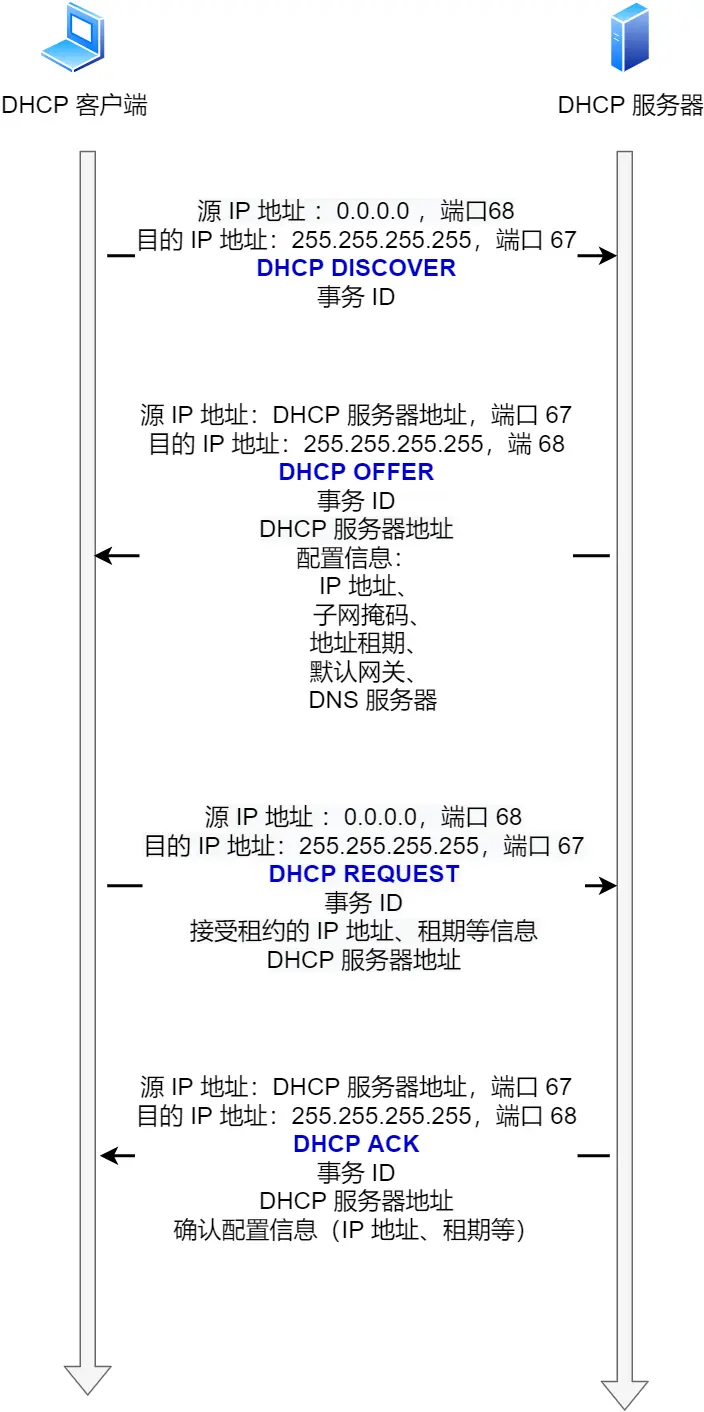


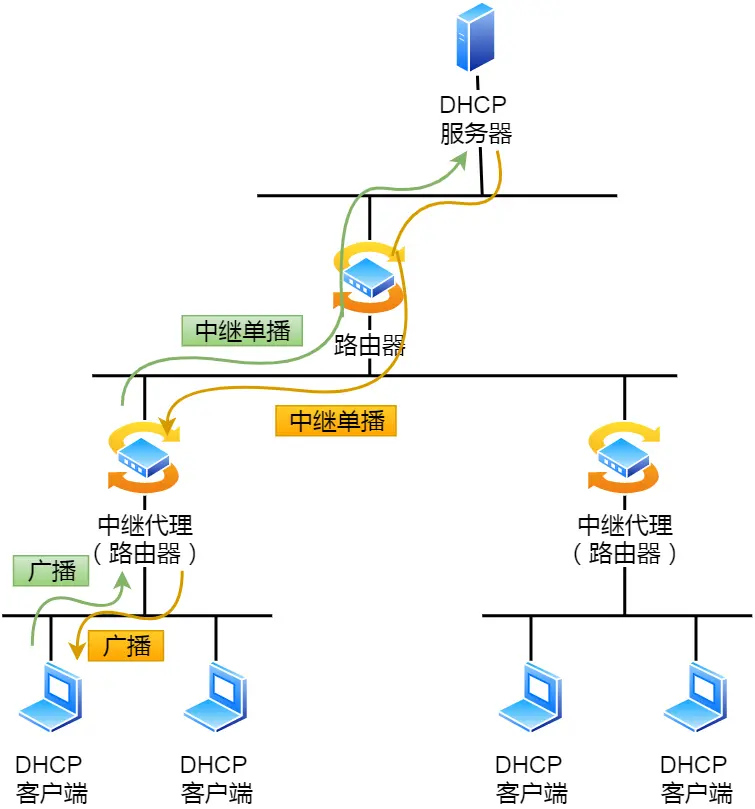

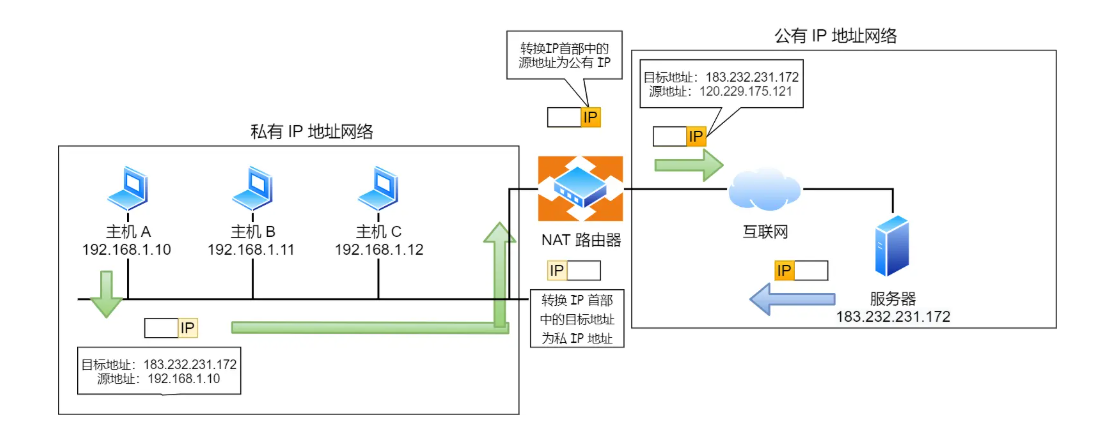
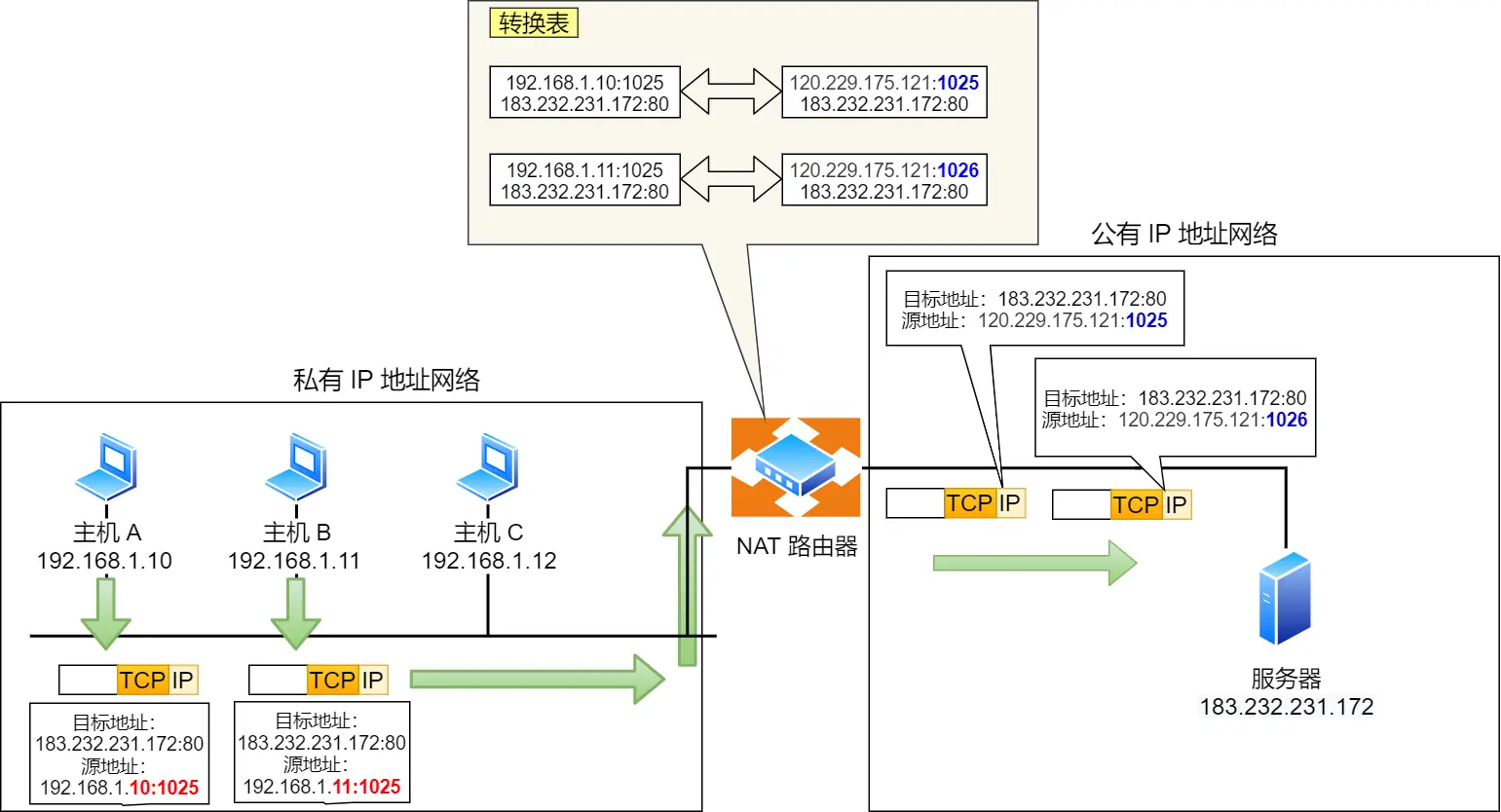


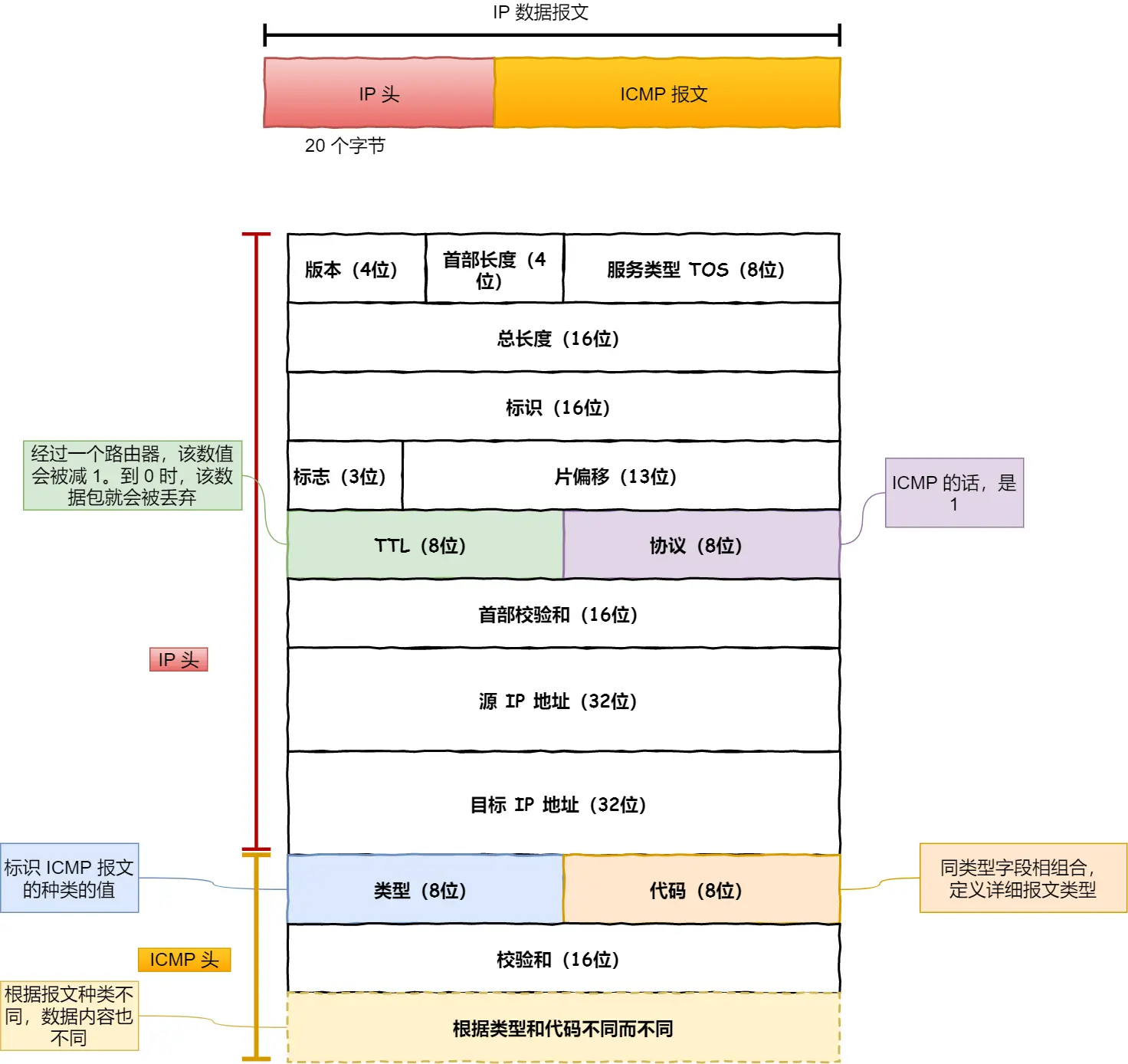
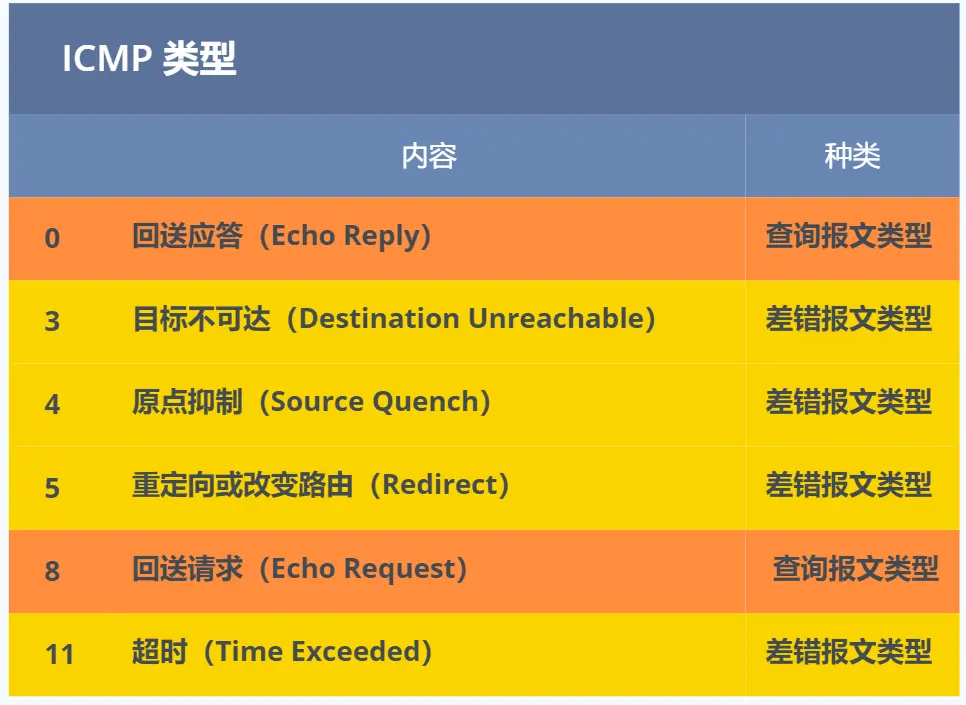
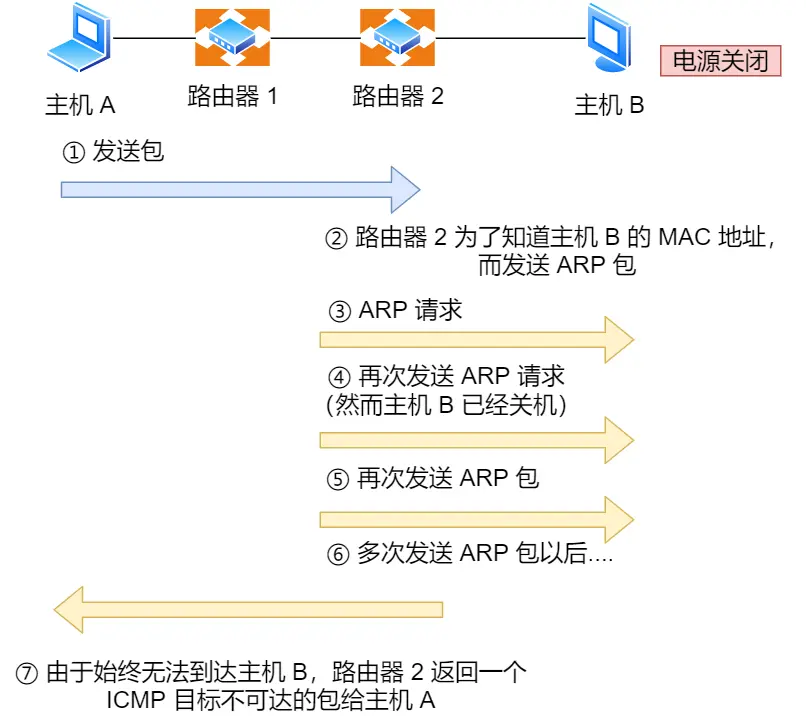





