
(3.6)sql server存储引擎--文件与数据页及数据行的结构
一. 文件
(1)主数据文件.mdf初始大小至少为3MB(在sql2012/2008以后至少需要5M),次要数据文件.ndf初始大小,同日志文件一样至少为512KB(在sql2012/2008以后至少需要1M);
(2)SQL SERVER在逻辑上用文件组将文件分批管理(类似ORACLE的TABLESPACE),一个文件组可以包含多个文件,插入数据时,同一个文件组内的所有文件等比例增长(ORACLE的一个TABLESPACE中逐个使用多个文件),例如:文件组中有两个文件,初始大小分别为100M和200M,此时插入3M数据,file1新增(100/300)*3M=1M,file2新增(200/300)*3M=2M,如下图:


(3)页(page),SQL SERVER中的数据文件由8K大小的数据页组成,每个数据文件中的页从0开始编号,页大小不可以自定义(ORACLE可自定义),且每个页只可以属于一个数据对象;
(4)区(extent),或者叫扩展,8个物理上连续的页为一个扩展,即64K,扩展的存在是为了避免不停地分配8K的页面,提高页面分配的效率。SQL SERVER有两种类型的区,如下图:

(4.1)混合区:为了节约空间,将少量数据的表或索引存放在混合区中,当表或索引的数据增长到8页时,再使用统一区来存放,一个混合区有8个页,每个页可以属于不同的数据对象,即每个混合区最多为8个数据对象共享;
(4.2)统一区:由单个数据对象所有,如果对表中现有数据创建索引,且索引的大小超过8页,则索引将全部使用统一区,没有混合区的分配过程。

二. 页
2.1、非数据页
(1)文件头(FILE HEADER),每个数据文件的第1页,页号为0,该页主要包括当前文件的属性描述,比如:文件组ID、文件ID、文件当前大小、文件最大/最小值、文件增量、一系列的LSN等;
(2)页面空闲空间(PFS),每个数据文件的第2页,页号为1,该页记录当前数据文件每个数据页的空间状态:该页是为空、已满 1% 到 50%、已满 51% 到 80%、已满 81% 到 95% 还是已满 96% 到 100%。PFS页内用1个字节来描述1个数据页的分配及空间状态,每个PFS页约有可用空间8088个字节,即数据文件内约每64M的空间会出现一个PFS页。PFS页描述数据页空间状态如下图:


(3)全局分配映射(GAM),每个数据文件的第3页,页号为2,该页记录当前数据文件每个区的分配状态,0为已使用(作为混合区或统一区,已被分配),1为未使用(自由区,未被分配);
(3.1)结合PFS和IAM页,如果数据对象没有可用空间时,且数据大小已超过8页,GAM为数据对象分配一个统一区;若数据大小尚未超过8页,则GAM结合SGAM为其寻找或者分配一个混合区;
(3.2)GAM页内用1位来描述1个区的分配状态,每个GAM页约有可用空间8000个字节,即数据文件内约每4G的空间会出现一个GAM页;
(4)共享分配映射(SGAM),每个数据文件的第4页,页号为3,该页记录当前数据文件哪些区被用作混合区,1为含有自由页面的混合区,0为自由区或已满的混合区;
(4.1)当数据对象需要一个含有自由页面的混合区时,SGAM用来辅助GAM寻找或分配一个混合区;
(4.2)SGAM页内用1位来描述1个区的分配状态,每个SGAM页约有可用空间8000个字节,即数据文件内约每4G的空间会出现一个SGAM页;
(5)索引分配映射(IAM),该页跟踪数据文件中的页属于哪一个数据对象,IAM页头有8个页面指针,指向数据对象在混合区中的数据页(如果混合区中数据被删除可能少于8个指针),IAM页内比特位为1表示该区属于自己所属的数据对象,比特位为0表示该区不属于自己所属的数据对象;
(5.1)每个数据对象的每个分配单元拥有一个IAM页,IAM同GAM、SGAM一样可以管理约4G的空间,如果分配单元包含多个文件,或者文件大小超过4G,则需要另外的IAM页来管理,IAM页间通过双向链表连接;
(5.2)可以通过sysindexes或sys.system_internals_allocation_units系统目录得到first_IAM页面的位置,IAM页在数据文件中的位置是随机的,可能IAM页所在文件并不是所管理的那个文件;

