
sql server 统计信息
统计信息相关操作: [sql] view plain copy --查看只索引的统计信息更新时间 SELECT name AS index_name,STATS_DATE(object_id, index_id) AS update_date FROM sys.indexes WHERE object_id = OBJECT_ID('[Sales].[SalesOrderDetail]'); --查看所有统计信息更新时间 select s.name,STATS_DATE(s.object_id, stats_id) AS update_date from sys.stats s WHERE s.object_id = OBJECT_ID('[Sales].[SalesOrderDetail]'); --查看所有统计信息更新时间 exec sp_helpstats N'[Sales].[SalesOrderDetail]', 'ALL' GO --创建统计信息 CREATE STATISTICS [_WA_user_00000001_00000001] ON [Sales].[SalesOrderDetail](ProductID, SalesOrderDetailID) --查看某个统计信息 DBCC SHOW_STATISTICS('[Sales].[SalesOrderDetail]','_WA_user_00000001_00000001') --更新1个统计信息 UPDATE STATISTICS [Sales].[SalesOrderDetail] [_WA_user_00000001_00000001] WITH FULLSCAN --更新表的所有统计信息 UPDATE STATISTICS [Sales].[SalesOrderDetail] --更新数据库中所有可用的统计信息 EXEC sys.sp_updatestats --删除统计信息 DROP STATISTICS [Sales].[SalesOrderDetail].[_WA_user_00000001_00000001]
前言
转自:https://blog.csdn.net/kk185800961/article/details/42806709
Sqlserver 查询是基于开销查询的,在首次生成执行计划时,是基于多阶段的分析优化才确定出较好的执行计划。而这些开销的基数估计,是根据统计信息来确定的。统计信息其实就是对表的各个字段的总体数据进行分段分布,数据库默认都会自动维护。
表和视图都有统计信息,统计信息对象是根据索引或表列的列表创建的。当某列第一次最为条件查询时,将创建单列的统计信息。当创建索引时,将创建同名的统计信息。索引中,统计信息只统计首列,因此索引除了按首列排序存储数据外,其统计信息也是按首列计算统计的,所以索引设置时定义的第一列非常重要。每个统计信息对象都在包含一个或多个表列的列表上创建,并且包括显示值在第一列中的分布的直方图。
接下来了解统计信息吧~~ ^ ^
统计信息的查看:
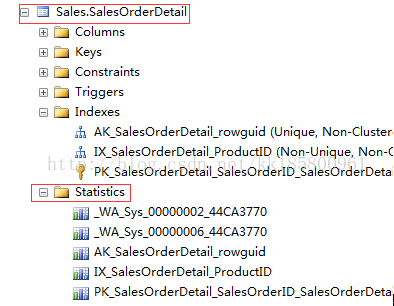
可以看到,统计信息也是表的一种对象。
- --列出表中的所有统计信息
- select * from sys.stats where object_id=OBJECT_ID(N'[Sales].[SalesOrderDetail]')
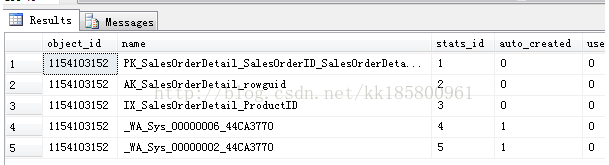
- --查看统计信息及其列
- SELECT s.name AS statistics_name ,c.name AS column_name ,sc.stats_column_id
- FROM sys.stats AS s
- INNER JOIN sys.stats_columns AS sc ON s.object_id = sc.object_id AND s.stats_id = sc.stats_id
- INNER JOIN sys.columns AS c ON sc.object_id = c.object_id AND c.column_id = sc.column_id
- WHERE s.object_id = OBJECT_ID(N'[Sales].[SalesOrderDetail]');
- --查看所有统计信息更新时间
- exec sp_helpstats N'[Sales].[SalesOrderDetail]', 'ALL'
统计信息的属性:
右键统计信息,选择“属性”,可看到统计信息的设置和分布。
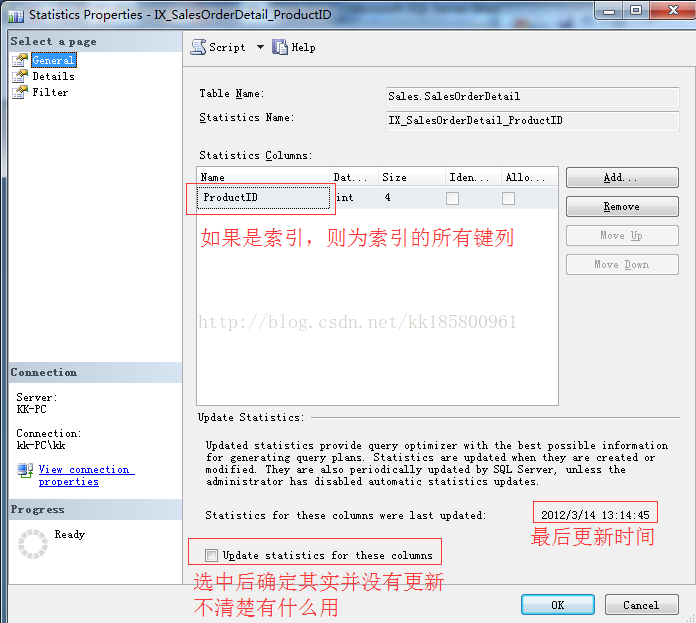
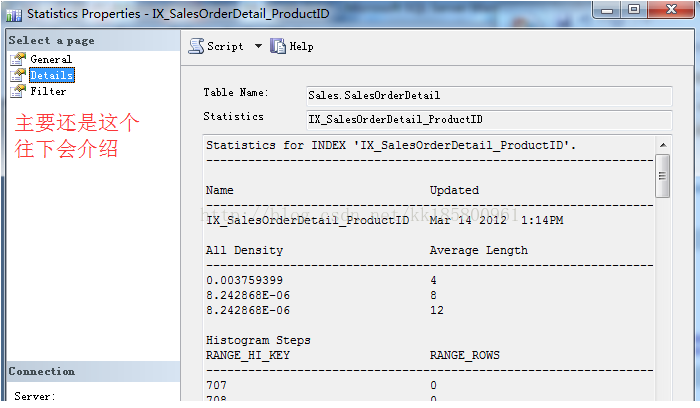
- 还可以使用命令DBCC SHOW_STATISTICS查看,以下为列。
- DBCC SHOW_STATISTICS('[Sales].[SalesOrderDetail]','IX_SalesOrderDetail_ProductID')
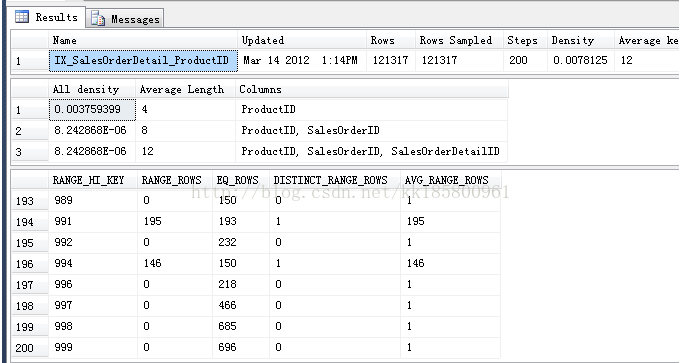
主要分为三部分,分别为“统计信息头部”,“密度向量”,“直方图”
1 统计信息头信息
|
列名 |
说明 |
|
Name |
统计信息对象的名称(IX_SalesOrderDetail_ProductID) |
|
Updated |
上一次更新统计信息的日期和时间(Mar 14 2012 1:14PM) |
|
Rows |
上次更新统计信息时表或索引视图中的总行数(121317)。如果筛选统计信息或者统计信息与筛选索引对应,该行数可能小于表中的行数 |
|
Rows Sampled |
用于统计信息计算的抽样总行数(121317)。如果 Rows Sampled < Rows,显示的直方图和密度结果则是根据抽样行估计的。 |
|
Steps |
直方图中的梯级数(200)。 每个梯级都跨越一个列值范围,后跟上限列值。 直方图梯级是根据统计信息中的第一个键列定义的。最大梯级数为 200。 |
|
Density |
计算公式为:1/统计信息对象第一个键列中的所有值(不包括直方图边界值)的 distinct values。(0.0078125) 查询优化器不使用此 Density 值,显示此值的目的是为了与 SQL Server 2008 之前的版本实现向后兼容。 |
|
Average Key Length |
统计信息对象中所有键列的每个值的平均字节数 (12 :3个int类型。 ProductID, SalesOrderID, SalesOrderDetailID) |
|
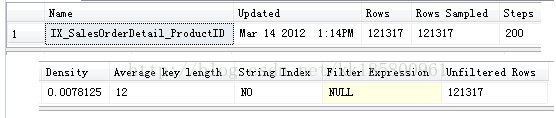
String Index |
(NO)Yes 指示统计信息对象包含字符串摘要统计信息,以改进对使用 LIKE 运算符的查询谓词的基数估计;例如 WHERE ProductName LIKE '%Bike'。 字符串摘要统计信息与直方图分开存储,如果统计信息对象为char、varchar、nchar、nvarchar、varchar(max)、nvarchar(max)、text 或 ntext. 类型,则基于其第一个键列创建字符串摘要统计信息。 |
|
Filter Expression |
包含在统计信息对象中的表行子集的谓词。 NULL = 未筛选的统计信息。 |
|
Unfiltered Rows |
应用筛选表达式前表中的总行数(121317)。 如果 Filter Expression 为 NULL,则 Unfiltered Rows 等于 Rows。 |
2 密度信息

|
列名 |
说明 |
|
All Density |
Density 为 1/distinct values。 结果显示统计信息对象中各列的每个前缀的密度,每个密度显示一行。 非重复值是每个行前缀和列前缀的列值的非重复列表。 反映索引列的选择性(selectivity) (参考《Microsoft sqlserver 企业级平台管理实践》) |
|
Average Length |
存储列前缀的列值列表的平均长度(以字节为单位)。 |
|
Columns |
为其显示 All density 和 Average length 的前缀中的列的名称 |
这里至于为什么会有3行,是因为【ProductID】为非聚集索引,【SalesOrderID,SalesOrderDetailID】为聚集索引,而每个非聚集索引中都包含有聚集索引的键值,所以这里的统计信息也出现了3个可选项。
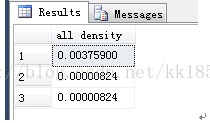
当前统计信息 [All Density] 计算方法:
- select count(*) from (select count(*) a from [Sales].[SalesOrderDetail]group by ProductID ) as T
- select count(*) from (select count(*) a from [Sales].[SalesOrderDetail] group by ProductID,SalesOrderID) as T
- select count(*) from (select count(*) a from [Sales].[SalesOrderDetail] group by ProductID,SalesOrderID,SalesOrderDetailID) as T
- --按不同组统计如下:
- group by ProductID --266行
- group by ProductID, SalesOrderID --121317行
- group by ProductID, SalesOrderID, SalesOrderDetailID --121317行
- select 1.0/266 as [all density]
- union all
- select 1.0/121317 as [all density]
- union all
- select 1.0/121317 as [all density]
2 直方图
|
列名 |
说明 |
|
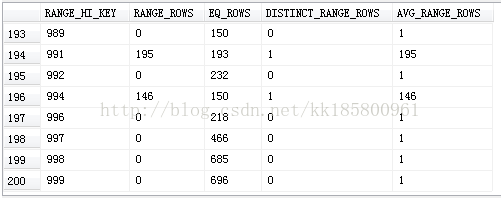
RANGE_HI_KEY |
直方图梯级的上限列值。 列值也称为键值。(按ProductID 的范围分布) |
|
RANGE_ROWS |
其列值位于直方图梯级内(不包括上限)的行的估算数目。(2个ProductID 值之间有多少行) |
|
EQ_ROWS |
其列值等于直方图梯级的上限的行的估算数目。(等于当前行ProductID值的有多少行) |
|
DISTINCT_RANGE_ROWS |
非重复列值位于直方图梯级内(不包括上限)的行的估算数目。 (2个ProductID 值之间有多少不重复的键值ProductID) |
|
AVG_RANGE_ROWS |
重复列值位于直方图梯级内(不包括上限)的平均行数(如果 DISTINCT_RANGE_ROWS > 0,则为 RANGE_ROWS / DISTINCT_RANGE_ROWS)。 |
统计信息的重要性:
SQLServer中,在执行一个批处理语句时,关系引擎中的查询优化器会先估计生成较优的执行计划,执行执行器才安照此执行计划请求数据。即在生成执行计划期间,sqlserver是根据表中的统计信息进行行数估计,按照脚本语义来确定物理操作步骤生成执行计划,再按照该执行计划访问数据。而对于数据较大的表,按照统计信息估计的行数也常常不准确,这就是使查询使用了不准确的执行计划而比较慢。类似如:“参数嗅探”因传递参数值无法确定而估算错误;使用表变量不会有统计信息也不会估算行数。
- --现在以这个表的列统计为例[Sales].[SalesOrderDetail](SpecialOfferID)
- DBCC SHOW_STATISTICS('[Sales].[SalesOrderDetail]','_WA_Sys_0000000B_44CA3770')
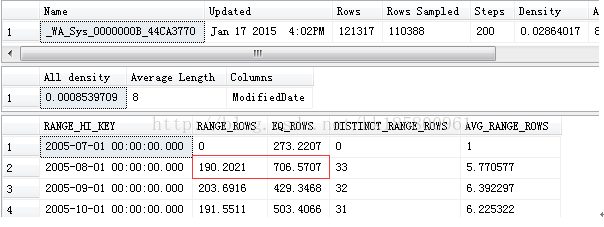
如果查询日期范围在'2005-07-01'<ModifiedDate<='2005-08-01' ,看上图,查询返回的估计行数应该为896.7728(190.2021+706.5707)
- SELECT COUNT( ModifiedDate )FROM [Sales].[SalesOrderDetail]
- WHERE ModifiedDate >'2005-07-01 00:00:00'AND ModifiedDate<='2005-08-01 00:00:00'
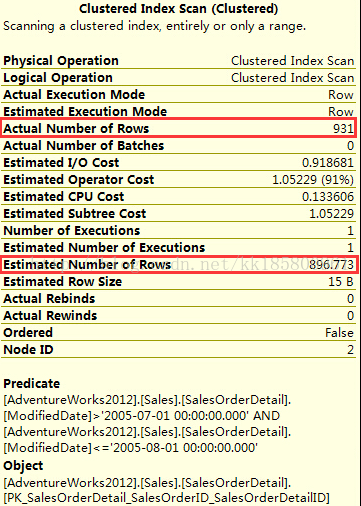
估计行数为896.773,与统计信息的直方图的信息一致。其实就是根据直方图统计出来的,如果估计行数不准确,一定是统计信息没有正确的直方图信息,因此需要更新统计信息。
在看带参数的测试:
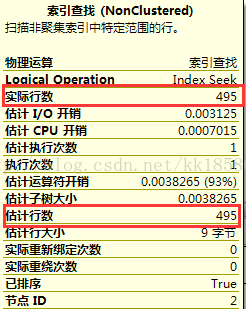
- SELECT COUNT(*) FROM [Sales].[SalesOrderDetail] WHERE ProductID=800
估计行数是495,是直方图里显示ProductID=800的估计。现在使用参数替换。
- DECLARE @ProductID INT
- SET @ProductID = 800
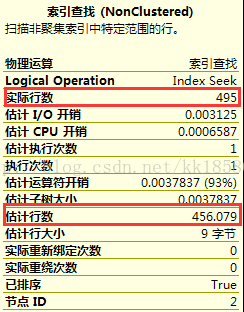
- SELECT COUNT(*) FROM [Sales].[SalesOrderDetail] WHERE ProductID=@ProductID
看到估计行数是456.079,这个估计与实际的相差不大,不影响执行计划改变。但是为什么又变了呢?这个怎么来的?下面解释
- DBCC SHOW_STATISTICS('[Sales].[SalesOrderDetail]','IX_SalesOrderDetail_ProductID')
ProductID=800的估计行数是495,而使用参数的是456.079,统计信息中并没有记录,但是SqlServer却能根据密度计算。看红框中的数值,因为我是以ProductID为谓词,因此选择了密度 All density = 0.003759399,估计行数为:
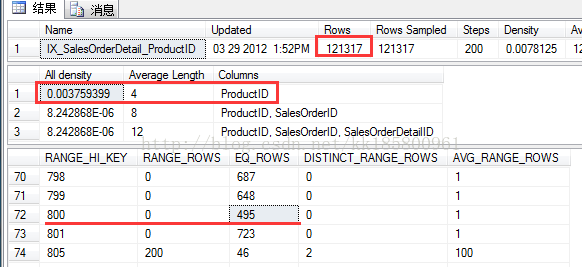
[Estimate Rows] = 121317 * 0.003759399 = 456.079008483
参数估计公式:[Estimate Rows] = Rows * [All density]
有时候即使更新了统计信息,结果还是一样,因为数据量太大,估计数据不完全,看Rows Sampled可知道,因此也可以在更新统计信息时采用全表行数统计,但是这样扫描表数据也耗性能。即便如此,还是有些可能不一样,因为直方图的步长最多200,数据列中相同的和不同的差距太大,200段分布也有参差不齐的数据,不能使用更多步更详细的数据直方图。
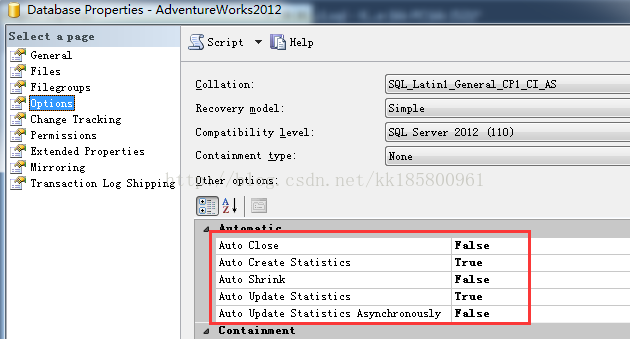
统计信息的更新设置:
Sqlserver 默认自动维护统计信息,在数据库级别可以设置自动创建和更新统计信息的选项。
- 用脚本设置如下:
- ALTER DATABASE [databaseName] SET AUTO_CREATE_STATISTICS ON WITH NO_WAIT
- ALTER DATABASE [databaseName] SET AUTO_UPDATE_STATISTICS ON WITH NO_WAIT
- ALTER DATABASE [databaseName] SET AUTO_UPDATE_STATISTICS_ASYNC ON WITH NO_WAIT
AUTO_CREATE_STATISTICS:
AUTO_CREATE_STATISTICS = ON 时,当将某列作为条件查询时,系统自动为每个条件列创建单列的统计信息。创建索引时也会自动创建相应的统计信息. 查询优化器通过使用 AUTO_CREATE_STATISTICS 选项创建统计信息时,统计信息名称以_WA 开头。
AUTO_UPDATE_STATISTICS:
AUTO_UPDATE_STATISTICS = ON 时,查询优化器将确定统计信息何时可能过期,然后在查询使用这些统计信息时更新它们。 统计信息将在插入、更新、删除或合并操作更改表或索引视图中的数据分布后过期。 查询优化器通过计算自最后统计信息更新后数据修改的次数并且将这一修改次数与某一阈值进行比较,确定统计信息何时可能过期。 该阈值基于表中或索引视图中的行数。查询优化器在编译查询和执行缓存查询计划前,检查是否存在过期的统计信息。 在编译某一查询前,查询优化器使用查询谓词中的列、表和索引视图确定哪些统计信息可能过期。 在执行缓存查询计划前,数据库引擎 确认该查询计划引用最新的统计信息。
AUTO_UPDATE_STATISTICS_ASYNC:
异步统计信息更新选项AUTO_UPDATE_STATISTICS_ASYNC 将确定查询优化器是使用同步统计信息更新还是异步统计信息更新。 默认情况下,异步统计信息更新选项被关闭,并且查询优化器以同步方式更新统计信息。 AUTO_UPDATE_STATISTICS_ASYNC 选项适用于为索引创建的统计信息对象、查询谓词中的单列以及使用 CREATE STATISTICS 语句创建的统计信息。统计信息更新可以是同步(默认设置)或异步的。 对于同步统计信息更新,查询将始终用最新的统计信息编译和执行;在统计信息过期时,查询优化器将在编译和执行查询前等待更新的统计信息。 对于异步统计信息更新,查询将用现有的统计信息编译,即使现有统计信息已过期。如果在查询编译时统计信息过期,查询优化器可以选择非最优查询计划。 在异步更新完成后编译的查询将从使用更新的统计信息中受益。
统计信息自动维护更新:
Sqlserver之所以自动维护统计信息,首先设置AUTO_UPDATE_STATISTICS=ON,sqlserver会在符合某条件时自动更新表中的统计信息。其中我们可以看到的,系统表sysindexes的列rowmodctr,它记录自上次更新统计信息后插入、删除、更新行的累计总次数。对于满足统计信息更新的条件,系统会自动更新。
SELECT name,rows,rowmodctrFROMsys.sysindexes
自动更新统计规则:
•表中行范围rows=0行增长rows>0行;
•表中行范围 0<rows<=500行,只要变化的次数rowmodctr>500;
•表中行范围rows>500行,只要变化的次数rowmodctr>500+20%rows;
•临时表行数rows<6,只要变化的次数rowmodctr>6;
需要手动更新统计信息:
查询执行时间很长。
在升序或降序键列上发生插入操作。
在维护操作后。
- --创建测试表
- create table test(id int identity(1,1),name char(20),value numeric(18,4),meno varchar(50))
- create clustered index IX_test on test(name)
- alter table test add constraint PK_test primary key nonclustered(id)
- --以[dbo].[test]表为例,先查看
- select i.name,rows,rowmodctr,stats_date(s.object_id,s.stats_id) AS update_date
- from sys.sysindexes i inner join sys.stats s on i.name=s.name
- where s.object_id = OBJECT_ID('[dbo].[test]')
- --此时观看两个索引的直方图,什么都没有
- DBCC SHOW_STATISTICS('[dbo].[test]','IX_test')
- DBCC SHOW_STATISTICS('[dbo].[test]','PK_test')
- --插入1行数据,统计信息没有更新?
- insert into test(name,value,meno)
- select 'name',0,'meno'
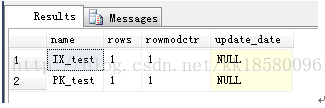
- --最终增删了506*2行,统计信息都没有生成
- insert into test(name,value,meno)
- select 'name',0,'meno'
- go 500
- delete from test
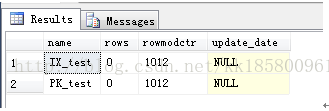
- --重新测试:重新删除创建表。在插入数据前,每个字段搜索一次,非索引字段会自动生成统计信息.
- select * from test where id=1
- select * from test where name=''
- select * from test where value=0
- select * from test where meno=''
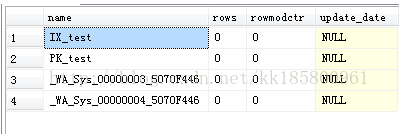
- --插入一行数据,否则操作任何列统计信息都没有更新
- insert into test(name,value,meno)
- select 'name',0,'meno'
- go
- --上面的查询并没有自动更新统计信息,只有作为where条件的更改或删除了才更新统计信息
- update test set name='name' where name='name'
- update test set value=0 where value=0
- update test set meno='meno' where id=1
- delete from test where meno='meno'
- --再重新插入数据,准备测试用
- insert into test(name,value,meno)
- select 'name',0,'meno'
- go
- --查看统计情况
- select i.name,rows,rowmodctr,stats_date(s.object_id,s.stats_id) AS update_date
- from sys.sysindexes i inner join sys.stats s on i.name=s.name
- where s.object_id = OBJECT_ID('[dbo].[test]')
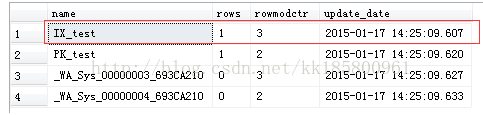
- --当我更新索引的统计信息到 rowmodctr = 500 行的时候,统计信息并没有更新
- update test set name='name' where name='name'
- go 497
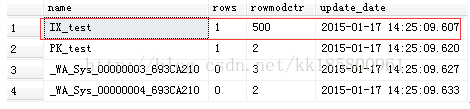
- --z再更新一次,使索引更新累计rowmodctr = 501行
- update test set name='name' where name='name'
- go
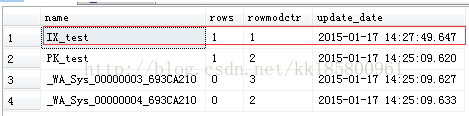
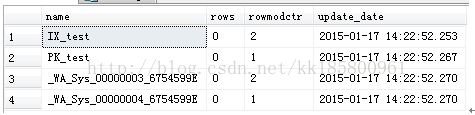
- 结果发现:索引的统计信息更新了,rowmodctr重新设置为1行。按相同的方法更新value为501次,非键列是没有更新的!
- update test set value=0 where value=0
- 也就是这个条件是符合的:表中行范围 0<rows<=500 行,只要变化的次数 rowmodctr>500 ;
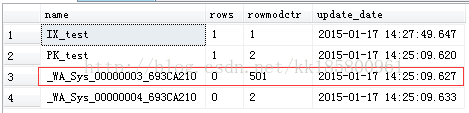
- --插入数据到501行
- insert into test(name,value,meno)
- select 'name',0,'meno'
- go 500
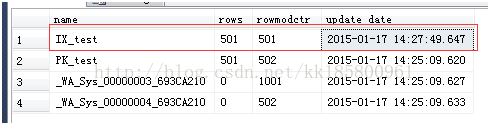
- 当数据大于500行达到501行时,rowmodctr此时大于500行并没有更新索引的统计信息。
- --现在更新501行数据的20%,统计信息并没有更新。
- with tab as(select top 20 percent * from test)
- update tab set name='name'
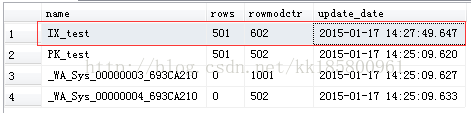
现在行数602行,理论上超过601.2(501+501*0.2)行会更新,现在在更新一次,如果统计信息自动更新就对了
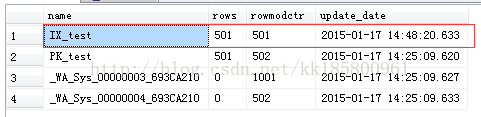
上图看到,真的更新了!所以这个条件是符合的:表中行范围rows>500行,只要变化的次数rowmodctr>500+20%rows;
统计信息更新总结如下:
•表中行范围rows=0行增长rows>0行(插入时不更新,更新删除行才更新);
•表中行范围 0<rows<=500行,只要变化的次数rowmodctr>500;
•表中行范围rows>500行,只要变化的次数rowmodctr>500+20%rows;
•临时表行数rows<6,只要变化的次数rowmodctr>6(未测试);
创建索引时自动生成同名统计信息
非索引列在表有数据时首次作为条件查询时自动生成统计信息
对表首次插入多少数据都不自动更新统计信息
非键列的rows总是不更新(因为不存储数据)
统计信息相关操作:
- --查看只索引的统计信息更新时间
- SELECT name AS index_name,STATS_DATE(object_id, index_id) AS update_date
- FROM sys.indexes
- WHERE object_id = OBJECT_ID('[Sales].[SalesOrderDetail]');
- --查看所有统计信息更新时间
- select s.name,STATS_DATE(s.object_id, stats_id) AS update_date
- from sys.stats s
- WHERE s.object_id = OBJECT_ID('[Sales].[SalesOrderDetail]');
- --查看所有统计信息更新时间
- exec sp_helpstats N'[Sales].[SalesOrderDetail]', 'ALL'
- GO
- --创建统计信息
- CREATE STATISTICS [_WA_user_00000001_00000001] ON [Sales].[SalesOrderDetail](ProductID, SalesOrderDetailID)
- --查看某个统计信息
- DBCC SHOW_STATISTICS('[Sales].[SalesOrderDetail]','_WA_user_00000001_00000001')
- --更新1个统计信息
- UPDATE STATISTICS [Sales].[SalesOrderDetail] [_WA_user_00000001_00000001] WITH FULLSCAN
- --更新表的所有统计信息
- UPDATE STATISTICS [Sales].[SalesOrderDetail]
- --更新数据库中所有可用的统计信息
- EXEC sys.sp_updatestats
- --删除统计信息
- DROP STATISTICS [Sales].[SalesOrderDetail].[_WA_user_00000001_00000001]
参考:
http://msdn.microsoft.com/zh-cn/library/ms190397(v=sql.120).aspx
DBCC SHOW_STATISTICS(Transact-SQL) (SQL Server 2014):
http://msdn.microsoft.com/zh-cn/library/ms174384.aspx
UPDATE STATISTICS(Transact-SQL) (SQL Server 2014):
http://msdn.microsoft.com/zh-cn/library/ms187348.aspx
《Microsoft sqlserver 企业级平台管理实践》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号