【转载】百分点大数据技术团队:ClickHouse国家级项目性能优化实践
编者按
ClickHouse自从2016年开源以来便备受关注,主要应用于数据分析(OLAP)领域,各个大厂纷纷跟进大规模使用。百分点科技在某国家级项目建设中完成了多数据中心的ClickHouse集群建设,日增千亿数据量,在此基础上进行优化与性能调优,能够更好地解决部署规模扩大和数据量扩容等问题。本文结合项目的数据规模及业务场景,重点介绍了百分点大数据技术团队在ClickHouse国家级项目建设中的性能优化实践。
一、概览
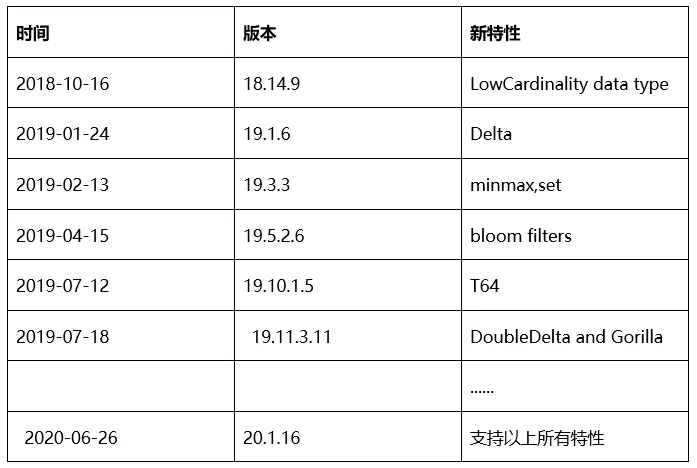
2020年4月,百分点大数据技术团队结合某国家级多数据中心的Clickhouse集群建设,发表了“ClickHouse国家级项目最佳实践”,该文介绍了Clickhouse的特点、适用场景与核心概念,以及百分点科技在大规模Clickhouse集群建设与运营方面的实践经验。为部署到更多的城市,解决当前城市数据量扩容问题,Clickhouse集群的设计优化与性能调优成为重点工作:
-
数据量增加了5倍多:数据量达到每天千亿的级别;
-
查询周期更长:即时查询周期从7天增加到30天;
-
数据种类更多:业务数据类型增加了1倍;
-
集群规模增加了400多台,聚合节点压力变大;
-
聚合查询值枚举空间大:部分字段的值枚举空间在几百万和几十亿之间,聚合可能内存溢出。
在做了大规模的测试后,我们发现沿用集群版本和规划不能满足需求。Clickhouse的很多新特性V1.1.5版本都不支持。经过一系列的版本对比测试,集群规划变更及参数调优,成功将版本升级到V20.1.16,同时也升级了Clickhouse指标采集与监控系统,满足了数据规模的增长和业务需求的变化。整个升级涉及很多内容,本文仅就Clickhouse性能调优实践进行重点介绍。

二、调优思路Clickhouse性能主要由CPU、IO、Memory驱动,无论是索引优化、列编码与压缩算法,还是配置的调优,主要是围绕着这三个方面进行。索引改变了数据存储和读取的顺序,编码和压缩改变数据存储与传输的大小,服务配置影响着ClickHouse的资源分配和执行行为。
首先通过版本升级,利用ClickHouse的新特性来提升单条SQL的查询速度,如采用跳数索引、列编码及新的压缩算法,这些都是在新版本中出的新特性。
其次,改变了整个集群的写入方式,在数据写入的时候对集群按照业务概念进入逻辑划分,减少了集群写入压力。
三、实践经验
1. 主键的选择
1.1 生产中如何建主键索引
实践中,时间对于业务是必查字段,因此选用时间字段作为主键,同时将几个重要字段也加入了主键。总体来说,ClickHouse索引的长度没有明确的限制,需要根据实际业务和数据的结构来综合考虑。
提升查询性能
加在索引中的列如果能跳过比较长的一段数据,则能很好的提升查询性能。
提高数据压缩率
根据主键排序的时候,数据一致性越高,压缩比越高,这两点在下面的测试用例中会很明显的看到。另外,较长的索引会影响索引的内存使用量,不过对于目前普遍的大数据机器配置来说,以及ClickHouse稀疏索引的特性,四五个字段的长索引,对内存的占用还是很有限的。
1.2 测试表结构
在项目建设前期,表的主键基本上只有业务时间一个字段,于是我们做了下面的测试,使用其他比较重要的字段作为主键开头。
下面四张测试表字段一致,只有主键不同。其中表2和表3数据一致,各有70亿数据;表28和表29数据一致,各有643575000数据,为了避免分区part数量的影响,所有表的分区都merge比较彻底,测试表的分区数也一致。

