Yarn的工作机制
我们知道 YARN 是 Hadoop 资源管理器,无论是 MapReduce 应用还是 Spark 应用,应该都会用到 Yarn。
Yarn 的组成以及工作流程:
先介绍几个角色
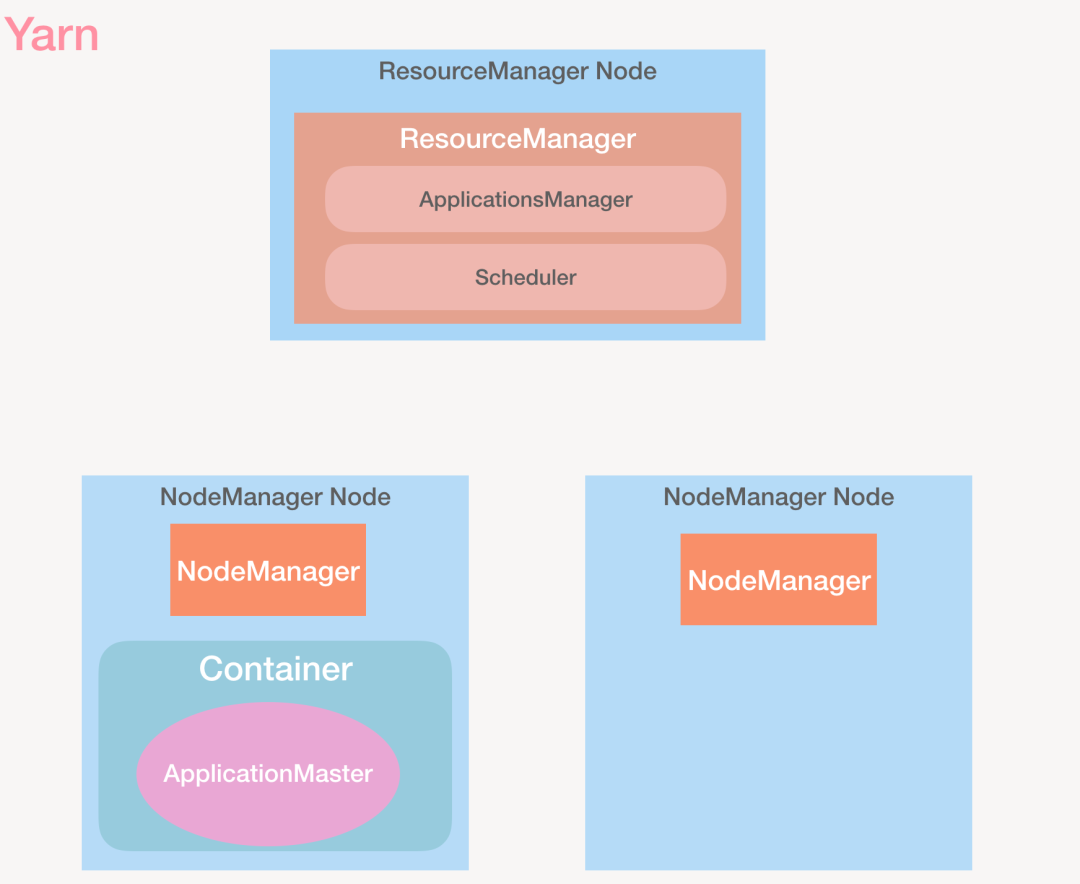
ResourceManager
一个集群只有一个 RM,它是 YARN 的总指挥,负责协调集群上的计算资源,它有以下两个组件:
- ApplicationsManager:这个不是 ApplicationMaster,注意区分。它会接受 Job 的提交请求,调度 Container 用于启动 ApplicationMaster,以及负责 ApplicationMaster 的失败重启。
