
POJ2492-A Bug's Life
继续刷邝斌飞并查集专题
POJ2492 (10s、64M)
洛谷 (189ms、1.46G)
可用平台 (10s、64M)
洛谷翻译跟个智障一样,复制到百度翻译懂了,这题读完立马起手想错误话问题,重复
再次感觉acm题目描述很棒,很有内味,题目刷多了就知道了,其实原文: followed by one line saying either “No suspicious bugs found!” if the experiment is consistent with his assumption about the bugs’ sexual behavior, or “Suspicious bugs found!” if Professor Hopper’s assumption is definitely wrong. 描述并不好,应该依照食物链题目来描述,即对于每一种关系,如果能确定,一定与教授观点相违背,则认为是可疑的,否则就认为教授观点没毛病。总共就俩答案,没有输出模棱两可的,所以默认就是异性,除非遇到了类似环吃的才说有问题
范围:
第一行是T组实验数据,但T没说范围。
之后的每组第一行是n(2000)为虫子数量,和m(10^6)为关系数量。
注意:
0、虫子从1开始连续编号。原文: Bugs are numbered consecutively starting from one.
1、每组输入这个我不确定 是不是 不同的。原文是: In the following lines, each interaction is given in the form of two distinct bug numbers separated by a single space. ,这里的 two distinct bug numbers 翻译成不同的虫子编号也行,翻译成明确的虫子编号也行,有点歧义。但搜了下英语释义,好像是翻译成“不同”的意思,也对,你总不能自交自慰,即自己JB插自己PY吧,绕大树光速跑吗
简单画了个图,发现如果有环,不能是奇数,理解成玩交换(妻)群p,男1→女1→男2→女2→男1,成偶数个环,必须成对出现。像这种男1→女1→男2→男1,则不行,出现了单男。
对比食物链那个题,比如告诉你1和3同A类,2吃4,但没法判断2是A/B/C哪一类,如果你随便设一个2是B类,那只要再说2和1是同类就会被误判为错,但其实是可以的。总结就是当前的状态是未知的,你随意赋种类会对后面产生影响。
而这个题就俩性别,1若跟3有关系,那我可以大胆假设1是男、3是女,再来句3和4有关系那4就是男,如果4和1再有关系那必然错,因为1男→3女→4男→1男,成了奇数环。即一个长串男女男女...这样接下去,再交叉一个男女男女的长串没问题,但只要中间某两个人牵线有关系了,那就是环,就要判断成环个数了,
但又想,比如12345分别为男女男女男,那突然说1和4有关系,我就要写个从1find到4的函数,看经历了几个点,有点der,太费时间了,而且稍微变一下,比如1 2有关系,你1指向2了,又说1 3 有关系,你咋处理?1已经有指向2了,再2指向3?2和3显然同性别,你这么指向了咋区分是不是可疑同性?
那2指向相反数?-3咋样?或者做个小标记?表示我指向你跟你没关系,纯粹是我异性伴侣跟你有关,有点乱但有点带权并查集向量的感觉了。
或者开vector?1有多个爹?既指向2又指向3?也不太好搞
。那我不如这样,你并查集反正也是指向根,比如345是一类,那45都指向3,789是一类就89指向7,但发没发现,所谓的指向无非就是数组而已,进一步说,我自己理解并查集就是相当于一个结构体,里面有个成员变量叫x的话,那数组下标为4和5的点x成员变量里面值存的都是3,数组下标是8和9的点x成员变量里面存的值都是7,比如分桌子那道题我这样写


1 #include<stdio.h>
2 #include<string.h>
3 #include<iostream>
4 using namespace std;
5 #define MAX 1001
6 int T;
7 int N,M;
8 //int node[MAX];//记录根
9 struct Node
10 {
11 int pre;
12 }node[MAX];
13 void init()
14 {
15 for(int i=1;i<=N;i++)
16 node[i].pre=i;
17 }
18 int find(int x)
19 {
20 if(x==node[x].pre)
21 return x;
22 node[x].pre=find(node[x].pre);
23 return node[x].pre;
24 }
25 int num[MAX];
26 int main()
27 {
28 while(cin>>T){
29 while(T--){
30 cin>>N>>M;
31 init();
32 for(int i=1;i<=M;i++){
33 int a,b;
34 cin>>a>>b;
35 int root1=find(a);
36 int root2=find(b);
37 node[root1].pre=root2;
38 }
39 int ans=0;
40 memset(num,0,sizeof(num));
41 for(int i=1;i<=N;i++){
42 int root=find(i);
43 if(num[root]==0)
44 ans++;
45 num[root]=1;
46 }
47 cout<<ans<<endl;
48 // cout<<endl;
49 }
50 }
51 }
依旧AC,其实看似差不多,那我刷了这么多题突然感觉并查集其实就是开个数组,记录某数位置而已,没啥特别的,不用理解成指向根这个事,那我直接把每个,都弄成结构体的成员点x为0代表男,结构体的成员点x为1代表女,这样,我草你奶奶想错了,这题根食物链一样,哪怕只有俩性别依旧不能指定,比如1 2如果你说1男2女,那3 4你说3男4女,那再来句1 3,本来可以是没问题的关系,这么一整就有问题了。不觉得想这么久却错了有什么不好的,思维碰撞的升华对理解并查集解有好处,老老实实写种类并查集吧。
可是画俩集合,比如1 2有关系,那A集合的1指向B集合的2,先不说B集合,然后1 3有关系,那A集合的1指向B结合的3,1根是2,那B集合的2指向A集合的3,可是2跟3没关系啊,至此我想到了上一个种类并查集食物链那个题目,搜“啥道理??”,也是有个没关系的指了,但那个有顺逆时针,这里感觉硬对也对不上啊。POJ10s会不会没压缩路径?
