(3.5)sql server存储引擎--事务日志与数据文件
一. 日志结构
1.1、物理日志
(0)物理日志即数据库的.ldf文件,当然后缀名是可以自定义的,默认是.ldf;
(1)一个SQL SERVER数据库,可以定义多个物理日志文件,SQL SERVER逻辑上把它们当成一个整体,顺序写入日志纪录,用完第一个再用下一个:即第一个日志文件的当前空间,如果没有可分配的VLF时,就会使用下一个日志文件的VLF,直到最后一个日志文件也没有可分配的VLF时,会重新回到第一个日志开始增长;VLF的使用如下图:


(2)物理日志文件初始大小至少为512KB;
(3)日志文件不可以放在文件组内;
1.2、虚拟日志
(0)日志文件除了文件头页外,其他VLF部分都不是以数据页的方式来存储的,物理日志以虚拟日志(VLF)为最小单位进行增长、收缩和使用,通常VLF大小至少为256KB,但第一个VLF的大小最小为256K-8K,因为第一个页面8K为日志文件头页面;
(1)虚拟日志是由SQL SERVER来维护的,大小不一,数量不定,不可以人工干预,但可以事先分配较大的物理日志,或者设置较大的物理日志增量,以减少虚拟日志的生成,从而减少数据库维护虚拟日志的成本、以及提高数据库启动及备份还原的速度;
注意:如果设置日志文件的增量过小,则会产生过多的VLFS,也就是日志文件碎片,过多的日志文件碎片会拖累SQL Server性能.
SQL Server创建数据库时,根据日志文件(ldf)的大小,生成VLF的数量公式如下:(可以通过dbcc loginfo(dbname)来查看数据库日志文件的VLF数量)
|
ldf文件的大小 |
VLF的数量 |
|
1M到64M |
4 |
|
64M到1GB |
8 |
|
大于1GB |
16
|
1.3、逻辑日志
(0)数据库逻辑操作的记录,每个事务可能会有多条日志纪录,每条日志记录由唯一的顺序增长的LSN来标记;
通过DBCC LOG()来查看日志文件如下图:或者通过fn_dblog(null,null)


(1)SQL SERVER数据库是不可能不记录日志的,它要用日志来保证事务的基本属性、及数据库恢复。同时也没有类似ORACLE的NOLOGGING开关(并非真正无日志),最相似的应该就是BULK_LOGGED恢复模式;
(2)前面说到过,SQL SERVER数据库遵循预写日志(WAL)的原则;
1.4、活动日志
(0)从MinLSN起往后的日志部分即为活动日志;如下图,以最早活动事务起点的LSN142作为MinLSN,从142起往后的日志部分为活动日志:


(1)检查点LSN、最早活动事务起点的LSN、尚未传递给分发数据库的最早的复制事务起点的 LSN,当中的最小值将作为MinLSN;
二. 日志管理
2.1、截断
(0)SQL SERVER可以通过截断日志以实现物理日志的回绕,截断操作仅是将被截断的日志部分标记为可重用。
根据数据库恢复模式的设置:SIMPLE/BULK_LOGGED/FULL,在SIMPLE模式下,SQL SERVER会自动截断日志,类似于ORACLE中的非归档模式;
(1)SIMPLE模式下,CHECKPOINT会自动截断日志的非活动部分,FULL和BULK_LOGGED模式下,备份日志的TRUNCATE_ONLY/NO_LOG选项在2008的版本中已不再支持,只有通过日志备份来截断日志;
(2)SQL SERVER 截断日志后,并不会主动释放日志文件占用的磁盘空间,需要手动去收缩日志文件才会释放,但通常不建议这样做,毕竟当日志文件再次增大时又需要去重新申请磁盘空间;
(3)日志文件的截断以VLF为单位,从不活动的日志纪录所在的第一个VLF起,到MinLSN所在的VLF的前一个VLF,如下图:


(4)只可以截断非活动的日志部分;
(5)当运行一个长事务且一直未结束时,此时会影响MinLSN的推进,进而影响日志文件的截断,从而会出现,即便是在SIMPLE模式下,日志文件也会变得很大,甚至出现吃掉磁盘所有空间,出现事务日志已满的9002错误。
2.2、备份
(0)SQL SERVER没有ORACLE中的ARCH进程,无法像ORACLE一样自动归档日志,需要去手动备份,而且在有多个物理日志文件时,也无法对单个日志文件进行备份;
(1)当数据库故障恢复时,在线的日志需要手动通过NO_TRUNCATE选项去备份,即尾日志备份,然后再利用尾日志备份结合之前的备份进行故障恢复。
2.3、还原
还原在两种情况下发生,一是数据库重启时,以下简称重启恢复;一是手动通过备份集恢复时,以下简称介质恢复。
(0)还原的过程,是把数据和日志放在内存中,模拟用户读写操作以进行的。还原时只需要重做或撤消最后一个检查点之后的日志部分,这也是检查点机制提高恢复效率的原因所在;
(1)如果事务日志已结束(提交或回滚),而且数据页尚未被刷新,则重做(REDO);如果事务日志未结束,但数据脏页已被刷新到磁盘,则回滚(UNDO);
(2)日志记录中包含数据页被修改前及当前修改的两个LSN,如果目前数据页头的LSN等于修改前的LSN,则日志操作被重做,如果数据页头的LSN等于或大于当前修改的LSN,则跳过日志操作,不重做;
(3)重启恢复不需要人工干预,介质恢复需要手工干预,因为需要逐个应用日志备份,可以利用日志备份,将数据库恢复到某个具体的时间点/日志点。
这里描述的较为概念化,具体可以参考宋大侠的几篇文章(Careyson)
SQL日志
浅谈SQL Server中的事务日志(一)----事务日志的物理和逻辑构架
浅谈SQL Server中的事务日志(二)----事务日志在修改数据时的角色
浅谈SQL Server中的事务日志(三)----在简单恢复模式下日志的角色
浅谈SQL Server中的事务日志(四)----在完整恢复模式下日志的角色
浅谈SQL Server中的事务日志(五)----日志在高可用和灾难恢复中的作用
本文转自:http://blog.51cto.com/qianzhang/1217394
参考:careySon的:浅谈SQL Server中的事务日志(一)----事务日志的物理和逻辑构架
其他文章描述
1 事务日志基本介绍
每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作。
日志的记录形式需要根据数据库的恢复模式来确定,数据库恢复模式有三种:
- 完整模式,完全记录事物日志,需要定期进行日志备份。
- 大容量日志模式,适用于批量操作的数据库,可以以更压缩的方式处理日志,需要定期进行日志备份。
- 简单模式,也有日志文件,只是该模式下可以通过checkpoint自动重用virtual log file,所以日志文件会处于一直重复使用的过程,保持一定大小,但是,如果有一个事务启动,很久没有commit,那么从这个事务开始到最后commit的时间段内的事务日志存储空间都无法checpoint自动重用,这时,你很可能看到一个很大的日志文件;注意,简单模式下是无法进行日志备份。
数据库里边,任何对数据库的读写都是在内存页中找到对应的数据也,再做修改,如果内存页中不存在数据页,则从磁盘加载如内存中。当一个修改操作发生时,修改的将是内存页中对应的数据页面,同时也会实时记录到日后文件ldf中。那么,什么时候数据会被同步到mdf文件呢,只有以下三种情况:
- 做checkpoint时,后续会专门整理checkpoint的相应文章;
- Lazy write运行时,即内存出现压力,需要把内存中的数据页写入到磁盘,腾出内存空间;
- eager write时,即发生bulk insert和select into操作时。
DB中的事务日志记录,可以给我们带来很多好处,它可以支持以下操作:
- 恢复个别的事务。
- 在 SQL Server 启动时恢复所有未完成的事务。
- 将还原的数据库、文件、文件组或页前滚至故障点。
- 支持事务复制。
- 支持高可用性和灾难恢复解决方案:AlwaysOn 可用性组、数据库镜像和日志传送。
2 对数据库启动的影响


