hadoop block missing处理
1、hdfs web界面出现文件block丢失

2、block丢失的时候报的什么错?
hadoop fs -get /user/bizlogcenter/warehouse/eunomia/160/warnning/2019-02-26/10.149.32.154.log
![]()
19/04/12 21:06:27 WARN hdfs.DFSClient: Found Checksum error for BP-1472871384-10.143.46.220-1508649897332:blk_1074936834_1198570811 from 10.143.57.89:1004 at 3123200
19/04/12 21:06:27 WARN hdfs.DFSClient: Found Checksum error for BP-1472871384-10.143.46.220-1508649897332:blk_1074936834_1198570811 from 10.143.59.46:1004 at 3123200
19/04/12 21:06:27 INFO hdfs.DFSClient: Could not obtain BP-1472871384-10.143.46.220-1508649897332:blk_1074936834_1198570811 from any node: java.io.IOException: No live nodes contain current block No live nodes contain current block Block locations: 10.143.57.89:1004 10.143.59.46:1004 Dead nodes: 10.143.57.89:1004 10.143.59.46:1004. Will get new block locations from namenode and retry...
19/04/12 21:06:27 WARN hdfs.DFSClient: DFS chooseDataNode: got # 1 IOException, will wait for 801.7790779945808 msec.
get: Checksum error: /user/bizlogcenter/warehouse/eunomia/160/warnning/2019-02-26/10.149.32.154.log at 3123200 exp: 584468584 got: -486844696
3、为什么会报block丢失呢?
参考官方jira:https://issues.apache.org/jira/browse/HDFS-6804
原因:
After checking the code of Datanode block transferring, I found some race condition during transferring the block to the other datanode. And the race condition causes the source datanode transfers the wrong checksum of the last chunk in replica.
Here is the root cause.
-
Datanode DN1 receives transfer block command from NameNode, say, the command needs DN1 to transfer block B1 to DataNode DN2.
-
DN1 creates a new DataTransfer thread, which is responsible for transferring B1 to DN2.
-
When DataTransfer thread is created, the replica of B1 is in Finalized state. Then, DataTransfer reads replica content and checksum directly from disk, sends them to DN2.
-
During DataTransfer is sending data to DN2. The block B1 is opened for appending. If the last data chunk of B1 is not full, the last checksum will be overwritten by the BlockReceiver thread.
-
In DataTransfer thread, it records the block length as the length before appending. Then, here comes the problem. When DataTransfer thread sends the last data chunk to ND2, it reads the checksum of the last chunk from the disk and sends the checksum too. But at this time, the last checksum is changed, because some more data is appended in the last data chunk.
-
When DN2 receives the last data chunk and checksum, it will throw the checksum mismatch exception.
解决办法:
Some thoughts about how to fix this issue. In my mind, there are 2 ways to fix this.
-
Option1
When the block is opened for appending, check if there are some DataTransfer threads which are transferring block to other DNs. Stop these DataTransferring threads.
We can stop these threads because the generation timestamp of the block is increased because it is opened for appending. So, the DataTransfer threads are sending outdated blocks.
-
Option2
In DataTransfer thread, if the replica of the block is finalized, the DataTransfer thread can read the last data chunk checksum into the memory, record the replica length in memory too. Then, when sending the last data chunk, use the checksum in memory instead of reading it from the disk.
This is similar to what we deal with a RBW replica in DataTransfer.
For Option1, it is hard to stop the DataTransfer thread unless we add some code in DataNode to manage DataTransfer threads.
For Option2, we should lock FsDatasetImpl object in DataNode when reading the last chunk checksum from disk. Otherwise, the last block might be overwritten. But reading from the disk needs time, putting the expensive disk IO operations during locking FsDatasetImpl might cause some performance downgrade in DataNodes.
需要升级Hadoop版本:
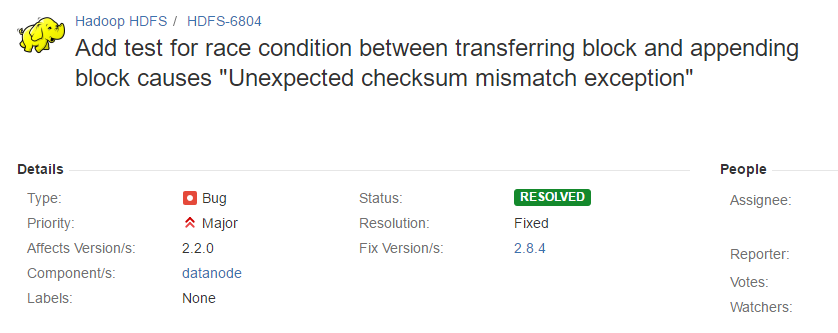
4、有一个replica是正常的为什么namenode不能自动修复?
虽然有一个replica是正常的,但是当remote transfer异常之后,异常的datanode向namenode汇报这个错误,namenode面对这种报错的处理方式是,认为所有副本都坏了,尽管source replica上的block是正常的
5、怎么恢复missing的文件呢?
其实文件missing是namenode自己对iNode进行标记的,但是还是有block块是正常的,是因为append操作导致了block块的checksum有问题,但是读能正常读取,所有我们可以get或者cat hdfs上的文件到本地,然后通过fsck -delete删除文件,最后put文件来修复该missing文件
6、删除missing file后,block会自动删除?
DataNode上的missing block,之前的两副本,其中一个是正常的,另一个是当时remote transfer异常的,所以删除该文件之后,正常的block file能删除,异常的不能删除,需手动删除
dataNode有个directoryScanner应该会自动处理,不过貌似启动的间隔周期很长,6个小时
posted on 2020-03-17 15:57 gentleman_hai 阅读(2765) 评论(0) 编辑 收藏 举报

