【高可用】alertmanager高可用,alertmanager集群
【1】alertmanager集群高可用介绍
(1.1)基本介绍
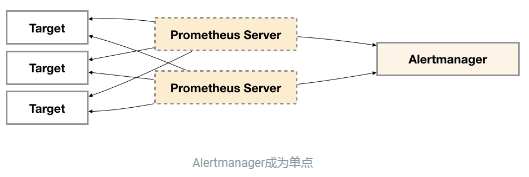
为了提升Promthues的服务可用性,通常用户会部署两个或者两个以上的Promthus Server,它们具有完全相同的配置包括Job配置,以及告警配置等。当某一个Prometheus Server发生故障后可以确保Promthues持续可用。
同时基于Alertmanager的告警分组机制即使不同的Prometheus Sever分别发送相同的告警给Alertmanager,Alertmanager也可以自动将这些告警合并为一个通知向receiver发送。
但不幸的是,虽然Alertmanager能够同时处理多个相同的Prometheus Server所产生的告警。但是由于单个Alertmanager的存在,当前的部署结构存在明显的单点故障风险,当Alertmanager单点失效后,告警的后续所有业务全部失效。
如下所示,最直接的方式,就是尝试部署多套Alertmanager。但是由于Alertmanager之间不存在并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
日常部署 alertmanager 组件的时候,都是用的单点架构,架构图如下所示:
解决这个问题的方法就是使用传统的HA架构模式,部署Alertmanager多节点。
但是由于Alertmanager之间关联存在不能满足HA的需求,因此会导致警报通知被Alertmanager重复发送多次的问题。
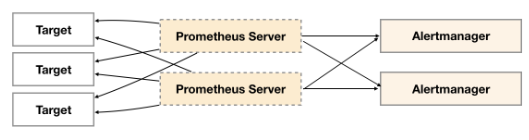
那么显然这样是存在单点故障的,另外对运维而言,其实单点故障是很可怕的,收不到报警有时候是致命的,所以要用高可用的报警方式:
alertmanager的高可用方式有两种方法:
第一种就是引入负载均衡,通过负载均衡的方法保证服务可用,架构如下:
这种方式可以实现高可用 并且可以灵活扩展,云服务的话一般都有负载均衡。
今天主要介绍官方提供的集群方法,架构如下:
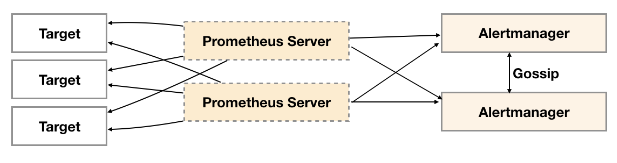
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。
确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
(1.2)Gossip机制
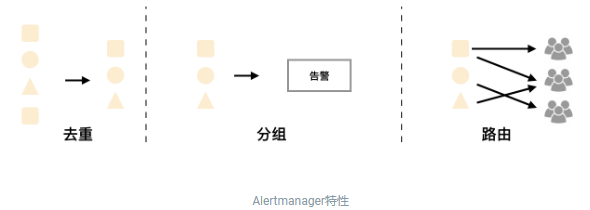
要知道什么是Gossip机制,必须了解清楚Alertmanager中的每一次警报通知是如何产生的,下面一图很详细的阐述了警报个流程:
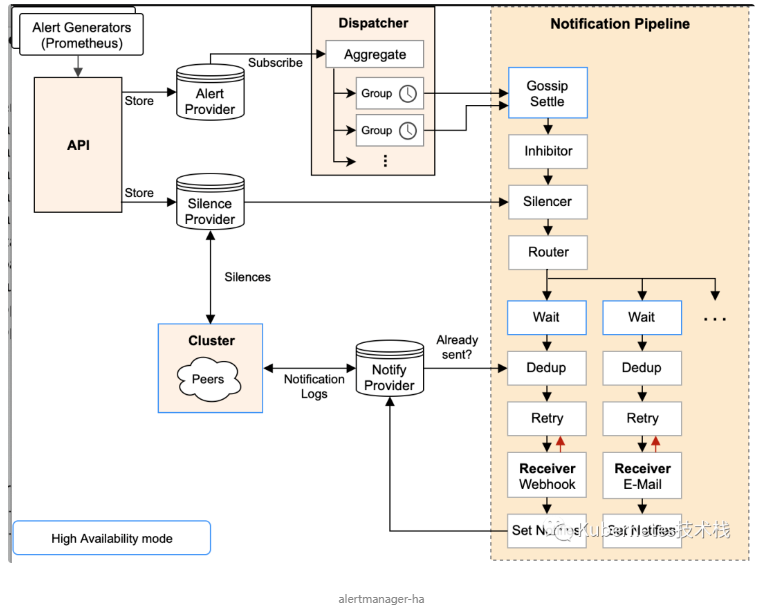

Gossip俩个关键:
-
Alertmanager 节点之间的Silence设置相同,这样确保了设置为静默的警报都不会对外发送
-
Alertmanager 节点之间通过Gossip机制同步警报通知状态,并且在流程中标记Wait阶段,保证警报是依次被集群中的Alertmanager节点读取并处理
一般来说Gossip有两种实现方式分别为Push-based和Pull-based。
Push-based:当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。
Pull-based:节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。
在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:

-
在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知。
-
在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
-
当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
-
告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。

-
Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息。
-
通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
【2】alertmanager 集群配置
(2.1)alertmanager集群参数
# 当前实例集群服务监听地址,为空则禁用高可用功能 --cluster.listen-address="0.0.0.0:9094" # 表示集群节点对其他节点发布的地址,其他节点可以用这个地址与该地址通信 --cluster.advertise-address=CLUSTER.ADVERTISE-ADDRESS # 用来设置该 Alertmanager 节点的集群对等体,将告警数据同步其他节点 --cluster.peer=CLUSTER.PEER # 对等超时时间,默认15秒 --cluster.peer-timeout=15s # 集群消息传播时间,默认200ms --cluster.gossip-interval=200ms # 定义了多个 Alertmanager 实例之间的信息同步频率 --cluster.pushpull-interval=10ms # 评估通知之前等待集群连接建立的最长时间 --cluster.tcp-timeout=10s # 在标记节点不正常之前等待确认的时间 --cluster.probe-timeout=500ms # 随机节点探测之间的间隔 --cluster.probe-interval=1s # 用来设置集群状态稳定的超时时间的参数 --cluster.settle-timeout=10ms # 尝试重新连接到丢失的对等设备之间的间隔时间 --cluster.reconnect-interval=10s # 尝试重新连接到丢失的对等设备的间隔时间 --cluster.reconnect-timeout=6h0m0s # 用于在 Alertmanager 集群模式中配置 TLS 证书 --cluster.tls-config="" # 允许节点发送不加密的广播请求,从而允许其他节点发现它的地址。 # 这条最好不用 --cluster.allow-insecure-public-advertise-address-discovery
(2.2)配置 alertmanager
计划配置2个,一个为
10.18.31.199:9093 集群口为默认的9094 另一个为 10.18.31.201:9093 集群口为默认的9094
修改alertmanager.yml 为一样的内容
# 先运行 10.18.31.199
cd /data/prometheus/alertmanager/ && nohup ./alertmanager --log.level=debug --config.file=alertmanager.yml \
--web.external-url=http://10.18.31.199:9093 >>/data/prometheus/logs/alertmanager.log 2>&1 &
# 再运行 10.18.31.201
cd /data/dba/software/alertmanager/ && nohup ./alertmanager --log.level=debug --config.file=alertmanager.yml --cluster.peer='10.18.31.199:9094' \
--web.external-url=":9093" &
核验:启动后如下图,任意节点的9093端口上去查看都可以看得到。
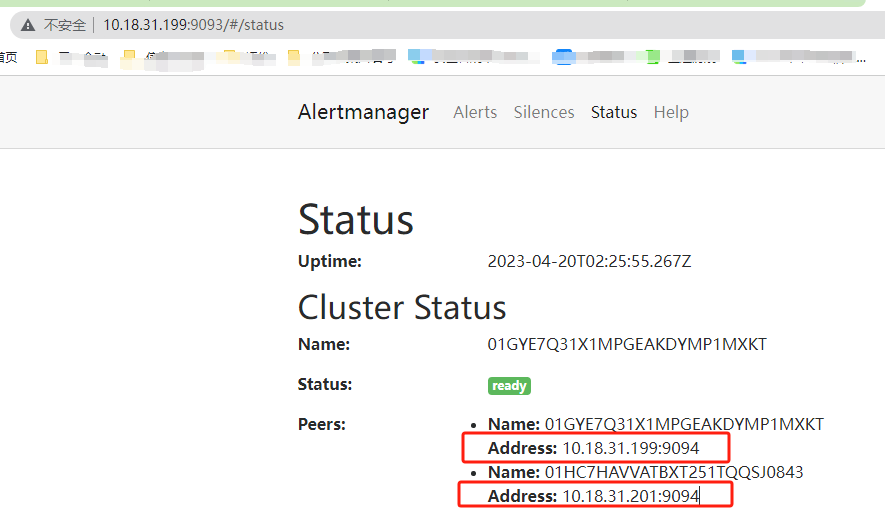
同时我们可以看到,我们在31.199上配置的静默也同步过来了

(2.3)alertmanager集群与prometheus
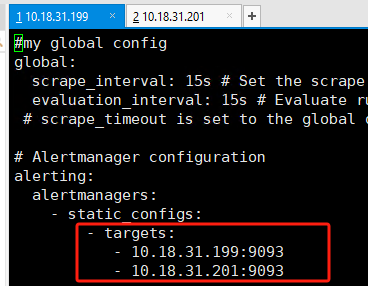
弄完之后记得重载啊: curl -X POST localhost:9090/-/reload
【3】alertmanager集群高可用核验
模拟告警:
aa='[ { "Labels": { "alertname": "alertmanager高可用测试", "IP": "192.168.2.101" }, "Annotations": { "summary": "NodeCpuPressure, IP: 192.168.2.101, Value: 90%, Threshold: 85%" }, "StartsAt": "2020-02-17T23:00:00.000+08:00", "EndsAt": "2029-02-18T23:00:00.000+08:00" } ]' # 执行 POST curl http://127.0.0.1:9093/api/v2/alerts -XPOST -H'Content-Type: application/json' -d"$aa"
1、【两个alertmanager均在运行的情况】模拟是否会产生多重告警?

结论是只有一个告警;
我试试静默在 31.199上静默,看看 31.201 是否会同步,如下图,成功同步;
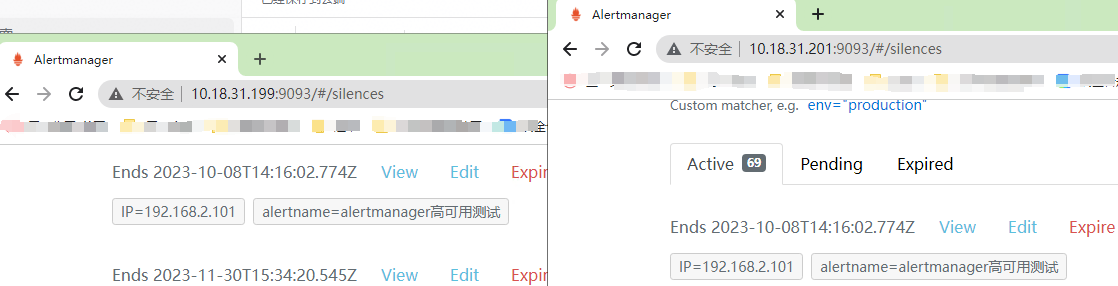
2、【两个alertmanager均在运行的情况】真实故障是否会发多个告警?
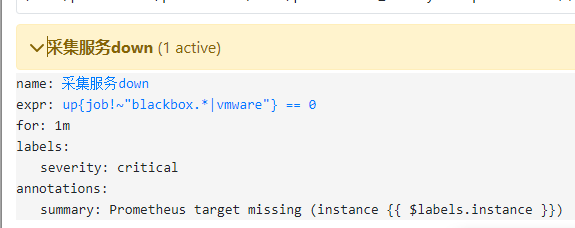
结果依然只是发了一个告警:

3、【宕机1个,正常运行1个】是否可以实现高可用,继续告警?
先关闭其中之一,比如 10.18.31.199 的 alertmanager

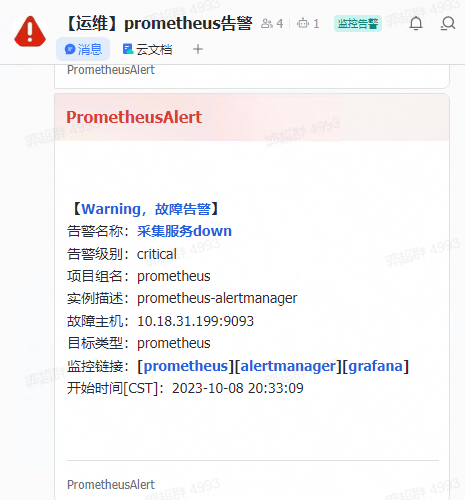
如下图:依然会告警,并且成功了,至此完成。
【参考文档】
https://www.qinglite.cn/doc/60426476c7da4276b
https://yyang.blog.csdn.net/article/details/128980313?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-4-128980313-blog-94476359.235%5Ev38%5Epc_relevant_anti_t3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-4-128980313-blog-94476359.235%5Ev38%5Epc_relevant_anti_t3&utm_relevant_index=3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号