
HDU1711-Number Sequence
开始刷KMP —— 几位计算机科学家辈D.E.Knuth、J.H.MorTis、V.R.Pratt发明的一个模式匹配算法,取名字一个字母命名


1 (看毛片算法)
分析之前学过的算法:
暴力就是A的数字个数 * B的数字个数,10^10,还要乘个未知的数据个数:T,肯定超时
开始 回顾 学KMP算法思想:
百度到一个博客,写的一坨屎一样,这狗逼还有逼脸要关注才能阅读全网,直接跳过
又看到另一个博客(链接尾巴786),讲的太底层了,太详细了,有点高深,我没看懂(很好的给高潮博客做了铺垫,前后缀、最长公共前后缀专业名词解释的相当好),简称铺垫博客,去铺垫博客里搜“可以发现只要字符串p”,对,就看到这就行,然后转去看高潮博客
换bing搜索引擎,查到这个博客(链接尾巴527),嘎嘎高潮相当透彻清晰,简称高潮博客,太尼玛开门了啊。根据之前看博客的经验,全网的傻狗网友看到垃圾博客也是好评666,而我却能发现一堆问题的现状,现在这个高潮博客写的相当之棒,下面评论反而有好多质疑的声音。
其实按照我这骂遍全网傻逼博主的性格,这人写的博客真的一点毛病没有,非常非常完美了,在他的博客中搜“在这个例子中我们发现”,这句话上面的例子和下面具体介绍KMP原理的例子,俩例子正好讲清楚了,一个是首位和后面不相等,一个是首位和后面几位相等,分别需要怎么处理,讲的很棒。
但有俩问题,先搁置
0、之后咋整
1、这么弄复杂度为啥就是n+m了,主串+子串长度
想想非常简单了就再BB两句就直接切题
首先明确个东西,前缀表或者叫最长公共前后缀,关于这个解释我觉得高潮博客和铺垫博客写的非常棒了,没法再多解释什么了,直接展开解释高潮博客里的这个图

判断道x发现不一样,说明x前面的都可以匹配上,那你找子串中abcab这个的最长公共前后缀,是2,说明子串T开头的那俩字母和尾巴那俩字母,是一样的,且可以和主串匹配上,那就好办了,你x不是不一样吗,我直接咋办呢,好到这先不说,先插一句话,就是,你不要考虑首位a和后面的几位一不一样,那样的话就会衍生出好多思考,比如有一样的,还有不一样的,那我就统称为拿这个最长公共前后缀2来说话,你别管a后面的跟a一不一样,我只知道一个事实就是:想成S是老公,T是老婆,到x那是分歧,可以想成年份,即老公S和老婆T在第六年产生分歧,前面能匹配的就代表和睦相处,那从a到x这么多年,老公和老婆都可以和睦相处,到x年那产生分歧了,(不要去想a和后面的是否一样),那一定会有前两年的情况和后两年的情况是一样的,和睦的,两个人可以从后两年开始重新匹配过日子。T的前两个一定可以和S的出问题的那里,的前面的两个字母匹配,那我又想了,为啥一下给我扯到S串的那老远,即S的第六个位置,我就不能跟S的前面的位置去匹配吗?这就是前缀表的玄妙之处,假设你T是ababax,S是abababaa,反正是构造出到x那个位置才分歧,大概这意思,那T的分歧之前的最长是aba、aba,即3,那我可以确定T的第一位一定可以匹配S的第三位,大概这意思。即分歧之前的一定可以跟分歧之前的匹配上。
还有就是,他下面的图

他x不匹配之后,T中的b跑去匹配S中的第六个字母b,也就是说他的T中的首字母a匹配到了S中的第4个字母a,他为啥不能是去匹配S中的第二个字母a呢?因为这样的话后面是不匹配的,aa已经通过前缀表很好的告诉你,跟S的第4、5个字母匹配了,那我又有疑问了,你只是保证了T前两个a,匹配S的第4、5个a,并没有S中间的字母的匹配情况啊,万一T的aa不仅可以跟S的4、5字母匹配还能跟S2、3字母匹配呢?好,假如
正常写代码位置是从0开始,但为了方便看,我从1开始的,且加了空格
位置:1 2 3 4 5
S : a a a b b
|
T: a a b
位置3不匹配,此时T的前两个数的最长前后缀是1,说明T的首1位和末1位相等,且分别可以和S串的对应位置匹配上,那直接把T的首一位拉过来,拉到S的位置2,即
位置:1 2 3 4 5
S : a a a b b
T: a a b
注意此时,拉是这样拉了,但因为已经确定最长前后缀是1,那纵向看位置2的两数,即S的第二位和T的第一位一定可以匹配上个,可以不用再匹配,所以此时只需要位置3的俩数去比就行了即
位置:1 2 3 4 5
S : a a a b b
|
T: a a b
然后再4位置的b跟b比,发现一样,直接结束。
前后缀表真的玄妙
此时上面提到的俩问题中的第一个,之后咋整那个好像懂了,S表的指针一直往前走,不匹配了T的指针就回退,但复杂度还是不懂,先研究代码
开始研究KMP代码:
卧槽好tm难啊这next数组,而且他代码里有问题,下标 j 会变成负数,纯纯傻狗博主,一看就是没切过题,应试教育只会考研的那种臭傻逼,垃圾一个
算法真的是烧时间啊,这玩意盯着屏幕,草稿本上划了来划了去,不消耗到固定时间真tm想不通,好折磨啊
好想理解高潮博客里的代码,写的真简洁,但看了一天了终究一丁点都无法理解,放弃了,换个博客,无意间看到个复杂度证明博客,看了云里雾
又这么搜了下,找了个博客讲解,(链接是知乎的,链接尾巴1530,里面有句话说的很好:背靠着山,未雨绸缪)看似好像挺接地气,但语言表达能力太差,看一半就关闭了
继续换,依旧不行,又看了一个博客脚本之家的,还是根本不懂啊,感觉他已经解释的够详细清楚够牛逼了,唉时间堆的不够多
换bing搜索引擎再试试,找到了这个(链接尾巴6528,这篇博客简直就是盘古开天辟地了,解释方式相当新颖,简称KMP祖师爷
仿佛导管子电报里彻夜找不到好素材,一下遇到了山岸逢花pred-200、木下凛子JUL-491、JUL-302,西工大姜学峰没有我搞不到的题,没有我没见过的片,武林界的扫地僧隐居的张三丰
果断关注,这不比那些要关注才能看全文的狗逼强百倍?图似曾相识貌似王道的?,这篇文章的精品之处就是在解释的时候就用上了 i 和 j,不至于到代码里突然看到而一脸懵逼),他博客里解释棒的语句,我摘抄一下:
0、如果前缀 [0, k-1] 与后缀 [j-k, j-1]完全相同,那么公共子串长度就是k
1、next[6] = 3算的是下标6前面的
2、索引位置为0和1的位置不存在公共字符串,next[1] = 0 , next[0] = 0
对于这一点插一句:
此博客里搜“链接尾巴786”,那篇博客说,next存的是开头到此下标位置之前一位的最长
$$
\rm next[j] = {子串p[0,..,j - 1]的最长公共前后缀长度;}\ \ \ \ \ 0\le j \le n
$$
此博客里搜“链接尾巴527”,那篇博客说,next存的是开头到此下标位置的最长
第五个子串是t4=“aabaa”,该子串的最大相等前后缀为"aa",长度为2,故next[4]=2
显然链接尾巴6528用的是786那篇博客里说的,开头到此下标位置之前一位的最长,
3、他的这句话:“在目标串中起始位置介于[i-j+1,i-k)的子串有没有可能与模式串匹配呢?绝无可能!证明如下:”,用数学理论严谨的证明了我上面搜“扯”字,和“并没有S中间的字母的匹配情况啊”,我用一个例子简单说了下。对于他的论证相当完美了,我再插一句,他说:“如果以目标串[i-j+1,i-k)中某个位置p为起始位置的子串能够与模式串匹配,那么两条红色虚线之间的部分肯定也会匹配”,我就会想为啥虚线中肯定也会匹配啊?那如果p为起始位置的子串能够匹配,但只是匹配了一点,没到k那么大呢?相当简单,KMP用的是最大,小的那些无意义,换句话说,虚线内如果有可以和起始点匹配的,也必然会在后面某处不匹配,还是会从 i-k 位置开始匹配,省去不必要的匹配,如果说可以匹配一直到某位置,使得匹配长度达到 k ,那 next 记录的就一定是那个点了即[i-j+1,i-k)中某个位置p,而如果能匹配的长度比 k 大,那就与最大前后缀长度 k 矛盾了。不好解释有点像传说中的数学分析让你证明1+1==2一样,不管这个。
开始继续读他的代码,为了方便把图和结论拽出来

