

python: read excel
NumPy
SciPy
matplotlib
IPython
pandas
tables
numexpr
openpyxl
XlsxWriter
xlrd
feedparser
Beautiful Soup
SQLAlchemy
Pony
dataset
MongoDB
PyMongo
Redis server
Redis
Cassandra
NLTK
scikit-learn
NetworkX
DEAP
theanets
Graphviz
pydot2
Octave
R
rpy
JPype
SWIG
PCRE
Boost
gfortran
GAE for Python
gprof2dot
line_profler beta
Cython
cytoolz
Joblib
Bottleneck
Jug
MPI
mpi4py
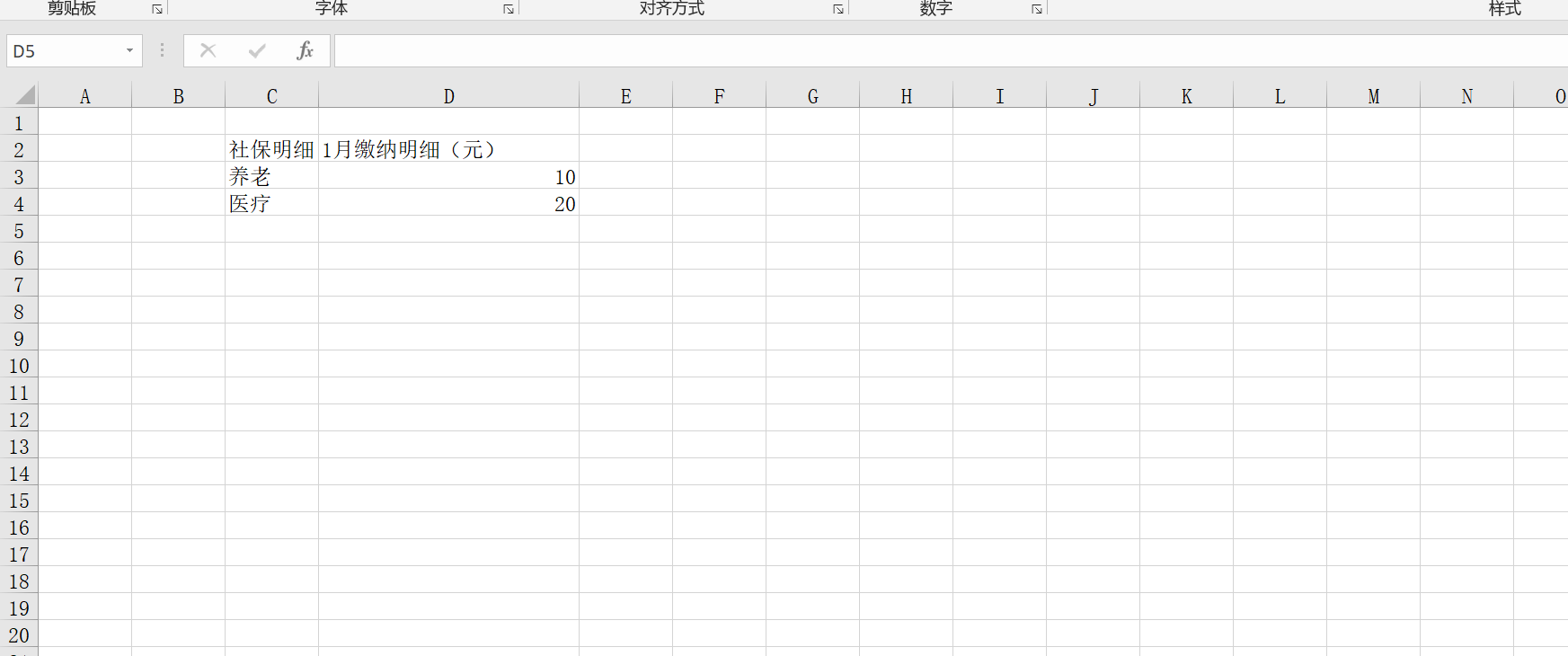
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 | """Insurance。pyedit: geovindu,Geovin Du,涂聚文date 2023-06-13保险类"""import sysimport osclass Insurance: """ 保险类 """ def __init__(self, InsuranceName, InsuranceCost, IMonth): """ 保险类 构造函数 :param InsuranceName: 保险类型 :param InsuranceCost: 保险费用 :param IMonth: 月份 """ self.__InsuranceName = InsuranceName self.__InsuranceCost = InsuranceCost self.__IMonth = IMonth def get_InsuranceName(self): """ 得到保险名称 :return: 返回保险名称 """ return self.__InsuranceName def set_InsuranceName(self, InsuranceName): """ 设置保险名称 :param InsuranceName: 输入保险名称 :return: none """ self.__InsuranceName = InsuranceName def get_InsuranceCost(self): """ 获取保险费用 :return: 返回保险费用 """ return self.__InsuranceCost def set_InsuranceCost(self, InsuranceCost): """ 设置保险费用 :param InsuranceCost: 输入保险费用 :return: none """ self.__InsuranceCost = InsuranceCost def get_IMonth(self): """ 获取月份 :return: 返回月份 """ return self.__IMonth def set_IMonth(self, IMonth): """ 设置月份 :param IMonth: 输入月份 :return: none """ self.__IMonth = IMonth def __str__(self): return f"InsuranceName: {self.__InsuranceName}, InsuranceCost: {self.__InsuranceCost}, Month: {self.__IMonth}""""ReadExcelData.py读取excel文件数据date 2023-06-13edit: Geovin Du,geovindu, 涂聚文"""import xlrdimport xlwtimport xlwings as xwimport xlsxwriterimport openpyxl as wsimport pandas as pdimport pandasqlimport osimport sysfrom pathlib import Pathimport reimport Insuranceclass ReadExcelData: """ 读EXCEL文件 """ def ReadFileName(folderPath,exif): """ 文读文件夹下的文件列表 :param folderPath: :param exif: 文件扩展名 如:'xls','xlsx','doc', 'docx' :return:返回文件名称列表,包括扩展名 """ # 查询某文件夹下的文件名 #folderPath=Path('C:\\Users\\geovindu\\PycharmProjects\\pythonProject\\') #fileList=folderPath.glob('*.xls') filenames=[] fileList = folderPath.glob('*.'+exif) for i in fileList: #stname=i.stem filenames.append(i.stem+'.'+exif) return filenames def ReadDataFile(xlspath): """ 读取指定一文件的数据 :param xlspath: excel文件物理路径 :return: 返回当前文件的数据 """ #print(xlspath) objlist = [] dfnonoe = pd.read_excel(io=xlspath, sheet_name='Sheet1', keep_default_na=False) dfnonoe1 = dfnonoe.dropna(axis=1) row1 = dfnonoe1.loc[0:0] #第一行 标题, 有规则的,就不需要这种处理方式 #print(row1['Unnamed: 2']) # 社保明细 #print(row1['Unnamed: 3']) # 1月缴纳明细(元) yl = row1['Unnamed: 2'] yll = yl.convert_dtypes() yc = row1['Unnamed: 3'] ycc = yc.convert_dtypes() mm = ReadExcelData.RemoveStr(ycc[0]) #提取月份数据 row2 = dfnonoe1.loc[1:1] #第二行 yl2 = row2['Unnamed: 2'] #养老 yll2 = yl2.convert_dtypes() yc2 = row2['Unnamed: 3'] #费用 ycc2 = yc2.convert_dtypes() row3 = dfnonoe1.loc[2:2] #第三行 yl3 = row3['Unnamed: 2'] #医疗 yll3 = yl3.convert_dtypes() yc3 = row3['Unnamed: 3'] #费用 ycc3 = yc3.convert_dtypes() objlist.append(Insurance.Insurance(yll2,ycc2,mm)) objlist.append(Insurance.Insurance(yll3,ycc3,mm)) return objlist def RemoveStr(oldstr): """ 去除指定的字符串 :param