挣扎一下看看能不能构造出来,面向图思路想编程 —— (注意:我图画错了!!!后面有说。这句话是AC完回来更新的)
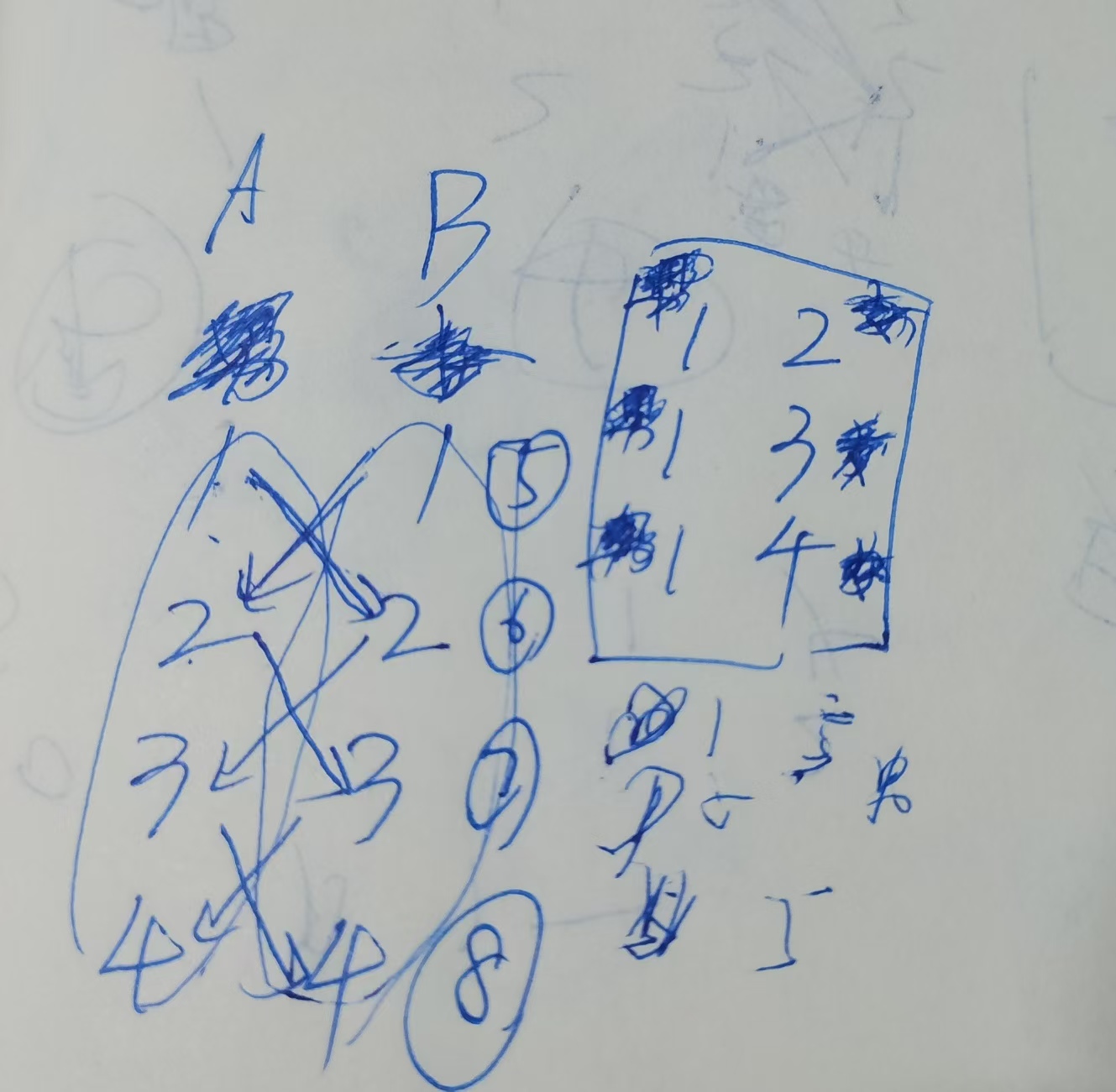
1 2有关系,1指向⑥,⑤指向2
1 3有关系,⑥指向3,2指向⑦
1 4有关系,3指向⑧,7指向4
(为了方便,先不看4 ⑧那个,就123仨人)
现在构造,发现没法构造,2 3没关系即同性没法打炮(不考虑男干男ts),但和有关系可以打炮的1 2,有着一模一样无法区分的指向关系。
发现多加一个集合也不行,食物链那个每个物种都有关系,只不过是吃与被吃,用集合的顺逆时针表示,而这个,2和3断然不可以有任何关系的。
构造带权并查集吧,发现带权并查集这个序号怎么设定都行,最后判断那自己灵活变就行,我写个随意的展示下,(写这段话的时候我还不知道咋做,但我就有莫名的信息可以A出来)
太牛逼了,带权并查集不过如此,发现挺简单的也。
说下心路历程,总结就是最好设置0 1,其他数比较难搞,比如我一开始
设置的是初始指向自己是-1、同性为0、异性为1。还有设置的4、5、6
傻逼邮储梁Y楠你这word一言难尽,大学概率老师,草稿纸过程写的越详细越好,乱无所谓,但要能看清,每一个结论从哪来的,别就放一个得数,让我能看到你的思考过程

数据:
1 2 1 3 1 4 3 7 7 8 8 9 1 9
发现456那个出现个10,不知道咋办了。而-1、0、1那个在第二张图那指向4的时候已经有问题了,1→4压缩成了0,但他俩异性,感觉问题出在了没搞清究竟几个状态,初始指向自己其实就是同性,但设置了俩值-1和0,应该弄成一个的,而我觉得负数没问题,就好像acm一些傻der #define mian main一样,全靠根据结果自己写赋值设置。又试了一下,只设置俩状态,同性和初始都是-3、异性是4,随意一点,

发现这里同性可以是0 2 -3,异性可是是1 4 6,估计要写好多个组数据才能搞出结论,具体是模几,放弃
猜测是由于有负数,和每次加的数如果是异性,那是加4,比较跳跃,又查了下,向量不可以为负数,代表的是反方向,可能会出问题,所以还是老老实实搞0 1吧

太tm开门了,牛逼,并查集也不过如此!