CREATE TABLElog_local2( `found_time` UInt32, `s_ip` String, `s_city` String, `s_long` Float32, `s_lat`Float32, INDEXs_ip_idx1 s_ip TYPE bloom_filter() GRANULARITY 4 )ENGINE = MergeTree PARTITION BYtoRelativeDayNum(toDateTime(found_time)) ORDER BYfound_time;
CREATE TABLElog_local3( `found_time` UInt32, `s_ip` String, `s_city` String, `s_long` Float32, `s_lat`Float32, INDEXs_ip_idx1 s_ip TYPE bloom_filter() GRANULARITY 4 )ENGINE = MergeTree PARTITION BYtoRelativeDayNum(toDateTime(found_time)) ORDER BY(found_time, s_ip, s_city, s_long, s_lat);
CREATE TABLElog_local28(`found_time` UInt32, `d_ip` IPv6CODEC(LZ4HC(9)), `s_ip` IPv6 CODEC(LZ4HC(9)), `d_port` UInt16 CODEC(NONE),`s_port` UInt16 CODEC(NONE), `s_country` LowCardinality(String), `s_city` StringCODEC(ZSTD(9)), s_geo String, s_long Float32 , s_lat Float32, d_countryLowCardinality(String), d_city String CODEC(ZSTD(9)), d_geo String,d_long Float32 , d_lat Float32 )ENGINE =MergeTree() PARTITION BYtoRelativeHourNum(toDateTime(found_time)) ORDER BY(found_time,s_city,s_long,s_lat) SETTINGSindex_granularity = 8192;
CREATE TABLE log_local29(`found_time`UInt32, `d_ip` IPv6CODEC(LZ4HC(9)), `s_ip` IPv6 CODEC(LZ4HC(9)), `d_port` UInt16 CODEC(NONE),`s_port` UInt16 CODEC(NONE), `s_country` LowCardinality(String), `s_city` StringCODEC(ZSTD(9)), s_geo String, s_long Float32 , s_lat Float32, d_countryLowCardinality(String), d_city String CODEC(ZSTD(9)), d_geo String,d_long Float32 , d_lat Float32 )ENGINE =MergeTree() PARTITION BYtoRelativeHourNum(toDateTime(found_time)) ORDER BY(s_city,s_long,s_lat,found_time) SETTINGSindex_granularity = 8192;
1.3 log_local2和log_local3两张测试表压缩效果对比
从表2和表3各列数据大小可看出,s_ip加入到主键后压缩得到一定的优化。


