

python: sql server insert record
sql script:
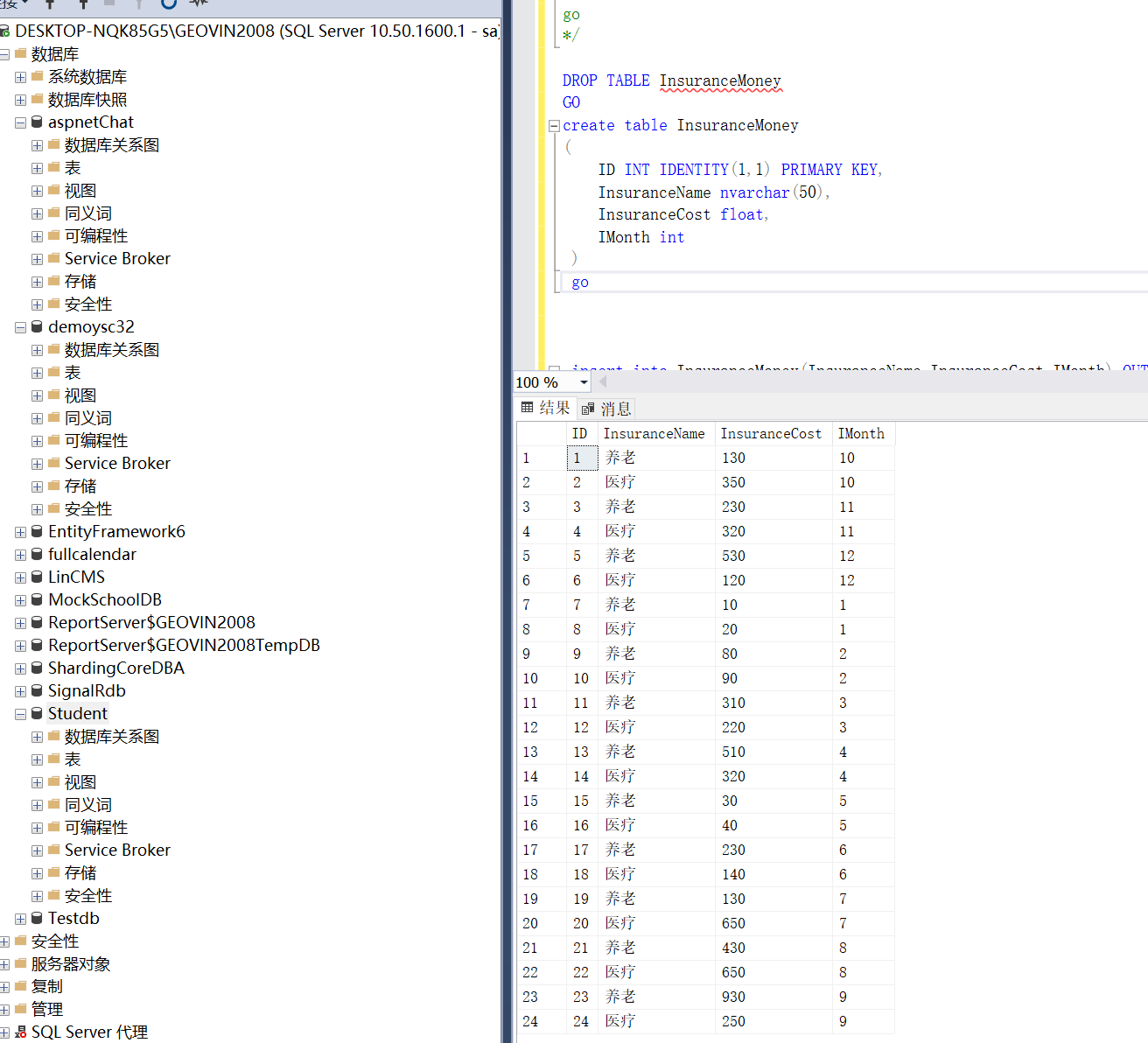
1 2 3 4 5 6 7 8 9 10 | DROP TABLE InsuranceMoneyGOcreate table InsuranceMoney( ID INT IDENTITY(1,1) PRIMARY KEY, InsuranceName nvarchar(50), InsuranceCost float, IMonth int ) go |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | # coding=utf-8"""SQLServerDAL.pySQL Server 数据库操作date 2023-06-13edit: Geovin Du,geovindu, 涂聚文ide: Visual Studio 2022 参考:https://learn.microsoft.com/zh-cn/sql/connect/python/pymssql/step-3-proof-of-concept-connecting-to-sql-using-pymssql?view=sql-server-ver16"""import osimport sysfrom pathlib import Pathimport reimport pymssql #sql serverimport Insuranceclass SQLclass(object): """ Sql server """ def select(self): """ 查询所有记录 """ conn = pymssql.connect(server='DESKTOP-NQK85G5\GEOVIN2008', user='sa', password='geovindu', database='Student') cursor = conn.cursor() cursor.execute('select * from InsuranceMoney;') row = cursor.fetchone() while row: print(str(row[0]) + " " + str(row[1]) + " " + str(row[2])) row = cursor.fetchone() def insert(iobject): """ 插入操作 param:iobject 输入保险类 """ dubojd=Insurance.InsuranceMoney(iobject) conn = pymssql.connect(server='DESKTOP-NQK85G5\GEOVIN2008', user='sa', password='geovindu', database='Student') cursor = conn.cursor() cursor.execute("insert into InsuranceMoney(InsuranceName,InsuranceCost,IMonth) OUTPUT INSERTED.ID VALUES ('{0}', {1}, {2})".format(dubojd.getInsuranceName, dubojd.getInsuranceCost,dubojd.getIMonth)) row = cursor.fetchone() while row: print("Inserted InsuranceMoney ID : " +str(row[0])) row = cursor.fetchone() conn.commit() conn.close() def insertStr(InsuranceName,InsuranceCost,IMonth): """ 插入操作 param:InsuranceName param:InsuranceCost param:IMonth """ conn = pymssql.connect(server='DESKTOP-NQK85G5\GEOVIN2008', user='sa', password='geovindu', database='Student') cursor = conn.cursor() cursor.execute("insert into InsuranceMoney(InsuranceName,InsuranceCost,IMonth) OUTPUT INSERTED.ID VALUES('{0}',{1},{2})".format(InsuranceName, InsuranceCost,IMonth)) row = cursor.fetchone() while row: print("Inserted InsuranceMoney ID : " +str(row[0])) row = cursor.fetchone() conn.commit() conn.close() |
调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 | # coding=utf-8"""PythonAppReadExcel.pyedit: geovindu,Geovin Du,涂聚文 python 11date 2023-06-13保险类ide: Visual Studio 2022 """import sysimport xlrdimport xlwtimport xlwings as xwimport xlsxwriterimport openpyxl as wsimport pandas as pdimport pandasqlfrom pandasql import sqldfimport osimport sysfrom pathlib import Pathimport reimport pysparkfrom pyspark.sql.functions import exprfrom pyspark.sql import Rowfrom pyspark.sql import SparkSessionimport Insuranceimport ReadExcelDataimport pymssql import SQLServerDALif __name__ == '__main__': #https://www.digitalocean.com/community/tutorials/pandas-read_excel-reading-excel-file-in-python #https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.convert_dtypes.html #https://www.geeksforgeeks.org/args-kwargs-python/ insura=[] objlist=[] #excelcovert() s = '1123*#$ 中abc国' str = re.sub('[a-zA-Z0-9!