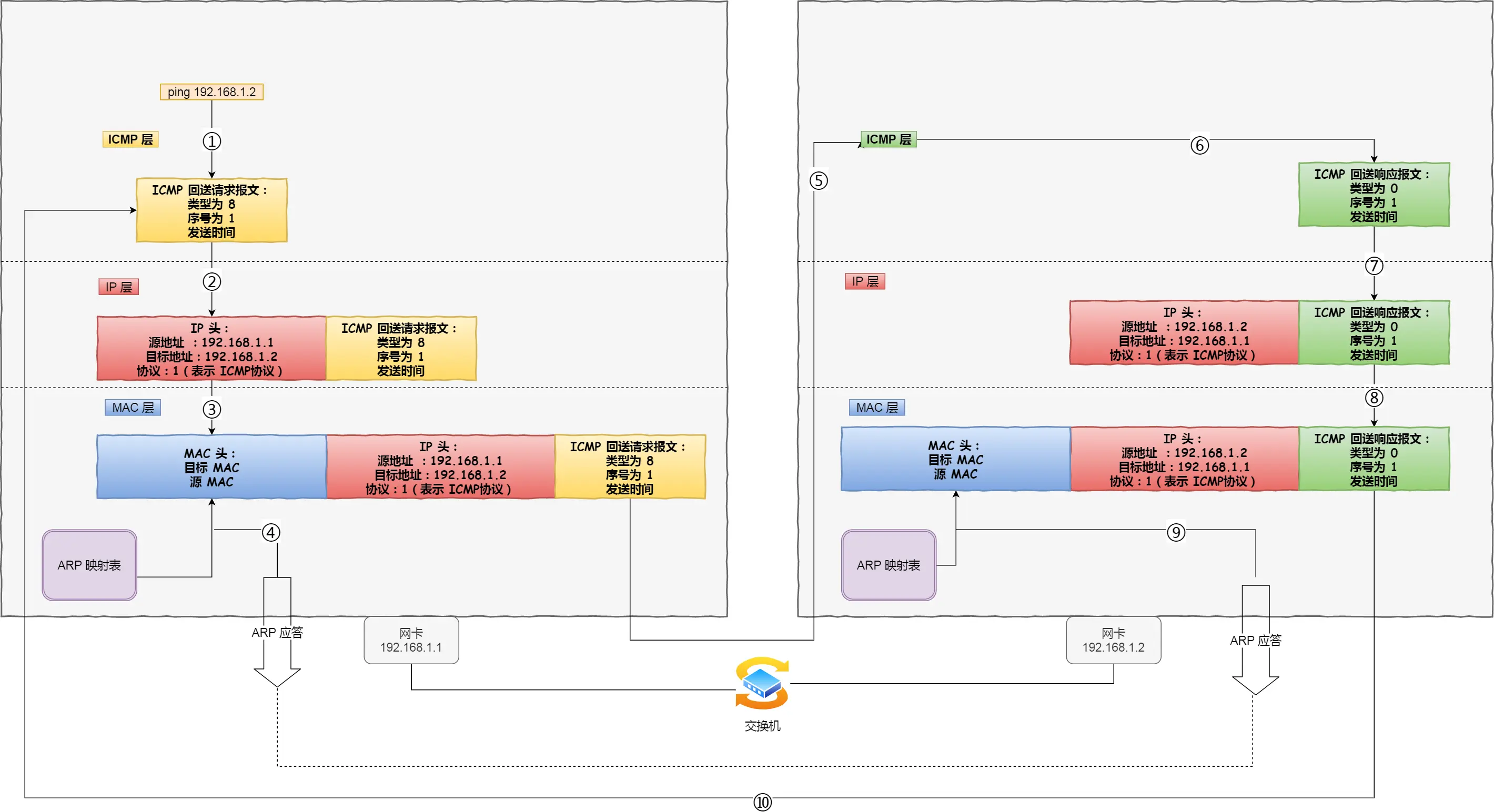


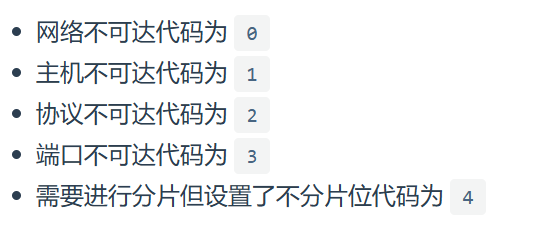

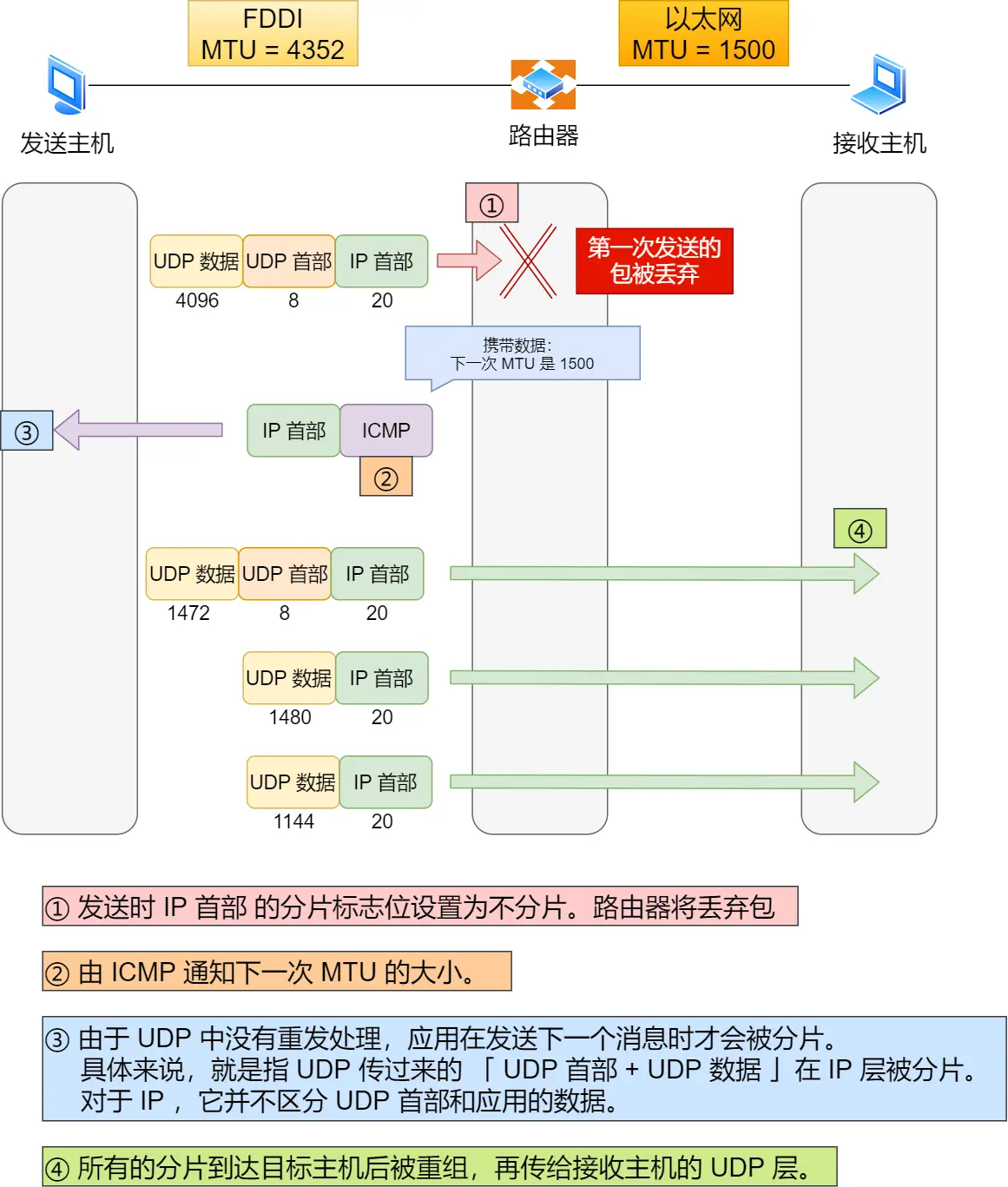
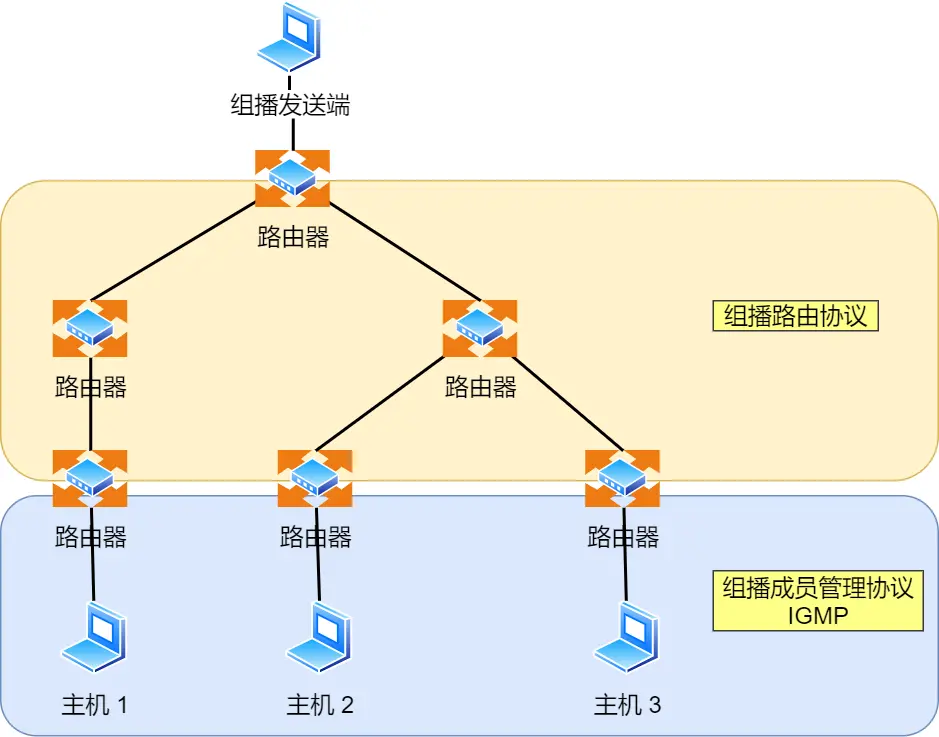

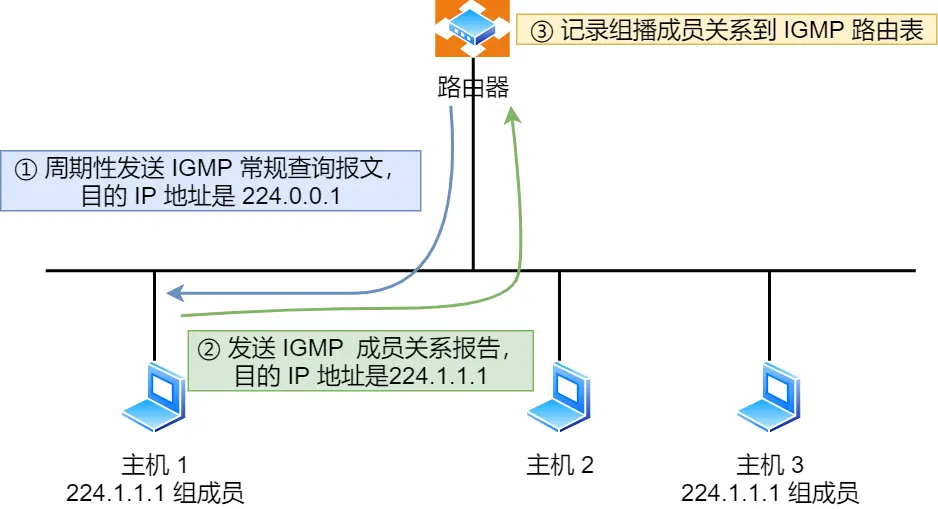

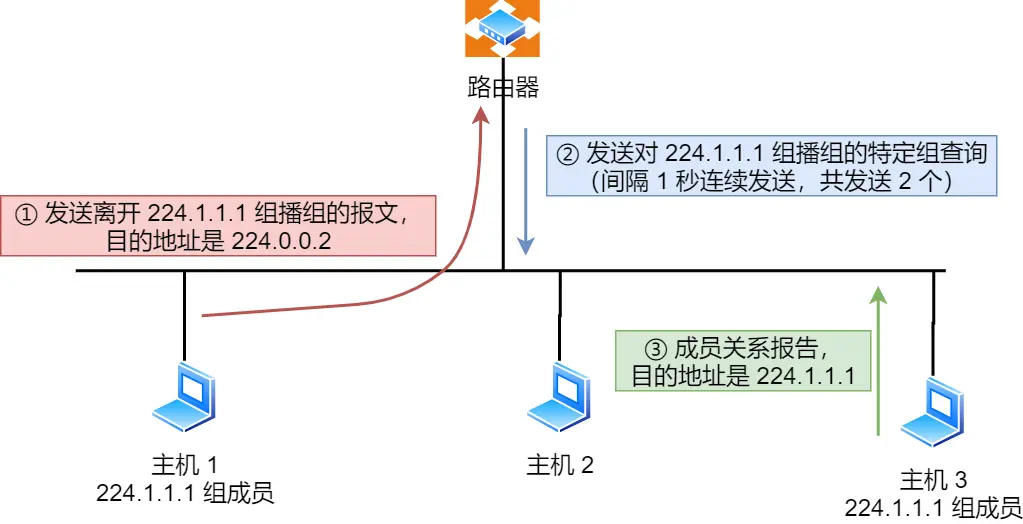



- 唉
我真的找不到活下去的意义,看不到光亮,哪怕现在有一份工作,哪怕腾讯offer摆在我面前也觉得索然无味没啥意思,心力交瘁 真的学吐了~~~~(>_<)~~~~。我不知道哪一天会不会猝死在哪个角落,不想被人知道,只想给家人留一笔钱
