
爬取各地区相关经济数据
一、选题背景
近几十年随着国家的发展,贫富差距在各个省份中体现,财政支付转移尤为重要。
从社会方面看,财政转移支付对维持社会稳定起着重要的作用。
从经济方面看,财政转移支付对平衡各省经济发展起着重要作用,一定程度上避免穷的省越来越穷,富的省越来越富。
从技术方面看,该课题需要从相关网站爬取相关数据,并对数据进行清洗,再以可视化来更直观的展示数据。
数据来源:2021年中央对地方一般公共预算转移支付分地区情况汇总表 (mof.gov.cn)
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取各地区相关经济数据
2.主题网络爬虫爬取的内容与数据特征分析:爬取中央对地方转移支付的地区、2020执行数、2021预算数,并对数据进行分析。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点):
实现思路:爬取相关网站数据,并进行数据清洗,再对数据进行分析,实现数据可视化。
技术难点:爬取过程中标签的查找、数据可视化。
三、主题页面的结构特征分析
爬取页面URL:http://yss.mof.gov.cn/2021zyys/202103/t20210323_3674874.htm
1.主题页面的结构与特征分析:

查看页面源代码,对页面源代码进行检索,发现数据存于页面源代码中,所以此时可以确定的是,不需要使用抓包工具,直接对页面源代码进行爬取。

2.页面解析
观察页面数据可以发现数据为表格类型,故在页面源码中查找<table>标签,<tr>为表格每行的数据,<td>为表格每列的数据,以下将对标签的查找方法进行详细阐述。
3.节点(标签)查找方法与遍历方法
因为页面的数据为表格,所以在页面源代码中寻找<table>标签,在页面源代码中对<table>进行检索,发现总共有三个<table>,所以我们对table的属性进行限制,class="MsoNormalTable"的table为要爬取的数据的table,此时从bs对象中查找<table>标签,属性的值为MsoNormalTable
。
在页面源代码中,<tr>代表表格的每一行,所以查找所有的tr,但是观察页面源代码发现,表格的前两行不是要爬取的数据,故我们对数据进行切片。

<td>则代表表格的每一列,所以要拿到所有的td,观察页面源代码,表格的第一列的数据为“地区”,第一列的索引为0,代码中,tds[0]表示拿到第一列“地区”的内容,接下来几列的数据都使用这种方法进行爬取。



四、网络爬虫程序设计
1.数据爬取与采集:
1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 #拿到页面源代码 5 #使用bs4进行解析,拿到数据 6 7 #写入地址,准备对数据进行爬取 8 url = "http://yss.mof.gov.cn/2021zyys/202103/t20210323_3674874.htm" 9 #写入请求标头 10 headers={ 11 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win4; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43" 12 } 13 14 resp = requests.get(url) 15 16 #爬取后发现乱码 17 #从页面源代码中发现编码方式为utf-8,写入代码防止乱码 18 resp.encoding = 'utf-8' 19 resp.close() 20 21 #导入csv文件 22 f = open("finance.csv", 23 mode="w", 24 newline="", 25 encoding="utf-8") 26 csvwriter = csv.writer(f) 27 28 #解析数据 29 #把页面源代码交给BeautifulSoup进行处理,生成bs对象 30 page = BeautifulSoup(resp.text,"html.parser") 31 #从bs对象中查找数据 32 #class为关键字,在其后添加关键字避免报错 33 34 table = page.find("table",class_="MsoNormalTable") 35 #print(table) 36 #找到所有的行 37 #对数据进行切片处理 38 trs = table.find_all("tr")[2:] 39 40 for tr in trs: 41 #拿到每行中的td 42 tds = tr.find_all("td") 43 #拿到被标签标记的内容 44 name = tds[0].text 45 num_20 = tds[1].text 46 num_20_1 = tds[2].text 47 num_21 = tds[3].text 48 csvwriter.writerow([name,num_20,num_20_1,num_21]) 49 50 #关闭文件 51 f.close() 52 53 print("over!")
运行结果:
![]()
CSV文件如下:

2.对数据进行清洗和处理:
1 import pandas as pd 2 import numpy as np 3 4 file_path = "D:/finance.csv" 5 df = pd.read_csv(file_path,header=None) 6 #打印 DataFrame 的简短摘要 7 print(df.info()) 8 #写入列名 9 df.columns = ['地区', 10 '2020执行数', 11 '2020执行数(剔除特殊转移支付)', 12 '2021预算数'] 13 #打印前几行列表,查看列表是否异常 14 df.head()
运行结果如下:
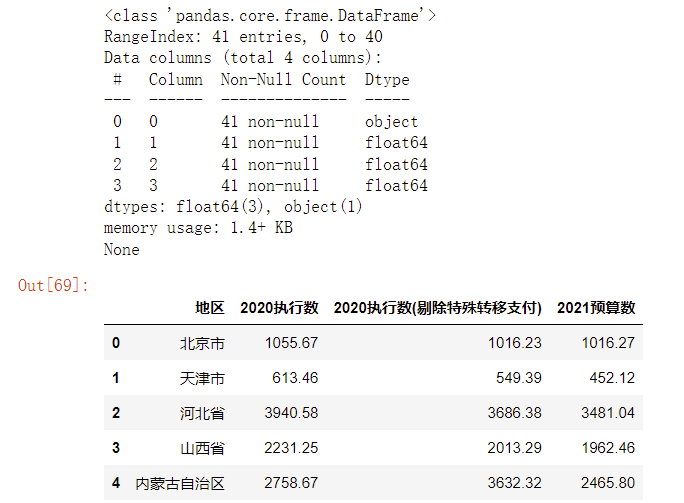
打印出前五行,可以看出数据正常
1 #查看是否存在重复值 2 df[df.duplicated()]
运行结果如下:

数据不存在重复、缺失值
3.文本分析(可选):jieba 分词、wordcloud 的分词可视:
4.数据分析与可视化:
折线图:
1 from matplotlib import pyplot as plt 2 import matplotlib 3 4 #设置中文显示,解决乱码问题 5 font = {'family' : 'MicroSoft YaHei', 6 'weight': 'bold', 7 'size': '12'} 8 matplotlib.rc("font",**font) 9 matplotlib.rc("font", 10 family='MicroSoft YaHei', 11 weight="bold") 12 13 #设置图片大小 14 plt.figure(figsize=(20,8),dpi=80) 15 16 #调整x轴,翻转90度 17 plt.xticks(rotation=90) 18 19 #添加描述信息 20 plt.xlabel("地区") 21 plt.ylabel("人民币 单位(亿元)") 22 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 23 24 #绘制图像 25 plt.plot(df['地区'], 26 df['2020执行数'], 27 label="2020执行数", 28 color="green") 29 plt.plot(df['地区'], 30 df['2020执行数(剔除特殊转移支付)'], 31 label="2020执行数(剔除特殊转移支付)", 32 color="orange") 33 plt.plot(df['地区'], 34 df['2021预算数'], 35 label="2021预算数", 36 color="blue") 37 38 #添加图例 39 plt.legend() 40 41 #展示图形 42 plt.show()
运行结果如下:
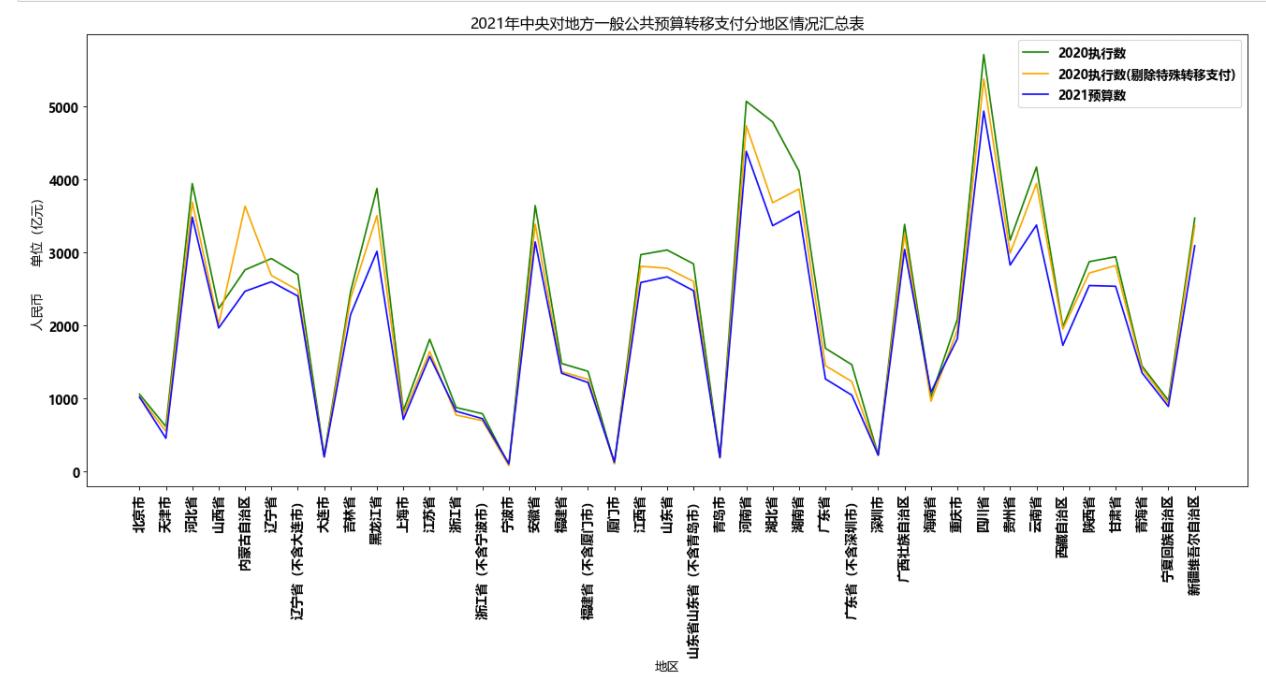
从图中可以直观的看出中央对地方转移支付金额较高的主要为落后省份,其中四川、河南、湖北等中西部省份较高,北京、上海、浙江等发达地区明显处于较低水平。
散点图:
1 #设置图形大小 2 plt.figure(figsize=(10,4),dpi=80) 3 4 #添加描述信息 5 plt.xlabel("地区") 6 plt.ylabel("人民币 单位(亿元)") 7 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 8 9 #调整x轴,翻转90度 10 plt.xticks(rotation=90) 11 plt.scatter(df['地区'], 12 df['2020执行数']) 13 plt.show() 14 #设置图形大小 15 plt.figure(figsize=(10,4),dpi=80) 16 17 #添加描述信息 18 plt.xlabel("地区") 19 plt.ylabel("人民币 单位(亿元)") 20 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 21 22 #调整x轴,翻转90度 23 plt.xticks(rotation=90) 24 plt.scatter(df['地区'], 25 df['2020执行数(剔除特殊转移支付)'], 26 color="red") 27 plt.show() 28 #设置图形大小 29 plt.figure(figsize=(10,4),dpi=80) 30 31 #添加描述信息 32 plt.xlabel("地区") 33 plt.ylabel("人民币 单位(亿元)") 34 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 35 36 #调整x轴,翻转90度 37 plt.xticks(rotation=90) 38 plt.scatter(df['地区'], 39 df['2021预算数'], 40 color="orange") 41 42 plt.show()
运行结果如下:
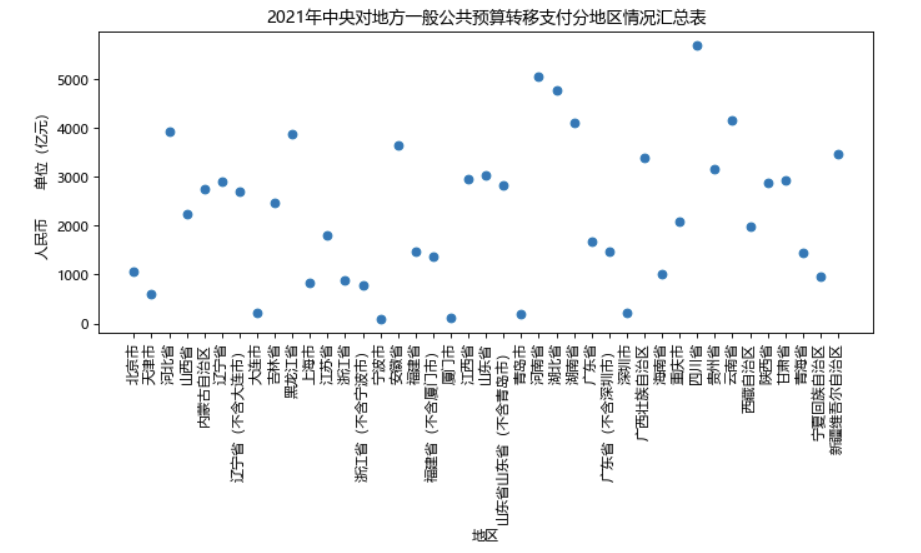
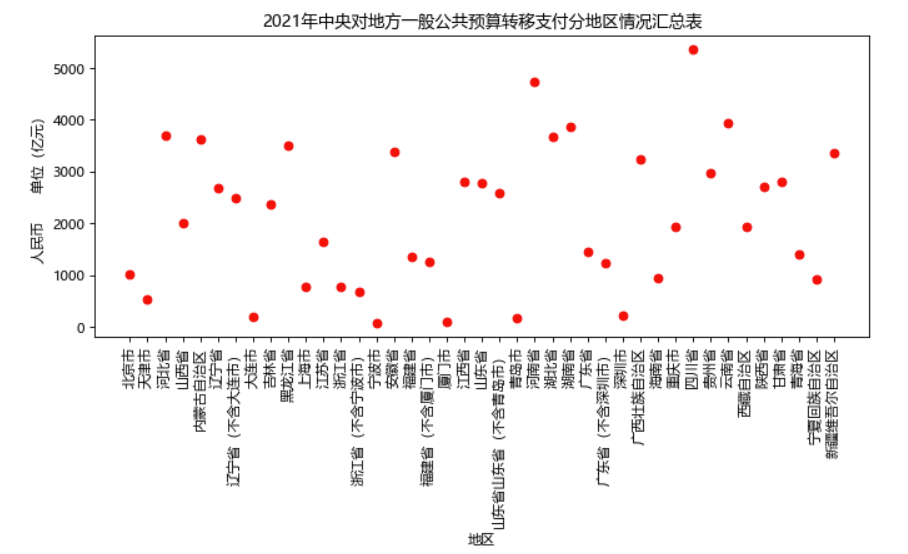
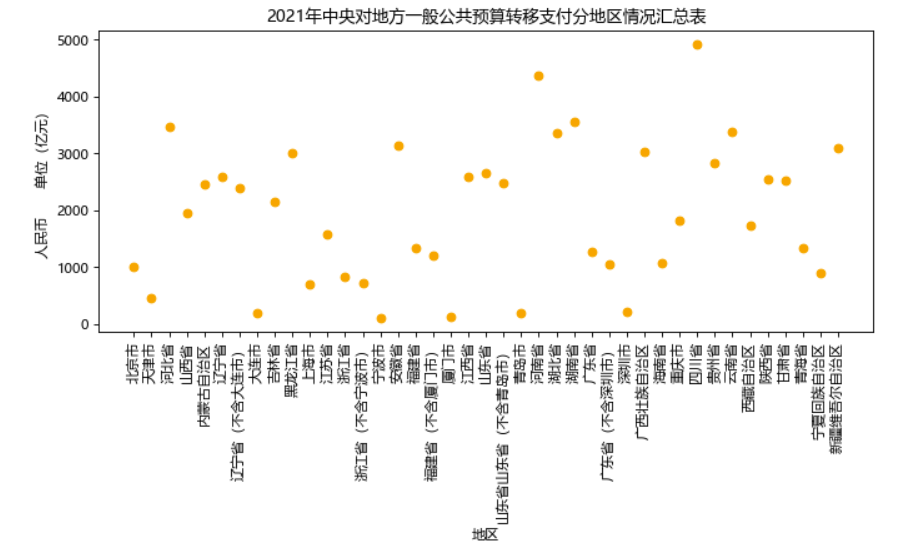
三张图分别为:2020执行数、2020执行数(剔除特殊转移支付)、2021预算数三个数据的散点图,可以转为直观的看出各地区转移支付情况。
条形图:
1 #设置中文显示,解决乱码问题 2 font = {'family' : 'MicroSoft YaHei', 3 'weight': 'bold', 4 'size': '12'} 5 matplotlib.rc("font",**font) 6 matplotlib.rc("font", 7 family='MicroSoft YaHei', 8 weight="bold") 9 10 #设置图形大小 11 plt.figure(figsize=(20,13),dpi=80) 12 13 #添加描述信息 14 plt.xlabel("人民币 单位(亿元)") 15 plt.ylabel("地区") 16 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 17 plt.barh(range(len(df['地区'])), 18 df['2021预算数'], 19 height=0.3, 20 color="orange") 21 plt.yticks(range(len(df['地区'])),df['地区']) 22 plt.show()
运行结果如下:
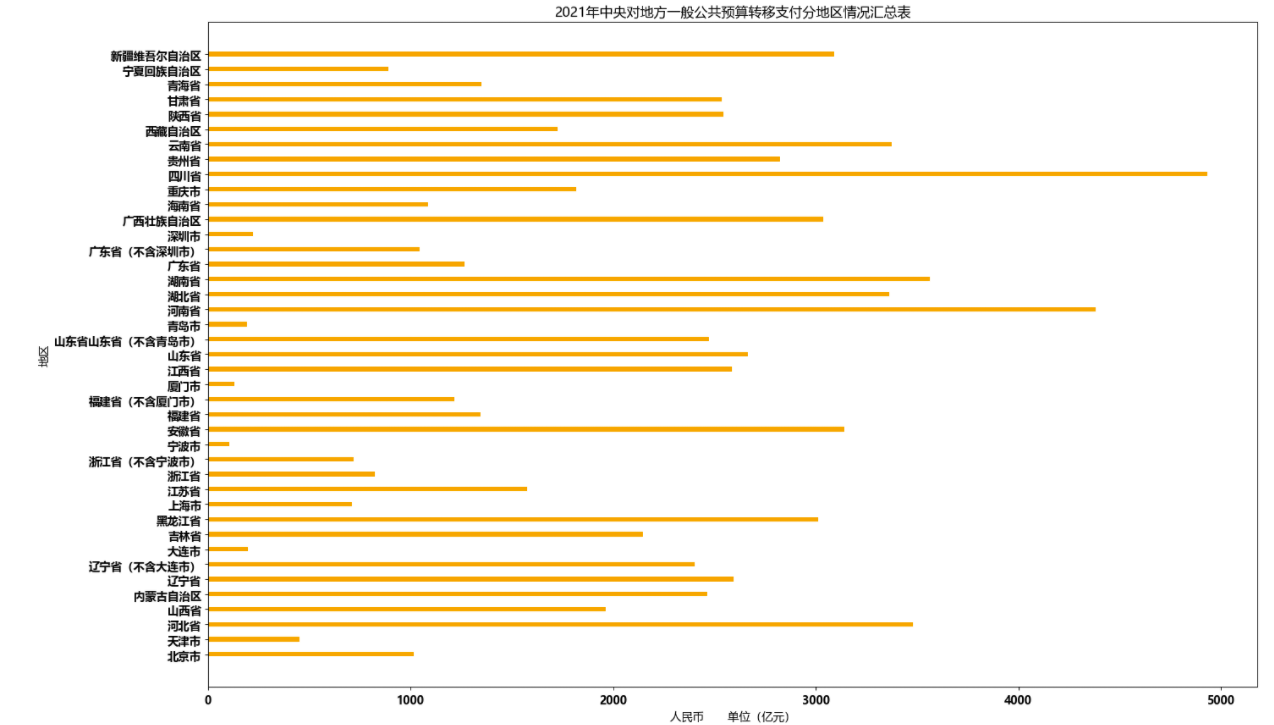
条形图也凸显了转移支付金额较高的省份。
茎叶图:
1 #设置中文显示,解决乱码问题 2 font = {'family' : 'MicroSoft YaHei', 3 'weight': 'bold', 4 'size': '12'} 5 matplotlib.rc("font",**font) 6 matplotlib.rc("font", 7 family='MicroSoft YaHei', 8 weight="bold") 9 fig, ax = plt.subplots(figsize=(20, 8)) 10 ax.stem(df['地区'], 11 df['2021预算数']) 12 13 #设置标签 14 plt.xlabel("地区") 15 plt.ylabel("人民币 单位(亿元)") 16 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 17 #X轴翻转90度 18 plt.xticks(rotation=90) 19 #打印图片 20 plt.show()
运行结果如下:

直方图:
1 import csv 2 import matplotlib 3 import matplotlib.pyplot as plt 4 import numpy as np 5 import pandas as pd 6 7 #设置图形大小 8 plt.figure(figsize=(20,8),dpi=80) 9 10 def xl_Dis():#统计转移支付各地区情况分布 11 pr = pd.read_csv('D:/finance.csv') 12 pr1 = pd.read_csv('D:/fiance.csv', low_memory=False) 13 print("转移支付各地区情况分布:") 14 print() 15 xl = [] 16 for i in pr['2020执行数']: 17 xl.append(i) 18 xl1=[] 19 xl2=[] 20 xl3=[] 21 xl4=[] 22 x15=[] 23 for i in xl: 24 if 0<i<1000: 25 xl1.append(i) 26 elif 1000<i<2000: 27 xl2.append(i) 28 elif 2000<i<3000: 29 xl3.append(i) 30 elif 3000<i<4000: 31 xl4.append(i) 32 elif 4000<i<5000: 33 xl4.append(i) 34 35 36 index=['0-1000','1000-2000','2000-3000','3000-4000','4000-5000'] 37 values=[len(xl1),len(xl2),len(xl3),len(xl4),len(x15)] 38 plt.bar(index,values) 39 plt.show() 40 41 42 if __name__=="__main__": 43 xl_Dis()
运行结果如下:
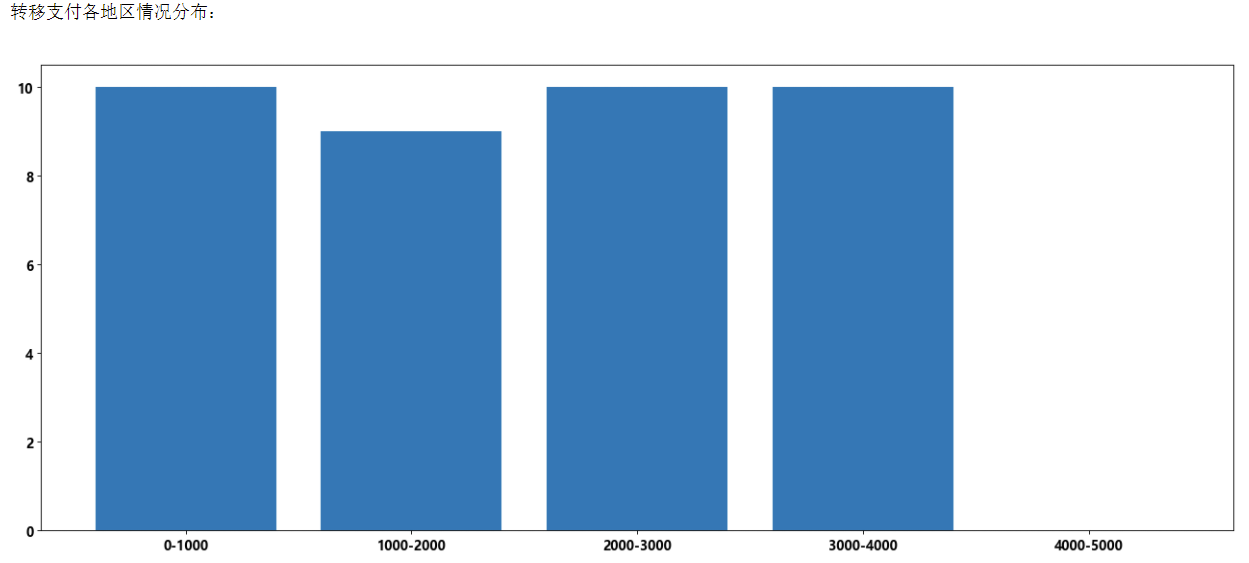
通过直方图,可以较为清晰的看出转移支付各地区分布情况。
饼图:
1 #查看数据占比 2 #print(df.describe()) 3 #设置图形大小 4 plt.figure(figsize=(15,8),dpi=80) 5 finance=[len(df[df["2020执行数"]<1000.00]["2020执行数"]), 6 len(df[df["2020执行数"]>1000.00][df["2020执行数"]<2000.00]["2020执行数"]), 7 len(df[df["2020执行数"]>2000.00][df["2020执行数"]<3000.00]["2020执行数"]), 8 len(df[df["2020执行数"]>3000.00]["2020执行数"])] 9 10 #设置中文显示,解决乱码问题 11 font = {'family' : 'MicroSoft YaHei', 12 'weight': 'bold', 13 'size': '12'} 14 matplotlib.rc("font",**font) 15 matplotlib.rc("font", 16 family='MicroSoft YaHei', 17 weight="bold") 18 labels = ["转移支付金额小于1000亿元", 19 "转移支付金额在1000亿与2000亿之间", 20 "转移支付金额在2000亿与3000亿之间", 21 "转移支付金额大于3000亿元"] 22 explode = [0, 0, 0, 0.1] 23 colors = ['paleturquoise', 'cyan', 'c', 'cadetblue'] 24 plt.pie(finance, explode=explode, labels=labels, 25 colors=colors,autopct='%.2f%%', 26 pctdistance=0.8, labeldistance=1.1, 27 startangle=180, radius=1.2, 28 counterclock=False, 29 wedgeprops={'linewidth':1.5, 'edgecolor':'white'}, 30 textprops={'fontsize':10, 'color':'black'} ) 31 32 plt.title('中央对地方转移支付分地区情况分布:') 33 34 ax1.axis('equal') 35 36 plt.show()
运行结果如下:

通过饼图,可以发现转移支付金额大于3000亿元这个区间较多。
5.完整代码
1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 #拿到页面源代码 5 #使用bs4进行解析,拿到数据 6 7 #写入地址,准备对数据进行爬取 8 url = "http://yss.mof.gov.cn/2021zyys/202103/t20210323_3674874.htm" 9 #写入请求标头 10 headers={ 11 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43" 12 } 13 14 resp = requests.get(url) 15 16 #爬取后发现乱码 17 #从页面源代码中发现编码方式为utf-8,写入代码防止乱码 18 resp.encoding = 'utf-8' 19 resp.close() 20 21 #导入csv文件 22 f = open("finance.csv", 23 mode="w", 24 newline="", 25 encoding="utf-8") 26 csvwriter = csv.writer(f) 27 28 #解析数据 29 #把页面源代码交给BeautifulSoup进行处理,生成bs对象 30 page = BeautifulSoup(resp.text,"html.parser") 31 #从bs对象中查找数据 32 #class为关键字,在其后添加关键字避免报错 33 34 table = page.find("table",class_="MsoNormalTable") 35 #print(table) 36 #找到所有的行 37 #对数据进行切片处理 38 trs = table.find_all("tr")[2:] 39 40 for tr in trs: 41 #拿到每行中的td 42 tds = tr.find_all("td") 43 #拿到被标签标记的内容 44 name = tds[0].text 45 num_20 = tds[1].text 46 num_20_1 = tds[2].text 47 num_21 = tds[3].text 48 csvwriter.writerow([name,num_20,num_20_1,num_21]) 49 50 #关闭文件 51 f.close() 52 53 print("over!") 54 import pandas as pd 55 import numpy as np 56 57 file_path = "D:/finance.csv" 58 df = pd.read_csv(file_path,header=None) 59 #打印 DataFrame 的简短摘要 60 print(df.info()) 61 #写入列名 62 df.columns = ['地区', 63 '2020执行数', 64 '2020执行数(剔除特殊转移支付)', 65 '2021预算数'] 66 #打印前几行列表,查看列表是否异常 67 df.head() 68 #查看是否存在重复值 69 df[df.duplicated()] 70 from matplotlib import pyplot as plt 71 import matplotlib 72 73 #设置中文显示,解决乱码问题 74 font = {'family' : 'MicroSoft YaHei', 75 'weight': 'bold', 76 'size': '12'} 77 matplotlib.rc("font",**font) 78 matplotlib.rc("font", 79 family='MicroSoft YaHei', 80 weight="bold") 81 82 #设置图片大小 83 plt.figure(figsize=(20,8),dpi=80) 84 85 #调整x轴,翻转90度 86 plt.xticks(rotation=90) 87 88 #添加描述信息 89 plt.xlabel("地区") 90 plt.ylabel("人民币 单位(亿元)") 91 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 92 93 #绘制图像 94 plt.plot(df['地区'], 95 df['2020执行数'], 96 label="2020执行数", 97 color="green") 98 plt.plot(df['地区'], 99 df['2020执行数(剔除特殊转移支付)'], 100 label="2020执行数(剔除特殊转移支付)", 101 color="orange") 102 plt.plot(df['地区'], 103 df['2021预算数'], 104 label="2021预算数", 105 color="blue") 106 107 #添加图例 108 plt.legend() 109 110 #展示图形 111 plt.show() 112 #设置图形大小 113 plt.figure(figsize=(10,4),dpi=80) 114 115 #添加描述信息 116 plt.xlabel("地区") 117 plt.ylabel("人民币 单位(亿元)") 118 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 119 120 #调整x轴,翻转90度 121 plt.xticks(rotation=90) 122 plt.scatter(df['地区'], 123 df['2020执行数']) 124 plt.show() 125 #设置图形大小 126 plt.figure(figsize=(10,4),dpi=80) 127 128 #添加描述信息 129 plt.xlabel("地区") 130 plt.ylabel("人民币 单位(亿元)") 131 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 132 133 #调整x轴,翻转90度 134 plt.xticks(rotation=90) 135 plt.scatter(df['地区'], 136 df['2020执行数(剔除特殊转移支付)'], 137 color="red") 138 plt.show() 139 #设置图形大小 140 plt.figure(figsize=(10,4),dpi=80) 141 142 #添加描述信息 143 plt.xlabel("地区") 144 plt.ylabel("人民币 单位(亿元)") 145 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 146 147 #调整x轴,翻转90度 148 plt.xticks(rotation=90) 149 plt.scatter(df['地区'], 150 df['2021预算数'], 151 color="orange") 152 153 plt.show() 154 #设置中文显示,解决乱码问题 155 font = {'family' : 'MicroSoft YaHei', 156 'weight': 'bold', 157 'size': '12'} 158 matplotlib.rc("font",**font) 159 matplotlib.rc("font", 160 family='MicroSoft YaHei', 161 weight="bold") 162 163 #设置图形大小 164 plt.figure(figsize=(20,13),dpi=80) 165 166 #添加描述信息 167 plt.xlabel("人民币 单位(亿元)") 168 plt.ylabel("地区") 169 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 170 plt.barh(range(len(df['地区'])), 171 df['2021预算数'], 172 height=0.3, 173 color="orange") 174 plt.yticks(range(len(df['地区'])),df['地区']) 175 plt.show() 176 #设置中文显示,解决乱码问题 177 font = {'family' : 'MicroSoft YaHei', 178 'weight': 'bold', 179 'size': '12'} 180 matplotlib.rc("font",**font) 181 matplotlib.rc("font", 182 family='MicroSoft YaHei', 183 weight="bold") 184 fig, ax = plt.subplots(figsize=(20, 8)) 185 ax.stem(df['地区'], 186 df['2021预算数']) 187 188 #设置标签 189 plt.xlabel("地区") 190 plt.ylabel("人民币 单位(亿元)") 191 plt.title("2021年中央对地方一般公共预算转移支付分地区情况汇总表") 192 #X轴翻转90度 193 plt.xticks(rotation=90) 194 #打印图片 195 plt.show() 196 import csv 197 import matplotlib 198 import matplotlib.pyplot as plt 199 import numpy as np 200 import pandas as pd 201 202 #设置图形大小 203 plt.figure(figsize=(20,8),dpi=80) 204 205 def xl_Dis():#统计转移支付各地区情况分布 206 pr = pd.read_csv('D:/finance.csv') 207 pr1 = pd.read_csv('D:/fiance.csv', low_memory=False) 208 print("转移支付各地区情况分布:") 209 print() 210 xl = [] 211 for i in pr['2020执行数']: 212 xl.append(i) 213 xl1=[] 214 xl2=[] 215 xl3=[] 216 xl4=[] 217 x15=[] 218 for i in xl: 219 if 0<i<1000: 220 xl1.append(i) 221 elif 1000<i<2000: 222 xl2.append(i) 223 elif 2000<i<3000: 224 xl3.append(i) 225 elif 3000<i<4000: 226 xl4.append(i) 227 elif 4000<i<5000: 228 xl4.append(i) 229 230 231 index=['0-1000','1000-2000','2000-3000','3000-4000','4000-5000'] 232 values=[len(xl1),len(xl2),len(xl3),len(xl4),len(x15)] 233 plt.bar(index,values) 234 plt.show() 235 236 237 if __name__=="__main__": 238 xl_Dis() 239 #查看数据占比 240 print(df.describe()) 241 #查看数据占比 242 #print(df.describe()) 243 #设置图形大小 244 plt.figure(figsize=(15,8),dpi=80) 245 finance=[len(df[df["2020执行数"]<1000.00]["2020执行数"]), 246 len(df[df["2020执行数"]>1000.00][df["2020执行数"]<2000.00]["2020执行数"]), 247 len(df[df["2020执行数"]>2000.00][df["2020执行数"]<3000.00]["2020执行数"]), 248 len(df[df["2020执行数"]>3000.00]["2020执行数"])] 249 250 #设置中文显示,解决乱码问题 251 font = {'family' : 'MicroSoft YaHei', 252 'weight': 'bold', 253 'size': '12'} 254 matplotlib.rc("font",**font) 255 matplotlib.rc("font", 256 family='MicroSoft YaHei', 257 weight="bold") 258 labels = ["转移支付金额小于1000亿元", 259 "转移支付金额在1000亿与2000亿之间", 260 "转移支付金额在2000亿与3000亿之间", 261 "转移支付金额大于3000亿元"] 262 explode = [0, 0, 0, 0.1] 263 colors = ['paleturquoise', 'cyan', 'c', 'cadetblue'] 264 plt.pie(finance, explode=explode, labels=labels, 265 colors=colors,autopct='%.2f%%', 266 pctdistance=0.8, labeldistance=1.1, 267 startangle=180, radius=1.2, 268 counterclock=False, 269 wedgeprops={'linewidth':1.5, 'edgecolor':'white'}, 270 textprops={'fontsize':10, 'color':'black'} ) 271 272 plt.title('中央对地方转移支付分地区情况分布:') 273 274 ax1.axis('equal') 275 276 plt.show()
五、总结
1.转移支付是为了平衡各省份的发展情况,避免出现富的更富,穷的更穷的极端情况。通过这次对财政部中央转移支付数据的爬取与可视化,可以较为直观的看出,中西部、北部经济落后省份较为依赖中央财政的转移支付,正因为有了转移支付这个手段,一定程度上避免了财富分化的情况,促进了落后省份的基础建设、经济发展。
2.在完成此次课程设计中,学会了很多关于python高级应用的知识,遇到了很多困难,最终也克服了这些困难,成功完成了课程设计。不过这次爬取的数据并不能较为直观的看出各地区的经济情况,应该从多个维度去观察各个省份。
