01_自然语言处理的基本过程
课程大纲
-
获取语料
-
预处理
-
特征工程
-
模型介绍
-
评测标准
-
项目介绍
01 获取语料
数据集
-
语料是NLP的生命之源
- 所有的NLP问题都是从语料中学到数据分布的规律
-
语料的分类
-
单语料
-
平行语料
-
复杂结构
-
| 类型 | 说明 | 例子 |
|---|---|---|
| 单语料 | 只有句子和句子集合 | 整理好的英文文档,中文古诗数据集 |
| 平行语料 | 有句子和句子之间的1 vs 1 对应关系 | 中英文翻译数据集,对话数据集 |
| 其它 | 复杂的结构 | 知乎的回答和评论数据 |
数据集与语料
概述
-
英文语言模型语料总结
-
语料例子
-
Penn Treebank(PTB)
-
Daily Dialog
-
WMT-1x翻译数据集
-
中文闲聊数据集
-
中国古诗数据集
-
-
获取方法
- 公开数据集
- 爬虫
- 社交工具埋点
- 数据库
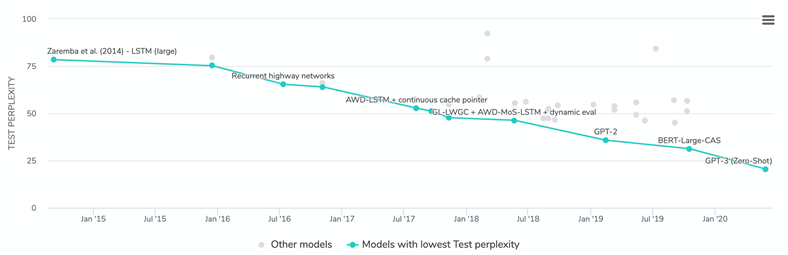
Penn Treebank
NLP中常用的PTB语料库,全名Penn Treebank。
Penn Treebank是一个项目的名称,项目目的是对语料进行标注,标注内容包括词性标注以及句法分析。语料来源为:1989年华尔街日报
语料规模:1M words,2499篇文章
语料价格:1500 ~ 1700$Penn Treebank委托Linguistic Data Consortium (LDC) 发行与收费,这意味着你想下载PTB就要去LDC的网站上下载(https://www.ldc.upenn.edu/)。
PTB有两个发行版,对应的LDC的编号分别为LDC95T7与LDC99742,在LDC中的名称为Treebank-2与Treebank-3。
这两个版本的语料内容是一样的,除了发行时间不清楚还有啥区别……
-
数据集地址:Pytorch集成的数据集DataLoader:https://pytorchnlp.readthedocs.io/en/latest/_modules/torchnlp/datasets/penn_treebank.html
-
Benchmark (学术界公认的实验结果)结果:https://paperswithcode.com/sota/language-modelling-on-penn-treebank-word
例句
no price for the new shares has been set instead the companies will leave it up to the marketplace to decide cray computer has applied to trade on nasdaq
Daily Dialog
- 英文对话经典bench mark数据集
- Paper:https://arxiv.org/abs/1710.03957
- 数据集地址:http://yanran.li/dailydialog.html
WMT-1x翻译数据集
平行语料
File |
Size | CS-EN | DE-EN | ET-EN | FI-EN | KK-EN | RU-EN | TR-EN | ZH-EN | Notes |
| Europarl v7 | 628MB | ✓ | ✓ | same as previous year, corpus home page | ||||||
| Europarl v8 | 235MB | ✓ | ✓ | et-en is new for this year, corpus home page | ||||||
| ParaCrawl corpus | 2.8GB | ✓ | ✓ | ✓ | ✓ | ✓ | New for 2018 Please use the filtered version. | |||
| Common Crawl corpus | 876MB | ✓ | ✓ | ✓ | Same as last year | |||||
| News Commentary v13 | 111M | ✓ | ✓ | ✓ | ✓ | updated | ||||
| CzEng 1.6 | 3.1GB | ✓ | Register and download CzEng 1.6. Better results can be obtained by using a subset of sentences, released under a new version name CzEng 1.7. | |||||||
| Yandex Corpus | 121MB | ✓ | ru-en | |||||||
| Wiki Headlines | 9.1MB | ✓ | ✓ | Provided by CMU.. | ||||||
| SETIMES2 | 44 MB | ✓ | Distributed by OPUS | |||||||
| UN Parallel Corpus V1.0 | 3.6 GB | ✓ | ✓ | Register and download | ||||||
| Rapid corpus of EU press releases | 156 MB | ✓ | ✓ | ✓ | Prepared by Tilde | |||||
| CWMT Corpus | ✓ |
测试集
| Year | CS-EN | DE-EN | ET-EN | FI-EN | KK-EN | RU-EN | TR-EN | ZH-EN |
|---|---|---|---|---|---|---|---|---|
| 2008 | ✓ | ✓ | ||||||
| 2009 | ✓ | ✓ | ||||||
| 2010 | ✓ | ✓ | ||||||
| 2011 | ✓ | ✓ | ||||||
| 2012 | ✓ | ✓ | ✓ | |||||
| 2013 | ✓ | ✓ | ✓ | |||||
| 2014 | ✓ | ✓ | ✓ | |||||
| 2015 | ✓ | ✓ | ✓ | ✓ | ||||
| 2016 | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 2017 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
中文闲聊数据集
示例
谢谢你所做的一切
你开心就好
开心
嗯因为你的心里只有学习
某某某,还有你
这个某某某用的好
你们宿舍都是这么厉害的人吗
眼睛特别搞笑这土也不好捏但就是觉得挺可爱
特别可爱啊
今天好点了吗?