1 /* 2 xp_readerrorlog参数说明 3 1. 存档编号 4 2. 日志类型(1为SQL Server日志,2为SQL Agent日志) 5 3. 查询包含的字符串 6 4. 查询包含的字符串 7 5. LogDate开始时间 8 6. LogDate结束时间 9 7. 结果排序,按LogDate排序(可以为降序"Desc" Or 升序"Asc"),默认升序 10 */ 11 12 Exec xp_readerrorlog 0,1,Null,Null,'2017-02-16 10:53:32.300','2017-02-16 12:53:32.300'

1 #设置数据库单用户
2 alter database backupdb set single_user with rollback immediate
3
4 #设置数据库紧急状态
5 alter database backupdb set emergency with rollback immediate
6
7 #获取事务日志的物理名和逻辑名后,重建日志文件
8 select name,physical_name from sys.master_fiels where database_id=db_id('backupdb')
9 alter database backupdb rebuild log on (name='事务日志的逻辑名',filename='事务日志的物理名词')
10
11 #设置数据库online
12 alter database backupdb set online with rollback immediate
13
14 #设置数据库为多用户
15 alter database backupdb set multi_user with rollback immediate
3 日志文件添加方式
- 初始大小,建议直接设置为 截断日志的期间内最大值,比如,某DB 恢复模式是完整模式,每隔半个小时做一次事务日志备份且截断日志,那么设置 日志文件大小的时候,取业务高峰期 每半小时的日志增长 最大值是5G,则可设置初始大小为 5G-7G之间;
- 增长大小,无论是 按比例增长还是按照MB增长,都不要设置过小,建议每次增长在100Mb左右,减少使用到自动增长,在最初设置的初始大小就满足其增长需求 ,如果开始设置的 初始大小 偏小,不满足,可以挑一个业务低峰期,修改变大初始大小。每一次文件自动增长期间,都会对写入的日志造成堵塞,虽然时间很短,但是如果增长频繁,则会影响数据库操作;
- 自动增长,建议设置为自动增长,但是前提定期监控日志的增长情况,避免磁盘空间不足,同时,如果恢复模式是 完整模式或者大容量模式,还需定期做日志备份截断日志,避免 事务日志已满的9002错误;
- 路径选择,建议与 mdf 文件放在不同的磁盘上,分散IO,若是磁盘读写瓶颈不大,则可放在一个磁盘上;
1 USE [master] 2 GO 3 ALTER DATABASE [backupdb] 4 ADD LOG FILE ( 5 NAME = N'backupdb_log_1', 6 FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\backupdb_log_1.ldf' , 7 SIZE = 524288KB , 8 MAXSIZE = 1048576KB , 9 FILEGROWTH = 10240KB 10 ) 11 GO

4 物理结构
1 #其行数及为VLF个数,status为0表示文件未用,为2表示已被使用,无法重用 2 dbcc loginfo 3 4 #备份日志 5 BACKUP LOG [backupdb] 6 TO DISK = N'D:\data\20170215_backupdb_log.trn' WITH NOFORMAT, NOINIT, NAME = N'backupdb-事务日志 备份', SKIP, NOREWIND, NOUNLOAD, STATS = 10 7 GO 8 9 #收缩日志文件,根据日志文件名来收缩500Mb,建议收缩大小是合理大小,参考上文的 初始大小 判断 10 USE [backupdb] 11 GO 12 SELECT name FROM sys.database_files WHERE type_desc='log' 13 DBCC SHRINKFILE (N'jiankong_db_log' , 500) 14 GO 15 16 #其行数及为VLF个数,VLF文件减少 17 dbcc loginfo
事务日志是一种回绕的文件。假设,数据库backupdb只有一个ldf文件,且刚好分成了5个虚拟日志,当我们开始使用数据库的时候,逻辑日志从物理日志的最开始端向末端记录,如下图。

