python | 爬虫笔记(二)- 爬虫基础
2.1 HTTP原理
1、URI、URL
统一资源标识符,统一资源定位符
协议+路径+资源名称
URL 是 URI 的子集,URI 还包括一个子类叫做 URN,它的全称为 Universal Resource Name,即统一资源名称。
URN 只命名资源而不指定如何定位资源,如 urn:isbn:0451450523,它指定了一本书的 ISBN,可以唯一标识这一本书,但是没有指定到哪里定位这本书,
2、超文本 Hypertext
html里有一系列标签,浏览器解析这些标签后便形成了我们平常看到的网页,而这网页的源代码 HTML 就可以称作超文本。
3、HTTP、HTTPS
协议类型;
HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫做超文本传输协议,HTTP 协议是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证传送高效而准确地传送超文本文档。
HTTPS 的全称是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,简称为 HTTPS。
SSL
- 建立信息安全通道,保证数据传输安全;
- 确认网站真实性,可以通过锁头确认真实信息;
4、HTTP请求过程
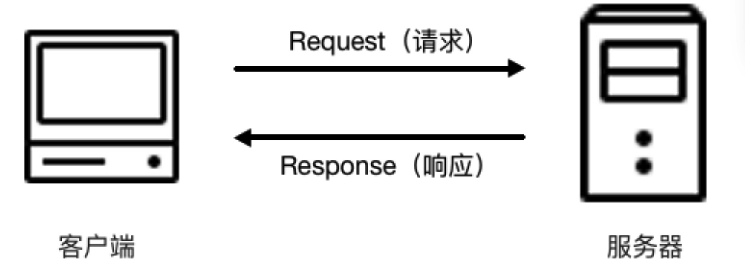
浏览器-检查-network 可以查看整个请求和返回过程
5、Request
由客户端向服务端发出。分为Request Method、Request URL、Request Headers、Request Body,即请求方式、请求链接、请求头、请求体。
· Request Method
请求方式,请求方式常见的有两种类型,GET 和 POST。
GET:输入网址加回车,URL中包含请求参数的信息;
POST:多为表单提交发起,如用户名密码登陆,数据以Form Data即表单形式传输,不会体现在URL中,会包含在 Request Body 中。
GET 方式请求提交的数据最多只有 1024 字节,而 POST 方式没有限制。
所以如登录(包含敏感信息)和文件上传时,会用POST。
其他方法

· Request URL
请求的网址
· Request Headers
请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、Referer、User-Agent 等

Request Headers 是 Request 等重要组成部分,在写爬虫的时候大部分情况都需要设定 Request Headers。
· Request Body
即请求体,一般承载的内容是 POST 请求中的 Form Data,即表单数据,而对于 GET 请求 Request Body 则为空。
在登录之前我们填写了用户名和密码信息,提交时就这些内容就会以 Form Data 的形式提交给服务器,此时注意 Request Headers 中指定了 Content-Type 为 application/x-www-form-urlencoded,此时才可以以Form Data形式提交
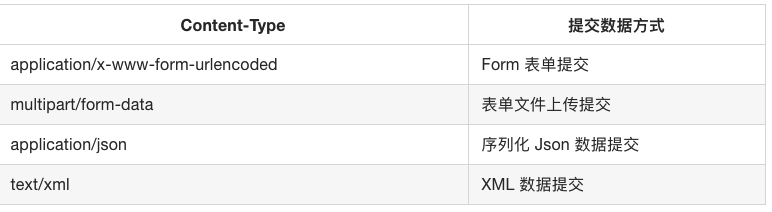
在爬虫中如果我们要构造 POST 请求需要注意这几种 Content-Type,了解各种请求库的各个参数设置时使用的是哪种 Content-Type,不然可能会导致 POST 提交后得不到正常的 Response。
6、Response
由服务端返回给客户端。Response 可以划分为三部分,Response Status Code、Response Headers、Response Body。
· Response Status Code
响应状态码,此状态码表示了服务器的响应状态,如 200 则代表服务器正常响应,301代表跳转,404 则代表页面未找到,500 则代表服务器内部发生错误。
· Response headers
内容类型,内容长度,服务器信息,设置cookie等
· Resposne Body
响应体,最重要的内容。响应的正文数据都是在响应体中,如请求一个网页,它的响应体就是网页的 HTML 代码,请求一张图片,它的响应体就是图片的二进制数据。
在做爬虫时主要解析的内容就是 Resposne Body,通过 Resposne Body 我们可以得到网页的源代码、Json 数据等等,然后从中做相应内容的提取。
2.2 Web网页基础
1、网页组成
网页可以分为三大部分,HTML、CSS、JavaScript,HTML 定义了网页的内容和结构,CSS 描述了网页的布局,JavaScript 定义了网页的行为。
· HTML
网页包括文字、按钮、图片、视频等各种复杂的元素,其基础架构就是 HTML。不同文件用不同标签标示,而元素之间又通过div嵌套组合而成。
· CSS
层叠样式表
“层叠”是指当在 HTML 中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。“样式”指网页中文字大小、颜色、元素间距、排列等格式。
CSS是目前唯一的网页页面排版样式标准
结构:CSS选择器+样式规则
在网页中,一般会统一定义整个网页的样式规则,写入到 CSS 文件,其后缀名为 css,在 HTML 中只需要用 link 标签即可引入写好的 CSS 文件,这样整个页面就会变得美观优雅。
· JavaScript
实现了一种实时、动态、交互的页面功能。JavaScript 通常也是以单独的文件形式加载的,后缀名为 js,在 HTML 中通过 script 标签即可引入。
2、网页结构