一天比一天严重
吃药不管用,去打一针。别拖着
中国古诗数据集
示例
shijing
[
{
"title": "关雎",
"chapter": "国风",
"section": "周南",
"content": [
"关关雎鸠,在河之洲。窈窕淑女,君子好逑。",
"参差荇菜,左右流之。窈窕淑女,寤寐求之。",
"求之不得,寤寐思服。悠哉悠哉,辗转反侧。",
"参差荇菜,左右采之。窈窕淑女,琴瑟友之。",
"参差荇菜,左右芼之。窈窕淑女,钟鼓乐之。"
]
}
]
02 预料预处理
NLTK
- https://www.nltk.org/
- 基本的英文NLP操作均支持
官网介绍如下:
## Natural Language Toolkit
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to [over 50 corpora and lexical resources](https://www.nltk.org/nltk_data/) such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active [discussion forum](https://groups.google.com/group/nltk-users).
Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike. NLTK is available for Windows, Mac OS X, and Linux. Best of all, NLTK is a free, open source, community-driven project.
NLTK has been called “a wonderful tool for teaching, and working in, computational linguistics using Python,” and “an amazing library to play with natural language.”
[Natural Language Processing with Python](https://www.nltk.org/book) provides a practical introduction to programming for language processing. Written by the creators of NLTK, it guides the reader through the fundamentals of writing Python programs, working with corpora, categorizing text, analyzing linguistic structure, and more. The online version of the book has been been updated for Python 3 and NLTK 3. (The original Python 2 version is still available at [https://www.nltk.org/book_1ed](https://www.nltk.org/book_1ed).)
NLTK 是构建 Python 程序以处理人类语言数据的领先平台。它为超过 50 个语料库和词汇资源(如 WordNet)提供易于使用的接口,以及一套用于分类、标记化、词干提取、标记、解析和语义推理的文本处理库,工业强度 NLP 库的包装器,和一个活跃的讨论论坛。
由于介绍了编程基础知识和计算语言学主题的动手指南,加上全面的 API 文档,NLTK 适合语言学家、工程师、学生、教育工作者、研究人员和行业用户等。NLTK 可用于 Windows、Mac OS X 和 Linux。最重要的是,NLTK 是一个免费、开源、社区驱动的项目。
NLTK 被称为“使用 Python 进行计算语言学教学和工作的绝佳工具”和“一个使用自然语言的惊人库”。
使用 Python 进行自然语言处理提供了对语言处理编程的实用介绍。由 NLTK 的创建者撰写,它引导读者了解编写 Python 程序、使用语料库、文本分类、分析语言结构等的基础知识。本书的在线版本已针对 Python 3 和 NLTK 3 进行了更新。(原始 Python 2 版本仍可从https://www.nltk.org/book_1ed 获得。)
Tokenize
import nltk
sen = """At eeight o'clock on Thursday morning Arthur didn't feel very good."""
tokens = nltk.word_tokenize(sen)
print(1, tokens)
tagged = nltk.pos_tag(tokens)
print(2, tagged)
# 1 ['At', 'eeight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
# 2 [('At', 'IN'), ('eeight', 'JJ'), ("o'clock", 'NN'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'), ('Arthur', 'NNP'), ('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'), ('very', 'RB'), ('good', 'JJ'), ('.', '.')]