再检测几个4 8是1+1、4 9是1+1+1,这种只有01直接条件反射想模2,那4 8就为0,4 8为女女或者男男,那就构造偶数是同性。
4 9为1,4是女9是男或者4是男9是女,正好构造奇数就是异性。
至此压缩和合并都有了,那咋判断矛不矛盾呢?
要么一条串,我只需要判断压缩后输入的俩数sex[a]和sex[b]模2,是不是一样就行,一样就同性即可疑,不一样就是符合教授观点的。代码就是(root1==root2) && (sex[a]==sex[b])就是不符合观点的同性恋
(被这个优先级运算符坑过,后遗症,啥都加括号)
要么两条串,补个图。问你2 5和2 6:

只要根不是一个,即没有互动关系,我就可以认定,你“新”出现的这个2和5想是啥就是啥,即root1!=root2,那就随意了,可以去进行给两个数赋关系,
所以至此,矛盾,不能赋值,需跳过的,只有一个就是上面一条串那个
带权并查集真的太有趣啦!!!!!
其实我这种叙述才可能让不懂的人看懂,也就是正着讲的,而很多博客,都是倒着说的,反着写的,即直接给你个结论,但不懂的人都不知道结论咋来的,考场上发的?像我这样说,会让更多人理解,即他是根据答案,根据图,构造的,面向答案编程,因为我画出图发现事实他就是同性之间是偶数,异性之间是奇数。
直接写代码。如果AC就不往后再刷了
????
卧槽??
这么没挑战吗??一次AC,我还等着WA呢
爷还想练练离散化呢,直接AC了,靠北!
AC代码(带权并查集,种类并查集我没想出来要怎么写) —— 三大平台均可AC,但注意:
0、POJ和可用平台必须用scanf,cin会TLE
1、POJ和可用平台必须要有代码59、64行,即每组数据后都要有个空行,否则会PE格式错误。而洛谷有没有都可AC

1 #include<stdio.h> 2 #include<iostream> 3 using namespace std; 4 #define MAX 2001 5 int T; 6 int pre[MAX]; 7 int sex[MAX];//与父节点关系 0同性 1异性 8 int find(int x) 9 { 10 int cache=pre[x]; 11 if(x==pre[x]) 12 return x; 13 pre[x]=find(pre[x]); 14 sex[x]=(sex[x]+sex[cache])%2; 15 return pre[x]; 16 } 17 int flag; 18 int main() 19 { 20 // cin>>T; 21 scanf("%d",&T); 22 int scenario=1; 23 while(T--){ 24 flag=0; 25 int n,m; 26 scanf("%d%d",&n,&m); 27 // cin>>n>>m; 28 for(int i=1;i<=n;i++){ 29 pre[i]=i;//指向自己 30 sex[i]=0;//起初每个人都指向自己,那父节点就是自己,都是同性。注意是父节点不是根节点 31 } 32 for(int i=0;i<m;i++){ 33 int a,b; 34 scanf("%d%d",&a,&b); 35 // cin>>a>>b; 36 if(flag==1) 37 continue;//剪枝 38 int root1=find(a); 39 int root2=find(b); 40 if((root1==root2)&&(sex[a]==sex[b])){ 41 flag=1; 42 continue; 43 } 44 pre[root1]=root2; 45 sex[root1]=(((1+sex[b])+2)-sex[a])%2; 46 //解释sex[a]和sex[b]:sex是跟父节点的关系,但已经find根了,此时sex[a],a的父节点就是根 47 //解释1是啥:如果是同性,直接continue了,所以直接把异性的1赋过去就行 48 //+2为了保证不是负数 49 //本来应该是: 50 // if(1+sex[b]>sex[a]) 51 // sex[root1]=(1+sex[b])-sex[a] 52 // else 53 // sex[root1]=sex[a]-(1+sex[b]); 54 55 } 56 if(flag==1){ 57 cout<<"Scenario #"<<scenario<<":"<<endl; 58 cout<<"Suspicious bugs found!"<<endl; 59 cout<<endl; 60 } 61 else{ 62 cout<<"Scenario #"<<scenario<<":"<<endl; 63 cout<<"No suspicious bugs found!"<<endl; 64 cout<<endl; 65 } 66 scenario++; 67 } 68 }
OJBK,AC后现在看看别人咋写的:
笨脑瓜子看世界(思路拓展)
可用平台说判断奇环,跟我最开始想的一样,但不知道咋写,发现洛谷这哥们写了(后面简称牛逼爷rui_er),但不是我想的并查集去判断奇环,最开始觉得很浪费时间太der就把这个略过了,现在想想发现也可以写但其实和带权并查集tm一样的,每个点都有个权值是1,如图1→7就是4,偶数为同性,那就是说1到根的个数减去7到根的个数,为4就违背,嗯?不是说奇数环才违背吗,咋偶数就违背了?你tm脑瓜子比我还笨吗?举个简单的,1指向2,1的根是2,1前面就1个,2前面没有,是0个,那1到根个数,减去2到根个数,得1,奇数,注意这个题题上个不同,1 2 1 2是没问题的,即发现1和2俩生物多次操逼打炮很正常啊,谁规定男女只能搞一次?阳痿?所以1到2总共俩生物,偶数环没问题,奇数环才有问题,只是算自己到根个数没包含自己,导致看上去是发现为偶数才违背。

但写个代码WA了,