next[0]:-1
next[1]:0
next[2]:0
next[3]:0
next[4]:1
next[5]:2
next[6]:3
注意KMP祖师爷的代码while那应该是 while(j<t.length()-1) ,另外一个问题相当之牛逼,感谢GPT。祖师爷的代码本来是
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std;//这里有next迭代器,所以变量别叫next 5 int ne[10]; 6 int main() 7 { 8 string t="abbabbc"; 9 int j=0,k=-1; 10 ne[0]=-1; 11 while(j<t.length()-1){ 12 if(k==-1||t[j]==t[k]){ 13 j++;k++; 14 ne[j] = k; 15 } 16 else k=ne[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神! 17 } 18 for(int i=0;i<t.size();i++) 19 cout<<i<<" "<<ne[i]<<endl; 20 }
本来是length那报错了,我问GPT后又发现另一个惊人的错误,如果没有GPT,之后自己遇到估计会搞好久,这也有了经验,以后对于这种.length函数,在调试的时候也不要放过,柯南道尔所说:排除一切不可能,剩下的再不可能也是真相。

试了一下,
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std;//这里有next迭代器,所以变量别叫next 5 int ne[10]; 6 int main() 7 { 8 string t=""; 9 int j=0,k=-1; 10 ne[0]=-1; 11 while(j<t.length()-1){ 12 if(k==-1||t[j]==t[k]){ 13 j++;k++; 14 ne[j] = k; 15 } 16 else k=ne[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神! 17 } 18 for(int i=0;i<t.size();i++) 19 cout<<i<<" "<<ne[i]<<endl; 20 }
空串确实死循环了。
结合KMP祖师爷的博客里的那幅图(我拽出来了在上面)、无意中因为报错而发现的GPT的解答(我也拽出来了帖到了上面)、代码(代码里的两个if输出是为了格式对齐,方便看)
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std;//这里有next迭代器,所以变量别叫next 5 int ne[10]; 6 int main() 7 { 8 string t="abbabbc"; 9 cout<<t.length()<<endl; 10 int j=0,k=-1; 11 ne[0]=-1; 12 while(j<t.length()-1){ 13 if(k==-1||t[j]==t[k]){ 14 j++;k++; 15 ne[j] = k; 16 } 17 else k=ne[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神! 18 if(k>=0) 19 cout<<"j:"<<j<<" k:"<<k<<" ne["<<j<<"]:"<<ne[j]<<endl; 20 if(k<0) 21 cout<<"j:"<<j<<" k:"<<k<<" ne["<<j<<"]:"<<ne[j]<<endl; 22 }cout<<endl; 23 for(int i=0;i<t.size();i++) 24 cout<<i<<" "<<ne[i]<<endl; 25 } 26 //GPT说:而k表示当前考虑的最长相同前缀后缀的长度 27 //为啥while(j<t.length()-1)输出 28 //7 29 //@1 0 30 //@1 0 31 //@2 0 32 //@2 0 33 //@3 0 34 //@4 1 35 //@5 2 36 //@6 3 37 // 38 //0 -1 39 //1 0 40 //2 0 41 //3 0 42 //4 1 43 //5 2 44 //6 3 45 // 46 //while(j<t.length())输出 47 //7 48 //@1 0 49 //@1 0 50 //@2 0 51 //@2 0 52 //@3 0 53 //@4 1 54 //@5 2 55 //@6 3 56 //@6 3 57 //@6 3 58 //@7 0 59 // 60 //0 -1 61 //1 0 62 //2 0 63 //3 0 64 //4 1 65 //5 2 66 //6 3 67 // 68 //最后ne结果都是一样的啊,祖师爷为啥弄个length-1 69 70 71 //-1下标
还有运行结果
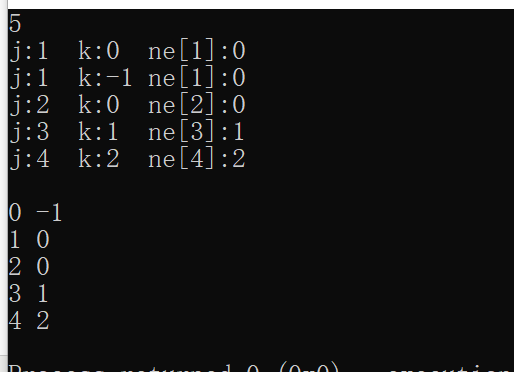
7 j:1 k:0 ne[1]:0 j:1 k:-1 ne[1]:0 j:2 k:0 ne[2]:0 j:2 k:-1 ne[2]:0 j:3 k:0 ne[3]:0 j:4 k:1 ne[4]:1 j:5 k:2 ne[5]:2 j:6 k:3 ne[6]:3 0 -1 1 0 2 0 3 0 4 1 5 2 6 3
最后有些许了解了。根据自己的理解叙述下,方便自己日后回顾
如下:

我勒个去,回想这个考研必考内容,考研都涉及kmp这么深奥的玩意了吗我靠???
重新解释下:
首先0、关于 while(j<t.length()) 还是 while(j<t.length()-1) 的问题,其实发现只要到next[6]就行,“abbabbc”的 length 是7,减一是6,当判断5<6时,进入循环将 j 搞为6,k 搞为3,这时候就可以退出循环了,注意:循环是为了给ne[]数组赋值,已经都找到下标6了就没必要再找了,而如果为了避免空串导致的length-1会无限循环,使得去用length,不减1,那就会多出几行输出
j:6 k:0 ne[6]:3 j:6 k:-1 ne[6]:3 j:7 k:0 ne[7]:0
可是数组如果开的不够大,ne[7]这里是会有问题了,刷题测评机一般会返回RE,未定义行为。当然这里只是提个醒,出现问题了及时定位找出问题就好,过多研究这里没意义
其次1、 if(k==-1||t[j]==t[k]) ,会出现下标为-1的情况,但由于或运算符的短路原则,一般不会有问题,留意下就好
没词儿了2、using namespace std;这玩意里有个叫next的迭代器,具体是啥我也不知道,所以变量命名的时候别叫next
3、开始解释next数组,先不要想匹配退回的事,现在仅仅是处理主串(目标串)和模式串匹配前,准备工作,即给模式串的每一位弄上最长的相同前后缀长度
为了清楚,把串弄长一点,“abbabbaaa”,(先看length-1的,length最后说)

