(4.13)sql server参数嗅探(parameter sniffing)
参考转自:https://blog.csdn.net/y1535623813/article/details/73331157
--参数嗅探 Parameter Sniffing
【1】存储过程中的疑惑
--当使用存储过程的时候,总是要使用到一些变量。变量有两种,一种
--是在存储过程的外面定义的。当调用存储过程的时候,必须要给他代入
--值。这种变量,SQL在编译的时候知道他的值是多少。
--例如: USE [AdventureWorks] GO DROP PROC Sniff GO CREATE PROC Sniff(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i GO --这里的变量@i,就是要在调用的时候代入值的 EXEC [dbo].[Sniff] @i = 50000 -- int GO
--还有一种变量是在存储过程里面定义的。他的值在存储过程的语句执行的过程中得到的。
--所以对这种本地变量,SQL在编译的时候不知道他的值是多少。
--例如:
USE [AdventureWorks] GO DROP PROC Sniff2 GO CREATE PROC Sniff2(@i INT) AS DECLARE @j INT SET @j=@i SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@j GO EXEC [dbo].[Sniff2] @i = 500000 -- int GO --这里的变量@j,是SQL在运行的过程中算出来的 --已经谈到过多次,SQL在处理存储过程的时候,为了节省编译时间, --是一次编译,多次重用的。用sp_executesql的方式调用的指令也是 --这样。那么执行计划重用就有两个潜在问题
--(1)对于第一类变量,根据第一次运行时代入的值生成的执行计划,是不是
--就能够适合所有可能的变量值呢?
--(2)对于第二类本地变量,SQL在编译的时候并不知道他的值是多少,那怎么
--选择“合适”的执行计划呢?
--对于第一个问题,会引出对 “参数嗅探”问题的定义。而对于第二个问题,本节
--将介绍使用本地变量对执行计划选择的影响。最后介绍参数嗅探问题的候选
--解决方案
------------------------------------------------------------------------
【2】什么是参数嗅探
--带着第一个问题,请做下面这两个测试
--测试一:
USE [AdventureWorks] GO DBCC freeproccache GO EXEC [dbo].[Sniff] @i = 500000 -- int --发生编译,插入一个使用nested loops联接的执行计划 GO EXEC [dbo].[Sniff] @i = 75124 -- int --发生执行计划重用,重用上面的nested loops的执行计划 GO
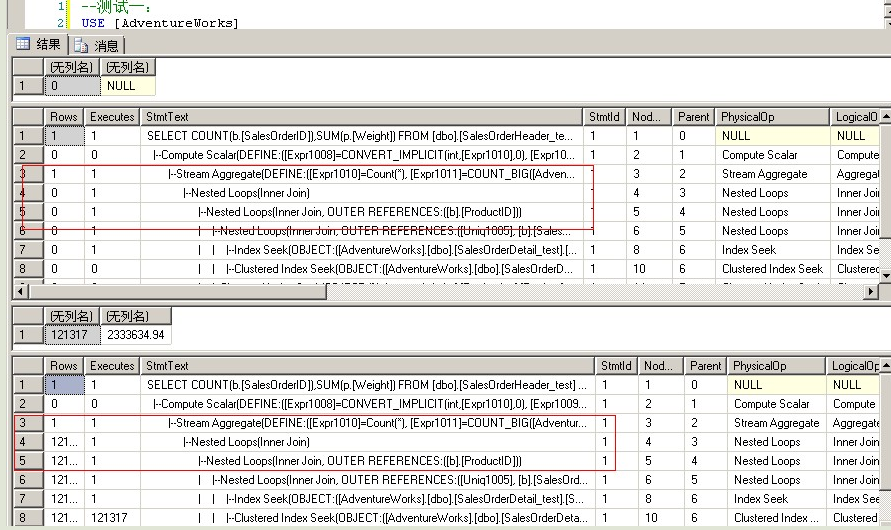
--测试二:
USE [AdventureWorks] GO DBCC freeproccache GO EXEC [dbo].[Sniff] @i = 75124 -- int --发生编译,插入一个使用hash match联接的执行计划 GO EXEC [dbo].[Sniff] @i = 50000 -- int --发生执行计划重用,重用上面的hash match的执行计划 GO

--从上面两个测试可以清楚地看到执行计划重用的副作用。由于数据分布差别很大
--参数50000和75124只对自己生成的执行计划有好的性能,如果使用对方生成的
--执行计划,性能就会下降。参数50000返回的结果集比较小,所以性能下降
--不太严重。参数75124返回的结果集大,就有了明显的性能下降,两个执行计划
--的差别有近10倍
核心概念:参数嗅探特性
当SQL Server第一次执行查询语句或存储过程(或者查询语句与存储过程被强制重新编译)的时候,SQL Server会有一个进程来评估传入的参数,并根据传入的参数生成对应的执行计划缓存;
然后参数的值会伴随查询语句或存储过程执行计划一并保存在执行计划缓存里。这个评估的过程就叫做参数嗅探。
参数嗅探引起的问题:
为什么会出现参数嗅探的问题?