- Scheduler:调度器纯粹为应用程序分配资源,它不会监控应用的状态,这里的调度就是基于 Container 这个抽象的资源容器,包含内存、CPU、磁盘、网络等。
NodeManager一个集群中有多个 NodeManager,它负责启动 Container,监控 Container 的资源使用情况(cpu、内存、磁盘、网络),并将这些信息汇报给 RM。一个 NodeManager 上可以有多个 Container。
ContainerContainer 是一组硬件资源的抽象,包含 CPU、内存、磁盘、网络等,所有的 Job 都是在 Container 中运行;
ApplicationMaster与 RM 协商资源,并与 NodeManager 一起监控任务,ApplicationMaster 和 Job 一样,都是运行在 Container 中。
下面我们详细了解下一个任务是怎么提交到 Yarn 中运行的。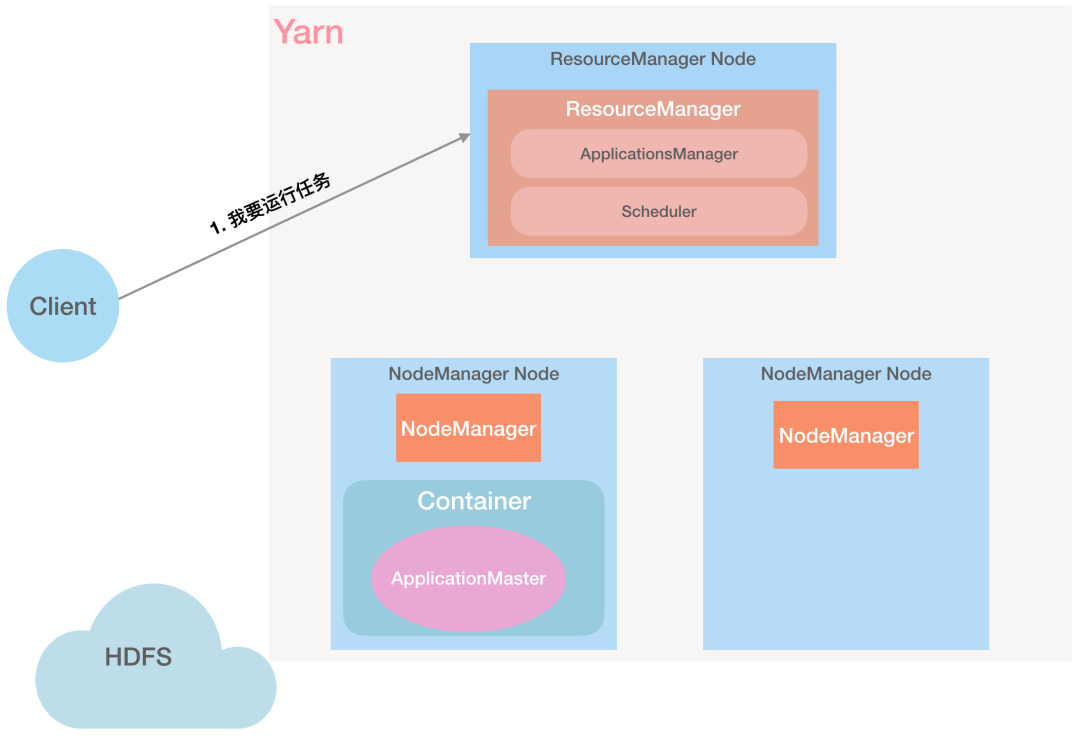
第 1 步:Client 向 RM 发起任务请求:「RM,我要执行一个任务」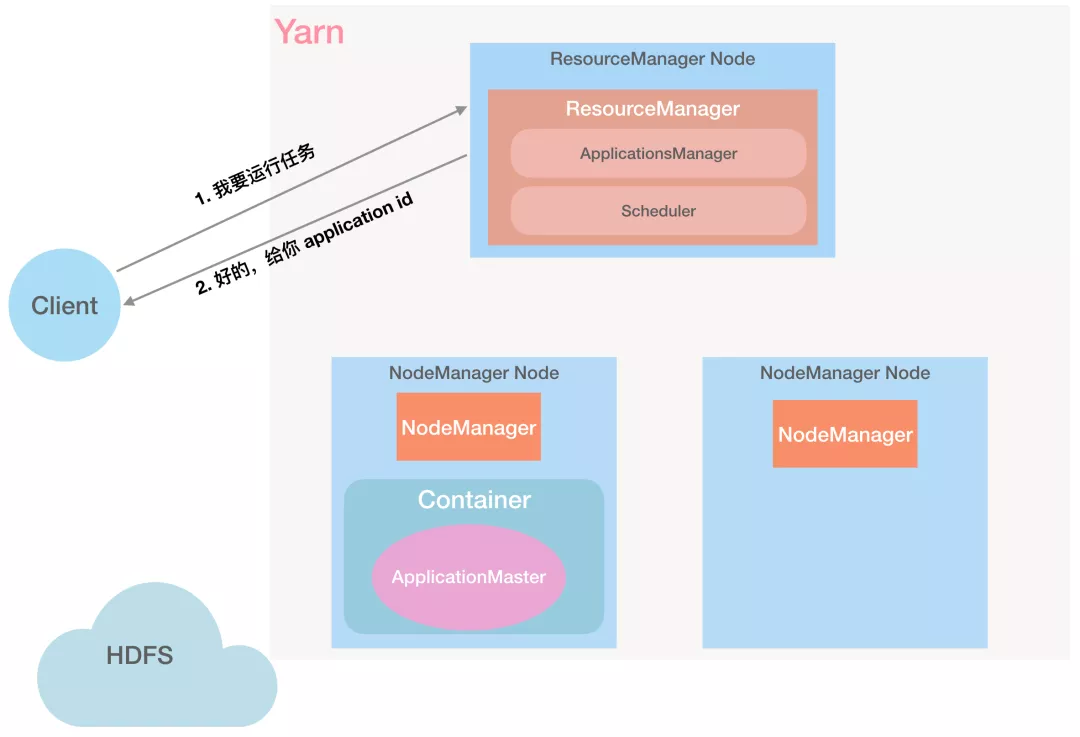