oldstr: 旧字符串 :return: 新字符串 """ newstr = re.sub(r'月缴纳明细(元)', "", oldstr) #月缴纳明细(元) return newstr def clearBlankLine(oldfile,newfile): """ 清除文件里面的空白行 :param oldfile: 旧文件 :param newfile: 新文件 :return: none """ file1 = open(oldfile, 'r', encoding='utf-8') # 要去掉空行的文件 file2 = open(newfile, 'w', encoding='utf-8') # 生成没有空行的文件 try: for line in file1.readlines(): if line == '\n': line = line.strip("\n") file2.write(line) finally: file1.close() file2.close() def excelcovert(): """ :return: """ app=xw.App(visible=False,add_book=False) folderPath=Path('C:\\Users\\geovindu\\PycharmProjects\\pythonProject\\') fileList=folderPath.glob('*.xls') for i in fileList: newFilePath=str(i.with_suffix('.xlsx')) workbook=app.books.open(i) workbook.api.SavaAs(newFilePath,FileFormat=56) workbook.close() app.quit() |
调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 | # This is a sample Python script.# Press Shift+F10 to execute it or replace it with your code.# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.import xlrdimport xlwtimport xlwings as xwimport xlsxwriterimport openpyxl as wsimport pandas as pdimport pandasqlimport osimport sysfrom pathlib import Pathimport reimport Insuranceimport ReadExcelDatadef print_hi(name): # Use a breakpoint in the code line below to debug your script. print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.# Press the green button in the gutter to run the script.if __name__ == '__main__': print_hi('PyCharm,Geovin Du') #https://www.digitalocean.com/community/tutorials/pandas-read_excel-reading-excel-file-in-python #https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.convert_dtypes.html #https://www.geeksforgeeks.org/args-kwargs-python/ insura=[] objlist=[] #excelcovert() s = '1123*#$ 中abc国' str = re.sub('[a-zA-Z0-9!#$%&\()*+,-./:;<=>?@,。?★、…【】《》?!^_`{|}~\s]+', "", s) # 去除不可见字符 str = re.sub('[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+',"", str) print(str) phone = "2004-959-559 # 这是一个电话号码" tt="1月缴纳明细(元)" newtt=re.sub(r'月缴纳明细(元)',"",tt) print(newtt) # 删除注释 num = re.sub(r'#.*$', "", phone) print("电话号码 : ", num) xlspath1 = r'C:\Users\geovindu\PycharmProjects\pythonProject\1月.xls' xlspath2 = r'C:\Users\geovindu\PycharmProjects\pythonProject\2月.xls' xlspath3 = r'C:\Users\geovindu\PycharmProjects\pythonProject\3月.xls' xlspath4 = r'C:\Users\geovindu\PycharmProjects\pythonProject\4月.xls' xlspath5 = r'C:\Users\geovindu\PycharmProjects\pythonProject\5月.xls' xlspath6 = r'C:\Users\geovindu\PycharmProjects\pythonProject\6月.xls' xlspath7 = r'C:\Users\geovindu\PycharmProjects\pythonProject\7月.xls' xlspath8 = r'C:\Users\geovindu\PycharmProjects\pythonProject\8月.xls' xlspath9 = r'C:\Users\geovindu\PycharmProjects\pythonProject\9月.xls' xlspath10 = r'C:\Users\geovindu\PycharmProjects\pythonProject\10月.xls' xlspath11 = r'C:\Users\geovindu\PycharmProjects\pythonProject\11月.xls' xlspath12 = r'C:\Users\geovindu\PycharmProjects\pythonProject\12月.xls' xlspath13 = r'C:\Users\geovindu\PycharmProjects\pythonProject\1月0.xls' xlspath14 = r'C:\Users\geovindu\PycharmProjects\pythonProject\2月0.xls' dfnew = pd.read_excel(r'C:\Users\geovindu\PycharmProjects\pythonProject\1月.xls') #dfnew = dfnew.drop(columns=[0, 1],axis=1) #dfnew.dropna(axis=0, how="all", inplace=True) # 删除excel空白行代码 #dfnew.dropna(axis=1, how="all", inplace=True) # 删除excel空白列代码 #dfnew.to_excel(r'C:\Users\geovindu\PycharmProjects\pythonProject\1月.xls', "1") #注:axis = 0 表示操作excel行,axis = 1 表示操作excel列 xls1 = pd.read_excel(io=xlspath1, sheet_name='Sheet1', index_col=(2, 3), skiprows=1,keep_default_na=False) # 从第2列至第3列,省略第一行 #xls1 = pd.read_excel(io=xlspath1, sheet_name='Sheet1') xls2 = pd.read_excel(io=xlspath2, sheet_name='Sheet1', index_col=(2, 3), skiprows=1,keep_default_na=False) # 从第2列至第3列,省略第一行 xls3 = pd.read_excel(io=xlspath13, sheet_name='Sheet1',keep_default_na=False) # 人工去除空行空列 xls4 = pd.read_excel(io=xlspath14, sheet_name='Sheet1',keep_default_na=False) # 人工去除空行空列 dulist=[] # 封装成类操作 dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath1) dulist2 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath2) dulist3 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath3) dulist4 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath4) dulist5 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath5) dulist6 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath6) dulist7 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath7) dulist8 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath8) dulist9 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath9) dulist10 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath10) dulist11 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath11) dulist12 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath12) #dulist.append(dulist2) for Insurance.Insurance in dulist1: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist2: duobj=Insurance.Insurance #print(duobj) dulist.append(duobj) for Insurance.Insurance in dulist3: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist4: duobj=Insurance.Insurance #print(duobj) dulist.append(duobj) for Insurance.Insurance in dulist5: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist6: duobj=Insurance.Insurance #print(duobj) dulist.append(duobj) for Insurance.Insurance in dulist7: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist8: duobj=Insurance.Insurance #print(duobj) dulist.append(duobj) for Insurance.Insurance in dulist9: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist10: duobj=Insurance.Insurance #print(duobj) dulist.append(duobj) for Insurance.Insurance in dulist11: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist12: duobj=Insurance.Insurance dulist.append(duobj) #print(duobj) for Insurance.Insurance in dulist: duobj = Insurance.Insurance print(duobj) print("geovindu,*************") ''' index_row = [] # loop each row in column A for i in range(1, ws.max_row): # define emptiness of cell if ws.cell(i, 1).value is None: # collect indexes of rows index_row.append(i) # loop each index value for row_del in range(len(index_row)): ws.delete_rows(idx=index_row[row_del], amount=1) # exclude offset of rows through each iteration index_row = list(map(lambda k: k - 1, index_row)) ''' #改列名 https://stackoverflow.com/questions/35369382/delete-empty-row-openpyxl #xls1.rename(columns={'Unnamed: 0': 'new column name'}, inplace=True) print(xls1) print("****") print(xls2) print(xls3) print(xls4) print(xls1.columns.ravel()) dfnonoe = pd.read_excel(io=xlspath1, sheet_name='Sheet1',keep_default_na=False) #dfnonoe1 = dfnonoe.loc[:, ~dfnonoe.columns.str.contains('^Unnamed')] #dfnonoe.rename(columns={'Unnamed: 3': '1月缴纳明细'}, inplace=True) dfnonoe1 = dfnonoe.dropna(axis=1) dfnonoe1.loc[2:2] print("none:",dfnonoe1) t=dfnonoe1.loc[0:0] #print(t) print(t['Unnamed: 2']) #社保明细 print(t['Unnamed: 3']) #1月缴纳明细(元) yy=t['Unnamed: 3'] print(yy) #.Replace('(元)','') #ynew='(元)'.join(filter(str.isalnum, yy)) #re.sub('[a-zA-Z0-9'!