
sql server 行列转换
【1】创建测试数据
CREATE TABLE [dbo].[tbl_Student]( [ID] [int] IDENTITY(1,1) NOT NULL, [学生ID] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL, [学生姓名] [nvarchar](50) COLLATE Chinese_PRC_CI_AS NULL, [课程ID] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL, [课程名称] [nvarchar](50) COLLATE Chinese_PRC_CI_AS NULL, [成绩] [int] NULL, [教师ID] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL, [教师姓名] [nvarchar](50) COLLATE Chinese_PRC_CI_AS NULL ) ON [PRIMARY] insert into tbl_Student values('S3','王五','K4 ','政治',53,'T4','赵老师'); insert into tbl_Student values('S1','张三 ','K1 ','数学',61,'T1','张老师'); insert into tbl_Student values('S2','李四','K3 ','英语',88,'T3','李老师'); insert into tbl_Student values('S1','张三 ','K4 ','政治',77,'T4','赵老师'); insert into tbl_Student values('S2','李四','K4 ','政治',67,'T5','周老师'); insert into tbl_Student values('S3','王五','K2 ','语文',90,'T2','王老师'); insert into tbl_Student values('S3','王五','K1 ','数学',55,'T1','张老师'); insert into tbl_Student values('S1','张三 ','K2 ','语文',81,'T2','王老师'); insert into tbl_Student values('S4','赵六','K2 ','语文',59,'T1','王老师'); insert into tbl_Student values('S1','张三 ','K3 ','英语',37,'T3','李老师');
【2】行转列
方法1:case when
select 学生姓名,课程ID,成绩,教师ID,教师姓名, max(case 课程名称 when '政治' then 成绩 else 0 end) 政治, max(case 课程名称 when '语文' then 成绩 else 0 end) 语文, max(case 课程名称 when '数学' then 成绩 else 0 end) 数学, max(case 课程名称 when '英语' then 成绩 else 0 end) 英语 from tbl_Student group by 学生姓名,课程ID,成绩,教师ID,教师姓名
方法2:pivot
select * from (select * from tbl_Student) a pivot (max(成绩) for 课程名称 in (语文,数学,英语,政治)) b
结果如图:

之所以很多地方为NULL是因为pivot和unpivot会把除 pivot()括号内的字段都作为分组项,所以如果想实现如下图效果。

则需要先做一个子查询或CTE来把相关字段给筛选出来,代码如下(或可以用case when做行转列直接group by 指定字段)
select * from (select 学生姓名,成绩,课程名称 from tbl_Student) a pivot (max(成绩) for 课程名称 in (语文,数学,英语,政治)) b
结果如下:

【3】列转行:(或可以用union all做列传行)
CREATE TABLE [dbo].[tbl_列转行测试]( [UserID] [int] NULL, [UserNo] [int] NULL, [A] [int] NULL, [B] [int] NULL, [C] [int] NULL ) ON [PRIMARY] insert into [tbl_列转行测试] values(1 , 1 , 11 , 22 , 33) select * from [tbl_列转行测试] SELECT USERID,USERNO,attribute,value FROM (select * from tbl_列转行测试)a UNPIVOT ( value FOR attribute IN(A, B,C) ) AS UPV

【4】行列转换实践
(1)常规列转行
需求:

解决:
--drop table #temp1 --drop table #temp2 create table #temp1([A-1] varchar(100),[A-2] varchar(100),[A-3] varchar(100)) insert into #temp1 values('张三','成都','123') insert into #temp1 values('李四','北京','456') create table #temp2([英文字段] varchar(100),[中文字段] varchar(100)) insert into #temp2 values('A-1','姓名') insert into #temp2 values('A-2','地址') insert into #temp2 values('A-3','电话') ;with t1 as ( select * from #temp1 unpivot ( value for attribute in ([A-1],[A-2],[A-3]) ) t ) ,t2 as ( select t1.value,t2.[中文字段] ,row_number() over(partition by t2.[中文字段] order by t1.value) as rn from t1 join #temp2 t2 on t1.attribute=t2.[英文字段] ) --select * from t2 select 姓名,地址,电话 from t2 pivot( max(value) for [中文字段] in (姓名,地址,电话)) q
(2)实用列传行
该题来自csdn论坛,答案出自sql server技术群 小小大神
需求:
 =》
=》 
思路,
(1)把 item1,item2.....item_name1,item_name2...... 全部值存在新生成列x,所有原本的列名存在新生成列y
(2)然后通过自连接,根据 y 列所存储值(即原列名)的规律,来把 item1,item2..... 和 item_name1,item_name2.... 区分开来,重新划分成2列
CREATE TABLE #A(code VARCHAR(30),name VARCHAR(200), item1 VARCHAR(30), item_name1 VARCHAR(100) , item2 VARCHAR(30), item_name2 VARCHAR(100) , item3 VARCHAR(30), item_name3 VARCHAR(100) ) INSERT INTO #A(code,name,item1,item_name1,item2,item_name2) SELECT '1001','A1001','W01','W011001','W03','W011003' UNION ALL SELECT '1002','D1001','K01','K011001','P09','P011009' UNION ALL SELECT '1003','G1001','M01','M011001','N03','N011003' INSERT INTO #A(code,name,item3,item_name3) VALUES('1004','xxxx','yy','yy001') INSERT INTO #A(code,name,item1,item_name1,item2,item_name2,item3,item_name3) VALUES('1005','11',1,2,3,4,5,6) ;with cet_t1 as ( SELECT * FROM ( -- 列转行之前,必须把相关列所在值转成同一种数据类型,否则组合生成的新列根本不知道应该是什么数据类型和长度 SELECT code ,CONVERT(VARCHAR(100),item_name1) AS item_name1,CONVERT(VARCHAR(100),item_name2) AS item_name2,CONVERT(VARCHAR(100),item_name3) AS item_name3,CONVERT(VARCHAR(100),item1) AS item1,CONVERT(VARCHAR(100),item2) AS item2,CONVERT(VARCHAR(100),item3) AS item3 FROM #A ) A UNPIVOT ( x FOR y IN (item_name1,item_name2,item_name3,item1,item2,item3) )p ) SELECT a.code,a.x AS item,b.x AS item_name FROM cet_t1 a INNER JOIN cet_t1 b ON b.code = a.code AND STUFF(a.y,1,4,'')=STUFF(b.y,1,9,'') AND SUBSTRING(a.y,5,1)<>'_' drop table #A
实现结果:

该程序如果有多个item/item_name,需要操作的话,换成动态SQL
--列数不固定,但是item和item_name后面跟的数字是一套一套的 CREATE TABLE #A(code VARCHAR(30),name VARCHAR(200), item1 VARCHAR(30), item_name1 VARCHAR(100) , item2 VARCHAR(30), item_name2 VARCHAR(100) , item3 VARCHAR(30), item_name3 VARCHAR(100) ) INSERT INTO #A(code,name,item1,item_name1,item2,item_name2) SELECT '1001','A1001','W01','W011001','W03','W011003' UNION ALL SELECT '1002','D1001','K01','K011001','P09','P011009' UNION ALL SELECT '1003','G1001','M01','M011001','N03','N011003' INSERT INTO #A(code,name,item3,item_name3) VALUES('1004','xxxx','yy','yy001') INSERT INTO #A(code,name,item1,item_name1,item2,item_name2,item3,item_name3) VALUES('1005','11',1,2,3,4,5,6) DECLARE @sql VARCHAR(max)='' DECLARE @where VARCHAR(max)='' DECLARE @filed VARCHAR(max)='' --动态拼接,先统一类型,然后列转行,在关联得到结果 SELECT @filed=@filed+',CONVERT(VARCHAR(100),'+name+') AS '+name , @where=@where+','+name FROM tempdb.sys.columns WHERE object_id=OBJECT_ID('tempdb..#A') AND name LIKE 'item_%' print @filed print @where SET @sql=' WITH ct AS ( SELECT * FROM ( SELECT code '+@filed+' FROM #A ) A UNPIVOT ( x FOR y IN ('+STUFF(@where,1,1,'')+') )p ) SELECT a.code,a.x AS item,b.x AS item_name FROM ct a INNER JOIN ct b ON b.code = a.code AND STUFF(a.y,1,4,'''')=STUFF(b.y,1,9,'''') AND SUBSTRING(a.y,5,1)<>''_''' print(@sql) EXEC (@sql) DROP TABLE #A
【5】分隔符行列转换
1、行转列,以','号为分隔符
好的 FOR XML PATH就基本介绍到这里吧,更多关于FOR XML的知识请查阅帮助文档!
接下来我们来看一个FOR XML PATH的应用场景吧!那么开始吧。。。。。。
一个应用场景与FOR XML PATH应用
首先呢!我们在增加一张学生表,列分别为(stuID,sName,hobby),stuID代表学生编号,sName代表学生姓名,hobby列存学生的爱好!那么现在表结构如下:

这时,我们的要求是查询学生表,显示所有学生的爱好的结果集,代码如下:
SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby FROM ( SELECT sName, (SELECT hobby+',' FROM student WHERE sName=A.sName FOR XML PATH('')) AS StuList FROM student A GROUP BY sName ) B
结果如下:
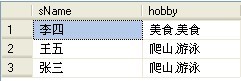
分析: 好的,那么我们来分析一下,首先看这句:
SELECT hobby+',' FROM student WHERE sName=A.sName FOR XML PATH('')
这句是通过FOR XML PATH 将某一姓名如张三的爱好,显示成格式为:“ 爱好1,爱好2,爱好3,”的格式!
那么接着看:
SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby FROM ( SELECT sName, (SELECT hobby+',' FROM student WHERE sName=A.sName FOR XML PATH('')) AS StuList FROM student A GROUP BY sName ) B
剩下的代码首先是将表分组,在执行FOR XML PATH 格式化,这时当还没有执行最外层的SELECT时查询出的结构为:

可以看到StuList列里面的数据都会多出一个逗号,这时随外层的语句:SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby 就是来去掉逗号,并赋予有意义的列明!
2.列转行

----------------------------------------------------------------
--> 测试数据[huang]if object_id('[huang]') is not null drop table [huang] go create table [huang]([a] nvarchar(4),[b] nvarchar(10)) insert [huang] select 'X1','1,4,8' union all select 'X2','2' union all select 'X3','3,6' union all select 'X4','7' union all select 'X5','5'
--------------SQL查询生成数据--------------------------select a.[a], SUBSTRING([b],number,CHARINDEX(',',[b]+',',number)-number) as [b] from [huang] a,master..spt_values where number >=1 and number<=len([b]) and type='p' and substring(','+[b],number,1)=','
----------------结果----------------------------/* a b---- ----------X1 1X1 4X1 8X2 2X3 3X3 6X4 7X5 5*/
 浙公网安备 33010602011771号
浙公网安备 33010602011771号