是因为缓存执行计划的这个机制
--对于这种因为重用他人生成的执行计划而导致的水土不服现象,SQL有一个专有
--名词,叫“参数嗅探 parameter sniffing”是因为语句的执行计划对变量的值
--很敏感,而导致重用执行计划会遇到性能问题
在理想情况,即外部因素包括索引、索引碎片、统计信息都较为合理时,参数嗅探导致的问题一般都是发生在数据分布差异比较大的情况下
【2.1】本地变量的影响
--那对于有parameter sniffing问题的存储过程,如果使用本地变量,会怎样呢?
--下面请看测试3。这次用不同的变量值时,都清空执行计划缓存,迫使其
--重编译
--第一次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff] @i = 50000 -- int GO ------------------------------
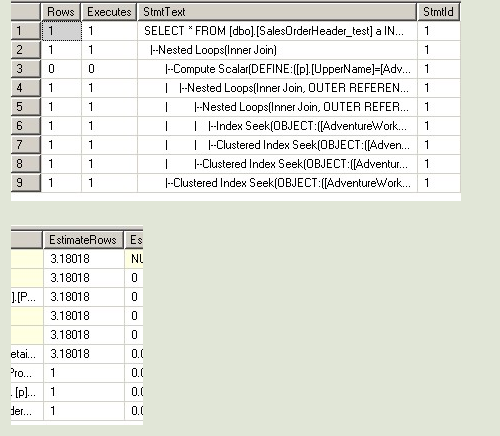
--第二次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff] @i = 75124 -- int GO --------------------------------
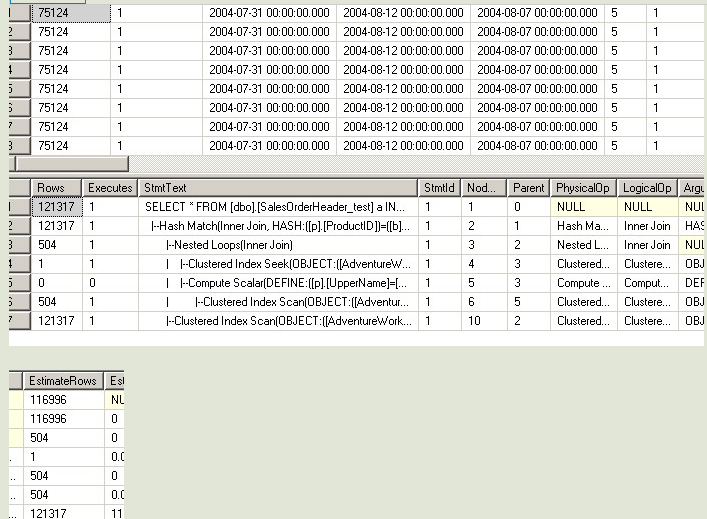
--第三次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff2] @i = 50000 -- int GO ---------------------------------
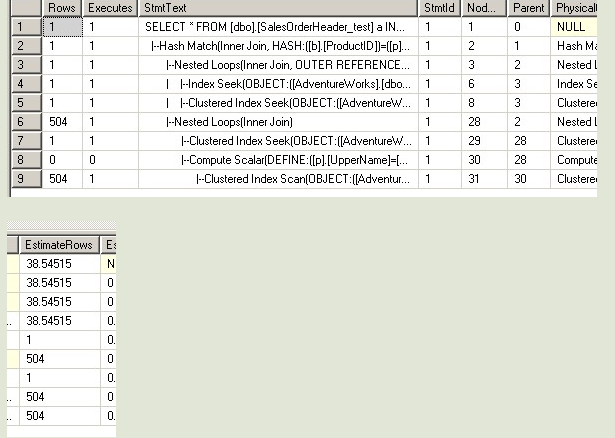
--第四次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff2] @i = 75124 -- int GO

--来看他们的执行计划:
--对于第一句和第二句,因为SQL在编译的时候知道变量的值,所以在做EstimateRows的时候,
--做得非常准确,选择了最适合他们的执行计划
--但是对于第三句和第四句,SQL不知道@j的值是多少,所以在做EstimateRows的时候,
--不管代入的@i值是多少,一律给@j一样的预测结果。所以两个执行计划是完全一样的。
--这里EstimateRows的大小,在语句1和语句2的值之间,所以他选择的执行计划,和
--语句1与语句2都不一样
--我们再来比较一下不同执行计划下的速度
-------------------------------------- --第一次 SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 715 毫秒。 SQL Server 执行时间: CPU 时间 = 16 毫秒,占用时间 = 1775 毫秒。 -------------------------------------------- -------------------------------------- --第二次 SQL Server 执行时间: CPU 时间 = 998 毫秒,占用时间 = 9821 毫秒。 SQL Server 执行时间: CPU 时间 = 998 毫秒,占用时间 = 9906 毫秒。 -------------------------------------------- -------------------------------------- --第三次 SQL Server 执行时间: CPU 时间 = 15 毫秒,占用时间 = 57 毫秒。 SQL Server 执行时间: CPU 时间 = 15 毫秒,占用时间 = 66 毫秒。 -------------------------------------------- -------------------------------------- --第四次 SQL Server 执行时间: CPU 时间 = 1981 毫秒,占用时间 = 6926 毫秒。 SQL Server 执行时间: CPU 时间 = 1997 毫秒,占用时间 = 6933 毫秒。 --------------------------------------------
--有参数嗅探的情况,语句三和语句四作出来的执行计划是一种比较中庸的方法,不是最快的