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘'![\\]^_`{|}~\s]+', "", yy) #ynew =re.sub('[a-zA-Z0-9'!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘'![\\]^_`{|}~\s]+',"",yy) #print(ynew) t1=dfnonoe1.loc[1:1] print(t1['Unnamed: 2']) #养老 yl=t1['Unnamed: 2'] yll=yl.convert_dtypes() print(yll) print(t1['Unnamed: 3']) #10 yc=t1['Unnamed: 3'] ycc=yc.convert_dtypes() print(type(yc)) t3=dfnonoe1.loc[2:2] print(t3['Unnamed: 2']) #医疗 ll=t3['Unnamed: 2'] lll=ll.convert_dtypes() print(lll) print(t3['Unnamed: 3']) #20 lc=t3['Unnamed: 3'] lcc=lc.convert_dtypes() print(lcc) f=t['Unnamed: 3'] print(type(f)) #pandas.core.series.Series print(f.convert_dtypes()) print(f[0]) print(ReadExcelData.ReadExcelData.RemoveStr(f[0])) ff=ReadExcelData.ReadExcelData.RemoveStr(f[0]) print(ff) #m=re.sub(r'月缴纳明细(元)',"",f) #ReadExcelData.RemoveStr(t['Unnamed: 3']) #objins = Insurance(yll,ycc,ff) insura.append([yll,ycc,ff]) insura.append([lll,lcc,ff]) for i in insura: print(i[0],i[1],i[2]) #print(objins) #Insurance.Insurance(yll,ycc,ff) #Insurance.Insurance(lll,lcc,ff) ''' objlist.append(Insurance.Insurance(yll,ycc,ff)) objlist.append(Insurance.Insurance(lll,lcc,ff)) for Insurance.Insurance in objlist: obj=Insurance.Insurance print(obj) ''' print("**************") df = pd.DataFrame() df1=pd.DataFrame() out = pd.concat([xls1,xls2]) out1=pd.concat([xls3,xls4]) df = pd.concat([df, out]) df1=pd.concat([df1,out1]) print(xls3['1月缴纳明细(元)']) sum=0; dl=xls3['1月缴纳明细(元)'] dl2=xls4['2月缴纳明细(元)'] for ddd in dl: sum=sum+ddd print(dl[0]) #0为养老 print(dl[1]) #1为医疗 print("sum:",sum) #df3 = df.dropna(axis=1, how='any', thresh=None, subset=None, inplace=False) # 删除全部为空的行 #df4 = df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) # 删除全部为空的行 # 设置子集:删除第5、6、7行存在空值的列 #print(df.dropna(axis=1, how='any', subset=[0, 1])) print(df1) print(df) print(df.shape) print(df.columns) print(df.index) print(df1) print(df1.shape) print(df1.columns) print(df1.index) print(df1.groupby(['社保明细']).sum()) print(df.groupby(['社保明细']).sum()) #df.name='社保明细' #df.loc[0] #df.loc[0:1] for i, j in df.iterrows(): print(i, j) print() for i in df.itertuples(): print(i) # 查询某文件夹下的文件名 folderPath=Path(r'C:\\Users\\geovindu\\PycharmProjects\\pythonProject\\') fileList=folderPath.glob('*.xls') for i in fileList: stname=i.stem print(stname) # 查询文件夹下的文件 print(os.path.join(path, "User/Desktop", "file.txt")) dufile=ReadExcelData.ReadExcelData.ReadFileName(folderPath,'xls') for f in dufile: print(os.path.join(folderPath,f))# See PyCharm help at https://www.jetbrains.com/help/pycharm/ |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 | # coding=utf-8import sysimport xlrdimport xlwtimport xlwings as xwimport xlsxwriterimport openpyxl as wsimport pandas as pdimport pandasqlimport osimport sysfrom pathlib import Pathimport reimport Insuranceimport ReadExcelDataif __name__ == '__main__': #https://www.digitalocean.com/community/tutorials/pandas-read_excel-reading-excel-file-in-python #https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.convert_dtypes.html #https://www.geeksforgeeks.org/args-kwargs-python/ insura=[] objlist=[] #excelcovert() s = '1123*#$ 中abc国' str = re.sub('[a-zA-Z0-9!