1 #include<stdio.h> 2 #include<iostream> 3 #include<math.h> 4 using namespace std; 5 #define MAX 2001 6 int T; 7 int pre[MAX]; 8 int sex[MAX];//与父节点关系 0同性 1异性 9 int find(int x) 10 { 11 int cache=pre[x]; 12 if(x==pre[x]) 13 return x; 14 pre[x]=find(pre[x]); 15 sex[x]=sex[x]+sex[cache]; 16 return pre[x]; 17 } 18 int flag; 19 int main() 20 { 21 scanf("%d",&T); 22 int scenario=1; 23 while(T--){ 24 flag=0; 25 int n,m; 26 scanf("%d%d",&n,&m); 27 for(int i=1;i<=n;i++){ 28 pre[i]=i;//指向自己 29 sex[i]=0;//起初每个人都没有根 30 } 31 for(int i=0;i<m;i++){ 32 int a,b; 33 scanf("%d%d",&a,&b); 34 if(flag==1) 35 continue;//剪枝 36 int root1=find(a); 37 int root2=find(b); 38 if((root1==root2)&&(((abs(sex[a]-sex[b]))%2)==0)){//即奇数环,但为啥奇数则违背其实自己画个图就知道了,博客里也说了 39 // if((root1==root2)&&(sex[a]==sex[b])){ 40 flag=1; 41 continue; 42 } 43 // pre[root1]=root2;//写的不对,自己画个图1→2→3,4→5→6就懂了 44 // pre[a]=b;//写的也不对 45 // sex[a]=sex[a]+1;//还是不对 46 // //表示你自己就是根,那我想跟你打炮直接加1就行,理解为当我a后面的人想跟你b打炮,必须经过我再加1才行,而经过我的数值存在你们自己那里 47 48 //插一句话,我写到这才理解什么叫之前看的,两个点都落在才叫不合理:https://blog.csdn.net/qq_45377553/article/details/105757082 49 if() 50 51 } 52 if(flag==1){ 53 cout<<"Scenario #"<<scenario<<":"<<endl; 54 cout<<"Suspicious bugs found!"<<endl; 55 cout<<endl; 56 } 57 else{ 58 cout<<"Scenario #"<<scenario<<":"<<endl; 59 cout<<"No suspicious bugs found!"<<endl; 60 cout<<endl; 61 } 62 scenario++; 63 } 64 }
如下图

发现,和最短路有些相似,根本身sex是0,前面多个根的时候,后面所有的sex都要跟着变化。再次处理。(又回想起来之前修路题目,在做不出来的时候,认为更改一个头指针,其他之前的都要跟着改)
注意:图里1 4和4 1是一种情况,2 5这种俩串的是另一种情况。
其实就是带权并查集的残次版。俩串那尤为明显,因为不可以指向根
代码的语言就是,如果sex,这里sex含义是前面点的个数,比如1指向2指向3,3是根,则sex[1]是2,sex[2]是1,sex[3]是0。那如果sex[a]和sex[b]分别与自己的根root1和root2的差值都是偶数,代表俩串的根可以打炮即异性,那就依旧指向的时候赋值为加1,或者差值都为奇数,代表俩串的根都和各自的a\b异性,那也可以打炮赋值为1。否则就是同性,赋值为02468任何偶数都行,我选择0。
AC代码 —— 并查集判断奇环写法 (太高潮了)(不知道为啥脑子感觉思路好慢好慢,md要想好久,仿佛老年痴呆一样,如果赛场上我估计直接0AC╮(╯▽╰)╭~~~~(>_<)~~~~)
1 #include<stdio.h> 2 #include<iostream> 3 #include<math.h> 4 using namespace std; 5 #define MAX 2001 6 int T; 7 int pre[MAX]; 8 int sex[MAX];//与父节点关系 0同性 1异性 9 int find(int x) 10 { 11 int cache=pre[x]; 12 if(x==pre[x]) 13 return x; 14 pre[x]=find(pre[x]); 15 sex[x]=sex[x]+sex[cache]; 16 return pre[x]; 17 } 18 int flag; 19 int main() 20 { 21 scanf("%d",&T); 22 int scenario=1; 23 while(T--){ 24 flag=0; 25 int n,m; 26 scanf("%d%d",&n,&m); 27 for(int i=1;i<=n;i++){ 28 pre[i]=i;//指向自己 29 sex[i]=0;//起初每个人都没有根 30 } 31 for(int i=0;i<m;i++){ 32 int a,b; 33 scanf("%d%d",&a,&b); 34 if(flag==1) 35 continue;//剪枝 36 int root1=find(a); 37 int root2=find(b); 38 if((root1==root2)&&(((abs(sex[a]-sex[b]))%2)==0)){//即奇数环,但为啥奇数则违背其实自己画个图就知道了,博客里也说了 39 flag=1; 40 continue; 41 } 42 // 开始合并 43 // 如果a/b前面个数是偶数代表与a/b的根同性(同性就当作0吧),奇数代表与根a/b异性 44 // 哎就是带权并查集,但想法不同,是判断奇环 45 if((sex[a]%2==0 && sex[b]%2==0)||(sex[a]%2==1 && sex[b]%2==1)){//俩串的根也是异性 46 pre[root1]=root2; 47 sex[root1]=1; 48 } 49 else{ 50 pre[root1]=root2; 51 sex[root1]=0; 52 } 53 } 54 if(flag==1){ 55 cout<<"Scenario #"<<scenario<<":"<<endl; 56 cout<<"Suspicious bugs found!"<<endl; 57 cout<<endl; 58 } 59 else{ 60 cout<<"Scenario #"<<scenario<<":"<<endl; 61 cout<<"No suspicious bugs found!"<<endl; 62 cout<<endl; 63 } 64 scenario++; 65 } 66 }
再看这个牛逼爷rui_er写的搜索写法判断奇数环(搜索我也不会,其实懒得想不想回顾搜索专题)
0、好像那个天山折梅手写法
1、他貌似也用到了离散化,只不过也是手写map的感觉,同上0、和之前那个手搓建图