--也不是最慢的。他对语句性能的影响,一般不会有参数嗅探那么严重,他还是解决参数嗅探的一个候选方案
---------------------------------------------------------------------------------
【3】参数嗅探的解决方案
--参数嗅探的问题发生的频率并不高,他只会发生在一些表格里的数据分布很不均匀,或者
--用户带入的参数值很不均匀的情况下。例如,查询一个时间段数据的存储过程,如果
--大部分用户都只查1天的数据,SQL缓存的也是这样的执行计划,那对于那些要查一年
--的数据,可是SQL碰到“参数嗅探”问题的风险了。如果系统里大部分用户都要查一年的数据
--可是SQL碰巧缓存了一个只查一天数据的存储过程,那大部分用户都会遇到“参数嗅探”的问题
--这个对性能的影响就大了
--有什么办法能够缓解,或者避免参数嗅探问题呢?在SQL2005以后,可以有很多种方法可供选择
【3.1】用exec()的方式运行动态SQL
--如果在存储过程里不是直接运行语句,而是把语句带上变量,生成一个字符串,再让exec()这样
--的命令做动态语句运行,那SQL就会在运行到这句话的时候,对动态语句进行编译。这时SQL
--已经知道了变量的值,会根据生成优化的执行计划,从而绕过参数嗅探问题
--例如前面的存储过程Sniff,就可以改成这样 USE [AdventureWorks] GO DROP PROC NOSniff GO CREATE PROC NOSniff(@i INT) AS DECLARE @cmd VARCHAR(1000) SET @cmd='SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=' EXEC(@cmd+@i) GO --然后再用上面的顺序调用会得到比他更好的性能 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].NOSniff @i = 50000 -- int GO -------------------------------- USE [AdventureWorks] GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].NOSniff @i = 75124 -- int GO
--使用exec()的方式产生动态编译
--在查询语句执行之前,都能看见SP:CacheInsert事件。SQL做了动态编译,根据变量的值,
--正确地估计出每一步的返回结果集大小。所以这两个执行计划,是完全不一样的
--执行结果很快,这种方法的好处,是彻底避免参数嗅探问题。
--但缺点是要修改存储过程的定义,而且放弃了存储过程一次编译,多次运行的优点,在编译性能上有所损失
【3.2】使用本地变量local variable
--在前面,提到了如果把变量值赋给一个本地变量,SQL在编译的时候是没办法知道这个本地
--变量的值的。所以他会根据表格里数据的一般分布情况,“猜测”一个返回值。不管用户
--在调用存储过程的时候代入的变量值是多少,做出来的执行计划都是一样的。而这样
--的执行计划一般比较“中庸”,不会是最优的执行计划,但是对大多数变量值来讲,也不会
--是一个很差的执行计划
--存储过程[Sniff2]就是这样一个例子
--这种方法的好处,是保持了存储过程的优点,缺点是要修改存储过程,而且执行计划也不是
--最优的
【3.3】query hint(recompile,指定join运算,OPTIMIZE FOR,Plan Guide)
在语句里使用query hint,指定执行计划
--在select,insert,update,delete语句的最后,可以加一个"option(<query_hint>)"的子句
--对SQL将要生成的执行计划进行指导。当DBA知道问题所在以后,可以通过加hint的方式,引导
--SQL生成一个比较安全的,对所有可能的变量值都不差的执行计划
--现在SQL的query hint还是很强大的,有十几种hint。完整的定义是:
--msdn:http://msdn.microsoft.com/zh-cn/library/foo66fb1520-dcdf-4aab-9ff1-7de8f79e5b2d.aspx <query_hint > ::= { { HASH | ORDER } GROUP | { CONCAT | HASH | MERGE } UNION | { LOOP | MERGE | HASH } JOIN | FAST number_rows | FORCE ORDER | MAXDOP number_of_processors | OPTIMIZE FOR ( @variable_name = literal_constant [ , ...n ] ) | PARAMETERIZATION { SIMPLE | FORCED } | RECOMPILE | ROBUST PLAN | KEEP PLAN | KEEPFIXED PLAN | EXPAND VIEWS | MAXRECURSION number | USE PLAN N'xml_plan' } --这些hint的用途不一样。有些是引导执行计划使用什么样的运算的,比如, -- | { CONCAT | HASH | MERGE } UNION -- | { LOOP | MERGE | HASH } JOIN --有些是防止重编译的,例如 -- | PARAMETERIZATION { SIMPLE | FORCED } -- | KEEP PLAN -- | KEEPFIXED PLAN --有些是强制重编译的,例如 -- | RECOMPILE --有些是影响执行计划的选择的,例如 --| FAST number_rows --| FORCE ORDER --| MAXDOP number_of_processors --| OPTIMIZE FOR ( @variable_name = literal_constant [ , ...n ] ) --所以他们适合在不同的场合。具体的定义,请看SQL的联机帮助
--为了避免参数嗅探的问题,有下面几种常见的query hint使用方法
(1)recompile
--(1)recompile --recompile这个查询提示告诉SQL,语句在每一次存储过程运行的时候,都要重新编译一下。 --这样能够使SQL根据当前变量的值,选一个最好的执行计划。对前面的那个例子,我们可以 --这样写 USE [AdventureWorks] GO DROP PROC NoSniff_QueryHint_Recompile GO CREATE PROC NoSniff_QueryHint_Recompile(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i OPTION(RECOMPILE) GO -------------------------------------- USE [AdventureWorks] GO DBCC freeproccache GO EXEC NoSniff_QueryHint_Recompile 50000 GO ------------------------------------- USE [AdventureWorks] GO EXEC NoSniff_QueryHint_Recompile 75124 GO --在SQL Trace里我们能够看到,语句运行之前,都会有一个SQL:StmtRecompile的事件发生 --而使用的执行计划,就是最准确的那种 --和这种方法类似,是在存储过程的定义里直接指定“recompile”,也能达到避免 --参数嗅探的效果 USE [AdventureWorks] GO DROP PROC NoSniff_SPCreate_Recompile GO CREATE PROC NoSniff_SPCreate_Recompile(@i INT) WITH RECOMPILE AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i GO ------------------------------------------------- USE [AdventureWorks] GO DBCC freeproccache GO EXEC NoSniff_SPCreate_Recompile 50000 GO ------------------------------------------------ USE [AdventureWorks] GO EXEC NoSniff_QueryHint_Recompile 75124 GO