(5.3)对于堆数据插入而言,通过IAM页和PFS页找到自己有剩余空间的页,直接插入数据即可,但索引数据插入的位置是由索引键的顺序决定的;
(6)差异更改映射(DCM),每个数据文件的第7页,页号为6(页号4,5为保留页),该页跟踪当前数据文件中,自上次全备份后被修改的区,以提高差异备份的效率,1为被修改过,0为未被修改;
(6.1)DCM页内用1位来描述1个区的分配状态,每个DCM页约有可用空间8000个字节,即数据文件内约每4G的空间会出现一个DCM页;
(7)大批量更改映射(BCM),每个数据文件的第8页,页号为7,该页跟踪当前数据文件中,自上次日志备份后被大批量操作修改的区, 1为被修改过,0为未被修改;
(7.1)大批量恢复模型只记载大批量操作的最小日志记录(不记录明细,只记载动作),所以比在全恢复模型下执行速度要快(因为省去写大量日志的成本),但为了保证数据库的可恢复,在进行日志备份时,仍然会使用BCM页将大批量操作所修改的区备份出来,所以此时会出现日志很小,但日志备份很大的情况;
(7.2)BCM页只有在大批量恢复模型下才有用,因为简单恢复模型下不记载任何大批量操作的日志,且日志自动截断,全恢复模型下有详细的日志纪录;
(7.3)BCM页内用1位来描述1个区的分配状态,每个BCM页约有可用空间8000个字节,即数据文件内约每4G的空间会出现一个BCM页;
2.2、数据页
2.2.1、DATA
(0)数据页,包括页头、数据行、行偏移矩阵三部分内容,如下图:


(0.1)页头固定大小为96B,包括页号、所属对象、LSN等页面信息;
(0.2)数据行累计不超过8060B,那么单行数据最长为8060B,由于数据行还存在一些行开销,所以建表时,数据类型的最大长度不允许超过8000B(LOB类型除外),行开销在下面会有介绍;
(0.3)行偏移矩阵以2B为一个指针,标识每一个数据行的起点位置。哪怕是索引页,数据行在页内的物理顺序也并不一定是有序的,数据读取时按行偏移矩阵的顺序读出(从slot0起),从逻辑上保证了数据行在页内的顺序,可能slot0对应的数据行是在页面内物理上的第N行(N<>1);
(1)行内数据(IN_ROW_DATA)
单行未超过8060B的数据行,或者单行超过8060B但存储在当前页的数据,称为行内数据;
(2)行溢出数据(ROW_OVERFLOW_DATA)
在SQL SERVER 2005及以后的版本中,如果表中定义了变长数据类型,允许单行数据长度突破8060B,超过的部分即为行溢出数据,如果变长列被更新后缩短,可能会被移回行内数据页(通常减少1000字节以上时,SQL SERVER才会有检查是否可移回);
(2.1)行溢出数据为超过8060B数据行的一部分列,在行内数据页上有24B的指针指向行溢出数据页;
(2.2)只会将变长数据类型的行溢出数据移出行内数据页,因为定长数据类型在定义表时就不允许累计长度超过8000B,所以行内数据页足够存放定长数据列;
(2.3)移出行内数据页的变长列,必然是整列数据,不会将变长列数据拆开存放,一个新的数据页也足够存放最大长度为8000B的变长列;
(2.4)如果变长列使用了MAX分类符,如:varchar(MAX),则数据库自动根据varchar(MAX)的数据长度选择不同的数据页,如果MAX<=8000,则使用行溢出数据页;如果MAX>8000则使用大对象数据页;
(3)大对象数据(LOB_DATA)
存放如:TEXT/IMAGE/XML/varchar(MAX)等最大长度可超过8000B的数据类型的数据;
(3.1)大对象数据也是通过8k的数据页来存储数据,在行内数据页中包含一个16字节的指针指向大对象数据的根页,大对象数据通过B-树结构来组织多个数据页;
(3.2)可以通过打开text in row选项将大对象数据存储在行内数据页,当大对象数据被更新超过500B时,则会从行内数据页将大对象数据移出,这是个日志操作,因此移动操作比较耗时,所以不建议开启该选项;
(4)数据行
每个数据行,除了每个列的数据之外,还包括状态位、定长列偏移量、总列数、NULL位图、变长列数、列偏移矩阵,这些即为行开销。
创建全定长列的表,数据行如下图:
if object_id ('test_col') is not null drop table test_col; GO create table test_col ( col1 char(1), col2 char(2) ) GO insert into test_col values('A','B')