第 2 步:RM 给 Client 返回 Application ID 等信息:「好的,给你分配一个 Application ID」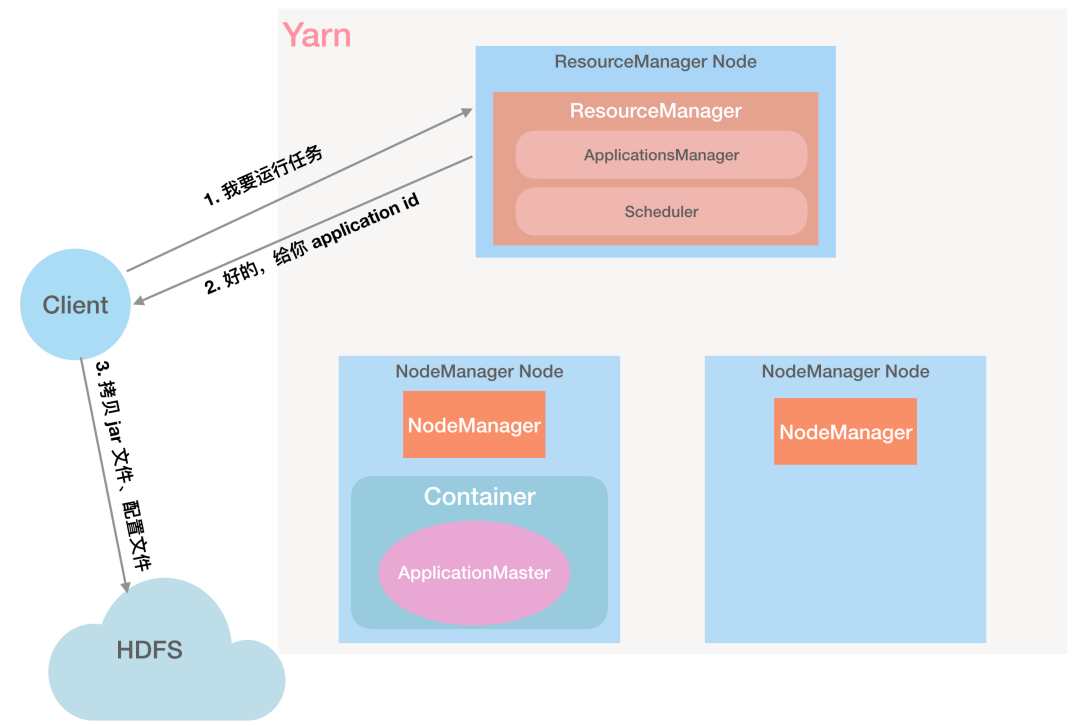
第 3 步:Client 根据返回的信息,检查作业的输入输出目录是否正确、计算作业输入分片是否正常,将运行作业需要的资源(作业 Jar 文件、配置文件、输入分片)复制到以 Application ID 命名的 HDFS 目录中。
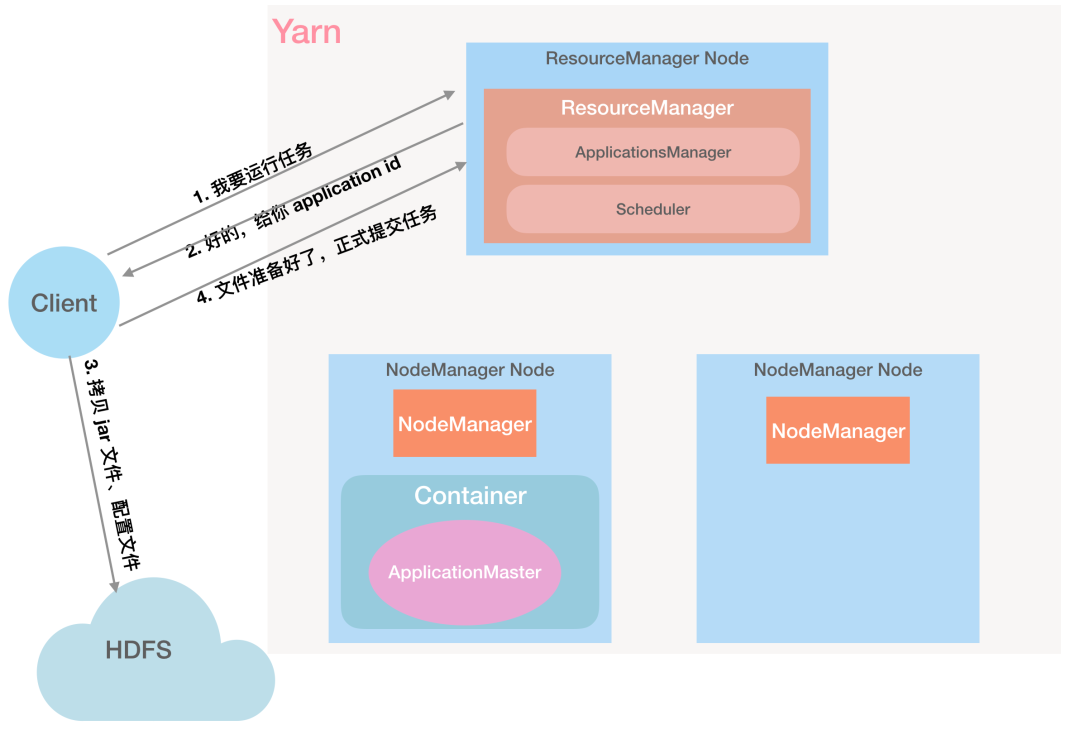
第 4 步:Client 向 RM 正式提交作业:「我都准备好了,执行任务吧」