一个网页标准形式都是 html 标签内嵌套 head 和 body 标签,head 内定义网页的配置和引用,body 内定义网页的正文。
3、节点及节点关系
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
DOM,英文全称 Document Object Model,即文档对象模型。它定义了访问 HTML 和 XML 文档的标准:
W3C 文档对象模型 (DOM) 是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。
W3C DOM 标准被分为 3 个不同的部分:
- 核心 DOM - 针对任何结构化文档的标准模型
- XML DOM - 针对 XML 文档的标准模型
- HTML DOM - 针对 HTML 文档的标准模型
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
- 整个文档是一个文档节点
- 每个 HTML 元素是元素节点
- HTML 元素内的文本是文本节点
- 每个 HTML 属性是属性节点
- 注释是注释节点
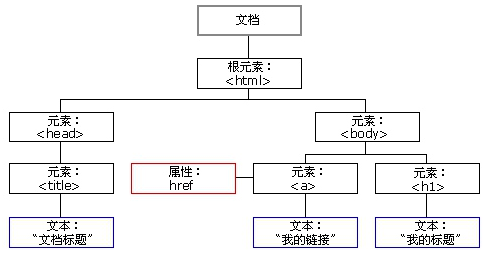
通过 HTML DOM,树中的所有节点均可通过 JavaScript 进行访问,所有 HTML 节点元素均可被修改,也可以被创建或删除。
节点树中的节点彼此拥有层级关系。我们常用 parent(父)、child(子)和 sibling(兄弟)等术语用于描述这些关系。父节点拥有子节点,同级的子节点被称为兄弟节点。