命名实体识别
entities = nltk.chunk.ne_chunk(tagged)
print(3, entities)
# 3 (S
# At/IN
# eeight/JJ
# o'clock/NN
# on/IN
# Thursday/NNP
# morning/NN
# (PERSON Arthur/NNP)
# did/VBD
# n't/RB
# feel/VB
# very/RB
# good/JJ
# ./.)
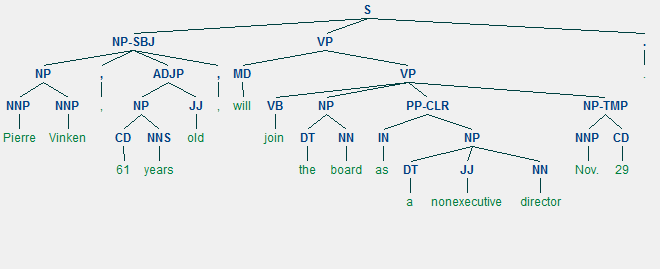
句法树构造
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()
Jieba分词
# encoding=utf-8
import jieba
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:
seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式
print("Paddle Mode: " + '/'.join(list(seg_list)))
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
SnowNLP
-
Pip install snownlp
from snownlp import SnowNLP
s = SnowNLP(u'这个东西真心很赞')
print(s.words)
# ['这个', '东西', '真心', '很', '赞']
print(list(s.tags) )
# [('这个', 'r'), ('东西', 'n'), ('真心', 'd'), ('很', 'd'), ('赞', 'Vg')]
print(s.sentiments)
# 0.9769551298267365
print(s.pinyin)
# ['zhe', 'ge', 'dong', 'xi', 'zhen', 'xin', 'hen', 'zan']
s = SnowNLP(u'「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
print(s.han)
# 「繁体字」「繁体中文」的叫法在台湾亦很常见。
text = u'''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
'''
s = SnowNLP(text)
print(s.keywords(3))
# ['语言', '自然', '计算机']
print(s.summary(3))
# ['因而它是计算机科学的一部分', '自然语言处理是计算机科学领域与人工智能领域中的一个重要方向', '自然语言处理是一门融语言学、计算机科学、数学于一体的科学']
print(s.sentences)
# ['自然语言处理是计算机科学领域与人工智能领域中的一个重要方向', '它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法', '自然语言处理是一门融语言学
# 、计算机科学、数学于一体的科学', '因此', '这一领域的研究将涉及自然语言', '即人们日常使用的语言', '所以它与语言学的研究有着密切的联系', '但又有重要的区别', '自
# 然语言处理并不是一般地研究自然语言', '而在于研制能有效地实现自然语言通信的计算机系统', '特别是其中的软件系统', '因而它是计算机科学的一部分']
s = SnowNLP([[u'这篇', u'文章'],
[u'那篇', u'论文'],
[u'这个']])
print(s.tf)
# [{'这篇': 1, '文章': 1}, {'那篇': 1, '论文': 1}, {'这个': 1}]
print(s.idf)
# {'这篇': 0.5108256237659907, '文章': 0.5108256237659907, '那篇': 0.5108256237659907, '论文': 0.5108256237659907, '这个': 0.5108256237659907}
print(s.sim([u'文章']))
# [0.4686473612532025, 0, 0]
Pyrouge
- 评测文本摘要好坏开源库
Exception has occurred: NoSectionError
No section: 'pyrouge settings'
常用python-based机器学习框架
- Pytorch
- Tensorflow
- Keras

Sklearn
https://scikit-learn.org/stable/
机器学习和数据处理辅助神器
Gensim
知乎教程:https://zhuanlan.zhihu.com/p/37175253
关键技能:
- Tf-Idf
- LSA
- LDA
- Word2vec
从语料构建词典
from gensim import corpora
texts = [['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
print(corpus[0])
# [(0, 1), (1, 1), (2, 1)]
03 特征工程
简单的特征工程
- Numpy https://numpy.org/
- Tf-Idf
- Word2vec
TF-IDF
-
Term Frequency
The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs.
-
高频词往往能够反馈文章的主要思想
购买、折扣、优惠 ---> 广告、电商等
恐怖主义、叙利亚、斩首 ---> 国际政治
威尼斯、圣托里尼、极光、洲际酒店 ---> 旅游
-
-
Inverse Document Frequency
很多无实际意义的虚词词频也很高
的、是、好 ---> 无实际意义的虚词,几乎所有文章都存在
一个直观结论:词频高但是文档频率低的词往往能反馈文档的主题
tf, idf, tf-idf 计算
Variants of term frequency (tf) weight
| weighting scheme | tf weight <\div> |
|---|---|
| binary | \(0,1\) |
| raw count | \(f_{t,d}\) |
| term frequency | \(\Large \frac{{{f_{t,d}}}}{{\sum\limits_{t' \in d} {{f_{t',d}}} }}\) |
| log normalization | \(log \space (1+f_{t,d})\) |
| double normalization 0.5 | \(\Large 0.5+0.5·\frac{{{f_{t,d}}}}{{max_{\{t' \in d\}} \space{{f_{t',d}}} }}\) |
| double normalization K | \(\Large K+(1-K)·\frac{{{f_{t,d}}}}{{max_{\{t' \in d\} } \space{{f_{t',d}}} }}\) |
Variants of inverse document frequency (idf) weight
| weighting scheme | idf weight(\(n_t=|\{d \in D: \space t \in d\}|\)) <\div> |
|---|---|
| unary | $1 $ |
| inverse document frequency | \(\large log \space \frac {N} {n_t}\space=\space -log \space \frac {n_t} {N}\) |
| inverse document frequency smooth | \(\large log \space (\frac {N} {1+n_t})\space+1\) |
| inverse document frequency max | \(\large log\space(\frac {{max_{\{t' \in d\}} ·n_{t'}}} {1+n_t})\) |
| probabilistic inverse document frequency | \(\large log \frac {N-n_t} {n_t}\) |
Recommended tf-idf weighting schemes
| weighting scheme | document term weight <\div> |
query term weight <\div> |
|---|---|---|
| 1 | \(\large f_{t,d}·log \space \frac {N} {n_t}\) | \(\large (0.5+0.5 \frac {f_{t,q}} {{max_t} \space f_{t,q}} )·log \frac {N} {n_t}\) |
| 2 | \(\large 1+log \space f_{t,d}\) | \(\large log \space (1+\frac {N} {n_t})\) |
| 3 | \(\large (1+log \space f_{t,d})·log \space\frac {N} {n_t}\) | \(\large (1+log \space f_{t,d})·log \space\frac {N} {n_t}\) |
词云制作
import jieba.analyse as analyse
from PIL import Image
import numpy as np
from wordcloud import WordCloud
f_c = """
元宇宙(Metaverse)是整合了多种新技术而产生的新型虚实相融的互联网应用和社会形态,通过利用科技手段进行链接与创造的,
与现实世界映射与交互的虚拟世界,具备新型社会体系的数字生活空间。
元宇宙本质上是对现实世界的虚拟化、数字化过程,需要对内容生产、经济系统、用户体验以及实体世界内容等进行大量改造。
但元宇宙的发展是循序渐进的,是在共享的基础设施、标准及协议的支撑下,由众多工具、平台不断融合、进化而最终成形。
它基于扩展现实技术提供沉浸式体验,基于数字孪生技术生成现实世界的镜像,基于区块链技术搭建经济体系,
将虚拟世界与现实世界在经济系统、社交系统、身份系统上密切融合,并且允许每个用户进行内容生产和世界编辑。
元宇宙一词诞生于1992年的科幻小说《雪崩》,小说描绘了一个庞大的虚拟现实世界,在这里,人们用数字化身来控制,
并相互竞争以提高自己的地位,到现在看来,描述的还是超前的未来世界。 关于“元宇宙”,
比较认可的思想源头是美国数学家和计算机专家弗诺·文奇教授,在其1981年出版的小说《真名实姓》中,
创造性地构思了一个通过脑机接口进入并获得感官体验的虚拟世界。.8万个贫困村全部出列,区域性整体贫困得到解决,
完成了消除绝对贫困的艰巨任务,困扰中华民族几千年的绝对贫困问题得到历史性解决!
"""
print(analyse.extract_tags(f_c,
topK=10,
withWeight=False,
allowPOS=()))
# ['宇宙', '世界', '虚拟世界', '现实', '贫困', '体验', '基于', '系统', '技术', '数字化']
alice_mask = np.array(Image.open("ditu.jpg"))
wordcloud=WordCloud(background_color="white", # 设置背景颜色,与图片的背景色相关
max_words=200, # 设置最大显示的字数
font_path='C:\Windows\Fonts\STZHONGS.TTF', # 显示中文,可以更换字体
mask=alice_mask # 设置背景图片
)
wordcloud.generate(f_c)
wordcloud.to_file("ditu_g.jpg")

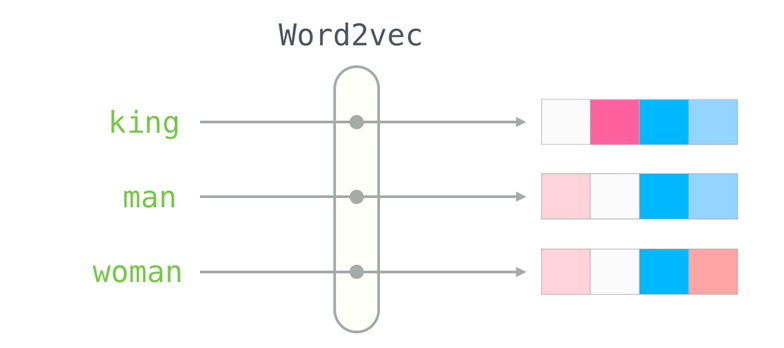
Word2Vec
使用一个欧式空间向量表示词汇
模型介绍
- 朴素贝叶斯
- 线性回归模型
- 逻辑回归
- CNN
- LSTM
- Transformer
- Sequence to Sequence