#$%&\()*+,-./:;<=>?@,。?★、…【】《》?!^_`{|}~\s]+', "", s) # 去除不可见字符 str = re.sub('[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+',"", str) print(str) phone = "2004-959-559 # 这是一个电话号码" tt="1月缴纳明细(元)" newtt=re.sub(r'月缴纳明细(元)',"",tt) print(newtt) # 删除注释 num = re.sub(r'#.*$', "", phone) print("电话号码 : ", num) xlspath1 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\1月.xls' xlspath2 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\2月.xls' xlspath3 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\3月.xls' xlspath4 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\4月.xls' xlspath5 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\5月.xls' xlspath6 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\6月.xls' xlspath7 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\7月.xls' xlspath8 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\8月.xls' xlspath9 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\9月.xls' xlspath10 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\10月.xls' xlspath11 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\11月.xls' xlspath12 = r'C:\Users\geovindu\Documents\Visual Studio 2022\Projects\PythonAppReadExcel\12月.xls' dulist=[] # 封装成类操作 dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath1) dulist2 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath2) dulist3 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath3) dulist4 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath4) dulist5 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath5) dulist6 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath6) dulist7 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath7) dulist8 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath8) dulist9 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath9) dulist10 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath10) dulist11 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath11) dulist12 = ReadExcelData.ReadExcelData.ReadDataFile(xlspath12) ''' #dulist.append(dulist2) for Insurance.InsuranceMoney in dulist1: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist2: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist3: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist4: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist5: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist6: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist7: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist8: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist9: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist10: duobj=Insurance.InsuranceMoney #print(duobj) dulist.append(duobj) for Insurance.InsuranceMoney in dulist11: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist12: duobj=Insurance.InsuranceMoney dulist.append(duobj) #print(duobj) for Insurance.InsuranceMoney in dulist: duobj = Insurance.InsuranceMoney print(duobj) ''' print("geovindu,*************") # 查询某文件夹下的文件名 folderPath=Path(r'C:\\Users\\geovindu\\Documents\\Visual Studio 2022\\Projects\\PythonAppReadExcel\\') fileList=folderPath.glob('*.xls') for i in fileList: stname=i.stem print(stname) # 查询文件夹下的文件 print(os.path.join(path, "User/Desktop", "file.txt")) dufile=ReadExcelData.ReadExcelData.ReadFileName(folderPath,'xls') for f in dufile: fileurl=os.path.join(folderPath,f) dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(fileurl) # object is not callable 变量名称冲突的原因 for duobj in dulist1: dulist.append(duobj) print(os.path.join(folderPath,f)) for geovindu in dulist: #print(type(geovindu)) name= geovindu.getInsuranceName() print("保险类型:",name) coast=geovindu.getInsuranceCost() print("费用:",coast) month=geovindu.getIMonth() print("月份:",month) #Insurance.InsuranceMoney=geovindu |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | # 查询某文件夹下的文件名 folderPath=Path(r'C:\\Users\\geovindu\\Documents\\Visual Studio 2022\\Projects\\PythonAppReadExcel\\') fileList=folderPath.glob('*.xls') for i in fileList: stname=i.stem print(stname) # 查询文件夹下的文件 print(os.path.join(path, "User/Desktop", "file.txt")) dufile=ReadExcelData.ReadExcelData.ReadFileName(folderPath,'xls') for f in dufile: fileurl=os.path.join(folderPath,f) dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(fileurl) # object is not callable 变量名称冲突的原因 for duobj in dulist1: dulist.append(duobj) print(os.path.join(folderPath,f)) ylsum=0 # 养老 llsum=0 #医疗 totalsum=0 #一年费用 for geovindu in dulist: #print(type(geovindu)) name= geovindu.getInsuranceName() duname = name.convert_dtypes() #yname = duname['Unnamed: 2'] print(type(duname)) print("保险类型:",duname) #class 'pandas.core.series.Series strname=pd.Series(duname).values[0] coast=int(geovindu.getInsuranceCost()) totalsum=totalsum+coast if(strname=="养老"): ylsum=ylsum+coast if(strname=="医疗"): llsum=llsum+coast print("费用:",coast) month=geovindu.getIMonth() print("月份:",month) #Insurance.InsuranceMoney=geovindu print("一年养老",ylsum) print("一年医疗",llsum) print("一年费用",totalsum) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | print("**************end how are you,geovindu")ylsum = 0 # 养老llsum = 0 # 医疗totalsum = 0 # 一年费用datalist=[]for geovindu in dulist: #duobj = Insurance.Insurance print(geovindu) name = geovindu.getInsuranceName() duname = name.convert_dtypes() # yname = duname['Unnamed: 2'] print(type(duname)) print("保险类型:", duname) # class 'pandas.core.series.Series strname = pd.Series(duname).values[0] coast = int(geovindu.getInsuranceCost()) totalsum = totalsum + coast if (strname == "养老"): ylsum = ylsum + coast if (strname == "医疗"): llsum = llsum + coast print("费用:", coast) month = geovindu.getIMonth() print("月份:", month) datalist.append([strname,coast,month])print("一年养老",ylsum)print("一年医疗",llsum)print("一年费用",totalsum)#导出数据生成EXCELdataf = pd.DataFrame(datalist,columns=['保险类型','交费金额','交费月份'])dataf2=pd.DataFrame({"统计类型":["一年养老","一年医疗","一年费用"],"金额":[ylsum,llsum,totalsum]})with pd.ExcelWriter('geovindu.xlsx') as writer: dataf.to_excel(writer, sheet_name='2023年保险费用详情',index=False) dataf2.to_excel(writer, sheet_name='保险统计',index=False) |
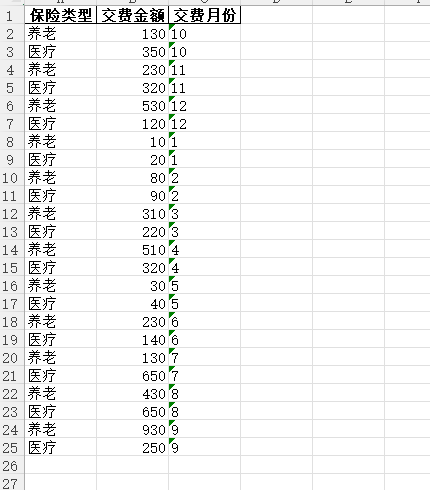
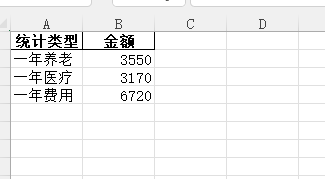
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | ylsum = 0 # 养老llsum = 0 # 医疗totalsum = 0 # 一年费用datalist=[]for geovindu in dulist: #duobj = Insurance.Insurance print(geovindu) name = geovindu.getInsuranceName() duname = name.convert_dtypes() # yname = duname['Unnamed: 2'] print(type(duname)) print("保险类型:", duname) # class 'pandas.core.series.Series strname = pd.Series(duname).values[0] coast = int(geovindu.getInsuranceCost()) totalsum = totalsum + coast if (strname == "养老"): ylsum = ylsum + coast if (strname == "医疗"): llsum = llsum + coast print("费用:", coast) month = int(geovindu.getIMonth()) print("月份:", month) datalist.append([strname,coast,month])print("一年养老",ylsum)print("一年医疗",llsum)print("一年费用",totalsum)#导出数据生成EXCELdataf = pd.DataFrame(datalist,columns=['保险类型','交费金额','交费月份']) #增加列名称dataf2=pd.DataFrame({"统计类型":["一年养老","一年医疗","一年费用"],"金额":[ylsum,llsum,totalsum]})dataf.sort_values('交费月份', inplace=True) #指定列排序with pd.ExcelWriter('geovindu.xlsx') as writer: dataf.to_excel(writer, sheet_name='2023年保险费用详情',index=False) dataf2.to_excel(writer, sheet_name='保险统计',index=False) |
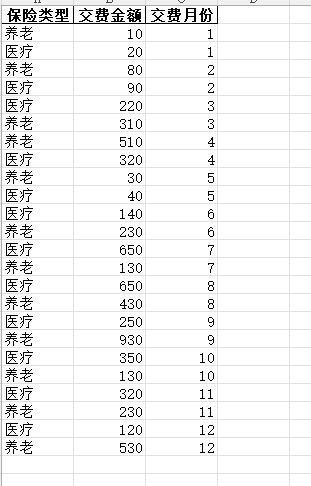
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | print("**************end how are you,geovindu")ylsum = 0 # 养老llsum = 0 # 医疗totalsum = 0 # 一年费用datalist=[]for geovindu in dulist: #duobj = Insurance.Insurance print(geovindu) name = geovindu.getInsuranceName() duname = name.convert_dtypes() # yname = duname['Unnamed: 2'] print(type(duname)) print("保险类型:", duname) # class 'pandas.core.series.Series strname = pd.Series(duname).values[0] coas1=geovindu.getInsuranceCost() #coast = int(geovindu.getInsuranceCost()) coas =coas1.convert_dtypes() coast=pd.Series(coas).values[0] #int(coas) #print("casa",int(coas)) totalsum = totalsum + coast if (strname == "养老"): ylsum = ylsum + coast if (strname == "医疗"): llsum = llsum + coast print("费用:", coast) month = int(geovindu.getIMonth()) print("月份:", month) datalist.append([strname,coast,month])print("一年养老",ylsum)print("一年医疗",llsum)print("一年费用",totalsum)#https: // pandas.pydata.org / pandas - docs / stable / reference / api / pandas.DataFrame.groupby.html#导出数据生成EXCELdataf = pd.DataFrame(datalist,columns=['保险类型','交费金额','交费月份']) #增加列名称dataf2=pd.DataFrame({"统计类型":["一年养老","一年医疗","一年费用"],"金额":[ylsum,llsum,totalsum]})dataf.sort_values('交费月份', inplace=True) #指定列排序#duda=dataf.groupby(by=["保险类型"], dropna=False).sum()#print(duda)#https://www.datacamp.com/tutorial/how-to-use-sql-in-pandas-using-pandasql-queries#sdf = dataf.sqldf("select '保险类型','交费金额','交费月份' from dataf")#sdf.head()#print(sdf)#交费用分份统计print(sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份LIMIT 25'''))staicmont=sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份LIMIT 25''')with pd.ExcelWriter('geovindu.xlsx') as writer: dataf.to_excel(writer, sheet_name='2023年保险费用详情',index=False) dataf2.to_excel(writer, sheet_name='保险统计',index=False) staicmont.to_excel(writer, sheet_name='月份统计', index=False) |

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | """pythonAppReadExcel.pyIDE: Visual Studio 2022 editedit:geovindu, Geovin Dudate: 20230614"""import xlrdimport xlwtimport xlwings as xwimport xlsxwriterimport openpyxl as wsimport pandas as pdfrom pandasql import sqldfimport pandasqlimport osimport sysfrom pathlib import Pathimport reimport pysparkfrom pyspark.sql.functions import exprfrom pyspark.sql import Rowfrom pyspark.sql import SparkSessionimport Insuranceimport ReadExcelDataif __name__ == '__main__': print("hi,geovindu,Geovin Du,涂聚文") spark = SparkSession.builder.getOrCreate() insura=[] objlist=[] dulist=[] # 查询某文件夹下的文件名 folderPath=Path(r'C:\\Users\\geovindu\\PycharmProjects\\pythonProject\\') fileList=folderPath.glob('*.xls') for i in fileList: stname=i.stem #print(stname) # 查询文件夹下的文件 print(os.path.join(path, "User/Desktop", "file.txt")) dufile=ReadExcelData.ReadExcelData.ReadFileName(folderPath,'xls') for f in dufile: #fileurl = os.path.join(folderPath, f) #print(r''+f) ReadExcelData.ReadExcelData.ReadDataFile(f) dulist1 = ReadExcelData.ReadExcelData.ReadDataFile(f) for duobj in dulist1: #duobj = Insurance.Insurance dulist.append(duobj) print("**************end how are you,geovindu") ylsum = 0 # 养老 llsum = 0 # 医疗 totalsum = 0 # 一年费用 datalist=[] for geovindu in dulist: #duobj = Insurance.Insurance #print(geovindu) name = geovindu.getInsuranceName() duname = name.convert_dtypes() # yname = duname['Unnamed: 2'] #print(type(duname)) #print("保险类型:", duname) # class 'pandas.core.series.Series strname = pd.Series(duname).values[0] coas1=geovindu.getInsuranceCost() #coast = int(geovindu.getInsuranceCost()) coas =coas1.convert_dtypes() coast=pd.Series(coas).values[0] #int(coas) #print("casa",int(coas)) totalsum = totalsum + coast if (strname == "养老"): ylsum = ylsum + coast if (strname == "医疗"): llsum = llsum + coast #print("费用:", coast) month = int(geovindu.getIMonth()) #print("月份:", month) datalist.append([strname,coast,month]) print("一年养老",ylsum) print("一年医疗",llsum) print("一年费用",totalsum) #https: // pandas.pydata.org / pandas - docs / stable / reference / api / pandas.DataFrame.groupby.html #导出数据生成EXCEL dataf = pd.DataFrame(datalist,columns=['保险类型','交费金额','交费月份']) #增加列名称 dataf2=pd.DataFrame({"统计类型":["一年养老","一年医疗","一年费用"],"金额":[ylsum,llsum,totalsum]}) dataf.sort_values('交费月份', inplace=True) #指定列排序 #pySpark # https://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html geovindudf = spark.createDataFrame(dataf) # #geovindudf.show() geovindudf.printSchema() geovindudf.createOrReplaceTempView("GeovinDu") #spark.sql("SELECT * from GeovinDu").show() #有异常 #spark.read.csv('foo.csv', header=True).show() #query_df = pyspark.SQLContext(f"SELECT * FROM dataf") #duda=dataf.groupby(by=["保险类型"], dropna=False).sum() #print(duda) #https://www.datacamp.com/tutorial/how-to-use-sql-in-pandas-using-pandasql-queries #交费用分份统计 #print(sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''')) staicmonth=sqldf('''SELECT 交费金额,交费月份 FROM dataf group by 交费月份 LIMIT 25''') with pd.ExcelWriter('geovindu.xlsx') as writer: dataf.to_excel(writer, sheet_name='2023年保险费用详情',index=False) dataf2.to_excel(writer, sheet_name='保险统计',index=False) staicmonth.to_excel(writer, sheet_name='月份统计', index=False) |
哲学管理(学)人生, 文学艺术生活, 自动(计算机学)物理(学)工作, 生物(学)化学逆境, 历史(学)测绘(学)时间, 经济(学)数学金钱(理财), 心理(学)医学情绪, 诗词美容情感, 美学建筑(学)家园, 解构建构(分析)整合学习, 智商情商(IQ、EQ)运筹(学)生存.---Geovin Du(涂聚文)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2019-06-13 MIME Types
2007-06-13 查询ID第五条至第十五条记录(SQL server2000)