节点树及节点关系
4、选择器
CSS 选择器会根据不同的节点设置不同的样式规则
例如上例中有个 div 节点的 id 为 container,那么我们就可以用 CSS 选择器表示为 #container,# 开头代表选择 id,其后紧跟 id 的名称。
另外如果我们想选择 class 为 wrapper 的节点,便可以使用 .wrapper,. 开头代表选择 class,其后紧跟 class 的名称。
另外还有一种选择方式是根据标签名筛选,例如我们想选择二级标题,直接用 h2 即可选择。如上是最常用的三种选择表示,分别是根据 id、class、标签名筛选,请牢记它们的写法。
另外 CSS 选择器还支持嵌套选择,各个选择器之间加上空格分隔开便可以代表嵌套关系,如 #container .wrapper p 则代表选择 id 为 container 内部的 class 为 wrapper 内部的 p 节点。
如果不加空格则代表并列关系,如 div#container .wrapper p.text 代表选择 id 为 container 的 div 节点内部的 class 为 wrapper 节点内部的 class 为 text 的 p 节点
还有一种比较常用的选择器是 XPath
2.3 爬虫基本原理
节点比作网页,连线比作网页之间连接关系。蜘蛛将整个网爬行到,抓取网站数据
1、爬虫概述
爬虫就是获取网页并提取和保存信息的自动化程序。
· 获取网页
网页源代码包含网页部分有用信息
最关键的部分就是构造一个 Request 并发送给服务器,然后接收到 Response 并将其解析出来
Python 里面提供了许多库来帮助我们实现这个操作,如 Urllib、Requests 等,我们可以用这些库来帮助我们实现 HTTP 请求操作,Request 和 Response 都可以用类库提供的数据结构来表示,得到 Response 之后只需要解析数据结构中的 Body 部分即可。
· 提取信息
最通用的方法便是采用正则表达式提取,但比较复杂,容易出错
还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 BeautifulSoup、PyQuery、LXML 等,使用这些库可以高效快速地从中提取网页信息,如节点的属性、文本值等内容。
提取信息使杂乱的数据变得清晰有条理,方便后续分析
· 保存数据
txt文本或json文本;数据库;或远程服务器
2、能爬怎样的数据
HTML 代码,Json 字符串
二进制数据,如图片、视频、音频等
各种扩展名的文件,如 CSS、JavaScript、配置文件等等
以上的内容其实都对应着各自的URL,是基于 HTTP 或 HTTPS 协议的,只要是这种数据爬虫都可以进行抓取。
3、JavaScript渲染页面
html多为空壳,网页被js渲染。用基本 HTTP 请求库得到的结果源代码可能跟浏览器中的页面源代码不太一样。可使用 Selenium、Splash 这样的库来实现模拟 JavaScript 渲染
2.4 Session和Cookies
1、静态网页和动态网页
HTML 代码编写的,文字、图片等内容均是通过写好的 HTML 代码来指定的,这种页面叫做静态网页。
动态网页应运而生,它可以动态解析 URL 中参数的变化,关联数据库并动态地呈现不同的页面内容。而是可能由 JSP、PHP、Python 等语言编写的。
动态网页可实现用户登录注册的功能,凭证
2、无状态HTTP
缺少状态记录,再次请求需要重复操作。
为了节约资源,保持HTTP连接状态, Session 和 Cookies出现。
Session 在服务端,也就是网站的服务器,用来保存用户的会话信息,Cookies 在客户端,也可以理解为浏览器端,有了 Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的 Response。cookie保存了登录凭证。
在爬虫中,有时候处理需要登录才能访问的页面时,我们一般会直接将登录成功后获取的 Cookies 放在 Request Headers 里面直接请求,而不必重新模拟登录。
3、Session 会话
是指有始有终的一系列动作/消息。
在 Web 中 Session 对象用来存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web 页时,如果该用户还没有会话,则 Web 服务器将自动创建一个 Session 对象。当会话过期或被放弃后,服务器将终止该会话。
4、Cookies
某些网站为了辨别用户身份、进行 Session 跟踪而储存在用户本地终端上的数据。
· 会话保持
客户端第一次请求服务器,服务器会返回一个Headers中带有Set-Cookies字段的Response给客户端,用来标记用户,客户端保存。下次请求时,浏览器会把此Cookies 放到 Request Headers 一起提交给服务器,Cookies 携带了 Session ID 信息,服务器检查该 Cookies 即可找到对应的 Session 是什么,然后再判断 Session 来以此来辨认用户状态。
有效则保持登陆,无效或过期则重新登录
· 属性结构
name
value
max age: 失效时间
path
domain
size
http
secure
· 会话Cookie、持久Cookie
会话 Cookie 就是把 Cookie 放在浏览器内存里,浏览器在关闭之后该 Cookie 即失效,持久 Cookie 则会保存到客户端的硬盘中,下次还可以继续使用,用于长久保持用户登录状态。
5、常见误区
关闭浏览器,服务器不会知道,因此也需要为服务器设置一个失效时间
2.5 代理基本原理
服务器检测的是某个 IP 单位时间的请求次数
设置代理,伪装IP
1、基本原理
代理服务器, Proxy Server 代理网络用户去取得网络信息。
request和response都通过代理服务器进行中转
2、代理作用
突破自身 IP 访问限制
提高访问速度
方位一些单位或团体内部资源
隐藏真实ip
3、代理分类

根据匿名程度区分:
· 高度匿名
· 普通匿名
· 透明匿名
...
4、常见代理设置
免费、付费、ADSL拨号
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:
持续更新...
对应代码请见:..

 浙公网安备 33010602011771号
浙公网安备 33010602011771号