python | 爬虫笔记(五)- 数据存储
5.1 文件存储
先用request把源码获取,再用解析库解析,保存到文本
1- txt
文本打开方式:
![]()
![]()
![]()
file = open('explore.txt', 'a', encoding='utf-8') #a代表以追加的方式写入文本 file.write('\n'.join([question, author, answer])) file.write('\n' + '=' * 50 + '\n') file.close()
r 只读
rb 二进制只读
r+ 读写
rb+ 二进制读写
w 只用于写入
wb 二进制写入
w+ 读写,存在覆盖,不存在新建
a 追加
a+ 追加读写
2- Json
JavaScript 对象标记,通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,它是一种轻量级的数据交换格式。一切皆对象,常用的是对象和数组
对象 数据结构为 {key1:value1, key2:value2, ...} 的键值对结构
数组 数据结构为 ["java", "javascript", "vb", ...] 的索引结构
· 一个Json对象
[{ "name": "Bob", "gender": "male", "birthday": "1992-10-18" }, { "name": "Selina", "gender": "female", "birthday": "1995-10-18" }]
· 读取Json
loads() 方法将 Json 文本字符串转为 Json 对象,可以通过 dumps()方法将 Json 对象转为文本字符串。
data = json.loads(str) print(data) 读取json文件 with open('data.json', 'r') as file: str = file.read() data = json.loads(str) print(data)
· 输出Json
3- CSV
写入
import csv with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id', 'name', 'age']) writer.writerows([['10001', 'Mike', 20], ['10002', 'Bob', 22], ['10003', 'Jordan', 21]])
读取
import pandas as pd df = pd.read_csv('data.csv') print(df)
5.2 关系型数据库
rdb- 二维表存储;可通过主键外键关联
1- MySQL存储
pymysql
内容包括:连接数据库、创建表、插入数据、删除、查询
一般流程:
import pymysql db = pymysql.connect(host='localhost',user='root', password='123456', port=3306) #connect()方法声明一个连接对象 cursor = db.cursor() sql = '' try: cursor.execute(sql, (id, user, age)) db.commit() except: db.rollback() #事务回滚,保证数据一致性 db.close()
关系型数据库属性:

5.3 非关系型数据库
NoSQL 是基于键值对的,而且不需要经过 SQL 层的解析,数据之间没有耦合性,性能非常高。
细分-

对于爬虫的数据存储来说,一条数据可能存在某些字段提取失败而缺失的情况,而且数据可能随时调整,另外数据之间能还存在嵌套关系,因此多采用NoSQL。常用的是MongoDB和Redis
1- MongoDB
在 MongoDB 中,每条数据其实都有一个 _id 属性来唯一标识,如果没有显式指明 _id,MongoDB 会自动产生一个 ObjectId 类型的 _id 属性。insert() 方法会在执行后返回的 _id 值。
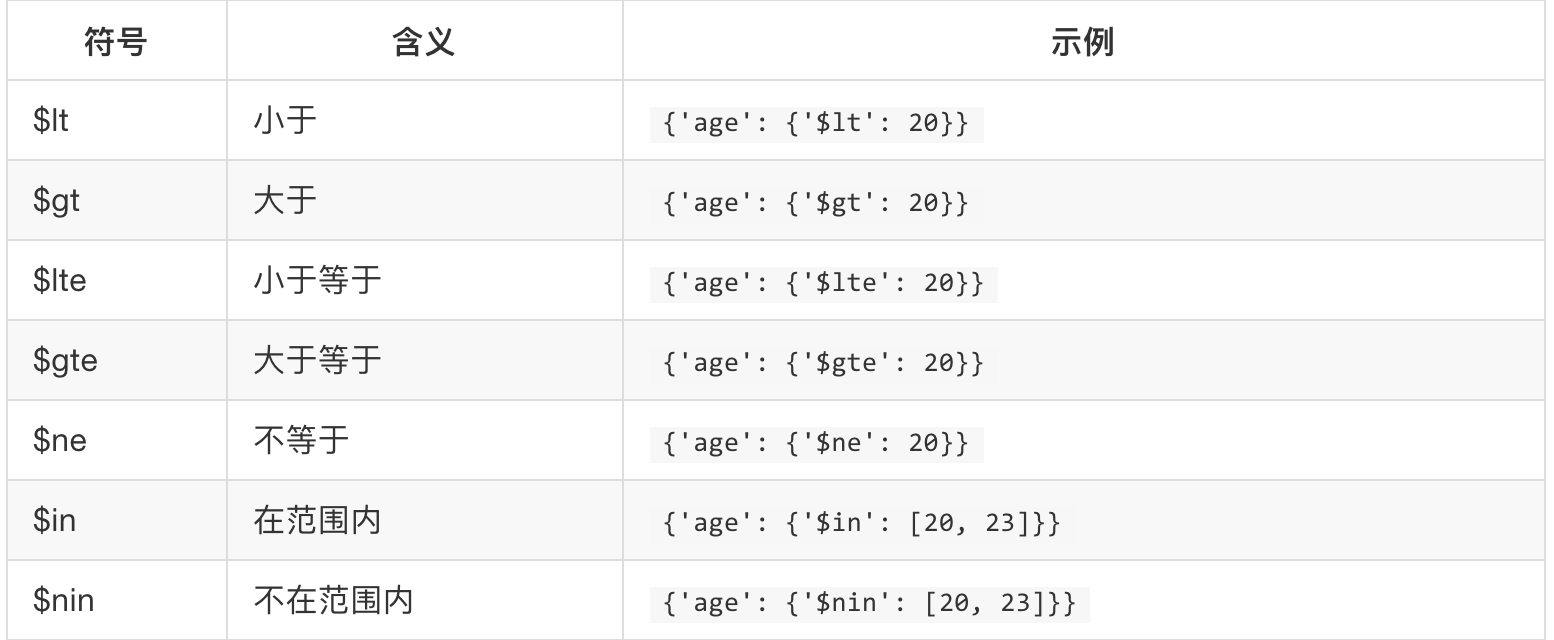

##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:
持续更新...
对应代码请见:..

 浙公网安备 33010602011771号
浙公网安备 33010602011771号