#$%&\()*+,-./:;<=>?@,。?★、…【】《》?!^_`{|}~\s]+', "", s) # 去除不可见字符 str = re.sub('[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+',"", str) print(str) phone = "2004-959-559 # 这是一个电话号码" tt="1月缴纳明细(元)" newtt=re.sub(r'月缴纳明细(元)',"",tt) print(newtt) # 删除注释 num = re.sub(r'#.*$', "", phone) print("电话号码 : ", num) xlspath1 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\1月.xls' xlspath2 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\2月.xls' xlspath3 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\3月.xls' xlspath4 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\4月.xls' xlspath5 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\5月.xls' xlspath6 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\6月.xls' xlspath7 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\7月.xls' xlspath8 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\8月.xls' xlspath9 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\9月.xls' xlspath10 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\10月.xls' xlspath11 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\11月.xls' xlspath12 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\12月.xls' dulist=[] # 封装成类操作 dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath1) dulist2 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath2) dulist3 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath3) dulist4 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath4) dulist5 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath5) dulist6 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath6) dulist7 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath7) dulist8 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath8) dulist9 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath9) dulist10 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath10) dulist11 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath11) dulist12 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath12) ''' #dulist.append(dulist2) for Insurance.InsuranceMoney in dulist1: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist2: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist3: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist4: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist5: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist6: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist7: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist8: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist9: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist10: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist11: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist12: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist: duobj = Insurance.InsuranceMoney print(duobj) ''' spark = SparkSession.builder.getOrCreate() print("geovindu,*************") datalist=[] # 查询某文件夹下的文件名 folderPath=Path(r'C:\\Users\\geovindu\\Documents\\Visual Studio 2022\\Projects\\PythonAppReadExcel\\') fileList=folderPath.glob('*.xls') for i in