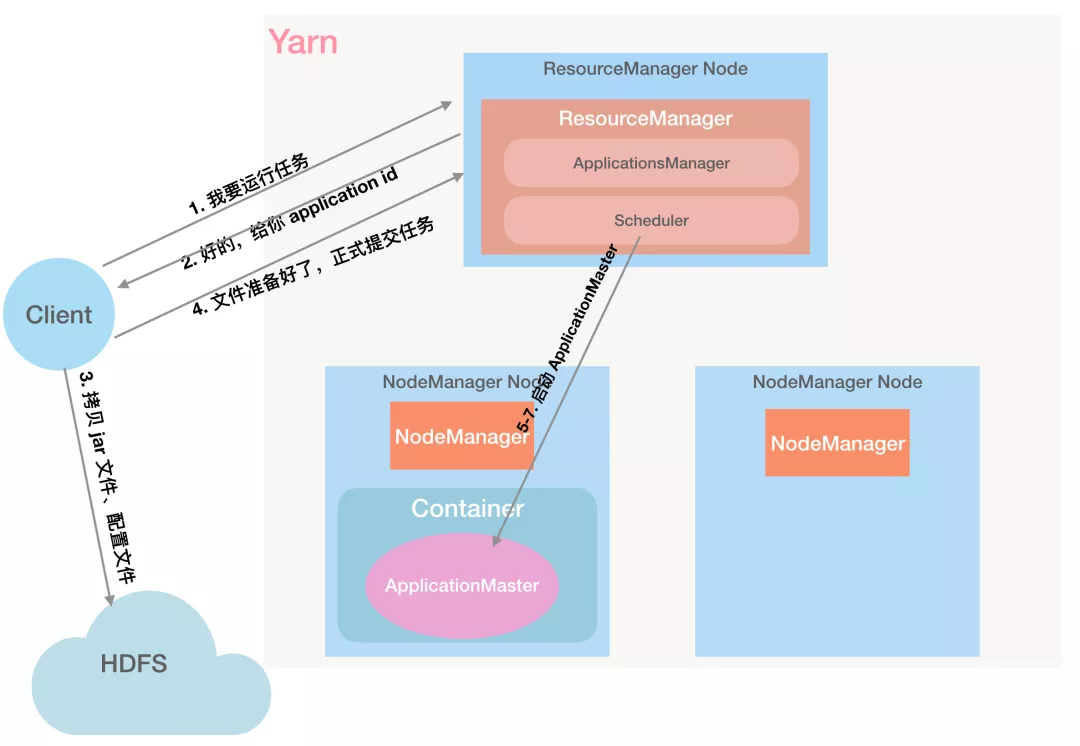
第 5 步:RM 将请求信息传递给自己的小弟 Scheduler:「Scheduler 老弟,你来分配个 Container」
第 6 步:Scheduler 分配 Container,用于启动 ApplicationMaster:「好的,这个 Container 就是 0 号选手」
第 7 步:ApplicationsManager 与指定的 NodeManager 通信,要求在 Container 中启动 ApplicationMaster。
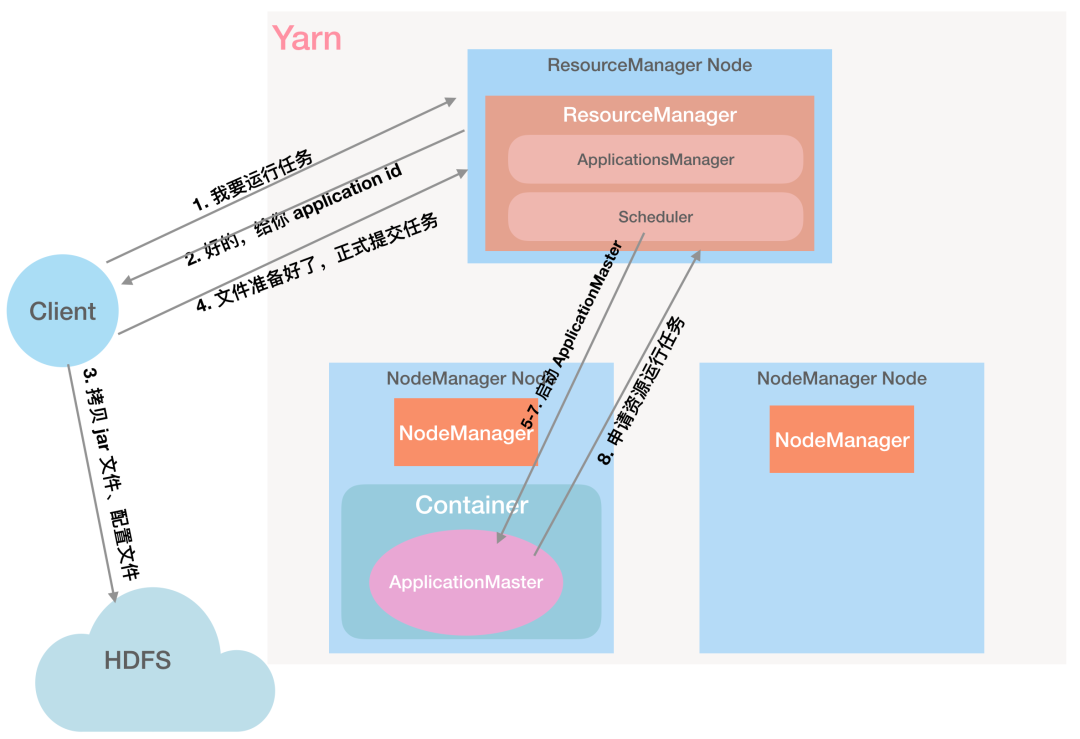