2、代码里的Edge结构体,文心GPT告诉我是构造函数(之前遇到过,搜“弊病”),先大概了解下,说是面向对象特有的东西,先不管
3、 e[++ne] = Edge(v, h[u]); 这个等同于 e[++ne].v=v; e[ne].nxt=h[u] 但文心GPT说增加可读性和可维护性
安全性问题:这种写法假设了数组e已经有足够的空间来存储元素。但是,在实际情况中,如果数组e的大小有限,并且已经存储了其他元素,那么这种写法可能会导致数组越界,进而引发未定义行为。 代码可读性:拆分成员赋值降低了代码的可读性。当你看到e[++ne].v = v;和e[ne].nxt = h[u];这两行代码时,你可能需要花费额外的时间来理解它们的意图和顺序。而如果你将它们合并为一行代码e[++ne] = Edge(v, h[u]);,那么代码的意图就会更加清晰明了。 代码可维护性:拆分成员赋值也降低了代码的可维护性。如果你需要在未来修改这些代码(例如,添加额外的成员变量或更改赋值逻辑),那么你可能需要在多个地方进行更改,这增加了出错的风险。而如果你使用合并的写法,那么你只需要在一个地方进行修改即可。 因此,即使在这种情况下代码没有立即出错,但拆分成员赋值的写法仍然是不安全的和不好的编程实践。正确的做法应该是一次性设置所有必要的成员变量
4、查了下add函数的链式向前星(解释的相当不错,还有邝斌的专题,我的天他才初二,我直接评论想加博主wx好友),MD!!!我才发现我一直用的就是链式向前星卧槽惊了!!!(本还打算先放弃学这个东西呢),然后又去回顾了下,发现学懂了好多高科技可以进入高科技时代,结果一直以为自己是工业时代的人,掌握太极拳结果一直以为是普通弟子拳,md重新总结下:这里的手搓哥是链式向前星,虫洞里的wjy666和ljcljc,即vector是邻接表。这道题的链式向前星画了个图:

道理还是一样的,
首先你如果想找4开头的关系,就用一个火药导火索h数组去找,
发现h[4]一开始是1后来更新为3了,这里只有更新后的3是有用的,即称之为火药导火索(鞭炮引燃捻儿),得到他的值是3,那就去找e数组,
e[3]的.v是6,e[3]的.nxt是1,这个nxt记录着下一个存储4开头的关系,注意h[4]一开始的1已经没用了,用代码的语言说就是已经被破坏了,用nxt的这个1,即门牌号直接去e数组里找,
e[1]的.v是5,e[1]的.nxt是0,代表没了,至此得到4 6和4 5俩关系。同理会得到5 6、5 4、6 5、6 4。至此本题的链式向前星理解完毕。发现他这其实也无形中离散化了,因为先存了起来。
5、无意间了解到他博客提到的算法
6、突然发现这人的输出真的离谱,但各大平台都能AC,学到了
7、发现他也遍历的n个点,这就有点前面放了个大招,后面鸡肋了啊,
①离散化很好的在初始化的时候避免了遍历所有点去初始化赋值,而是实际有多少就存多少,但之后是遍历所有点dfs,如果只有一个关系那不就太der了
②非离散化初始的时候,遍历所有点赋值,但之后是每输入一个就判断一个,只有一个关系就输入一次,判断一次后,立马输出。
我的思考,为何要把没有打炮关系的点,也赋值上颜色呢?1000个点,1个关系,却需要遍历1000次md。(不信在调用dfs函数那加个输出看看)
综上这个牛逼爷写的是离散化残次品,但搜索的思路真的惊人太牛逼了,啃了好久好久好久,最好在开个数组,有互动打炮关系的做个标记,你dfs只去处理这些标记的,但数组也要遍历,想到上一个题那人的map离散化。故,去再读下那人代码,然后给这位牛逼爷rui_er改动一下。
重新读上一个博客里的离散化,(脑子好笨,~~~~(>_<)~~~~,这么简单点东西不画出图根本理解不了,麻痹的现在我这么弱了么,学啥代码都得画,我tm不是练画画来了) —— 注此图是上道题 Is It A Tree? 的。(Is It A Tree题的离散化大佬这个不知道属于啥简建图,不是链式向前星,也不是邻接表,就单纯的记录边。注意:那离散化大佬能否用链式向前星来做,应该是不行或者没必要,对于之前输入过的已经成边了存储在edge里了,有用的就是指向的根,每次新输入的俩数,就用根去做对比判断操作即可。牛逼爷这个残疾版链式向前星能否也用单纯记录边?应该是不行,他博客里那句“每一次遍历从当前点u为起点的所有的边 e ( u , v )”有点误导,仿佛是说想遍历类似邻接表vector一样的,找出某点出发有的所有边一样,但其实不全是,牛逼爷是又结合了从某点出发,像是玩“以成语最后一个字为开头的成语接龙游戏”一样,抽丝剥茧找出一条完整接龙线,比如数据有10个点,4个关系:4 5、5 6、4 3、6 7,如果找4,先4赋颜色col为1,即col[4]=1,col[5]赋2,此时带着“3-col即3-2,等于1”的这个值和“尾巴:5”,去成语接龙,找5出发的,5 6,则col[6]=1,再带着“3-col等于2”的这个颜色值,和“尾巴:6”去成语接龙,找到6 7,col[7]赋值2,这么个意思。至此结束一轮,返回的时候,是返回最开始4的那块,再找开头的其他点,找到了4 3,col[3]赋值2。所以他是检索所有的点,去构成无数个整链,综上,你如果像上一个离散化大佬那样单纯记录边,找第一条边4 5的时候,会col[4]=1,col[5]=2,然后第二条边,5 6,会由于5已经进入过,只进行col[6]=1的操作,可是第三条边4 3,会由于4进入过而跳过,3的时候会col[3]=1,这不就跟4同性了吗)

思想就是把4 5 6仨点弄成1 2 3,三这个数量就存到blocnt,弄完之后初始化不用遍历所有点直接遍历blocnt,(注意st数组没用,注释掉就行),只给这仨数初始化就行。照着离散化大佬的代码,给牛逼爷rui_er改下:(牛逼爷的代码变量我都重新搞成了三个字母,这样方便选中后高亮)(为了方便看,变量用的和离散化大佬一样)
先放个牛逼爷原始AC代码 (方便回顾的时候找不同)