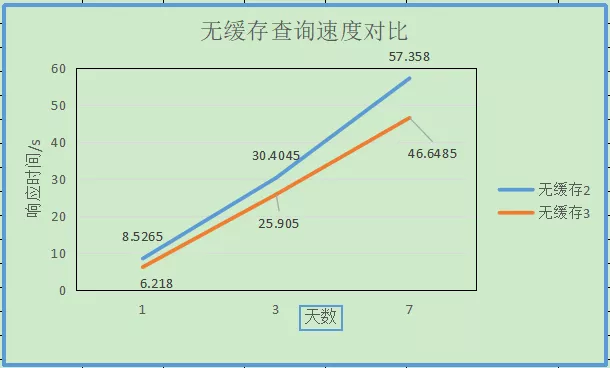
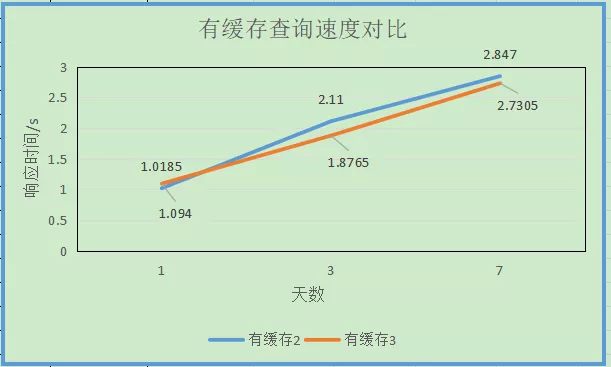
1.4 log_local2和log_local3两张测试表s_ip分页查询效果对比
可以看出s_ip加入主键后查询性能有一定的提升。
1.5 found_time和s_city开头主键压缩效果对比
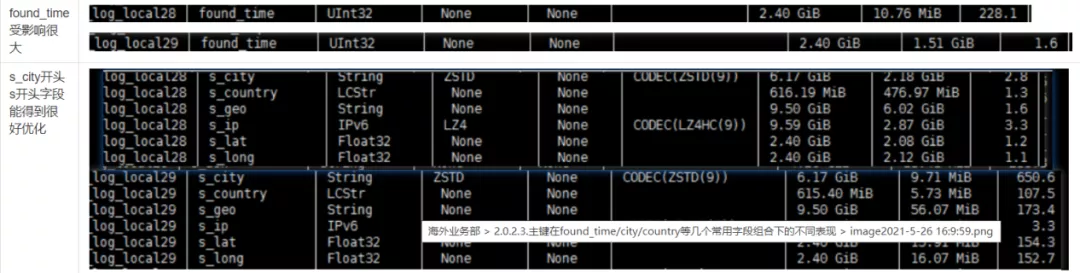
1.6 看上去log_local29的压缩效果更好,但是为什么不用这种组合索引呢?
实际业务中是多字段开放式查询,found_time是必查字段,无论查什么字段,都要带上found_time字段,使用s_city开头的主键看上去这几个字段得到极大的优化效果,但是在不查询这几个字段的时候,会因为found_time没有得到较好的优化而查询效果变差。
如果是要对每天的数据做类似于数仓的ETL,原始数据层使用这种索引组合则会因为降低比较多的存储而好很多。
2. 跳数索引
2.1 ClickHouse跳数索引类型
生产中,主要是使用MergeTree系列的引擎,目前,MergeTree系列引擎共支持5种跳数索引,分别是minmax、set和ngrambf_v1和tokenbf_v1、bloom_filter。实际生产中我们只选用了bloom_filter跳数索引,这个是由百分点科技实际业务的数据分布所决定的,后面会分析为什么只用了bloom_filter索引。
2.2 如何创建
为了演示,此处创建一张测试表,只有两个字段,found_time和ip,为了下文描述方便,类型都采用String,并给ip字段建了5种索引以展示索引用法。
CREATE TABLE ip_test(found_timeString,ip String, INDEX ip_idx1(ip) TYPE minmax GRANULARITY 1, INDEX ip_idx2 ip TYPE bloom_filter(0.025) GRANULARITY 1, INDEX ip_idx3 ip TYPE ngrambf_v1(3, 512, 5, 0) GRANULARITY 1, INDEX ip_idx4 ip TYPE tokenbf_v1(512, 5, 0) GRANULARITY 1, INDEX ip_idx5 ip TYPEset(0) GRANULARITY 4 )ENGINE= MergeTree() order by found_time partitionby toYYYYMMDD(toDateTime(found_time)) SETTINGS index_granularity = 4;
-
minmax—存储相应索引区间的大小极值;
-
bloom_filter(误差概率)—布隆过滤器,里面的参数为自己设定的误差概率,区间为(0,1),默认为0.025;
-
ngrambf_v1(n,布隆过滤器字节大小,hash函数个数,随机种子)—;
-
tokenbf_v1(布隆过滤器字节大小,hash函数个数,随机种子)—;
-
set(max_rows)—存储相应索引区间的唯一值并不超过max_rows的个数,默认值0意味着没有限制。
样例数据如下:
insertinto ip_test values('1620756379','178.237.20.123');
insertinto ip_test values('1620756380','204.79.197.200');
insertinto ip_test values('1620756445','180.163.151.161');
insertinto ip_test values('1620756449','72.247.116.168');
insertinto ip_test values('1620759973','172.24.20.17');
insertinto ip_test values('1620759977','101.89.39.120');
insertinto ip_test values('1620760033','192.168.162.96');
insertinto ip_test values('1620760035','123.6.2.171');
insertinto ip_test values('1620760036','172.217.24.74');
insertinto ip_test values('1620760036','101.89.39.120');