当出现checkpoint的时候,则会标注 最小恢复日志序列号 MinLSN,“MinLSN”是成功进行数据库范围内回滚所需的最早日志记录的日志序列号。如下图。

-
简单恢复模式下,在检查点之后发生。
- 在完整恢复模式或大容量日志恢复模式下,如果自上一次备份后生成检查点,则在日志备份后进行截断(除非是仅复制日志备份)。


5 延迟日志截断原因

6 管理事务日志
1 #查看日志使用情况,文件大小及实际使用大小 2 dbcc sqlperf(logspace) 3 4 #查看文件相关信息 5 select name,physical_name,size*8.0/1024 size_Mb,* from sys.database_files
定期日志备份,两个备份的间隔是运行丢失数据的时间跨度,不要过于频繁备份,会对数据库IO造成一定影响。
1 BACKUP LOG [backupdb] 2 TO DISK = N'D:\data\20170215_backupdb_log.trn' WITH NOFORMAT, NOINIT, NAME = N'backupdb-事务日志 备份', SKIP, NOREWIND, NOUNLOAD, STATS = 10 3 GO
- 若是限制了文件最大值,在磁盘空间有剩余的情况下,增加日志文件的大小。
- 释放磁盘空间以便日志可以自动增长。
- 在其他磁盘上添加日志文件。
- 备份日志后,收缩日志。
- 将日志文件移到具有足够空间的磁盘驱动器。
1 创建数据文件时,在考虑什么
1.1 数据文件与文件组
- 建立表格及索引时,只能指定到某一个文件组,不能够指定到这个文件组的某个文件
- 同一个文件组内的数据文件,起到一个平摊分布数据的作用,如果是位于不同的驱动器,则有利于提高并发IO,如果是位于同一个驱动器,则有利于后期的运维管理;
- 当使用表分区的时候,每一个分区会使用到一个辅助数据文件(可以同一个驱动器,也可以不同)
- 大库的灵活运维管理,其实呢,如果在同一个驱动器上建立多个数据文件,对IO性能并没有任何改善,但是,却为后期的管理提供了方便性,尤其是大库管理,比如线上数据库损坏,需要还原出来一个新的数据文件,或者是测试环境的搭建等等,很多时候会遇到剩余的磁盘空间并不足以来存放这个大库,但是如果是多个数据文件,那么就可以分开指定驱动器存储,减少磁盘大小的要求。
- 使用表分区
- 当磁盘IO资源出现瓶颈的情况下,可以考虑迁移部分热表到 其他文件组的文件上(不同驱动器),分散IO;
- 当磁盘空间不足但是想把文件中的 冷表(类似与记录登录日志)的表格,迁移到其他驱动器上,可以考虑使用文件组;
- 历史数据和热数据分开,历史归档数据损坏,不影响热数据;
- 大库的灵活运维管理,可以使用文件组来备份数据库的一部分,比如某些特定的表格放在 辅助数据文件上,出事故后,还原的时候,可以对数据库进行部分还原,主文件组还原结束,即可提供服务,但在其他文件组上的对象暂时不能使用,等到其他文件组也还原结束,其存储的数据才能提供服务。
1 --案例 1 :给数据库 dbpage新增 文件组 testfg,并在这个文件组内建立辅助数据文件 dbpage_3,dbpage_4 2 USE [master] 3 GO 4 ALTER DATABASE [dbpage] ADD FILEGROUP [testfg] 5 GO 6 7 ALTER DATABASE [dbpage] 8 ADD FILE ( 9 NAME = N'dbpage_3', 10 FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\dbpage_3.ndf' , 11 SIZE = 51200KB , 12 FILEGROWTH = 10240KB 13 ) TO FILEGROUP [testfg] 14 GO 15 16 ALTER DATABASE [dbpage] 17 ADD FILE ( 18 NAME = N'dbpage_4', 19 FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\dbpage_4.ndf' , 20 SIZE = 51200KB , 21 FILEGROWTH = 10240KB 22 ) TO FILEGROUP [testfg] 23 GO 24 25 --案例 2 :指定文件组创建表格 26 CREATE TABLE tbtest(id int not null,name varchar(10) not null) on [testfg] 27 28 --案例 3 :迁移表到其他文件组 29 --表无聚集索引,通过建立聚集索引,把整个表格迁移到 指定文件组 30 alter table tbtest add constraint pk_tbtest primary key (id) on [testfg] 31 32 --表有聚集索引 33 方法一:重建聚集索引,先删除聚集索引,然后再建立新的聚集索引指定到文件组,如上一个SQL 34 方法二:利用表分区,先建立 中间表格,中间表添加分区方案,分区建立在 指定的文件组上,然后再 需要迁移到表格上执行 swith partion,然后重命名表格,最后删除旧表,中间表格的分区脚步这里不涉及 35 36 ALTER TABLE tbtest SWITCH PARTITION 1 TO tbtest_new PARTITION 1 37 GO 38 39 EXEC sp_rename 'tbtest','tbtest_old' 40 EXEC sp_rename 'tbtest_new','tbtest' 41 GO 42 43 DROP TABLE tbtest_old 44 GO
1 select
2
3 fg.name fgname,o.name tbname ,index_id,rows,au.type_desc,au.container_id,au.total_pages,au.used_pages,au.data_pages
4 from sys.partitions p
5 join sys.allocation_units au on p.partition_id=au.container_id
6 join sys.filegroups fg on fg.data_space_id=au.data_space_id
7 join sys.objects o on p.object_id=o.object_id
8 where o.type='u' and p.object_id=object_id('orders')