1 //By: Luogu@rui_er(122461) 2 #include <bits/stdc++.h> 3 using namespace std; 4 const int N = 2005, M = (int)(1e6+5)<<1; 5 int T, n, m, ans; 6 int col[N]; 7 struct Edge {//前向星建图 8 int v, nxt; 9 Edge() {} 10 Edge(int a, int b) : v(a), nxt(b) {} 11 }e[M]; 12 int ne, h[N]; 13 void add(int u, int v) { 14 e[++ne] = Edge(v, h[u]); 15 h[u] = ne; 16 e[++ne] = Edge(u, h[v]); 17 h[v] = ne; 18 } 19 20 void dfs(int u, int c) { // 0/1 染色 dfs,两个参数分别是当前点编号和颜色 21 col[u] = c; 22 for(int i=h[u];i;i=e[i].nxt) { 23 int v = e[i].v; 24 if(col[v] == col[u]) { 25 ans = 0; 26 break; 27 } 28 if(!col[v]) { 29 dfs(v, 3-c); 30 } 31 } 32 } 33 34 int main() { 35 scanf("%d", &T); 36 for(int _=1;_<=T;_++) { 37 memset(e, 0, sizeof(e)); 38 memset(h, 0, sizeof(h)); 39 memset(col, 0, sizeof(col)); 40 ne = 0; 41 ans = 1; 42 printf("Scenario #%d:\n", _); 43 scanf("%d%d", &n, &m); 44 for(int i=1;i<=m;i++){ 45 int u, v; 46 scanf("%d%d", &u, &v); 47 add(u, v); 48 } 49 for(int i=1;i<=n;i++) { // 对于每一个未被染色的点(新连通块),进行 dfs,与 tarjan 算法类似 50 if(ans && !col[i]) { 51 dfs(i, 1); 52 } 53 } 54 if(ans){ 55 puts("No suspicious bugs found!"); 56 cout<<endl; 57 } 58 else { 59 puts("Suspicious bugs found!"); 60 cout<<endl; 61 } 62 } 63 return 0; 64 }
再放个加输出的版本,即上面的7、②,
1 //By: Luogu@rui_er(122461) 2 #include <bits/stdc++.h> 3 using namespace std; 4 const int N = 2005, M = (int)(1e6+5)<<1; 5 int T, n, m, ans; 6 int col[N]; 7 int blocnt; 8 struct Edge {//前向星建图 9 int v, nxt; 10 Edge() {} 11 Edge(int a, int b) : v(a), nxt(b) {} 12 }e[M]; 13 int ne, h[N]; 14 void add(int u, int v){ 15 e[++ne] = Edge(v, h[u]); 16 h[u] = ne; 17 e[++ne] = Edge(u, h[v]); 18 h[v] = ne; 19 } 20 21 void dfs(int u, int c) { // 0/1 染色 dfs,两个参数分别是当前点编号和颜色 22 col[u] = c; 23 for(int i=h[u];i;i=e[i].nxt) { 24 int v = e[i].v; 25 if(col[v] == col[u]) { 26 ans = 0; 27 break; 28 } 29 if(!col[v]) { 30 dfs(v, 3-c); 31 } 32 } 33 } 34 35 int main() { 36 scanf("%d", &T); 37 for(int _=1;_<=T;_++) { 38 memset(e, 0, sizeof(e)); 39 memset(h, 0, sizeof(h)); 40 memset(col, 0, sizeof(col)); 41 ne = 0; 42 ans = 1; 43 blocnt=0; 44 printf("Scenario #%d:\n", _); 45 scanf("%d%d", &n, &m); 46 for(int i=1;i<=m;i++){ 47 int u, v; 48 scanf("%d%d", &u, &v); 49 add(u, v); 50 } 51 for(int i=1;i<=n;i++) { // 对于每一个未被染色的点(新连通块),进行 dfs,与 tarjan 算法类似 52 if(ans && !col[i]) { 53 cout<<i<<endl; 54 dfs(i, 1); 55 } 56 } 57 if(ans){ 58 puts("No suspicious bugs found!"); 59 cout<<endl; 60 } 61 else { 62 puts("Suspicious bugs found!"); 63 cout<<endl; 64 } 65 } 66 return 0; 67 }
输入
1 1000 1 1 4
就一个关系,居然要输出1000行后才能得到答案!
md真费劲,win+←左边是离散化大佬博客,win+→右边是复制的牛逼爷的博客,照着改成离散化也这么费劲~~~~(>_<)~~~~
把牛逼爷的代码更改成加离散化的,直接AC
AC代码 —— (把洛谷牛逼爷的搜索代码,改成加入离散化的写法)
1 //By: Luogu@rui_er(122461) 2 #include <bits/stdc++.h> 3 using namespace std; 4 #include<map> 5 map<int,int>qqq; 6 const int N = 2005, M = (int)(1e6+5)<<1; 7 int T, n, m, ans; 8 int col[N]; 9 int blocnt; 10 struct Edge {//前向星建图 11 int v, nxt; 12 Edge() {} 13 Edge(int a, int b) : v(a), nxt(b) {} 14 }e[M]; 15 int ne, h[N]; 16 void add(int u, int v){ 17 e[++ne] = Edge(v, h[u]); 18 h[u] = ne; 19 e[++ne] = Edge(u, h[v]); 20 h[v] = ne; 21 } 22 23 void dfs(int u, int c) { // 0/1 染色 dfs,两个参数分别是当前点编号和颜色 24 col[u] = c; 25 for(int i=h[u];i;i=e[i].nxt) { 26 int v = e[i].v; 27 if(col[v] == col[u]) { 28 ans = 0; 29 break; 30 } 31 if(!col[v]) { 32 dfs(v, 3-c); 33 } 34 } 35 } 36 37 int main() { 38 scanf("%d", &T); 39 for(int _=1;_<=T;_++) { 40 qqq.clear(); 41 memset(e, 0, sizeof(e)); 42 memset(h, 0, sizeof(h)); 43 memset(col, 0, sizeof(col)); 44 ne = 0; 45 ans = 1; 46 blocnt=0; 47 printf("Scenario #%d:\n", _); 48 scanf("%d%d", &n, &m); 49 for(int i=1;i<=m;i++){ 50 int u, v; 51 scanf("%d%d", &u, &v); 52 if(!qqq[u]){ 53 blocnt++; 54 qqq[u]=blocnt; 55 } 56 if(!qqq[v]){ 57 blocnt++; 58 qqq[v]=blocnt; 59 } 60 add(qqq[u],qqq[v]); 61 } 62 for(int i=1;i<=blocnt;i++) { // 对于每一个未被染色的点(新连通块),进行 dfs,与 tarjan 算法类似 63 if(ans && !col[i]) { 64 // cout<<i<<endl; 65 dfs(i, 1); 66 } 67 } 68 if(ans){ 69 puts("No suspicious bugs found!"); 70 cout<<endl; 71 } 72 else { 73 puts("Suspicious bugs found!"); 74 cout<<endl; 75 } 76 } 77 return 0; 78 }
将64行注释去掉发现上面的数据只输出了一行,太棒啦哈哈。
再把自己的带权并查集AC代码更改成离散化的
依旧一次AC
AC代码 —— 带权并查集加入离散化
1 #include<stdio.h> 2 #include<iostream> 3 #include<map> 4 using namespace std; 5 map<int,int>qqq; 6 #define MAX 2001 7 int T; 8 int pre[MAX]; 9 int sex[MAX];//与父节点关系 0同性 1异性 10 int find(int x) 11 { 12 int cache=pre[x]; 13 if(x==pre[x]) 14 return x; 15 pre[x]=find(pre[x]); 16 sex[x]=(sex[x]+sex[cache])%2; 17 return pre[x]; 18 } 19 int blocnt; 20 int flag; 21 int main() 22 { 23 scanf("%d",&T); 24 int scenario=1; 25 while(T--){ 26 qqq.clear(); 27 blocnt=0; 28 flag=0; 29 int n,m; 30 scanf("%d%d",&n,&m); 31 // for(int i=1;i<=n;i++){//将这里注释掉 32 //// cout<<i<<endl; 33 // pre[i]=i;//指向自己 34 // sex[i]=0;//起初每个人都指向自己,那父节点就是自己,都是同性。注意是父节点不是根节点 35 // } 36 for(int i=0;i<m;i++){ 37 int a,b; 38 scanf("%d%d",&a,&b); 39 if(flag==1) 40 continue;//剪枝 41 if(!qqq[a]){ 42 blocnt++; 43 qqq[a]=blocnt; 44 pre[a]=a; 45 sex[a]=0; 46 } 47 if(!qqq[b]){ 48 blocnt++; 49 qqq[b]=blocnt; 50 pre[b]=b; 51 sex[b]=0; 52 } 53 int root1=find(a); 54 int root2=find(b); 55 if((root1==root2)&&(sex[a]==sex[b])){ 56 flag=1; 57 continue; 58 } 59 pre[root1]=root2; 60 sex[root1]=(((1+sex[b])+2)-sex[a])%2; 61 } 62 if(flag==1){ 63 cout<<"Scenario #"<<scenario<<":"<<endl; 64 cout<<"Suspicious bugs found!"<<endl; 65 cout<<endl; 66 } 67 else{ 68 cout<<"Scenario #"<<scenario<<":"<<endl; 69 cout<<"No suspicious bugs found!"<<endl; 70 cout<<endl; 71 } 72 scenario++; 73 } 74 }
但发现俩事:
0、oj平台居然都用时更加久,艹了,不管了
1、这个貌似是个加的离散化,无法是初始化,其实sex可以用memset,只是pre那需要离散化,这就想到另一个问题,n个数,初始化赋不的值,复杂度一定要是n吗?简单百度下,说了一堆屁话,(GPT说理论上都是n),直接略过,不考虑
笨脑瓜子看世界(思路拓展)
再啃洛谷这人的种类并查集
0、没必要1e6,2001就行
1、那个特判加的很不错
2、发现之前自己写的没错,只是画错了,或者说根本没理解清楚种类并查集,那之前我错的不冤,现在又加深理解了。具体如下,看我逼逼错误点:
①、这篇文章的第一个图(“面向图思路想编程”这句话下面的图),我一开始写的A男集合,B女集合,其实是对的,但!因为1假定是男、2假定是女,而A集合里有1(男)也有2(女),就误以为A集合里有男有女就给删了,其实跟食物链一样,A/B/C集群里就是A/B/C集群的动物,只是假如说1吃3,因为不知道1和3都属于哪个集群,所以给A/B/C集群里的第1个动物和第3个动物都给赋上这个关系了。这里A集合就是男,或者说是同性别,即B集合是女,或者说是另一个性别,但1既在A集合,也在B集合,2既在A也在B,跟食物链是一样的想法,不能确定1是男还是女,所以AB都放一个,类似镜像or平行世界的自己一样。我第二个犯的错误是