(4.1)状态位A占1B标识列的类型、是否有变长列等信息,状态B占1B未启用;
(4.2)定长列偏移量占2B,标识定长列的截止位置,这里为1+1+2+1+2=7B,每个定长列的起始位置,可以在无文档记载的系统视图sys.system_internals_partition_columns中查到(leaf_offset字段),col1、col2为定长数据所在;
(4.3)在包含可为NULL的列时(定长列为NULL时列值为0,而变长列不存储列值),这时就需要总列数(占2B)和NULL位图了,比如:有4列,NULL位图为11110100(由低位向高位对应),则表示第3列为NULL,那么第1、2、4列返回数据,第3列返回NULL。上图中两列均可为NULL(11111100)但都有值,所以不返回NULL,NULL位图的长度随着表中列数的多少在变化,以BYTE为单位进行增长,最小为1B即8位,可以标识8列;
(4.4)全定长的数据行中,不包括变长列数、列偏移矩阵的行开销;
创建包含变长列的表,数据行如下图:
if object_id ('test_col2') is not null drop table test_col2; GO create table test_col2 ( col1 char(1), col2 varchar(2) ) GO insert into test_col2 values('A','B')

(4.5)此时定长列偏移量为1+1+2+1=5B,因为只一个长度为1B的定长列,另外,总列数仍然是2,NULL位图也相同;
(4.6)变长列数占2B,表示表中有几个变长列,它决定了后面的列偏移矩阵中要放几个元素,列偏移矩阵标识表中每个变长列的截止位置,col2为变长数据所在;
创建全变长列的表,数据行如下图:

if object_id ('test_col3') is not null drop table test_col3; GO create table test_col3 ( col1 varchar(1), col2 varchar(2), col3 varchar(3) ) GO insert into test_col3 values(NULL,'','B')

(4.7)此时定长列偏移量为1+1+2=4B,因为没有定长列,另外,总列数为3,NULL位图为11111001,表示第1列为NULL,第2列与第1列偏移量一样,表示没有值,但又不为NULL,即空字符串,变长列数为3,列偏移矩阵中共有3个元素;
(4.8)当表中的列被删除时,列在数据行中的占用的空间并不会立即被回收,除非立即重建索引,或者当空间不足时数据库才考虑回收;
(4.9)当表中的列被修改时:
(a)从NULL到NOT NULL,数据类型长度缩短都会带来全表的该列数据检查,对于大表将非常耗时;
(b)对于修改数据类型长度,并没有真正替换原有列,只是新增了一列,根据列偏移量读取数据时,原有列不会被读到而已,并且对于定长列,只是限制了新插入数据的值范围,列存储空间依旧使用改变前的数据类型的长度,如下图:
alter table test_col alter column col2 char(1) --以下语句将失败 insert into test_col values('A','BB')


此时定长列偏移量仍然为1+1+2+1+2=7B,总列数仍然为2,新增的列位于原有列之前;
(c)修改变长列数据类型长度后,列偏移矩阵会向后移动,如下图:
alter table test_col3 alter column col3 varchar(1)


此时变长列数为4,原来的第3列从0x11到0x12,长度为1,第4列为原有列,并且新的列值将会使用新的数据类型长度;
(4.10)当表中新增列时,无法指定新列的逻辑顺序(列号),只能排在后面,除非重建表,在某些图形工具中将新列插入到某个位置,事实上就是在重建表;新增列的物理顺序放在数据行的相应数据区域,如下图:
alter table test_col3 add col_new char(1) not null default 'a'


定长列col_new被放在定长数据区域,从列偏移矩阵可以看出,后面的变长数据相应的向后移动了1B;
转自:http://blog.51cto.com/qianzhang/1217431
1 数据页的类型
| Id | User_for | Page Type | Page Name | Description |
| 1 | 实际数据 | 数据页 | Data Page | 堆表或者聚集索引的叶子节点 |
| 2 | 索引页 | Index Page | 聚集索引的分支节点或者非聚集索引 | |
| 3 | LOB | LOB | 用来存放大型对象数据类型:text , image ,varchar(max) , varbinary(max)等 | |
| 4 | 行溢出页 | Row Overflow Page | 只能存储单一text或者image列数据块 | |
| 5 | 管理数据页数据 | GAM页 | Global Allocation Map | 管理统一区的位图 |
| 6 | SGAM页 | Shared Global Allocation Map | 管理混合区的位图 | |
| 7 | IAM页 | Index Allocation Map | 分配单元分配到的区 | |
| 8 | PFS页 | Page Free Space | 可用空间 | |
| 9 | 备份相关的数据 | DCM页 | Differential Changed Map | 自最后一条backup database 语句之后更改的区的信息 |
| 10 | BCM页 | Bulk Changed Map | 自最后一条backup log语句之后的大容量操作所修改的区的信息 |