1 with data as(
2 select
3 fg.name fg_name, o.name tbname
4 from sys.partitions p
5 join sys.allocation_units au on p.partition_id=au.container_id
6 join sys.objects o on p.object_id=o.object_id
7 join sys.filegroups fg on fg.data_space_id=au.data_space_id
8 where o.type='u'
9 group by o.name,fg.name
10 )
11 select
12 a.fg_name,
13 count(*) tbcount,
14 tbnames=stuff((select ','+b.tbname from data b where a.fg_name=b.fg_name order by tbname for xml path('')),1,1,'')
15 from data a
16 group by fg_name

1.2 增长选项
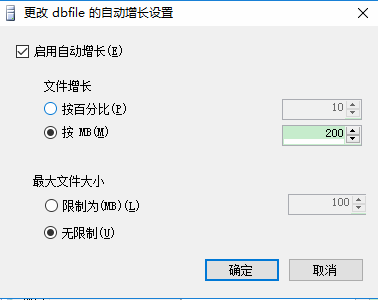
1.3 即时初始化
- 创建数据库
- 向现有数据库中添加文件
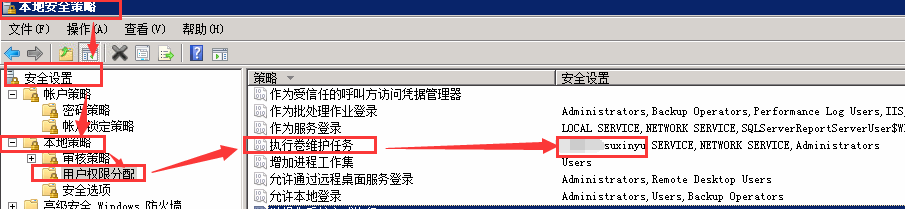
- 增大现有文件的大小、包括自动增长操作(不含日志文件的自动增长)
- 还原数据库或文件组

