
POJ3259-Wormholes
POJ好了(好了后我也经历了崩溃,详间上一个题后面的更新)
继续刷邝斌飞最短路专题
洛谷(翻译贼棒)
可用平台没有这个题
题意给我干缺氧了,鬼翻译真无语,都没看原汁原味的英文读的通顺,洛谷题目里说的农场,农田,地,这仨玩意给我干蒙了,其实农场和农田都是一个。我直接去看poj的英文吧,结合百度翻译,题意如下:
农场主有F个的大农场,每个大农场都各自有N块田地和W个虫洞,对于每个大农场的这些N块田地来说,
既有M条双向路(即无向边),连接这N块田,(可能存在1号田地到2号田地有很多路的情况,原英文: Two fields might be connected by more than one path. ,你可以把田地想成点)
也有W条单向路的虫洞连接这N块田,(即有向边,原英文: one-way path ,英文题意某田地到某田地的有向路径不存在多条),问你是否存在从某个田地出发走来走去,最后能在出发点之前回到起点。根据第一个样例出发点之前0s回到也是不行的。
数据范围:1<=大农场F<=5、1<=田地N<=500、1<=路M<=2500、1<=虫洞W<=200、1<=虫洞和双向路径长度均是<=10^4
理解完题好懵逼,一想到是最短路就有点思路了
迪杰斯特拉无法处理负边,参考博客,其实只有那个图有用
但我发现不对啊,迪杰斯特拉为啥不能处理负边啊??如果你以这个想法去理解迪杰斯特拉的话,那之前的那几个题A的都是照抄模板根本没理解算法本质啊,我一个题墨迹半天才A掉,你们直接套模板短时间AC证明根本没理解啊。
之前的几个题虽然没负边,但每次将点加进去后,都不是这个点的最优解,后面沾亲带故的更新会逐渐把最优解更新出来
现在负边也是啊
比如看爹给你举个例子
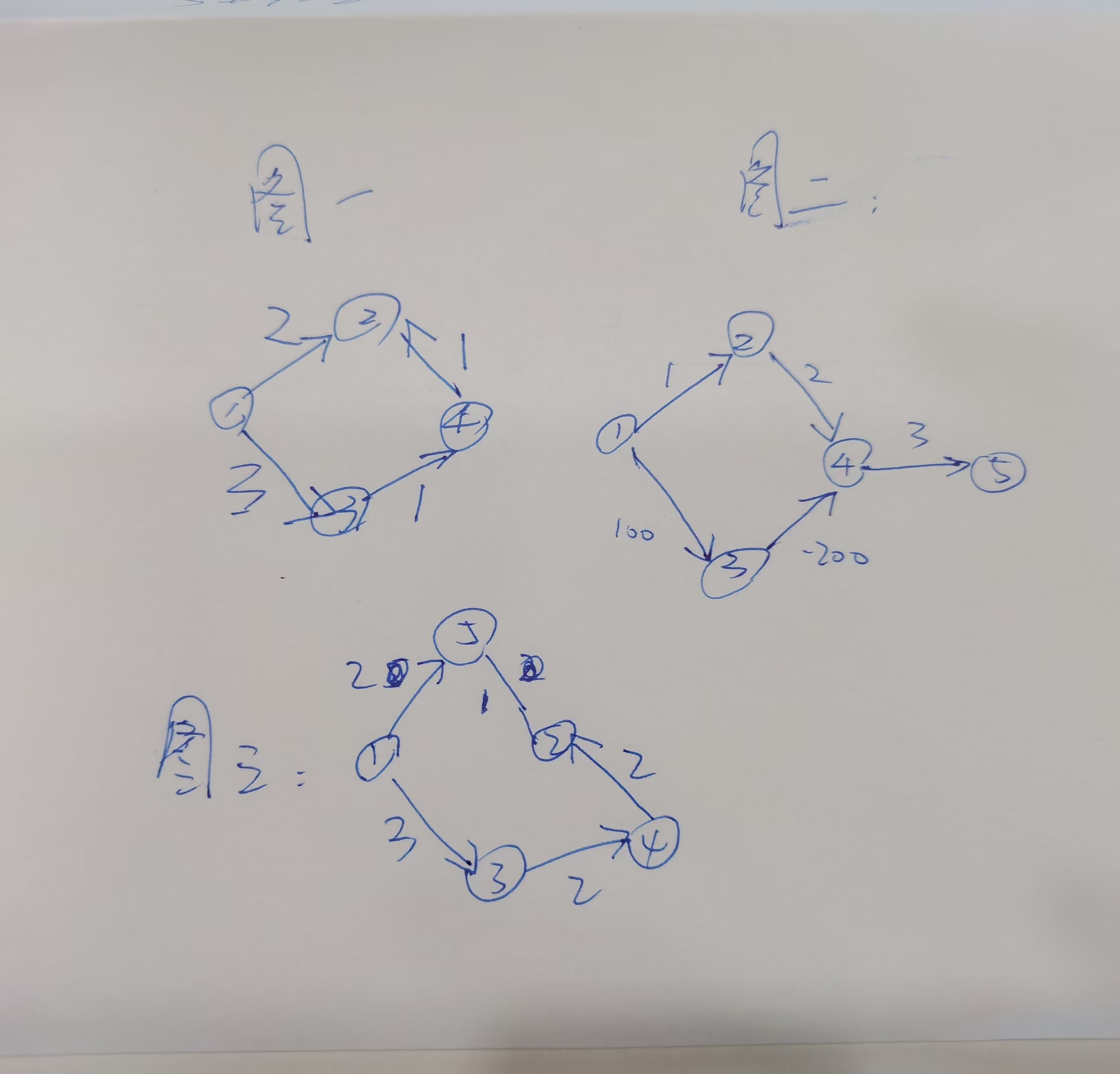
你就瞅图一,新开个标签页,把我这篇文章的链接复制打开,新开的标签拖出来,alt+←分屏看
如果每条路的权值表示这条路能承受的重量的话,假设一段路中各个线段的承重最少的那段,为此段路的最大承重,问你①到②最大承重的最大值,或者说短板最大可以取多少。如果连这句话都读不懂就去把前几道题刷了(Heavy Transportation那个题,md我发现自己写的博客自己回头都不愿意看,q神:想破脑袋想出来的怎么会忘,岛:忘记思路但感觉在),不过也可能是我没描述清楚
按照迪杰斯特拉,起手①①到自身设置为无穷大(没什么实际意义,只是这样方便写代码),然后①到所有点memset为0
①①、①②、①③、①④做比较,最大承重为①①是无穷大,①点加进来沾亲带故更新①②和①③距离为2和3,①点滚犊子别再参与之后的比较
①②和①③做比较,最大承重是①③是3,③点加进来,然后更新①④最大承重为1,③点滚犊子别再参与之后的比较
①④和①②做比较,最大承重是①②是2,②点加进来,发现没有可以更新的,然后继续,②滚犊子别再参与后面的比较
然后只有④加进来,做更新发现走④导致①②最大承重为1,之前最大承重是2,所以不更新,①②最大承重是2.
所以你看起初③点加进来了,但他走①③去往②的路径并不是最后的答案,后加进来的②才是。
什么你没考虑这些?你直接就套模板,第一次就找最小了?②加进来就完事了?
那你再看图三,我刚发现其实也行,找最小⑤加进来,更新①②最大承重是1,然后③加进来,更新导致①④最大承重是2,④加进来,更新导致①②最大承重比之前1大,那更新为2,也行。
至此我发现是不是每次不论找最大还是最小都行,那是不是只要顶点距离你有距离,你就可以加进来?反正我加进来导致什么结果只是暂时的,后面有比我更合适的就会更新,于是乎,我用Heavy Transportation那题试了一下,代码简称逆反版本吧,但却可以更加理解算法
首先啊,看好,本应该每次选最大值,然后加进去,下次不再做比较,具体看我之前的博客
这里为了验证猜想,我写每次取最小值看行不行,但注意,初始值怎么设置看松弛那个if里的比较,我想把没更新过的进行更新即松弛,通过小于号,这里因为是永远取短板最大,所以必须用小于号,比你小就更新(不要把松弛和做比较加进去这两件事搞混淆),那本来没有路的我就要将maxweight用memset成0没得说,但每次比较如果你想找最小的话,0没路如果加进来那毫无意义,因为下一步没法更新,比如数据
1 4 4 4 2 2 3 2 4 1 2 3 4 3 3
那我如果把③因为他没路是0最小就加进来,本来可以通过③更新①④,但这么一整,①④会更新为0没意义,那如果找最小的时候加一个特判只要是没路的0就不算在比较范围内,算了我干脆不找最小了,我直接随机,遍历到谁谁加进来


1 #include<stdio.h> 2 #include<string.h> 3 #include<math.h> 4 #include<iostream> 5 using namespace std; 6 int weight[1001][1001]; 7 int maxweight[1001]; 8 int vis[1001]; 9 int thismax; 10 int main() 11 { 12 freopen("data.txt","r",stdin); 13 int t; 14 scanf("%d",&t); 15 int tp=t; 16 while(t--) 17 { 18 memset(weight,0,sizeof(weight)); 19 int n,m; 20 scanf("%d%d",&n,&m); 21 memset(maxweight,0,sizeof(maxweight)); 22 memset(vis,0,sizeof(vis)); 23 24 int a,b,c; 25 for(int i=0;i<m;i++){ 26 scanf("%d%d%d",&a,&b,&c); 27 weight[a][b]=c; 28 weight[b][a]=c;//数据输入完毕 29 } 30 for(int i=1;i<=n;i++) 31 maxweight[i]=weight[1][i]; 32 int p; 33 vis[1]=1; 34 for(int i=1;i<=n;i++){ 35 for(int j=1;j<=n;j++){ 36 if(vis[j]==0&&maxweight[j]!=0) 37 p=j; 38 } 39 cout<<"!"<<p<<endl; 40 vis[p]=1; 41 for(int j=1;j<=n;j++){//松弛 42 if(maxweight[j]<min(maxweight[p],weight[p][j])){ 43 maxweight[j]=min(maxweight[p],weight[p][j]); 44 if(j==1) 45 maxweight[p]=maxweight[j]; 46 cout<<p<<" "<<j<<" "<<maxweight[j]<<endl; 47 } 48 } 49 } 50 cout<<"Scenario #"<<tp-t<<":"<<endl; 51 cout<<maxweight[n]<<endl; 52 cout<<endl; 53 } 54 }
也WA,但我的思路我觉得没任何问题,对拍好久终于找到了问题
对拍代码
1 #include<stdio.h> 2 #include<iostream> 3 #include<time.h> 4 using namespace std; 5 int a; 6 int b; 7 int c; 8 int main(){ 9 srand(time(0) + (unsigned long long)(new char)); 10 int n = rand()%5+2; 11 int m = rand()%5+1; 12 int x=rand()%n+1; 13 cout<<"1"<<endl; 14 cout<<n<<" "<<m<<endl; 15 for(int i=0;i<m;i++){ 16 a=rand()%n+1; 17 b=rand()%n+2; 18 c=rand()%7+1; 19 cout<<a<<" "<<b<<" "<<c<<endl; 20 } 21 }
数据
1 5 5 1 4 3 4 5 6 2 3 6 1 3 4 2 4 7
自己画个图,这里当随便进入的时候,如果④点进入了,那他之后不会再进入参与比较,①⑤最大承重就会更新为3,由于④不会再进入且到⑤只有经过④这个点,所以永远无法得到正确答案①③②④⑤最大承重4。那每次找最大就可以完美实现
由此可见,每次找到的并不是最优解只是伪最优,但是向着真最优趋势上走的
吼吼,回过头来发现图三确实不行,确实处理不了负边,参考博客里面说的是对的,这个逼解释的相当完美,处理不了负边跟负边没关系
说服自己了,老老实实去学处理负边的算法
好到让人高潮的博客,全网最强,唯一一点这哥们的代码写的太抽象了艹,后面代码还不错,学到了记录路径的小技巧,跟之前搜索里的记录轨迹明显上升了个难度
但写了一半,发现贝尔曼福特算法复杂度是n^3啊,并不是m*n,且没闭环回来的啊,而且是要从任一点开始走
麻痹的写了一半发现这题是不是弗洛伊德啊
抛开算法束缚重新想下:遍历n(500),对于每个n,比如说n遍历到了2(意思是从2出发看能不能有题意要求的回到2且时间是之前的情况),不用1举例子是为了防止忘记这次的遍历,那么我从2到任意点的最短距离可以用最短路算法求,但再到2怎么求?原路返?(不太对)继续向前?(那我这到2不是失去了意义), 那我是不是再以得到的最短路为新地图,并反向存一遍地图,然后再从2出发再搞一遍最短路作为回程?(再次觉得邝斌题目的阶梯度层次感真好!!),但感觉怪怪的,有点der儿,兴许哪里会出错,因为并没要求走你,为啥非要走个你,再从你找去顶点2的最短呢?
时间复杂度:边m总共2500*2+200=5200,输入的时候反存图m(想了好久,这个题更加了解反存图的本质了),遍历的n *(贝尔曼福特n*m + 反存图的贝尔曼n*m),这里n是点的数量,m是边的数量,5组数据,10^10,2s应该不可以(虽然洛谷又写的是1s)
再看我想到的另一种思路:遍历n(500),对于每个n,比如说n遍历到了2,那我设置一个东西叫影子顶点,再遍历n遍,每一个点到2有如果距离,我就把这距离赋给影子顶点,那么老子只要找从2到影子顶点最短路是不是负数不就好了吗?也没上一个思路那个der儿。实现了首尾位分离
时间复杂度:遍历出发点n *(设置影子顶点也即影子出发点n + 贝尔曼n*m),但设置影子的时候,边总共2500*2+200=5200,5组数据,10^9,2s可以吧。
再去学一下非n^3版本的贝尔曼算法(那篇高潮博客的基础上,潮上加潮),发现遍历n-1遍,里面的遍历不要求顺序,跟弗洛伊德一样,迪杰斯特拉是找当前极值,不能随便将点加入
代码第一次提交
1 //#include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[502]; 6 int u[502]; 7 int v[502]; 8 int edge[2701]; 9 int dir[502][502];//正常500点,会有dir[1][500],所以开501,再多开一个给影子顶点用 10 int exist[502][502];//仅仅为了优化地图,针对虫洞 11 int F; 12 int n,m,w; 13 int a,b,c; 14 int attach; 15 int p,q; 16 void bellman(); 17 int flag=0; 18 int main() 19 { 20 freopen("zhishu.txt","r",stdin); 21 scanf("%d",&F); 22 while(F--){ 23 memset(exist,0,sizeof(exist)); 24 memset(edge,0x3f,sizeof(edge)); 25 memset(dir,0x3f,sizeof(dir)); 26 scanf("%d%d%d",&n,&m,&w); 27 for(int i=1;i<=m*2;i++){ 28 scanf("%d%d%d",&a,&b,&c); 29 u[i]=a; 30 v[i]=b; 31 edge[i]=c;//真正贝尔曼算法用到的 32 dir[a][b]=c;//为影子顶点准备的 33 exist[a][b]=i;//后面优化边的数量用的 34 i++; 35 u[i]=b; 36 v[i]=a; 37 edge[i]=c; 38 dir[b][a]=c; 39 exist[b][a]=i; 40 } 41 p=0; 42 for(int i=m*2+1;i<=m*2+w-p;i++){ 43 scanf("%d%d%d",&a,&b,&c); 44 if(exist[a][b]!=0){//优化边的数量,如果之前有过这条边,但是正数,这次将要输入的是负数,有就把之前的正数用这次的负数覆盖掉,减少边的数量。即某点到某点如果有虫洞,完全可以走虫洞,不走路 45 edge[exist[a][b]]=-c;//起点终点uv和dir之前已经有了 46 p++;//相当于这次i作废了,是把之前的覆盖了 47 } 48 else 49 u[i]=a; 50 v[i]=b; 51 edge[i]=-c; 52 dir[a][b]=-c; 53 } 54 // 至此输入结束 55 // 总共表面上输入了m+w条边,m双向,共输入了2m+w条,p记录了重复的边,总共2m+w-p条边 56 // for(int i=1;i<=2*m+w-p;i++) 57 // cout<<u[i]<<" "<<v[i]<<" "<<dir[i]<<endl;//测试发现完美实现 58 flag=0; 59 for(int i=1;i<=n;i++){//分别从1、从2、从3...出发,找到就停止 60 if(D[n+1]<0){ 61 flag=1;//找到有可以完成的 62 // cout<<D[n+1]<<endl; 63 cout<<"YES"<<endl; 64 break; 65 } 66 q=2*m+w-p;//目前实际边数 67 attach=0;//如果没有到i的点,附加边就是0,i为顶点 68 memset(D,0x3f,sizeof(D)); 69 D[i]=0; 70 for(int j=1;j<=n;j++){ 71 if(dir[j][i]!=0x3f3f3f3f){ 72 edge[++q]=dir[j][i]; 73 u[q]=j; 74 v[q]=n+1;//影子顶点 75 attach++; 76 } 77 } 78 bellman(); 79 } 80 if(flag==0) 81 cout<<"NO"<<endl; 82 } 83 } 84 85 void bellman() 86 { 87 for(int k=1;k<=n;k++){//变量没啥用,纯纯为了使下面操作循环n-1遍,算上影子 88 for(int i=1;i<=(2*m+w-p+attach);i++) 89 if(D[v[i]]>D[u[i]]+edge[i]) 90 D[v[i]]=D[u[i]]+edge[i]; 91 } 92 }
之前说过这种提示不太喜欢,那个下载数据都懒得看转去用POJ了,返回的是WA
怎么感觉被模板整思维定势了呢,这里貌似并不只是n-1趟就可以了,是往返啊,而且好像直接也不用镜子顶点,搞对遍历的趟数貌似就可以了艹。
感觉是2倍的n,依旧WA,不想看洛谷分数是不是接近了,我这么弱还活在世界上真的对不起,艹怒了,就硬调,
逐步调试发现输入数据的代码写错了
然后发现许多问题,好挣扎写到一半就不想写了,因为发现根本不用影子这玩意,既然开了头强迫症写完了,所有WA的地方都标注了
1 #include<stdio.h> //正常iostream包括sacnf,但poj不行 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[1012]; 6 int u[1012]; 7 int v[1012]; 8 int edge[9901]; 9 int dir[1012][1012]; 10 int exist[1012][1012]; 11 int F; 12 int n,m,w; 13 int a,b,c; 14 //int attach; 15 int p,q; 16 void bellman(); 17 int flag=0; 18 int main() 19 { 20 // freopen("zhishu.txt","r",stdin); 21 scanf("%d",&F); 22 while(F--){ 23 memset(exist,0,sizeof(exist)); 24 memset(edge,0x3f,sizeof(edge)); 25 memset(dir,0x3f,sizeof(dir)); 26 scanf("%d%d%d",&n,&m,&w); 27 for(int i=1;i<=m*2;i++){ 28 scanf("%d%d%d",&a,&b,&c); 29 u[i]=a; 30 v[i]=b; 31 edge[i]=c; 32 dir[a][b]=c; 33 exist[a][b]=i; 34 i++; 35 u[i]=b; 36 v[i]=a; 37 edge[i]=c; 38 dir[b][a]=c; 39 exist[b][a]=i; 40 } 41 p=0; 42 for(int i=m*2+1;i<=m*2+w-p;i++){ 43 scanf("%d%d%d",&a,&b,&c); 44 if(exist[a][b]!=0){ 45 edge[exist[a][b]]=-c; 46 p++; 47 i--;//i下次还要再这个下标赋值,WA好几次调试出来的 48 } 49 else{ 50 u[i]=a; 51 v[i]=b; 52 edge[i]=-c; 53 dir[a][b]=-c; 54 exist[a][b]=i; 55 } 56 } 57 58 flag=0; 59 for(int i=1;i<=n;i++){ 60 // cout<<D[n+1]<<endl; 61 62 q=2*m+w-p; 63 if(i!=1){//说明第一次已经被搞了,数据破坏了,先恢复数据,WA了好几次 64 for(int j=1;j<=n;j++){ 65 if(dir[j][i-1]!=0x3f3f3f3f){ 66 v[exist[j][i-1]]=i-1; 67 } 68 } 69 } 70 // attach=0; 71 for(int j=1;j<=n;j++){ 72 if(dir[j][i]!=0x3f3f3f3f){ 73 // edge[++q]=dir[j][i]; 74 // u[dir[j][i]]=j; 75 v[exist[j][i]]=n+1;//WA好几次才调出来 76 // attach++;//不应该加点而是应该用这个影子覆盖掉去顶点的 77 // cout<<u[q]<<" "<<v[q]<<" "<<edge[q]<<endl; 78 } 79 } 80 81 memset(D,0x3f,sizeof(D));//这句话位置搞错了,导致第二次输入数据就直接用上一个的D输出YES就没了 82 D[i]=0; 83 // for(int i=1;i<=6;i++) 84 // cout<<"@"<<i<<" "<<u[i]<<" "<<v[i]<<" "<<edge[i]<<endl; 85 bellman(); 86 // cout<<i<<" "<<D[n+1]<<endl; 87 if(D[n+1]<0){ 88 flag=1; 89 cout<<"YES"<<endl; 90 break; 91 } 92 } 93 if(flag==0) 94 cout<<"NO"<<endl; 95 } 96 } 97 98 void bellman() 99 { 100 for(int k=1;k<=n;k++){//变量没啥用,纯纯为了使下面操作循环n-1遍,算上影子 101 for(int i=1;i<=(2*m+w-p);i++) 102 if(D[v[i]]>D[u[i]]+edge[i]){ 103 D[v[i]]=D[u[i]]+edge[i]; 104 // cout<<i<<" "<<D[u[i]]<<" "<<D[v[i]]<<endl; 105 } 106 } 107 // cout<<D[1]<<" "<<D[2]<<" "<<D[3]<<" "<<D[n+1]<<endl; 108 }
但还是RE,实在烦RE,提交洛谷48分4个RE,看讨论说点不止有500个,我直接用洛谷看分了,发现增大数组后74分2个RE,代码如下
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[2012]; 6 int u[2012]; 7 int v[2012]; 8 int edge[10901]; 9 int dir[2012][2012]; 10 int exist[2012][2012]; 11 int F; 12 int n,m,w; 13 int a,b,c; 14 int p,q; 15 void bellman(); 16 int flag=0; 17 int main() 18 { 19 // freopen("zhishu.txt","r",stdin); 20 scanf("%d",&F); 21 while(F--){ 22 memset(exist,0,sizeof(exist)); 23 memset(edge,0x3f,sizeof(edge)); 24 memset(dir,0x3f,sizeof(dir)); 25 scanf("%d%d%d",&n,&m,&w); 26 for(int i=1;i<=m*2;i++){ 27 scanf("%d%d%d",&a,&b,&c); 28 u[i]=a; 29 v[i]=b; 30 edge[i]=c; 31 dir[a][b]=c; 32 exist[a][b]=i; 33 34 i++; 35 u[i]=b; 36 v[i]=a; 37 edge[i]=c; 38 dir[b][a]=c; 39 exist[b][a]=i; 40 } 41 p=0; 42 for(int i=m*2+1;i<=m*2+w-p;i++){ 43 scanf("%d%d%d",&a,&b,&c); 44 if(exist[a][b]!=0){ 45 edge[exist[a][b]]=-c; 46 p++; 47 i--; 48 } 49 else{ 50 u[i]=a; 51 v[i]=b; 52 edge[i]=-c; 53 dir[a][b]=-c; 54 exist[a][b]=i; 55 } 56 } 57 58 flag=0; 59 for(int i=1;i<=n;i++){ 60 61 q=2*m+w-p; 62 if(i!=1){ 63 for(int j=1;j<=n;j++){ 64 if(dir[j][i-1]!=0x3f3f3f3f){ 65 v[exist[j][i-1]]=i-1; 66 } 67 } 68 } 69 for(int j=1;j<=n;j++){ 70 if(dir[j][i]!=0x3f3f3f3f){ 71 v[exist[j][i]]=n+1; 72 } 73 } 74 75 memset(D,0x3f,sizeof(D)); 76 D[i]=0; 77 bellman(); 78 if(D[n+1]<0){ 79 flag=1; 80 cout<<"YES"<<endl; 81 break; 82 } 83 } 84 if(flag==0) 85 cout<<"NO"<<endl; 86 } 87 } 88 89 void bellman() 90 { 91 for(int k=1;k<=n;k++) 92 for(int i=1;i<=(2*m+w-p);i++) 93 if(D[v[i]]>D[u[i]]+edge[i]) 94 D[v[i]]=D[u[i]]+edge[i]; 95 }
硬是不想看数据
仔细想过发现应该是5000条边,因为双向,但超时了,洛谷1.2s就超时看来时限是1s,但poj2s时限也tm超艹!
加了个剪枝居然就AC了
AC代码(思路实在恶心,镜子根本没必要)
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[502];//点:因为我加了个影子顶点总共501个点,D[501],所以要开到502 6 int u[5201];//边:因为总共2500双向,5000个有向的,再加200个有向虫洞,5200,u[5200],所以要开5201 7 int v[5201]; 8 int edge[5201]; 9 int dir[502][502]; 10 int exist[502][502]; 11 int F; 12 int n,m,w; 13 int a,b,c; 14 int p,q; 15 void bellman(); 16 int flag=0; 17 int main() 18 { 19 // freopen("zhishu.txt","r",stdin); 20 scanf("%d",&F); 21 while(F--){ 22 memset(exist,0,sizeof(exist)); 23 memset(edge,0x3f,sizeof(edge)); 24 memset(dir,0x3f,sizeof(dir)); 25 scanf("%d%d%d",&n,&m,&w); 26 for(int i=1;i<=m*2;i++){ 27 scanf("%d%d%d",&a,&b,&c); 28 u[i]=a; 29 v[i]=b; 30 edge[i]=c; 31 dir[a][b]=c; 32 exist[a][b]=i; 33 34 i++; 35 u[i]=b; 36 v[i]=a; 37 edge[i]=c; 38 dir[b][a]=c; 39 exist[b][a]=i; 40 } 41 p=0; 42 for(int i=m*2+1;i<=m*2+w-p;i++){ 43 scanf("%d%d%d",&a,&b,&c); 44 if(exist[a][b]!=0){ 45 edge[exist[a][b]]=-c; 46 p++; 47 i--; 48 } 49 else{ 50 u[i]=a; 51 v[i]=b; 52 edge[i]=-c; 53 dir[a][b]=-c; 54 exist[a][b]=i; 55 } 56 } 57 58 flag=0; 59 for(int i=1;i<=n;i++){ 60 61 q=2*m+w-p; 62 if(i!=1){ 63 for(int j=1;j<=n;j++){ 64 if(dir[j][i-1]!=0x3f3f3f3f){ 65 v[exist[j][i-1]]=i-1; 66 } 67 } 68 } 69 for(int j=1;j<=n;j++){ 70 if(dir[j][i]!=0x3f3f3f3f){ 71 v[exist[j][i]]=n+1; 72 } 73 } 74 75 memset(D,0x3f,sizeof(D)); 76 D[i]=0; 77 bellman(); 78 if(D[n+1]<0){ 79 flag=1; 80 cout<<"YES"<<endl; 81 break; 82 } 83 } 84 if(flag==0) 85 cout<<"NO"<<endl; 86 } 87 } 88 89 void bellman() 90 { 91 int tp; 92 for(int k=1;k<=n;k++){ 93 tp=0; 94 for(int i=1;i<=(2*m+w-p);i++){ 95 if(D[v[i]]>D[u[i]]+edge[i]){ 96 tp=1; 97 D[v[i]]=D[u[i]]+edge[i]; 98 } 99 } 100 if(tp==0) 101 return; 102 } 103 }
详尽注释版本
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[502];//点:因为我加了个影子顶点总共501个点,D[501],所以要开到502 6 int u[5201];//边:因为总共2500双向,5000个有向的,再加200个有向虫洞,5200,u[5200],所以要开5201 7 int v[5201]; 8 int edge[5201]; 9 int dir[502][502]; 10 int exist[502][502]; 11 int F; 12 int n,m,w; 13 int a,b,c; 14 int p,q; 15 void bellman(); 16 int flag=0; 17 int main() 18 { 19 // freopen("zhishu.txt","r",stdin); 20 scanf("%d",&F); 21 while(F--){ 22 memset(exist,0,sizeof(exist)); 23 memset(edge,0x3f,sizeof(edge)); 24 memset(dir,0x3f,sizeof(dir)); 25 scanf("%d%d%d",&n,&m,&w); 26 for(int i=1;i<=m*2;i++){//用来存双向路的,无论奇数偶数都可以,自己举个例子1和2试下 27 scanf("%d%d%d",&a,&b,&c); 28 u[i]=a; 29 v[i]=b; 30 edge[i]=c;//贝尔曼算法真正用到的 31 dir[a][b]=c;//下面会说 32 exist[a][b]=i;//下面会说 33 34 i++; 35 u[i]=b; 36 v[i]=a; 37 edge[i]=c; 38 dir[b][a]=c; 39 exist[b][a]=i; 40 } 41 p=0; 42 for(int i=m*2+1;i<=m*2+w-p;i++){//输入虫洞用的 43 scanf("%d%d%d",&a,&b,&c); 44 if(exist[a][b]!=0){//之前exist记录了从a到b输入第几条边,如果exist不是0,证明之前从a到b在输入道路的时候输入过,那道路是正的,现在来个个负的路线,我可以直接把之前的路替换掉 45 edge[exist[a][b]]=-c; 46 p++;//证明我替换了几个,后面可以不用2*m+w那么边,直接2*m+w-p就行了 47 i--;//因为这次的i我是替换之前输入道路边,也即是这次虫洞数据记录在了之前有过的边里,那这次--,再++,相当于下次继续用这个数组下标,因为这次我没用 48 } 49 else{//如果之前道路没有,那就老老实实输路径 50 u[i]=a; 51 v[i]=b; 52 edge[i]=-c; 53 dir[a][b]=-c; 54 exist[a][b]=i; 55 } 56 } 57 58 flag=0; 59 for(int i=1;i<=n;i++){//1当出发点,2当出发点,3... 60 61 q=2*m+w-p;//总边数 62 if(i!=1){//这句话其实是给下面擦屁股用的,先去读下面那个 63 for(int j=1;j<=n;j++){ 64 if(dir[j][i-1]!=0x3f3f3f3f){ 65 v[exist[j][i-1]]=i-1;//先读下面的再读这句!修复数据,将i-1即上一次的出发点被影子顶点弄没了,这次先重新赋上 66 } 67 } 68 } 69 for(int j=1;j<=n;j++){//对先读这里,我遍历i~n,如果那个点到出发点,有路径(因为待会目的不是要回出发点嘛),那我把n+1设成影子顶点,其实是覆盖,终点修改成到n+1这个影子顶点的。这时候再去读上面那句话,我这次修改破坏了数据,下次我从i是2开始就得先修复数据,上面代码就是修复数据 70 if(dir[j][i]!=0x3f3f3f3f){//不是无穷大就代表路径 71 v[exist[j][i]]=n+1; 72 } 73 } 74 75 memset(D,0x3f,sizeof(D)); 76 D[i]=0; 77 bellman(); 78 if(D[n+1]<0){ 79 flag=1; 80 cout<<"YES"<<endl; 81 break; 82 } 83 } 84 if(flag==0) 85 cout<<"NO"<<endl; 86 } 87 } 88 89 void bellman() 90 { 91 int tp; 92 for(int k=1;k<=n;k++){ 93 tp=0; 94 for(int i=1;i<=(2*m+w-p);i++){ 95 if(D[v[i]]>D[u[i]]+edge[i]){ 96 tp=1; 97 D[v[i]]=D[u[i]]+edge[i]; 98 } 99 } 100 if(tp==0) 101 return; 102 } 103 }
poj的discuss里,一群傻逼说开大点不止500,我tm试了发现没必要,他们代码写错了而已,我看的严丝合缝AC了
poj确实水,发现有人超过1s在pojAC了
但又想到个事,这个题不剪枝TLE,加了100和101行的剪枝了才AC(我加影子顶点,不用考虑负环的事),有点问题呀,这代码复杂度10^9,1s完事了,依靠的是没完全走完贝尔曼的所有松弛趟数,那这么说,貌似贝尔曼最外层的n顶点遍历都没用上,那按着意思数据范围再给大点也可以,可是如果真正比赛,10^9写都不会去写,我写是因为我一开始以为2s时限,这数据范围误人子弟呢咋感觉(起码要保证最坏的时间复杂度能在给的时限内跑完才合理吧,或者加一个10^9的测试数据,也就是说跑满贝尔曼n-1个顶点的)—— 更新:后面了解到SPFA,又想起我写的这段了, 说SPFA已死的跟出这题的都是一个傻逼,能卡掉你SPFA,跑满你复杂度才是正常的吧
这思路恶心的不行,不用影子顶点再写一遍
清清爽爽,依旧是不加剪枝会TLE
AC代码
1 #include<stdio.h> 2 #include<iostream> 3 #include<string.h> 4 using namespace std; 5 int D[501];//点:因为我加了个影子顶点总共501个点,D[501],所以要开到502 6 int u[5201];//边:因为总共2500双向,5000个有向的,再加200个有向虫洞,5200,u[5200],所以要开5201 7 int v[5201]; 8 int edge[5201]; 9 int exist[502][502]; 10 int F; 11 int n,m,w; 12 int a,b,c; 13 int p,q; 14 void bellman(int x); 15 int flag=0; 16 int main() 17 { 18 // freopen("zhishu.txt","r",stdin); 19 scanf("%d",&F); 20 while(F--){ 21 memset(edge,0x3f,sizeof(edge)); 22 memset(exist,0,sizeof(exist)); 23 scanf("%d%d%d",&n,&m,&w); 24 for(int i=1;i<=m*2;i++){ 25 scanf("%d%d%d",&a,&b,&c); 26 u[i]=a; 27 v[i]=b; 28 edge[i]=c; 29 exist[a][b]=i; 30 31 i++; 32 u[i]=b; 33 v[i]=a; 34 edge[i]=c; 35 exist[b][a]=i; 36 } 37 p=0; 38 for(int i=m*2+1;i<=m*2+w-p;i++){ 39 scanf("%d%d%d",&a,&b,&c); 40 if(exist[a][b]!=0){ 41 edge[exist[a][b]]=-c; 42 p++; 43 i--; 44 } 45 else{ 46 u[i]=a; 47 v[i]=b; 48 edge[i]=-c; 49 } 50 } 51 52 flag=0; 53 for(int i=1;i<=n;i++){ 54 q=2*m+w-p; 55 memset(D,0x3f,sizeof(D)); 56 D[i]=0; 57 bellman(i); 58 if(flag==1){ 59 cout<<"YES"<<endl; 60 break; 61 } 62 } 63 if(flag==0) 64 cout<<"NO"<<endl; 65 } 66 } 67 68 void bellman(int x) 69 { 70 int tp; 71 for(int k=1;k<=n;k++){ 72 tp=0; 73 if(D[x]<0){ 74 flag=1; 75 return; 76 } 77 for(int i=1;i<=(2*m+w-p);i++){ 78 if(D[v[i]]>D[u[i]]+edge[i]){ 79 tp=1; 80 D[v[i]]=D[u[i]]+edge[i]; 81 } 82 } 83 if(tp==0) 84 return; 85 } 86 }
到此写完了,再去看看别人咋写的,主要觉得自己输入边和剪枝处理的不够好(回想之前洛谷题解提到过输入边乘2,先搁置)
发现都没像我一样在输入虫洞的时候处理没意义的road优化边数量,就洛谷有个弗洛伊德写法筛了下两点之间路径确保是最短的,比如2到3输入了4,2到3又输入了5,则实际存4
大多是用结构体SPFA队列,如果硬要处理,可以先用邻接矩阵输入的时候dir[a][b]记录下真正的边,然后两遍历for,dir的值挨个赋值给结构体点,结构体点压入队列。或者像我那样记录优化后的实际总边数,然后压入队列
还有用弗洛伊德的邻接矩阵输入的边(这题弗洛伊德是最好的,都不用遍历顶点,500*500*500比我的500 *(500 * 5200)好多了),还找到个洛谷题解也是贝尔曼福特,他单开了个h记录实际边长,比我清爽的多
洛谷题解提到SPFA卡常数(上一道题也说SPFA 卡常),听过还没遇到,留个卡常博客先搁置吧,
洛谷题解结构体SPFA优化,不错的模板,但mp明明是一维数组,用的时候确实二维数组好奇怪,暂时也不想写了,下面遇到不用SPFA队列优化过不了的题再写吧,放个参考博客(学到个技巧,不用走完n遍再判断,顶点只要第二次压入队列,虽然感觉貌似一样)—— 更新:vector一维数组其实是二维数组,vector一个变量,相当于一维数组。看别人代码相当痛苦,耗费时间,但这代码有个很大的好处
1、初始fl是0(fl是顶点到其他所有点的距离),只有比0小的才松弛,比我设置无穷大步步松弛找小于0的牛逼多了,一开始不明白为啥,如果有正边也能形成负环呢,其实只要能形成负环,关键一定是那个负边的点,所以你正边只是参与形成环而已,从人家负边点视为顶点既能优化又不会丢东西
2、fl我以为可以在遍历顶点的时候就memset,不懂为啥一步步return的时候改成0,自己大和尚小和尚想了好久,最后用对拍代码
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() { 5 srand(time(0) + (unsigned long long)(new char)); 6 cout<<1<<endl; 7 int n = rand() % 3 + 2; 8 int m=rand()%3+1; 9 int w=rand()%2+1; 10 cout<<n<<" "<<m<<" "<<w<<endl; 11 for(int i=0;i<m;i++){ 12 int u=rand()%n+1; 13 int v=rand()%n+2; 14 int p=rand()%7+1; 15 cout<<u<<" "<<v<<" "<<p<<endl; 16 } 17 for(int i=0;i<w;i++){ 18 int u=rand()%n+1; 19 int v=rand()%n+2; 20 int p=rand()%7+1; 21 cout<<u<<" "<<v<<" "<<p<<endl; 22 } 23 return 0; 24 }
生成样例
1 3 1 2 3 2 4 1 3 7 1 2 6
发现,其实每次从spfa出来,就已经相当于memset了,而真正应该做的是SPFA每次return的时候清空将标记置0,主要作用是为了比如这个样例,1到3是-,7,3进去,3到2是4,那此时1为顶点,顶点到2就是-3,2进去,2更新不了就返回,此时记住2已经是标记为1了,逐步返回,下次1走另一个路线1到2是-6,2又会进一遍,直接误判为YES
而我更加了解代码之后,给代码做了修改,不谈代码美不美观,之谈逻辑,其实每次遍历顶点之后,即在 spfa(i); 前面加一个 memset(fl,0,sizeof(fl)); ,然后SPFA函数里的两个 if (flag == 1) 里面的清空标记 fl[k] = 0; 就可以去掉了,只保留最后那个 fl[k] = 0; ,一样可以AC,因为究其本质,这个清空是给那些没找到还在继续找的用的(没找到逐步退回清标记,返回到前面能走其他路的点,去走其他路),即SPFA函数自己,还有就是这个顶点不行,回调用他的主函数,换下一个顶点用的。而如果找到了就没必要清空了,这个清空主要是给下一组输入数据用的。
这次这人的队列优化+DFS版本的SPFA代码吃明白了感觉,在没啥思路且不知道队列版本咋写的时候,即算半个新算法,我感觉直接吃别人代码更有效果,我自己写进误区耽误好久。
哎,还是太菜了,也不够专注,总心思女生
麻痹的不行,强迫症犯了,必须写下spfa队列优化,并且把bfs,dfs都写下(根据邝斌题目极佳的阶梯度感觉下一个题貌似就要用队列优化的)
查了好多说spfa已经死了,但我要先会用,参考博客、参考博客
SPFA已死?知乎:CodeRyan说的不能同意更多!!那些用SPFA被卡就说SPFA已死了的,不是自己傻逼没算明白复杂度导致的么?
大概知道意思了先写下,洛谷题解 、洛谷题解说这题SPFA要结合DFS,不能用BFS看的我云里雾里
为什么感觉脑子空空的,这些算法一个 都不会了的感觉。而且感觉自己学新东西好慢好慢啊啊啊啊,脑子要锈住了
唉,强迫症,我刷一道题好慢啊啊啊,但学新算法不写就是不行啊,我现在A掉了的这题都觉得对贝尔曼理解并不透彻,期待接下来的题
说是队列,怎么好多人用的是vector都没queue头文件
感觉不咋会写,返回去吃别人代码,见上面“洛谷题解结构体SPFA优化”的更新,即队列优化+DFS版本
但感觉BFS也可以啊(实时证明确实可以吧,难道我理解错啦?),并且感觉这个算法仅仅是负环,并没有学到正统的贝尔曼队列优化(即高潮博客里的这句:搞一个队列,第一轮让所有顶点都入队列,第二轮就只让第一轮更新出更短路径的顶点入队列(后续也是如此),只对队列中的顶点进行松弛操作,就可以避免冗余计算),看下其他人代码(BFS)
针对此人代码学会了第二种把边(结构体)压入vector容器的写法
读了两个SPFA代码感觉已经理解了SPFA,接下来尽量用SPFA刷题,这道题不想再写了
至此这题结束
###:
经历和阅历让我杀伐果断,但图书馆学习+心性始终无法↓,表面又很。妖朋友圈,江湖气+书生气。q神虽然不看代码,洛谷看,但我之前夏天群武理北大那个,我也给他找bug装逼,找bug再装女 19BUPT考研纸盒电梯场景刚学队列 不看题解的好处 1、踩过坑所有办法都想一遍,找到正确的解题办法,不然永远无法自己想到解题办法 2、题解的一个简简单单的结论,背后有许多思考,没亲自走过这些思考过程,这个结论根本看不懂,就算看懂了下次同样类型的根本想不到,因为很多坑其实相通
###:风格不错的博客
###:小知识回顾:n个点最多n(n-1)/2条边
###:codeblock里iostream包涵scanf,但POJ的scanf必须用stdio.h。参考博客、参考博客
###:时间是所有数据测试完的总合
###:vjudge评论区这人都没搞懂解题思路
###:边是Edge,点是V,在边E比较少的时候,即稀疏图,用贝尔曼和SPFA比较好
###:菊花图
###:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号