insertinto ip_test values('1620760047','192.168.162.96');
insertinto ip_test values('1620760138','123.6.2.171');
insertinto ip_test values('1620760239','172.217.24.74');
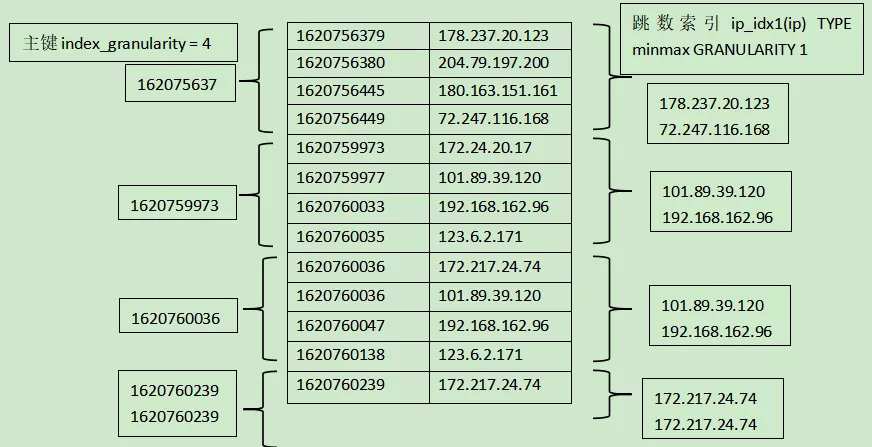
2.3 index_granularity和GRANULARITY
index_granularity:指的是ClickHouse的索引粒度,多少行数据产生一条索引,默认是8192行数据产生一条索引;
GRANULARITY:跳数数据根据指的表达式聚合数据块上的信息,聚合信息的粒度是由创建索引的时候指定GRANULARITY的值决定的。
如下图所示,index_granularity = 4意味着每4条数据产生一条索引,GRANULARITY1则意味着minmax索引聚合信息的粒度是1个index_granularity,也是4条数据,minmax索引会从每4条数据中心聚合出最大最小的值来。GRANULARITY n=n*index_granularity。
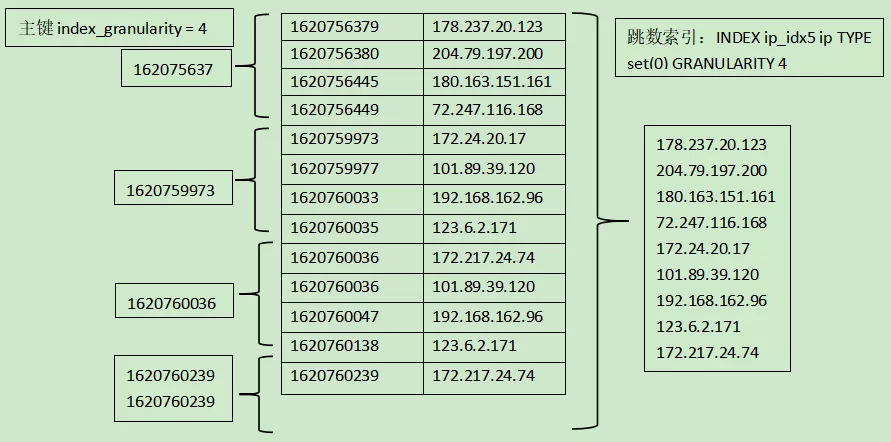
再如下图所示,set索引聚合的信息是整个样例数据的枚举值。
2.4 如何对历史数据建索引
添加索引:
ALTER TABLE ip_test add INDEXip_idx1(ip) TYPE minmax GRANULARITY 1; ALTER TABLE ip_test add INDEXip_idx2 ip TYPE bloom_filter(0.025) GRANULARITY 1; ALTER TABLE ip_test add INDEXip_idx3 ip TYPE ngrambf_v1(3, 512, 5, 0) GRANULARITY 1; ALTER TABLE ip_test add INDEXip_idx4 ip TYPE tokenbf_v1(512, 5, 0) GRANULARITY 1; ALTER TABLE ip_test add INDEXip_idx5 ip TYPE set(0) GRANULARITY 4;
删除索引:
ALTER TABLE ip_test DROP INDEXip_idx1;
重建索引(对历史数据add索引的时候,只是改变了表的schema,实际的索引文件并没有生成,需要再使用重建索引的语句对历史数据建立索引):
ALTER TABLE ip_test MATERIALIZEINDEX name[ IN PARTITION partition_name]
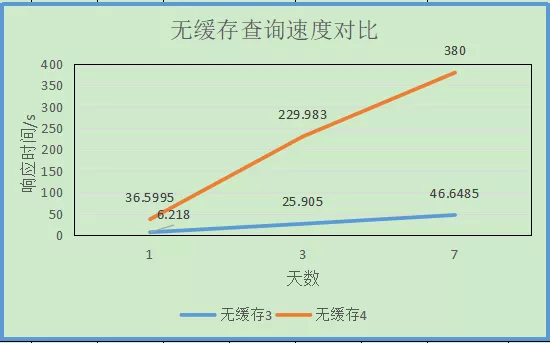
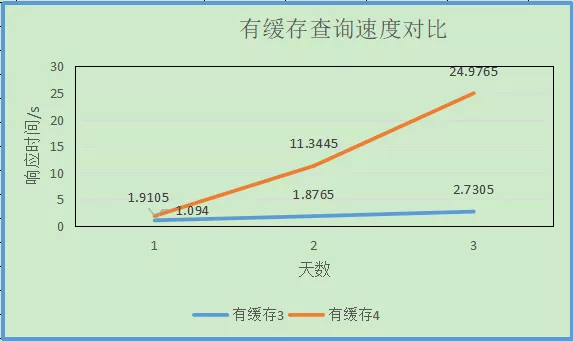
2.5 bloom_filter 查询效果
黄线为没有建bloom_filter索引的查询数据,蓝色为建了bloom_filter索引的查询数据,二者数据内容一致。
2.6 跳数索引需要额外存储
下面表格是对70亿ip字段建立索引后,原始数据和索引数据大小的对比,ip枚举值在3亿以上,对于这类数据建索引,索引文件会非常大。
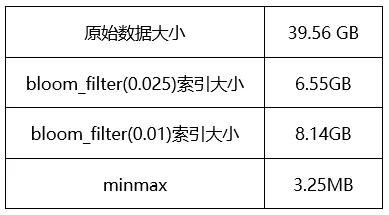
在生产中只对枚举值比较多的字段用了bloom_filter跳数索引,其他索引没有使用,因为bloom_filter的索引文件不至于太大,同时对于值比较多的列又能起到比较好的过滤效果。因为经过测试发现对于枚举值较少的字段,不建索引查询速度就已经很快,因为枚举少,本身在压缩的时候压缩比很高,读取速度很快,但是建了索引之后,要么不能过滤掉数据,要么确实过滤掉一部分数据,但是因为读取的数据块不一致又会导致从原先的大块读取的顺序IO退化为随机IO,反而得不偿失。而枚举值较多的情况比如ip字段,在使用ngrambf_v1索引的时候,ngram size和bloom filter大小的选择对索引的大小和效果影响很大。
另外,通过上面的表格也能看出来,有些字段的bloom_filter跳数索引还是非常占用存储的,查询的时候跳数索引的IO也需要考虑。因此,实际中才会出现日志中确实过滤掉了数据,但是查询速度反而慢了的情况。最后,选择什么索引以及索引的参数怎么设置,都要结合业务数据的分布特点也进行,数据的排序方式、散列程度都会影响索引效果。
3. 压缩和编码
3.1 通用编码