每天跟建筑工地干活的人一起吃16元的自助午饭,好几个月吃的都是同样的饭菜,忍受着油烟子和呛人的烟味蟑螂饭馆老鼠宿舍,每天重复的道路,每天饿肚子吃不饱饭,每天看这图书馆的桌子椅子真的厌倦的要吐了。恶心想吐,不是生理性的,就是对这些月月如一日的一年多的生活
饿的疼的在床上蜷缩着打滚,像一个僵死的臭虫
无比怨恨曾经对人真诚善良的自己,无比憎恨曾经做任何事对朋友都事事尽心尽力闭环极值靠谱的傻逼自己。
如果大学毕业没在家4年照顾家人而是离开家不至于这么不堪吧
- 最后展开讨论下ping
ping属于应用层,应用的底层,用的是网络层的ICMP协议。
虽然ICMP协议和IP协议都属于网络层协议,但其实ICMP也是利用了IP协议进行消息的传输
ping 某个IP 就是往某个IP地址发个消息
先整合下之前啃的TCPIP网络编程尹圣雨书,
比如聊天软件要发送消息,用TCP,即抽象成Linxu里你往目的地发送东西,即往某个文件发,引入socket,
socket(AF_INET, SOCK_STREAM, 0);
SOCK_STREAM是指使用面向字节流的 TCP 协议,工作在传输层创建socket后,用socket的sendto接口把要传输的数据写到文件里,进程从用户态到内核态,调用sock_sendmsg方法
然后进入传输层,带上
TCP头。网络层带上IP头,数据链路层带上MAC头等一系列操作后。进入网卡的发送队列 ring buffer ,顺着网卡就发出去了。
ping也是如此
只不过用的是
socket(AF_INET,SOCK_RAW,IPPROTO_ICMP),SOCK_RAW是原始套接字 ,工作在网络层, 所以构建ICMP(网络层协议)的数据
为何断网也可以ping通
ping回环地址和ping本机地址没有区别
科普一些基础知识:
localhost不叫IP,是一个跟
baidu.com一样的域名,只不过会默认解析为127.0.0.1etc 是存放配置文件的目录
/etc/hosts 是其中用于域名 IP 映射的文件,修改它可干预本地域名解析过程
所以
localhost=127.0.0.1
再说
0.0.0.0,ping是失败的,无效目标地址这个就是监听所有端口的意思,啃TCPIP网络编程尹圣雨书的时候,里面的
server_addr.sin_addr.s_addr = INADDR_ANY就是,因为头文件#include <netinet/in.h>里定义了#define INADDR_ANY ((in_addr_t)0x00000000)
总结


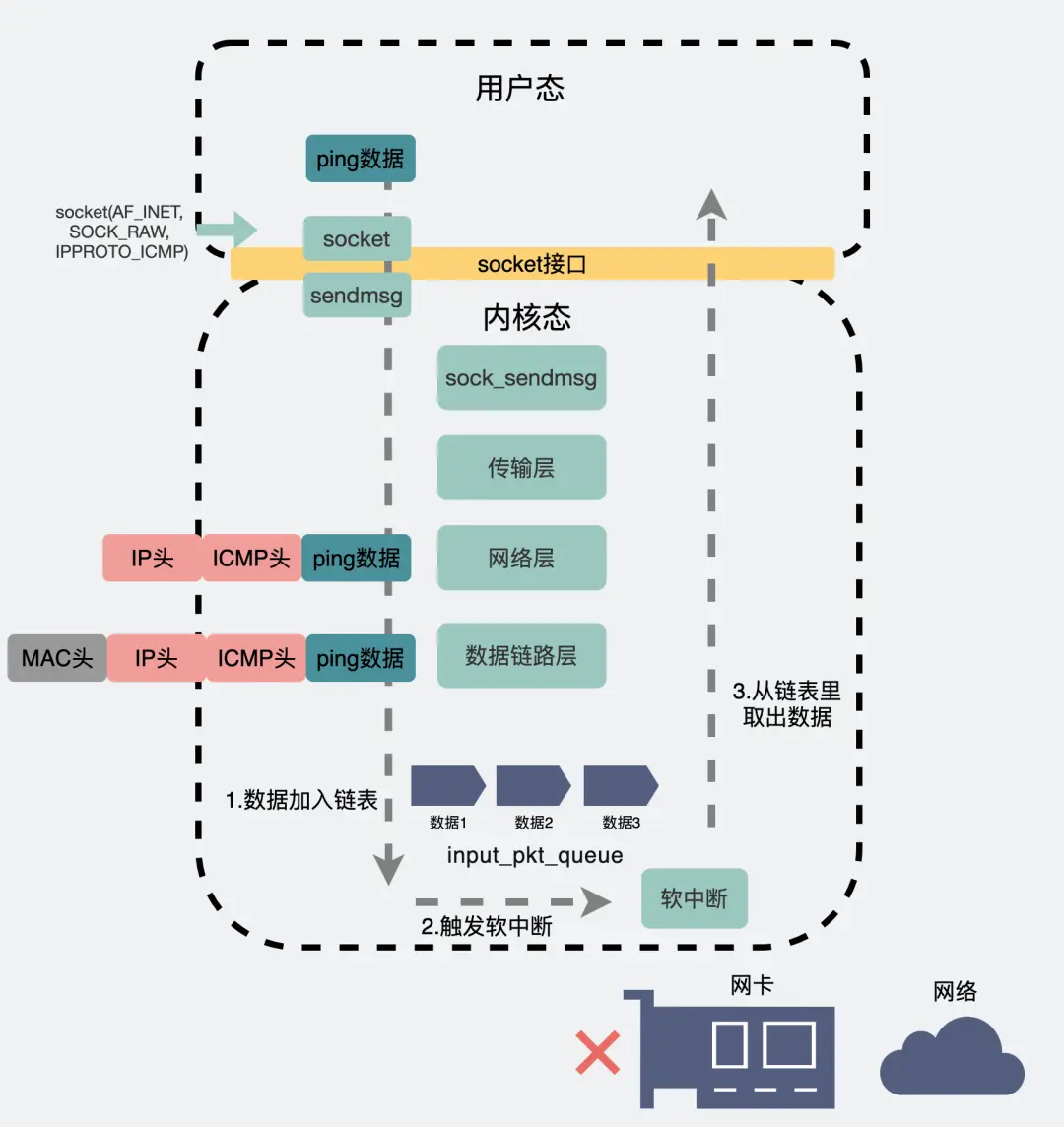
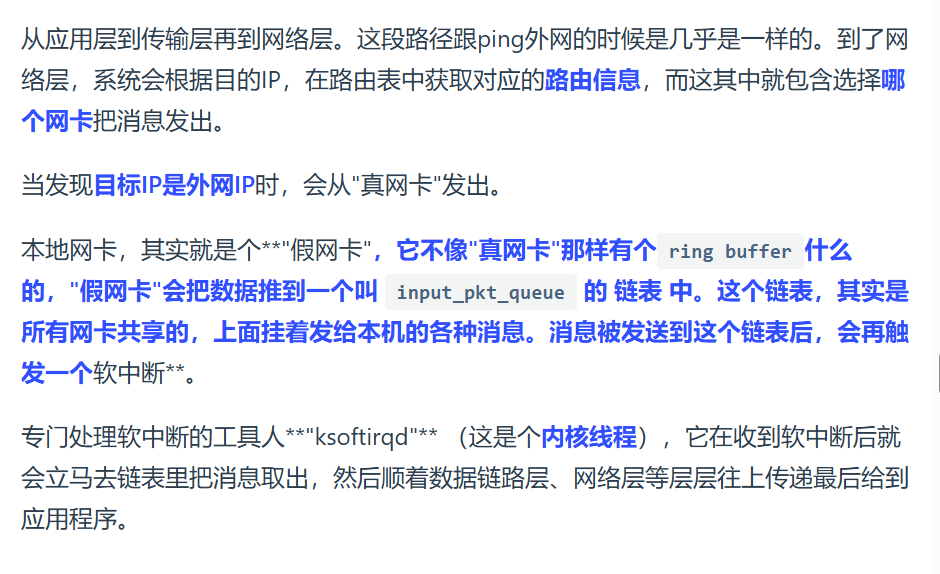

最后附上从TCP篇开始找到学习方法,不再放链接的豆包问答链接(TCP篇+IP篇)
至此小林coding的计算机网络学完了
回头把基础篇和HTTP重新写下总结
... ...
至此总结结束开始操作系统
此文8w字(全选到word里看的)
-------------------------------------------------------------------------
逐渐总结自己的特点放在简历:
重构C++算法题后面再说
根据哪怕回声服务器捋顺出整个通信流程,无比细致(HTTP链接分享里自己捋顺的工作流程)、展开socket
socket演变(结合啃的书,这样可以把浪费时间劣势写不到简历里当作自己有探索求知欲!即把学小林coding发现很多人问题那么的低级,后悔看书,当作学完主动驱动自己去看书,呵呵)
机械那人的项目感觉不难
有一个构想算法结合业务做最小生成树啥的那个
写自己会的就好不用在乎乌烟瘴气的就业环境
RSA算法
TSL过程
会啥都写上去
大量时间研究过的时间戳
TCP三次握手的意义和原理
感觉跟之前啃的TCPIP网络编程串起来了,太开门了艹
TIME_WAIT和bind error自己实验(这都死后之前的误区弯路,看机械小林coding经验贴发现简历写什么什么,都写上)
书里的send后立马close问题,深入了解复杂场景中,为保证数据的可靠传输的保障本质
SO_LINGER

 浙公网安备 33010602011771号
浙公网安备 33010602011771号