--在SQL Trace里,我们能看到,存储过程在执行的时候已经找不到前面的执行计划
--SP:CacheMiss,所以要生成新的。而使用的执行计划,就是最准确的那种
--这两种“Recompile”提示的差别是,如果在语句层次指定OPTION(RECOMPILE),
--那存储过程级别的计划重用还是会有的。只是在运行到那句话的时候,才会发生重编译。
--如果存储过程里有if-else之类的逻辑,使得发生问题的语句没有执行到,那重编译就不会发生。
--所以,这是一种问题精确定位后,比较精细的一种调优方法。如果在存储过程级别
--指定WITH RECOMPILE,那整个存储过程在每次执行的时候都要重编译,这个重复工作量就比较大了
--但是,如果问题没有精确定位,可以用这种方法快速缓解问题
(2)指定join运算 { LOOP | MERGE | HASH } JOIN
--很多时候,参数嗅探问题是由于SQL对一个该用merge join/hash join的情况误用了
--nested loops join。确定了问题后,当然可以用查询提示,指定语句里所有join方法。
--但是这种方法一般很不推荐,因为不是所有的join,SQL都能够根据你给的提示做出来
--执行计划的。如果对例子存储过程的那个查询最后加上“option(hash join)”,运行
--的时候会返回这样的错误。SQL不接受这个查询提示:
消息 8622,级别 16,状态 1,第 1 行
由于此查询中定义了提示,查询处理器未能生成查询计划。请重新提交查询,
并且不要在查询中指定任何提示,也不要使用 SET FORCEPLAN。
--更常见的是,在特定的那个join上使用join hint。这种方法成功几率要高得多
--例如:
USE [AdventureWorks] GO DROP PROC NoSniff_QueryHint_JoinHint GO CREATE PROC NoSniff_QueryHint_JoinHint(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER hash JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i GO USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS PROFILE ON GO EXEC NoSniff_QueryHint_JoinHint 50000 GO --------------------------------------------- USE [AdventureWorks] GO SET STATISTICS PROFILE ON GO EXEC NoSniff_QueryHint_JoinHint 75124 GO
--这种方法的好处,是保持了存储过程一次编译,后续多次使用的特性,节省编译时间。
--但是缺点也很明显,使用这样的方法生成执行计划,不一定就是一个好的执行计划
--而且表格里的数据量变化以后,现在合适的join方式将来可能就不合适,到时候还会
--造成性能问题,所以使用的时候要很小心
(3)OPTIMIZE FOR ( @variable_name = literal_constant [ , ...n ] )
--当确认了参数嗅探问题后,发现,根据某些变量值生成的执行计划,快和慢会相差
--很大,而根据另外一些变量生成的执行计划,性能在好和坏的时候,相差并不很大。
--例如当变量等于50000的时候,他用最好的nested loops执行计划,用时十几毫秒,
--用hash join的那个执行计划,也不过300多毫秒。但是变量等于75124的时候,
--hash join执行计划需要500多毫秒,用nested loops的时候,要用4000多。
--从绝对值来讲,让用户等几百毫秒一般是没问题的。但是等上几秒钟,就容易
--收到抱怨了。所以hash join是一个比较“安全”的执行计划。如果SQL总是使用75124
--这个值做执行计划,会对大部分查询都比较安全。
--使用OPTIMIZE FOR这个查询指导,就能够让SQL做到这一点。这是SQL2005以后的一个新
--功能。
USE [AdventureWorks] GO DROP PROC NoSniff_QueryHint_OptimizeFor GO CREATE PROC NoSniff_QueryHint_OptimizeFor(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER hash JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i OPTION(optimize FOR(@i=75124)) GO --------------------------------- USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS PROFILE ON GO EXEC NoSniff_QueryHint_OptimizeFor 50000 GO --------------------------------------------- USE [AdventureWorks] GO SET STATISTICS PROFILE ON GO EXEC NoSniff_QueryHint_OptimizeFor 75124 GO
--从SQL Trace里看,存储过程第一次运行时有编译,但是第二次就出现了执行计划重用
--分析执行计划会发现SQL在第一次编译时,虽然变量值是50000,他还是根据75124
--来做预估的,EstimateRows的值很大。正因为这样,第二次运行也有不错的性能
--这种方法的优点是,既能够让SQL作出有倾向性的执行计划,又能保证SQL选择执行计划
--时候的自由度,所以得到的执行计划一般是比较好的。相对于用join hint,这个方法
--更精细一些。缺点是,如果表格里的数据分布发生了变化,比如用户有一天把
--75124的记录全删除了,那SQL选择的执行计划就不一定继续正确了。所以他也有他
--的局限性。
--上面介绍的方法,都有一个明显的局限性,那就要去修改存储过程定义。有些时候没有
--应用开发组的许可,修改存储过程是不可以的。对用sp_executesql的方式调用的指令,
--问题更大。因为这些指令可能是写在应用程序里,而不是SQL里。DBA是没办法去修改
--应用程序的。
--好在SQL2005和2008里,引入和完善了一个种叫Plan Guide的功能。DBA可以告诉SQL,当
--运行某一个语句的时候,请你使用我指定的执行计划。这样就不需要去修改存储过程或
--应用了。
(4)Plan Guide
--例如可以用下面的方法,在原来那个有参数嗅探问题的存储过程“Sniff”上,解决sniffing问题
USE [AdventureWorks] GO EXEC [sys].[sp_create_plan_guide] @name=N'Guide1', @stmt=N'SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i', @type=N'OBJECT', @module_or_batch=N'Sniff', @params=NULL, @hints=N'option(optimize for(@i=75124))'; GO ----------------------------------- USE [AdventureWorks] GO SET STATISTICS PROFILE ON GO DBCC freeproccache GO EXEC [dbo].[Sniff] @i = 50000 -- int GO --使用了75124的hash match的join方式 --对于Plan Guide,他还可以使用在一般的语句调优里。在后面的章节会介绍
【4】解决方法的比较
-- 方法 是否修改存储过程 是否每次运行都要重编译 执行计划准确度
--用exec()方式运行动态SQL 需要 会 很准确
--使用本地变量local variable 需要 不会 一般
--query hint+"recompile" 需要 会 很准确
--query hint指定join运算 需要 不会 很一般
--query hint optimize for 需要 不会 比较准确
--Plan Guide 不需要 不会 比较准确

【5】可能引起参数嗅探的原因分析(理论)
(1)索引合适度合理性
(2)索引缺失
(3)索引碎片过大
(4)统计信息跟新不及时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号