3.2 特殊编码类型

特殊编码与通用的压缩算法相比,区别在于,通用的LZ4和ZSTD压缩算法是普适行的,不关心数据的分布特点,而特殊编码类型对于特定场景下的数据会有更好的压缩效果。
3.3 如何使用
CREATE TABLE k19_ods.test8 ( `found_time` UInt32, `recv_time1` UInt32 CODEC(NONE), `recv_time2` UInt32, `recv_time3` UInt32 CODEC(LZ4), `recv_time4` UInt32 CODEC(LZ4HC(9)), `recv_time5` UInt32 CODEC(ZSTD(9)), `recv_time6` UInt32 CODEC(T64()), `name0` String CODEC(Delta(),LZ4), `name1` String CODEC(DoubleDelta()), `name2` String CODEC(Gorilla()), `name4` String CODEC(Gorilla(), LZ4) ) ENGINE = MergeTree() PARTITION BYtoYYYYMMDD(toDateTime(found_time)) ORDER BY found_time
压缩算法和特殊编码两者可以结合起来使用。
3.4 压缩效果举例对比
需要注意一点就是,对于LZ4HC和ZSTD选择的压缩level越高,压缩效果越好,但是CPU的使用率也会相应的越高。如果插入的数据量很大,会明显看到较高的CPU使用率。
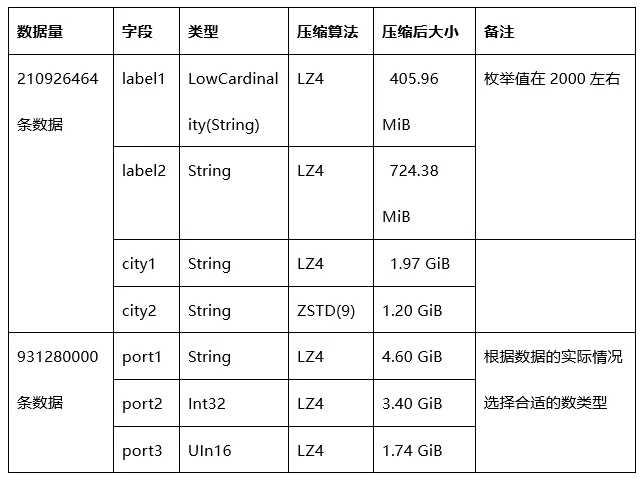
在生产中,我们调整了一些字段的类型,有的从String变为Int,有的从较大取值范围的类型调整为较小范围的类型;还有一些不常用和压缩后size非常大的字段采取了较高的压缩算法;对于一些枚举值较少的String使用了LowCardinality(String),但由于这个特性在所用版本中有bug,因此在生产中改成了String。
4. 数据分区
4.1 数据分区规则
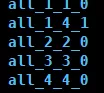
不指定分区键
如果建表时不指定分区键,则数据默认不分区,所有数据写到一个默认分区all里面。
如下图:
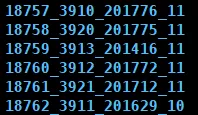
使用整型
如果分区键取值属于整型且无法转换为日期类型YYYYMMDD格式,则直接按照该整型的字符形式输出作为分区ID的取值。
如下图:
使用日期类型
如果分区键取值属于日期类型,或者是能够转换为YYYYMMDD日期格式的整型,则按照分区表达式逻辑格式化后作为分区ID的取值。
使用其它类型
如果分区键取值既不属于整型,也不属于日期类型,例如String、Float等,则通过128位Hash算法取其Hash值作为分区ID的取值。

4.2 分区目录命名规则

-
partition_id:20210524:,见上页的生成规则;
-
min_block_number:1,,最小块编号,MergeTree引擎从1开始计数,每次+1;
-
max_block_number:1,最大块编号,新插入的数据,最小与最大编号一致;
-
level:0,这个可以理解为合并的次数,新插入的数据都是0,每合并1次+1。
4.3 分区目录合并过程


