Python、Excel、MySQL 基于数据分层,打标签
pandas.cut()
用来将数据划分为不同的区间
x:array型数据 DataFrame每列数据都是array型数据
bins:传入int型数据,表示划分的区间个数,传入list型数据,表示自定义的区间
labels: 与bins对应区间的标签(默认为None)
retbins:True表示返回划分的区间,False表示不返回划分的区间(默认为False)
right:True表示左开右闭,False表示左闭右开(默认为True)
返回数据:
x对应所在的区间,array类型
retbins为True时,还会返回划分区间
excel
=LOOKUP(I:I,
{0,50,100,500,1000,2000,5000,10000,15000},
{"[0, 50)","[50, 100)","[100, 500)","[500, 1000)","[1000, 2000)","[2000, 5000)","[5000, 10000)","[10000, 15000)"}
)
法二: if函数逐层嵌套
对于参数,可以提前构造分级表,如下:
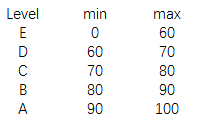
构造数据
=RANDBETWEEN(0, 100)
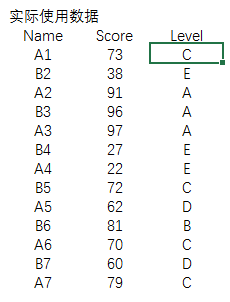
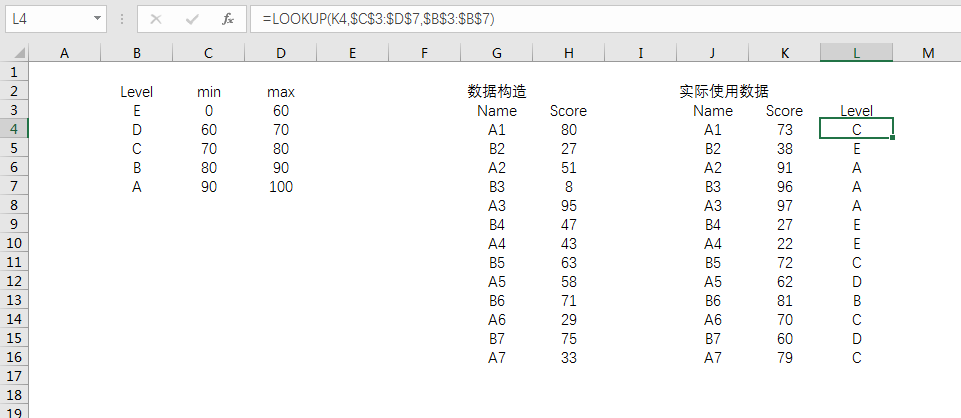
MySQL
法一:
CASE
WHEN cost>=0 and cost<50 THEN "[0, 50)"
WHEN cost>=50 and cost<100 THEN "[50, 100)"
...
ELSE "[10000, 15000)"
END material_flag_off,
法二:
-- 偶然所得,未尝试
SELECT
elt(
INTERVAL (days, 1, 3, 5, 7, 10),
"1-3",
"3-5",
"5-7",
"7-10",
"10+"
) AS region,
count(*)
FROM
tour_group
GROUP BY
region;
法三:
笛卡尔积
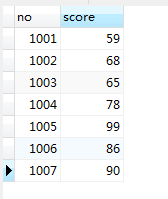
SCORE表:
GRADE:
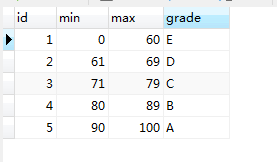
SELECT
s.`no`,
s.score,
g.grade
FROM
score s
LEFT JOIN grade g ON 1 = 1
WHERE
s.score >= g.min
AND s.score <= g.max


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!