1 /* 2 以全局方式打开跟踪标记 3004 和 3605。 3 3004:查看SQL Server对日志文件进行填零初始化的过程 4 3605:要求DBCC的输出放到SQL server ERROR LOG 5 -1:以全局方式打开指定的跟踪标记。 6 */ 7 8 DBCC TRACEON(3004,3605,-1) 9 GO 10 11 --创建测试库 12 CREATE DATABASE [xinysu] 13 CONTAINMENT = NONE 14 ON PRIMARY 15 ( NAME = N'xinysu', 16 FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\xinysu.mdf' , 17 SIZE = 104857600KB , FILEGROWTH = 204800KB 18 ) 19 LOG ON 20 ( NAME = N'xinysu_log', 21 FILENAME = N'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER2012\MSSQL\DATA\xinysu_log.ldf' , 22 SIZE = 524288KB , FILEGROWTH = 102400KB 23 ) 24 GO 25 26 --查看错误日志 27 Exec xp_readerrorlog 0,1,Null,Null,'2017-05-29 10:28:00','2017-05-29 10:30:00' 28 29 --删除测试库 30 DROP DATABASE xinysu 31 GO 32 33 DBCC TRACEOFF(3004,3605,-1) 34 GO
2 DB收缩
2.1 指令及设置
1 DBCC SHRINKFILE ( { file_name | file_id } { [ , EMPTYFILE ] | [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ] } ) [ WITH NO_INFOMSGS ]
2
3 /*
4 target_size
5 用兆字节表示的文件大小(用整数表示)。 如果未指定,则 DBCC SHRINKFILE 将文件大小减少到默认文件大小。 默认大小为创建文件时指定的大小。如果target_size指定,DBCC SHRINKFILE 尝试将文件收缩到指定的大小。 将要释放的文件部分中的已使用页重新定位到保留的文件部分中的可用空间。
6
7 EMPTYFILE
8 将所有数据从指定的文件都迁移到其他文件相同的文件组。 换而言之,清空文件将迁移数据,从指定的文件到同一个文件组中的其他文件。 清空文件可确保你没有新数据将添加到文件。可以通过删除该文件ALTER DATABASE语句。
9
10 NOTRUNCATE
11 文件末尾的可用空间不会返回给操作系统,文件的物理大小也不会更改。 因此,指定 NOTRUNCATE 时,文件看起来未收缩。
12 NOTRUNCATE 只适用于数据文件。 日志文件不受影响。
13
14 TRUNCATEONLY
15 将文件末尾的所有可用空间释放给操作系统,但不在文件内部执行任何页移动。 数据文件只收缩到最后分配的区。
16 target_size如果使用 TRUNCATEONLY 指定将被忽略。
17 TRUNCATEONLY 选项不会移动日志中的信息,但会删除日志文件末尾的失效 VLF。
18
19 WITH NO_INFOMSGS
20 取消显示所有信息性消息。
21 */
22
23 --举例说明
24 DBCC SHRINKFILE ( dbpage_data, 100 )
25
26 DBCC SHRINKFILE ( dbpage_data, EMPTYFILE)
27 --清空 dbpage_data 数据文件上面的所有内容
28
29 DBCC SHRINKFILE ( dbpage_data, 100 ,NOTRUNCATE)
30 --收缩数据库 datapage的数据文件,文件名师 dbpage_data,收缩到100Mb
31 --重新分配超过100Mb的数据行到前面100Mb未分配的区,保留空闲空间
32
33 DBCC SHRINKFILE ( dbpage_data, TRUNCATEONLY)
34 --收缩数据库 datapage的数据文件,文件名是 dbpage_data,文件末尾未使用的空间释放给操作系统,不会重新分配数据行到未分配的区
35
1 DBCC SHRINKDATABASE ( database_name | database_id | 0 [ , target_percent ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ) [ WITH NO_INFOMSGS ]
2
3 /*
4 database_name | database_id | 0
5 要收缩的数据库的名称或 ID。 如果指定 0,则使用当前数据库。
6
7 target_percent
8 数据库收缩后的数据库文件中所需的剩余可用空间百分比。
9
10 NOTRUNCATE
11 通过将已分配的区从文件末尾移动到文件前面的未分配区来压缩数据文件中的数据。 target_percent是可选的。
12 文件末尾的可用空间不会返回给操作系统,文件的物理大小也不会更改。 因此,指定 NOTRUNCATE 时,数据库看起来未收缩。
13 NOTRUNCATE 只适用于数据文件。 日志文件不受影响。
14
15 TRUNCATEONLY
16 将文件末尾的所有可用空间释放给操作系统,但不在文件内部执行任何页移动。 数据文件只收缩到最后分配的区。 target_percent如果使用 TRUNCATEONLY 指定将被忽略。
17 TRUNCATEONLY 将影响日志文件。 若要仅截断数据文件,请使用 DBCC SHRINKFILE。
18
19 WITH NO_INFOMSGS
20 取消严重级别从 0 到 10 的所有信息性消息。
21 */
22
23 --举例说明
24 DBCC SHRINKDATABASE (dbpage, 20)
25 --对数据库dbpage执行收缩处理,其中收缩后空闲空间占整个数据库大小的 20%
26 --等同于先执行 DBCC SHRINKDATABASE (dbpage, 20, NOTRUNCATE) ,再执行DBCC SHRINKDATABASE (dbpage, 20, TRUNCATEONLY)
27
28 DBCC SHRINKDATABASE (dbpage, 20, NOTRUNCATE)
29 --对数据库dbpage执行收缩处理,其中收缩后空闲空间占整个数据库大小的 20%
30 --数据文件,分配文件末尾的区到文件前面未分配的区,压缩空间不会返回给操作系统,文件大小不变
31
32 DBCC SHRINKDATABASE (dbpage, 20, TRUNCATEONLY)
33 --对数据库dbpage执行收缩处理,但是收缩的空间不一定是 20%
34 --收缩的空间是文件末尾的可用空间,也就是 target_percent 在这里指定了也没有用
35 --日志文件跟数据文件,释放文件末尾的可用空间给系统文件,但是文件内不执行任何数据页移动