1.1 PFS
- bit 0-2位,描述该页还有多少空闲空间
- 0x00 is empty
- 0x01 is 1 to 50% full
- 0x02 is 51 to 80% full
- 0x03 is 81 to 95% full
- 0x04 is 96 to 100% full
- bit 3 (0x08): 该数据页是否存在鬼影记录(ghost records:http://www.cnblogs.com/lyhabc/archive/2013/06/16/3138214.html)?
- bit 4 (0x10): 是否是IAM页?
- bit 5 (0x20): 是否是混合页?
- bit 6 (0x40): 是否已分配使用?
- Bit 7 保留,未使用,无实际含义
1.2 GAM & SGAM & IAM
1.2.1 GAM
- Bit=1,标识当前的区是空闲的,可以用来分配;
- Bit=0,标识当前的区以及被数据使用。
1.2.2 SGAM
- 当存储引擎分配一个统一区时,在GAM页中寻找标记为1的页面,把标记修改为0,SGAM页中的标记位不做变动,保持为0;
- 当存储引擎分配一个混合区时,在GAM页中寻找标记为1的页面,把标记修改为0,SGAM页中的标记位从0修改1;
- 当存储引擎寻找一个有空闲页的混合区是,直接在SGAM页中查找标记位1对应的数据页;如果没有找到,则会重新分配一个混合区。
1.2.3 IAM
- IN_ROW_DATA
- 存储堆或索引分区,即heap和B-tree。
- LOB_DATA
- 存储大型对象 (LOB) 数据类型,例如 xml、varbinary(max) 和 varchar(max)。
- ROW_OVERFLOW_DATA
- 存储超过 8,060 字节行大小限制的 varchar、nvarchar、varbinary 或 sql_variant 列中存储的可变长度数据。
每个有数据的表格,至少有一个 IAM页来管理 IN_ROW_DATA的存储情况,如果表格里有LOB_DATA,则会多一个IAM页来管理LOB_DATA,ROW_OVERFLOW_DATA也是一样。
2 数据页结构
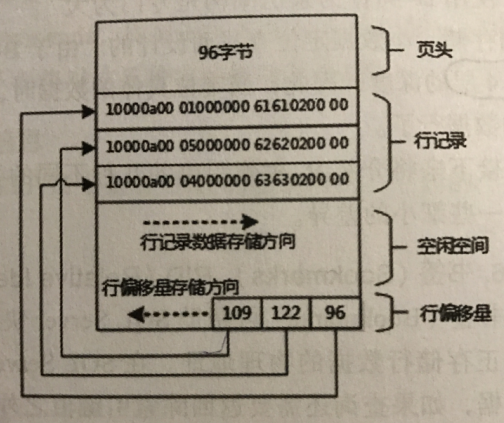
2.1 页头
占用96字节,存储跟该页面相关的系统数据。
页头的内容如下:
2.2 行记录
- 存储数据行记录以及索引数据
- 行记录也可以在独立页面上存储,比如行溢出数据即LOB数据
2.3 空闲空间
- 除去页头,行记录,以及偏移量剩下的空间,提供给行记录及行偏移量使用
2.4 行偏移量
- 行偏移是一个个小块组成的,每个小块2个字节,表示数据行从第几个字节后开始记录,也就是距离页头多少偏移量开始记录
- 存储方式是从有往左存储,用槽位来描述,slot 0 ,slot 1 ....
- 行偏移量记录的内容是什么呢?该行记录从哪个字节开始,一般情况下,slot 1 从第96个字节后开始
- 常说的聚集索引存储顺序是物理排序,指的不是行记录物理排序,而是行偏移量物理排序,数据页中,行记录都是顺序往后添加的,通过修改行偏移量来达到聚集索引的顺序查找
3 查询数据页存储格式的途径
3.1 dbcc ind
3.1.1 语法说明