即图234中的1
这个串的next是:
a b b a b b a a a
-1 0 0 0 1 2 3 4 1
程序过程是

这个首先令k是-1,表示在模式串的0下标位置不存在next值 —— 注意:王秋献:吃7个烧饼不是第七个饱的,是有前六个垫底,前面说垃圾的那些博客,也在潜移默化的加深着KMP的理解,所以也要扫一眼
j 是0,j 代表我目前想给模式串的哪个下标位置进行求next数组操作。
首先k是-1,没啥说的,j++、k++,这里你问为啥就加1了,GPT说的很官方,什么可以扩展之类的,这就纯属狗逼发言,官方的话术从来都是愚民用的,从来都不是解决实际问题用的,所以我用人话说就是,这里加1,其实就是构造而已,因为这样写会得到 j 在模式串的1下标的时候,k可以为0,当然这里的加1意义现在也体现不出来,纯属根据答案强行构造,没啥逻辑,不用纠结,换句话说背就完了,我头一次背代码(注意我写此段的时候也是懵懵懂懂,一知半解,打算边写边理解)
捋顺下此时:j:1 k:0 ne[1]:0,next[1]有了
GPT说k表示当前考虑的最长相同前缀后缀的长度,姑且可以这样理解,继续往下走
我本来应该走下标为2去求next[2]的值了,这里引入一个前面说过的,链接尾巴1530提到的“未雨绸缪”,我并不是求完next[1]就不管了,而是铺好路,为下面的next[2]做准备,而此时next[1]是0,这个0和1正好可以去当作检测下标,去检测下模式串下标0位置和1位置是否相同,发现不同,(回忆下咱们的模式串 t 是“abbabbaaa”别忘了),好,将0的next,即那个-1,赋给k,让k重新回归-1,
捋顺下此时:j:1 k:-1 ne[1]:0
next[1]不是求完了吗?咋还来一遍?目的就是做铺垫,即告诉next[2],你别指望了,模式串 t[0] 和 t[1] 不相等,你老老实实根据构造的流程来,都加1,直接被安排为j:2 k:0 ne[2]:0完事,
捋顺下此时:j:2 k:0 ne[2]:0,next[2]有了
继续往下走,并不是求完就完事,我还要给模式串t下标为3的做铺垫,好此时捋顺一下,咋做铺垫?你要知道我们现在在干啥?现在是在解释next数组怎么赋值,之后是要通过next来跟主串匹配的,也就是说当我模式串跟主串匹配到了3的时候,如果不匹配,要回退,我要你快速给我3前面,即0~2这几个字符的,最大的公共前后缀,那好说,由于我们根据前面看的别人博客知道,012这仨玩意,最大的串,最理想是:01串==12串,使得next[3]是2,那么由于我们已经在上面检测下标的时候,已经知道了0 1不等,那比如0位置的模式串是“A”,1位置的模式串是“B”,那你2位置无论是什么,都不可能有01串==12串,即AB永远不可能等于B开头的某某,所以此时,你next[3]只有一个选择,要么你狗JB不是,没有能匹配的,next[3]是0,要么模式串0位置和模式串2位置相等,也就是说你next[3]最多是个1,那好办了,你看上面,我现在next[2]不就是0嘛,直接 t[j] 和 t[k] 比较,发现不等,好说,执行 else k=ne[k]; ,k被赋值成了-1,
j:2 k:-1 ne[2]:0
即告诉即告诉next[3],你别指望了,模式串 t[0] 和 t[2] 不相等,你老老实实根据构造的流程来,都加1,直接等下下一次循环,因为k是-1,而被安排为j:3 k:0 ne[3]:0完事,
捋顺下此时:j:3 k:0 ne[3]:0
好了,到此都清楚了,尽量自己先想,然后再看我写的,咱们继续,next[3]有了,然后给next[4]做铺垫,此时用0和3作为下标,去看 t[0] 和 t[3],发现一样,那就直接继续都加1,到了next[4]那就是j:4 k:1 ne[4]:1,
此时next[4]也有了,是1,再往后都是加1,没啥好说的,
但到这我就有疑问了,
next[4]是1,不对啊,你只是判断了 t[0] 和 t[3] 啊,我万一0123这几个字符里,012串==123串咋办(next[4]就会是3),你没判断啊,或者01==23(next[4]就会是2),
好咱们捋顺一下,之前已经判断过的有:
0≠1(t[0]≠t[1],咱们简称0≠1)、
01串≠12串、
0≠2、
0==3,
如果你想01==23,就必须0==2且1==3,跟0≠2矛盾,
如果你想012==123,就必须0==1且1==2且2==3,跟0≠1矛盾,
至此解释完毕
奥妙无穷,最笨的方法解释的。
此时我们再看上面图2,刚才讲的是图1
位置 : 0 1 2 3 4
模式串: a b a b c
next : -1 0 0 1 2
过程如下:
找找感觉,依旧是 j 初始0,k 初始 -1,
第一行(不算那个总长度5):j:1 k:0 ne[1]:0
常规操作,next[1]已经找到了,是0
第二行:开始为了next[2]做准备,去比较 t[0] 和 t[1],不等直接-1,就有了j:1 k:-1 ne[1]:0
第三行:都加1,被安排好的,next[2]已经找到了,是0,即:j:2 k:0 ne[2]:0
第四行:还是想为next[3]做铺垫,发现 t[0] == t[2],直接都加1,j:3 k:1 ne[3]:1,还是那句话next[3]因为前面有012三个下标字符摆在那,理论上最大公共前后缀可以达到2,但必须01串==12串,但有 t[0] ≠ t[1],
第五行:正常加1,没啥好解释的
再看个例子:“aaaa”
图3那个,也没啥好说的
图4,“aaba”,例子不明显,
我再举一个例子:举不出来了,拿图4说吧,这个主要是我想说的 —— 退回操作
先阐述下图1的例子,“abbabbaaa”,上面以为都是加1就忽略了,其实还有可以说的,
回去看那个例子的控制台输出,在找到:j:7 k:4 ne[7]:4,的这一行,abba==abba,然后该为 t[8] 的 next[8] 做铺垫了,
程序做的是用7和4比较,发现不等,就 k=ne[k]; k 变成 next[k] 了,即 k 变成了1,
这其实就是我说的回退思想,来研究一下为啥,
(注意我说的完全不是跟主串匹配的回退到某位置的回退,现在还没到那一步呢,仅仅是给next数组赋值,回退其实想表达的是next里自身的事)
来从头捋顺下,之前是说到了next[4],那就继续说,next[4]为1,是通过next[3]来的,next[3]做了个铺垫,t[0] 和 t[3]一样,next[4] 立马就是1了,
至于为啥不能是2,理由是想为2,就必须01==23,但是0≠2早就说过,
现在有next[4]是1后,为 next[5] 做铺垫,t[4] 和 t[1] 比,发现还是等于的,说明啥,我想说的重点逐渐呈现出来了,(听起来很简单但却是KMP的牛逼之处),next[4] 是1,具体是啥?其实就是4之前的0123这几个数的最大公共匹配长度是1,即 t[0] == t[3],进一步说是 a == a,到了求5的时候,只需要判断 t[4] 和 t[1],发现相等就+1,代表啥?我已经有了 t[0] ==t[3],这也是位置 4 之前,最大的公共长度,那t[4] 如果再等于 t[1] ,不就说明 01 == 34 吗?啥意思?next[3]是0,那4最多也就是1,t[0] ==t[3],基于此,next[5]最多也就是个2,发现01 == 34,即ab ==ab直接铺垫结束,next[5]就是2,至此看似是屁话但其实很玄妙。
后面以此类推,每个都加1,也就是同理了。
现在就剩一个事没说了,你发没发现,加1很容易理解,那如果不符合没法加1呢?咋办?终极重点来了 —— 回退
我刚发现这个例子正好可以,就是一个比0大一点的数,比如这里 next[7] 是4,然后我想找的就是接下来 next[8] 不是增的,因为增的已经懂了,那就降低,但也降不到0,那这里 next[8] 正好符合,是1。
开始讨论 next[8] 的事:(其实写博客的好处是可以更好理解新算法,其实这些所有的我都是边写边理解懂的,写之前我也不懂,并不是懂了才来写博客的,如果已经很懂了我也懒得去写,但就是有信心弄懂,或者说弄不懂不罢休,所以才敢写,但对于算法题目来说,总感觉写博客就像课堂记笔记,不如不写博客直接思考想的深刻)
因有 0123 == 3456,
即: abba == abba,使得 next[7] 为4,现在开始为 next[8] 做铺垫,假如 t[7] ==t[4],那继续有
01234 == 34567,新加入的 4、7 是匹配的(重点),如果这样 next[8] 就会为5,
然而现在 t[4] ≠ t[7],那咋办?控制台输出告诉我们 k 重新赋值为 next[k],k 为 1了,我认为 01234 ≠ 34567 也别退这么多啊,后缀必须有最后一个字符,那我应该去看看 0123 和 4567 相不相等啊
至此我也不懂,研究一下... ...,
问了下GPT说的有些启发,有点懂了,
插一句全网别人都没提过的事,我自己以为这有点辗转相除法和链式前向星的味道,当然没这感觉的就别强找了,再整岔劈了,至于辗转相除法我只是有个印象,之前记得西安培训的时候看过这玩意,现在不去纠结这个。
回归正题就是:
前面在已经懂了KMP原理的基础上,只是单拿模式串,即子串来思考,去先搞 next 数组的值
即只考虑目前给 next 数组赋值这个事,
换句话说,按照串的下标增加顺序,next 也是增加的,例子就是图1 next 为:-1 0 0 0 1 2 3 4 1,这里 4 之前都是增加的,即升序,还有图 2,next是 -1 0 0 1 2 也是增加的,升序,但涉及到了减低,就要考虑回退了,即就要结合实际KMP与主串匹配来理解了,啥叫降低,图1的图1 next 为:-1 0 0 0 1 2 3 4 1,最后这个1就是降低,图 4 的 next:-1 0 1 0 这个最后的0也是降低。
好,理解我们现在要讨论的问题,开始说我的想法:
我自己画的图是位置、模式串、next数组。最下面是KMP的主串 和 模式串,主串是我随便编了一个

首先想到了子串(模式串)的位置 7 这 ,基于一个事实,next[6] 是3已经没啥说的了,含义是6前面的模式串,012==345,即abb==abb,故 next[6] == 3,
现在又判断出 t[3]==t[6],即0123 == 3456,都加1,使得 next[7] == 4,好至此可以理解,继续往下走,
该未雨绸缪,为 next[8] 做铺垫了,
想求 next[8] ,next[8] 是啥意思,代表之前的最长公共前后缀,那 next[7] 啥意思,代表 7 之前的最长公共前后缀,即 0123 == 3456,想考虑 next[8] 就要看 7 这一位,如果 t[7] ==t[4] ,即 01234 == 34567 ,则直接加1,next[8] 为 5,但 t[7] ≠ t[4] ,这时候我之前想的是,next[7] 已经是4了,那 next[8] 理想情况是5,但 t[7] ≠ t[4] ,说明不是5,但有可能是 4 啊,比如可能 0123 == 4567,咋直接跑到 next[4] 即 1 那去了, else k=ne[k];

其实单纯思考最长前后缀,这么想确实没错, 但要注意,KMP的这句精华思想 else k=ne[k]; 可不是求最长公共前后缀的!,换句话说,KMP的next数组,存的并不是最长前后缀!!!只是答案无比完美的巧合而已(这么说其实可能也有点不对,但至少初步这么理解是可以懂的),全网所有博客都是说求最长公共前后缀,但只是因为那是增的,升序next,一旦遇到这种降低的,你想想看,真要是求最长前后缀,为啥遇到 t[j] ≠ t[k] 的,直接就 k=ne[k]; 了,按理说应该试试0123串 是否等于 4567串 啊,相等的话 next[8] 直接就是4了,
这就是KMP的玄妙所在!,
即,由于字符串的玄妙、和发明KMP算法的三个科学家经过严格的推导证明,发现 0123串 不可能等于 4567串,故省去了判断,
那去哪里判断?啥玩意去哪里判断?,好,我先捋顺下,
我自己编的主串是:abbabbabbcca
位置: 0 1 2 3 4 5 6 7 8 9 A B
主: a b b a b b a b b c c a
|
子: a b b a b b a a a
next:-1 0 0 0 1 2 3 4 1
现在 7 位那不是不匹配了吗,next[7] 是 4,我朴素做法是子串继续从主串的位置 1 开始匹配,现在有了 next 数组,子串直接的 4位 去和 7位 匹配,这就是KMP的思想,理由是 next[7] 是4,表示子串的 7位 的前面,最大前后缀长度是 4,即:
前缀:从0开始找4个字符(0123:abba)
后缀:从末尾(就是7位前头的最后一位,6位,包括6位本身),往前找4个字符 (6543,倒过来就是3456:abba)
这个 前缀 和 后缀 是相等的,即 0123 == 3456
又因为, next[7] 是 4 ,且编号是从0开始编的,那当在 7位 发现子串跟主串不匹配的时候, 子串位置 4 前头直接有了4个字符,0123,完美,直接 0123 == 3456 不需要比较了,直接 4 和 7 比,这就是KMP思想,子串往后拽到下面所示的位置
位置: 0 1 2 3 4 5 6 7 8 9 A B
主: a b b a b b a b b c c a
|
子: a b b a b b a a a
next: -1 0 0 0 1 2 3 4 1
前面加粗的铁定相等,说了半天只是再强化下基础知识,还不是回退的重点
开始说回退,
我现在想为位置8 做铺垫,求 next[8] ,就是说当子串跟主串匹配到 8位 的时候,子串从哪里开始继续跟主串匹配比较好,因为说到8位了,主串的 7 位我要变一下,跟子串一样,如下 8 位才不同:
位置: 0 1 2 3 4 5 6 7 8 9 A B
主: a b b a b b a a b c c a
|
子: a b b a b b a a a
next:-1 0 0 0 1 2 3 4 1
由于都是找前面的,即 0~7 包括 0 和 7 位,的最长公共前后缀长度,我就那 7位 说话,
“7 啊,你的 next 不是 4 吗?,0123 跟 3456”
“如果你跟 4位 再相等,直接都加1,next[8] 为 5,等子串 8位 去跟主串匹配的时候,发现不匹配就直接找 5位,因为 01234 和34567相等,省的比了,即直接把子串的 5位 拉到主串的 8位 那去比,做接下来的操作,”
“主人,现在我子串的 7位 和 4位 不等,咋办”
“好说,你俩不相等,说明我不可以像下面这样拉”
位置: 0 1 2 3 4 5 6 7 8 9 A B
主: a b b a b b a a b c c a
|
子: a b b a b b a a a
位置: 0 1 2 3 4 5 6 7 8
next: -1 0 0 0 1 2 3 4 1
“对,这是 t[4] == t[7] 的情况,子串发现 8位不匹配后,拉到这么远,去直接 8位 跟 5位 比较,因为01234 必等于 34567,但现在 t[4] ≠ t[7] ”
“那么好,他不等,就别想让我子串拉这么多,前面的那个 7位 不是用来给 8位 做铺垫的吗,就找他对接,问他”
“好的”
“7啊,你存的这个 next 值4,给我用用,上头说不能拉这么多”
“啥意思”
“就是你现在不是直接从子串 0位 跟主串 0位 对齐的情况,直接因为 8位 不匹配就拉到 0位 根 3位 对齐了吗,多拉的是01234这么多,你朴素做法是应该子串 0位 跟主串1位对齐去匹配”
“长官,那也太朴素了,我有办法,我存的这个4,等我找他问问”
“4啊,你赶紧过来,你存的 next 是几,是1对吧,含义就是我的最大公共前后缀长度是1,0位 == 3位”
“长官,我找4说,0位 == 3位”
“收到”
“主人,7说他找4核实了下,0位 == 3位,并且 7位 他自己 next 是4,表明 0123 == 3456,我画了个图”
0
|
3
上面是7从4那得来的消息:0 == 3
0123
| |
3456
上图是7自己的消息 0 == 3、1 == 4 、2 == 5、3 == 6

“知道了,说那么多屁话干啥?主要信息不就是 0 == 3 == 6吗?你下去吧,我直接 0 跟 6 不用比较了,1 跟 7 比,next[7] 存的就是4,next[4] 存的就是 1 ,如果相等,next[8] 就是 2,即0 == 6,1 == 7,即 01串 == 67串,8位 直接找 2位,拉到 2位,即 子串 2位 跟 主串 8位 开始比就行了”
我感觉有点:传递性、回溯,递归,深搜,辗转相除,链式前向星 的味道。
“但现在1根7不等,t[1] ≠ t[7]”
“那好办,按照上面的再去往前找,1位 next 存的是0,t[7] 跟 t[0] 比较”
“大人,相等”
“好都加1,8位不匹配,直接拉到这就行了,主串 8位 只用从 子串的 1位 开始比就行”
位置: 0 1 2 3 4 5 6 7 8 9 A B
主: a b b a b b a a b c c a
子: a b b a b b a a a
位置: 0 1 2 3 4 5 6 7 8
next: -1 0 0 0 1 2 3 4 1
至此应该讲的很透彻了,但我又有个疑问,这tm咋越不匹配,拉的越多呢??想想确实是,
拉的越快代表差的不同越离谱,尽早结束,拉的慢代表给你机会,有很多可以匹配上的点位
如果子串每一位的 next 都是0,那直接就主串每一个不同的,都把子串拉过来从 0位 开始匹配比较就行了,
可如果next数字比较大,不是0,比如是5,那意味着你主串不匹配的那块,要把子串拉到5的位置,肯定往后移动的慢
就好比你抽插山岸逢花,你是她的主人,先是头和头贴贴,然后舌头跟舌头贴贴,等到她的禁区小穴跟你的武器帖的时候,你说不爽,她问你从哪开始不爽了呢?你如果说前面都不爽,那她直接从头过来跟你的武器匹配,但你如果说胸部开始不爽,她就会从头开始跟你的胸部匹配贴贴。显然哪里都匹配不上的情况,她下降到你的脚趾头是最快的。
滴蜡安全词:你没吃饭吗
再说图4,此博客搜“开始解释next数组”,这句下面的那个图,图4,模式串是:aaba

位置: 0 1 2 3
子串: a a b a
next: -1 0 1 0
next[2] 是 1,因为子串 t[0] ==t[1],到了3位,这个简单直接考虑自己这个串就行,在2给他做铺垫的时候,如果 t[1] == t[2],直接都加1,next[3] 是 2,因为 0 == 1 且 1 == 2,那 01串 就等于 12串
但 t[1] ≠ t[2],那给你机会让你 01 可能等于 12,你不等,就没说的了,你只剩一个选择了,你 2位 去直接跟 1位 记录的 next 比较吧,next[1] 是 0,如果 t[2] == t[0] ,那就都加1,next[3] 就是 1,
但 t[2] ≠ t[0],那拉JB倒,你是 next[0] 记录的值,即-1,到时候都加1,next[3] 是 0
至此KMP算法的 next数组代码方面 有了些许了解了
其实,我觉得我够有强迫症的了,很不好,就是根本不会投机取巧,不会架空空中楼阁那样学东西(19考研BUPT复试机试AK第一那个276分的大佬),要么不学,学必须搞到这么透彻才罢休。
但我也只是从验证角度来试图理解、了解这个算法的表面,感觉足够了,你要比我还强迫症,想知道这个算法咋来的,为啥能想到 else k=ne[k]; ,我建议你亲自去问问Knuth前辈本人(考研概率论张伟口头禅哈哈),这前辈1938年出生的。
别忘了有几个事还没去解决:(随时更新)
0、之后咋弄(已解决:就正常往后走,用这句话 while(i<s.length && j<t.length) 来控制结束与否)
1、复杂度 (已解决:根据 祖师爷 的代码就显然了,子串长度 m 求 next 数组,主串长度 n 来遍历匹配)
2、length - 1 和 length (已解决:其实道理很简单,如下图:其实本身就9个字符“abbabbaaa”,最大 next[8],这里体现了未雨绸缪,把 next[9] 给提前整出来了而已。刷题的时候注意下是否越界就好。再次证明了 next[9] 其实和 子串t[9] 没任何关系)

开始看匹配,继续看 KMP祖师爷 里的代码,
他的这个优化太牛逼了,
如果t[j+1] == t[k+1] , next[j+1] = next[k+1],而不是next[j+1] = k+1。
其实不用看+1,反而看不懂,就很轻松的看,当作 j 和 k 就行。简单解释两句,

此时 6位 的是A,next[6]是 3,因为 012 == 345,这个祖师爷 的 优化KMP 其实就是说,你 6位 不匹配的时候,正常是拉到 next[6] 存的3那个位置,但之前说了,朴素版里的
if(k==-1||t[j]==t[k]){ j++;k++; ne[j] = k; }
这玩意是 未雨绸缪 做铺垫用的,求 next[6] 的时候,其实是 next[5]求完就开始搞 next[6] 了,那优化KMP里
if(k == -1 || t[j] == t[k]) { j++;k++; if(t[j]==t[k])//当两个字符相同时,就跳过 next[j] = next[k]; else next[j] = k; }
其实就多了一个 if(t[j]==t[k])//当两个字符相同时,就跳过 next[j] = next[k]; 就是说你子串跟主串不匹配的时候是, 比方说是 6位 ,那判断 6位 的字符,是不是跟朴素法里本应记录的k,也就是最长公共前后缀,字符相同,注意 j k 都++了,但还没赋值给 next[j] ,6位 的 k 是 3,本应该是把这个 3 赋值给 next[6],但多了个优化,如果 t[6] 和 t[3] 相等,就别赋值了,必定跟主串还是匹配不上,直接把 3 的 next 值给 6 吧。即 next[j] = next[k];
但祖师爷最后这个“下面直接附上全部KMP算法”,代码没法上下滑动呀,哈哈只能赋值按钮到codeblock来看了
随手放一个 KMP祖师爷 博客里,两段代码组合起来的代码,重点前面都说过了
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int ne[10]; 6 int main() 7 { 8 // string t="aaba"; 9 string t="abbabbaaa"; 10 // string t="aqbaqbaqa"; 11 cout<<t.length()<<endl; 12 int j=0,k=-1; 13 ne[0]=-1; 14 while(j<t.length()){//开始求next 15 if(k==-1||t[j]==t[k]){ 16 j++;k++; 17 ne[j] = k; 18 } 19 else k=ne[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神! 20 if(k>=0) 21 cout<<"j:"<<j<<" k:"<<k<<" ne["<<j<<"]:"<<ne[j]<<endl; 22 if(k<0) 23 cout<<"j:"<<j<<" k:"<<k<<" ne["<<j<<"]:"<<ne[j]<<endl; 24 }cout<<endl; 25 for(int i=0;i<t.size();i++) 26 cout<<i<<" "<<ne[i]<<endl;//next赋值结束 27 28 while(i<s.length && j<t.length)//开始匹配 29 { // 从模式串j = 0 开始匹配 30 if(j==-1 || s[i]==t[j]) 31 { 32 i++; 33 j++; 34 } 35 else j=next[j]; //j回退。。。若j = -1,说明模式串回退到了起点0 36 } 37 if(j>=t.length) 38 return (i-t.length); //匹配成功,返回子串的位置 39 else 40 return (-1); //没找到 41 }
运行肯定不过,我只是随手一贴,切题的时候重新写的,尽量忘记他代码,根据算法去写,原因之前说过很多次了。但这个KMP感觉还是背模板比较好,太高深了,这是我第一次背代码。或者说,需要这种很难的算法,背代码没问题,但别特意背,理解思想,开始写的时候,就不要再去看别人的代码了,边默写边思考算法含义,但一定会因为小细节写不对,这时候一定一定不要去回去再看他的代码,哪一步什么含义干什么用的,自己调试出来,,不然就真没任何意义了。但也别太死板,一个代码调试一整天还没调试出来的话,就看下吧,我说的是基础KMP,如果是题目WA那另说,大概也是1天没A掉再看题解,前提基础算法代码写的没问题
至此 KMP 有了略微清晰的了解了,开始切题。
写了个代码,明显感觉代码能力有提升,有质的飞跃了了,就是很灵活既能结合祖师爷的代码和KMP的思想,又不拘泥于他的代码,大胆改动,其中一些我觉得有疑惑的地方都注释了出来,很值得看,结果提交TLE了
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 //string a[1000001];//麻痹的搞错了,误以为是数组了 7 //string b[10001]; 8 string a; 9 string b; 10 int ne[10001];//给子串b用的 11 int main() 12 { 13 // freopen("zhishu.txt","r",stdin); 14 cin>>T; 15 while(T--){ 16 // a={}; 17 a=""; 18 b=""; 19 int n,m; 20 cin>>n>>m; 21 22 char str; 23 for(int i=0;i<n;i++){ 24 cin>>str;//string不吃空格 25 a+=str; 26 // a[i]=c;//std:string类型是一个动态大小的字符串,它不能直接当作字符数组来使用 27 } 28 for(int i=0;i<m;i++){ 29 cin>>str; 30 b+=str; 31 } 32 // 开始求子串b的next 33 int len_a=a.length()-1;//由于说ab长度都是≥1,所以不用考虑0-1那个事。还有就是验证过,长度为9,0~8,只需要j跑到7就可以得到8的next值,故7就是<(长度-1) 34 int len_b=b.length()-1; 35 36 int j=0; 37 int k=-1; 38 memset(ne,0,sizeof(ne)); 39 ne[0]=-1; 40 // cout<<len_b<<endl; 41 while(j<len_b){//这玩意纯纯趁热乎写的,过一个月我啥也不会了。q神想破脑袋的怎么可能忘掉——岛娘忘记题目思路但会记得当时切题的感觉——q神校友51nod站长:想破脑袋才有提升 42 if(k==-1 || b[j]==b[k]){ 43 j++; 44 k++; 45 if(b[j]==b[k])//KMP优化 46 ne[j]=ne[k]; 47 else 48 ne[j]=k; 49 } 50 else 51 k=ne[k]; 52 } 53 // for(int i=0;i<b.length();i++) 54 // cout<<ne[i]<<" "; 55 56 // 开始匹配 57 int i=0; 58 // int j=0;//定义过了,不能重复定义 59 j=0; 60 while(i<a.length() && j<b.length()){ 61 if(j==-1) 62 j++;//这里跟祖师爷不一样 63 if(a[i]==b[j]){ 64 i++; 65 j++; 66 } 67 else{ 68 j=ne[j]; 69 } 70 } 71 if(j==b.length())//找到了就是这个,找不到的话子串中的字符会匹配到超出主串的 72 //展开说能匹配上: 73 // 主的指针: 74 // 要么还在主串里,子的指针在串外,比如主abb,子ab 75 // 要么就在主串外,子的指针在串外,主跟子都到最后一个就跳出循环结束了,比如主aab,子ab 76 // 子指针:一定是在最末尾的后一个,都匹配结束 77 // 78 // 不能匹配上: 79 // 应该就一种可能吧,就是子串还没匹配完,主串干出去了,匹配结束了 80 // 或者可以剪枝,直接就是主串当前指针之后的字符数量,比子串当前指针之后的字符数量少,那还各自++个屁,直接不可能匹配成功 81 82 83 // cout<<"yes";//这里感觉祖师爷写的那个i-j.length也不对,都应该到尾巴了啊,如果匹配OK的话 84 cout<<i-b.length()+1<<endl; 85 else if(j>b.length()) 86 cout<<"-1"<<endl; 87 } 88 } 89 //为啥非得要-1啊???
先不说他祖师爷的代码,我光看我写的代码是一点问题没有的,算法写的没问题,既然超时去检查各种细节,比如主串子串都是1,最小值这些,或者哪些特殊点导致死循环之类的
随便试了几个发现反例:
1
3 1
abc c
居然输出-1
简单测试了下发现
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 string a; 7 string b; 8 int ne[10001]; 9 int main() 10 { 11 freopen("zhishu.txt","r",stdin); 12 cin>>T; 13 while(T--){ 14 a=""; 15 b=""; 16 int n,m; 17 cin>>n>>m; 18 19 char str; 20 for(int i=0;i<n;i++){ 21 cin>>str; 22 a+=str; 23 } 24 for(int i=0;i<m;i++){ 25 cin>>str; 26 b+=str; 27 } 28 29 // 开始求子串b的next 30 int len_a=a.length()-1; 31 int len_b=b.length()-1; 32 33 // cout<<len_a<<" "<<len_b<<endl; 34 35 int j=0; 36 int k=-1; 37 memset(ne,0,sizeof(ne)); 38 ne[0]=-1; 39 while(j<len_b){ 40 if(k==-1 || b[j]==b[k]){ 41 j++; 42 k++; 43 if(b[j]==b[k])//KMP优化 44 ne[j]=ne[k]; 45 else 46 ne[j]=k; 47 } 48 else 49 k=ne[k]; 50 } 51 52 // 开始匹配 53 int i=0; 54 j=0; 55 cout<<a.length()<<" "<<b.length()<<endl; 56 while(i<a.length() && j<b.length()){ 57 cout<<1<<endl; 58 if(j==-1) 59 j++; 60 if(a[i]==b[j]){ 61 i++; 62 j++; 63 cout<<"#"<<i<<" "<<j<<endl; 64 } 65 else 66 j=ne[j]; 67 68 cout<<"@"<<j<<endl; 69 if(j<b.length()) 70 cout<<"&"<<endl; 71 if(j>b.length()){ 72 73 cout<<"^"<<j<<" "<<b.length()<<endl; 74 } 75 } 76 if(j==b.length()) 77 cout<<i-b.length()+1<<endl; 78 else if(j>b.length()) 79 cout<<"-1"<<endl; 80 } 81 }
里面的这句
if(j>b.length()){ cout<<"^"<<j<<" "<<b.length()<<endl; }
j 是 -1,b.length()是1,他俩比较居然会是 j > b.length(),会输出下面那一行,根据之前GPT告诉我的,大概懂啥意思,又问了下GPT

但这个例子只是错了,HDU的TLE的例子没找到,肯定是哪里溢出导致的不去纠结这里。
试着改了一下
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 string a; 7 string b; 8 int ne[10001]; 9 int main() 10 { 11 freopen("zhishu.txt","r",stdin); 12 cin>>T; 13 while(T--){ 14 a=""; 15 b=""; 16 int n,m; 17 cin>>n>>m; 18 19 char str; 20 for(int i=0;i<n;i++){ 21 cin>>str; 22 a+=str; 23 } 24 for(int i=0;i<m;i++){ 25 cin>>str; 26 b+=str; 27 } 28 29 // 开始求子串b的next 30 int len_a=a.length()-1; 31 int len_b=b.length()-1; 32 33 // cout<<len_a<<" "<<len_b<<endl; 34 35 int j=0; 36 int k=-1; 37 memset(ne,0,sizeof(ne)); 38 ne[0]=-1; 39 while(j<len_b){ 40 if(k==-1 || b[j]==b[k]){ 41 j++; 42 k++; 43 if(b[j]==b[k])//KMP优化 44 ne[j]=ne[k]; 45 else 46 ne[j]=k; 47 } 48 else 49 k=ne[k]; 50 } 51 52 // 开始匹配 53 int i=0; 54 j=0; 55 // cout<<a.length()<<" "<<b.length()<<endl; 56 while(i<a.length() && j<b.length()){ 57 cout<<1<<endl; 58 if(j==-1) 59 j++; 60 if(a[i]==b[j]){ 61 i++; 62 j++; 63 // cout<<"#"<<i<<" "<<j<<endl; 64 } 65 else{ 66 j=ne[j]; 67 // cout<<"#"<<j<<endl; 68 // if(j<0)//想处理下无符号和有符号的事,结果这样写直接tm死循环了。我估计 69 // j++; 70 //cout<<j-b.length()<<endl; 71 } 72 73 cout<<"@"<<j<<endl; 74 } 75 if(j==b.length()) 76 cout<<i-b.length()+1<<endl; 77 else if(j>b.length()) 78 cout<<"-1"<<endl; 79 } 80 }
发现不行,对于例子
1 3 1 abc c
本来应该输出3,结果因为 j 是 -1,跟length()比较的时候,有无符号导致溢出 j 无穷大,直接跳出了,导致输出-1,
考虑代码哪里可以改进,发现就算-1正常跟length比,进去循环了,这样写
1 while(j==-1 || (i<a.length() && j<b.length())){ 2 cout<<1<<endl; 3 if(j==-1) 4 j++; 5 if(a[i]==b[j]){ 6 i++; 7 j++; 8 // cout<<"#"<<i<<" "<<j<<endl; 9 } 10 else{ 11 j=ne[j]; 12 // cout<<"#"<<j<<endl; 13 // if(j<0)//想处理下无符号和有符号的事,结果这样写直接tm死循环了。我估计 14 // j++; 15 //cout<<j-b.length()<<endl; 16 } 17 18 cout<<"@"<<j<<endl; 19 }
也依旧是死循环,每次都是主串跟子串的0位开始点,总是不匹配,感觉主串指针应该往前走一下啊,但是其他例子比如
abbabbbaa
abbb
确实没问题的
进一步发现只要涉及到 j 为-1就会乱套。看下祖师爷的代码
不,等下,这个-1在求next数组的时候,很好的加1,当作了一个特殊标志,那我求完之后,把 next[0] 赋成0行不行呢?
麻痹的还是不行,都赋成0,会导致
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 string a; 7 string b; 8 int ne[10001]; 9 int main() 10 { 11 freopen("zhishu.txt","r",stdin); 12 cin>>T; 13 while(T--){ 14 a=""; 15 b=""; 16 int n,m; 17 cin>>n>>m; 18 19 char str; 20 for(int i=0;i<n;i++){ 21 cin>>str; 22 a+=str; 23 } 24 for(int i=0;i<m;i++){ 25 cin>>str; 26 b+=str; 27 } 28 29 // 开始求子串b的next 30 int len_a=a.length()-1; 31 int len_b=b.length()-1; 32 33 int j=0; 34 int k=-1; 35 memset(ne,0,sizeof(ne)); 36 ne[0]=-1; 37 while(j<len_b){ 38 if(k==-1 || b[j]==b[k]){ 39 j++; 40 k++; 41 if(b[j]==b[k])//KMP优化 42 ne[j]=ne[k]; 43 else 44 ne[j]=k; 45 } 46 else 47 k=ne[k]; 48 } 49 for(int i=0;i<b.length();i++) 50 if(ne[i]==-1) 51 ne[i]=0; 52 53 for(int i=0;i<b.length();i++) 54 cout<<ne[i]<<endl; 55 // 开始匹配 56 int i=0; 57 j=0; 58 while((i<a.length() && j<b.length())){ 59 // if(j==-1) 60 // j++; 61 //cout<<"$"<<endl; 62 if(a[i]==b[j]){ 63 i++; 64 j++; 65 } 66 else 67 j=ne[j]; 68 } 69 if(j==b.length()) 70 cout<<i-b.length()+1<<endl; 71 else if(j>b.length()) 72 cout<<"-1"<<endl; 73 } 74 }
3 1 abc
c
一样的死循环,始终主串和子串0位比较,放弃,看祖师爷匹配这块咋写的。
发现祖师爷另一个错误是没考虑溢出这个事,这位博主应该是对KMP相当了解,理论很强,但没刷过题
但从祖师爷那学到一个牛逼写法是
if(j==-1 || s[i]==t[j]) { i++; j++; } else j=next[j];
很巧妙的把不匹配的变成 -1,然后同时加1 ,这样就变相的让 j 往前走了一步不至于死循环,我如果自己不提前写一下,从一开始就背他的代码,一定不会发现这里的神奇之处。溢出的问题自己处理下就好。
操泥妈一直TLE,刚反应过来,cin的缘故
改完后,一直RE,发现scanf那吃空格各种细节搞错了
操你马的,getchar吃空格和回车吗(百度查说不吃回车,吃空格)、scanf读取char类型,读回车和空格吗?(查百度说不吃回车,但直接试验是读空格也读回车)
char aaa; while(scanf("%c",&aaa)) cout<<"#"<<aaa<<"#"<<endl;
输入空格敲回车,输出
# #
#
#
只输入个回车,输出##之间有个回车,妈逼的傻逼百度
证明scanf读取char的时候,读空格,读回车,缓存里有也会读取
下图GPT:

下图百度搜索:

这俩玩意不是一个妈生的吗???真心烦! 边学东西边给你们挑错
这些基础问题真他妈的好烦!!!
先搁置,回头好好修理修理这些问题。
修改后代码如下:
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 string a; 7 string b; 8 int ne[10011]; 9 int main() 10 { 11 // freopen("zhishu.txt","r",stdin); 12 scanf("%d",&T); 13 while(T--){ 14 a=""; 15 b=""; 16 int n,m; 17 scanf("%d%d",&n,&m); 18 getchar();//输入完n和m还有个回车艹 19 char str; 20 for(int i=0;i<n;i++){ 21 scanf("%c",&str); 22 // if(str==" ") 23 if(str==' ') 24 scanf("%c",&str); 25 a+=str; 26 } 27 getchar();//上一个输入完敲的回车也要 28 for(int i=0;i<m;i++){ 29 // cin>>str; 30 scanf("%c",&str); 31 if(str==' ') 32 scanf("%c",&str); 33 34 b+=str; 35 } 36 37 // 开始求子串b的next 38 int len_a=a.length()-1; 39 int len_b=b.length()-1; 40 41 int j=0; 42 int k=-1; 43 memset(ne,0,sizeof(ne)); 44 ne[0]=-1; 45 while(j<len_b){ 46 if(k==-1 || b[j]==b[k]){ 47 j++; 48 k++; 49 // if(b[j]==b[k])//KMP优化 50 // ne[j]=ne[k]; 51 // else 52 ne[j]=k; 53 } 54 else 55 k=ne[k]; 56 } 57 58 // 开始匹配 59 int i=0; 60 j=0; 61 // while(j==-1 || (i<a.length() && j<b.length())){//为啥这句不对啊?样例 62 while((i<a.length() && j<b.length())){ 63 // if(j==-1 || a[i]==b[j]){ 64 if(a[i]==b[j]){ 65 i++; 66 j++; 67 } 68 else{ 69 j=ne[j]; 70 // if(j==-1){//防止溢出while那有无符号比较 71 // i++; 72 // j++; 73 // } 74 } 75 // cout<<1<<endl; 76 } 77 // cout<<j<<endl; 78 if(j==b.length()) 79 cout<<i-b.length()+1<<endl; 80 else 81 cout<<"-1"<<endl; 82 } 83 }
操了,改完又TLE了,先注释掉匹配算法,还是TLE,再注释掉求 next 的代码发现WA了,说明求next数组那里有问题
查了下题解发现大家都用数组,感觉可能是输入的时候string字符反复拼接那块超时了
修改下,麻痹的惊了,AC了,
AC代码

1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 int a[1000001]; 7 int b[10001]; 8 int ne[10011]; 9 int main() 10 { 11 // freopen("zhishu.txt","r",stdin); 12 scanf("%d",&T); 13 while(T--){ 14 int str; 15 int n,m; 16 scanf("%d%d",&n,&m); 17 for(int i=0;i<n;i++){ 18 scanf("%d",&str); 19 a[i]=str; 20 } 21 for(int i=0;i<m;i++){ 22 scanf("%d",&str); 23 b[i]=str; 24 } 25 26 // 开始求子串b的next 27 int j=0; 28 int k=-1; 29 memset(ne,0,sizeof(ne)); 30 ne[0]=-1; 31 while(j<m-1){ 32 if(k==-1 || b[j]==b[k]){ 33 j++; 34 k++; 35 if(b[j]==b[k])//KMP优化 36 ne[j]=ne[k]; 37 else 38 ne[j]=k; 39 } 40 else 41 k=ne[k]; 42 } 43 44 // 开始匹配 45 int i=0; 46 j=0; 47 48 //改代码后不涉及length,就怎么写都行了 49 while(i<n && j<m){ 50 // if(j==-1 || a[i]==b[j]){ 51 if(a[i]==b[j]){ 52 i++; 53 j++; 54 } 55 else{ 56 j=ne[j]; 57 if(j==-1){//防止溢出while那有无符号比较 58 i++; 59 j++; 60 } 61 } 62 } 63 if(j==m) 64 printf("%d\n",i-m+1); 65 // cout<<i-m+1<<endl; 66 else 67 printf("-1\n"); 68 // cout<<"-1"<<endl; 69 } 70 }
心路历程真的难受



期间还用了 different网站 找了下不同,
时间限制是500ms,我4800ms,HDU最快的居然不到78ms,发现vjudge里有个 博主 1100ms,加了快读,那就没啥纠结的了
小总结一下:
0、cin一定超时TLE,必须scanf,看来无论是POJ还是HDOJ,cin都是切切实实的很慢
1、我AC的代码,最后输出printf改成cout,提交到HDOJ有时候4800msAC,有时候5000msTLE,之前就发现过,同样的代码每次提交返回的AC时间都会不同,大概测评机那时候提交人数原因不纠结,这里TLE耽误了我好久,我从来没想到cout也会TLE
2、最重点的来了,字符串拼接到底效率咋样?昨天调试的时候,百度搜 “acm竞赛string拼接会导致超时吗” 也没搜到啥,感觉会比较耗时就特意试了下,就单独把a这个主串改成string,用字符串拼接,发现直接TLE了,TLE代码
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 int T; 6 string a; 7 int b[10001]; 8 int ne[10011]; 9 int main() 10 { 11 // freopen("zhishu.txt","r",stdin); 12 scanf("%d",&T); 13 while(T--){ 14 a=""; 15 int str; 16 int n,m; 17 scanf("%d%d",&n,&m); 18 getchar(); 19 for(int i=0;i<n;i++){ 20 char str; 21 scanf("%c",&str); 22 if(str==' ') 23 scanf("%c",&str); 24 a+=str; 25 } 26 for(int i=0;i<m;i++){ 27 scanf("%d",&str); 28 b[i]=str; 29 } 30 // cout<<a<<endl; 31 32 // cout<<endl; 33 34 // 开始求子串b的next 35 int j=0; 36 int k=-1; 37 memset(ne,0,sizeof(ne)); 38 ne[0]=-1; 39 while(j<m-1){ 40 if(k==-1 || b[j]==b[k]){ 41 j++; 42 k++; 43 if(b[j]==b[k])//KMP优化 44 ne[j]=ne[k]; 45 else 46 ne[j]=k; 47 } 48 else 49 k=ne[k]; 50 } 51 52 // for(int i=0;i<m;i++) 53 // cout<<ne[i]<<" "; 54 // cout<<endl; 55 // 开始匹配 56 int i=0; 57 j=0; 58 //cout<<"@"<<a[0]<<" ^"<<a[0]-48<<endl; 59 //改代码后不涉及length,就怎么写都行了 60 while(i<n && j<m){ 61 // if(j==-1 || a[i]==b[j]){ 62 if(a[i]-48==b[j]){ 63 i++; 64 j++; 65 // cout<<"$"<<j<<endl; 66 } 67 else{ 68 j=ne[j]; 69 if(j==-1){//防止溢出while那有无符号比较 70 i++; 71 j++; 72 } 73 } 74 } 75 // cout<<"#"<<j<<endl; 76 if(j==m) 77 printf("%d\n",i-m+1); 78 // cout<<i-m+1<<endl; 79 else 80 printf("-1\n"); 81 // cout<<"-1"<<endl; 82 } 83 }
所以之前刷的迷宫问题,用字符串拼接只是题目要求的数据量不多而已,以后知道 string拼接会慢 就行了,不至于再傻逼呵呵找一天都找不出问题
另外无意间发现的小知识点,就是主串a(string拼接的)和子串b(整型数组),比较的时候,要减去48,

至此KMP有了些许了解了。
还剩几个写代码时候遇到后搁置的小问题没解决,回顾一下:
0、总结下那几个读字符的老大哥 (先说下啥叫“吃”,就是读取的意思,scanf 读一个 int 型的 a 变量,输入 整型 a 之前,你输入一堆空格,scanf是不读取的,从输入到整型数字开始读取,作为 a变量 的值,这里scanf读取int就是不吃空格的,说法不严谨,但是最接地气最好理解的), 像 制表符 那些玩意用不到,我也没去测
———— getchar()这玩意吃空格、吃回车,缓冲区里有也会吃,我理解为啥都吃 。不只是char,string类型的也一样
char c; while(c=getchar()){ cout<<"#"<<c<<"#"<<endl; }
———— scanf()读取char,前面说过,也是吃空格,吃回车,缓冲区里有也会吃,我理解为啥都吃。但scanf不处理string类型,string是C++,scanf只是C的工具。
但注意scanf读char是啥都吃,如果读字符数组就不一样了,不吃空白字符
#include <stdio.h> int main() { char str[100]; while(scanf("%s", str)) printf("%s\n", str); }
输入
abcds 5 dfg4r
输出
abcds 5 dfg4r
对于前面的回车,之间的那些的空格,都不会读取。
———— cin不吃空格,不吃回车。回车当作输入结束标志
char c; while(cin>>c){ cout<<"#"<<c<<"#"<<endl; }
输入“空格空格回车asd b”只输出asdb
如果是string类型,一样不吃空格回车。回车当作输入结束的标志
string str; while(cin>>str){ cout<<str<<endl; }
输入
bc sdf 4f
输出
bc
sdf
4f
———— getline()吃空格,不吃回车,标准输入std::cin中读取一行文本,并将其存储在字符串line中,遇到回车结束,回车不读,只是做一个标志,遇到回车就结束读取
string str; while(getline(cin,str)){ cout<<"#"<<str<<"#"<<endl; }
就这么几个,总结多了屁用没有,over
1、string可以像数组那样用下标访问
2、求next的时候,少一个就行,即上面说的length - 1 和 length 那
3、祖师爷的KMP优化那里从HDOJ测评机上没看出跟不优化有啥差别,但绝对是优化了
4、验不涉及string求长度, .length() 就用不到了,因为有 n 和 m,所以之前代码里像规避这个问题的 “防止溢出while那有无符号比较” 写法就测不出来对不对了,先搁置
5、最后就是 if(j==m) ,验证了判断是否匹配的输出思路是对的,不用像祖师爷那样写成大于等于
其他备注:
###:发现acm并不能让人变聪明,这个KMP最终也只会是孰能就生巧了,再遇到这么难的算法,只是知道往哪个方向上想,怎么理解并会用这个算法,但依旧会很费劲,所以并不能提高智力,只是熟练度。就比如之前的并查集路径压缩find函数,路径压缩叫的那么高大上,但其实就是那么点事,可以我每次写也只是脑海里熟能生巧,具体原理能知道咋回事,但并不是每次写都想原理再写,所以acm并不能让人变聪明,我还是那么笨~~~~(>_<)~~~~╮(╯▽╰)╭
###:之前学的时候,全网找的一堆博客既不能保证讲的是对的,写的又多,既有逻辑错误也有口误笔误,那些狗逼博主有些自己都不懂,所以不敢花时间去看那些臃肿的博客,怕看了也浪费时间,但你信我,看我这一篇文章就够了,又不懂的直接加我微信给你讲
###:感觉我的思维好固化死板,~~~~(>_<)~~~~
###:关于 string 初始化

###: 关于 scanf 非法
###:无意间学到的小知识:
关于string是否吃空格,cin是否吃空格,getline是否吃空格

string str1; string str2; cin>>str1; cout<<str1<<endl; getline(cin, str2); cout<<str2<<endl;
对于输入abc ddd,str1会读取abc,str2会读取abc ddd
###:大旗 气场 震慑 BUPT(北邮 空中楼阁 架空学习)
FZU2150-Fire Game  仅仅登陆可见
仅仅登陆可见
A Bug's Life  审核未通过仅自己可见
审核未通过仅自己可见
浏览量增多会有更多的文章被搞
###:现在CSDN的代码好像都没法看全部了,没滑动按钮,都只显示一半艹,垃圾玩意

不知道咋回事下一秒又这样了

真他妈无语,这排版看着真费劲
后来打开一下ADblock自己就好了
###:狗逼培训班把行业搞的乌烟瘴气恶臭,乌鲁木齐银行你在这埋没人才了“自学的有些基础都不会,培训班出身的好”,呵呵呵呵呵,像KMP这样的思维难度,不比那些狗逼做10个所谓的项目有含金量,看他们网上简历项目写的都直吓人,太恐怖了,然后还说没offer,狗屁不是,什么让公司收益实现从xxx到xxxxx的翻倍,什么让并发量,让公司服务器承载客户量规模,去你妈的吧。之前粪坑银行外包测试,我会XXXXXx真恶心
###:实验室只有我不知道 next 不能做变量名
###:博客园的编辑器真难用:
粘贴后直接给你编辑框搞到最下
保存的时候没法上下滑动编辑框,
保存的时候点击编辑框任意位置直接掉到最文末
还好审核比较好,可以文章里骂人
特殊格式的文字粘贴进来,如果删掉或者怎样,这些垃圾字符会莫名其妙在文章最末尾出现,好多好多,要删除好久。很烦很烦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号