fileList: stname=i.stem print(stname) # 查询文件夹下的文件 print(os.path.join(path, "User/Desktop", "file.txt")) dufile=ReadExcelData.ReadExcelData.ReadFileName(folderPath,'xls') for f in dufile: fileurl=os.path.join(folderPath,f) dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(fileurl) # object is not callable 变量名称冲突的原因 for duobj in dulist1: dulist.append(duobj) print(os.path.join(folderPath,f)) ylsum=0 # 养老 llsum=0 #医疗 totalsum=0 #一年费用 for geovindu in dulist: #duobj = Insurance.Insurance print(geovindu) name = geovindu.getInsuranceName() duname = name.convert_dtypes() # yname = duname['Unnamed: 2'] print(type(duname)) print("保险类型:", duname) # class 'pandas.core.series.Series strname = pd.Series(duname).values[0] coas1=geovindu.getInsuranceCost() #coast = int(geovindu.getInsuranceCost()) coas =coas1.convert_dtypes() coast=pd.Series(coas).values[0] #int(coas) #print("casa",int(coas)) totalsum = totalsum + coast if (strname == "养老"): ylsum = ylsum + coast if (strname == "医疗"): llsum = llsum + coast print("费用:", coast) month = int(geovindu.getIMonth()) print("月份:", month) datalist.append([strname,coast,month]) SQLServerDAL.SQLclass.insertStr(strname,coast,month) #插入数据库中 print("一年养老",ylsum) print("一年医疗",llsum) print("一年费用",totalsum) #https: // pandas.pydata.org / pandas - docs / stable / reference / api / pandas.DataFrame.groupby.html #导出数据生成EXCEL dataf = pd.DataFrame(datalist,columns=['保险类型','交费金额','交费月份']) #增加列名称 dataf2=pd.DataFrame({"统计类型":["一年养老","一年医疗","一年费用"],"金额":[ylsum,llsum,totalsum]}) dataf.sort_values('交费月份', inplace=True) #指定列排序 #duda=dataf.groupby(by=["保险类型"], dropna=False).sum() #print(duda) #https://www.datacamp.com/tutorial/how-to-use-sql-in-pandas-using-pandasql-queries #sdf = dataf.sqldf("select '保险类型','交费金额','交费月份' from dataf") #sdf.head() #print(sdf) #交费用分份统计 print(sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''')) staicmont=sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''') #pySpark # https://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html geovindudf = spark.createDataFrame(dataf) # #geovindudf.show() geovindudf.printSchema() geovindudf.createOrReplaceTempView("GeovinDu") #spark.sql("SELECT * from GeovinDu").show() #有异常 #spark.read.csv('foo.csv', header=True).show() #query_df = pyspark.SQLContext(f"SELECT * FROM dataf") #duda=dataf.groupby(by=["保险类型"], dropna=False).sum() #print(duda) #https://www.datacamp.com/tutorial/how-to-use-sql-in-pandas-using-pandasql-queries #交费用分份统计 #print(sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''')) staicmonth=sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''') with pd.ExcelWriter('geovindu.xlsx') as writer: dataf.to_excel(writer, sheet_name='2023年保险费用详情',index=False) dataf2.to_excel(writer, sheet_name='保险统计',index=False) staicmont.to_excel(writer, sheet_name='月份统计', index=False) |
 \
\

哲学管理(学)人生, 文学艺术生活, 自动(计算机学)物理(学)工作, 生物(学)化学逆境, 历史(学)测绘(学)时间, 经济(学)数学金钱(理财), 心理(学)医学情绪, 诗词美容情感, 美学建筑(学)家园, 解构建构(分析)整合学习, 智商情商(IQ、EQ)运筹(学)生存.---Geovin Du(涂聚文)
分类:
Python
标签:
sql server


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!