DBCC TRACEON(2588)
DBCC HELP('ind')
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
dbcc IND ( { 'dbname' | dbid }, { 'objname' | objid }, { nonclustered indid | 1 | 0 | -1 | -2 } [, partition_number] )
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
- -2:返回所有IAM页,基于管理行内数据页,行溢出数据页及大对象数据页的IAM页
- -1:返回所有IAM页及数据页。
- 0:返回管理行内数据页的IAM页,行内数据页
- 1:返回聚集索引的数据页信息及IAM页信息(同-1)
- 2:返回第1个非聚集索引的数据页信息及IAM页信息
- 3:返回第2个非聚集索引的数据页信息及IAM页信息
- ...
- n:返回第(n-1)个非聚集索引的数据页信息及IAM页信息(n>1)

3.1.2 测试案例
create table tbpage_c(id int identity(1,1) not null primary key ,namea varchar(6000),nameb varchar(3000),descriptions text)
#name_a INSERT 6000个字符,name_b INSERT 3000个字符,descriptions INSERT 100个字符
INSERT INTO tbpage_c(NAMEA,nameb,descriptions)
select
substring(stuff((select name+',' from master.dbo.spt_values for xml path('')),1,1,''),1,6000) ,
substring(stuff((select name+',' from master.dbo.spt_values for xml path('')),1,1,''),1,3000) ,
substring(stuff((select name+',' from master.dbo.spt_values for xml path('')),1,1,''),1,100)
dbcc ind('dbpage','tbpage_c',-2)
选项为-2,显示表格的所有IAM页面。由于表格存在行溢出及大对象列,所以会有其相对应的IAM页面,故可以看到有3个IAM,分别为 In-row data ,Row-overflow data ,LOB data。

- 数据页号310,309属于 In-row data 类型。309记录实际数据,310记录In-row data实际数据页的分布情况。
- 数据页号307,308属于 Row-overflow data 类型。307记录实际数据,308记录 Row-overflow data 实际数据页的分布情况。
- 数据页号305,306属于 LOB data 类型。305记录实际数据,306记录 LOB data 实际数据页的分布情况。



3.2 dbcc page
3.2.1 语法说明
DBCC TRACEON(2588)
DBCC HELP('PAGE')
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
dbcc PAGE ( {'dbname' | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系
- 0:输出可读形式的数据页页头数据
- 1:输出可读形式的数据页页头数据,并且还有槽位对应记录的十六进制内容
- 2:输出可读形式的数据页页头数据,输出整个数据页页头的十六进制数据,整一页的内容都显示,包括未使用的空间。
- 3:输出可读形式的数据页页头数据,并且包括记录中每个字段的可读形式,行溢出数据也会显示数据内容,但是大对象则不显示内容,而是说明其存储位置!所以选项3,也是输出内容最全面的。
3.2.2 测试案例
DBCC TRACEON(3604)
dbcc page('dbpage',1,309,0) ---------------------------------------------------------------------------------------------------------- PAGE: (1:309) BUFFER: BUF @0x000000027C0827C0 bpage = 0x000000026FA86000 bhash = 0x0000000000000000 bpageno = (1:309) bdbid = 10 breferences = 0 bcputicks = 0 bsampleCount = 0 bUse1 = 46781 bstat = 0xb blog = 0x212121cc bnext = 0x0000000000000000 PAGE HEADER: Page @0x000000026FA86000 m_pageId = (1:309) m_headerVersion = 1 m_type = 1 /* m_pageId 当前页面号码;m_headerVersion 版本号,始终为1;m_type 页面数据类型,1为数据页面,10为IAM页面等,具体参考pagetype */ m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0xc000 /* m_typeFlagBits 数据页和索引页为4,其他页为0 m_level 该页在索引页(B树)中的级数,0表示为叶子节点 m_flagBits 页面标志 */ m_objId (AllocUnitId.idObj) = 35 m_indexId (AllocUnitId.idInd) = 256 /* m_indexId (AllocUnitId.idInd) 索引ID,0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 大于250就是text或image字段 */ Metadata: AllocUnitId = 72057594040221696 Metadata: PartitionId = 72057594038976512 Metadata: IndexId = 1 Metadata: ObjectId = 341576255 m_prevPage = (0:0) m_nextPage = (0:0) /* Metadata: AllocUnitId 存储单元的ID,sys.allocation_units.allocation_unit_id Metadata: PartitionId 数据页所在的分区号,sys.partitions.partition_id Metadata: ObjectId 该页面所属的对象的id,sys.objects.object_id Metadata: IndexId sys.objects.object_id&sys.indexes.index_id m_prevPage 该数据页的前一页面 m_nextPage 该数据页的后一页面 */ pminlen = 8 m_slotCnt = 1 m_freeCnt = 5035 m_freeData = 3155 m_reservedCnt = 0 m_lsn = (39:400:68) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 0 DB Frag ID = 1 /* pminlen 定长数据所占的字节数为多少个字节 m_slotCnt 页面中的数据的行数 m_freeCnt 页面中剩余的空间,还剩多少字节的空间 m_freeData 页面空闲空间的起始位置,一个页面8KB约等于8192字节 页面空闲空间的位置在3155 m_reservedCnt 活动事务释放的字节数 m_lsn 日志记录号 m_xactReserved 最新加入到m_reservedCnt领域的字节数 m_xdesId 添加到m_reservedCnt的最近的事务id m_ghostRecCnt 幻影数据的行数 m_tornBits 页的校验位或者被由数据库页面保护形式决定页面保护位取代 数据库页面的 lsn SQL Server在内存中维护一个哈希表,记录下自己所有做过写入动作的页面最新的LSN(Log Sequence Number)值。 在下次读出页面的时候,会去比较这两个值是否相等。由于LSN是个自动增长的唯一值,每个发生新修改的页面, LSN的值会比原来的要大。所以如果读到的LSN与内存中存放的不一致,就说明上次的写入请求没有真正完成。 这时824错误也会被触发。 */ Allocation Status GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
dbcc page('dbpage',1,309,1)
----------------------------------------------------------------------------------------------------------
页头信息省略中...
Slot 0, Offset 0x60, Length 3059, DumpStyle BYTE
/*
Slot 槽位号,一个槽位一行数据,这一行数据从 0x60 = 96开始,长度是 3059 bytes
下文文该行记录的16进制内容
*/
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 3059
Memory Dump @0x000000001F978060
/*下文为这一行记录 3059个字节内容*/
0000000000000000: 30000800 01000000 0400a003 002b80e3 0bf38b02 0............+......
0000000000000014: 00000001 000000d5 69000070 17000033 01000001 ........i..p...3....
0000000000000028: 00000028 72707429 2c594553 204f5220 4e4f2c53 ...(rpt),YES OR NO,S
000000000000003C: 59535245 4d4f5445 4c4f4749 4e532054 59504553 YSREMOTELOGINS TYPES
中间省略...
0000000000000BCC: 7072696d 61727920 6b65792c 616e7369 5f6e756c primary key,ansi_nul
0000000000000BE0: 6c5f6400 00d10700 00000031 01000001 000100 l_d........1.......
OFFSET TABLE:
Row - Offset
0 (0x0) - 96 (0x60)
选项为2, 输出整个数据页页头的十六进制数据,整一页的内容都显示,包括未使用的空间。
dbcc page('dbpage',1,309,2)
----------------------------------------------------------------------------------------------------------
页头信息省略中...
/*下文为一整页的数据存储情况,包括行记录跟空闲空间,不区分槽位*/
DATA:
Memory Dump @0x0000000028178000
0000000028178000: 01010000 00c00001 00000000 00000800 00000000 ....................
0000000028178014: 00000100 23000000 ab13530c 35010000 01000000 ....#.....S.5.......
0000000028178028: 27000000 90010000 44000000 00000000 00000000 '.......D...........
000000002817803C: 00000000 01000000 00000000 00000000 00000000 ....................
0000000028178050: 00000000 00000000 00000000 00000000 30000800 ................0...
0000000028178064: 01000000 0400a003 002b80e3 0bf38b02 00000001 .........+..........
0000000028178078: 000000d5 69000070 17000033 01000001 00000028 ....i..p...3.......(
000000002817808C: 72707429 2c594553 204f5220 4e4f2c53 59535245 rpt),YES OR NO,SYSRE
00000000281780A0: 4d4f5445 4c4f4749 4e532054 59504553 2c535953 MOTELOGINS TYPES,SYS
省略中...
0000000028178C1C: 65726963 20726f75 6e646162 6f72742c 7072696d eric roundabort,prim
0000000028178C30: 61727920 6b65792c 616e7369 5f6e756c 6c5f6400 ary key,ansi_null_d.
0000000028178C44: 00d10700 00000031 01000001 00010000 00212121 .......1.........!!!
0000000028178C58: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!!
0000000028178C6C: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!!
省略中...
0000000028179FE0: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!!
0000000028179FF4: 21212121 21212121 21216000 !!!!!!!!!!`.
OFFSET TABLE:
Row - Offset
0 (0x0) - 96 (0x60)
选项为3, 输出可读形式的数据页页头数据,并且包括记录中每个字段的可读形式,行溢出数据也会显示数据内容,但是大对象则不显示内容,而是说明其存储位置!
dbcc page('dbpage',1,309,3)
-------------------------------------------------------------------------------------------------
页头信息省略中...
Slot 0 Offset 0x60 Length 3059
/*
Slot 槽位号,一个槽位一行数据,这一行数据从 0x60 = 96开始,长度是 3059 bytes
*/
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 3059
Memory Dump @0x000000002BB78060
/*下文为这一行记录 3059个字节内容*/
0000000000000000: 30000800 01000000 0400a003 002b80e3 0bf38b02 0............+......
0000000000000014: 00000001 000000d5 69000070 17000033 01000001 ........i..p...3....
0000000000000028: 00000028 72707429 2c594553 204f5220 4e4f2c53 ...(rpt),YES OR NO,S
000000000000003C: 59535245 4d4f5445 4c4f4749 4e532054 59504553 YSREMOTELOGINS TYPES
0000000000000050: 2c535953 52454d4f 54454c4f 47494e53 20545950 ,SYSREMOTELOGINS TYP
0000000000000064: 45532028 55504441 5445292c 41463a20 61676772 ES (UPDATE),AF: aggr
0000000000000078: 65676174 65206675 6e637469 6f6e2c41 503a2061 egate function,AP: a
中间省略...
0000000000000BB8: 2c6e756d 65726963 20726f75 6e646162 6f72742c ,numeric roundabort,
0000000000000BCC: 7072696d 61727920 6b65792c 616e7369 5f6e756c primary key,ansi_nul
0000000000000BE0: 6c5f6400 00d10700 00000031 01000001 000100 l_d........1.......
/*下文为 在槽位0 slot 0 的 这一行记录 ,详细描述每一列的存储情况*/
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
/*slot 0,第一列 在本页占用4字节,列名为id,值为1*/
id = 1
namea = [BLOB Inline Root] Slot 0 Column 2 Offset 0x13 Length 24 Length (physical) 24
/*slot 0,第2列,本页占用24字节,列名为namea
这里可以看到是发生了行溢出情况,列中没有数据,但是存储了该列的实际位置
实际大小为6000字节,值 存储在第一个文件第307页的 slot 0 槽位上*/
Level = 0 Unused = 0 UpdateSeq = 1
TimeStamp = 1775566848 Type = 2
Link 0
Size = 6000 RowId = (1:307:0)
Slot 0 Column 3 Offset 0x2b Length 3000 Length (physical) 3000
nameb = (rpt),YES OR NO,SYSREMOTELOGINS TYPES,SYSREMOTELOGINS TYPES (UPDATE),AF: aggregate function,AP: applicati
on,C : check cns,...省略中...primary key,ansi_null_d
/*slot 0,第3列 ,本页占用3000字节,列名为nameb ,值为 nameb= 的后面一大段中*/
descriptions = [Textpointer] Slot 0 Column 4 Offset 0xbe3 Length 16 Length (physical) 16
/*slot 0,第4列 ,该列为text数据类型,本页占用16字节,列名为descriptions,其值存储在第一个文件的第305页的 slot 1 槽位上*/
TextTimeStamp = 131137536 RowId = (1:305:1)
Slot 0 Offset 0x0 Length 0 Length (physical) 0
/*该表格有主键 ,该行的keyhashvalue值*/
KeyHashValue = (8194443284a0)
create table tbpage(id int primary key not null identity(1,1) ,cola int,colb varchar(10),colc varchar(100))
insert into tbpage(cola,colb,colc) select object_id,type,name from sys.objects
create index ix_colc on tbpage(colc)
select * from sys.indexes where name='ix_colc'
dbcc ind('dbpage','tbpage',-1)



《SQL Server性能调优实战》
4 数据行
4.1 数据行结构
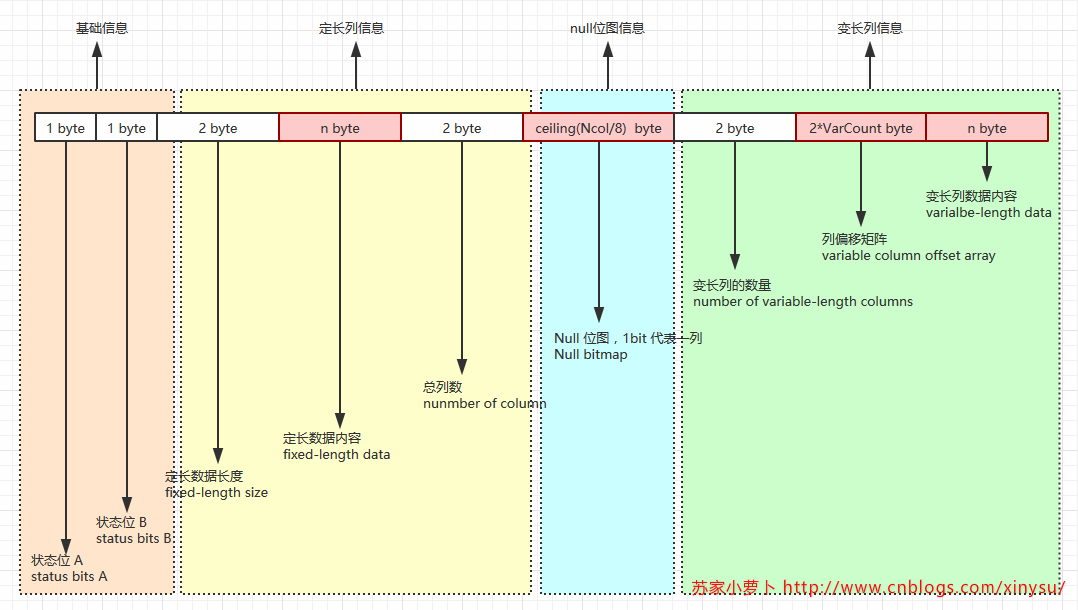
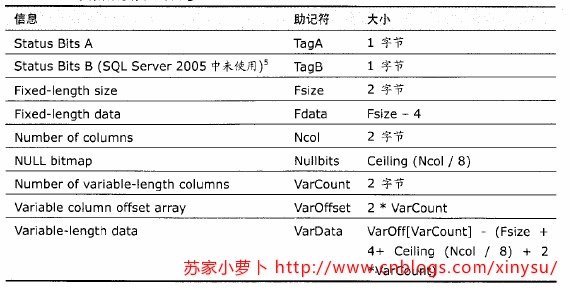
- 状态位A:表示行属性的位图,1字节,8bit
-
- Bit 0 位,版本信息
- Bits 1-3 位,行记录类型
-
- 0,primary record,主记录
- 1,forwarded record
- 2,forwarding stub
- 3,index record,索引记录
- 4,blob或者行溢出数据
- 5,ghost索引记录
- 6,ghost数据记录
- Bit 4 位,NULL位图
- Bit 5 位,表示行中有变长列
- Bit 6 位,保留
- Bit 7 位,ghost record(幽灵记录)
- 列偏移矩阵
-
- 如果一个表格,没有变长列,那么这个表格则不需要列偏移矩阵
- 一个变长列,有一个列偏移矩阵,一个列偏移矩阵2个字节,用于表示变长列中每个列的结束位置。
特殊情况:大对象(LOB_DATA)
特殊情况:行溢出(ROW_OVERFLOW_DATA)
特殊情况:指向 forword(IN_ROW_DATA)
5 数据行:测试存储情况
- 先建立一个只有2列非空定长列的堆表,然后INSERT一行数据,检查page页面存储内容
- 添加主键,检查存储页面内容
- 增加一列:可空变长列
- 增加一列:非空变长列+默认值(分大对象和非大对象)
- 删除无数据的列
- 删除有数据的列
- 行溢出
- forword
5.1 堆表分析



5.2 添加主键


5.3 增加一列:可空变长列

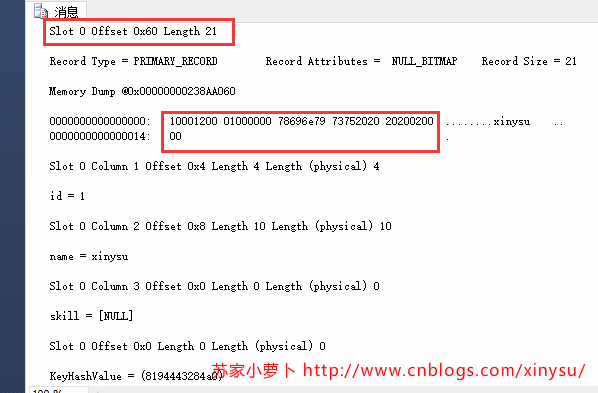
5.4 增加一列:非空变长列+默认值
5.4.1 非大对象列




5.5 删除无数据的列

5.6 删除有数据的列

3.7 行溢出


3.8 Forword


6 行结构与DDL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号