4.4 分区设计
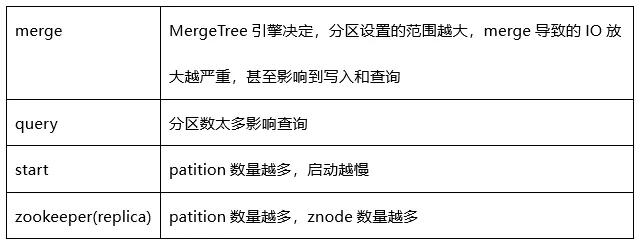
分区选择考虑merge (写入放大)、查询(slelect part数量)、启动等方面考虑。在实际生产中选择时间作为分区键,根据表数据的大小按天或者按周进行了分区。
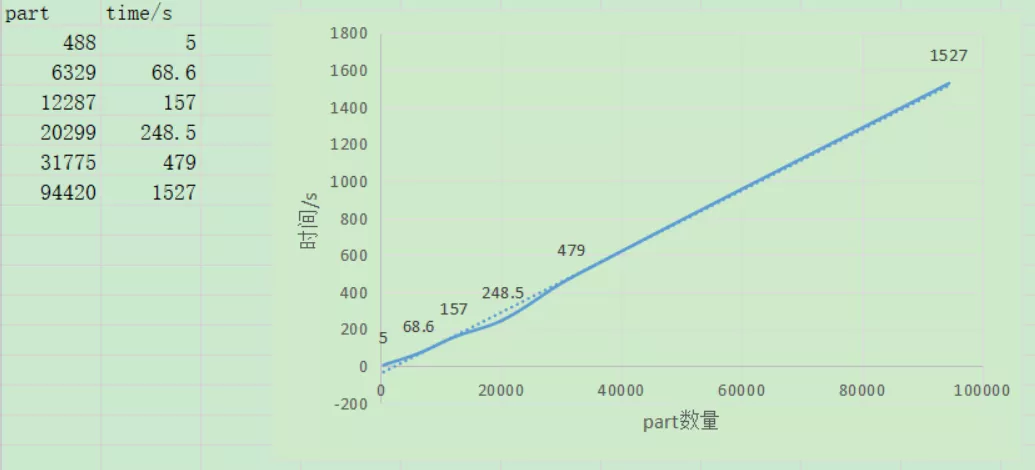
这是之前做过的一个part数量与启动速度测试,从中可以明显的看出part数量很影响启动速度。
5. 配置参数调优
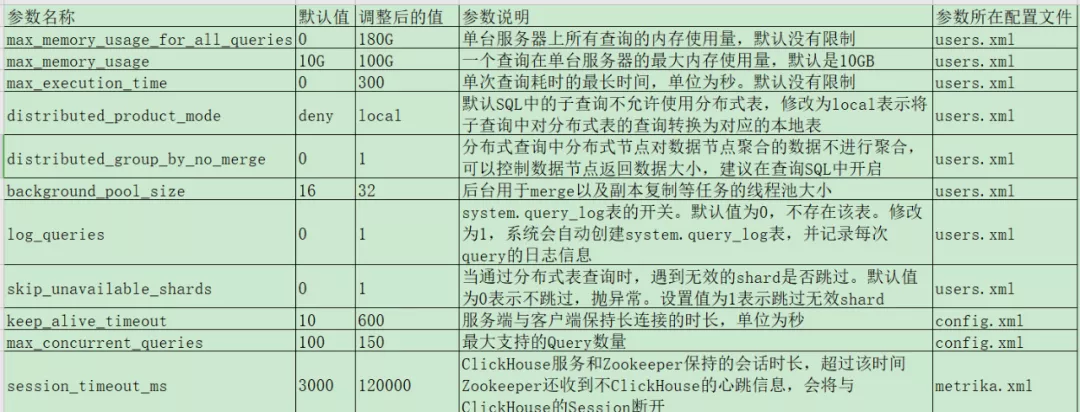
5.1 现场使用的配置参数
关于配置参数,大部分在之前的分享中都描述过,这里着重讲一个新加的配置:distributed_group_by_no_merge。
下面是这个参数的解释,从官方给出的说明中,有两个关键点:一是分布式查询的时候,不会从不同服务器merge聚合状态;二是不同分片上有不同的key是起比较好的应用场景。为什么不同的分片上要有不同的key,下文中将做出解释。

5.2 不开启distributed_group_by_no_merge
以1台分布式节点、4个数据节点的集群来做举例,建表语句和样例数据如下(表里只有两个字段:id和其对应的数量):
create table local.server(id Int32,cntInt32)ENGINE=Memory(); create table local.server(id Int32,cntInt32)ENGINE=Memory(); create table local.server(id Int32,cntInt32)ENGINE=Memory(); create table local.server(id Int32,cntInt32)ENGINE=Memory(); createtable dis.server(id Int32,cntInt32)ENGINE=Distributed('test',local,'server'); insert into server values(1,10) ,(2,9),(3,8) ,(4,5) ,(5,4) ,(6,3); insert into server values (1,11), (3,12),(5,13), (7,14), (9,10); insert into server values (2,15 ), (4,16 ),(6,17 ), (8,18 ), (10,19); insert into server values (3,14 ), (6,15 ),(9,16 ), (11,17), (12,18), (13,20);
正常情况下,要统计整个集群的id机器数量并取Top3,sql如下:
select id,sum(cnt)counts from server groupby id order by counts desc limit 3 ;
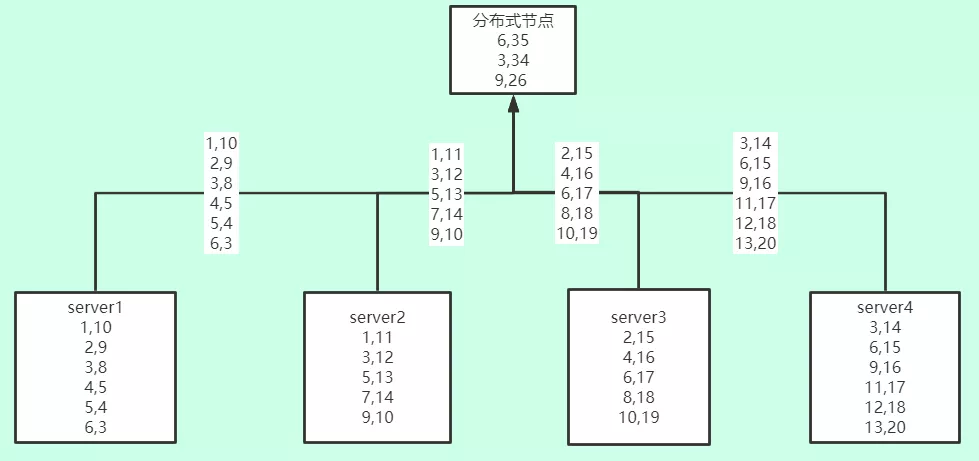
ClickHouse的聚合过程大致如下图(这里只画了数据返回流程)。在ClickHouse的聚合查询中,每个机器都会把自己的聚合的中间状态返回给分布式节点,也就是说,即使你只是想要Top100,每台机器也会把自己所拥有的所有枚举值都返回给分布式节点进行进一步的聚合。
返回给分布式节点22条数据,分布式节点对着22条数据进行进一步的聚合,最后得出想要的结果。
5.3 开启distributed_group_by_no_merge
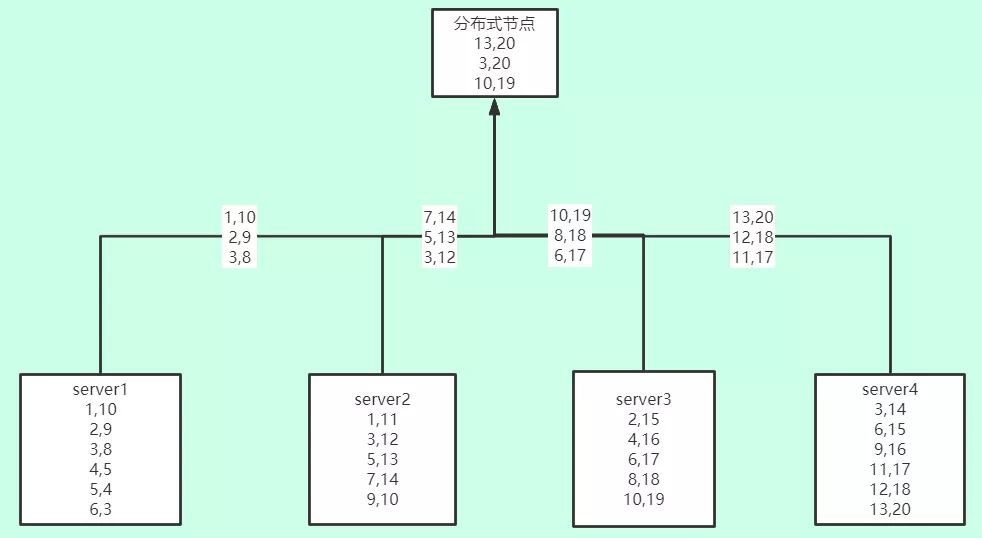
select id,sum(counts)counts from( select id,sum(cnt)counts from servergroup by id order by counts desc limit 3 settingsdistributed_group_by_no_merge=1) group by id order by counts desc limit 3;
这条SQL在聚合的时候每个节点只只会返回各自节点的Top3给分布式节点,分布式节点最终聚合3*4=12条数据。不过可以看到数据有一定误差,在生产中对于比较靠前的topN来说,实际统计的误差较小,如果不是要求百分百精确的话,完全可以接受。
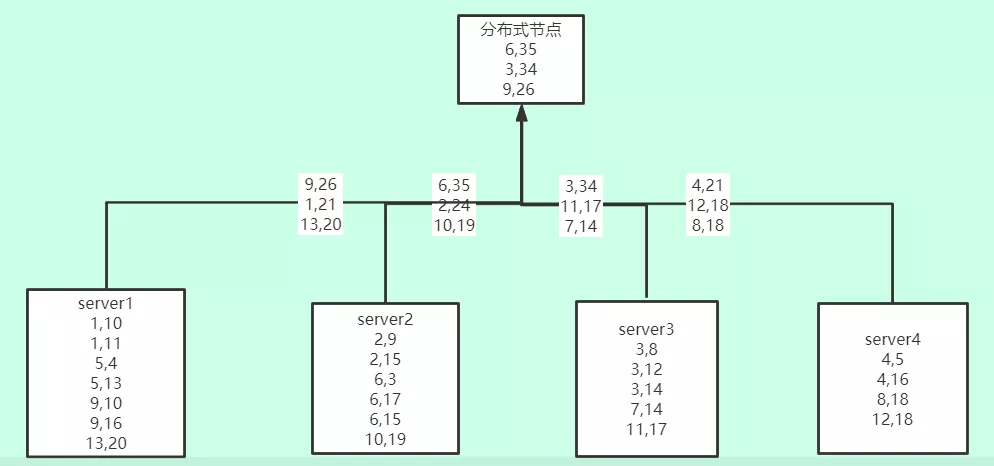
5.4 如果数据ip hash存储
对于上面的统计误差,如果数据是按照一定规则一类数据存储到一个分片上,则可以避免这个问题,如下图所示。所以上文里提到官方说要不同的key分布在不同的shard上面,不过,这同时会引进一个新的问题——数据倾斜问题,这里就不做讨论了。
6. 物化视图
6.1 如何创建
CREATE MATERIALIZED VIEW db.viewname
(
field TYPE...
)
[ENGINE = engine] [POPULATE] AS SELECT ...
POPULATE关键字可以创建物化视图的时候对历史数据起作用,否则只会对新插入的数据生效。
6.2 物化视图与普通视图的区别
普通视图不保存数据,保存的仅仅是查询语句,查询的时候还是从原表读取数据,可以将普通视图理解为是个子查询。物化视图则是把查询的结果根据相应的引擎存入到了磁盘或内存中,对数据重新进行了组织,你可以理解物化视图是完全的一张新表。
6.2 物化视图示例
我们准备了一份1547145102数据量的ClickHouse的text_log数据,表结构如下:
CREATE TABLE system.text_log(`event_date` Date, `event_time` DateTime, `microseconds` UInt32, `thread_name`LowCardinality(String), `thread_number` UInt32, `os_thread_id` UInt32, `level`Enum8('Fatal' = 1, 'Critical' = 2, 'Error' = 3, 'Warning' = 4, 'Notice' = 5,'Information' = 6, 'Debug' = 7, 'Trace' = 8), `query_id` String, `logger_name`LowCardinality(String), `message` String, `revision` UInt32, `source_file`LowCardinality(String), `source_line` UInt64) ENGINE = MergeTree PARTITION BYtoYYYYMM(event_date) ORDER BY (event_date, event_time) SETTINGSindex_granularity = 8192。
如果要统计每天各种日志级别的log数量,查询语句:
select event_date,level,countMerge(counts)counts from test.log_level_count group byevent_date,level order by event_date,level;
查询耗时:

现在对该查询建一个物化视图看看效果:
CREATE MATERIALIZED VIEW test.log_level_count ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMMDD(event_date)ORDER BY (event_date, level) POPULATE AS select event_date,level,countState(level)counts from system.text_loggroup by event_date,level order by event_date,level;
再次查询:
select event_date,level,countMerge(counts)counts fromtest.log_level_count group by event_date,level order by event_date,level;

可以明显的看出两者查询速度的巨大差异,相差100多倍,看到这里有没有两眼发光,很兴奋,觉得自己学到了一个屠龙技!
那两者为什么同样的结果使用物化视图会快这么多呢?


再看两个查询的不同之处,能明显看出查询处理的数据量不一样,原查询直接查询原表15.5亿的数据,使用物化视图后,物化视图查询的是存在自己视图表里的数据,数据重组后的数据量差异是两者查询速度差异的根本原因。
6.4 物化视图在实践中的使用
因为业务查询条件的不固定,所以在实际业务中没有使用物化视图,不过在对ClickHouse的监控中使用到了,比如每天新增、每小时新增数据量,每天的流量情况以及慢SQL的查询等,这里就不详细展开了。
总结与展望
通过调优,在生产环境中,95%的查询小于1S响应、98%查询小于3秒响应、99%查询小于5秒响应。
文中的优化思路和方法总体上非常的通用,但具体怎么设计和使用需要结合实际的业务场景来进行。比如,在百分点科技项目中数据的存储是随机写到一定数量机器上的,在了解的不少公司实践中,比较推荐的都是对数据按照一定规则进行hash进行让相同的数据落到同一台机器上,我们没有这样做,主要有三点原因:一是数据从源头进来的时候就没有进行hash,二是如果在数据流中进行hash会大大的降低数据流的处理速度,三是数据倾斜问题。
另外,对于项目中存在的一些问题我们也进行了反思,比如选用的版本,还不是很稳定和比较优的版本,选择一个版本需要花费时间和精力进行各种测试,这个版本也只是在当时匆忙的时间与多个版本中综合妥协的选择。现在,ClickHouse的大版本已经更新到21.X,在此版本后,又出现了很多新功能,比如对于小表的wide part功能、SQL的explain功能、mysql同步数据到ClickHouse、开窗函数,以及使用S3等作为ClickHouse底层存储进行存算分离等,需要学习和实践的还有很多。
文章的最后,就以开窗函数作为彩蛋吧!
开窗函数
开窗函数这个功能在21.3中出现实验性功能,使用这个功能需要设置allow_experimental_window_functions = 1。
实例:求过去10分钟每分钟都出现并连续出现3次的活跃ip。
使用开窗函数的写法:
select count(distinct s_ip)from( select s_ip,dt-rank*60 flat_date from( select s_ip, found_time dt, rank() over(partition by s_ip order by dt)rank from s_ip_group_view2 where found_time>=1620583215and found_time<=1620583915 order by s_ip,dt )group by s_ip,flat_date havingcount()>=3 );

在没有开窗函数之前的写法:
select count(distincts_ip)from( select s_ip from( select s_ip,dt2 from( selects_ip,groupArray(dt)dt_arr,arrayEnumerate(dt_arr)dt_arr_enum,arrayMap((x,y)->(x-y*60),dt_arr,dt_arr_enum)map_arrfrom( select s_ip, found_time dt from s_ip_group_view2 where found_time>=1620583215and found_time<=1620583915 order by s_ip,dt ) group by s_ip)ARRAY JOINmap_arr as dt2 )group by s_ip,dt2 havingcount()>=3);

可以看出,使用开窗函数后不但SQL简洁不少,执行速度也快很多。开窗函数对于数仓的朋友来说,简直就是福音。
说明:
文中所做测试用的均是测试数据,与生产会有一定偏差,但总体不影响本文中的相关结论;
测试机器使用的RAID5,具体IO行为与SSD会有差别。
参考资料
[1] 官网:https://clickhouse.tech/docs/en/
[2] 《ClickHouse原理解析与开发实战》朱凯
[3] https://www.altinity.com/blog/
转载:https://mp.weixin.qq.com/s/46tvZYjy-IiWdwoJhp1KDQ


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY