Person Re-ID行人重试别梳理
1. 概念
Re-ID(行人重试别, 跨境追踪)是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。给定一张切好块的行人图像 (query image,), 从一大堆切好块的图像 (gallery images) 中找到同一身份的人的图像的过程。这些图像通常是由不同摄像头拍摄的不连续帧。
- ReID与人脸识别有什么联系和区别?
联系:都是多媒体内容检索,从方法论来说是通用的;
区别:但是ReID相比行人更有挑战,跨摄像头场景下复杂姿态,严重遮挡,多变的光照条件等等。
2. 简要介绍
- 两方面入手:
- 度量学习,设计损失函数,用多张图像的label来约束它们特征之间的关系,使学到的特征尽量类内间隔短,类间间隔大。
- 表征学习,设计网络来学习不同场景下都general的visual feature,用query-gallery的特征相关性来作为ranking的依据,一般直接Softmax分类。
- 主要技术方案
3. 损失函数
1. ID_loss
本质是[Cross Entropy Loss]
2. Triplet_loss
一个输入的三元组(Triplet)包括一对正样本对和一对负样本对。三张图片分别命名为固定图片(Anchor) a ,正样本图片(Positive)p和负样本图片(Negative) n 。图片 a 和图片 p 为一对正样本对,图片 a 和图片 n 为一对负样本对。则三元组损失表示为:

3. 边界挖掘损失

3. 其他
难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss), 四元组损失(Quadruplet loss),对比损失(Contrastive loss)...
4. 评价指标
4.1 mAP
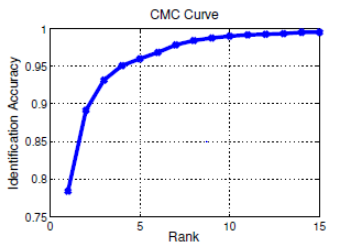
4.2 累计匹配曲线(cumulative matching characteristics ,CMC)
ReID 终归还是排序问题,Rank-k 是排序命中率核心指标。Rank1 是首位命中率,就是排在第一位的图有没有命中他本人,Rank5 是 1-5 张图没有一张命中他本人。
Rank-k计算方式:
def Calculate_Acc_k(query_result_of_img_i):
Acc_k = 0
if (query_result_of_img_i[:k].any()):
Acc_k = 1
return Acc_k
rank_k = mean(Acc_k(query_result_of_img_i)
for query_result_of_img_i in qury_list)
4. 数据集情况

5. 重点介绍及Idea
5.1 先验知识
5.1.1 基于属性
论文地址:Improving Person Re-identification by Attribute and Identity Learning
5.1.2 基于骨架关键点
对于输入的一张行人图片,有一个预训练好的骨架关键点提取CNN(蓝色表示)来获得14个人体关键点,从而得到7个ROI区域,其中包括三个大区域(头、上身、下身)和四个四肢小区域。
5.2 对齐
类似人脸识别, 考虑根据先验知识, 把不同姿态的人体部件进行对齐.
5.2.1 基于骨架对齐
先用姿态估计的模型估计出行人的关键点,然后用仿射变换使得相同的关键点对齐。如下图所示,一个行人通常被分为14个关键点,这14个关键点把人体结果分为若干个区域。为了提取不同尺度上的局部特征,作者设定了三个不同的PoseBox组合。之后这三个PoseBox矫正后的图片和原始为矫正的图片一起送到网络里去提取特征,这个特征包含了全局信息和局部信息。

论文链接:Pose Invariant Embedding for Deep Person Re-identification
5.2.2 最短路径自动对齐
首次准确率超过人工实现了自动对齐,首次超越人工识别.
- 特点1:动态规划
为了解决两幅图像之间的 Part对齐问题,分别提取局部特征和全局特征,通过N*N的距离矩阵描述最短路径即是两幅图像最佳的Local 匹配。

5.3 注意力
5.3.1 硬分割/软分割
(1) 沿用均匀分块的 Part-based Convolutional Baseline(PCB)(硬划分,简单粗暴,但对齐不准确)
- 对输入384128行人图提取深度特征(ResNet50),把最后一个block( averagepooling前)的下采样层丢弃掉,得到空间大小 248的 tensor T
- 按照水平方向分成均匀分成6parts,即6个空间大小 4*8 tensor,然后各自进行 average pooling,得到6个column vectors g
- 使用1*1卷积对g降维通道数,然后接6个FC层(权值不共享),Softmax进行分类
- 训练时等于有 6个cross-entropy loss;测试时则将 6个 vectors h 合并在一起,再算相似度
(2) 提出了基于 parts 的 Refined part pooling(RPP),用注意力机制来对齐 parts.
- 属于软注意力模型,利用部件之间的一致性,训练一个像素级别的分类器即分割;
- 目标是把6 parts 对应的空间分布进行软权值分配,进而对齐parts(PCB中均匀分割6parts 的过程,其实可看成人为地 hard attention,只把当前part空间权值设为1,其他parts都为0)
5.3.2 注意力
SenseTime的论文,基于caffe,将多层注意力机制图多向映射到不同的特征层。。HP-net包含两部分,M-Net和AF-Net。 >>>此处有中文注解
- Main Net(M-Net):
单纯的CNN结构,论文的实现是基于inception_v2,包含三个inception block,还包含几个低层卷积层; - Attentive Feature Net(AF-Net):三个分支,每个分支有三个inception_v2 block和一个MDA
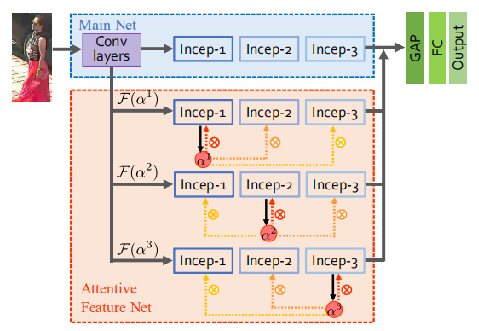
AF-Net包含三个子网络分支,并使用MDA模块增强,即F(αi)F(αi),其中αiαi是由inception块输出特征生成的注意力图,图中使用黑实线标记。随后应用到kth块的输出,图中用虚红线标示。每个MDA模块,有一条注意力生成链接,三条注意力特征构造链接。不同的MDA模块,注意力图由不同的inception模块生成,之后乘到不同层的特征图,生成不同层在注意特征。 MDA模块的一个示例如下图所示:
以下是可视化特征:
结果:
行人属性:
Re-ID:
论文链接:HydraPlus-Net (Hydraplus-net: Attentive deep features for pedestrian analysis)(ICCV-2017)
5.4 多种方法综合
5.4.1 EANet (地平线)
-
特点1:部件对齐池化(PAP: Part Aligned Pooling)
其实就是根据骨架关键点先验知识,在feature map上进行纵向划分;
-
特点2:部件分割约束(PS Constraint)
发现meature map特征冗余性很强,所以添加一个正则约束,也就是和预训练的不见分割器所产生的部件伪标签对比,增加Conv5后meature map特征的空间区分性,减少相关度.

5.4.2 Bag of Tricks and A Strong Baseline for Deep Person Re-identification(旷视)
Tricks:
- 1. Warmup Learning
- 2. Random Erasing Augmentation
- 3. Label Smoothing
- 4.Last Stride
最后一层conv的stride=1 - 5. BNNeck
"使得triplet loss能够在自由的欧式空间里约束feature;
ID loss可以在一个超球面附近约束feature" - 6. Center Loss
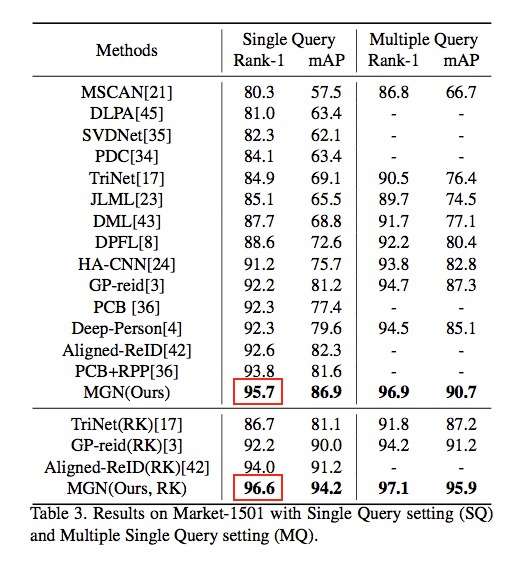
5.4.3 MGN(云从)
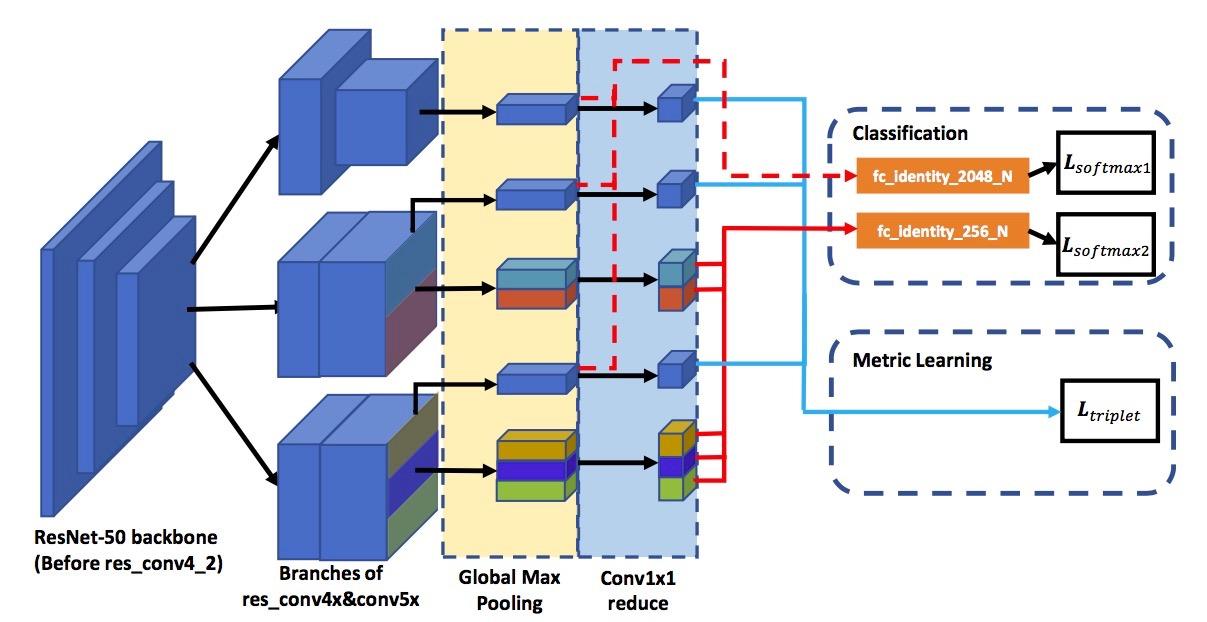
使用Resnet50前三层提取图像的基础特征,而在高层次的语意级特征作者设计了3个独立分支。如图所示,第一个分支负责整张图片的全局信息提取,第二个分支会将图片分为上下两个部分提取中粒度的语意信息,第三个分支会将图片分为上中下三个部分提取更细粒度的信息。这三个分支既有合作又有分工,前三个低层权重共享,后面的高级层权重独立,这样就能够像人类认知事物的原理一样即可以看到行人的整体信息与又可以兼顾到多粒度的局部信息。
6. 待解决的问题
- dataset
- domain adaption

 浙公网安备 33010602011771号
浙公网安备 33010602011771号