2.2 原理
- 文件并没有变小
-
- 是否执行的命令含有 NOTRUNCATE
- 是否指定的大小比实际数据的大小还要小
- 数据文件没有空闲的区
- 日志文件中的LSN无法截断,详情查看本系列第6篇
- 执行时间非常久
-
- 某些 基于版本控制隔离级别 的事务 堵塞了 收缩操作,这里会在 errorlog中有记录,可以查看
-
- 如果是这个原因堵塞,可以选择停止收缩操作或者停止事务操作或者等待
- 回收的空间特别大,并且回收的空间上有大量的数据页面需要重分配到前面的空闲数据页面上
3 空间计算方法和区别

3.1 基于区统计
3.2 基于页面统计
3.2.1 sp_spaceused
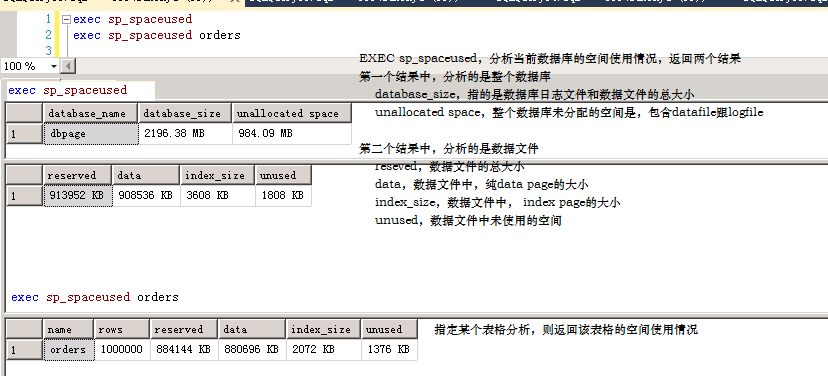
3.2.2 sys.dm_db_partition_status
1 select
2 o.name,
3 sum(case when (p.index_id<2) then row_count end) rows,
4 sum(p.reserved_page_count)*8 reseved_kb,
5 sum(p.reserved_page_count-p.used_page_count)*8 unused_kb,
6 sum(p.used_page_count)*8 used_kb,
7 sum(case when (p.index_id<2) then (p.in_row_data_page_count+p.lob_used_page_count+p.row_overflow_used_page_count)
8 else p.lob_used_page_count+p.row_overflow_used_page_count end
9 )*8 data_kb,
10 sum(p.used_page_count-(case when (p.index_id<2) then (p.in_row_data_page_count+p.lob_used_page_count+p.row_overflow_used_page_count)
11 else p.lob_used_page_count+p.row_overflow_used_page_count end)
12 )*8 index_kb
13 from sys.dm_db_partition_stats p inner join sys.objects o on p.object_id=o.object_id
14 where o.type='u'
15 and o.name in ('orders','tba','tb_clu_no_unique')
16 group by o.name
17 order by o.name

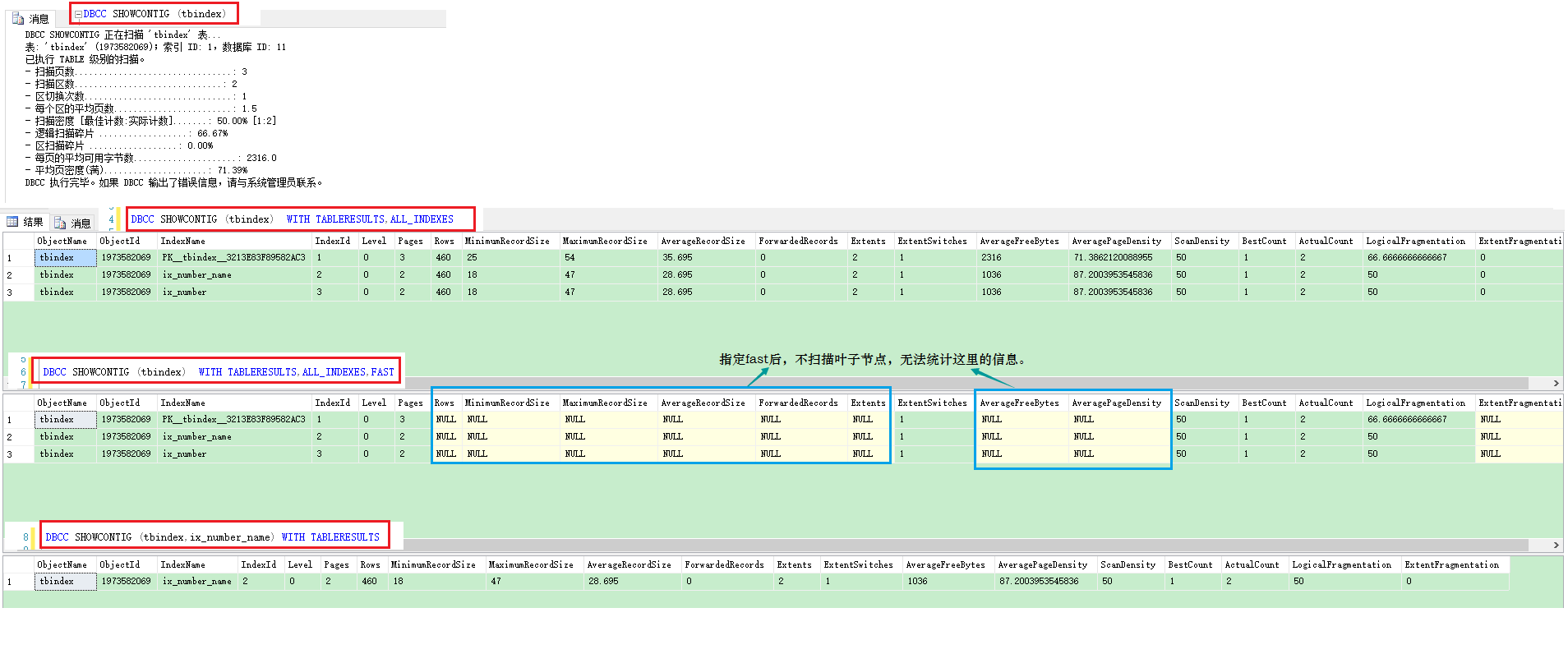
3.2.3 DBCC SHOWCONTIG


 浙公网安备 33010602011771号
浙公网安备 33010602011771号