第 8 步:ApplicationMaster 初始化任务并向 RM 申请所需要的资源:「RM 大哥,给我资源运行任务」
第 9 步:RM 返回 ApplicationMaster 申请的资源:「给你 1、2 两个 NodeManager」
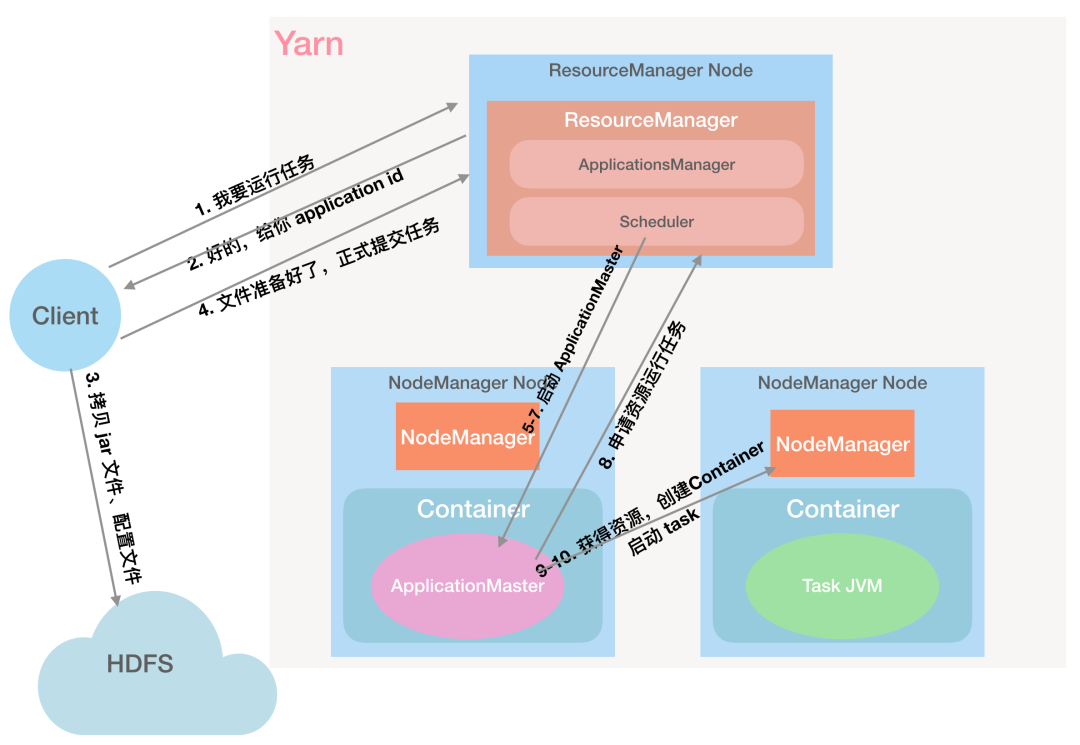
第 10 步:ApplicationMaster 与对应的 NodeManager 通信,申请 Container 启动任务「NodeManager 大哥,给我启动 Container 运行这个任务」
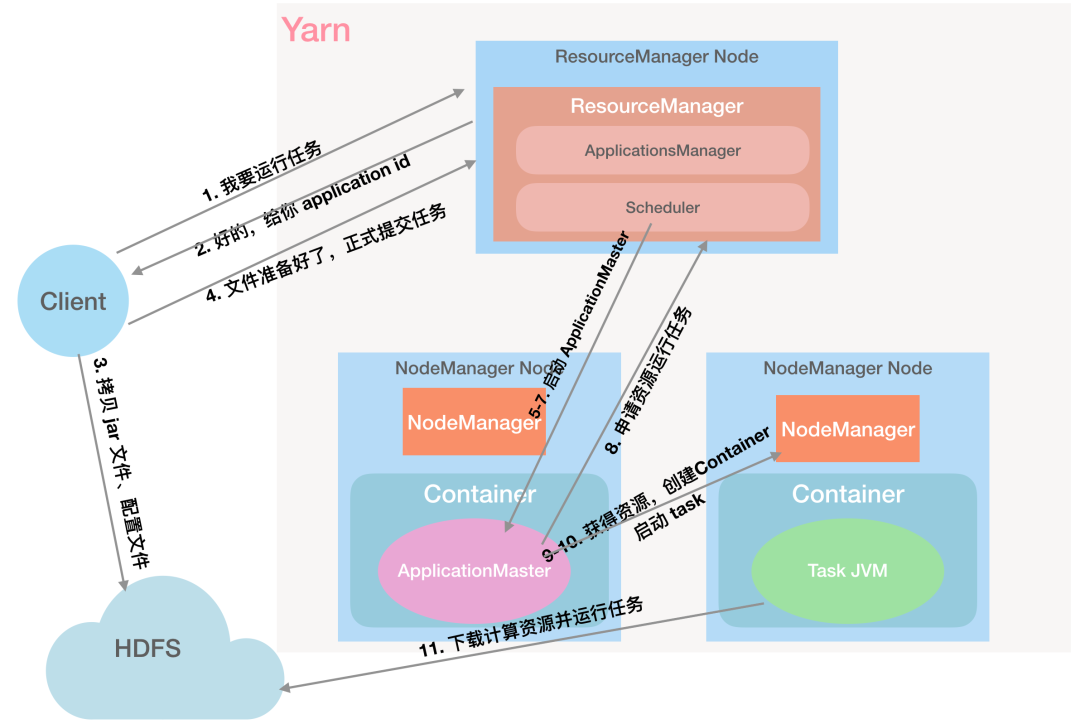
第 11 步:Container 中的应用程序会先将需要的计算资源从 HDFS 下载到本地,再启动任务:「都给我跑起来」
第 12 步:运行过程中,任务会将状态和进度报告给 ApplicationMaster,Client 每秒 (通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
第 13 步:运行完成后,Container 会注销掉,也就是把资源归还给系统,ApplicationMaster 向 RM 注销自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号