发现真的是刷的越多越深刻,之前就跟着洛谷大佬学种类并查集了,没多想,现在发现其实之前如果1吃2,2吃3,3吃1的话,那1、2、3这三种动物也是同时都放到A集合B集合C集合里了。
②、是我没想到位,图连接错了,还是看“面向图思路想编程”那句话下面的图,其实到1 3这个数据的时候,即1和3抽插打炮,我就找1根,是2,然后2指向3了,其实tmd应该是指向7!!!即B集合的3。哎当时糊涂了
③、既然前两个都错了,那判断矛盾那估计也会错,直接提一嘴判断矛盾只需要俩有同根即可。不要再犯错误!1和3是否有错,要看1根3,3的根也是3,不同,即没错。那怎么表示1和3操逼这个事,别忘了互相打炮是跟另一个集合里的,所以得去B集合找,即1是否跟7有同根,发现有的,因为1指向6,6指向7嘛
至此种类并查集也晓得了
笨脑瓜子看世界(思路拓展)
洛谷题解好多提到了二分图,科普了下二分图,我感觉这玩意就死种类并查集啊,先搁置。
至此OVER
根据小希迷宫最后那个总结,下一道题才是离散化带权并查集,但带权并查集感觉入门了,有了些许了解了,遇到的话不至于傻逼呵呵手足无措呆呆的坐在那上不了手,起码能比划比划,不打算再刷了。直接把这个题自己练一下离散化得了,看看时间上是否有优化 ——(1/1)已完成
感觉再刷个最小生成树专题和KMP专题,算法就可以先放放了,再确认下江苏那个acm铜牌哥们给我的动规资源,B站“谁tm买煤球”发布的,后来不在了,又靠自己强大的搜索能力(考研那时候接触的什么大力盘搜,各种工具),Google找到了百度云存起来了,确认下在不在(找到了
1 九章算法付费内容谁tm买煤球B站删除视频: 2 动态规划 3 通过百度网盘分享的文件:【瑞客论坛 ww… 4 链接:https://pan.baidu.com/s/1GodMM42_2TX1cYLBbhDkxg 5 提取码:GerJ 6 复制这段内容打开「百度网盘APP 即可获取」 7 8 july七月在线,分享 9 通过百度网盘分享的文件:算法_动态规划实… 10 链接:https://pan.baidu.com/s/1dvUn9z5wB51SyCnZBScXiA 11 提取码:GerJ 12 复制这段内容打开「百度网盘APP 即可获取」
失效的话评论留言
)
至此此题OVER,麻痹的强迫症刷算法真tm折磨,好累~~~~(>_<)~~~~
再刷个最小生成树 & KMP就结束,动态规划没大把时间学,
等学C++的时候,晚上撸管子的时间剩下来,看点视频瞅一瞅
后记:
###:
岛娘:
“不管以后怎么样都要把算法竞赛学好
记得初中抱着电脑坐在楼下小卖部台阶上,走廊,借着wifi信号,对着屏幕微弱的灯光,打codeforces,雨水滴在电脑屏幕上,手借着散热器取暖,切一道题都好开心”
###:印象程度:直接切题不写博客想的要深很多,写博客很多地方就以写为主,会有所肤浅。
故写博客不回顾的效果<直接切题事后有所思考<写博客事后经常回顾思考。
跟听课记笔记是一样的,有时候只听思考,不记笔记,比记笔记效果要好
###:并查集一般都要压缩路径,如果想到什么不用压缩路径的思路那基本就是误区
###:博客园换图标了好丑

↑之前的

↑现在的
###:再次跪拜邝斌大神,题目太有梯度性了
###:如果有不懂的可以评论,我直接录视频,边说边现场撸代码可能更清晰点
现场写连西工大邓思雨和岛娘都翻车
###:其实说是高大上的构造,无非就是面向画出的图这个结论编程而已,面向答案去创造式子
###:垃圾博客园不仅编辑器是上古的,就连你不小心贴了带格式的字再删除,或者,直接贴的代码没用插入代码,再Ctrl+Z,都会把这些脏东西,弄到文章最后一个字后面,需要delete好久艹!!!还没法shift按↓删除
###:关于HDU403代码被拒绝的博客,今天收到了HDOJ团队教练刘春英(浙大高材生)老师的回复,ACM届扛把子HDU的acm教练,这种事真没想到能回复我,感谢HDU感谢刘教练,我又很礼貌的追问的具体原因,感觉很神奇,但估计这个就不能回复我了。本来之前大学玩QQ的时候,一堆群,kuangbin好友都有,还有叉姐岛娘q神孙科鏼神克拉丽丝他们,但自己傻了吧唧的多是水群,也不玩QQ了不想回忆过去,直接简单粗暴百度了刘老师邮箱,直接问了。其实有QQ直接群里问更直接

###:
1 作息:每天13点起来,16元农民工自助,走3km去图书馆,晚上18元盖饭,学到23:40走3km回家,00:40到家,看一章小说,真实赛车,看看贴图视频号,再刷会题,洗漱逛电报撸管子,5点睡
###:????
邻接表:只存储非零元素来减少存储空间的浪费。在稀疏图中,大部分元素为0,那么实际有边的就会很少,邻接表是用点存图的,正好。如果使用邻接矩阵,这些0元素会占用大量的存储空间,而邻接表则只存储边信息,避免了这种空间浪费,所以邻接表适合存稀疏图。
链式向前星:我最开始在手搓哥那学到了这个算法,理解完一直以为是邻接表,直到现在才知道自己会的这玩意就是链式向前星,但始终无法理解为啥这玩意会适合存稠密图,查的都没看懂。姑且这样理解吧,自圆其说一下,即链式前向星使用链表结构来存储图的信息,每个节点包含一个指向下一个节点的指针,如果稀疏图别人邻接表只存完了n个点了,你却要多开个空间存这些衔接信息(我的疑惑是,那邻接表的vector就不用了?他链表不也是记录了下一个的信息嘛)。它通过一个头节点数组来记录每个节点的第一条边,这使得链式前向星在存储稠密图时效率较高,适合边数较多的情况。邻接表则通过为每个顶点创建一个单链表来存储与该顶点相关的边,这种方式在处理稀疏图时更为高效,因为它只存储实际存在的边,避免了不必要的空间浪费。
自己瞎JB举例子理解:比如n个点,邻接表会开n个链表,然后指向所有从i点出发的点。而链式向前星则只要一个链表,开一个next数组,开一个head头数组。发现当n少的时候,邻接表比较划算,链式向前星又开了俩多余数组。注意:点少指的是可以互相连接的点,那不就是边吗?即边少,即稀疏图适合邻接表
但当点多了,邻接表就会有n个链表,而链式向前星就一个链表,代价是多了两个数组,那我自圆其说一下俩数组比n-1个链表要划算的多,所以链式向前星更适合点多的情况。注意点多指的是有关系可以进行连接的点,那不就是边吗?即边多,即稠密图适合链式向前星。
###:~~~~(>_<)~~~~,md,我现在才知道这玩意叫链式前向星,不叫链式向前星
###:查了下牛逼爷用的puts,程序中puts()函数的作用与语句“printf("%s\n",s);的作用相同,可以认为puts()是printf()函数的简化版。我的理解,就是相当于printf输出后多一个换行。主要用于输出字符串的
###:注意POJ不支持全能头文件: #include <bits/stdc++.h>
###:

